SOSP'17 Talk Transcription: KV-Direct
KV-Direct: High-Performance In-Memory Key-Value Store with Programmable NIC
Bojie Li, Zhenyuan Ruan, Wencong Xiao, Yuanwei Lu, Yongqiang Xiong, Andrew Putnam, Enhong Chen and Lintao Zhang.
Proceedings of the 26th Symposium on Operating Systems Principles (SOSP ‘17). [PDF] [Slides]
Transcription with Whisper.

Thanks Professor Aditya Akella for the introduction.
Hello everyone, I’m Bojie Li, a fourth year PhD student in a joint PhD program of USTC and Microsoft Research.
In this session we have seen two wonderful works, Eris and NetCache to use in-network processing with dataplane programmable switches to accelerate systems.
Now I will show programmable NICs can also be very useful in accelerating datacenter workloads.
Our KV-Direct work is done during internship in Microsoft Research Asia with my colleagues. Zhenyuan Ruan and me are co-first authors who design and implement this system together.

As everyone knows, traditional key-value stores like memcached or redis are used for caching in web services.
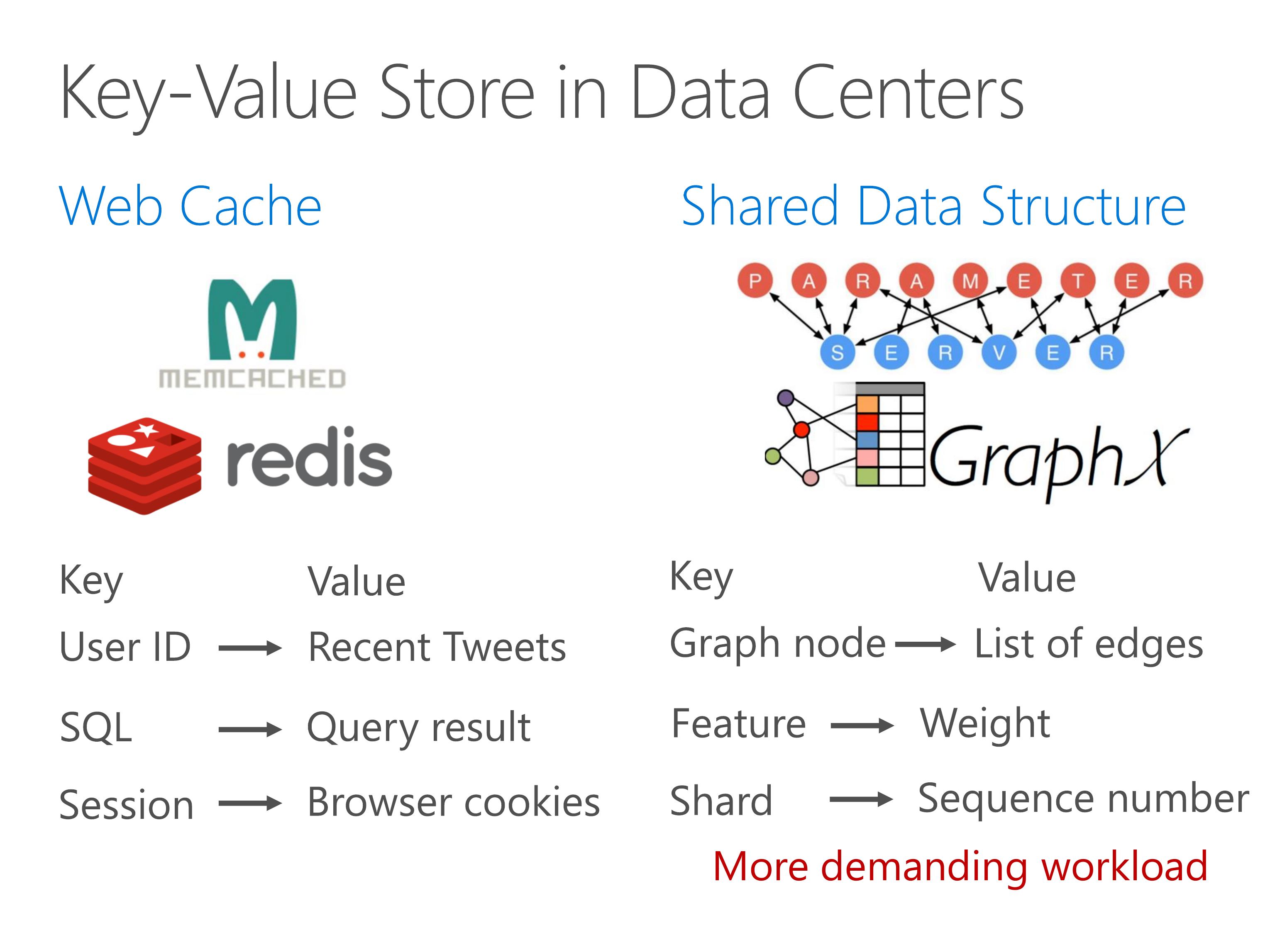
In recent years, key-value store goes beyond object caching and becomes an infrastructure service to store shared data structure in a distributed system.
Examples include parameter servers in machine learning, graph computing engine and sequencers for distributed transactions, as the Eris paper in this session just said.
Shared data structure stores demands more performance compared to web cache.
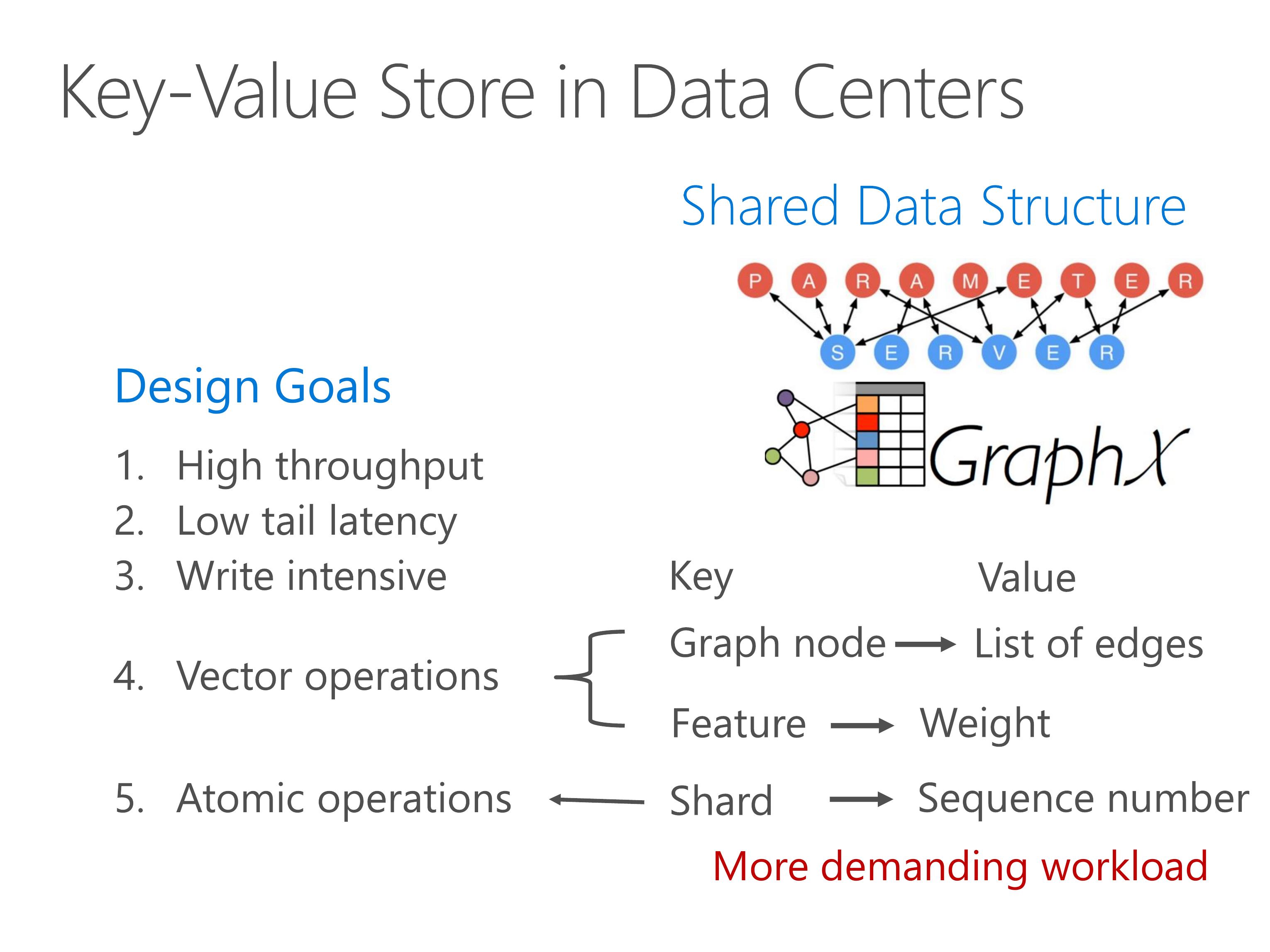
These shared data structure stores have enormous throughput requirement, for example a graph computation application may need billions of key-value operations per iteration.
Second, it requires low tail latency because the latency of an application is typically determined by the slowest one.
Third, the workload is no longer read intensive, so both reads and writes need to be efficient.
Finally, we should have built in support for vector operations and atomic operations.
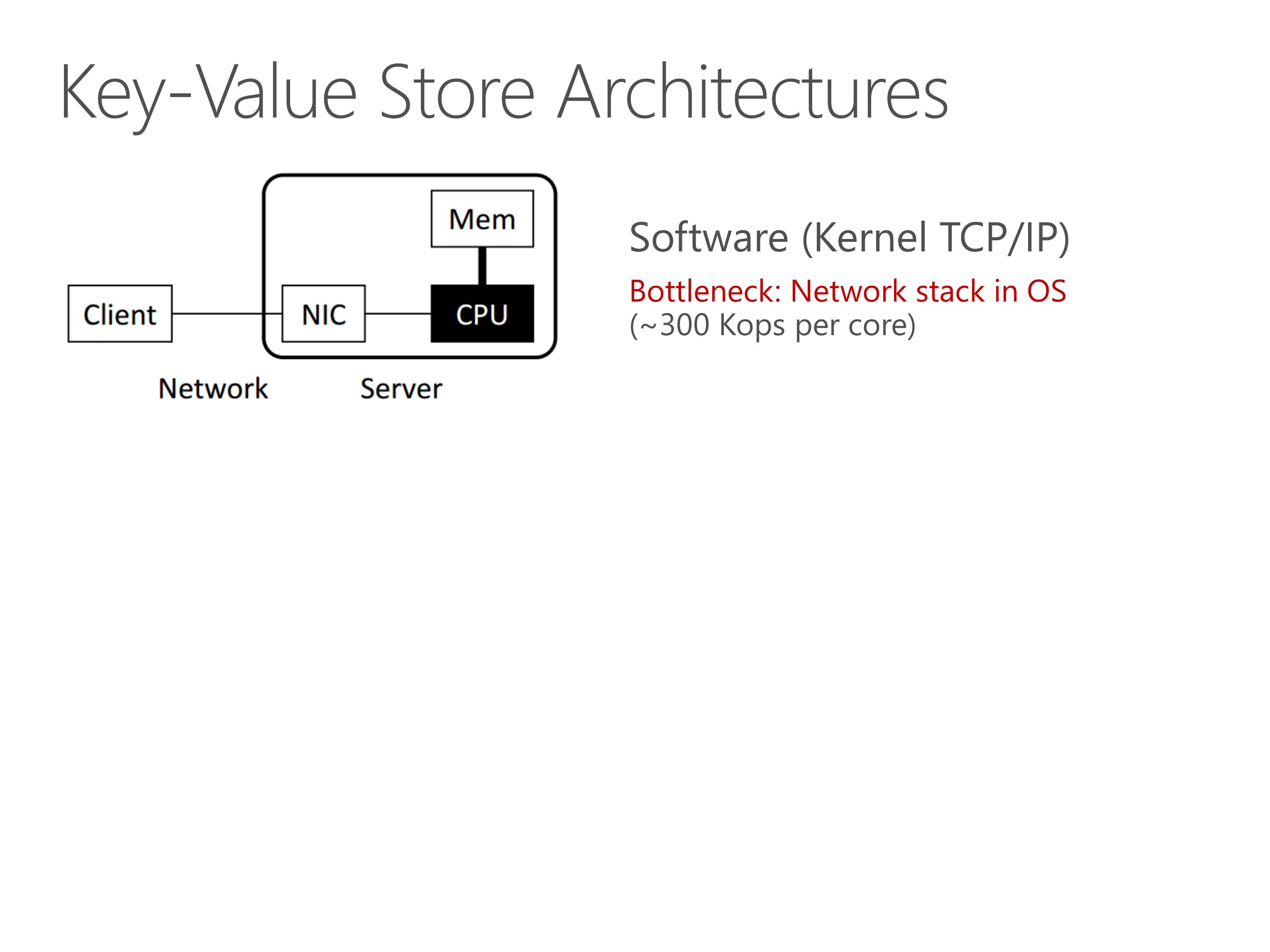
Key-value store is a holistic exercise of systems, including networking, computation and memory accesses.
For traditional key-value stores such as memcached and redis, the bottleneck is network stack in operating system. We all know that TCP/IP stack are slow.
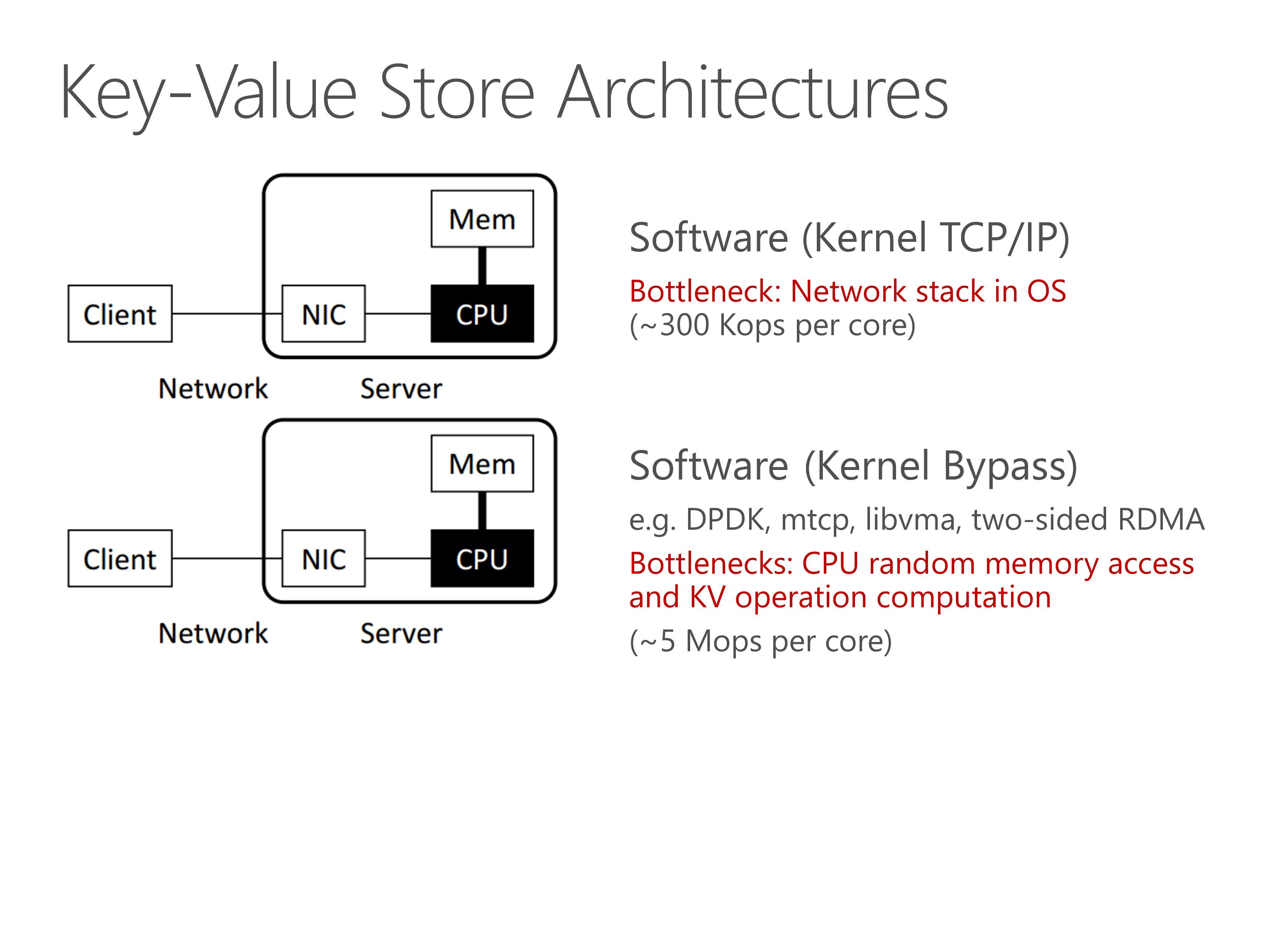
Next, researchers use kernel-bypass networking to mitigate the network stack overhead.
One way is to build a lightweight network stack in user-mode.
Another way is to leverage two-sided RDMA to offload the networking stack into NIC hardware.
However, the throughput bottleneck is now CPU random access and key-value operation computation.
