APNet'23 Talk Transcription for FastWake: Revisiting Host Network Stack for Interrupt-mode RDMA
虽然大多数人比较喜欢看视频,但是我更喜欢看文字,因为文字便于非线性查找,可以快速跳读,也便于随时回顾前面的内容。
最近,我把我在学术会议上的一些演讲视频转成了文字,例如 ClickNP、KV-Direct 和 计算机网络的新黄金时代系列,今天发布的是 APNet 2023 上的 FastWake。在 ClickNP 和 KV-Direct 演讲前,我都是先在 PPT 的备注里写好稿子,到场上直接对着备注念。今年连 PPT 都是会议前一天才赶完的,更没有时间写备注了,甚至都没有完整的练习一遍,我就直接上台去讲了。
现在有了大模型,把演讲视频转成 PPT + 文字稿一点都不难。其实我一直想做个这样的在线会议插件。
- 把视频中的关键帧提取出来组成 PPT 图片列表。每帧和前一帧的差异如果超过一定阈值,就认为是切换了一页 PPT。有一个开源软件 video2pdf 就能做到。
- 把每张图片 OCR 成文字,都是打印字符,识别准确率很高,Tesseract 就可以。
- 把停留在每页 PPT 上的视频音轨提取出来,交给 Speech-to-Text 模型识别,例如我用的是 OpenAI 开源的 Whisper。
- (最后一步很重要)让大语言模型(例如 GPT-4)以 OCR 出来的当前页 PPT 和首页 PPT 内容为参考,修正 Speech-to-Text 模型识别出的 transcription。
Speech-to-Text 模型目前对于专有名词和人名的识别准确率并不高,但是这些专有名词很多是在这一页 PPT 中出现过的,PPT 首页也框定了演讲的标题和领域。因此以 PPT 内容为参考,大语言模型可以修正大部分的专有名词识别错误。如果没有 PPT 内容作为参考,需要 GPT-4 才能修正大部分的专有名词,但有了 PPT 内容,LLaMA-2-70b-chat 就足够了。此外,大语言模型可以修正演讲中口语化的表达,让文字稿更严谨、易读。
以下文字稿完全为自动生成,除了几个人名,一字未改。当然,一些小错误也就保留了,但是都无伤大雅。整个过程中用到的 Video2PDF、Tesseract、Whisper 和 LLaMA-2-70b-chat 模型都跑在我自己的 Mac 笔记本上,全程无需联网。
视频内容
Bojie Li, Zihao Xiang, Xiaoliang Wang, Han Ruan, Jingbin Zhou, and Kun Tan. FastWake: Revisiting Host Network Stack for Interrupt-mode RDMA. In 7th Asia-Pacific Workshop on Networking (APNET 2023), June 29–30, 2023, Hong Kong, China.
文字稿
(Session Chair Gaoxiong Zeng) Okay, let’s start. Welcome to the APNet 2023 session number one on host networking. I am Gaoxiong Zeng from Huawei Technologies. In this session, we have four very interesting papers focusing on host networking and RDMA. Each paper will be presented with a 17-minute talk followed by 3 minutes for Q&A. I hope you enjoy it.
Let’s begin with the first paper titled “FastWake: Revisiting Host Network Stack for Interrupt-mode RDMA”. The speaker is Dr. Bojie Li. Dr. Bojie Li is a technical expert with Huawei Technologies. His research interests include high-performance data center systems. Currently, he’s focusing on high-performance data center interconnect and RPC. He earned his Ph.D. degree in 2019 and received the ACM China Doctoral Dissertation Award. Let’s welcome him.

(Presenter Bojie Li) Thank you, Gaoxiong, for the introduction. I’m honored to be the first speaker following Prof. Haibo Chen’s keynote. I will present “FastWake: Revisiting Host Network Stack for Interrupt-mode RDMA”. I currently work with the Computer Network Protocol Lab at Huawei, and this is a joint work with our lab and Prof. Xiaoliang Wang from Nanjing university.
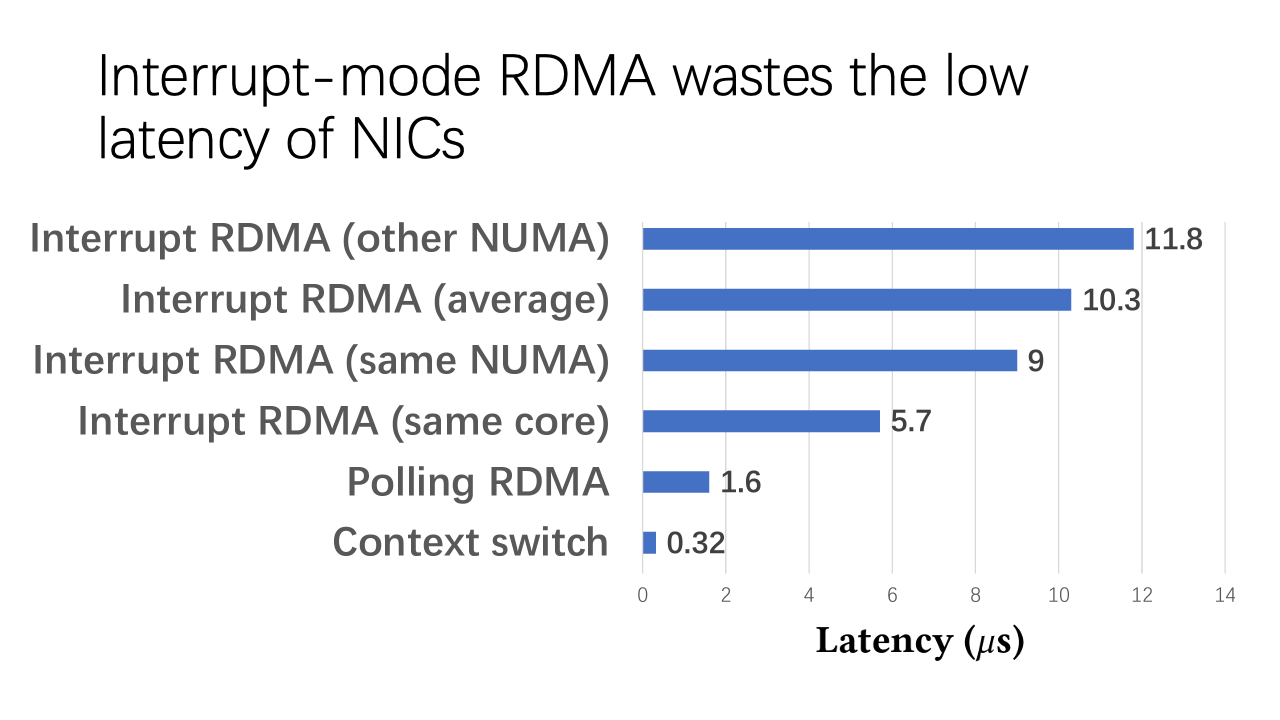
First, let’s revisit why the interrupt mode is crucial for RDMA. There are two scenarios. In some databases, hundreds of threads compete for CPU cores. They require efficient context switching. In other cases, some applications demand low CPU utilization and don’t want to rely on polling, which would make the CPU run at 100% utilization. However, even with RDMA’s low latency, we see that polling RDMA has only 1.6 microseconds of latency, whereas interrupt mode has 10 microseconds. This has led to the emergence of microsecond events which are challenging to address in current operating systems.

