Bojie Li (李博杰)
2023-05-27
(本文系笔者根据 2022 年 12 月 12 日在北京大学的演讲整理,首先将会议录音使用科大讯飞语音识别转换成口水稿,然后用 GPT-4 加以润色,修正语音识别的错误,最后人工加入一些新的思考)
非常感谢黄群教授和许辰人教授邀请,很荣幸来到北京大学为两位教授的计算机网络课程做客座报告。我听说你们都是北大最优秀的学生,我可是当年做梦都没进得了北大,今天能有机会来跟大家交流计算机网络领域学术界和工业界的一些最新进展,实在是非常荣幸。
图灵奖得主 David Patterson 2019 年有一个非常有名的演讲,叫做《计算机体系结构的新黄金时代》(A New Golden Age for Computer Architecture),它讲的是通用处理器摩尔定律的终结和领域特定体系结构(DSA)兴起的历史机遇。我今天要讲的是,计算机网络也进入了一个新黄金时代。
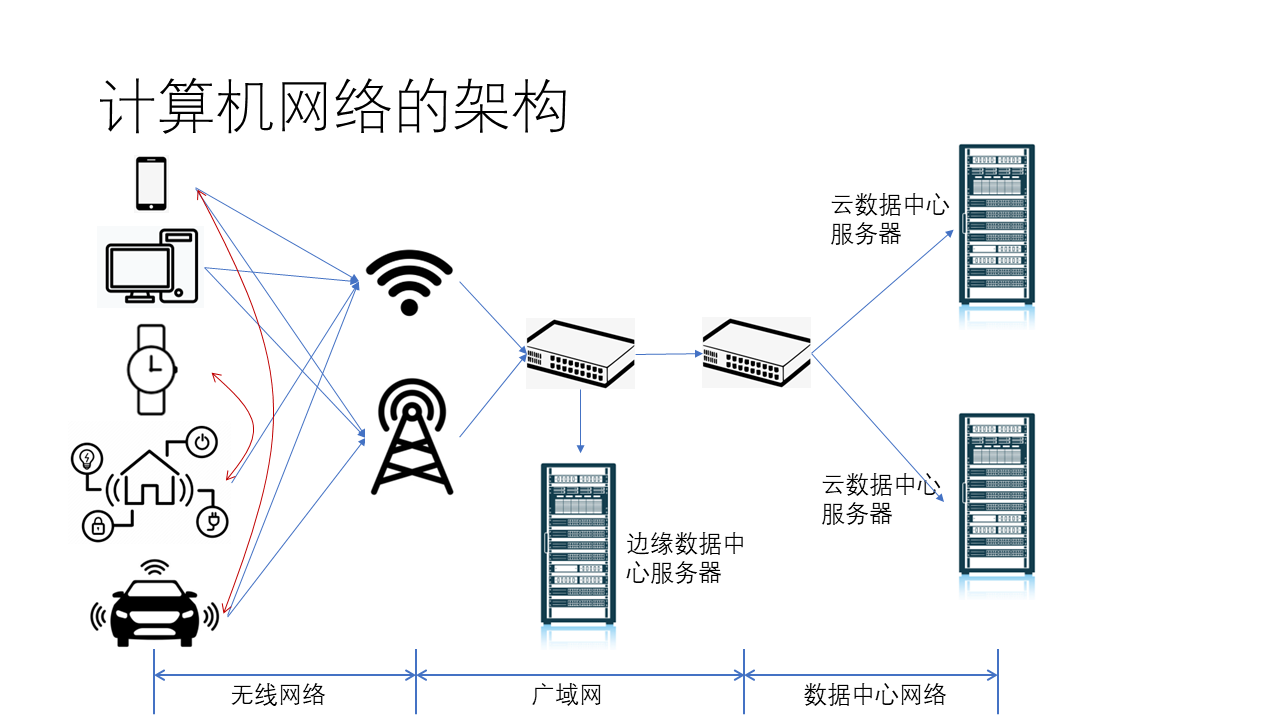
我们日常接触到的计算机网络主要由三大部分组成:无线网络、广域网和数据中心网络。它们为万物互联的智能世界提供了通信基石。
其中,无线网络的终端设备包括手机、PC、手表、智能家居、智能汽车等各种设备。这些设备通常是通过无线方式(如 Wi-Fi 或 5G)访问网络。经过 5G 基站和 Wi-Fi 热点之后,设备将进入广域网。广域网中还有一些 CDN 服务器,这些服务器属于边缘数据中心。接下来,设备将进入数据中心网络。在数据中心网络中,还有许多不同类型的设备,如网关、服务器等。

今天,我将分别从数据中心网络、广域网和终端无线网络这三个领域给大家做一些介绍。首先,让我们来看数据中心网络。数据中心网络最大的变化是从为简单的 Web 服务设计的简单网络,演变成为大规模异构并行计算所设计的网络,执行 AI、大数据、高性能计算等传统上超级计算机才能处理的任务。
2023-05-27
(智造公社微信公众号文章,原文链接,非常感谢智造公社的精彩问题和整理编辑)
AI到底会对人类社会的技术和生活产生什么影响?