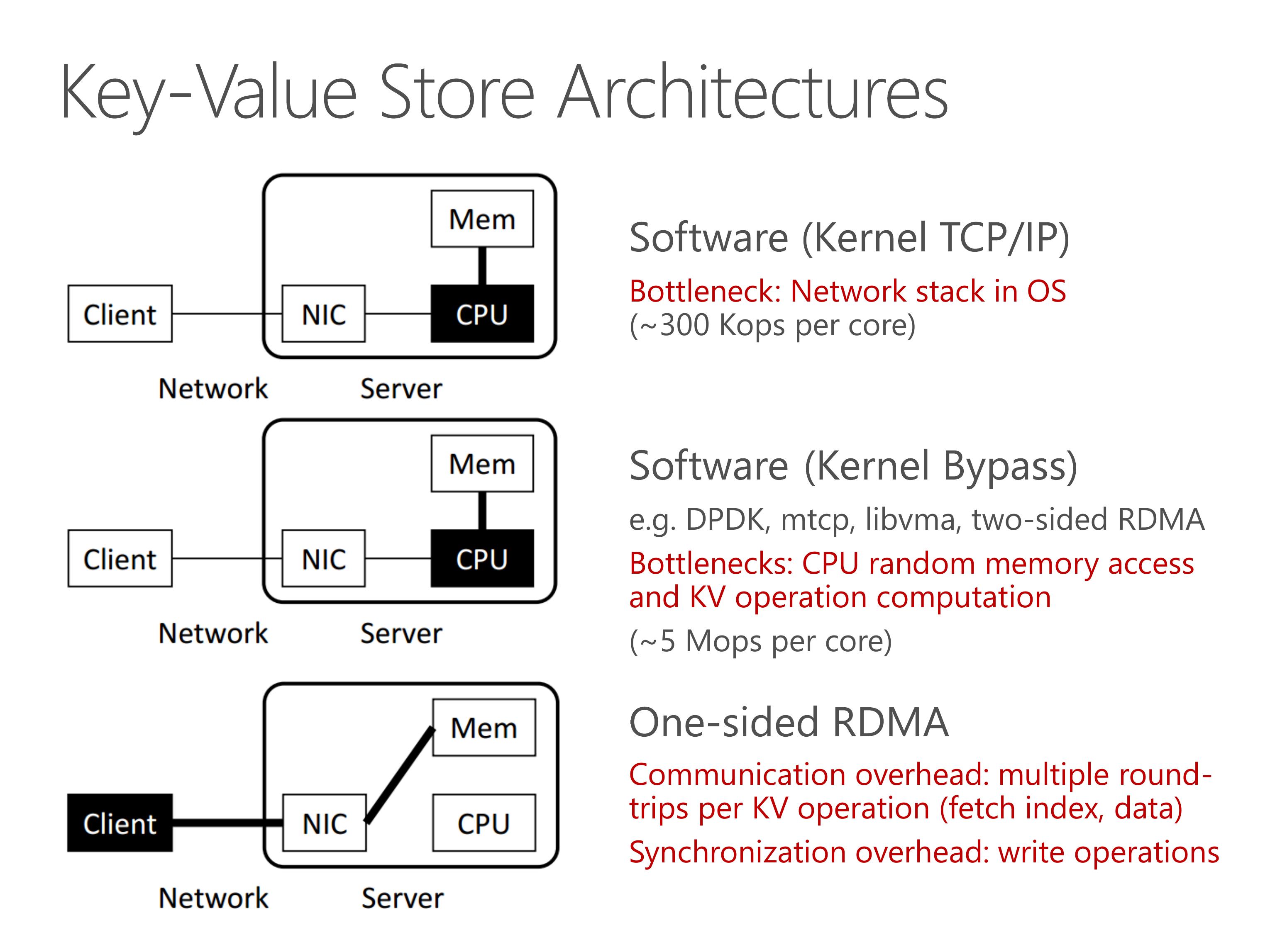
Another key-value store architecture is to bypass the server CPU entirely using one-sided RDMA.
The KV processing is offloaded to clients, and they access the key-value store via remote memory access.
However, in this design, there is significant communication overhead due to multiple round-trips per KV operation.
Furthermore, when clients need to write on a same key-value pair, they need synchronization to ensure consistency.
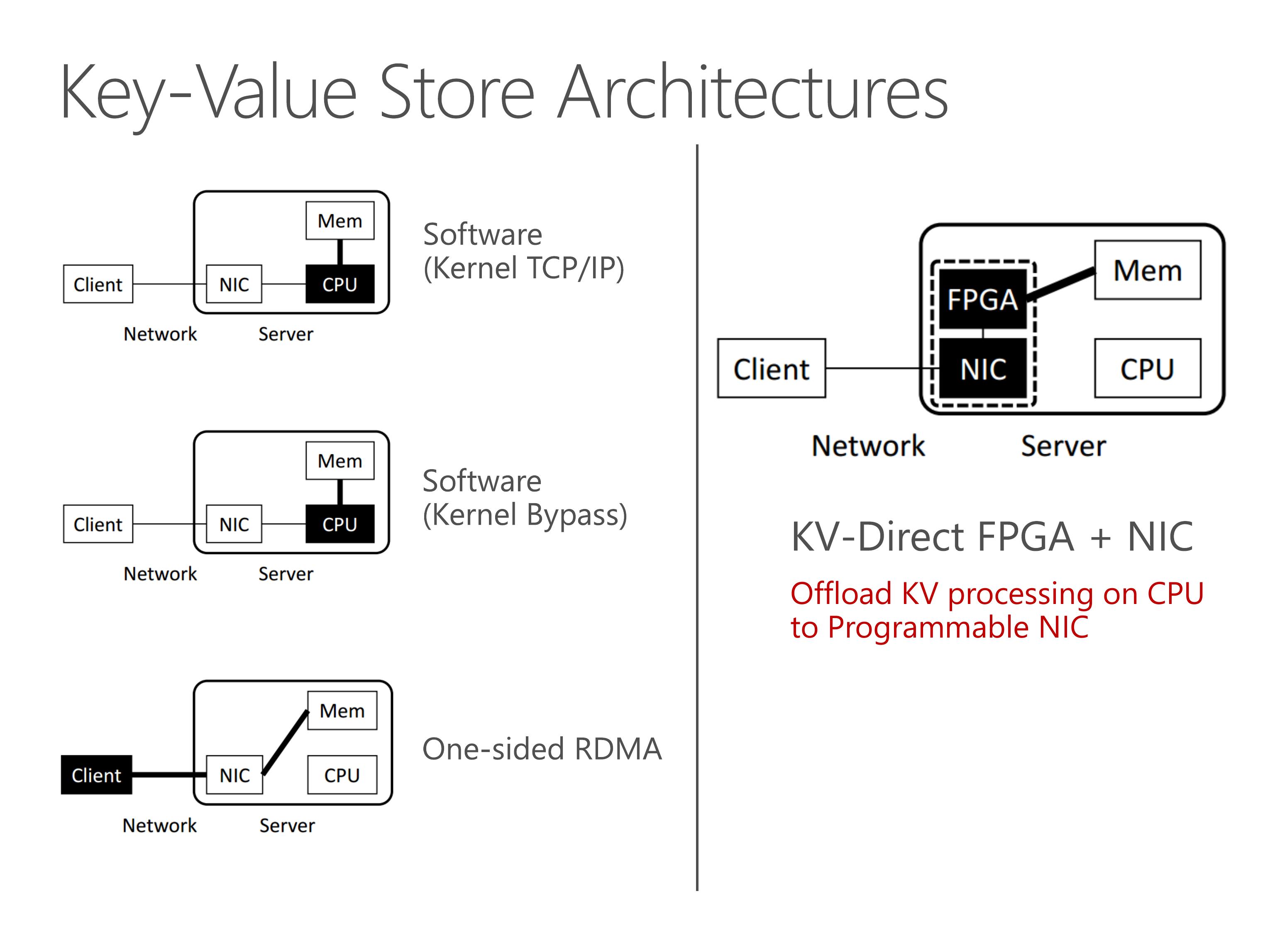
We propose KV-Direct to offload KV processing on CPU to programmable NIC.
The name of KV-Direct means that the NIC directly fetches data and applies updates in the host memory to serve KV requests, completely bypassing server CPU.
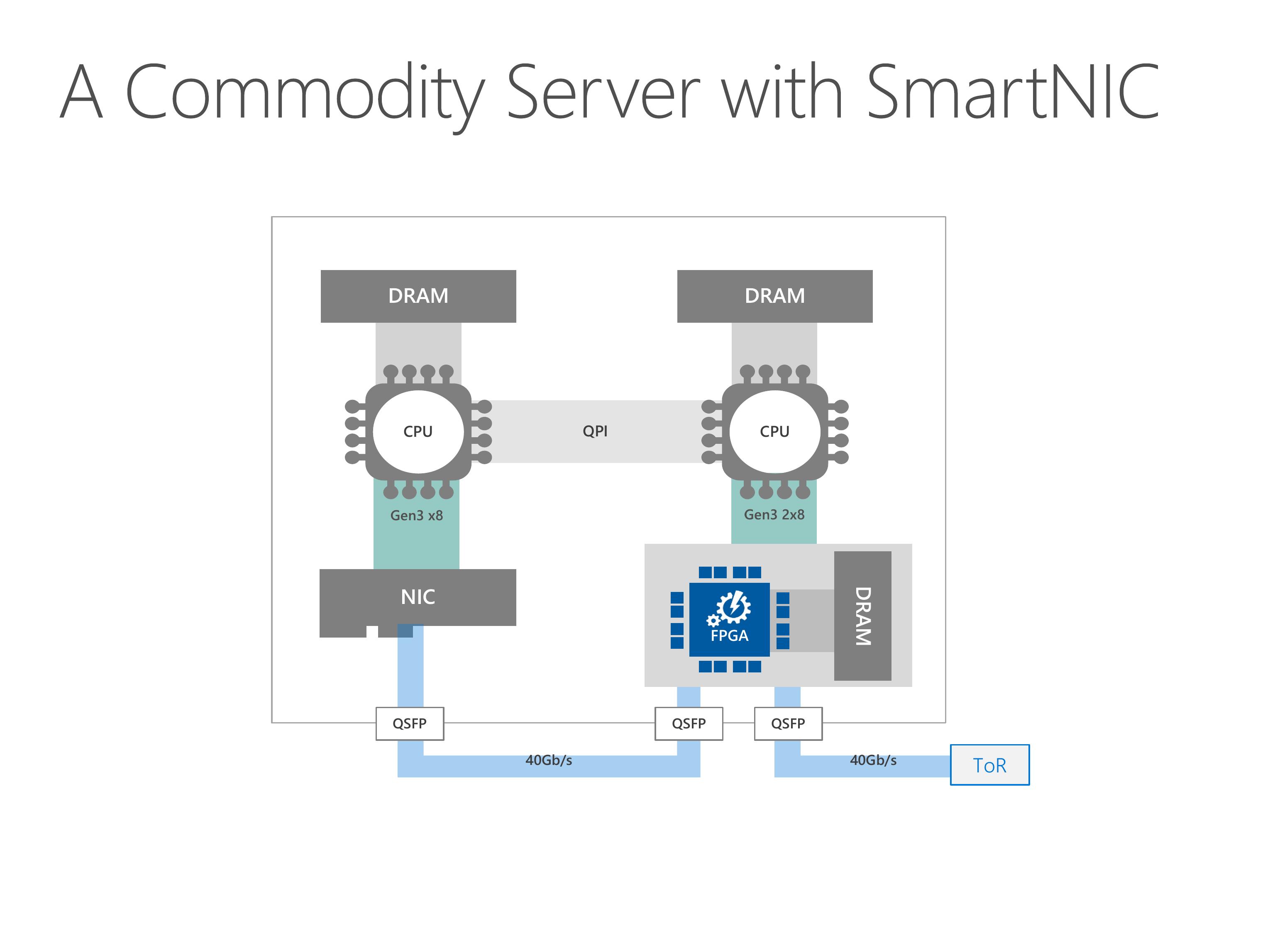
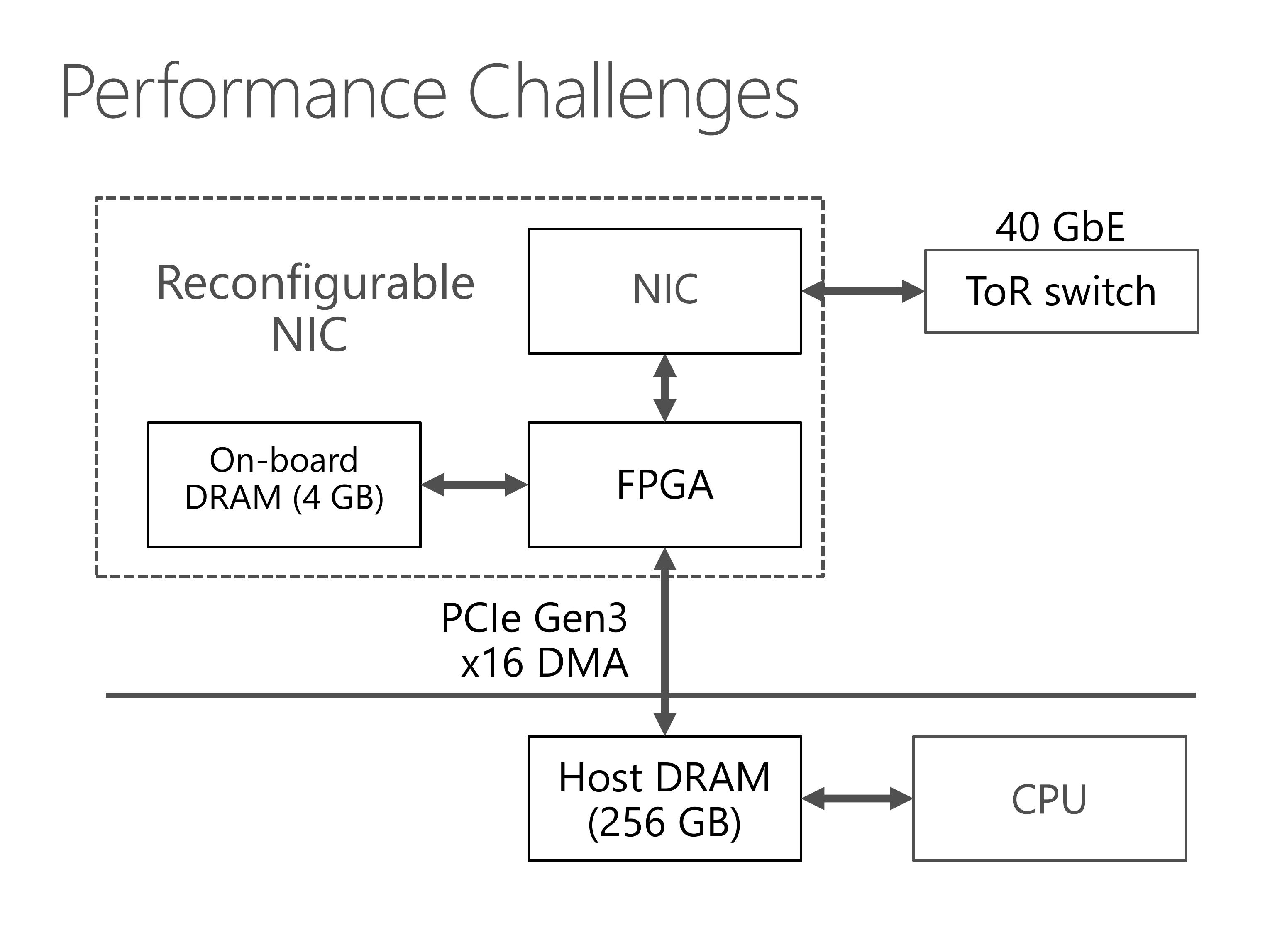
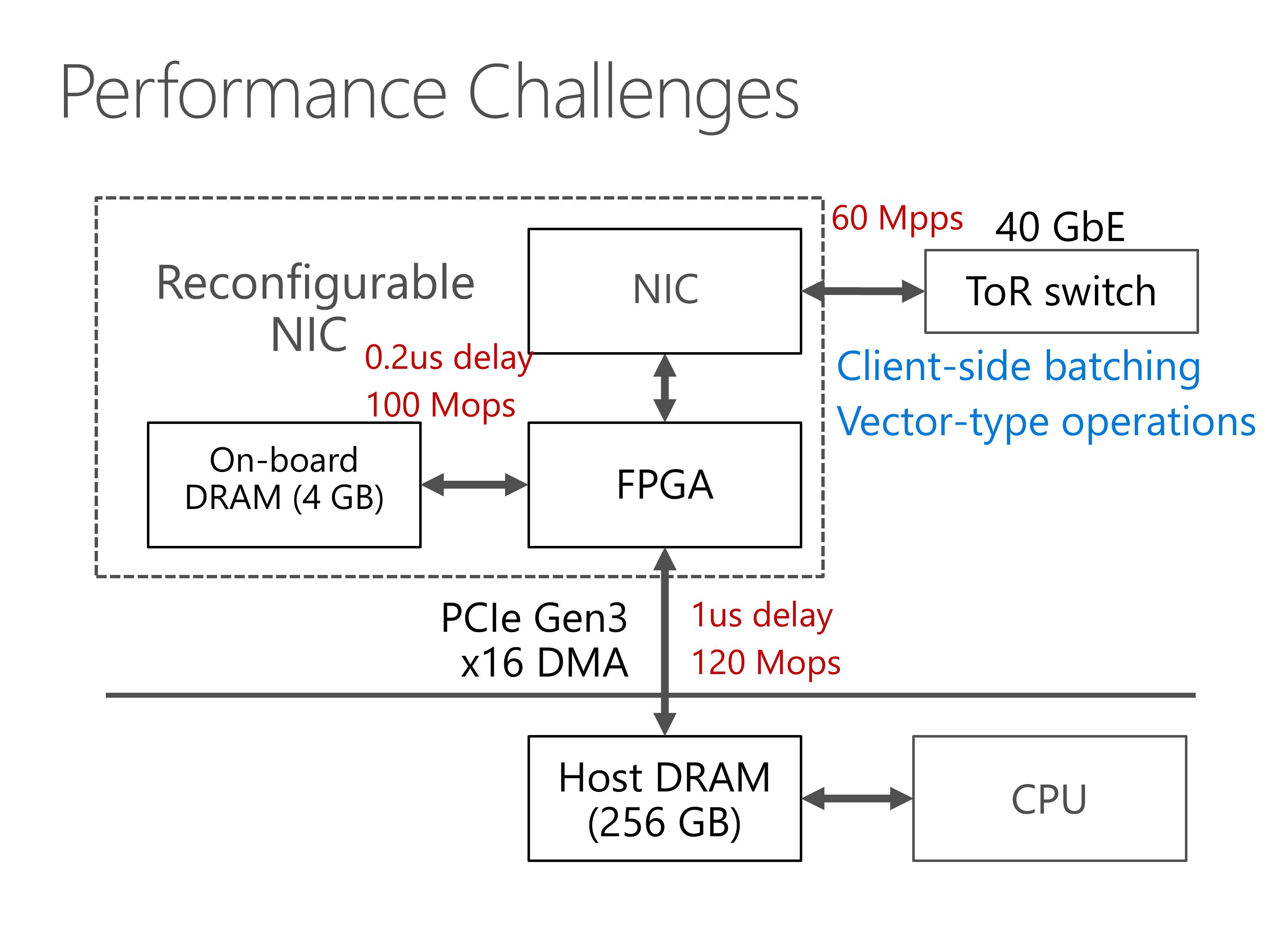
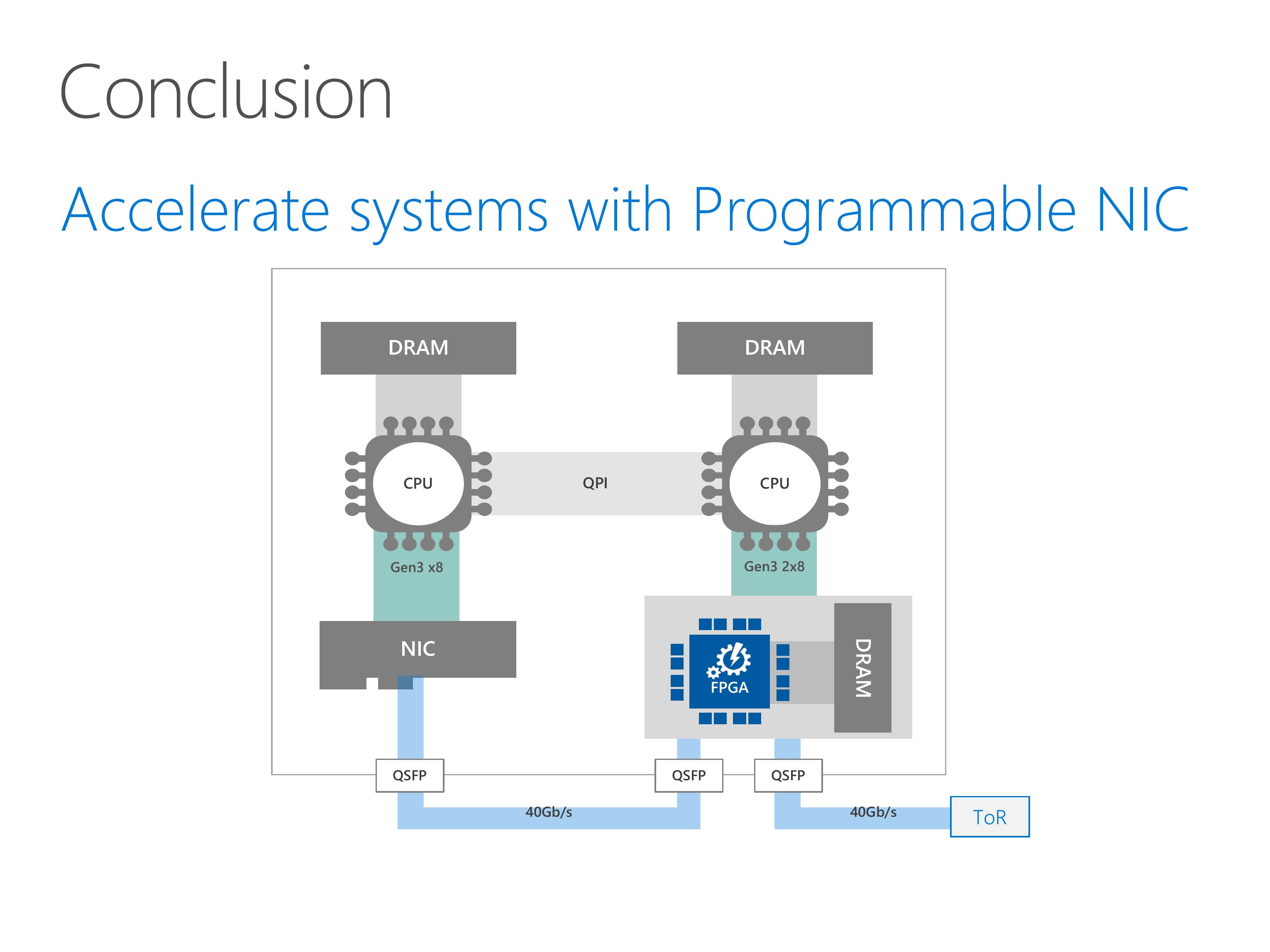
This slides show the architecture of our server with SmartNIC.
Our programmable NIC is composed of two parts, an FPGA and a standard network interface card.
The FPGA has some on-board DRAM, and can access the host DRAM via PCIe link.
For the network part, the FPGA stays between the NIC and the top of rack switch.
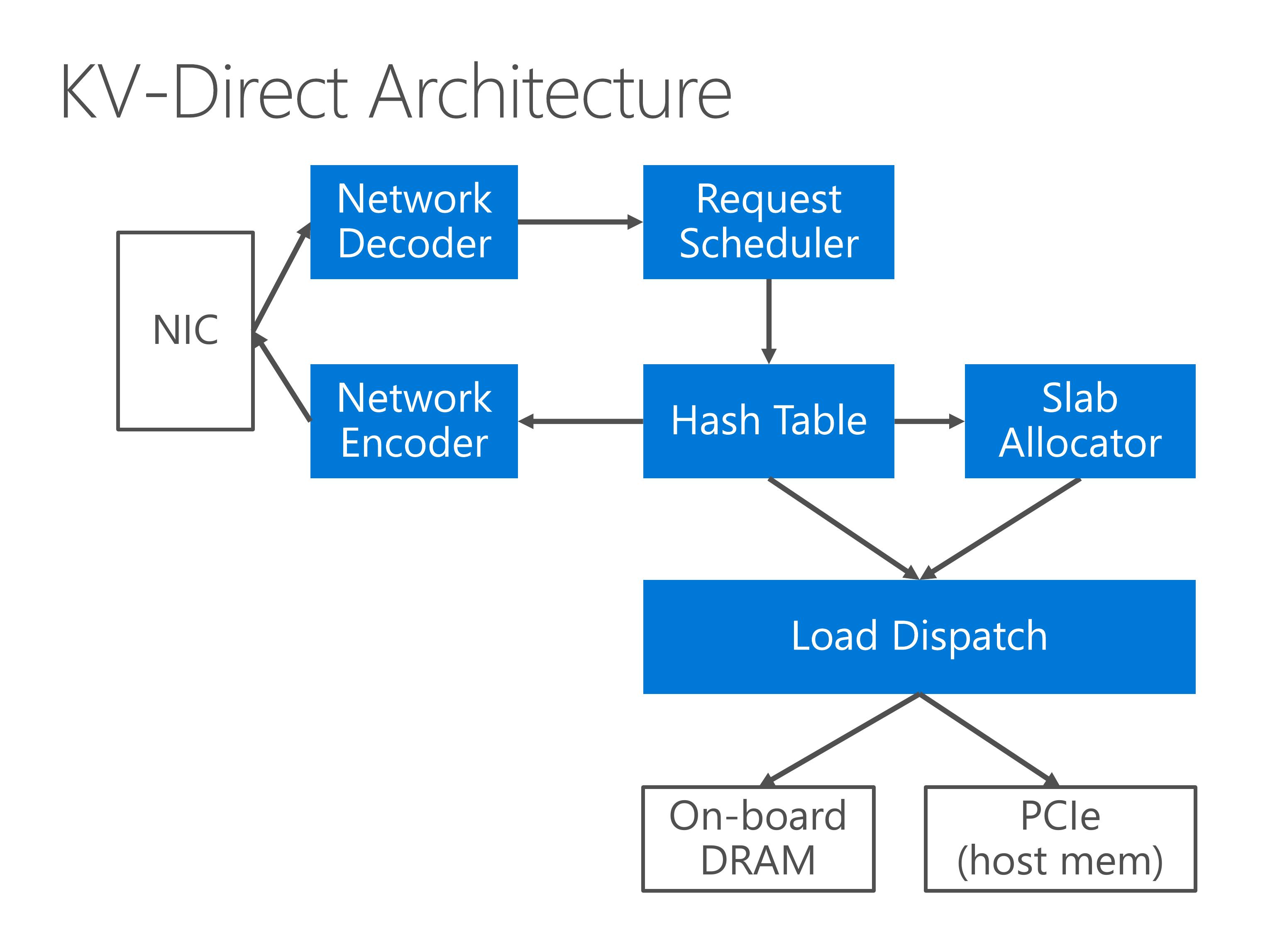