There’s a notable paper called “Attack of the Killer Microseconds” from Google, which highlights that current systems can handle nanosecond and millisecond events but struggle with microsecond events. The reasons are twofold:
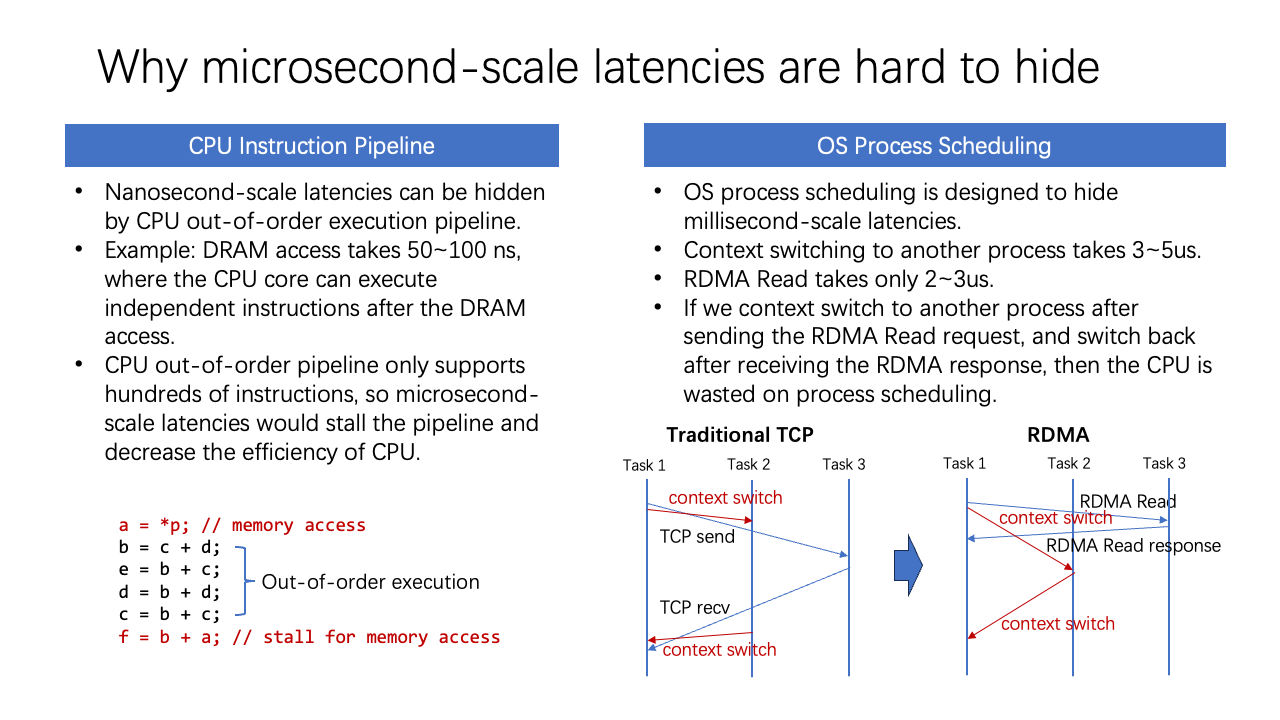
First, the CPU instruction pipeline is designed to mitigate nanosecond-scale latencies due to its out-of-order execution pipeline. But, it can only handle hundreds of instructions, meaning microsecond-scale latencies still stall the CPU pipeline, reducing efficiency.
Second, we can use the OS’s process scheduling. For instance, in traditional TCP, a context switch occurs to another task when the TCP packet is sent out. When the CPU receives the TCP packet, it switches back to the original task. This works well for millisecond-scale latencies. However, if an I/O operation only takes two microseconds, but switching to another process takes three to five microseconds, then valuable CPU time is wasted on process scheduling.
This presents a significant challenge. Our team has proposed a potential approach to address this.
