Bojie Li (李博杰)
2023-07-04
2012 年 11 月,我的博客随 USTC Blog 诞生。2013 年 5 月,我的博客有了独立域名 bojieli.com。2015 年 1 月,博客启用新域名 ring0.me,ring0 是 x86 体系结构中的最高特权级,意味着我对系统底层技术不懈的追求。
今天,我注册了溢价域名(premium domain) 01.me。0 和 1 是二进制仅有的两个数位,我选择这个域名是希望投身 AGI(通用人工智能)事业,为基于 0 和 1 的硅基生命作出一点微小的贡献。
01.me 这个域名也有一定的投资价值,01.org 是 Intel Open Source 的官网,01.ai 是李开复老师 AI 创业公司零一万物的官网,01.com 曾在 2017 年售出过 $1,820,000 的高价(当然 .me 和 .com 的价值不可同日而语)。
为方便在微信等国内平台上分享文章,本网站另有两个国内备案过的域名 bojieli.com 和 boj.life。待注册局的新注册域名 60 天保护期过后,可能会考虑把 01.me 迁到国内注册商,进行备案。
2023-06-20
KV-Direct: High-Performance In-Memory Key-Value Store with Programmable NIC
Bojie Li, Zhenyuan Ruan, Wencong Xiao, Yuanwei Lu, Yongqiang Xiong, Andrew Putnam, Enhong Chen and Lintao Zhang.
Proceedings of the 26th Symposium on Operating Systems Principles (SOSP ‘17). [PDF] [Slides]
Transcription with Whisper.

2023-06-19
ClickNP: Highly Flexible and High-Performance Network Processing with Reconfigurable Hardware
Bojie Li, Kun Tan, Layong (Larry) Luo, Yanqing Peng, Renqian Luo, Ningyi Xu, Yongqiang Xiong, Peng Cheng and Enhong Chen.
Proceedings of the 2016 ACM SIGCOMM Conference (SIGCOMM ‘16). [PDF] [Slides]
Transcription with Whisper.

2023-06-14
Polling and interrupt has long been a trade-off in RDMA systems. Polling has lower latency but each CPU core can only run one thread. Interrupt enables time sharing among multiple threads but has higher latency. Many applications such as databases have hundreds of threads, which is much larger than the number of cores. So, they have to use interrupt mode to share cores among threads, and the resulting RDMA latency is much higher than the hardware limits. In this paper, we analyze the root cause of high costs in RDMA interrupt delivery, and present FastWake, a practical redesign of interrupt-mode RDMA host network stack using commodity RDMA hardware, Linux OS, and unmodified applications. Our first approach to fast thread wake-up completely removes interrupts. We design a per-core dispatcher thread to poll all the completion queues of the application threads on the same core, and utilize a kernel fast path to context switch to the thread with an incoming completion event. The approach above would keep CPUs running at 100% utilization, so we design an interrupt-based approach for scenarios with power constraints. Observing that waking up a thread on the same core as the interrupt is much faster than threads on other cores, we dynamically adjust RDMA event queue mappings to improve interrupt core affinity. In addition, we revisit the kernel path of thread wake-up, and remove the overheads in virtual file system (VFS), locking, and process scheduling. Experiments show that FastWake can reduce RDMA latency by 80% on x86 and 77% on ARM at the cost of < 30% higher power utilization than traditional interrupts, and the latency is only 0.3~0.4 𝜇s higher than the limits of underlying hardware. When power saving is desired, our interrupt-based approach can still reduce interrupt-mode RDMA latency by 59% on x86 and 52% on ARM.
Publication
Bojie Li, Zihao Xiang, Xiaoliang Wang, Han Ruan, Jingbin Zhou, and Kun Tan. FastWake: Revisiting Host Network Stack for Interrupt-mode RDMA. In 7th Asia-Pacific Workshop on Networking (APNET 2023), June 29–30, 2023, Hong Kong, China. [Paper PDF] [Slides PPTX] [Slides PDF] [Video] [Talk Transcript]
 APNet group photo @ HKUST campus
APNet group photo @ HKUST campus
 APNet group photo @ Victoria Harbour Cruise
APNet group photo @ Victoria Harbour Cruise
People
- Bojie Li, Technical Expert at Computer Networking and Protocol Lab, Huawei.