Now we look at the architecture of KV-Direct.
- Key-value operations are received from the NIC and decoded in the network decoder.
- Then, the request scheduler issues independent key-value operations to the hash table,
- Small key-value pairs are stored inline in the hash table, while larger key-value pairs are stored in dynamically allocated memory, which requires a slab memory allocator.
- The memory accesses are dispatched to either on-board DRAM, or the PCIe bus to access host memory.
- When the memory lookup result comes back, finally we encode the KV operation results and send to the client.
Here we look at the exact performance numbers of our system and see the performance challenges of our system.
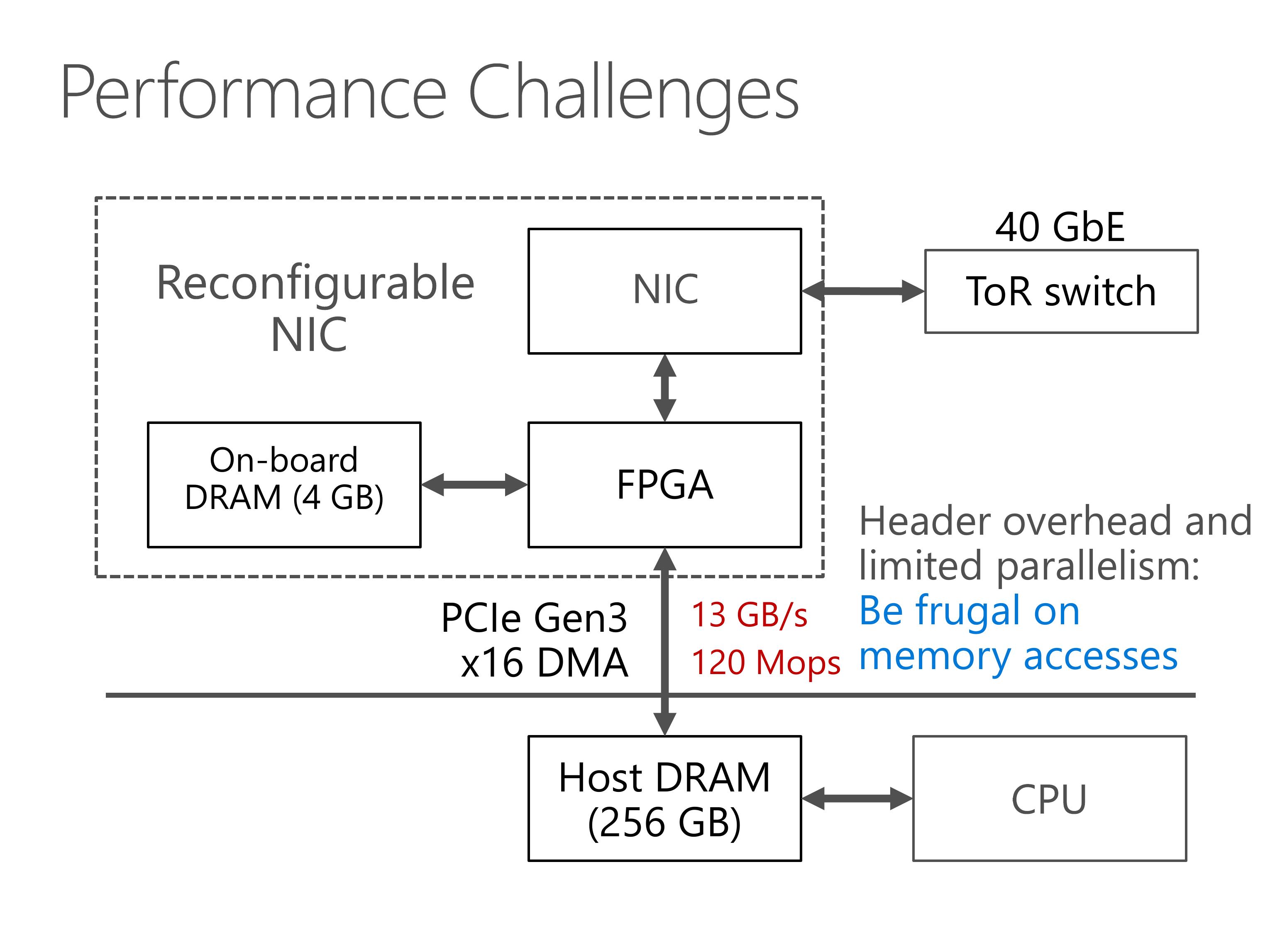
First, our PCIe interface between FPGA and host memory has limited throughput.
There is something worse. PCIe transport layer packets has header overhead, and the PCIe IP core in our FPGA has limited parallelism, which limits our PCIe throughput to 120 million operations per second.
So we need to be frugal on memory accesses.
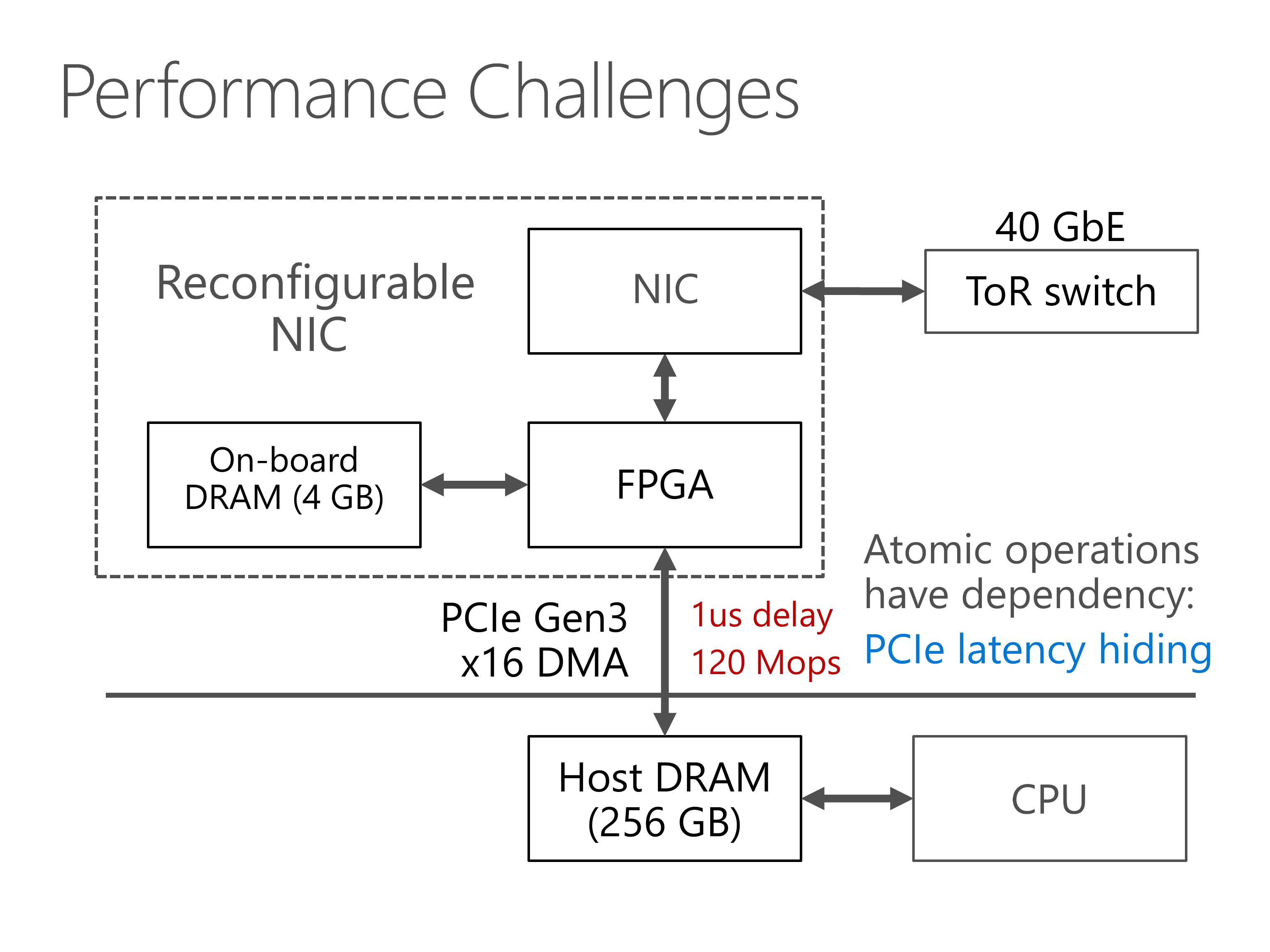
Second, the PCIe bus has delay of nearly 1 microsecond, due to additional delay in the PCIe IP core in our FPGA.