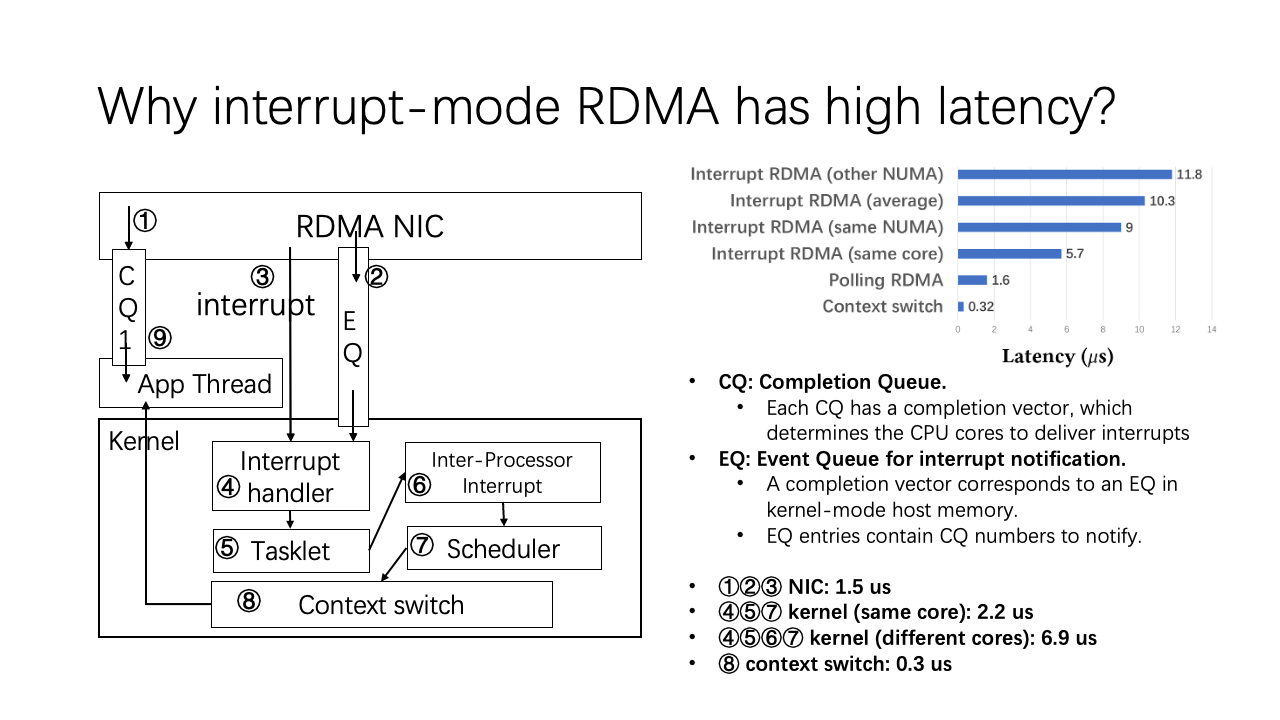
To understand why interrupt mode RDMA has such high latency, we examined the procedure of immediate interrupt delivery. The process involves introducing a completion queue, generating a CQE into the CQ, and for each interrupt notification, there’s an event queue. This event gets generated into the ADMA event queue, subsequently producing an interrupt to the CPU cores. The interrupt handler and associated tasks will then be managed.
The first three steps involving the NIC consume approximately 1.5 microseconds. Depending on whether or not the interrupt core and the thread are on the same core or different ones, the kernel’s subsequent steps take between two to seven microseconds. However, the direct context switch is rapid, consuming only 0.3 microseconds.

This observation led us to consider if we can mitigate some of these latencies either from the NIC side or the kernel side. Two key observations guide our approaches:
First, Direct context switch is faster than process scheduling. For a direct context switch, let’s consider the left side of this slide. The “yield” function is a system call in Linux that relinquishes the current thread’s execution and places it at the end of the scheduling queue. Consequently, Thread Two begins its execution. Using this method, the context switch only takes 0.3 microseconds. However, if we utilize a mutex or similar IPC primitives provided by the kernel for the context switch through process scheduling, it consumes significantly more time.
Given this insight, our goal is to circumvent process scheduling and implement direct context switches instead. This approach promises to streamline operations, optimize CPU efficiency, and pave the way for a more responsive RDMA within data center networks.
