Bojie Li
2024-07-21
Space Exploration Requires Too Much Fuel
When I was a child, there was an old man in our yard who worked in aerospace. He often explained some aerospace knowledge to me. What impressed me the most was a solar system space map on his wall, similar to the one below.

The old man told me, Doesn’t this solar system space map look a lot like a train route map? But the numbers on it are not distances, but changes in speed (Delta-V).
When he was young, he also hoped to build an extensive space network like a train network, but the stations would no longer be Beijing West, Shanghai Hongqiao, but the Earth’s surface, low Earth orbit, Earth-Moon transfer orbit, Mars transfer orbit, Mars surface, etc. Unfortunately, to date, humans have not visited most of the stations on this map.
The most important reason for this is that human energy technology is too backward in the face of space. Current rockets rely on ejecting propellant for propulsion, and the fastest ejection speed today is only about 4500 meters per second. This is much faster than a bullet, but still not very fast in space. For example, the first cosmic velocity is 7900 meters per second, and considering air resistance and gravity at a 250-kilometer orbit, a speed increment of about 9200 meters per second is needed to enter Earth’s orbit at 250 kilometers high.
More critically, the mass of fuel required by rockets grows exponentially with the required speed change. When I was in elementary school, I didn’t understand this. If the ejection speed of the propellant doesn’t change, shouldn’t the speed be proportional to the amount of fuel burned? For example, if a car’s fuel tank has twice as much fuel, it can travel twice as far.
2024-07-06
Nearly 5000 people attended the USTC 2024 Alumni Reunion, and about a quarter of our 2010 class from the School of the Gifted Young returned.

Respected leaders, teachers, and dear alumni:
Good afternoon, everyone! I am Li Bojie from Class 00 of the 2010 cohort. It is a great honor to speak as an alumni representative. In the blink of an eye, it has been ten years since we graduated with our bachelor’s degrees.
First of all, I want to express my most sincere gratitude to my alma mater. From 2010 to 2019, from undergraduate to master’s and doctorate, I met a group of outstanding classmates and alumni who are still my best friends and partners in entrepreneurship. During my Ph.D., Professor Tan from my wife’s lab invited me to give an academic report, and that’s how I met my wife.
2024-05-05
(This article is my Zhihu answer to “Are highly career-oriented men suitable as life partners?”)
After starting my own business, I met many entrepreneurs, most of whom are highly career-oriented men.
I discovered an interesting phenomenon: These entrepreneurs have a significantly higher single rate compared to their peers. Moreover, the stability of their marriages is also lower than that of their peers.
High Single Rate
In the fields of AI, mobile internet, and Web3, successful co-founders of startups are generally worth at least a small fortune; even those whose startups haven’t succeeded have very impressive resumes, such as graduating from prestigious universities, holding high positions in major companies, and having various titles and awards. They certainly have no trouble finding great partners. So why is the single rate so high and marriage stability so low?
The core reason is that highly career-oriented men spend most of their time and interest on their careers, with relatively little investment in life, relationships, and family.
2024-04-22
A month ago, the interview video by Zhihu “New Figures” was finally released. It was my first time participating in such an interview that included aspects of personal life, and it definitely wasn’t a company PR, as the name and products of our company were never mentioned throughout the entire session, and few people even know the real name of our company.
It seems that Zhihu still maintains journalistic integrity, as they did not let me view the video before publishing it; all editing, titles, and voice-overs were done by the Zhihu editors.
(04:16, 215 MB)
Video shooting locations:
- Beijing office
- Home (interview, cooking with my wife, and some photos)
- Shucun Suburban Park (a place where I often run, the flying electric butterfly was made by me in 2017, it got caught in a tree during the shooting, and our very capable photographer climbed up the tree to retrieve it)
2024-04-17
Produced by | Sohu Technology
Author | Liang Changjun
“Every day from 9 AM to 3 PM, I have meetings with foreign teams for remote development, internal testing, or bug fixing.” Entrepreneur Li Bojie, who is about to launch an AI product overseas, has been exceptionally busy recently.
This is a C-end AI evaluation product that helps users recommend different AI models or products. He hopes to make this product the “TikTok of the large model era.”