When atomic operations operate on the same key, they depend on the result of each other and needs to executed one by one.
Therefore, we need to hide the PCIe latency, otherwise the throughput will degrade to 1 million operations per second.
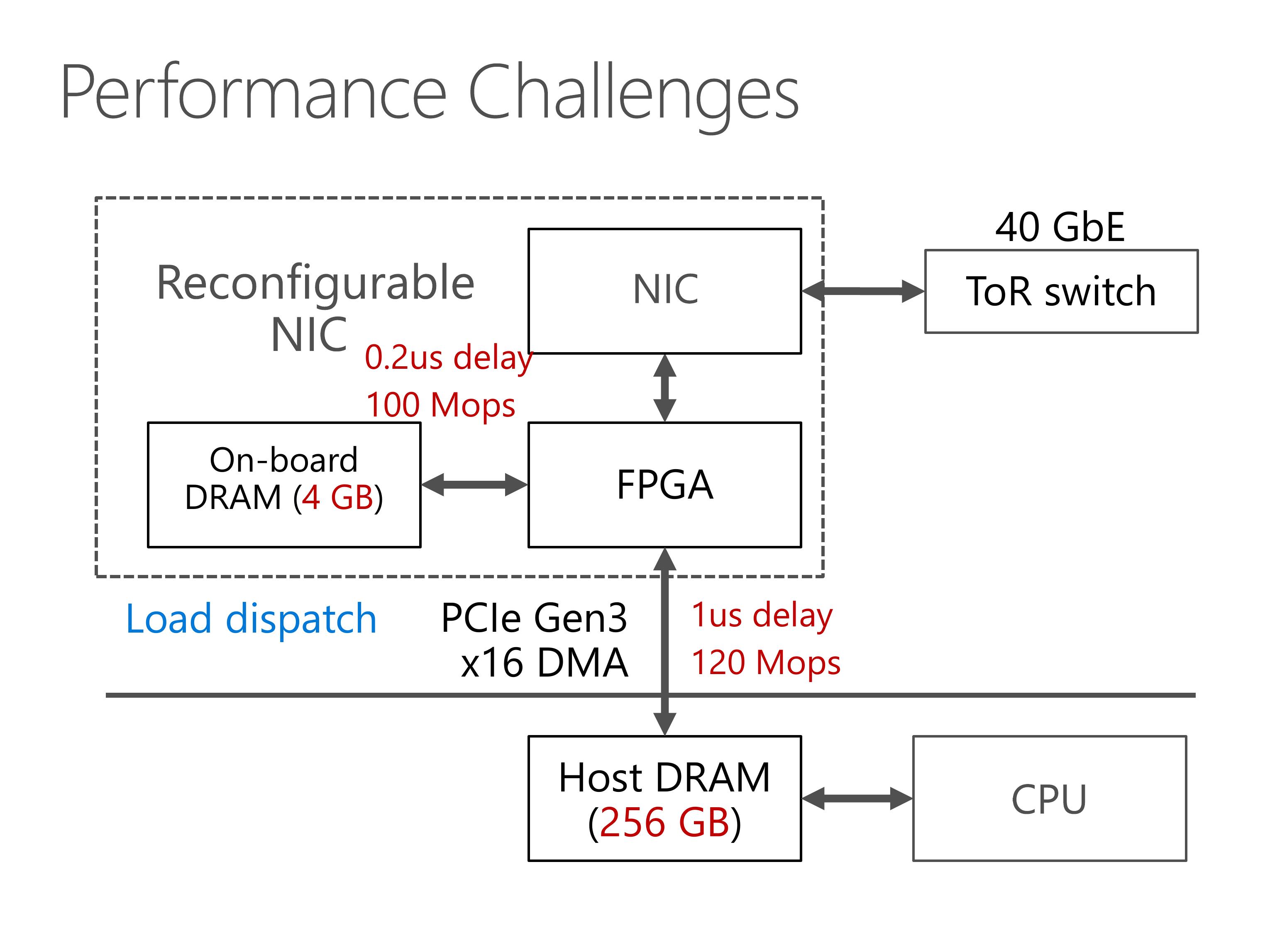
Third, we hope to leverage both the throughput of on-board DRAM and host DRAM, so we need an efficient load dispatch mechanism.
Finally, because network packet headers also have significant overhead, we leverage client-side batching and support vector-type operations to reduce network overhead.

I already know that many people may do not have a programmable NIC or FPGA, actually you do not need to be disappointed by this talk.
Actually, our design principles are not specific to the hardware design of our system. Pure CPU based designs can still benefit from the design principles.
Next we go through each of the optimizations.
First, we need to be frugal on the number of memory accesses.

Hash table is a central part to a key-value store.
Our goal is to achieve minimal memory accesses per both GET and PUT operation.
Cuckoo hashing achieves constant number of memory accesses per GET operation, but sacrifice PUT under high load factors.
Log-structured memory, on the other hand, requires only one memory write operation per PUT, but may require more memory read operations per GET.
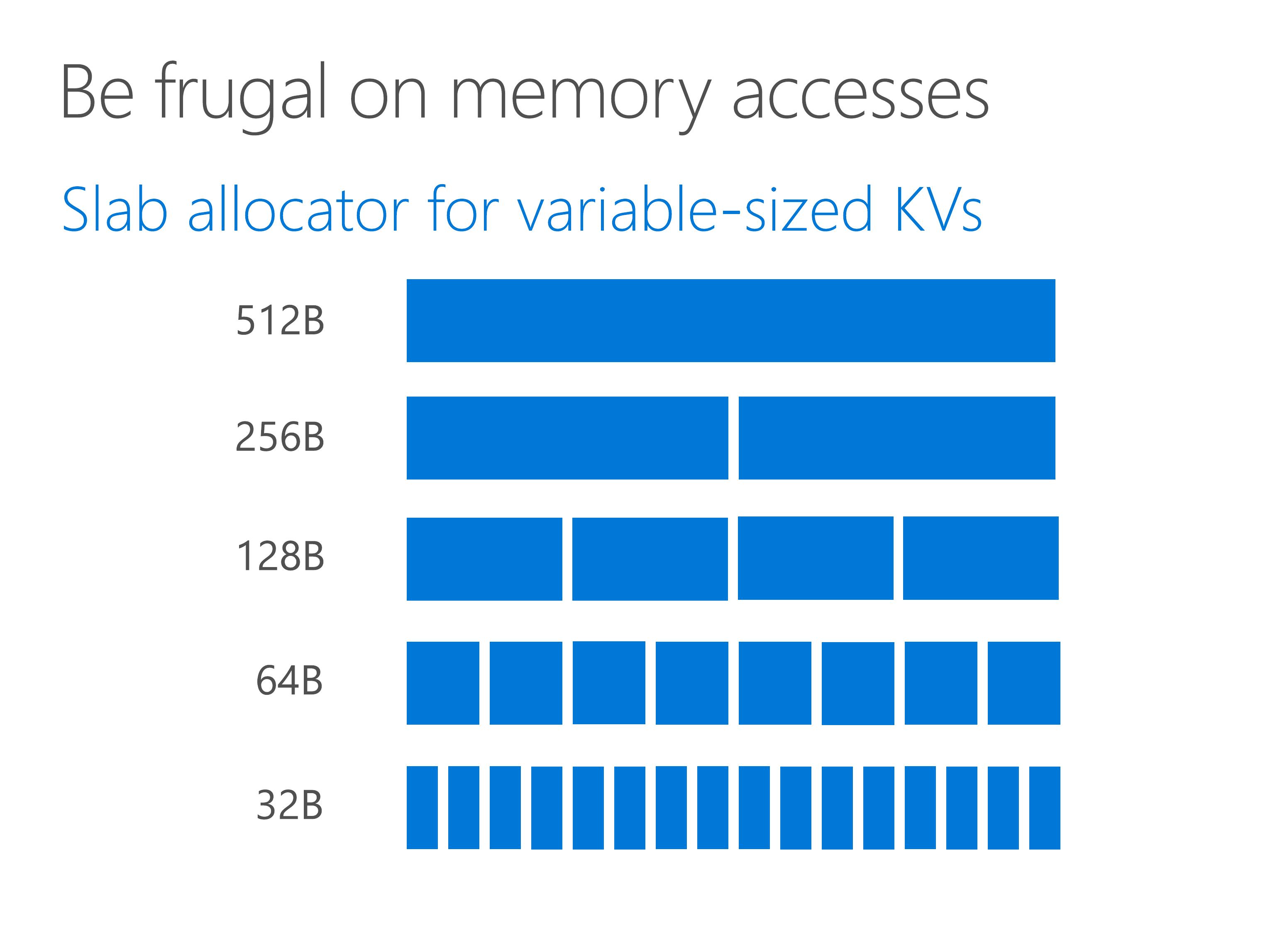
Because KV-Direct is a general key-value store, it needs to store key-values of variable sizes. We need dynamic memory allocation for key-value pairs larger than some inline threshold.
As we can see from the figure, a slab allocator partitions the memory space into several slab entries with predetermined size.

However, the problem comes when a slab is freed.
When a slab is freed, the adjacent slab needs to be checked. If the adjacent slab is also free, we merge the two free slabs into a larger free slab. Otherwise, we mark the newly freed slab in the bitmap. This introduces two random memory accesses, one read and one write.
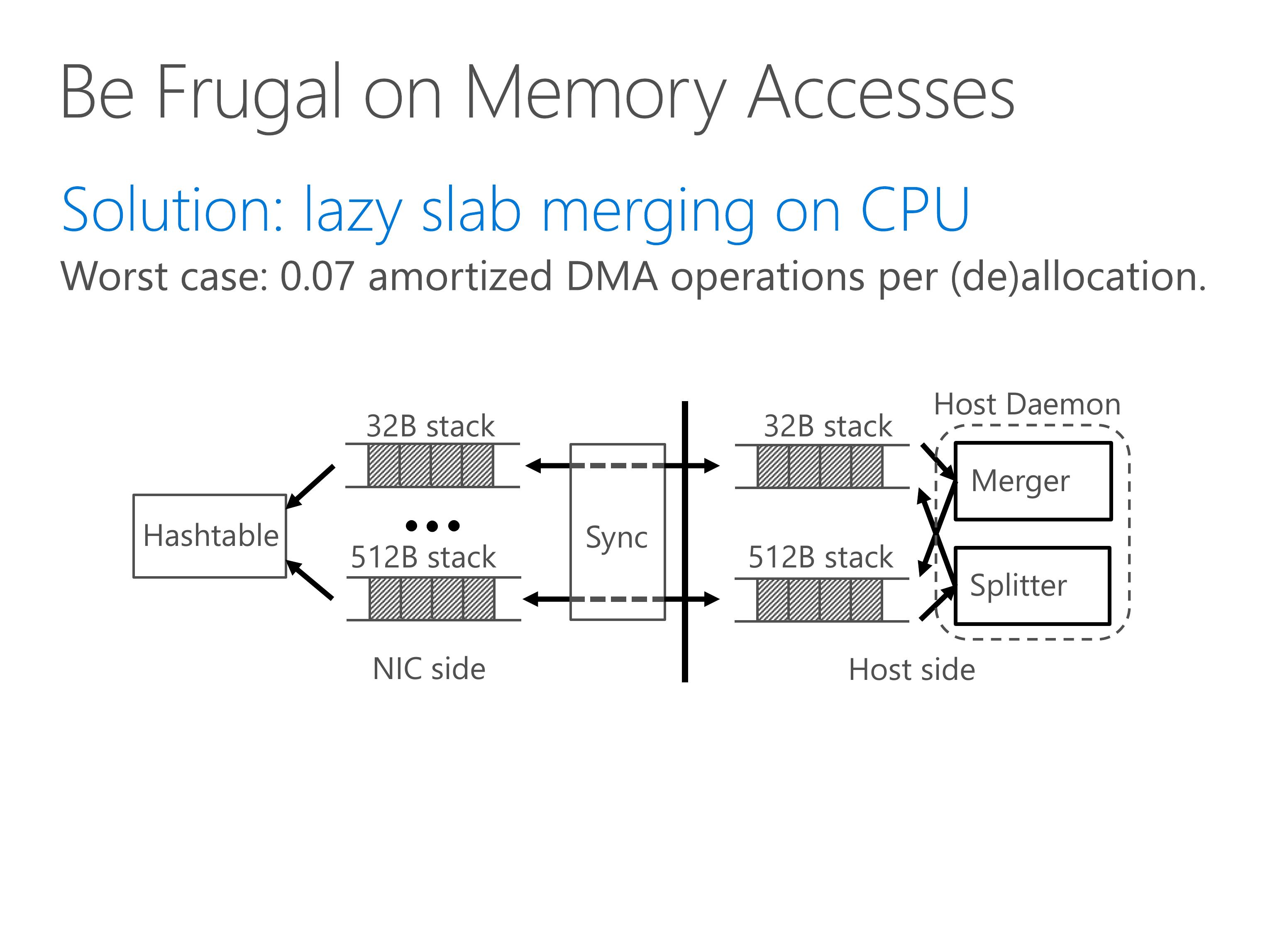
Our solution is to perform lazy slab merging on the CPU.
For each slab size, we cache slab entries on the NIC.
When a slab size is in short of slabs or has excessive slabs, we split or merge them on host CPU.
The NIC cache is synchronized with the host slab pool in batches.
This is similar to log-structured memory where we amortize the write operations by batching them and appending them to the end of operation list.
Due to batching, we achieve less than one tenth amortized DMA operations per allocation and deallocation.

The second design principle is to hide memory access latency.
This is the most important optimization in our system. If you can only remember one optimization technique, out-of-order execution is the take away.
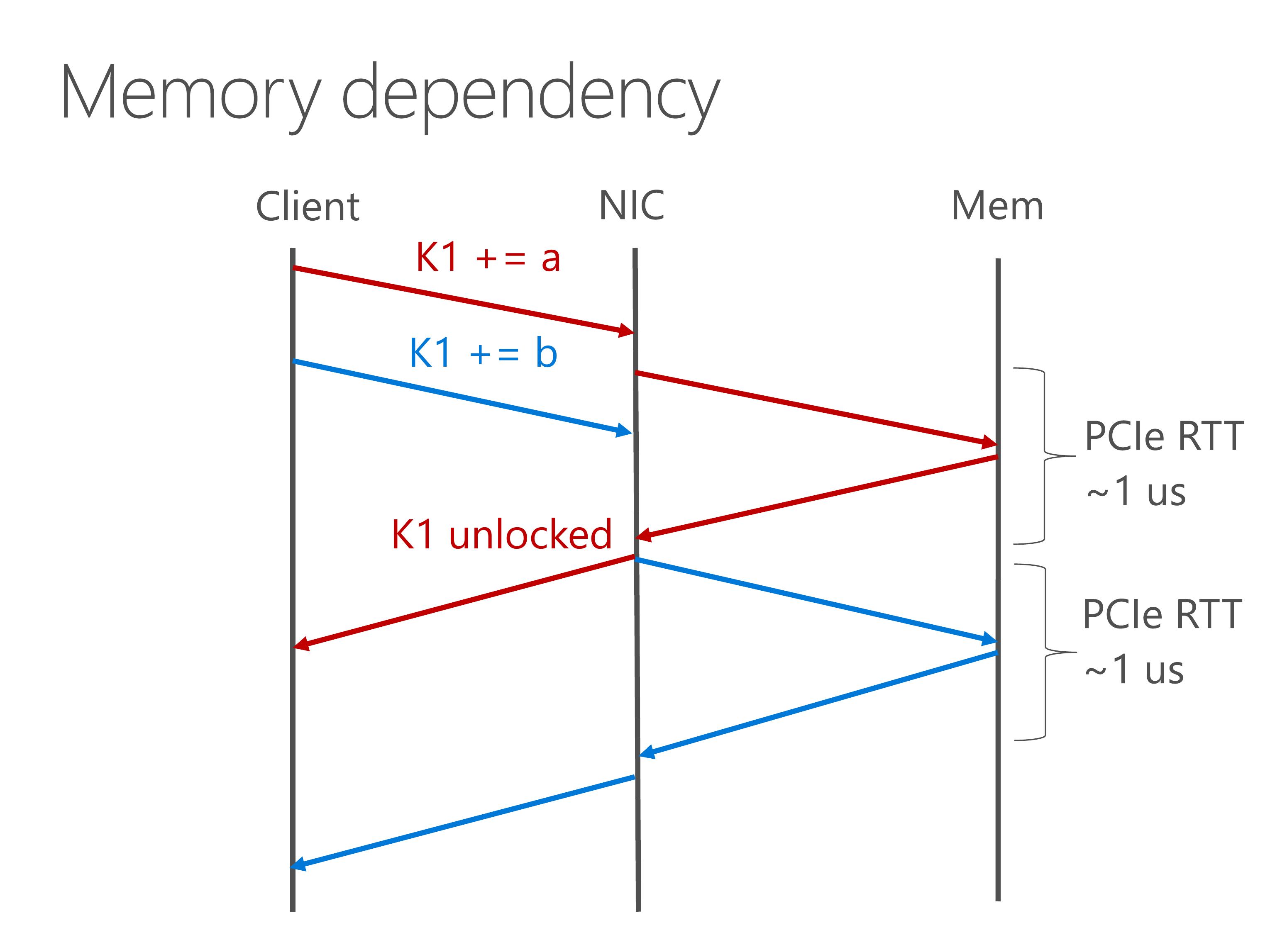
Memory dependency occur when multiple write operations have the same key. For example, we have two atomic add operation arriving simultaneously from clients.