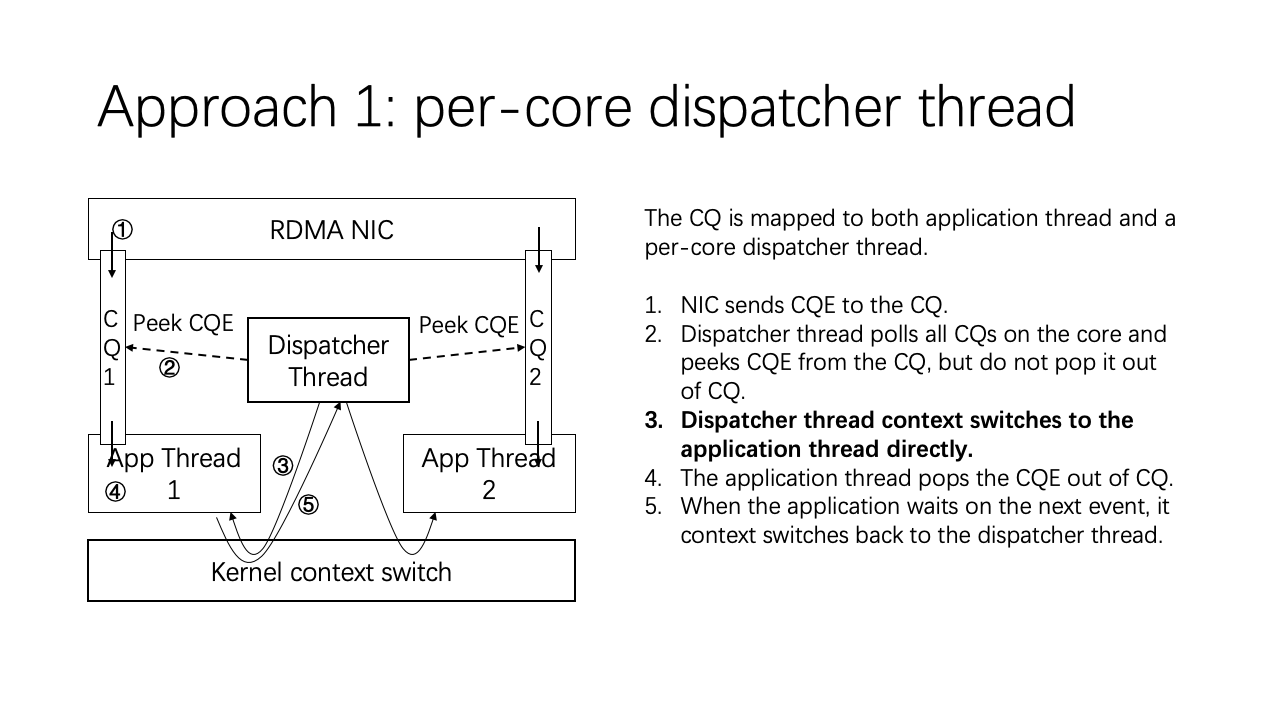
To this end, we designed a dispatcher thread that is mapped to both the application thread and the dispatcher thread. This thread functions as a polling thread. Consider that each CPU core has one dispatcher thread, which manages all the CQs on that core. For instance, whenever a CQ is generated by the NIC, the dispatcher thread first polls all the CQs and identifies the CQE. It identifies but doesn’t extract it. The dispatcher thread then recognizes that this CQ requires action, performing a direct kernel context switch to the application thread. Once the application thread addresses the CQ, it switches back to the dispatcher thread. For other threads, the process is similar.

A significant challenge is implementing this direct context switch because Linux does not natively support context switching to a specific thread. We introduced a new system call named “switch_to“ with a single parameter – the PID (Process Identifier).
The “switch_to“ call checks permissions and places the specified PID at the forefront of the runqueue, which manages the scheduling for the current priority. The performance of this system call outshines other IPC semantics.
For security, we aimed to prevent potential misuse of the “switch_to“ call to stifle other threads. We permit only non-dispatcher threads to switch to dispatcher threads and vice versa. A flag bit in the process control block within the kernel was introduced to enforce this rule.
However, there are limitations. Direct context switches can cause the application thread to have a higher priority than other threads with equivalent priority. Hence, there are certain constraints regarding priority inversion.

Our second key observation aims to expedite interrupt delivery. One reason our first approach isn’t optimal is that it necessitates a constantly polling CPU core – the dispatcher thread – meaning all CPUs operate at 100% utilization. In our second approach, we aim to cut down on CPU utilization and directly address swift interrupt delivery.
We observed that delivering interrupts to a thread operating on a different CPU core is significantly slower than delivering an interrupt on the same core. Consequently, we proposed an approach focusing on interrupt core affinity. We also sought to shorten the kernel path for greater efficiency.
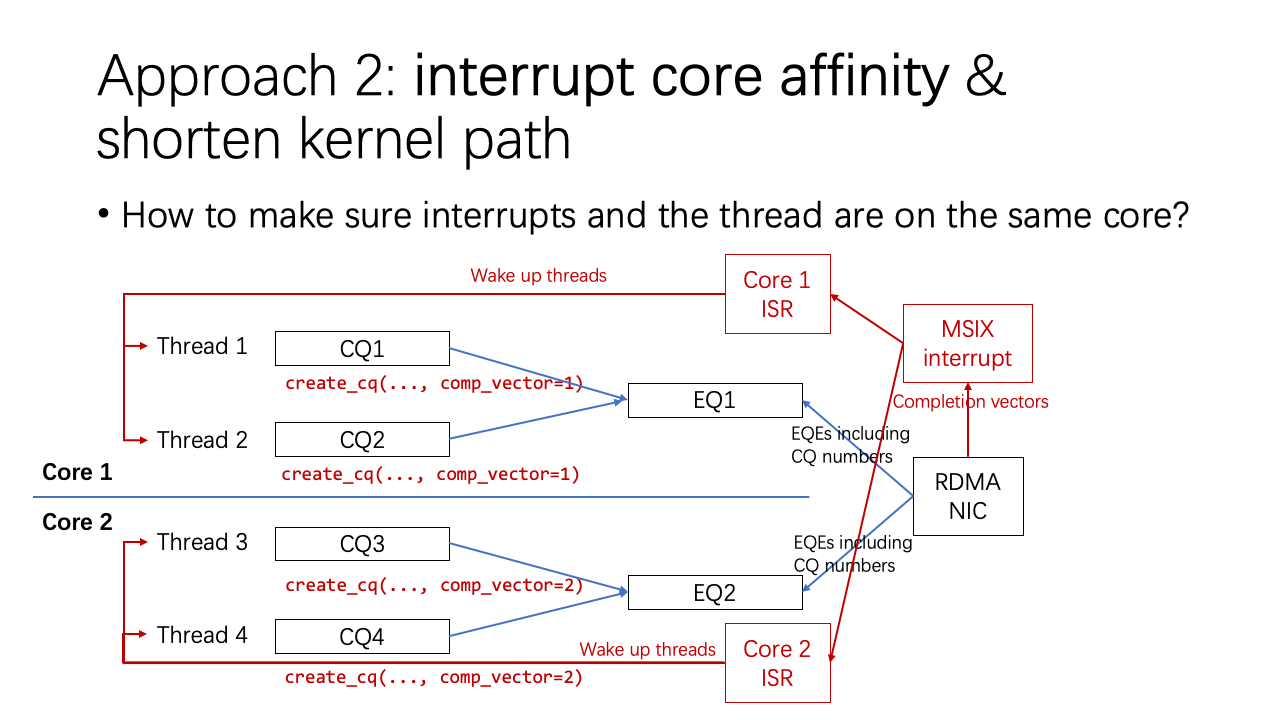
To improve interrupt core affinity, we focused on ensuring that interrupts and threads operated on the same core. This involved the “completion vector” when creating a completion queue in RDMA. This completion vector correlates with an event queue inside the NIC, which is where the NIC delivers its interrupts. The NIC sends interrupts where the event queue lists CQ numbers. If we ensure that the thread and core, as well as the CQ creation thread and user thread, are on the same core, we guarantee optimal interrupt core affinity.