- Zihao Xiang, Senior Developer at Computer Networking and Protocol Lab, Huawei.
- Xiaoliang Wang, Associate Professor, Nanjing University.
- Han Ruan, Senior Technical Planning Expert at Computer Networking and Protocol Lab, Huawei.
- Jingbin Zhou, Director of Computer Networking and Protocol Lab, Huawei.
- Kun Tan, Director of Distributed and Parallel Software Lab, Huawei.
2023-06-11
(本文系笔者根据 2022 年 12 月 12 日在北京大学的演讲整理,首先将会议录音使用科大讯飞语音识别转换成口水稿,然后用 GPT-4 加以润色,修正语音识别的错误,最后人工加入一些新的思考)

无线网络是一个非常广阔的领域,对应华为的两大产品线,一是无线,二是消费者 BG。无线主要就是我们熟悉的 5G 和 Wi-Fi,而消费者 BG 做的是包括手机在内的各种智能终端。
在上一章广域网开头我们就提到,当前的传输协议对无线网络和广域网的带宽并没有充分利用,导致很多应用实际上无法体验到 5G 和 Wi-Fi 标称的数百 Mbps 高带宽,这就是我们常说的 “最后一公里” 问题。随着无线网络的性能越来越接近有线网络,一些原本适用于数据中心的优化将适用于无线网络。之前我们提到分布式系统,想到的都是数据中心,而现在家中这么多终端设备和智能家居设备,也组成了一个分布式系统,未来有可能一个家庭就是一个迷你数据中心。
2023-05-28
(本文系笔者根据 2022 年 12 月 12 日在北京大学的演讲整理,首先将会议录音使用科大讯飞语音识别转换成口水稿,然后用 GPT-4 加以润色,修正语音识别的错误,最后人工加入一些新的思考)

广域网主要分为两大类通信模式,一类是端云通信,一类是云际通信。我们先从端云开始讲起。
端云网络
我们一般提到广域网,就认为它是不可控的,运营商的网络设备都不是自己能控制的,还有大量其他用户在并发访问,很难做到确定性。但今天的很多应用又需要一定程度的确定性,比如视频会议、网络游戏,时延高到一定程度用户就会感觉卡顿。如何调和这一对矛盾呢?这就是我们今天的课题。