随着GPT4发布,大模型AI的性能再一次刷新公众想象,AIGC产出的内容越发真实、精致,随着数据清洗和训练的不断深入,AI对自然语言的理解能力也显示出了巨大的进步,从被动地接受数据“投喂”,到主动向世界发问,或许,科幻片里的“人工智能生命”已经距离我们不再遥远。
焦虑在所难免,“AI失业”在部分行业似乎正在真切上演。当地时间2023年5月18日,英国最大的电信运营商英国电信公司表示,将在2028年至2030年期间裁员4万至5.5万人。此次裁员将包括英国电信的直接员工和第三方员工,将使公司员工总数减少31-42%。目前,英国电信公司员工数量约为13万人。
英国电信的老板菲利普·詹森对外宣称,在完成光纤铺设、数字化工作方式、采用人工智能(AI)并简化其结构之后,将依靠更少的劳动力和显著降低的成本基础,“新的英国电信集团将是一个更精简的企业,拥有更光明的未来”。回看国内,一些互联网科技企业也显露出了相关的势头,尤其游戏公司的美术外包等岗位,堪称“重灾区”。
谈及这个问题,华为2012实验室助理科学家李博杰表示,公众的一些焦虑被媒体放大了,AI技术并非取代人类的洪水猛兽,反而,是解放生产力,塑造更多新岗位的浪潮,“比如说我们去看过去的工业革命,原来做农耕的人现在都要去使用机器了,他所需要的教育,以及对社会、经济和人们的生活生产方式变化都非常大”。
李博杰认为,在AI技术普及,成为一种新的生产工具以后,又会因应产生更多业态以及职业,“比如说有了电脑之后,就不需要抄写员在那辛辛苦苦抄东西了对吧?AI也是一样的,有些行业直接涉及人的,它没办法取代,比如说像服务业对吧?但有些很按部就班做固定模式化的东西,AI就可以简化很多的劳动”。
作为和AI密切相关的数据中心网络技术研究者,李博杰提出了许多对AI的看法和思考,下面,是智造公社主笔小智与李博杰的对谈记录:
2023-05-25
这是我 5 年前的旧文。那是 2018 年初的冬夜,我在十三陵自己架起了一口大锅,向 8.6 光年之外的天狼星发送了人类知识的一小部分。这件事背后的故事在这里。今天我们关心的是,向可能的外星文明发送消息,显然需要让外星文明认识到这个消息是一个智慧生命发出的,还得让外星文明理解它。
一个很基础的问题就是,如何在消息中证明自己的智能程度呢?换言之,如果我是一个监听宇宙信号的智慧生命,如何判断收到的一堆信号中是否包含智能?由于智能不是一个有或无的问题,而是一个多或少的问题,如何衡量这堆信号中包含何种程度的智能呢?我觉得 5 年前自己的思考还是有点意思,整理一下发出来。
消息就是一个字符串。设想我们能够截获外星人的所有通信,拼接成一条长长的消息。它包含多少智能?这并不是一个容易回答的问题。
现有技术一般是尝试对消息进行解码,然后看它是否表达了数学、物理学、天文学、逻辑学等科学中的基本信息。1974 年的阿雷西博信息就是用这种方式来编码信息,希望得到地外文明的关注的。我则试图找到一种纯计算的方法来衡量消息中蕴含的智能程度。
2023-04-20

昨天这条朋友圈在公司内外引起热议,很多人来联系我。
我是从创新和商用两个角度考虑的。
2023-01-29
长文预警:《MSRA 读博五年》系列之二,约 13000 字,未完待续……
发表在 SOSP 2017 上的 KV-Direct 是我的第二篇(第一作者)论文。因为第一篇 SIGCOMM 论文 ClickNP 是谭博手把手带我做的,KV-Direct 也是我自己主导的第一篇论文。
SIGCOMM 之后做什么
SIGCOMM 论文投稿之后,谭博说,下一个项目我需要自己去想方向。
做编译器还是做应用?