However, there are challenges. For instance, if the CQ’s creator and user operate on different threads, or if a thread migrates to another core during operation, we must dynamically update the affinity between the completion queues and event queues. We utilize a feature in the kernel that allows remapping of the completion queue to event queues. This remapping occurs when the interrupt handler detects that the thread is no longer on the same core as the interrupt handler.
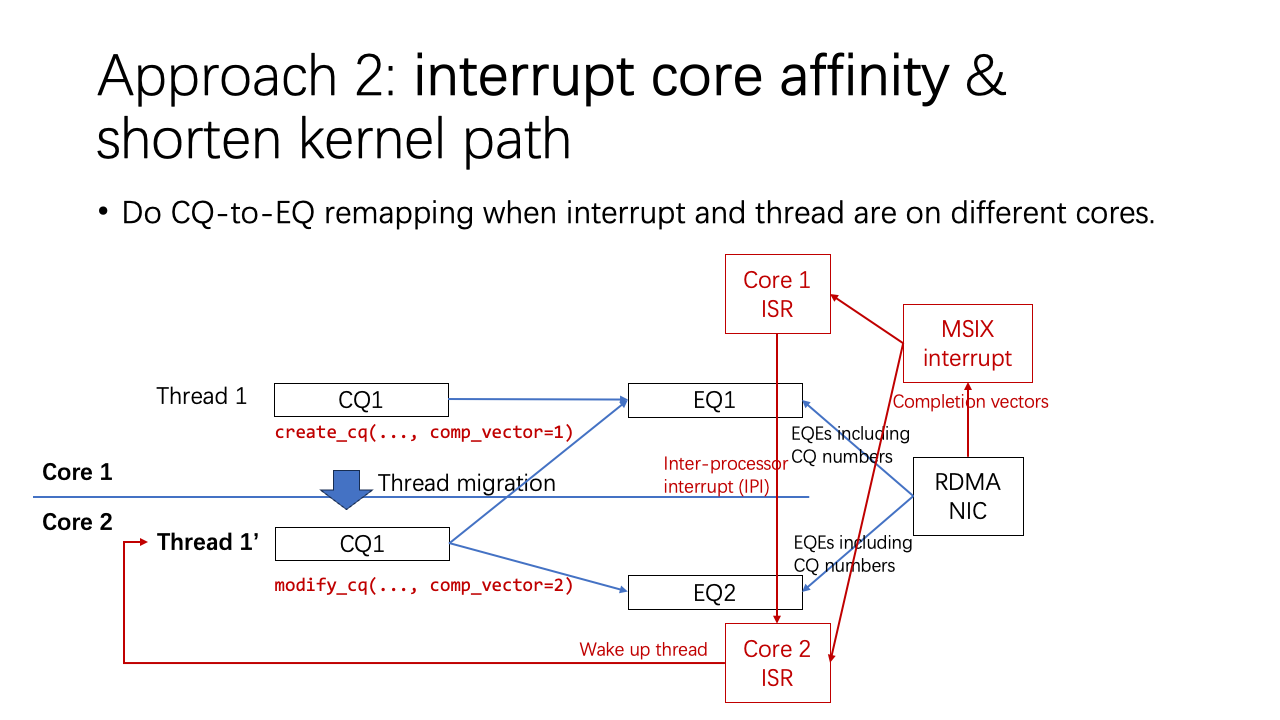
For instance, if Thread 1 migrates from Core 1 to Core 2, the interrupt service routine (ISR) might need an inter-processor interrupt, which is relatively slow due to inter-core communication. To optimize future interrupts, we added a “modify CQ“ call to the OFED (OpenFabrics Enterprise Distribution). This call changes the completion vector, directing the NIC to deliver to a different event queue. This ensures that subsequent operations and interrupts maintain strong core affinity.