就像我们在上一章数据中心网络中讲到的,应用实际感受到的带宽与物理带宽差距很大,因此才有优化的空间。我们知道现在 5G 和 Wi-Fi 的理论带宽都是数百 Mbps 乃至上 Gbps,家庭宽带的带宽很多也是几百 Mbps 甚至达到了千兆,理论上 100 MB 的数据一两秒钟就能传输完成。但我们在应用市场里面下载应用的时候,有几次是 100 MB 的应用一两秒钟就能下载完的?另外一个例子,压缩后的 4K 高清视频只需要 15~40 Mbps 的传输速度,听起来远远没有达到带宽的理论上限,但我们有多少网络环境能流畅看 4K 高清视频?这一方面是端侧无线网络的问题,一方面是广域网的问题。要把理论带宽用好,还有很长的路要走。
我当年在微软实习的时候,微软大厦二楼的中餐厅就叫做 “云 + 端”(Cloud + Client),12 楼 sky garden 那里的背景板也写着 cloud first, mobile first,数据中心和智能终端确实是 2010~2020 年最火的两个领域。但可惜的是微软的移动端一直没做起来。华为恰好是在端云两侧都有强大的实力,因此在端云协同优化方面有着独特的优势。
2023-05-27
(本文系笔者根据 2022 年 12 月 12 日在北京大学的演讲整理,首先将会议录音使用科大讯飞语音识别转换成口水稿,然后用 GPT-4 加以润色,修正语音识别的错误,最后人工加入一些新的思考)
非常感谢黄群教授和许辰人教授邀请,很荣幸来到北京大学为两位教授的计算机网络课程做客座报告。我听说你们都是北大最优秀的学生,我可是当年做梦都没进得了北大,今天能有机会来跟大家交流计算机网络领域学术界和工业界的一些最新进展,实在是非常荣幸。
图灵奖得主 David Patterson 2019 年有一个非常有名的演讲,叫做《计算机体系结构的新黄金时代》(A New Golden Age for Computer Architecture),它讲的是通用处理器摩尔定律的终结和领域特定体系结构(DSA)兴起的历史机遇。我今天要讲的是,计算机网络也进入了一个新黄金时代。
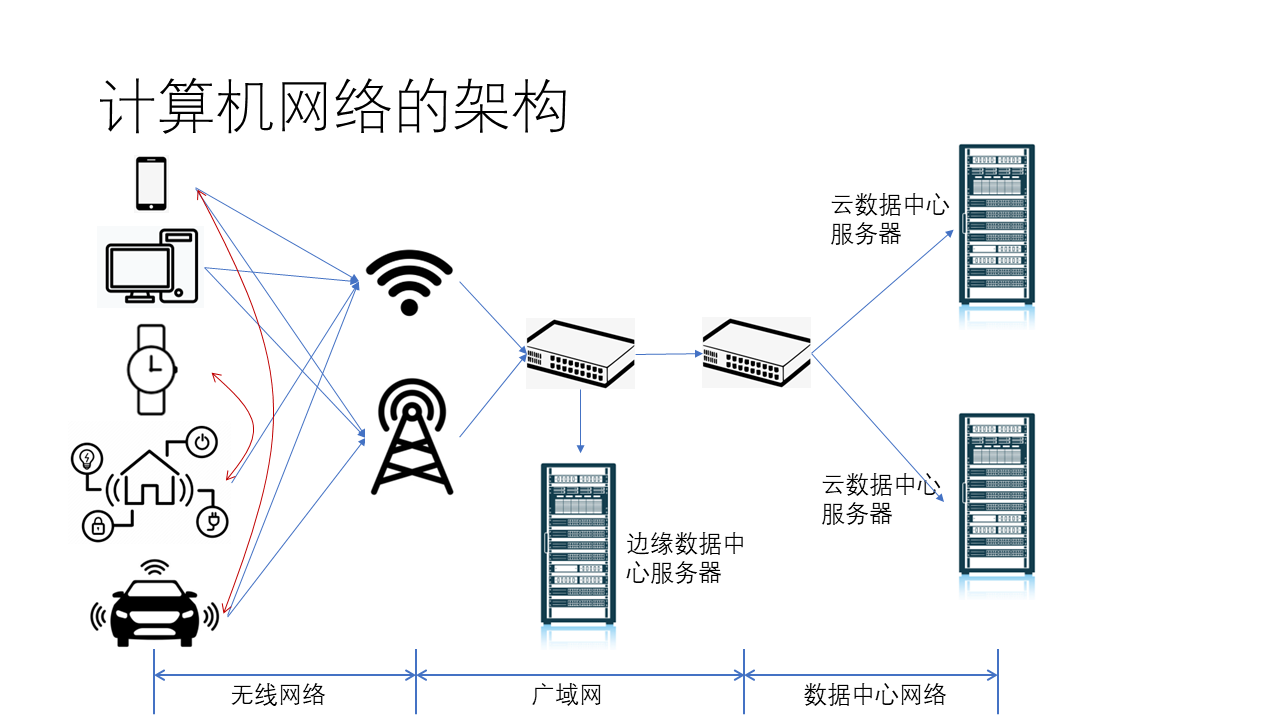
我们日常接触到的计算机网络主要由三大部分组成:无线网络、广域网和数据中心网络。它们为万物互联的智能世界提供了通信基石。
其中,无线网络的终端设备包括手机、PC、手表、智能家居、智能汽车等各种设备。这些设备通常是通过无线方式(如 Wi-Fi 或 5G)访问网络。经过 5G 基站和 Wi-Fi 热点之后,设备将进入广域网。广域网中还有一些 CDN 服务器,这些服务器属于边缘数据中心。接下来,设备将进入数据中心网络。在数据中心网络中,还有许多不同类型的设备,如网关、服务器等。

今天,我将分别从数据中心网络、广域网和终端无线网络这三个领域给大家做一些介绍。首先,让我们来看数据中心网络。数据中心网络最大的变化是从为简单的 Web 服务设计的简单网络,演变成为大规模异构并行计算所设计的网络,执行 AI、大数据、高性能计算等传统上超级计算机才能处理的任务。
2023-05-27
(智造公社微信公众号文章,原文链接,非常感谢智造公社的精彩问题和整理编辑)
AI到底会对人类社会的技术和生活产生什么影响?