我们深知 ClickNP 还有很多问题,目前支持的编译优化过于简单,希望从编程语言的角度提升编译器的可靠性。与此同时,我们把 ClickNP 作为组内网络研究的一个公共平台,孵化更多的研究创意。
我自然就沿着两个方向去探索,一个是扩展 ClickNP 来让它更容易编程、更高效;另一个是利用 ClickNP 这个平台来开发新型的网络功能,去加速网络里的各种中间件。那时,我们在并行探索很多中间件,例如加密解密、机器学习、消息队列、七层(HTTP)负载均衡器、键-值存储,这些都可以用 FPGA 来加速。
为了提高 ClickNP 的可编程性,我开始从学校里物色好的苗子加入 MSRA 实习。李弈帅在本科期间,就对编程语言和形式化方法很感兴趣。他是我推荐来到 MSRA 实习的第一位学生。春季学期开始,李弈帅就来 MSRA 开始实习,也恰好完成他的本科毕业设计。他为 ClickNP 系统提出了几个关键的优化,新增了一些简化编程的语法,修正了一些蹩脚的语法。
但是,由于工作量的原因,我们并没有对编译框架做大的重构,仍然在使用简单的语法制导翻译,没有使用 clang 这种专业的编译器框架,也没有中间语言。因此,每次新增编译优化的时候都显得比较 ad-hoc。
由于 OpenCL 经常遇到奇奇怪怪的问题,我就萌生了自己做一个高层次综合(HLS)工具的想法,从 OpenCL 直接生成 Verilog。我的想法很简单,对于网络领域的应用场景,我们所做的就是把一段 C 代码中的循环全部展开,变成了一大块组合逻辑,只要在合适的位置插入寄存器,就能变成一条吞吐量极高、每个时钟周期都能处理一次输入的流水线。如果代码中有访问全局状态,那么这种循环依赖就决定了依赖路径上寄存器的最大数量,也就是时钟频率的上限。
但是谭博并不同意我自己做 HLS 工具的想法,因为我们并不是专业的 FPGA 研究者,这样的工作创新性不足,更多是在填补现有 HLS 工具的 “坑”,是一个工程问题,不管在 FPGA 还是网络领域都难以发表顶级论文。
由于 FPGA 卡的烧写经常出现问题,我就天天到机房里面插拔 FPGA 卡,有时候直接在机房里面就地调试。因此,我就又像本科在少院机房的时候一样,经常吹着冷风,忍着 80 多分贝的噪音,在机房里面一泡一两个小时。
2023-01-23
长文预警:《MSRA 读博五年》系列之一,约 12000 字,未完待续……
2021 年 7 月 31 日,ACM 中国图灵大会上,我站在主席台上等待 ACM 中国优秀博士学位论文奖,没想到走上台来为我颁奖的是包校长,我的双腿不由自主地有些颤抖。这是我唯一一次近距离见到包校长。包校长高兴地说,看到获奖人中有我们中科大的,说明中科大也是可以培养大师的,希望以后你们能够成为大师,报效祖国,回归母校。
颁奖典礼的主持人刘云浩教授让我们说说博士论文的标题和导师,我脱口而出,《基于可编程网卡的高性能数据中心系统》,导师是中科大的陈恩红教授和微软的张霖涛博士,还要特别感谢华为的谭焜博士。我能清楚地记住博士论文的标题,它就挂在自己的主页上。在公司里,经常有人给我发私信,问我你就是某某论文的作者吗?我就不好意思地说,是的……