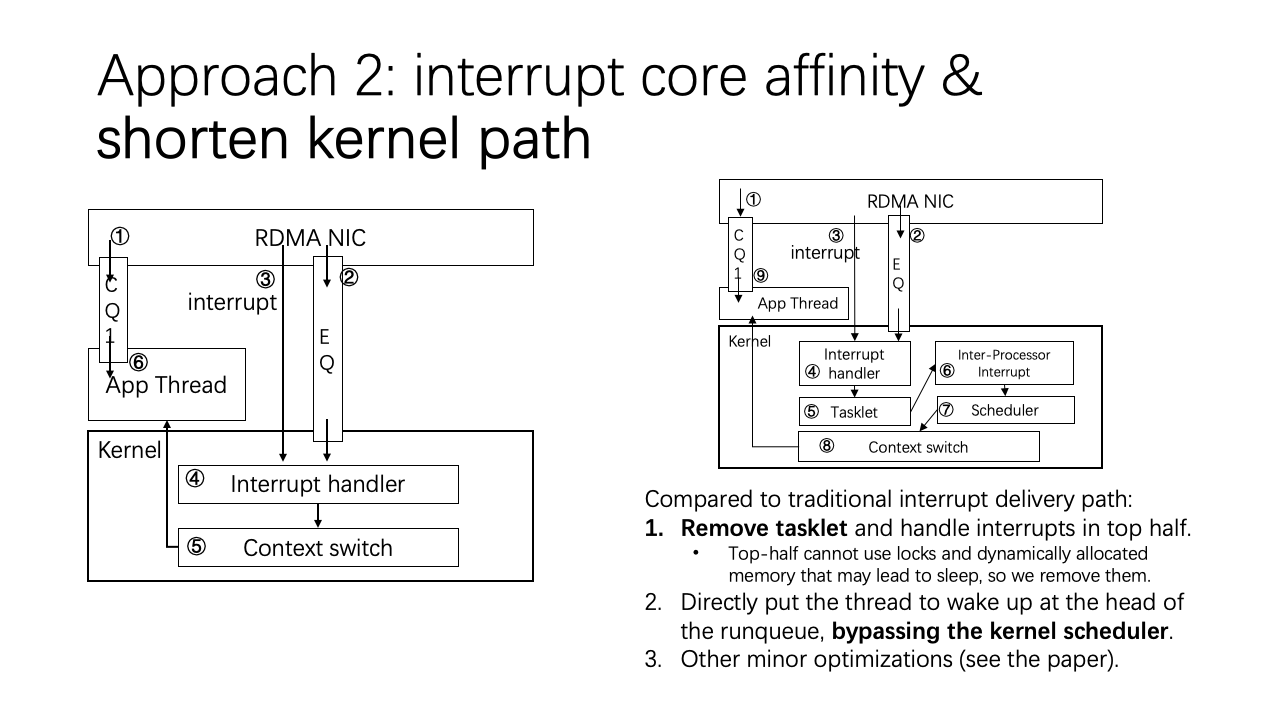
Lastly, in our second approach, we also aimed to streamline the kernel path. On examination, the original kernel path was intricate and involved multiple steps. We modified this by removing the tasklet and bypassing the core scheduler, along with introducing various other optimizations. This refactoring provides a more efficient and swift path for RDMA operations in data center networks.
Firstly, we handle the CQ, then the EQ, and finally the interrupt. We didn’t make any modifications to these three steps because they originate from the NIC hardware, and we can’t modify that. What we did modify is in the kernel part. In the interrupt handler, we omit the task click and directly handle the interrupt in the top half. Due to some programming limitations in the top half, we had to eliminate some of the locks and dynamically allocated memory. We then perform a direct switch to the thread, bypassing the core scheduler. This makes kernel scheduling very fast.
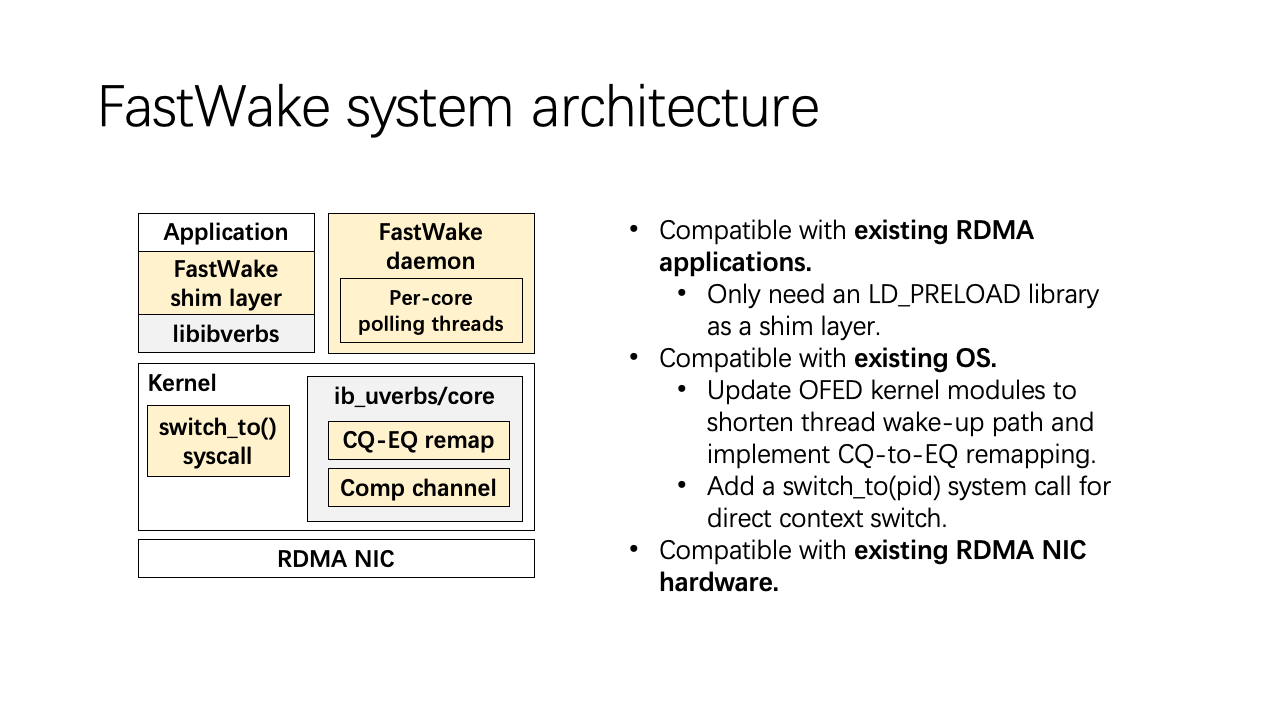
The FastWake system architecture is compatible with existing RDMA applications, operating systems, and hardware. We added the ODPI preload library as a shim layer in the user space. We updated the OFED kernel modules to shorten the kernel path and added a “switch_to“ system call to implement the direct context switch.