More than a year ago, when Li Bojie decided to leave Huawei to start his own business, he aimed to enter the overseas market. At that time, domestic large models were still in the stage of fierce technical competition, but now more and more companies are choosing the same direction as him.
Whether it’s ByteDance, Baidu, Alibaba, or large model unicorns like MiniMax, Dark Side of the Moon, and Zero One Everything, they are all accelerating their overseas expansion to tap into the global market.
Many companies are quietly making a fortune. Sohu Technology has learned that several overseas products have achieved rapid growth in users and revenue, and some have even started to become profitable. Some products have seen a surge in traffic with AI support, and are expected to achieve profits of 70 to 80 million yuan this year.
In the mobile internet era, Chinese companies went overseas and created TikTok. Now everyone is trying to create the TikTok of the AI era. This is a huge opportunity, but also full of challenges.
2024-04-15
(This article was first published on Zhihu answer: “How to develop research taste in the field of computer systems?”)
In the blink of an eye, it’s been nearly 10 years since I graduated from USTC. Yesterday, while discussing with my wife the recent developments of our classmates in the USTC systems circle, I realized that research taste is the most critical factor in determining academic outcomes. The second key factor is hands-on ability.
What is research taste? I believe that research taste is about identifying influential future research directions and topics.
Many students are technically strong, meaning they have strong hands-on skills and system implementation abilities, but still fail to produce influential research outcomes. The main reason is poor research taste, choosing research directions that either merely chase trends without original thought or are too niche to attract attention.
PhD Students’ Research Taste Depends on Their Advisors
I believe that research taste initially depends heavily on the advisor, and later on one’s own vision.
2024-04-14
(This article was first published on Zhihu Answer: “What are the current benchmarks for evaluating large language models?”)
We must praise our co-founder @SIY.Z for Chatbot Arena!
Chatbot Arena is a community-based evaluation benchmark for large models. Since its launch a year ago, Chatbot Arena has received over 650,000 valid user votes.
Chatbot Arena Witnesses the Rapid Evolution of Large Models
In the past month, we have witnessed several very interesting events on Chatbot Arena:
- Anthropic’s release of Claude-3, with its large Opus model surpassing GPT-4-Turbo, and its medium Sonnet and small Haiku models matching the performance of GPT-4. This marks the first time a company other than OpenAI has taken the top spot on the leaderboard. Anthropic’s valuation has reached $20B, closely approaching OpenAI’s $80B. OpenAI should feel a bit threatened.
- Cohere released the strongest open-source model to date, Command R+, with a 104B model matching the performance of GPT-4, although still behind GPT-4-Turbo. Earlier this year, I mentioned the four major trends for large models in 2024 during an interview with Jiazi Guangnian (“AI One Day, Human One Year: My Year with AI | Jiazi Guangnian”): “Multimodal large models capable of real-time video understanding and generating videos with complex semantics; open-source large models reaching GPT-4 level; the inference cost of GPT-3.5 level open-source models dropping to one percent of the GPT-3.5 API, making it cost-effective to integrate large models; high-end smartphones supporting local large models and automatic app operation, making everyone’s life dependent on large models.” The first is Sora, the second is Command R+, both have come true. I still hold this view, if a company mainly focused on foundational models cannot train a GPT-4 by 2024, they should stop trying, wasting a lot of computing power, and not even matching open-source models.
- Tongyi Qianwen released a 32B open-source model, almost reaching the top 10, performing well in both Chinese and English. The cost-effectiveness of the 32B model is still very strong.
- OpenAI was surpassed by Anthropic’s Claude Opus, and naturally, they did not show weakness, immediately releasing GPT-4-Turbo-2024-04-09, reclaiming the top spot on the leaderboard. However, OpenAI has been slow to release GPT-4.5 or GPT-5, and the much-anticipated multimodal model has not yet appeared, which is somewhat disappointing.
2024-04-07
This video is an interview with me by the Bilibili uploader “Apple Bubbles”, original video link
The entire interview lasted half an hour, recorded in one take, with no edits except for the intro added by the uploader, and no prepared answers to the questions.