很多人也许认为,我是那种一心学习的博士,其实我的博士生活比很多人想象的有趣很多,真应了 MSRA(微软亚洲研究院)这句格言 “Work hard, play harder”。
研究小白
联合培养
MSRA(微软亚洲研究院)跟国内的多所高校有联合培养博士生项目。其中,跟中科大的联合培养项目已经持续多年。大三下学期,MSRA 到学校面试几十位候选人,从中选出十几位学生到 MSRA 进行暑期实习和大四一年的实习,并在暑期实习结束后确定下来大约 7 位学生成为联合培养博士。这些联合培养博士将在中科大完成第一年的硕博课程,而后面四年将在北京的 MSRA 进行学术研究,最后取得中科大的博士学位。
MSRA 选拔联合培养博士的要求是所谓 “三好” 学生:数学好、编程好、态度好。这个规矩据说是前院长沈向洋博士定下来的。我本科因为整天在少年班学院机房和 LUG 活动室倒腾各种 Linux 网络服务,不怎么好好学习,成绩自然也不好看,GPA 只有 3.4(满绩 4.3),其中数学分析(二)还挂过科。面试官当时就问我,数学成绩怎么这么差。大概是我高中曾经在编程竞赛(NOI)中得过奖,简历上又有很多在LUG搞的网络服务项目,最后我竟然被联合培养博士项目录用了。其他被联合培养项目录用的同学 GPA 都起码是 3.7,大部分都是 3.8 以上的大神。
2023-01-23
从故纸堆里发现了 2004 年石家庄电视台送我留念的 VCD 盘,经过修复和转码,19 年前播出的《大明星李博杰——记华罗庚金杯赛金奖得主》访谈节目终于重见天日。
从这个 13 分半钟的视频中,可以看出我当年有多胖 :) 视频 11:25 开始是当众揭短的体育问题 :)
2023-01-22

时间:2023 年 5 月 1 日 10:58
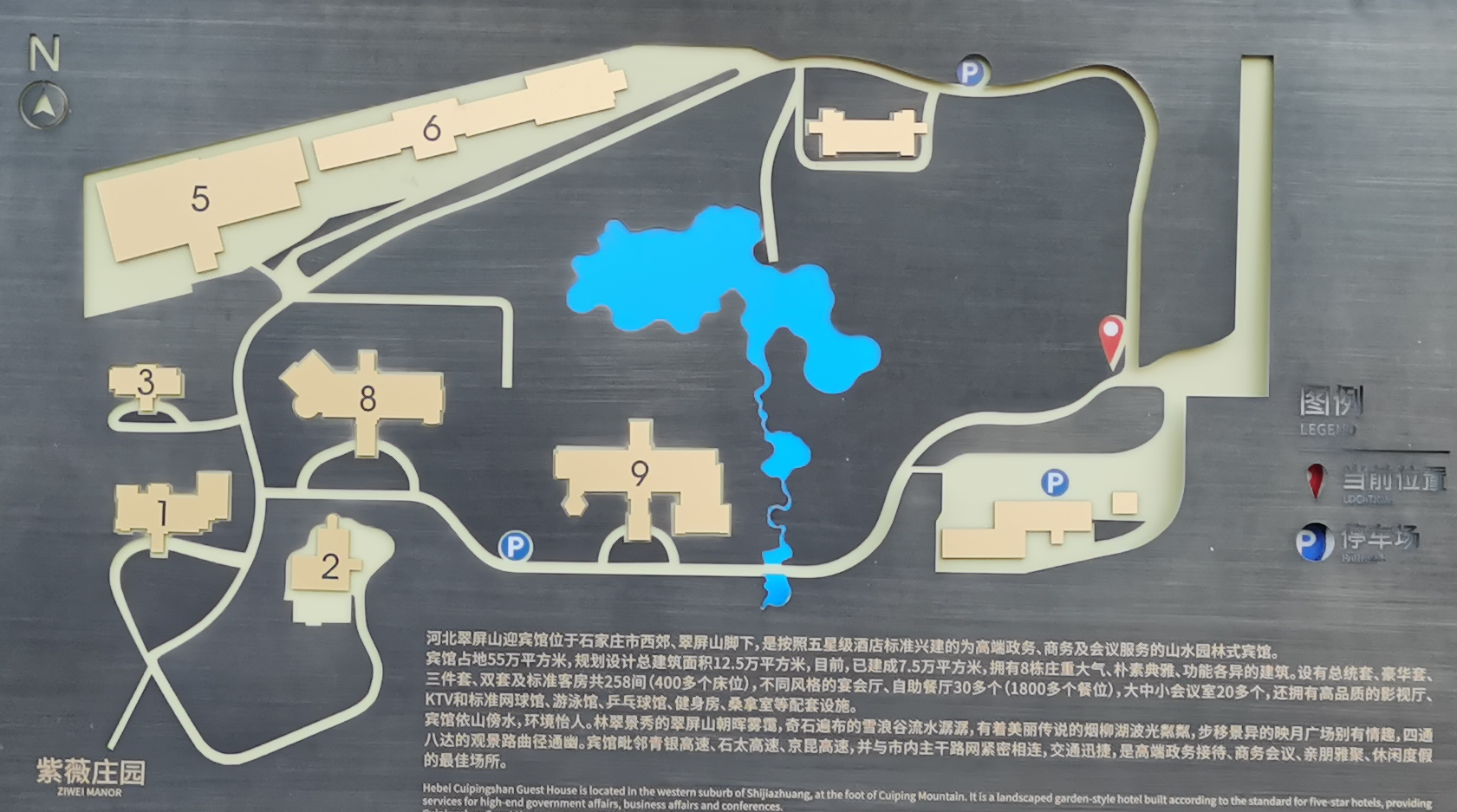
地点:河北翠屏山迎宾馆
交通信息 :河北翠屏山迎宾馆位于石家庄市鹿泉区迎宾馆路 1 号。
- 由于翠屏山迎宾馆地处西郊,不通地铁,公共交通较为不便,建议打车出行。
- 高铁:
- 乘车:距离石家庄高铁站最近路线 16 公里、走高架 22 公里,不堵车情况下约需 35 分钟车程。
- 公共交通:可乘 320 路/空 320 路直达(需步行 1.3 公里),需 1 小时 20 分钟;或乘地铁 3 号线转地铁 1 号线转旅游 5 路,需 1 小时 10 分钟。
- 石家庄高铁站晚上 22 点后打车排队很长,如果较晚抵达,建议提前联系我们接站。
- 飞机:
- 乘车:距离石家庄正定国际机场 53 公里,不堵车情况下约需 50 分钟车程。
- 公共交通:从正定机场可乘机场大巴 1 号线(每小时一班)转地铁 1 号线转旅游 5 路,需 2 小时 10 分钟。
- 正定机场晚上打车不便,如果较晚抵达,建议提前联系我们接站。
- 由于婚礼 10:58 正式开始,建议 4 月 30 日抵达石家庄。北京出发的如果时间紧张也可以考虑乘坐 5 月 1 日的早班高铁(06:26 至 08:34 出发的 5 个班次)。