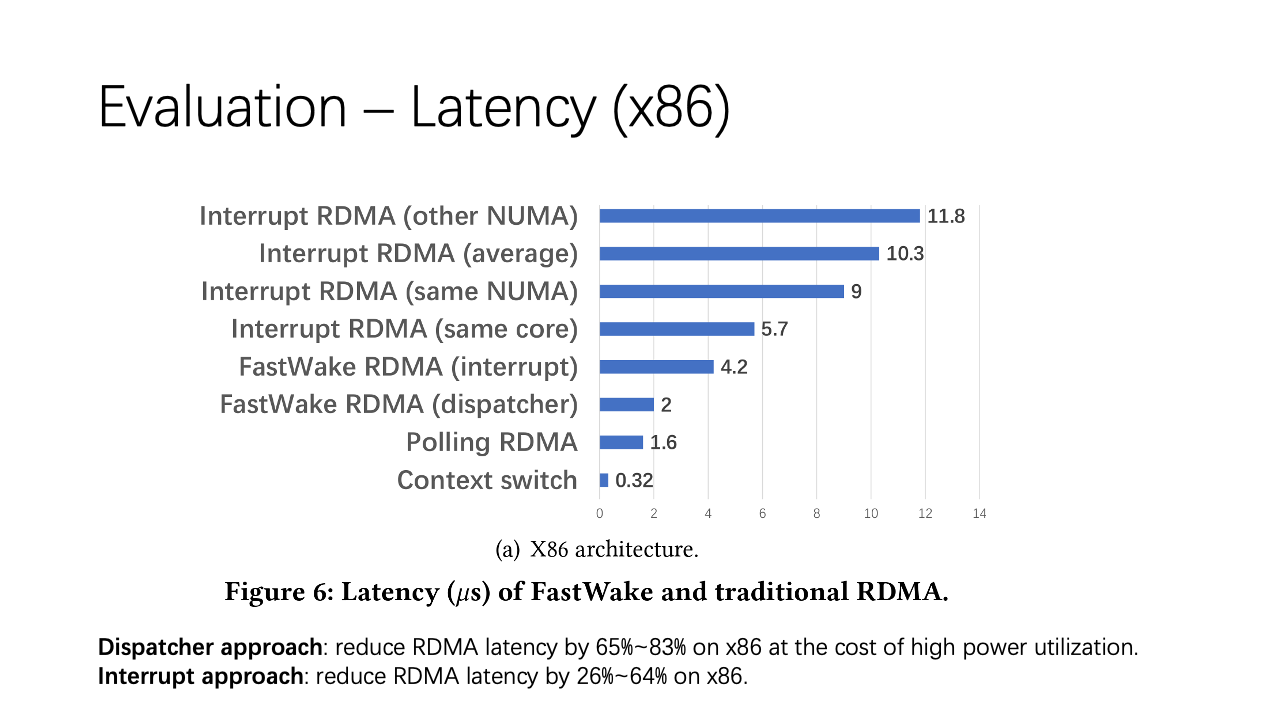
For evaluation, we tested FastWake on both x86 and ARM platforms. With the dispatcher approach, FastWake RDMA adds only about 0.4 microseconds to the ping time. This slight delay is due to the context switch from the dispatcher thread to the user thread. For the interrupt mode, it is slightly slower than the dispatcher mode but still faster than traditional interrupt mode RDMA. This improvement is because we’ve shortened the kernel path and ensured good interrupt core affinity, ensuring interrupts typically run on the same core.
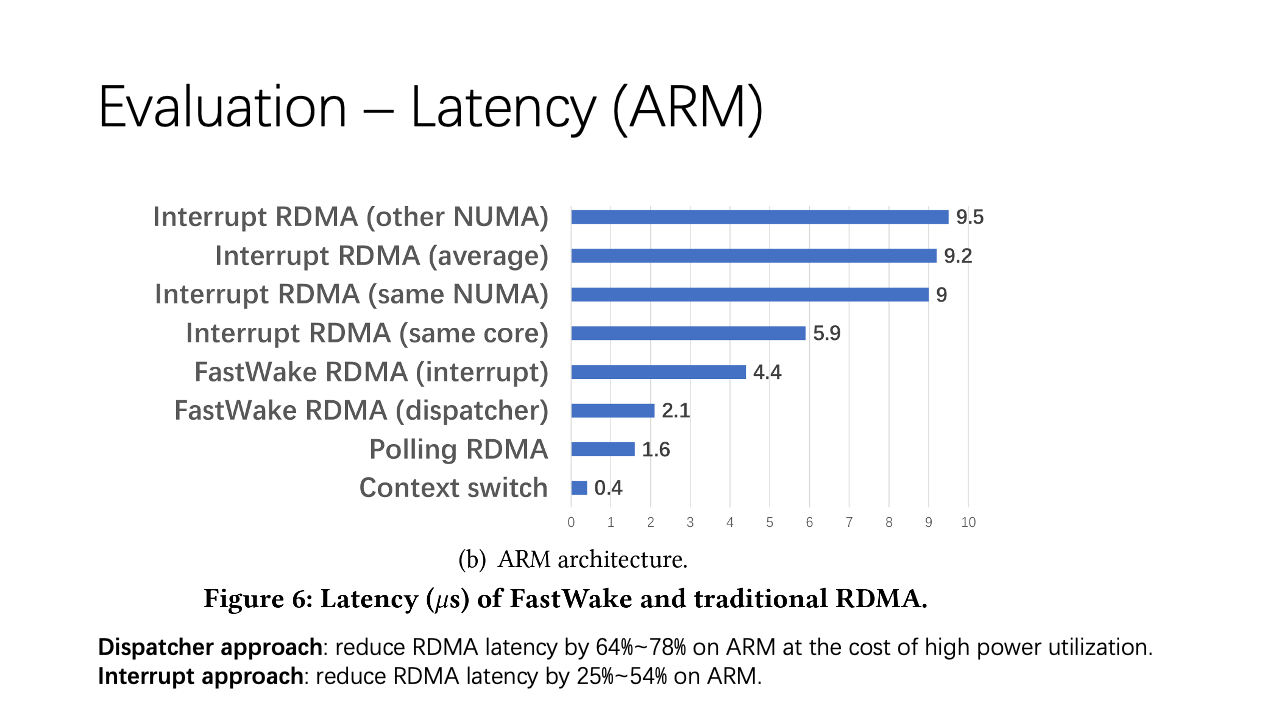
For ARM, results were similar. The FastWake dispatcher is close to the polling case, while the interrupt mode is slower due to the NIC interrupt delivery. However, it’s still much faster than average interrupt RDMA.