The second atomic add depends on the result of first operation, so each operation takes a round-trip time between NIC and host memory, which is about one microsecond. This causes the throughput of write operations to be only 1 million operations per second.
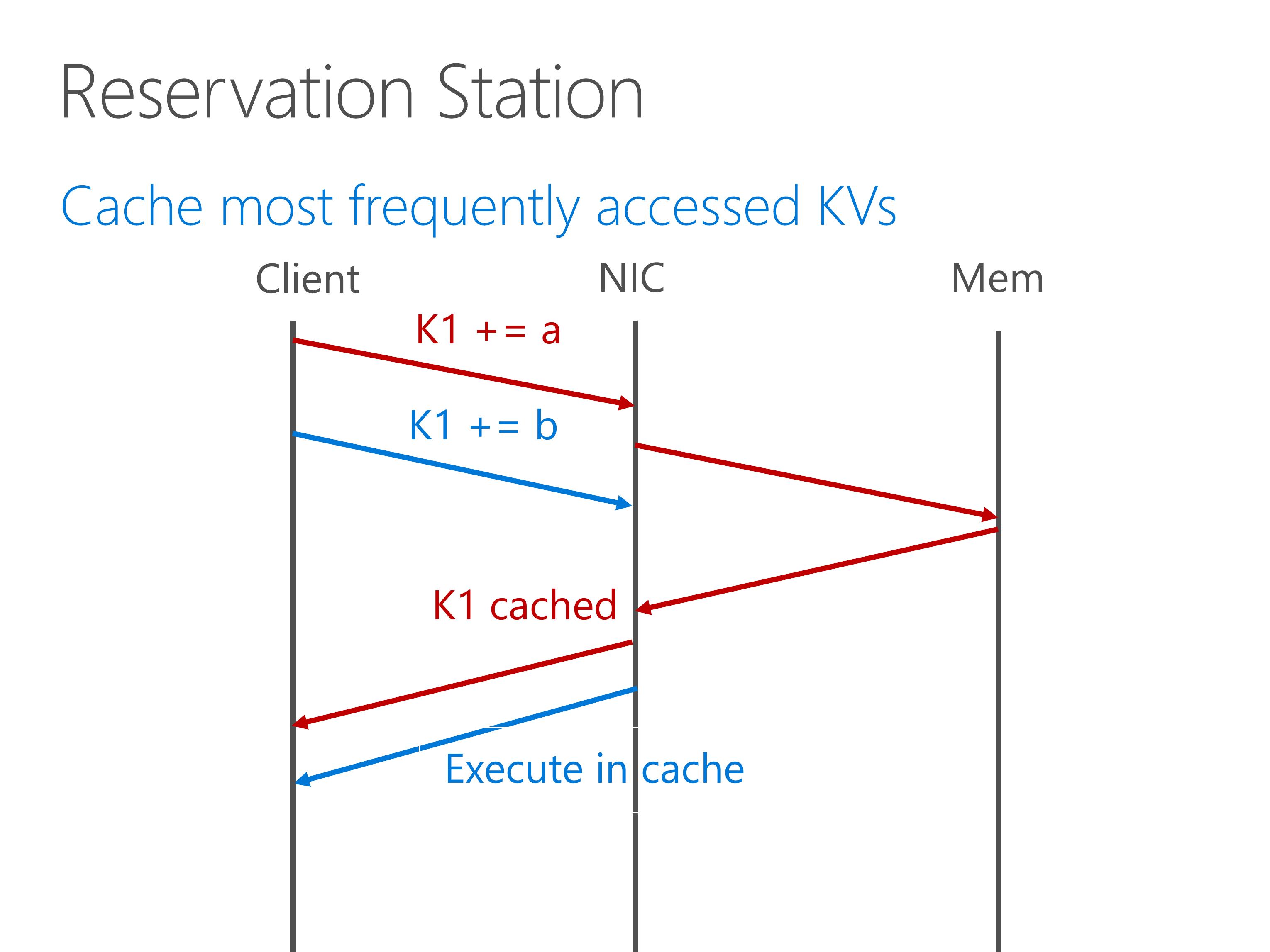
To this end, we build a reservation station to cache most frequently accessed key-value pairs. After the first atomic operation completes, the second atomic operation can be immediately executed in the on-chip cache.
The NetCache paper in this session has shown that, a small number of cache entries is sufficient to cache the most popular key-value pairs.
This is a very important property of key-value access distribution.
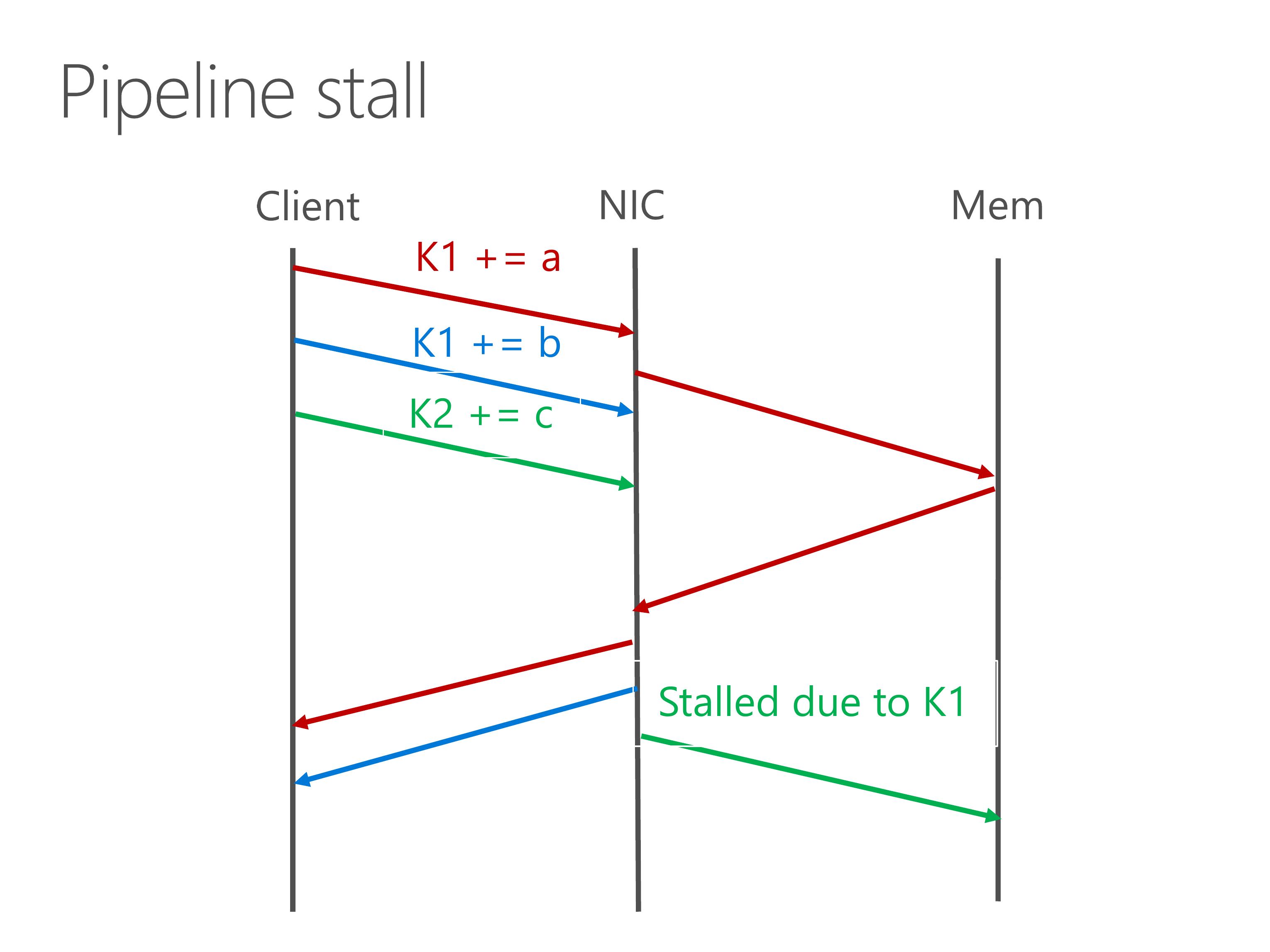
A second case caused by memory dependency is pipeline stall.
For example, after two dependent atomic operations, there is a third atomic operation on a different key.
If we execute the operations one by one, the third operation would be blocked by the second operation.
Actually we know that the operation on K2 can be executed in parallel with K1.
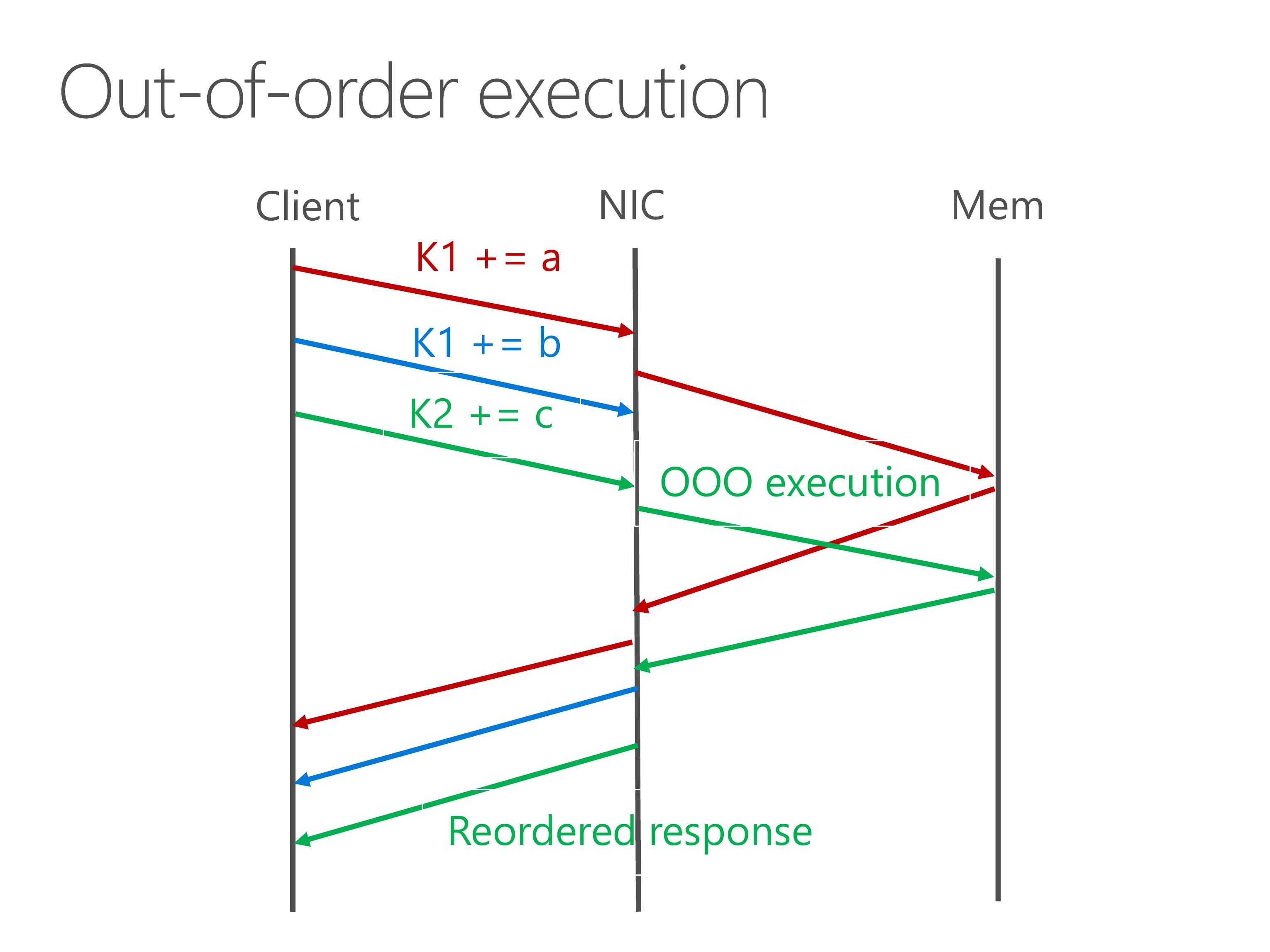
To this end, we design an out-of-order execution engine to issue independent key-value operations to the processing pipeline. When the responses come back, in order to ensure consistency, we reorder the response before sending back to the client.

The out-of-order execution engine achieves nearly 200 times speedup for single-key atomics, which is useful for sequencers, as the Eris paper just said.
For long-tail workload, because there are several extremely popular keys, they are cached by the out-of-order execution engine, so the throughput is only bound by the clock frequency of our FPGA.
Out-of-order execution is a well-known optimization technique in computer architecture literature. We hope future RDMA NICs could adopt this technology for atomic operations.

Now we come to the third principle, leverage throughput of both on-board and host memory.
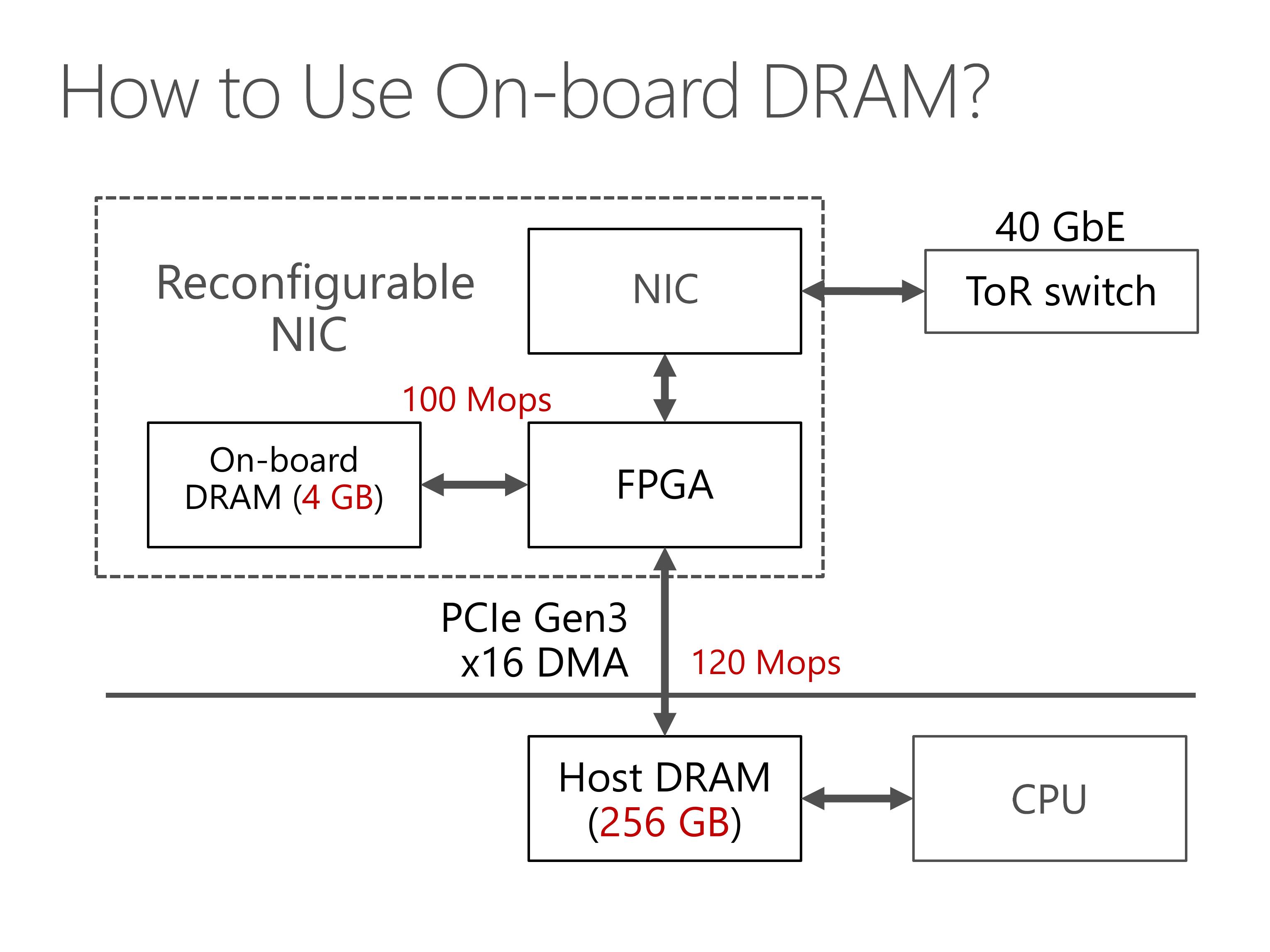
The host memory is large, and the on-board DRAM is small. Both of them have similar throughput. Next we will see why this performance and capacity mismatch is a big challenge.