(27:07, 136 MB)
2024-03-29
(The full text is about 40,000 words, mainly from a 2-hour report at the USTC Alumni AI Salon on December 21, 2023, and is a technical extended version of the 15-minute report at the Zhihu AI Pioneers Salon on January 6, 2024. The article has been organized and expanded by the author.)
- Should AI Agents Be More Entertaining or More Useful: Slides PDF
- Should AI Agents Be More Entertaining or More Useful: Slides PPTX

I am honored to share some of my thoughts on AI Agents at the USTC Alumni AI Salon. I am Li Bojie, from the 2010 Science Experimental Class, and I pursued a joint PhD at USTC and Microsoft Research Asia from 2014 to 2019. From 2019 to 2023, I was part of the first cohort of Huawei’s Genius Youth. Today, I am working on AI Agent startups with a group of USTC alumni.
Today is the seventh day since the passing of Professor Tang Xiaou, so I specially set today’s PPT to a black background, which is also my first time using a black background for a presentation. I also hope that as AI technology develops, everyone can have their own digital avatar in the future, achieving eternal life in the digital world, where life is no longer limited and there is no more sorrow from separation.
AI: Entertaining and Useful
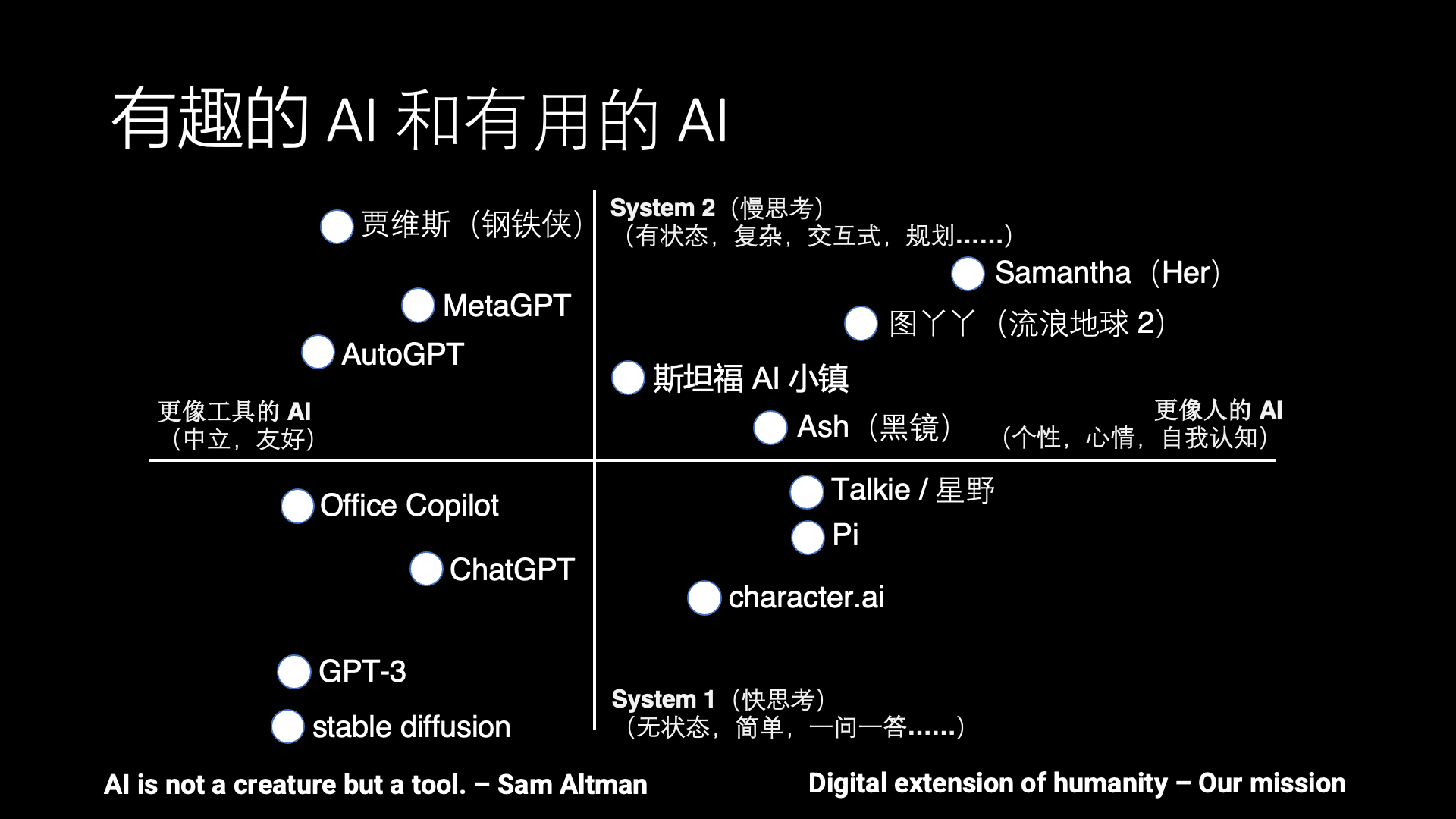
The development of AI has always had two directions, one is entertaining AI, which is more human-like, and the other is useful AI, which is more tool-like.