住宿信息 :
- 尽量安排住河北翠屏山迎宾馆 6 号楼和 9 号楼,已预留房间。如果有特殊情况,我们将安排附近酒店。
- 早餐预计在 6 号楼,7:00~10:00。伴郎伴娘及工作人员需要较早出发,来不及用早餐,将在 6 号楼和 9 号楼安排简餐。
- 6 号楼和 9 号楼之间距离 560 米,步行需 8 分钟。
2022-12-13
有个经典笑话,一学生选了一门课《选择与未来》,结果到了课堂才发现讲的是《期权与期货》,因为它们的英文都是 Options and Futures。前几天开会的酒店正好在上海期货交易所对面,就想到一个问题:我们的对未来的判断和选择,是根据什么做出的呢?
最近,我读了两本书《天资差异》(Gifts Differing)和《4D 卓越团队》(How NASA Builds Teams),发现这就体现了不同人思维方式的不同。感觉(Sensing)与直觉(iNtuition)、思考(Thinking)与情感(Feeling)就是两对最关键的差异。
在正文之前,请您不妨思考,在《西游记》中,孙悟空、猪八戒、唐僧、沙僧师徒四人的性格有什么差异,又是如何团队合作的呢?
2022-12-12
感谢许辰人教授、黄群教授邀请,非常荣幸于 2022 年 12 月 12 日为北京大学计算机网络课程做了一个 guest lecture。
Abstract: 数据中心网络、广域网和无线网络为万物互联的智能世界提供了通信基石。
数据中心网络传统上为容易并行的 Web 服务设计。但如今 AI、大数据、HPC 都是大规模异构并行计算系统,对通信性能都提出了很高的要求,厚重的软件栈造成巨大的开销,这就要求数据中心网络的通信语义从字节流演进到包括消息语义、同步和异步远端内存访问、RPC 在内的内存语义,软硬结合实现极致的时延和带宽。未来,我们期望把数据中心作为一台计算机,一方面实现异构计算、存储设备间的对等直通,让数据中心互联像主机内部总线一样高性能;另一方面通过 Serverless 让分布式系统编程像单机编程一样便捷。
大规模直播和短视频点播、实时音视频通信等应用对广域网传输的稳定性提出了新挑战。互联网巨头纷纷自建全球加速网络,并设计 QUIC 等新型传输协议,实现优质用户体验。此外,由于我国西部能源成本低,东数西算成为国家战略,通过 Regionless 调度,实现 “全国一体化大数据中心”。
手机、PC、穿戴设备、智能家居、智能车等智能终端的无缝协同、5G to B 等工业互联网应用都需要稳定的低时延和高带宽,这需要无线协议栈优化,甚至无线内存语义以支持 Gbps 级别的带宽。此外,通过鸿蒙的 “分布式超级终端” 编程框架,可以使能更紧密的分布式协同,实现数据和服务无缝流转。
Download Slides PDF (2022-12-15 更新)
Download Slides PPTX (2022-12-15 更新)
演讲全文:
- 第一篇:计算机网络的新黄金时代(一):数据中心
- 第二篇:计算机网络的新黄金时代(二):广域网
- 第三篇:计算机网络的新黄金时代(三):无线网络