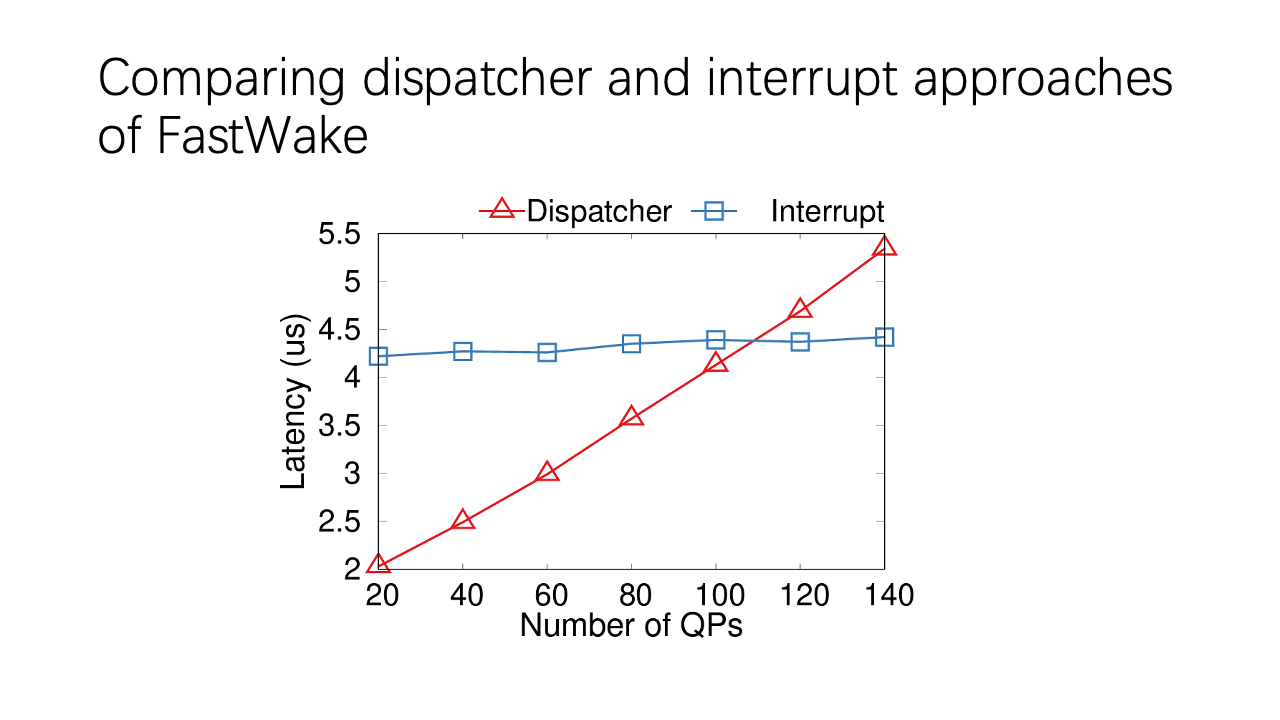
Comparing the dispatcher and interrupt approaches of FastWake: the dispatcher thread polls all the CQs, while interrupt mode doesn’t. So, as the number of QPs increases, latency in the dispatcher thread will increase linearly.

As a side product, FastWake also reduces interprocess communication latency because of the fast context switch. In some cases, it could replace semaphores and mutexes, indicating potential areas for future work.

In conclusion, as data center networking and storage hardware are moving into microsecond-scale latency, we face the “killer microsecond” problem. FastWake offers two solutions with community NIC and OS applications based on two observations: context switches are faster than process scheduling, and interrupt core affinity is crucial for latency of interrupt delivery. This work is preliminary, and we look forward to more research on the “killer microsecond” problem. We aim to push performance to the limits of underlying hardware.

Welcome to join or collaborate with our computer networking protocol lab. It is a fantastic lab in Huawei.
Now, we have time for questions.
Question 1: “Regarding the ‘switch_to‘ interface you introduced: it seems to potentially interfere with existing process scheduling algorithms. Have you considered other methods, like merely boosting the priority of the target thread?”
Answer 1: “Excellent question. We place the target thread at the top of the current priority queue, essentially elevating its priority between its existing level and the next higher one. If another thread has a higher priority, it would still take precedence. Boosting the priority would achieve a similar outcome.”
Question 2: “FastWake comprises two methods. Is it possible that not all applications will exclusively benefit from one approach over the other? Can there be a dynamic switch between the two based on the workload’s demands on the RDMA subsystem?”
Answer 2: “A pertinent observation. The two strategies serve different scenarios. The first, utilizing a polling dispatcher thread, is geared towards situations demanding 100% CPU utilization. The second, focusing on efficient kernel paths and interrupt core affinity, caters to low CPU utilization environments. While it’s conceivable to have a system profiler and optimization function in future iterations to address the exact concern you raised, it’s something we’ve yet to fully explore.”