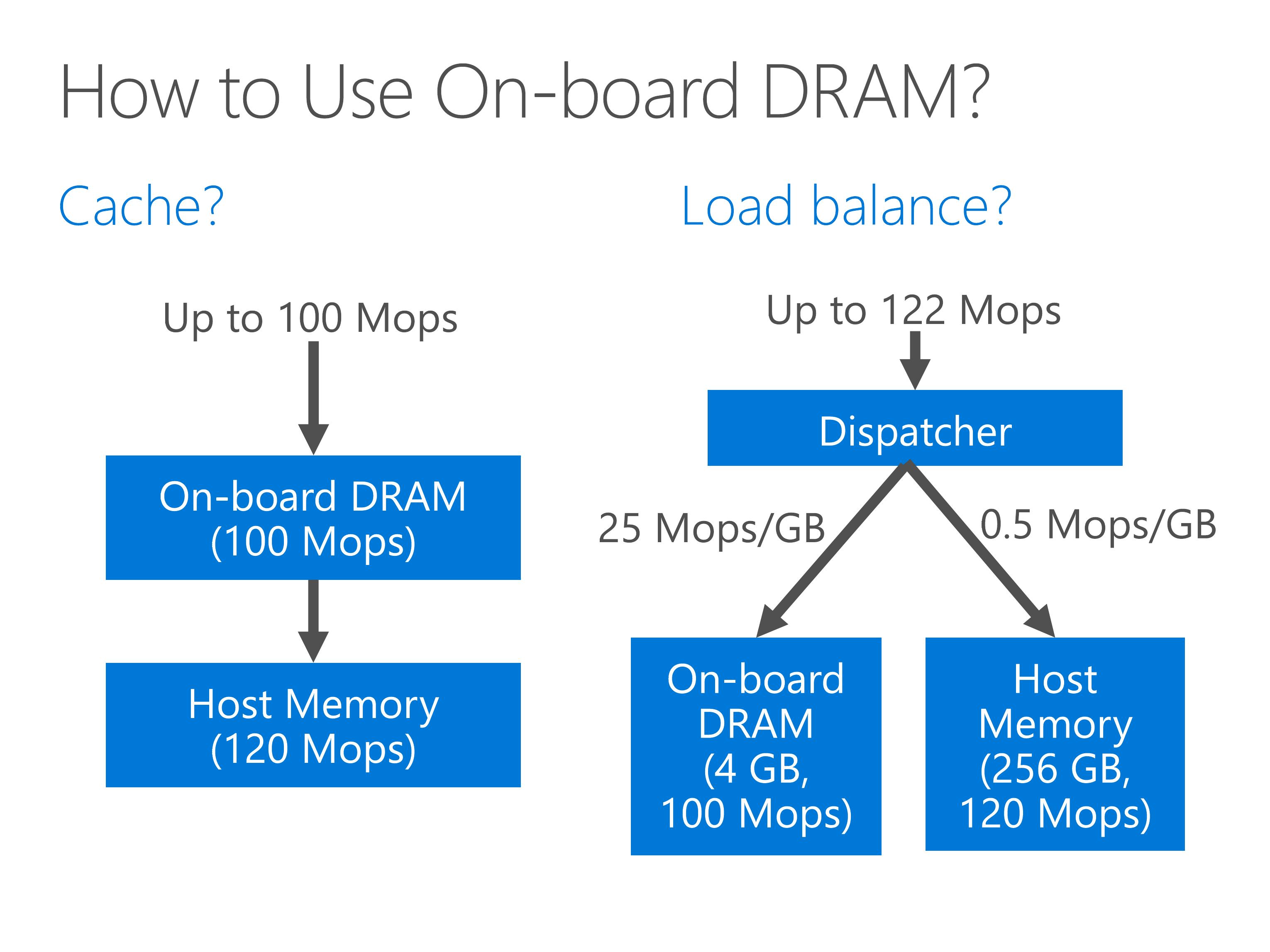
First, we may try to use the on-board DRAM as a cache of host memory. However, the on-board DRAM may be even slower than the host memory, so making it a cache does no good.
Second, we may try to load balance the requests to the on-board DRAM and host memory.
However, the on-board DRAM is much smaller than the host memory.
Because the throughput load per gigabyte of storage is roughly the same, the throughput of on-board DRAM cannot be fully utilized, and the overall throughput is only slightly larger than the host memory.
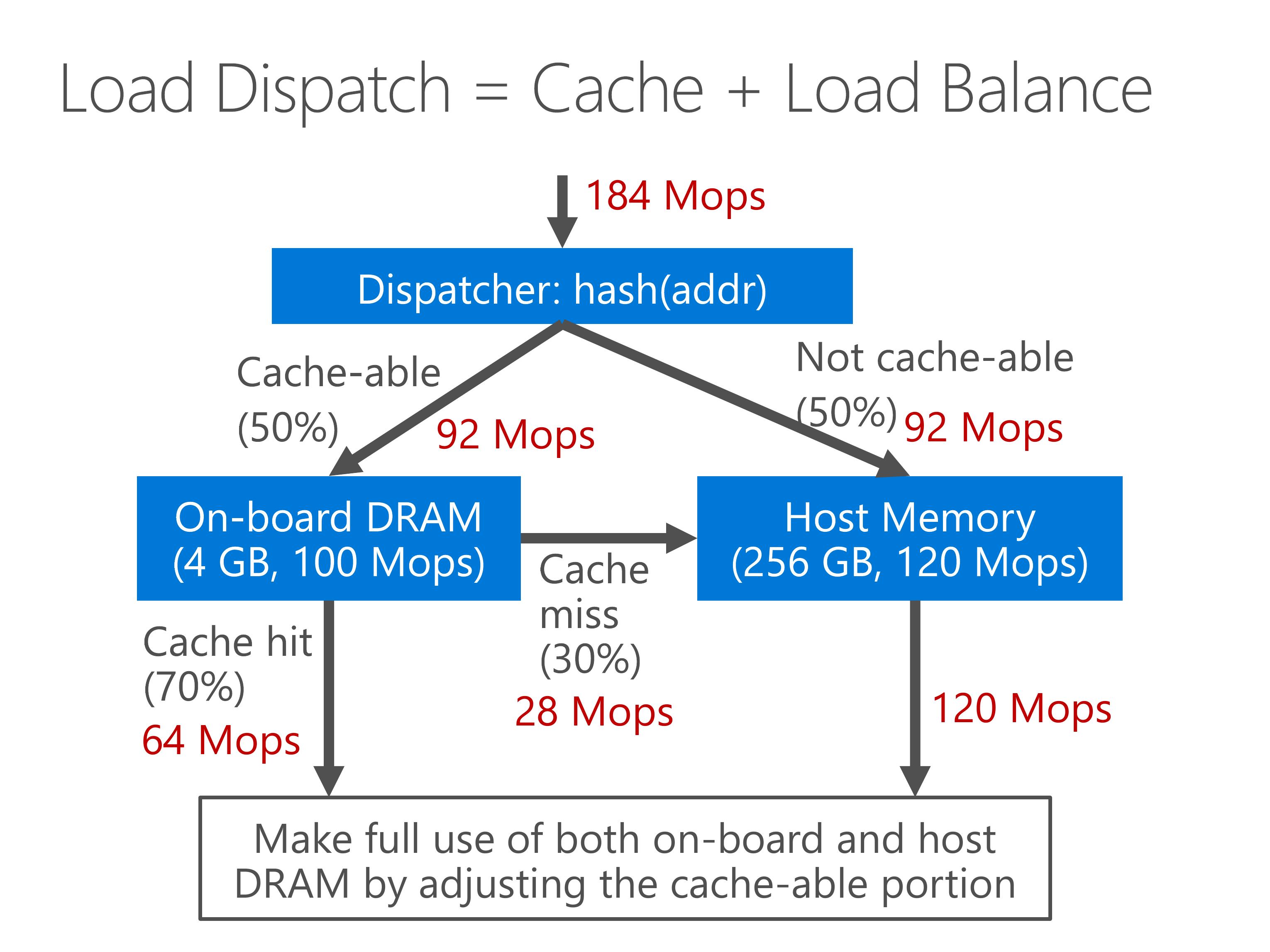
Our approach is a hybrid approach combining both cache and load balance.
The entire memory space is split to one cache-able portion and one non-cacheable portion according to hash of the memory address.
If the address is cache-able, we first look up the on board DRAM. If cache hit, the result is used.
If cache miss, we need to lookup the host memory.
If the address is not cache-able, we directly look up the host memory.
As we can see from the throughput numbers, both throughput of on-board DRAM and the host memory are nearly fully utilize.
By adjusting the portion of cache-able memory, we can balance the throughput of on-board DRAM and host memory.

The last optimization I will talk about is to offload simple client computation to server.
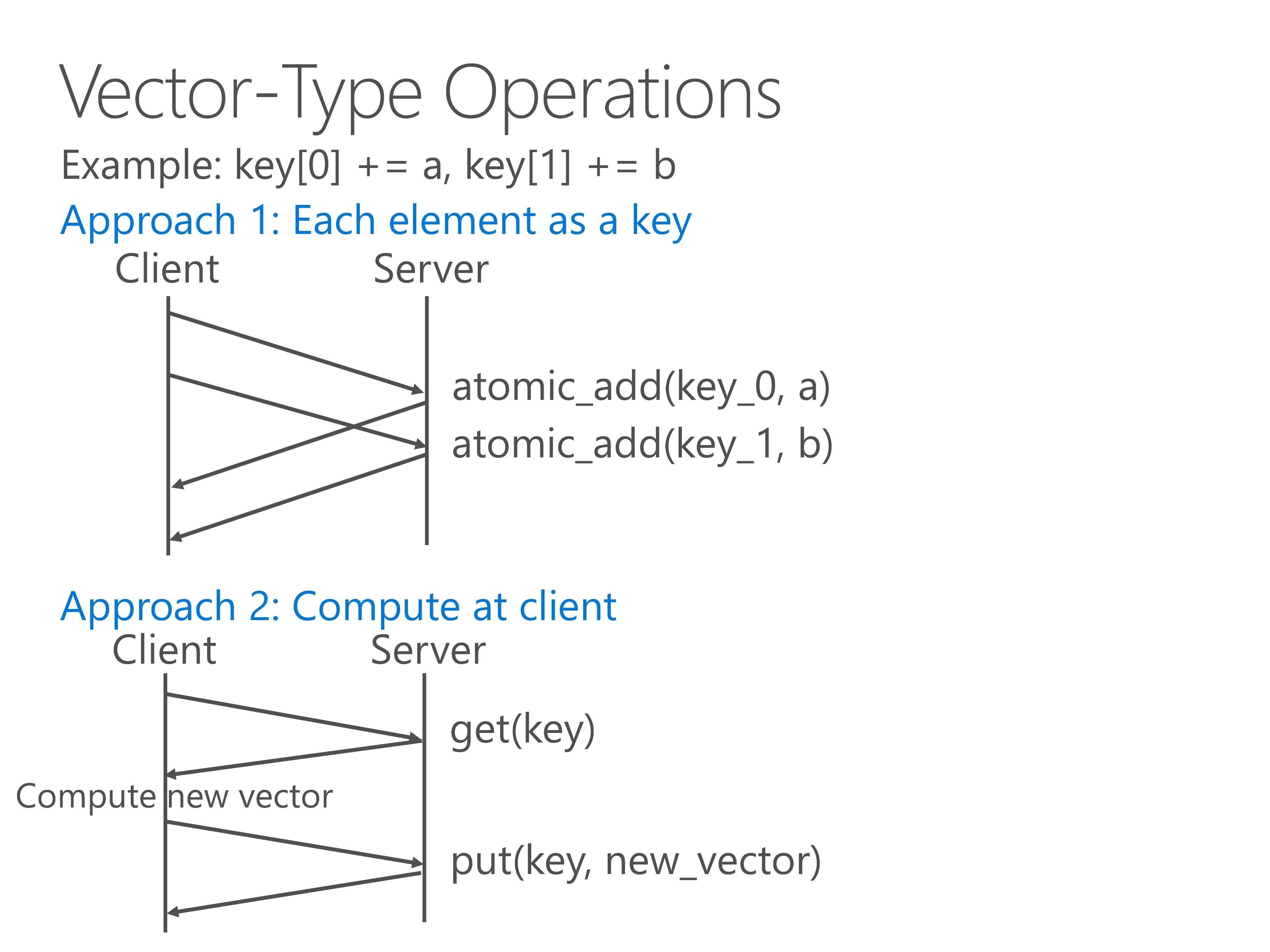
As we have seen from the parameter server and graph engine scenario, vector-type operations are a common pattern in key-value stores.
Here we see an example two-element vector, and we need to perform an atomic add to each component of the vector.
With a traditional key-value store, we have two approaches to implement vector-type operations.
First is to treat each element as a key.
In this way we need to issue multiple key-value operations.
Second is to treat the entire vector as a big value.
In this way we need to transfer the entire vector over the network twice, which doubles the latency.
Furthermore, both approaches need to lock the entire vector to ensure consistency.
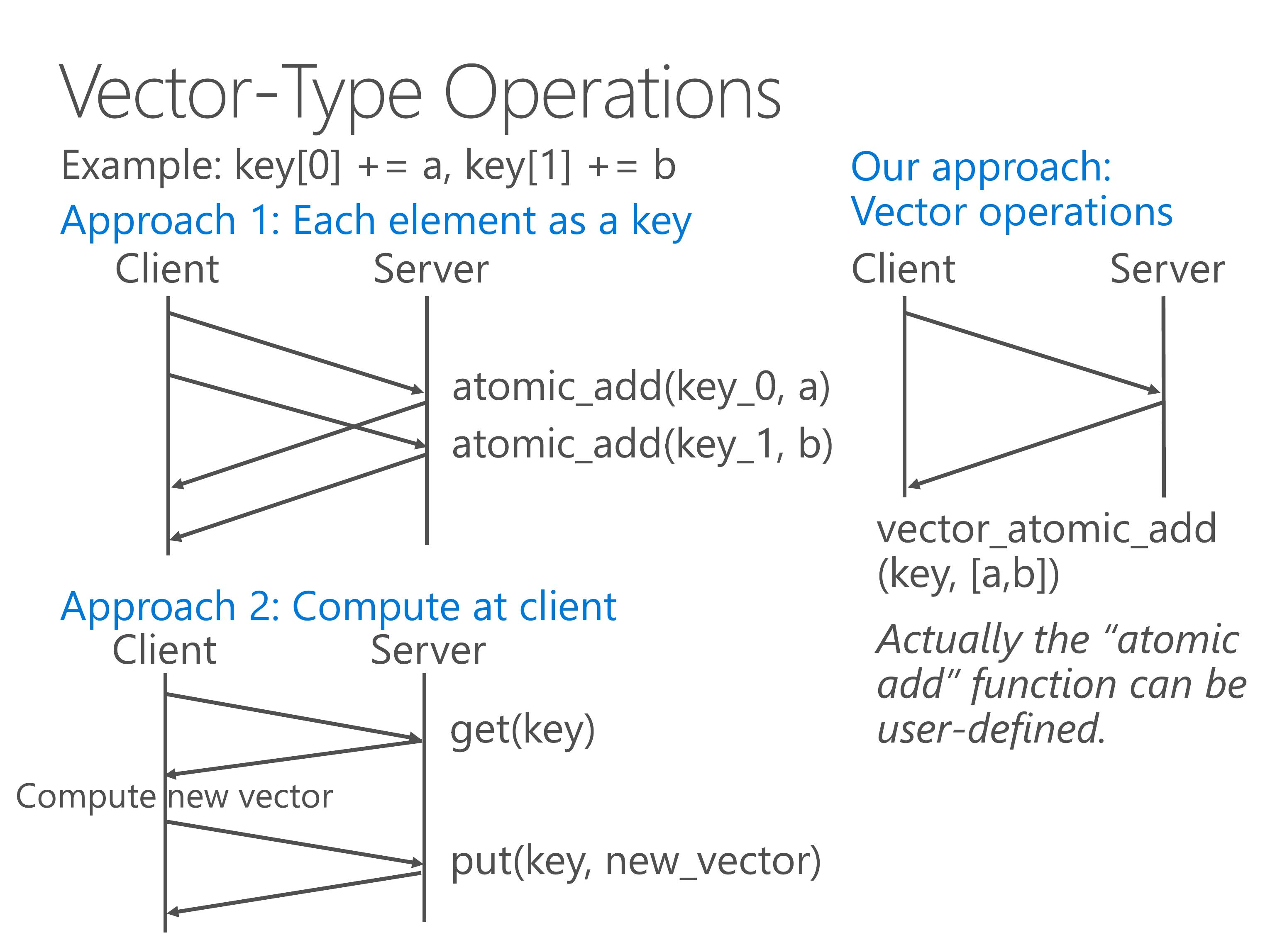
Our approach is to support vector-type operations directly on the server side, so the clients do not need to lock the vector and can save a lot of network bandwidth.
Actually the atomic add function can be any user-defined function. Please consult the paper for details.
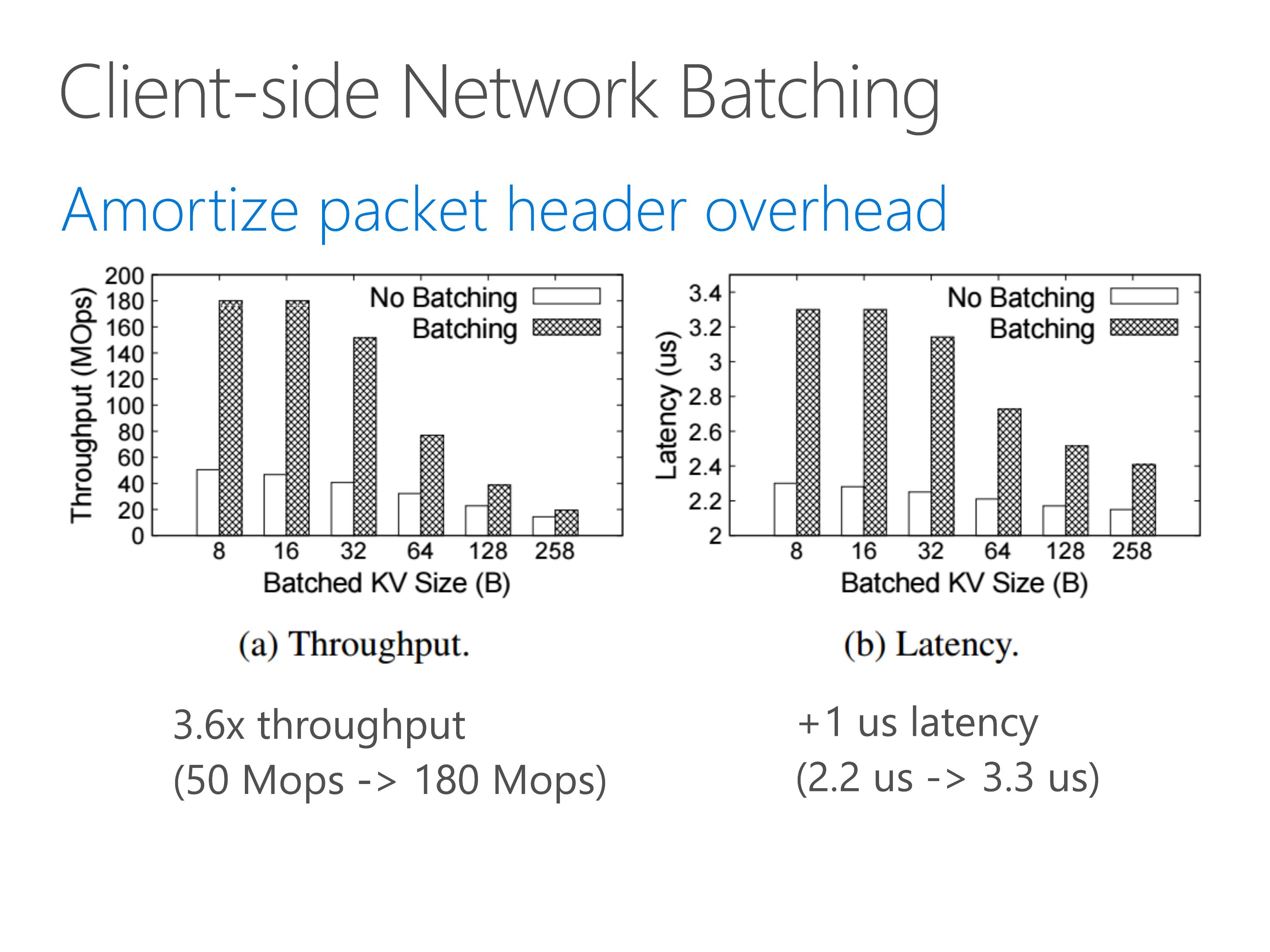
To reduce network overhead, we further leverage client-side network batching to pack multiple key-value operations into one single network packet.
Before network batching, one network packet only carries one key-value operation, so the throughput is only 50 million operations per second.
With network batching, the network throughput is no longer bottleneck for tiny key-value operations.
On the latency part, client-side network batching only adds 1 microsecond delay.
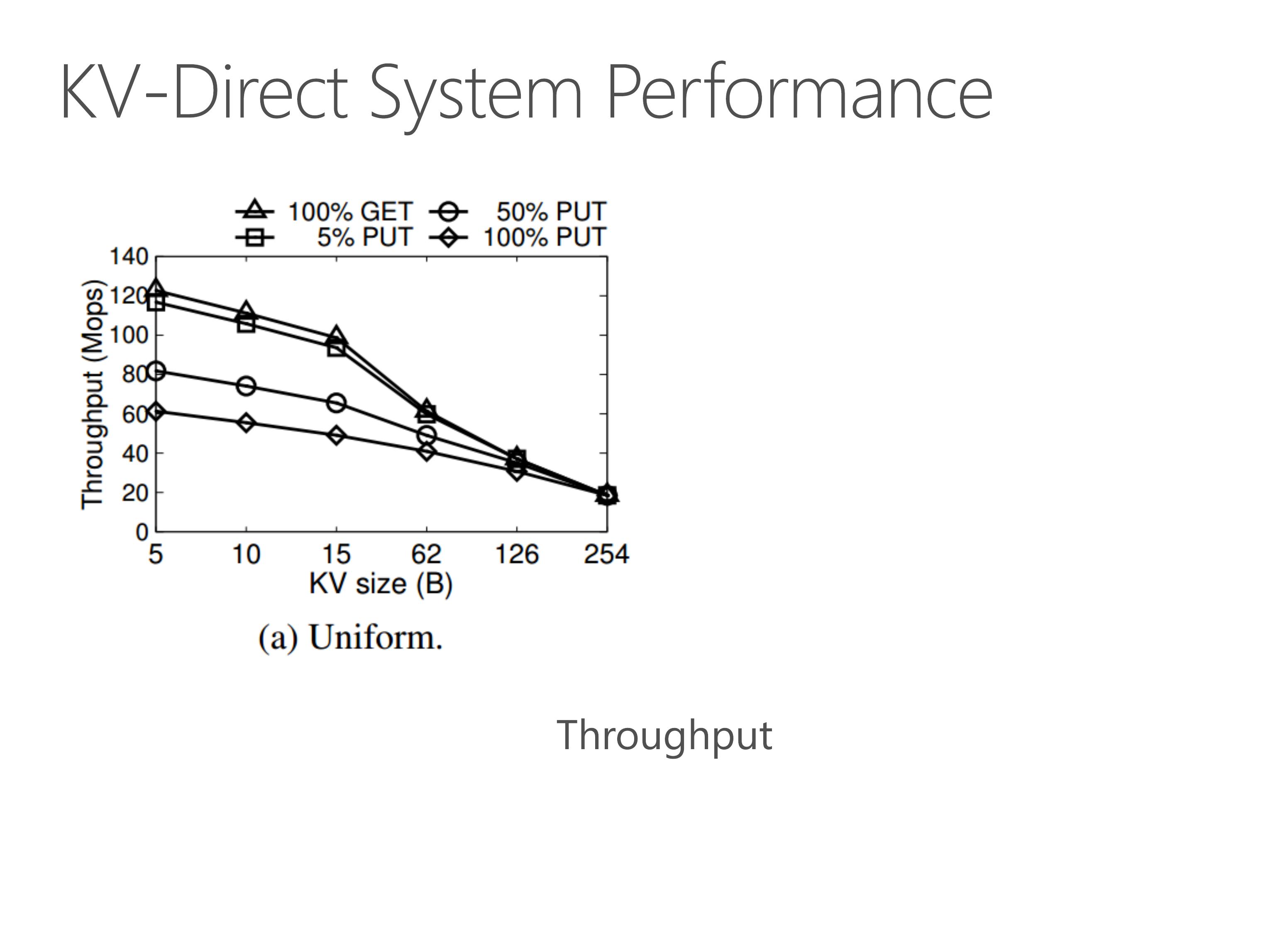
With all these optimizations we have mentioned, KV-Direct pushes the performance to the limit of underlying hardware.
Under uniform workload, for tiny key-value sizes, the GET throughput is over 120 million operations per second. The PUT throughput is approximately half of the GET throughput. This is because one GET operation needs one memory access, and one PUT operation needs two memory accesses, one for read and the other for write.
For larger key-value sizes, the throughput is bounded by the network throughput.
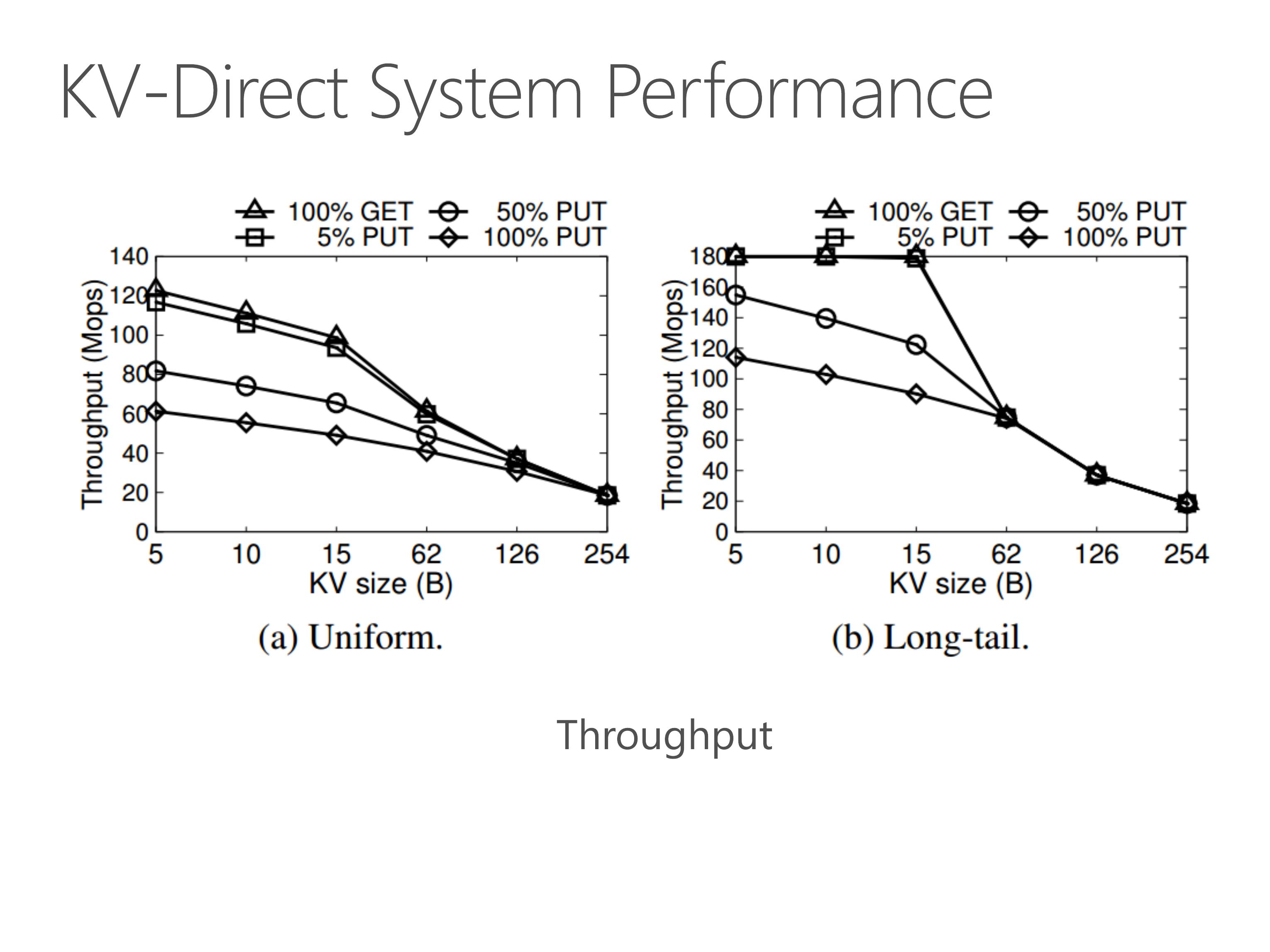
Under long-tail workload, the throughput is higher than uniform workload.
This is because the out-of-order execution engine caches several most popular keys in the on-chip memory, so it does not need to access on-board DRAM or host memory.
For GET operation on tiny KV sizes, the throughput achieves 180 million operations per second. This is the clock frequency of our FPGA.
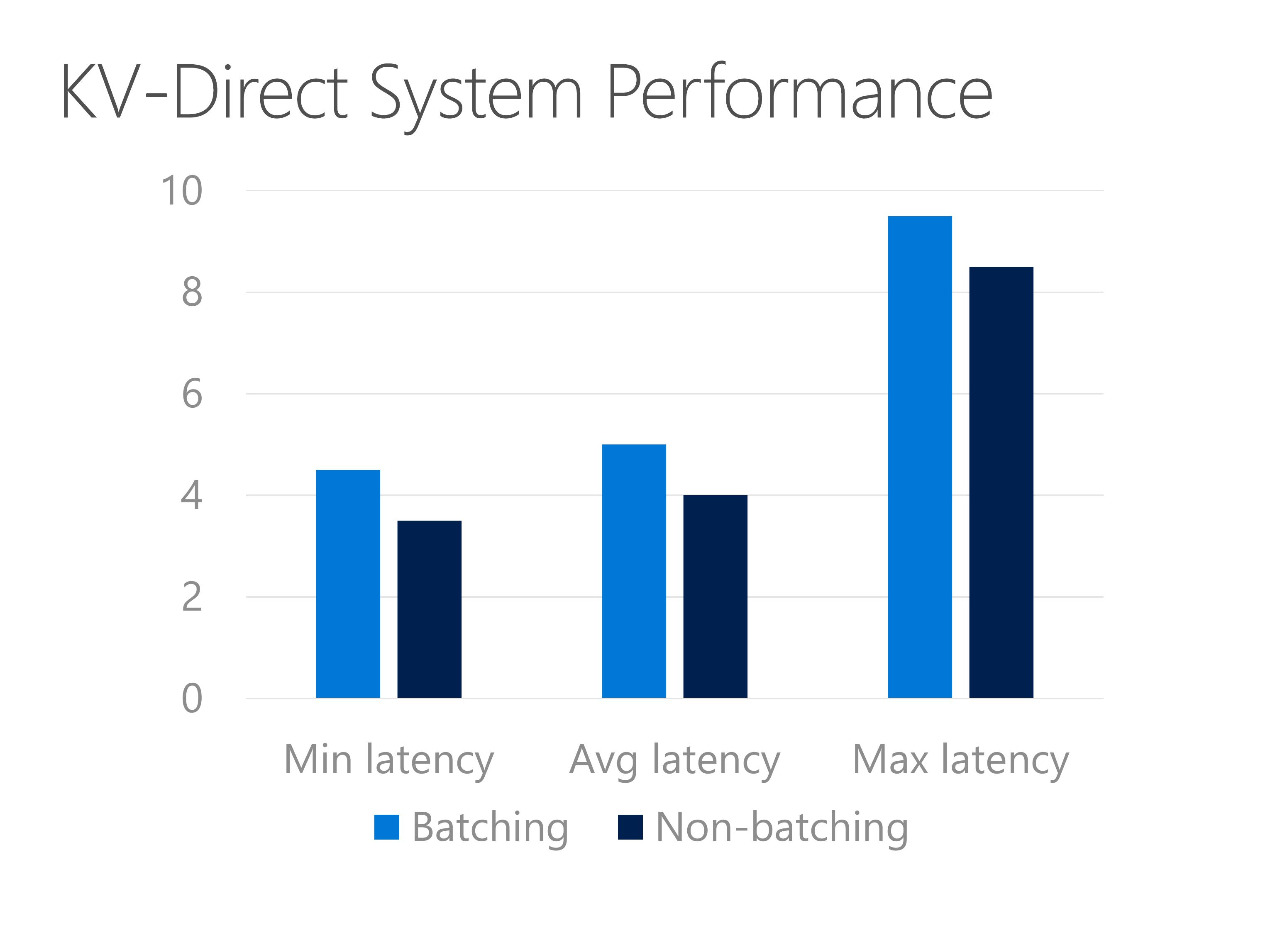
KV-Direct is not only high throughput but also low latency.
Latency of KV-Direct is around 5 to 10 microseconds.
Without batching, the latency reduces about 1 microsecond.

Because PCIe throughput is much lower than available bandwidth of all channels of host DRAM, we reserve only a part of host DRAM for key-value store, and the remaining part can be used for other workloads running on CPU.
As we see from the CPU performance benchmark numbers, when KV-Direct NIC is under peak load, it is little impact on CPU performance and memory access performance. So the server can still run workloads that are not network intensive.
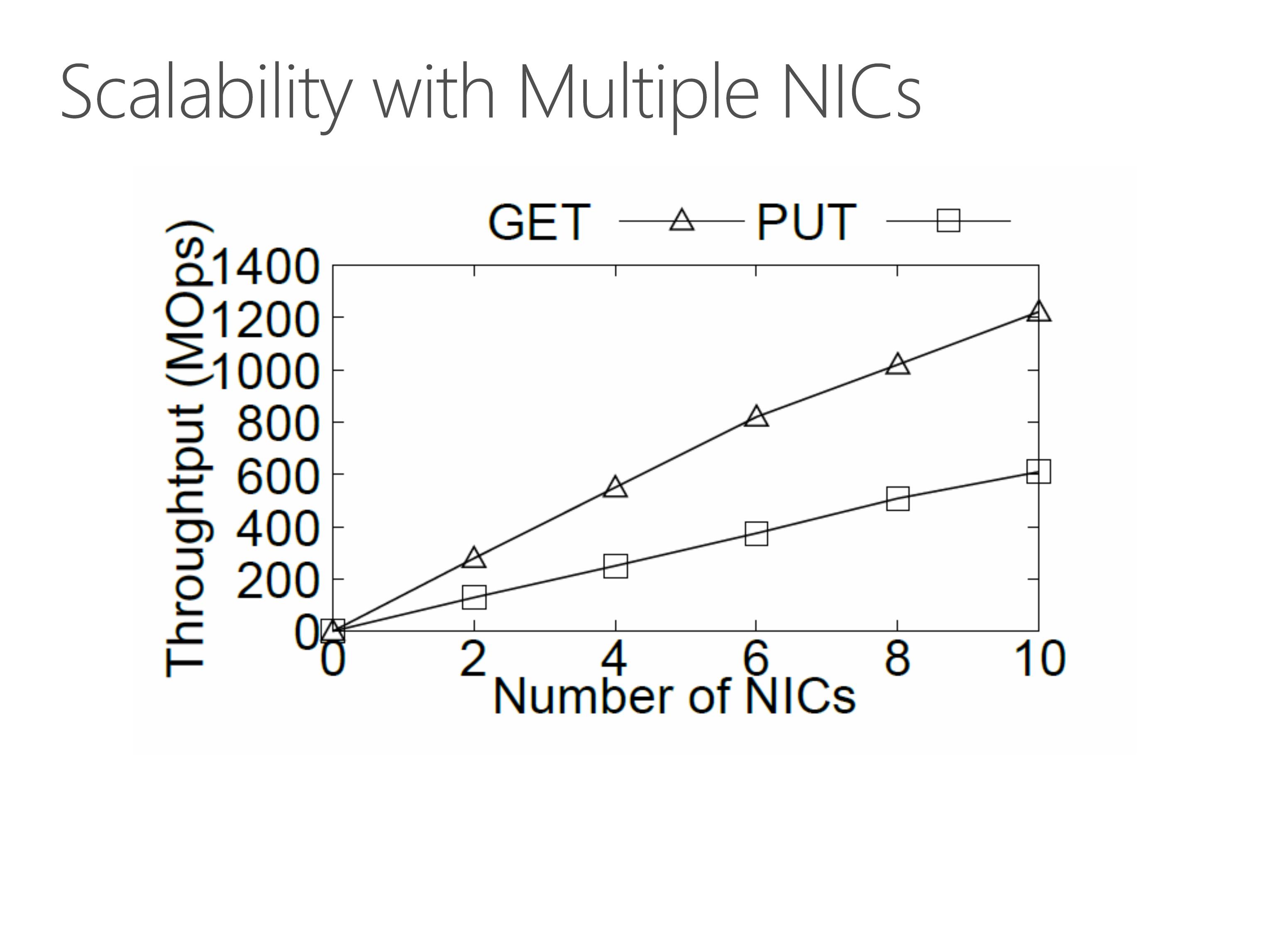
Because a single KV-Direct NIC has not saturated the bandwidth of host DRAM, we can leverage multiple programmable NICs to scale up the KV-Direct system. As we can see in the figure, the throughput increases almost linearly with number of NICs.

This photo is our test server with 10 programmable NICs, two Xeon E5 processors and 128 Gigabytes of memory.
Each programmable NIC is connected to the motherboard via 8 lanes of PCIe Gen3, so the 10 NICs saturate the 80 PCIe lanes from two Xeon E5 processors.
With 10 programmable NICs, KV-Direct achieves 1.2 billion key-value operations per second with less than 400 watts of power consumption, setting a new milestone for general purpose key-value stores.
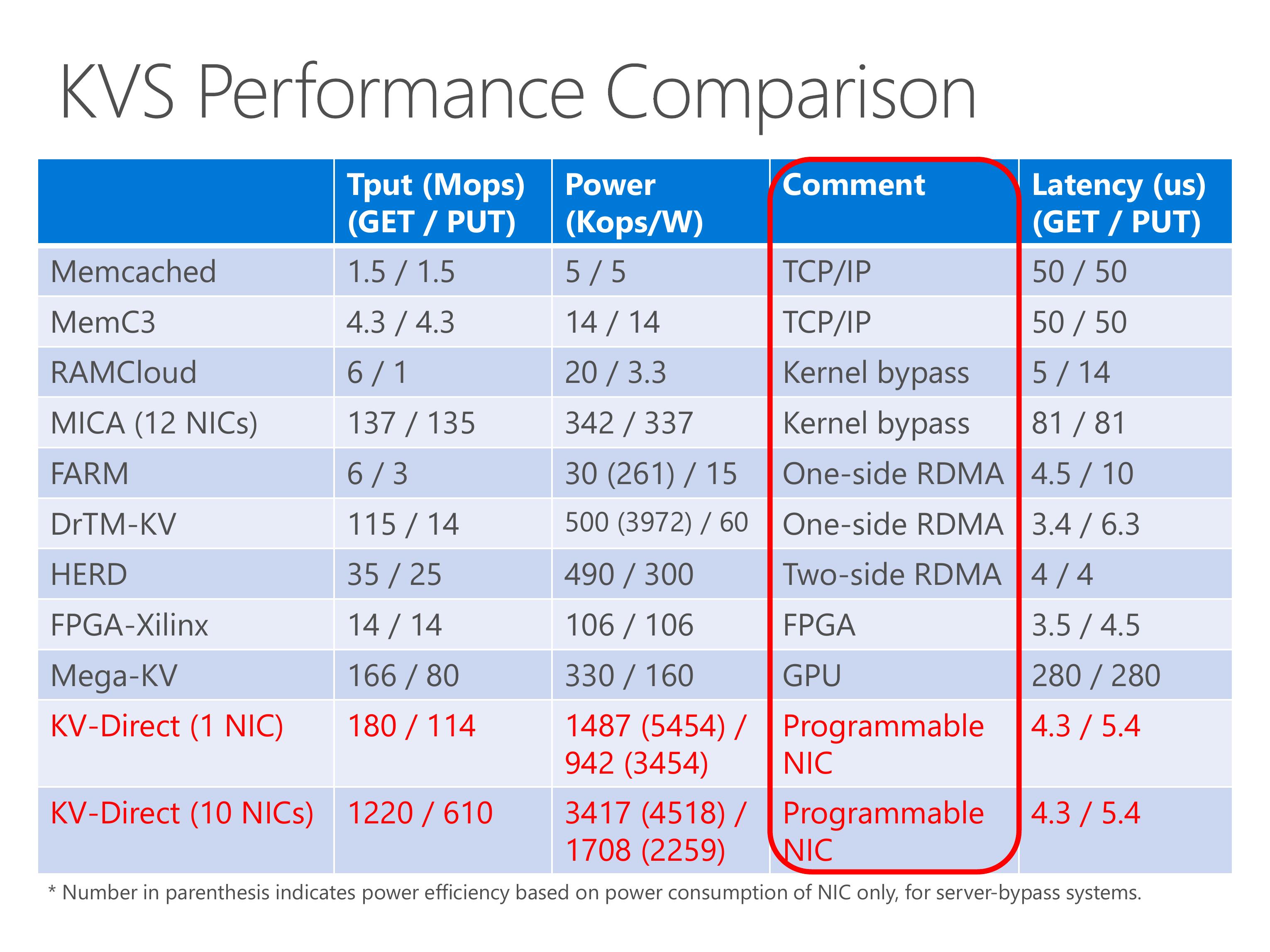
KV-Direct achieves high throughput and power efficiency compared to existing work.
In the table we show several existing systems, including traditional TCP IP, kernel-bypass networking, RDMA, FPGA and GPU.
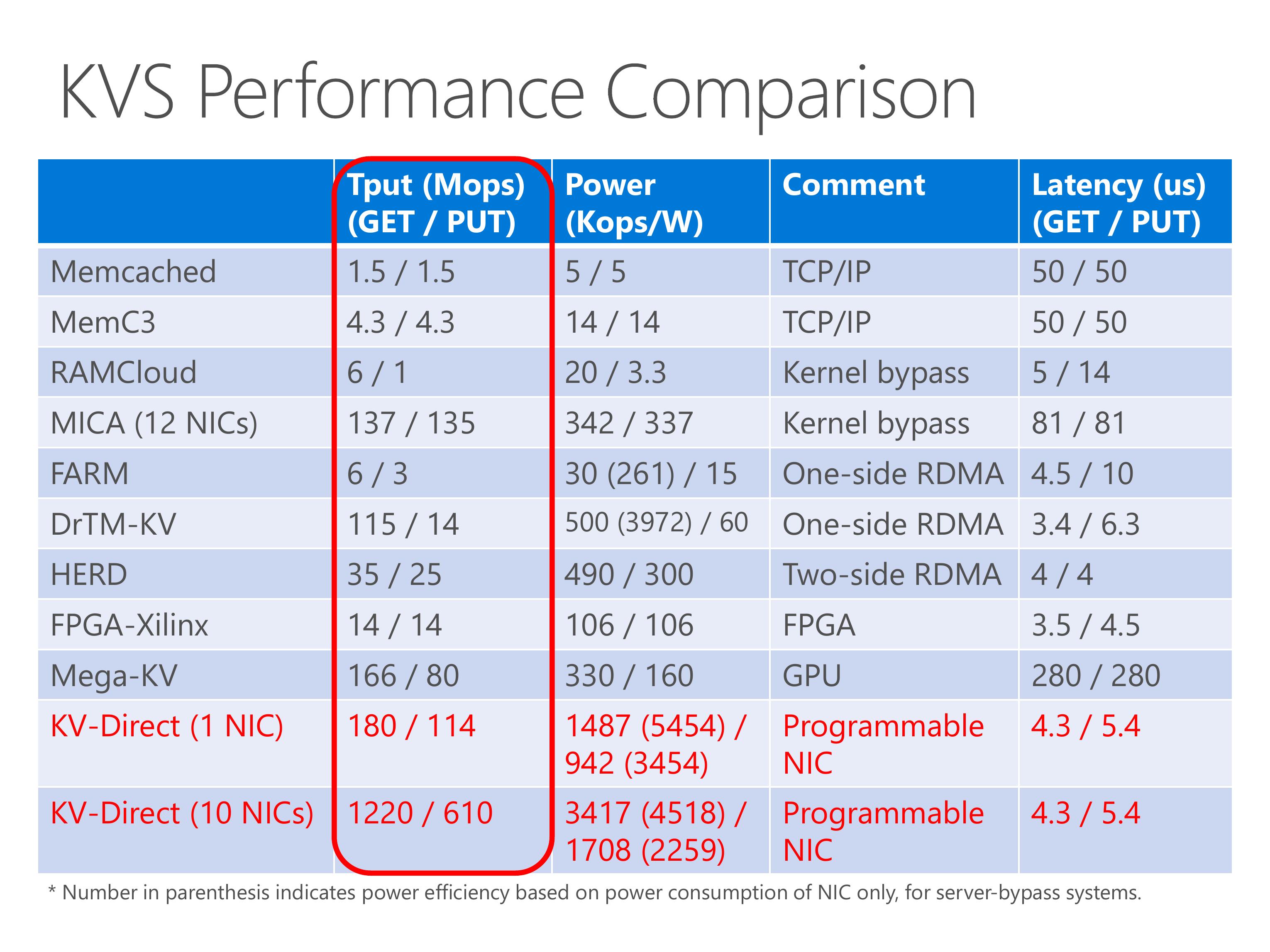
The throughput of KV-Direct is equivalent to 20 to 30 CPU cores.
The MICA system uses 12 NICs, but we achieve the throughput with only a single NIC.
Although the GET throughput of DrTM is high, the PUT throughput is low, this is because it uses one-sided RDMA and the clients need synchronization to keep consistency on write operations.
The Mega-KV system uses GPU, although the throughput of GPU memory is high, its capacity is much smaller than the host memory.
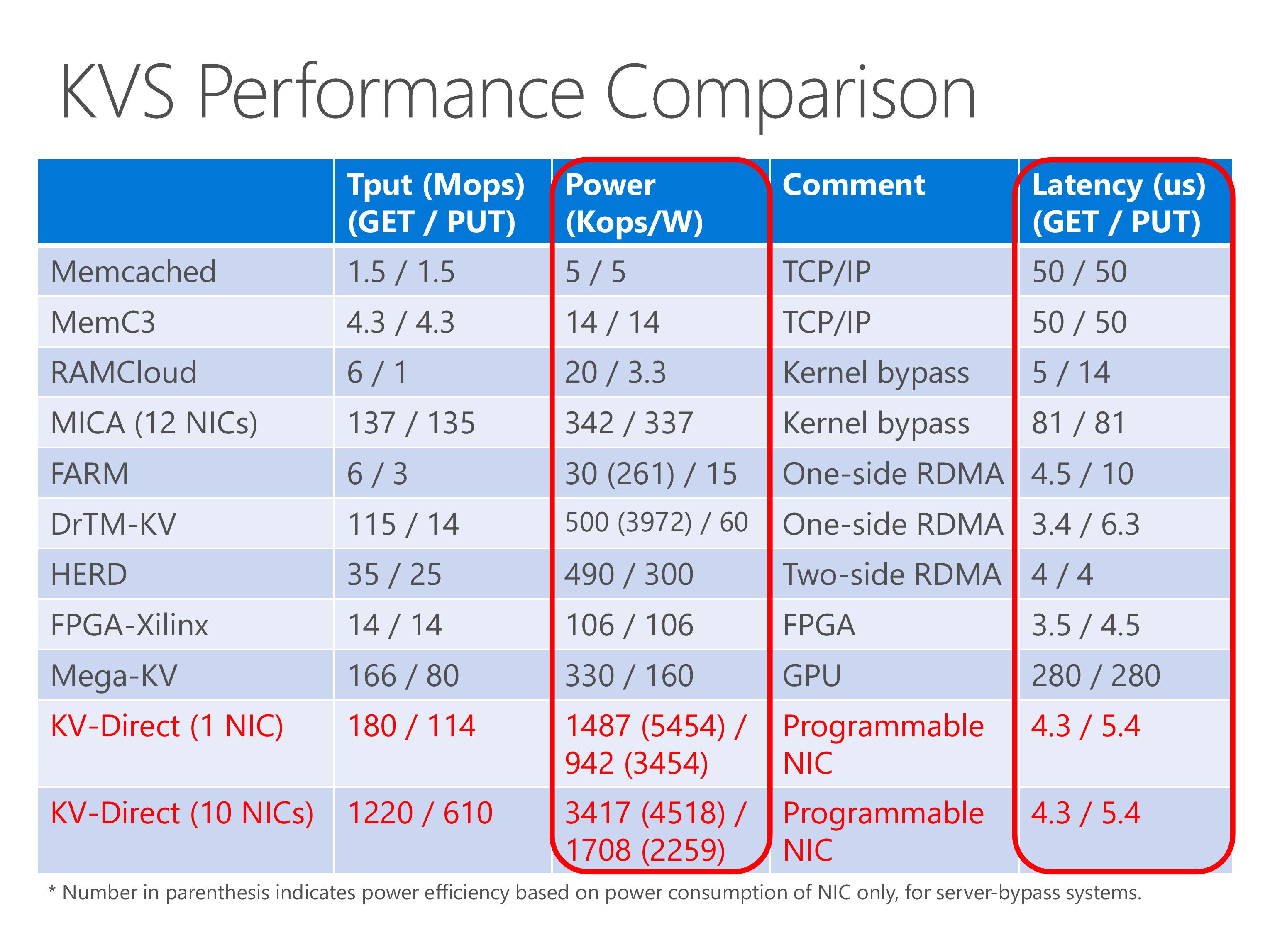
On the power efficiency part, KV-Direct is 10x power efficient than existing work with pure CPU, one-sided RDMA, two-sided RDMA or GPU. Number in parenthesis indicates power efficiency based on power consumption of NIC only, for server-bypass systems. This methodology is justified because other workload can still run on CPU with little performance impact.
Finally, the latency of KV-Direct is on-par with the best of other systems.
In conclusion, KV-Direct leverages programmable NICs to accelerate an important workload in data centers, in-memory key value stores. KV-Direct is able to obtain superior performance by carefully co-designing hardware and software in order to remove bottlenecks in the system and achieve performance that is close to the physical limits of the underlying hardware.
After years of broken promises, FPGA-based reconfigurable NIC finally becomes widely available in main stream data centers. Many significant workloads will be scrutinized to see whether they can benefit from reconfigurable hardware, and we expect much more fruitful work in this general direction.

Thank you for listening!
Q & A
What applications can KV-Direct apply to?
Back-of-envelope calculations show potential performance gains when KV-Direct is applied in end-to-end applications. In PageRank, because each edge traversal can be implemented with one KV operation, KV-Direct supports 1.2 billion TEPS on a server with 10 programmable NICs. In comparison, GRAM (Ming Wu on SoCC’15) supports 250M TEPS per server, bounded by interleaved computation and random memory access.
Are the optimizations general?
The discussion section of the paper discusses NIC hardware with different capacity. First, the goal of KV-Direct is to leverage existing hardware in data centers instead of designing a specialized hardware to achieve maximal KVS performance. Even if future NICs have faster or larger on-board memory, under long-tail workload, our load dispatch design still shows performance gain. The hash table and slab allocator design is generally applicable to cases where we need to be frugal on memory accesses. The out-of-order execution engine can be applied to all kinds of applications in need of latency hiding.
The throughput of KV-Direct is similar to state-of-the-art.
With a single KV-Direct NIC, the throughput is equivalent to 20 to 30 CPU cores. These CPU cores can run other CPU intensive or memory intensive workload, because the host memory bandwidth is much larger than the PCIe bandwidth of a single KV-Direct NIC. So we basically save tens of CPU cores per programmable NIC. With ten programmable NICs, the throughput can grow almost linearly.
How to ensure consistency among multiple NICs?
Each NIC behaves as if it is an independent KV-Direct server. Each NIC serves a disjoint partition of key space and reserves a disjoint region of host memory. The clients distribute load to each NIC according to the hash of keys, similar to the design of other distributed key-value stores. Surely, the multiple NICs suffer load imbalance problem in long-tail workload, but the load imbalance is not significant with a small number of partitions. The NetCache system in this session can also mitigate the load imbalance problem.
What is the non-batch throughput?
We use client-side batching because our programmable NIC has limited network bandwidth. The network bandwidth is only 5 GB/s, while the DRAM and PCIe bandwidth are both above 10 GB/s. So we batch multiple KV operations in a single network packet to amortize the packet header overhead. If we have a higher bandwidth network, we will no longer need network batching.