随着GPT4发布,大模型AI的性能再一次刷新公众想象,AIGC产出的内容越发真实、精致,随着数据清洗和训练的不断深入,AI对自然语言的理解能力也显示出了巨大的进步,从被动地接受数据“投喂”,到主动向世界发问,或许,科幻片里的“人工智能生命”已经距离我们不再遥远。
焦虑在所难免,“AI失业”在部分行业似乎正在真切上演。当地时间2023年5月18日,英国最大的电信运营商英国电信公司表示,将在2028年至2030年期间裁员4万至5.5万人。此次裁员将包括英国电信的直接员工和第三方员工,将使公司员工总数减少31-42%。目前,英国电信公司员工数量约为13万人。
英国电信的老板菲利普·詹森对外宣称,在完成光纤铺设、数字化工作方式、采用人工智能(AI)并简化其结构之后,将依靠更少的劳动力和显著降低的成本基础,“新的英国电信集团将是一个更精简的企业,拥有更光明的未来”。回看国内,一些互联网科技企业也显露出了相关的势头,尤其游戏公司的美术外包等岗位,堪称“重灾区”。
谈及这个问题,华为2012实验室助理科学家李博杰表示,公众的一些焦虑被媒体放大了,AI技术并非取代人类的洪水猛兽,反而,是解放生产力,塑造更多新岗位的浪潮,“比如说我们去看过去的工业革命,原来做农耕的人现在都要去使用机器了,他所需要的教育,以及对社会、经济和人们的生活生产方式变化都非常大”。
李博杰认为,在AI技术普及,成为一种新的生产工具以后,又会因应产生更多业态以及职业,“比如说有了电脑之后,就不需要抄写员在那辛辛苦苦抄东西了对吧?AI也是一样的,有些行业直接涉及人的,它没办法取代,比如说像服务业对吧?但有些很按部就班做固定模式化的东西,AI就可以简化很多的劳动”。
作为和AI密切相关的数据中心网络技术研究者,李博杰提出了许多对AI的看法和思考,下面,是智造公社主笔小智与李博杰的对谈记录:
2023-05-25
这是我 5 年前的旧文。那是 2018 年初的冬夜,我在十三陵自己架起了一口大锅,向 8.6 光年之外的天狼星发送了人类知识的一小部分。这件事背后的故事在这里。今天我们关心的是,向可能的外星文明发送消息,显然需要让外星文明认识到这个消息是一个智慧生命发出的,还得让外星文明理解它。
一个很基础的问题就是,如何在消息中证明自己的智能程度呢?换言之,如果我是一个监听宇宙信号的智慧生命,如何判断收到的一堆信号中是否包含智能?由于智能不是一个有或无的问题,而是一个多或少的问题,如何衡量这堆信号中包含何种程度的智能呢?我觉得 5 年前自己的思考还是有点意思,整理一下发出来。
消息就是一个字符串。设想我们能够截获外星人的所有通信,拼接成一条长长的消息。它包含多少智能?这并不是一个容易回答的问题。
现有技术一般是尝试对消息进行解码,然后看它是否表达了数学、物理学、天文学、逻辑学等科学中的基本信息。1974 年的阿雷西博信息就是用这种方式来编码信息,希望得到地外文明的关注的。我则试图找到一种纯计算的方法来衡量消息中蕴含的智能程度。
2023-04-20

昨天这条朋友圈在公司内外引起热议,很多人来联系我。
我是从创新和商用两个角度考虑的。