Should AI be more like humans or more like tools? Actually, there is a lot of controversy about this. For example, Sam Altman, CEO of OpenAI, said that AI should be a tool, not a life form. However, many sci-fi movies depict AI that is more human-like, such as Samantha in Her, Tu Ya Ya in The Wandering Earth 2, Ash in Black Mirror, so we hope to bring these sci-fi scenarios to reality. Only a few sci-fi movies feature tool-like AI, such as Jarvis in Iron Man.
Besides the horizontal dimension of entertaining and useful, there is another vertical dimension, which is fast thinking and slow thinking. This is a concept from neuroscience, from the book “Thinking, Fast and Slow,” which says that human thinking can be divided into fast thinking and slow thinking.
Fast thinking refers to basic visual and auditory perception abilities and expressive abilities like speaking that do not require deliberate thought, like ChatGPT, stable diffusion. These are tool-like fast thinking AIs that respond to specific questions and do not initiate interaction unless prompted. Whereas Character AI, Inflection Pi, and Talkie (Hoshino) simulate conversations with a person or anime game character, these conversations do not involve solving complex tasks and lack long-term memory, thus they are only suitable for casual chats and cannot help solve problems in life and work like Samantha in Her.
Slow thinking refers to stateful complex thinking, which involves planning and solving complex problems, determining what to do first and what to do next. For example, MetaGPT writing code simulates the division of labor in a software development team, and AutoGPT breaks down a complex task into many stages to complete step by step. Although these systems still have many practical issues, they already represent a nascent form of slow thinking capability.
Unfortunately, there are almost no products in the first quadrant that combine slow thinking with human-like attributes. Stanford AI Town is a notable academic attempt, but there is no real human interaction in Stanford AI Town, and the AI Agent’s daily schedule is pre-arranged, so it is not very interesting.
Interestingly, most of the AI in sci-fi movies actually falls into this first quadrant. Therefore, this is the current gap between AI Agents and human dreams. Therefore, what we are doing is exactly the opposite of what Sam Altman said; we hope to make AI more human-like while also capable of slow thinking, eventually evolving into a digital life form.
2024-02-25
Since December 2023, I have been working as a corporate mentor in collaboration with Professor Junming Liu from USTC on an AI Agent practical project, with about 80 students from across the country participating. Most of them are undergraduates with only basic programming skills, along with some doctoral and master’s students with a foundation in AI.
In December 2023 and January 2024, we held 6 group meetings to explain the basics of AI Agents, how to use the OpenAI API, this AI Agent practical project, and to answer questions students had during the practice. The practical project includes:
- Corporate ERP Assistant
- Werewolf
- Intelligent Data Collection
- Mobile Voice Assistant
- Meeting Assistant
- Old Friends Reunion
- Undercover
From February 20-24, some students participating in this research project gathered in Beijing for a Hackathon and presented the interim results of their projects. Participants generally felt the power of large models, surprised that such complex functions could be achieved with just a few hundred lines of code. Below are some of the project outcomes: