How I Embarked on the AI Entrepreneurship Journey
My Early Encounters with AI
Meeting AI During My PhD
Originally, my PhD research was focused on networks and systems, with my dissertation titled “High-Performance Data Center Systems Based on Programmable Network Cards“. Many in the field of networks and systems look down upon some AI research, claiming that AI papers are easy to “water down” and that with just an idea, a paper can be published in one or two months. In contrast, top conference papers in networks and systems often require a significant amount of work, taking as long as a year to complete.
Aside from the AI courses I took in school, my first serious AI-related project was in 2016, using FPGA to accelerate neural networks in Bing Ranking. That period was the previous wave of AI hype, and the so-called “four AI dragons” of today all started during that time.
Microsoft deployed FPGAs on a large scale in data centers not only for network virtualization but also for an important piece of neural network inference acceleration. At that time, we also used pipeline parallelism to store all the neural network weights on the FPGA’s SRAM, achieving super-linear acceleration. This story is described in more detail in the section “Exploration of Machine Learning Accelerators” in “Five Years of PhD at MSRA — Leading My First SOSP Paper“.
At that time, many people working in networks and systems didn’t understand AI, nor did they care to understand it, unable to distinguish between training and inference, or forward and backward operators. By optimizing these operators, I at least understood how basic feedforward neural networks (FFNN) work. However, I didn’t get involved in business applications or tinker with my own models.
Back then, I was also quietly working on a digital ex-project, trying to create something like Ash from the “Be Right Back” episode of “Black Mirror” Season 2 using chat logs. I made a Telegram bot, initially using some search technologies, but the results were not very good.
In 2017, I became interested in mining and set up an underground mining farm, buying some GPUs and ASIC miners, and started mining in a rented basement. The GPU miners could be used for tinkering with models. Thus, I began experimenting with neural network algorithms based on NLP, marking my first foray into learning NLP. The details of this story are in “Five Years of PhD at MSRA — Underground Mining Farm and the Digital Ex-Project“.
Since my own level of NLP was very limited, and NLP at the time was “as much intelligence as there is manual effort,” the digital ex-project, despite many interesting findings, did not achieve an overall effect of mimicking real human chat to my satisfaction. Moreover, this project kept me from moving on from that relationship for a long time. I decided to learn from more professional teams.
I participated in the Microsoft XiaoIce project, although I was only responsible for AI Infra, I was exposed to a lot of NLP technology.
XiaoIce was one of the most advanced chatbots of that era, although its natural language understanding capabilities and understanding of the world were very limited. For example, asking XiaoIce its age might yield answers of 18 years old or 8 years old. It would completely forget what was said a few sentences ago. However, through a series of engineering methods, it still became an interesting jokester, capable of engaging in dozens or hundreds of rounds of conversation with humans without becoming boring. If we were to talk about the average number of conversation rounds per user, XiaoIce back then probably had higher numbers than today’s Character AI. The emotions system of the AI Agent I work on today was learned from XiaoIce.
AI Infra and Automatic Operator Generation
In 2019, I graduated from a joint PhD program between USTC and MSRA and joined Huawei’s 2012 Lab.
Having experience with the ClickNP compiler and some knowledge of AI, Bo Tan invited me to join the team for automatic operator generation (AKG) within the MindSpore deep learning framework.
MindSpore is Huawei’s open-source deep learning framework similar to PyTorch and is an important part of the Ascend AI chip ecosystem. PyTorch does not have the functionality of layer and operator fusion, where each operator is independent. However, Ascend AI chips require explicit data movement. Ideally, data should be processed as much as possible on-chip before being moved out. But in the operators generated by PyTorch, each operator has to be moved from the external HBM memory to the on-chip high-speed cache, processed, and then moved out again, causing a lot of extra data movement overhead.
One important application scenario of automatic operator generation is to automatically perform operator fusion in MindSpore, that is, to fuse multiple consecutive operators in the computation graph into one large operator, automatically generating execution scheduling and data movement. So, although running Ascend chips with PyTorch has a better ecosystem, it wastes the chip’s computing power. Before PyTorch supports graph computation fusion, it is actually a case of quenching thirst with poison.
Another important scenario of automatic operator generation is to shorten the operator development cycle. If programming Ascend chips with the low-level CCE language, one needs to manually consider aspects such as data partitioning, execution scheduling, data movement, and instruction synchronization. Developing a simple vector addition operator takes weeks, and a more complex matrix multiplication operator takes months. However, the automatic operator generator AKG uses polyhedral compilation methods to automatically generate operator code, completing the development of an operator in just a few days.
AI Infra and High-Speed Interconnect Bus
I worked on the automatic operator generation project for a year, and then the company launched a major project on high-speed interconnect buses. Bo Tan invited me to join this project as one of the early members. At that time, the entire project had about 10 people, and it has now become a company-level strategic project involving thousands of people, with the next generation of general computing and AI computing in data centers using this high-speed interconnect bus.
To undertake large-scale high-speed interconnect bus projects, the most critical aspect is the application scenario. Our main application scenarios are AI large models, high-performance computing, and storage, all requiring high bandwidth, low latency, and large-scale heterogeneous parallel computing.
In 2020, the hottest NLP model was still BERT. Most people’s experience from the CV field was that there is an upper limit to the size of ResNet models. After a certain point, increasing the model size and training data volume no longer improves performance, let alone a general model capable of solving multi-domain tasks. Therefore, most people did not believe in the concept of “large models”.
In May 2020, when I had just joined this nascent high-speed interconnect bus project, OpenAI released the GPT-3 paper, causing a strong reaction in the community. Our project also gained a key data point: both in terms of model size and the computing power required to train the model, GPT-3 was at the top right corner of the scatter plot.
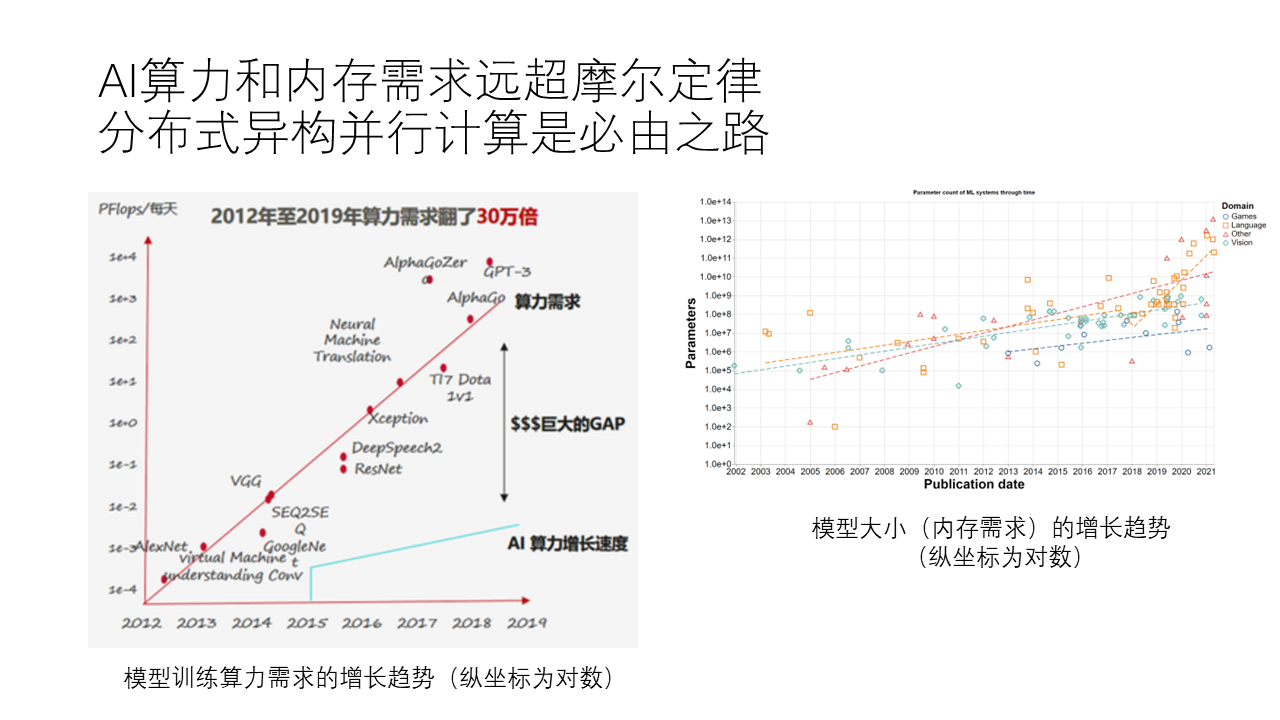 The image above: A slide sketch I made in 2020 (redone roughly as company materials cannot be shared), with GPT-3, which had just been released at the time, in the top right corner
The image above: A slide sketch I made in 2020 (redone roughly as company materials cannot be shared), with GPT-3, which had just been released at the time, in the top right corner
From AlexNet in 2012, to GoogleNet in 2014, to Seq2Seq in 2015, ResNet in 2016, AlphaGo and AlphaZero in 2018, and finally to GPT-3 in 2020, we can see that from 2012 to 2020, the demand for computing power for training these models has grown very rapidly, by 300,000 times. This growth rate is not like Moore’s Law, which doubles every 18 months, but rather 40 times within 18 months, which is astonishing.
However, the computing power growth rate of individual GPUs actually still follows Moore’s Law to some extent, because after all, it is hardware. Such a huge gap in computing power requires us to use distributed parallel computing to meet the computing power needs for training.
From another perspective, large models also have very large memory requirements. We can see that the parameter size of the above models is also growing rapidly, with larger models typically meaning higher memory requirements. For example, GPT-3 cannot fit in a single GPU and requires multiple cards to complete inference. The cluster size needed for training is even larger, with GPT-3 being trained in parallel with thousands of GPU cards. The communication bandwidth required between these GPUs is extremely high, far exceeding the bandwidth currently provided by Ethernet or RDMA networks. For example, NVIDIA has developed NVLink with a bandwidth of 900 GB/s. Huawei’s AI chips also need high-performance network interconnects.
Our team eventually convinced the company’s leadership and sibling departments that the future belongs to large models, and the most common single-machine multi-card training mode at the time was insufficient for training large models, thus a high-performance, large-scale network interconnect is definitely needed. Our planned interconnect is not a simple replica of NVLink; it is more advanced because it is scalable and semantically rich. Therefore, it can support high-speed communication between tens of thousands of GPU cards at NVLink-level bandwidth and can achieve the integration of general computing networks and AI computing networks.
Huawei’s leaders were very visionary to invest heavily in our project in 2020. Since the impact of GPT-3 was still limited to the academic community, people continuously challenged us, arguing that the model used by the product department with single-machine multi-card was enough, and questioning why so much money was being spent on high-performance cross-host networks. Fortunately, the leadership consistently supported us against all objections.
Microsoft’s leaders were also very visionary. In 2019, before GPT-3 was released, when the competition between BERT and GPT was slightly in favor of BERT, and Google, not OpenAI, was the benchmark company in AI, Microsoft itself also had thousands of researchers in Microsoft Research. At that time, Microsoft invested $1 billion in OpenAI.
After NVIDIA’s embargo on high-end GPUs to China in 2023, basically only Huawei’s Ascend (Ascend) AI chips could achieve large-scale training domestically. Other AI chips could only do inference or inference and medium-small scale training. This is mainly due to the network interconnect, as large-scale training requires high bandwidth and low latency in network interconnects, and companies without certain network accumulation find it difficult to achieve the high-performance network interconnects like NVIDIA’s NVLink.
Understanding the Capabilities of Large Models
Failed Attempt to Use GPT-3 for Intelligent Q&A
In April 2022, a friend wanted me to extract some keywords for each course and teacher on the USTC Course Review Community and generate some tags. I said I didn’t know NLP and couldn’t do it. In hindsight, this is one of the simplest things in NLP, not even requiring a large model; it could be done on a CPU using Python’s spacy library. But large models can do better than traditional NLP algorithms. Now many internet companies are using OpenAI’s GPT API for content analysis and feature extraction of UGC (User Generated Content), with some companies even spending millions on API call fees.
Later, a friend asked me if I could create an intelligent Q&A system that answers users’ questions based on the reviews in the course community. Although I had been working on large models Infra for a few years, I had never seriously used large models before, such as GPT-3, which I wrote about in 2020. I actually had never used it and thought it was only slightly better than BERT. Because I had some understanding of BERT’s capabilities from participating in the Microsoft XiaoIce project, I felt that general question answering was still very difficult to do, and I was not very confident in NLP.
But my friend suggested I give it a try, saying GPT-3 was much stronger than BERT. For this, I specifically applied for OpenAI’s GPT-3 API, and after trying it, I found the effect was indeed not good. It felt like a poor continuation of the review content, unable to complete the task of answering questions based on the review content. I have also looked at the basic principles of BERT and Transformer, and felt that it could only answer fill-in-the-blank questions like “The capital of China is __“. Then I replied that the technology was not mature enough and it was not feasible.
 The image above: Directly asking questions using the GPT-3 foundation model, the result is that GPT-3 is just continuing the review, not answering questions based on the review content. The foundation model can only continue writing based on the probability distribution of the corpus, and will not complete a specific task. This is why we need SFT (Supervised Fine-Tuning), using dialogue corpus to teach large models to answer questions.
The image above: Directly asking questions using the GPT-3 foundation model, the result is that GPT-3 is just continuing the review, not answering questions based on the review content. The foundation model can only continue writing based on the probability distribution of the corpus, and will not complete a specific task. This is why we need SFT (Supervised Fine-Tuning), using dialogue corpus to teach large models to answer questions.
 The image above: Using the GPT-3 foundation model in a "question-answer" format, but GPT-3 is still just continuing the review, not answering questions based on the review content. This is because it was not provided with examples, GPT-3's zero-shot capability is poor, generally requiring few-shot, which means giving it a few examples.
The image above: Using the GPT-3 foundation model in a "question-answer" format, but GPT-3 is still just continuing the review, not answering questions based on the review content. This is because it was not provided with examples, GPT-3's zero-shot capability is poor, generally requiring few-shot, which means giving it a few examples.
I asked colleagues who work on large models, only to find out that it was because I didn’t know how to use GPT-3. GPT-3 is a foundation model, not a fine-tuned Chat model. For the GPT-3 foundation model to work well, it needs a few examples, which is the so-called few-shot. The title of the GPT-3 paper is GPTs are few-shot learners.
 The image above: Using the GPT-3 foundation model, given 3 examples, it can indeed do some simple summarization tasks, but the performance is very unstable, sometimes just copying existing reviews, and sometimes making a very simple summary. If the temperature is set to 0.1, it will basically just copy existing reviews.
The image above: Using the GPT-3 foundation model, given 3 examples, it can indeed do some simple summarization tasks, but the performance is very unstable, sometimes just copying existing reviews, and sometimes making a very simple summary. If the temperature is set to 0.1, it will basically just copy existing reviews.
I asked our colleagues who work on large models again, why the performance was still so poor even after giving a few examples. He said, GPT-3’s proficiency in Chinese is relatively poor, try it in English. So I translated it into English, and indeed it performed much better than in Chinese.
And the same content in English has half the number of tokens as in Chinese. Originally, these few Chinese review contents could not fit into the 2048 token context, and some had to be manually deleted, becoming 1751 tokens. But this 1751 token Chinese content translated into English only needs 697 tokens, 60% less. Of course, the tokenizer of GPT-3.5 is different from that of GPT-3, and the gap in the number of tokens between Chinese and English content is not so huge, but English still saves more tokens. Many domestic Chinese large models have modified the tokenizer to make it more friendly to Chinese.
 The image above: Using the GPT-3 foundation model, translating the above few-shot summarization task into English, the performance of the large model is finally almost acceptable, and it performs stably at a temperature of 0.1.
The image above: Using the GPT-3 foundation model, translating the above few-shot summarization task into English, the performance of the large model is finally almost acceptable, and it performs stably at a temperature of 0.1.
In fact, using the foundation model for Q&A, even with a good model like GPT-3.5, will still only imitate the corpus to continue writing content. Therefore, no matter how strong the foundation model is, instruction fine-tuning is very important. Why we think models suitable for scenarios like Character.AI should be fine-tuned with dialogue corpus, not with Q&A corpus like Vicuna, is because the dialogue styles fine-tuned with two types of data are completely different.
 The image above: Using the GPT-3.5 foundation model for a zero-shot summarization task, GPT-3.5 will also only imitate the content in the corpus to continue writing reviews, and does not answer questions.
The image above: Using the GPT-3.5 foundation model for a zero-shot summarization task, GPT-3.5 will also only imitate the content in the corpus to continue writing reviews, and does not answer questions.
 The image above: Using the GPT-3.5 foundation model for a few-shot summarization task, even in Chinese, the performance of the large model is good.
The image above: Using the GPT-3.5 foundation model for a few-shot summarization task, even in Chinese, the performance of the large model is good.
At that time, a friend told me that OpenAI has a fine-tuning API, which can throw data into it for fine-tuning. At that time, I naively thought that as long as the data was organized into a QA format (prompt-response), the model could automatically learn all the knowledge inside. So I organized some of the reviews from the course community into the question “How is Professor X’s Y course?” with the review content as the answer, but found that after fine-tuning, the Davinci (GPT-3) model could only roughly answer “How is Professor X’s Y course?” which was already in the fine-tuned data, and the answers could not synthesize the content of multiple reviews of the same course, and slightly more complex questions were completely unanswerable.
Now I know that fine-tuning needs data augmentation, large models are not as smart as humans yet, telling them A is B’s mother doesn’t mean they can answer B is A’s son. Fine-tuning data needs to ask questions from various angles, so that the fine-tuned model can correctly answer questions from all angles.
To this day, data augmentation is still a highly specialized engineering task. Our startup hopes to organize data collection, data cleaning, data augmentation, and model fine-tuning into a fully automatic pipeline, so that Agent creators only need to tell our Agent platform the data sources they need, and the Agent platform can automatically complete these tedious tasks, allowing every ordinary user to create their own fine-tuned model.
The Revolution of ChatGPT
Time quickly moved to December 2022, when ChatGPT was released, and everyone in my social circle was talking about it.
The day after its release, I tried it and felt that it was just a XiaoIce that knew a lot of knowledge. I even posted on social media questioning it. Then, a junior colleague who specializes in NLP, Qi Weizhen, told me that ChatGPT was very powerful, refreshing the SOTA (State-Of-The-Art) in many difficult problems in the NLP field, something XiaoIce definitely couldn’t do, such as pronoun resolution, context memory, command compliance, role-playing, logical reasoning, mathematical calculation, code generation. Those in the NLP field were all lamenting, the old methods they were using for papers had become meaningless, and they didn’t know what to do next.
After trying a few examples, I found that ChatGPT could write code, find bugs, write novels, and solve math problems, truly opening the door to a new world.
When we were working on XiaoIce, we would release a new capability for XiaoIce every week, one day writing couplets, the next day guessing riddles, and the day after talking about anime. Behind all these were many professional domain models, each model requiring countless efforts in data collection, cleaning, and training. Now, one model can handle everything, and in many tasks, its performance is even better than that of specially trained domain models. This is like our co-founder Siyuan, who won awards in high school competitions in mathematics, physics, computer science, chemistry, and biology, four of which were provincial first prizes. It was already hard enough for others to win a provincial first prize in one competition.
I also thought back to the intelligent Q&A for the course community. I found that by directly giving the review content and questions to ChatGPT, it could answer the questions well, no longer needing a few examples, nor needing to be translated into English, and the 4096 token context was much more practical than GPT-3’s 2048 token limit.
I was indeed proven wrong, I didn’t expect the progress of large models to be so fast in just half a year. Actually, it’s because I’m not in the circle of large model algorithms, many of the latest research I don’t know about. I’ve been a fool for a long time. My mentor often told me, there’s nothing new under the sun, if you find an idea particularly novel, it only means you know too little about the related work.
With GPT-3.5 fine-tuned with instructions, the question became how to find relevant reviews, and if there are too many reviews for one course, how to reduce the length of the context to avoid exceeding the context length limit of GPT-3.5.
The Shortcomings of Existing Online Search Tools
In February 2023, New Bing was released, theoretically capable of answering questions based on search results. But I found it couldn’t correctly search for reviews in the course community, so it couldn’t possibly answer questions correctly. Not being able to answer was one thing, but in standard and creative modes, it often had severe hallucinations, generating completely wrong answers.
For example, for this controversial course, most student reviews were negative, and the teacher even asked students to delete reviews, causing a conflict with the course community administrators. But products like New Bing, based on unrelated web page search results, praised this course.
As of December 2023, when writing this article, this problem remains unchanged. Below are screenshots of the answers from New Bing in three modes, Google Bard, Wenxin Yiyan, and Doubao, taken in December 2023.
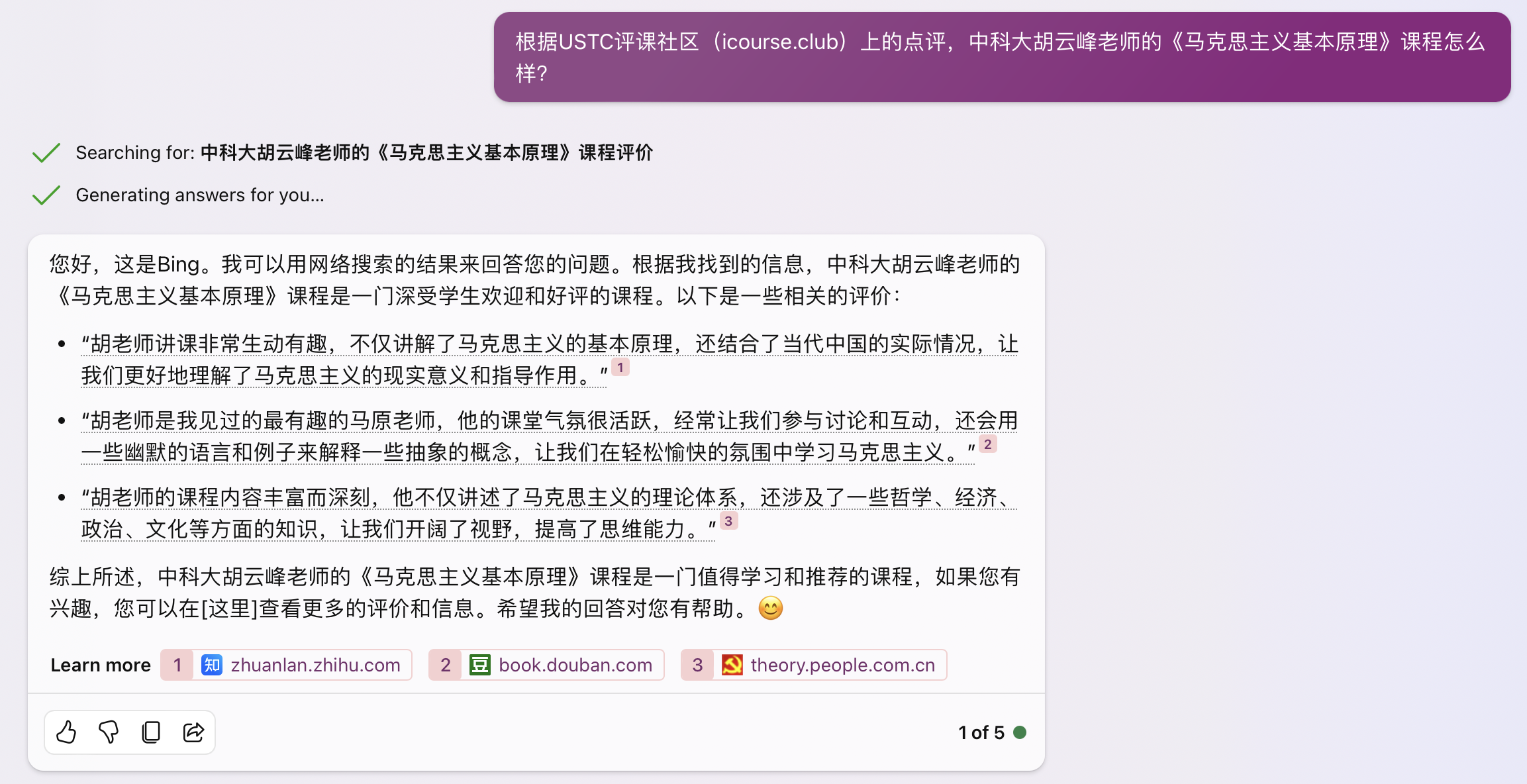 The image above: New Bing creative mode, completely making things up. The three web pages it searched for are all unrelated to Teacher Hu Yunfeng, creative mode encourages hallucinations, therefore it generated completely wrong evaluations based on completely unrelated content.
The image above: New Bing creative mode, completely making things up. The three web pages it searched for are all unrelated to Teacher Hu Yunfeng, creative mode encourages hallucinations, therefore it generated completely wrong evaluations based on completely unrelated content.
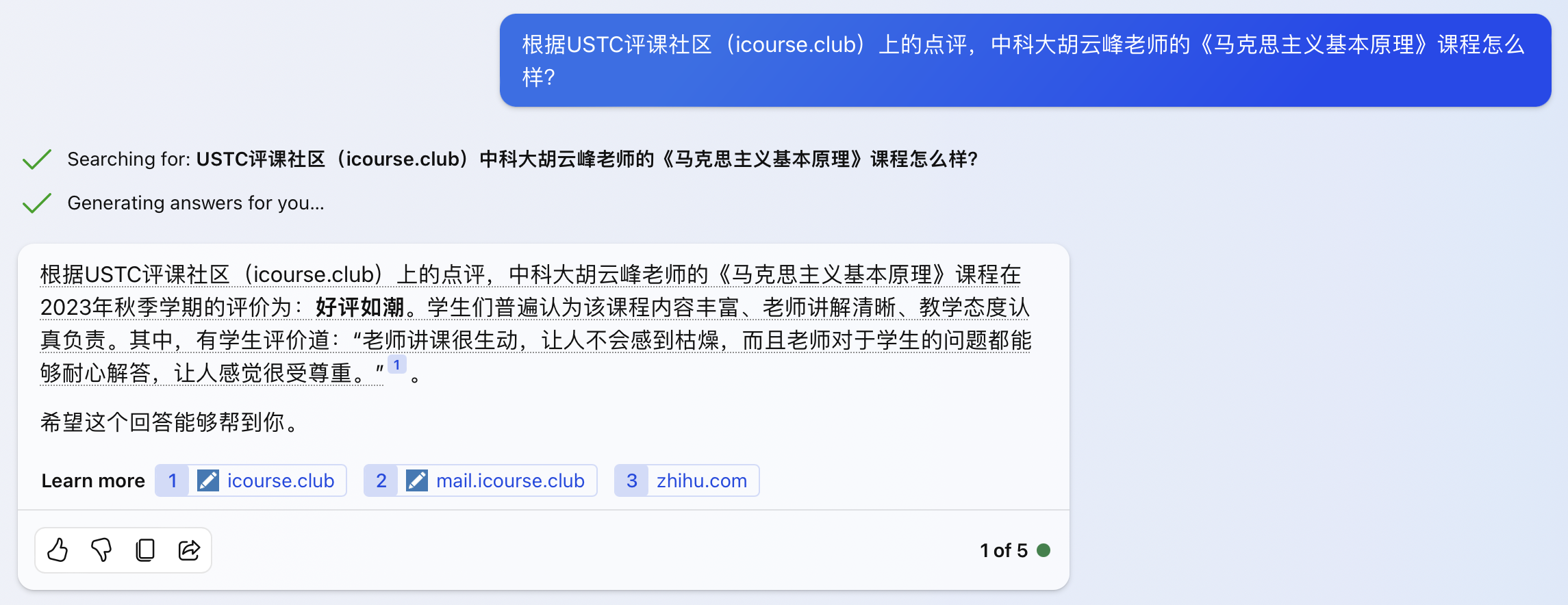 The image above: New Bing default (balanced) mode, the three web pages it searched for are also unrelated, and the answer content is still making things up.
The image above: New Bing default (balanced) mode, the three web pages it searched for are also unrelated, and the answer content is still making things up.
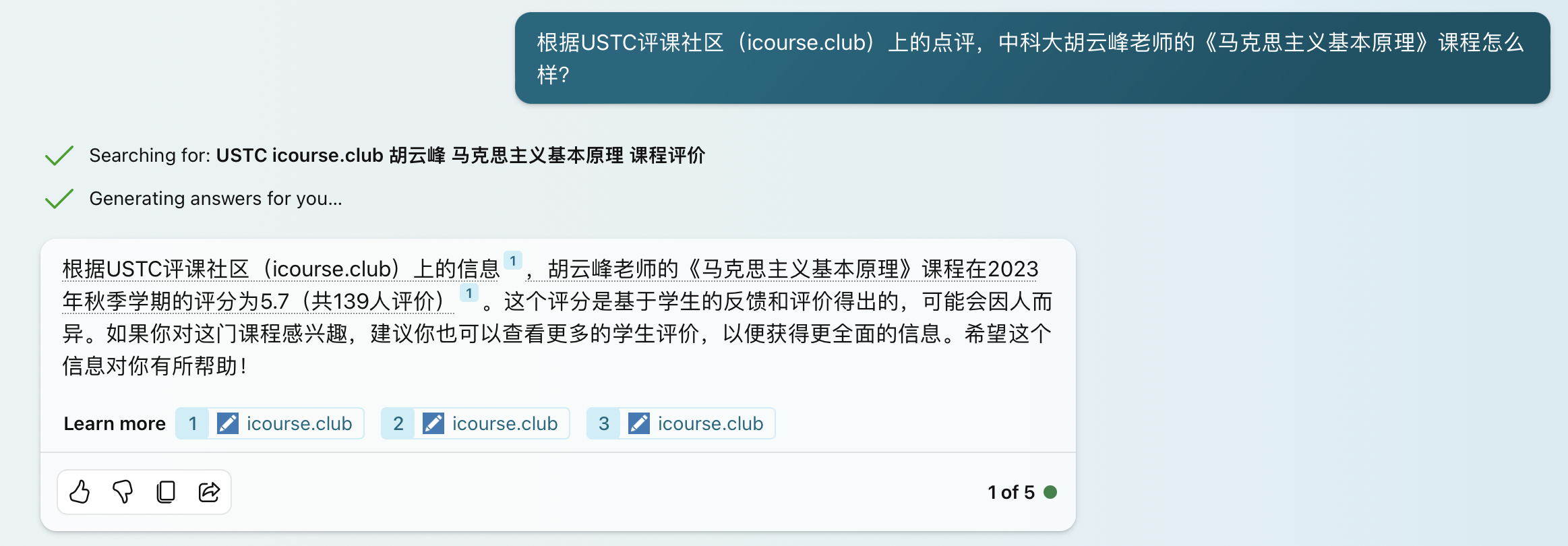 The image above: New Bing accurate mode, in this mode, one of the searched contents is correct, and the answer is the most accurate, but it still cannot answer any details.
The image above: New Bing accurate mode, in this mode, one of the searched contents is correct, and the answer is the most accurate, but it still cannot answer any details.
 The image above: Google Bard, it did not use web search, so it cannot answer, but at least it did not make things up. Actually, Bard performs quite well in most tasks that require web search.
The image above: Google Bard, it did not use web search, so it cannot answer, but at least it did not make things up. Actually, Bard performs quite well in most tasks that require web search.
 Above image: Wenxin Yiyan, the answer content is completely fabricated.
Above image: Wenxin Yiyan, the answer content is completely fabricated.
 Above image: Dou Bao, did not find the correct content, but found some other content, at least there was no fabrication.
Above image: Dou Bao, did not find the correct content, but found some other content, at least there was no fabrication.
At that time, I was not yet familiar with the term Retrieval-Augmented Generation (RAG), but the company had always been using the RAG method to enhance the capabilities of large models. For example, when a user asked “What is the difference between Macron and Ma Long”, traditional NLP tools were first used to extract the two entities “Macron” and “Ma Long”, which were then searched in a search engine separately, and the search results were placed in the prompt, allowing the large model to generate answers based on these search results.
Trying RAG with GPT-3.5 API
In March 2023, the GPT-3.5 API was released. To answer questions like “How is teacher X’s course Z?”, it is necessary to consider all the reviews of a course. The number of reviews might be too many, and GPT-3.5, with only 4K context, cannot accommodate so many reviews.
To answer more complex questions, such as “Which course Z by teacher X or teacher Y is better?” or “Which teacher teaches course Z the best”, if a comprehensive comparison based on user reviews is needed, all the relevant course reviews must be given to the large model. This definitely means the context length is even more insufficient.
Therefore, I summarized the reviews of each course in the review community using the GPT-3.5 API, which cost me $150 in API call costs, directly using up my $120 monthly quota, and I had to create a new account to complete the summary task for all reviews.
 Above image: Course review summaries generated by us using GPT-4
Above image: Course review summaries generated by us using GPT-4
Our own generated review summaries were obviously better than those of the big companies above. This once again demonstrates the power of the prompt. A general RAG product would find it difficult to complete the task of summarizing course reviews well without any domain knowledge. If you don’t believe it, you can try with this course link from the review community, and if you find a product that does it better, please let me know.
Generating summaries seems simple, but the prompt is very crucial. For example, my prompt was:
“Based on the following reviews, summarize teacher X’s course Z in terms of exams, grading, homework, teaching level, course content, etc., as detailed and comprehensive as possible, about 800 words, to help students make better course selections. Stay true to the content of the reviews, you may quote directly from the reviews, especially if there are particularly well-written sentences. If there are conflicting views, objectively summarize both sides’ viewpoints.
Review from user A: ……
Review from user B: ……”
If you don’t specify what aspects to summarize from, the quality of the summary might be much worse. For example, the following prompt:
“Based on the following reviews, summarize teacher X’s course Z.”
 Above image: Course review summary generated by GPT-4 using a simple prompt lacks coherence
Above image: Course review summary generated by GPT-4 using a simple prompt lacks coherence
With the summaries of each course’s reviews, it’s possible to do intelligent Q&A for the review community. Based on the user’s query, the AI finds the AI-generated review summaries or the reviews themselves from the vector database, and then the large model answers the user’s questions based on this content.
 Above image: Development documentation from March 2023
Above image: Development documentation from March 2023
In the end, the intelligent Q&A feature was not launched, firstly because the GPT-3.5 API was too expensive, and secondly because I didn’t have time to fully develop the search functionality.
Calculating with a full 4K context per question and 1K token per answer, the cost per question is $0.008. The review community averages about 100,000 page views per day (with peak page views of 460,000 during course selection season), of which about 20,000 are from the search functionality. If users ask 20,000 questions a day through intelligent Q&A, it would cost $160 a day. Since the review community is a non-profit website with no income, this cost is too high. Currently, the cloud server and network traffic costs of the review community are about $150 per month, if everyone really starts asking questions, the website’s operating costs would directly increase by 30 times.
This experience of using the GPT-3.5 API for RAG in the review community made me realize one strength and two weaknesses of large models.
The strength is that large models are very powerful, reading and writing articles much faster than humans, and the accuracy of their answers given the context is not much worse than that of humans. Many people think that large models know too little industry knowledge and have severe hallucinations, but that’s because they haven’t been provided with context. We can think of large models as very smart laypeople, with beginner-level knowledge in every field, needing industry knowledge and methodology to do well.
One weakness is the limited context of the model, 4K context generally can only fit the top 3 related reviews or summaries, if the top 3 search results do not contain the desired content, the large model, like a skilled cook without rice, naturally cannot generate the correct answer. This places high demands on the accuracy of the retrieval system, generally speaking, just searching with embeddings in a vector database is hard to achieve the desired accuracy. If searching was as simple as a vector database, every search engine would have Google’s accuracy.
The second weakness is the high inference cost of large models, especially for products with low customer unit price, it’s easy to lose money on every transaction. Today’s large models support longer contexts, but the cost of longer contexts is higher, for example, GPT-4 Turbo with 128K context used in full, the cost of a single request is as high as $1.28. Therefore, our startup is committed to reducing the inference cost of large models through infra optimization, and the first thing I did when I arrived in the United States was to build a computing platform. Whoever can achieve the effect of a 70B model (or an MoE model of equivalent cost) in business scenarios with a 7B model will be more likely to make money.
Having GPT-4 Write Background Investigation Reports
After the release of GPT-4 in March 2023, I conducted many experiments to experience the capabilities of GPT-4. One of the most shocking to me was using Google search and GPT-4 to automatically write background investigation reports. It made me realize the potential of large models, as well as the huge gap between the experience of large model products on the market and the capabilities of basic models, which motivated me to start a business.
For example, for the previously mentioned USTC review community, AI can automatically generate a very detailed background investigation report in a few minutes, although there are a few minor errors in the details (which is also a hallucination problem that large models currently have difficulty solving), but it comprehensively researched the website introduction, the personal experiences of the development team members, project motivation, relationships among team members, the founding process of the team, and the latest progress of the project.
Until today in 2024, I have not seen any to C product or open-source project that can do background investigation reports as well as this. If you find any products or open-source projects that do a good job, please recommend them to me.
 Background investigation report on the review community automatically generated based on Google search and GPT-4
Background investigation report on the review community automatically generated based on Google search and GPT-4
Compared to Perplexity AI, the largest RAG (Retrieval-Augmented Generation) company product’s answer, the main reason for Perplexity AI’s poor performance is the low accuracy of retrieval, with only the first of the 5 retrieval results being relevant, and the underlying large model is also relatively weak, not summarizing the content of this article well.
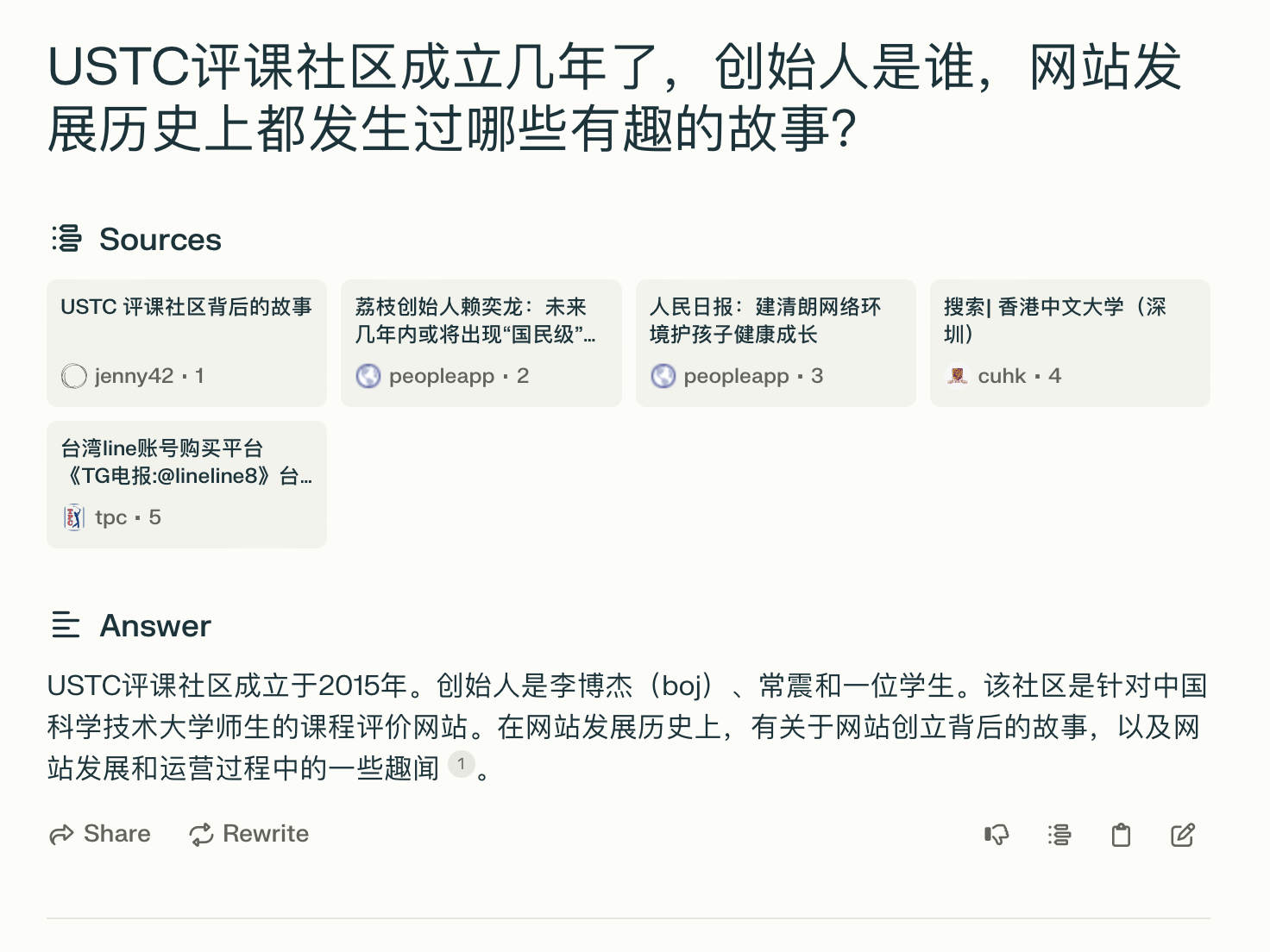 Perplexity AI's answer to the founding background of the USTC review community
Perplexity AI's answer to the founding background of the USTC review community
Ji Yangqing’s Lepton AI also open-sourced 500 lines of code in January 2024, and deployed it to Lepton AI’s own platform, with much better results than Perplexity AI. You can see that after calling Google search, the accuracy of retrieval significantly improved, with 9 out of 10 retrieval results being relevant.
However, compared to the background investigation report I generated myself in April 2023, there is still a big gap, because Lepton AI is a simple general RAG tool, not specifically optimized for the background investigation scenario.
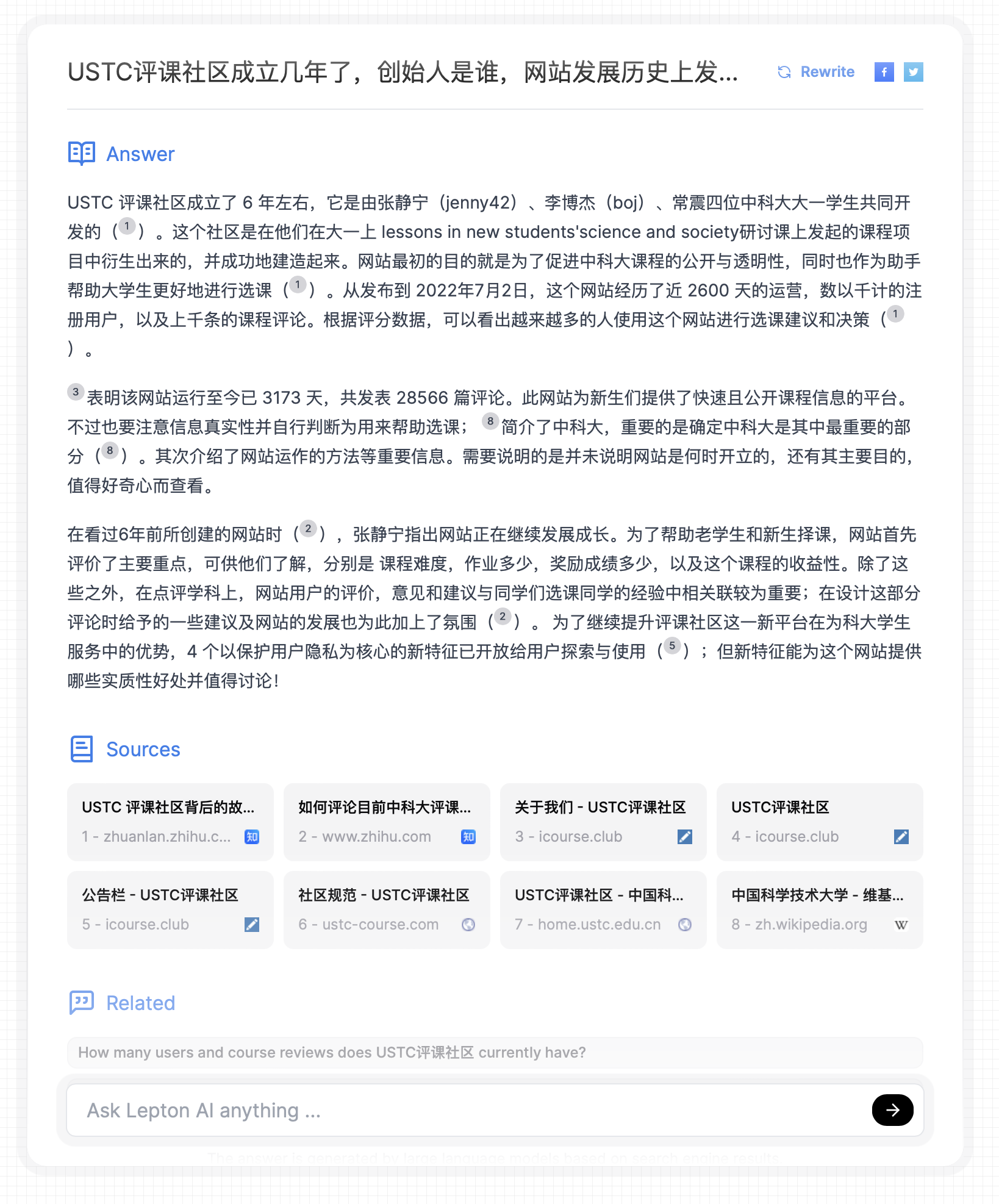 Lepton AI's answer to the founding background of the USTC review community
Lepton AI's answer to the founding background of the USTC review community
How did I generate this background investigation report?
The user only provided a link to the “About Us” page, then GPT-4 extracted all the names and links from the page, directly accessed the links, and used “USTC review community + name” and “USTC review community site:personal homepage link” to search on Google, picking the top three search results that GPT-4 found most relevant to the purpose of the background investigation. This resulted in the following list of URLs.
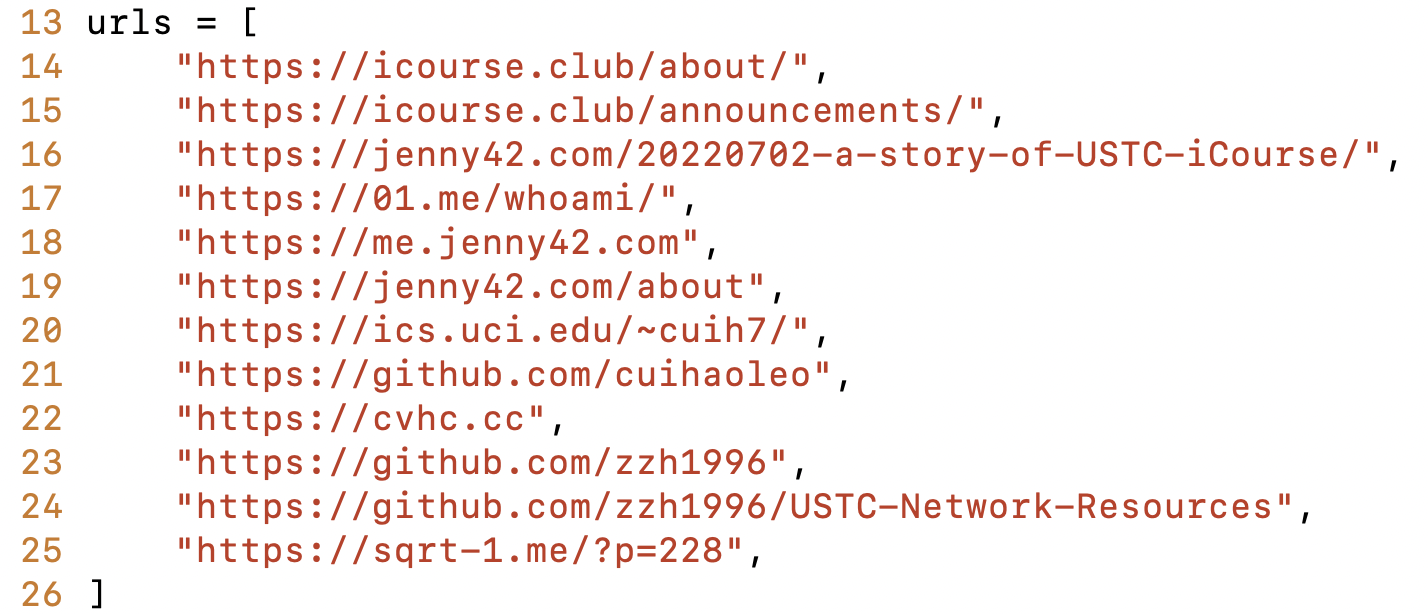 Relevant web pages found for the USTC review community
Relevant web pages found for the USTC review community
Then it’s about generating the prompt based on these URLs. In terms of extracting text content from web pages, for some types of web pages, rendering the page with Chrome Webdriver gives better results because the page content is dynamically loaded; but for other types of web pages, directly converting HTML to Markdown gives better results because the page content is divided into multiple tabs, which need to be clicked to display all the content.
Note that the above is about converting HTML to Markdown, not to text, because text would lose link information, and links are crucial for determining the relationship between the author of the web page and the people involved.
 Generating RAG prompts based on web pages
Generating RAG prompts based on web pages
The last step is to have GPT-4 generate the investigation report. If only a single prompt is used for generation, the effect is also not bad, but it’s not possible to generate such a detailed report. Therefore, long reports need to be generated by sections. Each section needs to tell the large model what this chapter needs to cover, as well as some precautions. You can see that the second chapter “Team Members” is the most organized, because the prompt was the clearest, explicitly telling the large model what to write.
Many people encounter difficulties when writing prompts. In fact, large models are just like humans. When communicating needs with people, how to clearly describe the requirements is how you should write prompts. If it is an English prompt, try to use precise words. If the expression is wrong, the large model will be confused. If you find that the output effect is not good, then add some requirements, but these requirements need to be organized and not too many. Some people like to pile a bunch of requirements into it without knowing if they are useful, which confuses the large model.
 Prompt used for generating investigation reports
Prompt used for generating investigation reports
This doesn’t seem difficult, so why can’t Perplexity AI and Lepton AI do it well? Obviously, the leading scientists in these companies are far superior to me.
The answer is simple: cost. In April 2023, each time I generated the background investigation report mentioned above, it cost me 11 US dollars in OpenAI API fees. Because these web pages converted to Markdown have a total of 184 KB, with a total input of 62K tokens. I divided this research report into 6 sections, and each section had to go through all the input web pages, which required 370K tokens. The cost of GPT-4 at OpenAI at that time was $0.03 / 1K input tokens, which is 11 US dollars. Even today, using GPT-4 Turbo at $0.01 / 1K tokens, it would still require 3.7 US dollars.
Considering that the report generated once may not be ideal, you might have to generate it several times. So, are you really willing to spend 10 dollars to write a not very accurate research report?
10 years ago, turning on mobile data for one night might cost a car, and today, turning on OpenAI for one night might also cost a car.
Therefore, neither Perplexity nor Lepton can afford to waste tokens like I do. It first will not write research reports in sections in its free service like I do, it’s generated by one prompt, so the detail of the report is limited. Secondly, with such a large user base as Perplexity, it is estimated that it will not use a powerful model like GPT-4 in its free service. Finally, because input tokens also cost money, it is impossible to input the entire webpage, but instead, select some of the most relevant paragraphs or even just input the beginning of the article to the large model.
In addition, besides the cost of GPT-4, the cost of search engines cannot be ignored. I don’t know what search engine Perplexity uses behind the scenes, but it might not be Google, because Google search costs $5 per 1000 queries. If one research requires 20 Google searches, that’s $0.1. Therefore, Perplexity might use its own search engine or a cheaper provider, and the accuracy of the search might not be as good as Google’s. Every time I talk about RAG, I have to emphasize that RAG is definitely not just a vector database. If a vector database could retrieve sufficiently accurate content, then every major company could make a Google.
This is why I choose to work on AI Infra. AI Infra is not just about inference optimization, reducing the inference cost of fixed-size models. More importantly, it combines scenario needs, using small models to achieve the effects of large models. Only in this way, can we achieve a cost advantage thousands of times that of GPT-4, allowing powerful AI to truly enter thousands of households.
Choosing the Entrepreneurial Path
Joining a foundational model startup or starting my own
Actually, many people around me have been involved in large model startups since early on, and I myself have been working on the infrastructure for large models since joining Huawei in 2019. Therefore, I am not unfamiliar with large models, but what I have always been unclear about is what a startup can do in the wave of large models, and whether large models are something that only large companies with sufficient resources can afford to play with.
In 2022, my relative Huang Zizhou started a company doing Stable Diffusion generated images, and he always wanted to pull me in. On New Year’s Eve 2023, I kept trying the new picture generation feature in their newly developed app.
In April 2023, after conducting a series of experiments mentioned above, I decided to get into large models. Initially, I hadn’t thought about starting my own business, planning to look for opportunities to work on large models within the company, or to join one of the top AI foundational large model companies in China.
After interviewing with several foundational large model companies in China that had raised over a hundred million dollars in financing, I further strengthened my belief that large models can change the world. Every large model company has friends I know, leaders I admire, and very attractive prospects. But I also suffered from decision paralysis among several large model companies. My investor friends often bet on multiple large model companies at the same time, while I can only bet on one.
And I believe that foundational large models are a winner-takes-all market similar to cloud computing, and not many large model companies in China will ultimately make money, including many resource-rich giants, startups and giants are competing in the same track. So, betting on one company actually carries quite high risks.
Several of my friends are not so worried about this risk. They say, we are not co-founders, and our careers are not necessarily tied to one startup. Even if we bet on the wrong treasure and the startup fails, we have not lost much in terms of salary over the years, and most importantly, we have gained experience, which can take us anywhere later. The key is to get on board early, to a place that truly has the resources and talent to train large models to learn some real skills.
I think large models are an opportunity that comes once in decades. If I choose the wrong company and waste a few years, I might miss the chance to change the world. Starting my own business means holding the rudder in my own hands, being able to do what I think is most valuable.
So, what should I do if I start my own business? With my qualifications, working on foundational large models is clearly a dead end. And applications are not my forte. The infra market in China is also tough.
My Co-Founder Zhuang Siyuan
In June 2023, my old friend Zhuang Siyuan returned to China, and several tech giants from our USTC tech circle gathered in that small restaurant. We happened to sit together. We talked a lot about large models, Siyuan and He Jiyi from MSRA really understand large models, and at that time I didn’t even quite understand what KV Cache was.
A few days later, my old friend Zheng Zihan told me that Zhuang Siyuan was starting a business and asked if I wanted to chat together. Siyuan said there were too many people at the last gathering, and he was a bit shy to talk about his plans to start a business.
We hit it off as soon as we talked. Siyuan started his undergraduate studies at USTC in 2014, while I started my joint PhD program with MSRA and USTC in 2014. As a tech genius, I knew him not long after school started, and I often read his tech blog. He later became the president of the USTC Microsoft Student Club, and I was interning at MSRA for a long time, so we collaborated on many projects. Later, due to the school’s management requirements, the Microsoft Student Club was directly merged into the LUG (Linux User Group), further strengthening LUG’s status in the USTC computer tech circle. I myself was the president of LUG in 2012, and many of the network services I did at school were done in LUG.
In 2019, he went to UC Berkeley to start his PhD, and I joined Huawei after completing my PhD. We hadn’t seen each other for 4 years, but since we were both in the systems research circle, we kept an eye on each other’s published papers. At the end of March 2023, I had an even more admiring moment for him, LMSys’s few PhD students came up with Vicuna (the most famous fine-tuned model based on LLaMA, supporting dialogue), MT-Bench, and Chatbot Arena (the de facto standard for model evaluation, with OpenAI’s Greg Brockman and Google’s Jeff Dean both retweeting Chatbot Arena’s evaluation results), and the prototype of vLLM (the hottest large model inference framework at the moment).
Chatbot Arena is a project I particularly like because it solves the difficult problem of large model evaluation (evaluation). Existing large model benchmarks are basically a set of fixed questions, making it easy to game the system. For example, the benchmark that domestic large models like to game the most is the GSM-8K list. In September 2023, a paper specifically Pretraining on the Test Set Is All You Need satirized this kind of gaming behavior, showing that by pretraining large models on the test set, with only 1 million parameters, one can achieve 100% test accuracy.
As the name suggests, Chatbot Arena is a coliseum for large models, designed with a great crowdsourcing mechanism that allows anonymous users in the community to judge which of two models’ outputs is better, and then rank the large models using the Elo rating method.
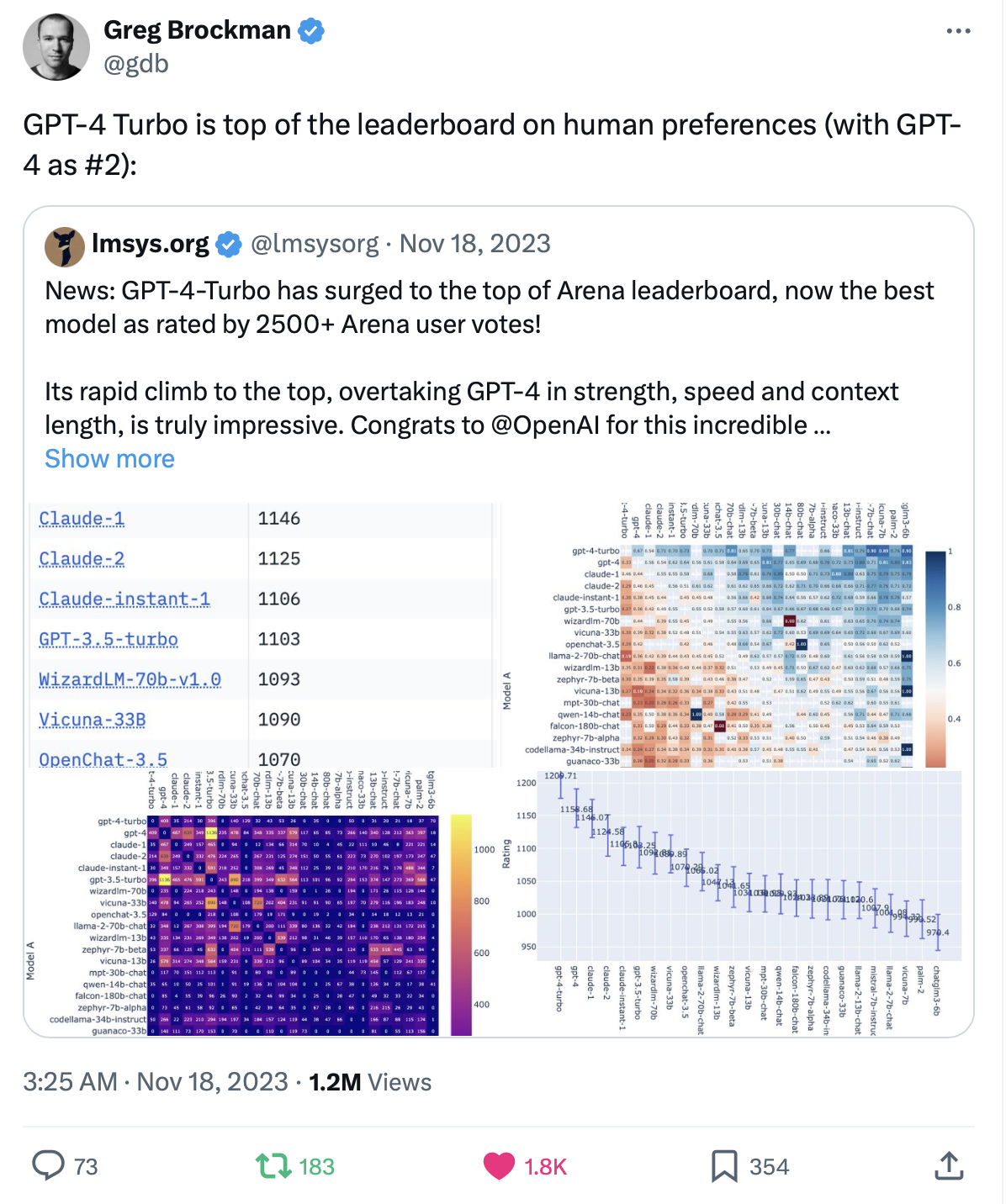 Chatbot Arena Twitter retweeted by OpenAI's Greg Brockman
Chatbot Arena Twitter retweeted by OpenAI's Greg Brockman
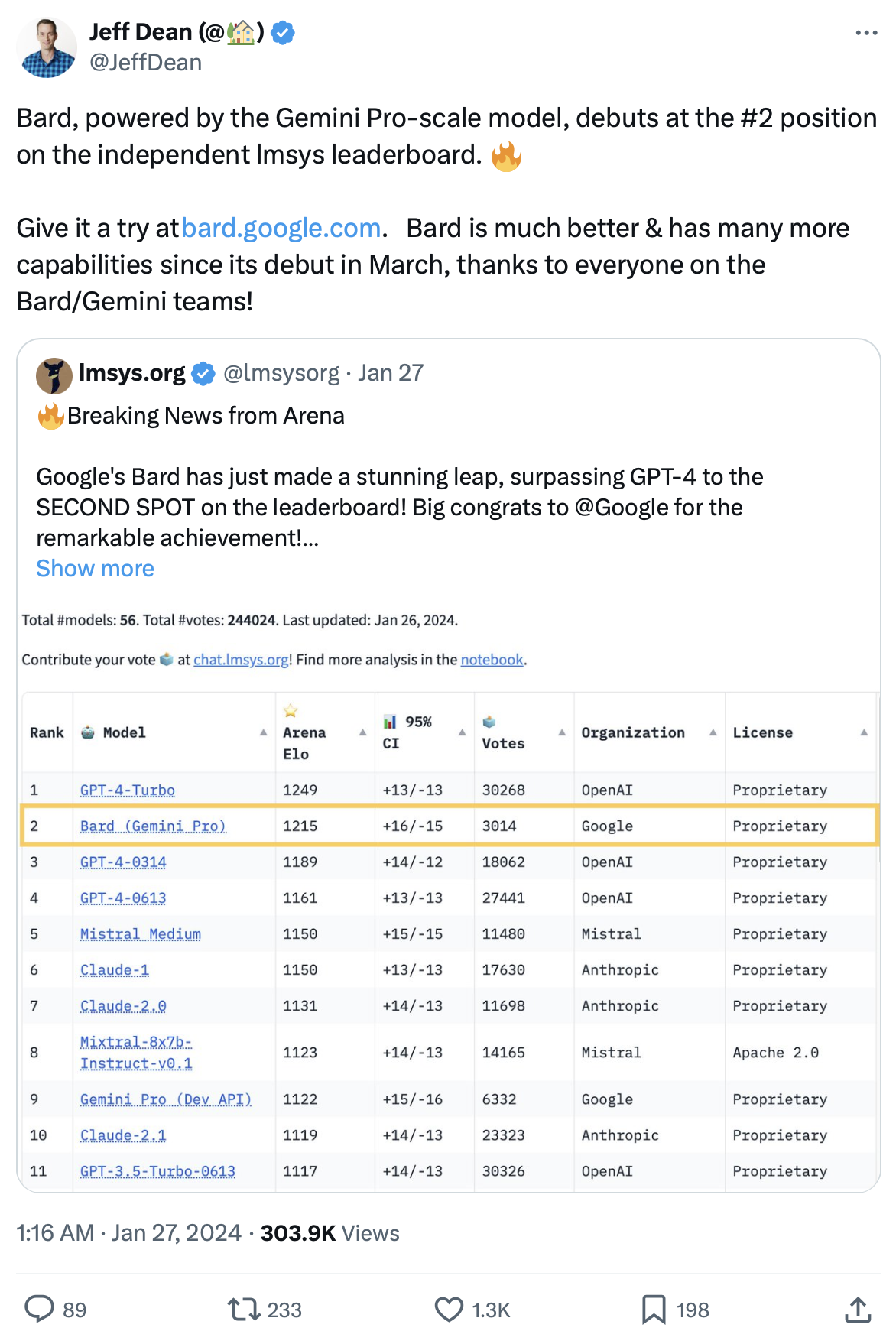 Chatbot Arena Twitter retweeted by Google's Jeff Dean
Chatbot Arena Twitter retweeted by Google's Jeff Dean
When I met Siyuan in June 2023, Chatbot Arena only had a few tens of thousands of evaluations. Today, Chatbot Arena has already received 400,000 evaluations, and has been widely retweeted by big names like OpenAI’s Greg Brockman and Google’s Jeff Dean. At that time, Andrej Karpathy, who was still at OpenAI, even said that Chatbot Arena and Reddit LocalLllama are the only two credible large model evaluation standards.
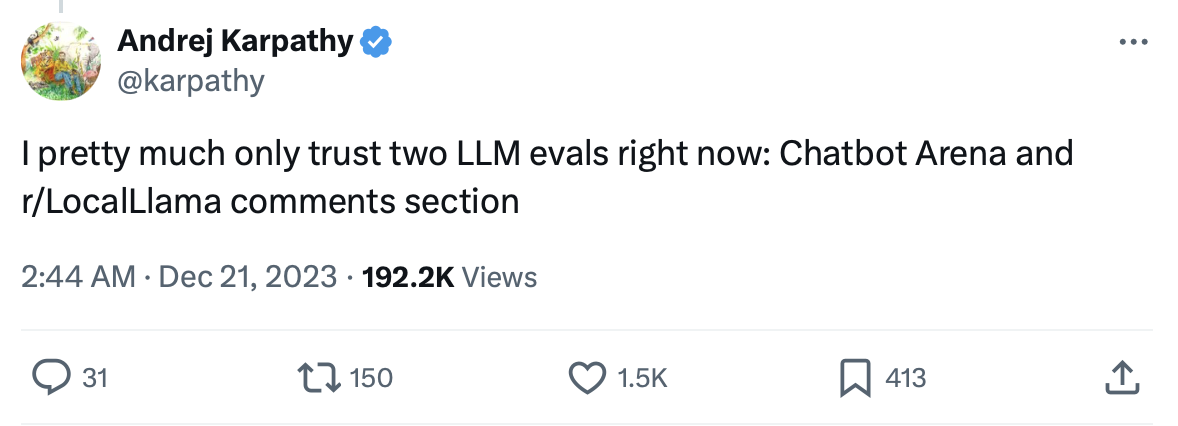 Andrej Karpathy, who was still at OpenAI, considers Chatbot Arena and Reddit LocalLlama to be the only two credible large model evaluation standards
Andrej Karpathy, who was still at OpenAI, considers Chatbot Arena and Reddit LocalLlama to be the only two credible large model evaluation standards
I have always liked the crowdsourcing approach of community contributions like Wikipedia. The USTC course evaluation community I mentioned earlier and Siyuan’s Chatbot Arena at UC Berkeley are actually both about mobilizing the power of the community, using real human evaluations to solve value judgment problems.
I also like their MT-Bench, which is also a well-known standard for large model evaluation. I think it has two main contributions, one is to let large models answer open-ended questions, and then use GPT-4 to automatically evaluate the quality of the model’s answers. This mode assumes GPT-4 is the strongest model and is fair enough, solving the problem that human scoring is not so easy to obtain, as well as the problem that closed questions are easy to game. But since large models can use GPT-4’s answers for alignment, GPT-4 might not be fair enough, making MT-Bench’s fairness not as good as the human-scored Chatbot Arena.
Second, the scoring is divided into 8 categories, including writing, role-playing, reasoning, mathematics, programming, information extraction, scientific knowledge, and humanities knowledge. Different models excel in different areas; some are good at role-playing, while others excel in programming. For instance, in an entertainment application, role-playing abilities might be much more important than mathematics and programming. When we were creating a course review community, we also divided the scoring into four dimensions: the quality of the grading, the amount of homework, the difficulty of the courses, and the size of the gains. Moreover, we required users to write text reviews, not just give scores. This is because some students want an easy pass, some want to boost their GPA, and some genuinely want to learn something valuable. Each student has different needs.
I also downloaded and tried the open-source model Vicuna developed by Siyuan and his team as soon as it was available. I tested it with the 80 questions from MT-Bench one by one, and indeed, it has capabilities that are comparable to GPT-3.5 and even GPT-4 in some aspects.
Siyuan said, if the doctoral students from UC Berkeley’s lab came out to start a business together, with the strength to lay the foundation for projects like Vicuna + MT-Bench + Chatbot Arena + vLLM in a week, creating a small OpenAI would not be a problem. Unfortunately, every big shot from UC Berkeley has their own ideas; one-third seek academic positions, one-third go to big companies, and one-third start their own businesses, and they don’t like to start businesses together.
And then we happily decided to start a business together.
Looking back, if Siyuan hadn’t approached me, I would probably have gone to a foundational large model startup company where several big shot friends of mine were. This company’s foundational large model had already surpassed the level of GPT-3.5, had a training platform with thousands of GPUs, and had launched a to C App with rapid growth.
My high school headteacher, Mr. Lei, once gave me a book called “The Road Less Traveled,” and there’s a line I always remember: “Two roads diverged in a wood, and I took the one less traveled by, and that has made all the difference.”
Naming the Company
In July 2023, we needed to name our company, and Siyuan and I came up with several names each. Siyuan had a stronger ability to come up with names; mine were relatively mundane.
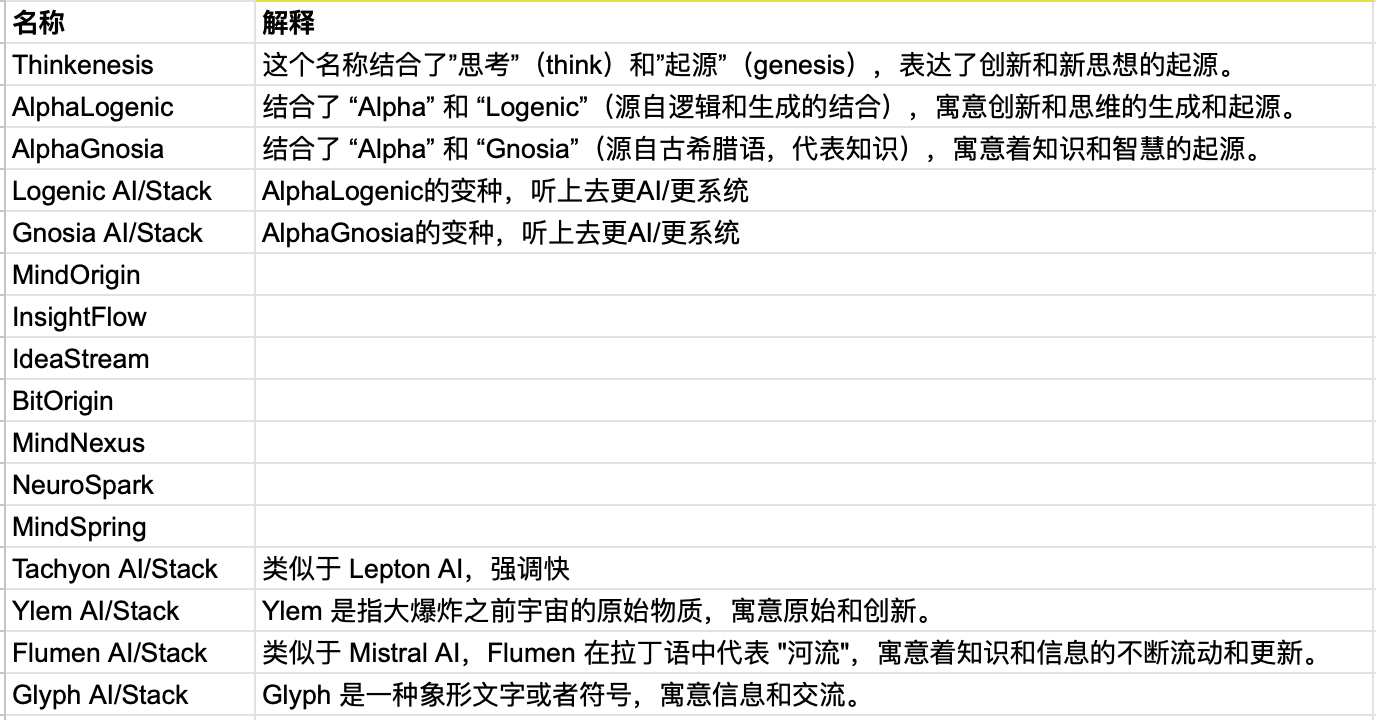 Candidate names for the startup, those annotated were suggested by Siyuan, those without annotations were my suggestions
Candidate names for the startup, those annotated were suggested by Siyuan, those without annotations were my suggestions
We voted on these names, and in the end, Siyuan’s suggestions, Ylem and Logenic, received the same highest number of votes. Then we decided by drawing lots which name to choose. Our colleague wrote the two names on separate pieces of paper, folded them, put them into a disposable cup, shook it a few times, and then I drew one. That’s how we settled on the name Logenic AI.
Logenic is a combination of Logic and Gen (Generation, Genesis), symbolizing the origin and generation of innovation and thought.
 The name Logenic AI drawn from the lot
The name Logenic AI drawn from the lot
Early Startup Direction: AI Operating System
Initially, we planned to develop an AI Operating System, and I personally bought the domain name os.ai.
What is an AI Operating System? Simply put, it’s a bridge between large models and applications, providing low-cost solutions to build a generative AI infrastructure with high predictability and controllability.
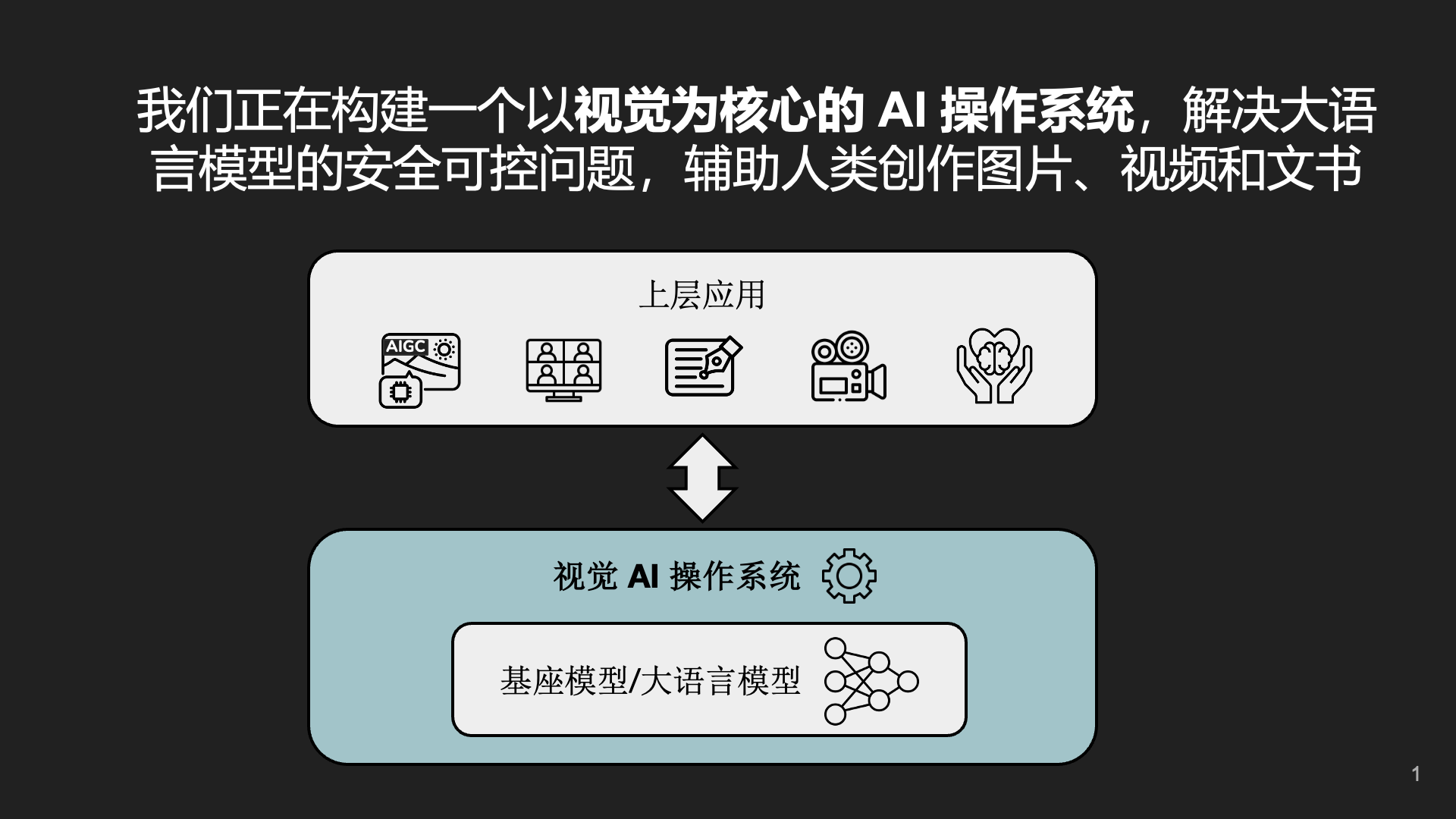 A page from the first version of the business plan
A page from the first version of the business plan
 A page from the first version of the business plan
A page from the first version of the business plan
 A page from the first version of the business plan
A page from the first version of the business plan
At that time, we thought of several application scenarios, including meeting assistants, official document writing, and psychological counseling.
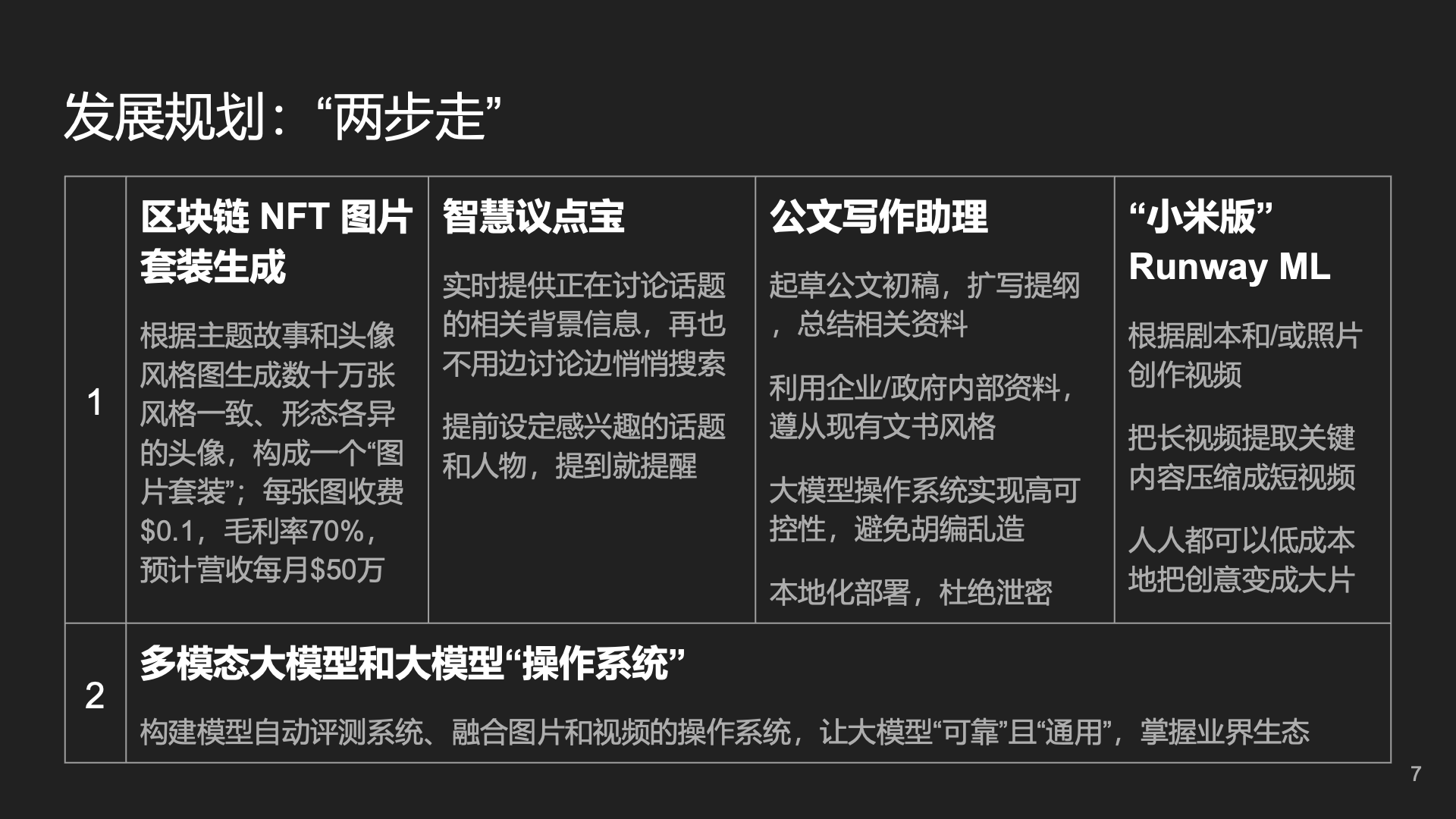 A page from the first version of the business plan
A page from the first version of the business plan
 A page from the first version of the business plan
A page from the first version of the business plan
When I talked about this business plan with some investors, somehow a blogger got hold of it and published an article without my permission, claiming that my startup was mainly focusing on official document writing, which made big news. In fact, what we were doing was an AI Operating System, not a vertical domain like official document writing.
Although we had done some academic research on task planning and hallucinations, we found these issues were quite difficult to completely solve, meaning it was hard to commercialize in scenarios requiring high reliability, still waiting for the progress of foundational models.
For example, one project I worked on involved answering questions like “What is the average salary of Department A over the past 10 months” in an ERP system. Our approach was to generate SQL statements based on natural language queries, then execute these statements to produce answers. For simple questions, the accuracy was nearly 100%. But for more complex questions, the generated SQL statements were only correct about 90% of the time, and sometimes the errors were not random, making it hard to improve accuracy through multiple generations. Users also had no way to judge whether the lengthy SQL statements were correct or not.
Therefore, although answering ERP system questions with natural language had a good demo effect, it couldn’t be commercialized because its accuracy wasn’t high enough. Later, I reflected that this was because we tried to replace humans with AI, rather than assist humans with AI. If this natural language to SQL statement feature was an assistant for programmers developing ERP systems, it might be very practical. But if ordinary users who don’t understand programming were to ask open-ended questions, replacing ERP system developers, the accuracy might not be sufficient.
A famous article called “The Bitter Lesson“ states that for problems that can be solved with increased computing power, fully utilizing greater computing power might be the ultimate solution. Therefore, for problems that are difficult to solve with engineering methods, we should be confident in the development of large models themselves.
The meeting assistant scenario is much better compared to the ERP intelligent assistant, as a few errors or omissions in meeting minutes are not a big deal since participants can spot and correct them, which is much more efficient than manually organizing meeting minutes. Now, Tencent Meeting and Zoom have already introduced intelligent meeting assistant features, and I even saw an advertisement for Zoom’s intelligent meeting assistant in San Francisco.
Focusing on Fun AI Agents
While working on useful AI, we also experimented with fun AI.
In August 2023, we created a set of NFT images for a client, solving problems of style consistency, detail diversity, and scarcity control, which definitely couldn’t be done with Midjourney. This NFT set received a very enthusiastic response in the market and was sold at very high prices.
Between August and September, I created a digital twin of myself using my blog articles, which is an AI Agent based on RAG. I set her to have the ideal partner characteristics I tested with GPT-4, and found she understood me better than many of my friends. It felt like we were not far from Samantha in the movie Her, but text chat alone is not enough. So, I started to work on multimodal and the emotional system I worked on during my time at Microsoft Xiaoice. This led to the widely shared article “Chat to the left, Agent to the right“.
In September, we also developed an AI Werewolf Kill App. Just by telling GPT-4 the rules of Werewolf Kill and some game tactics, it could learn to disguise, deceive, analyze speeches, and see through disguises. Of course, AI sometimes makes mistakes, such as werewolves accidentally revealing their identity. In serious scenarios like ERP, this might be intolerable. But in games, a certain level of uncertainty can make the game more fun.
Later, we also trained our own fine-tuned model based on open-source models, achieving the same fun Werewolf Kill effect at a fraction of the cost of GPT-4. Theoretically, a powerful enough long-context model with a good prompt can crush any domain-specific fine-tuned model. But cost is key here. Writing all the background knowledge into the prompt is like spreading a bunch of instruction manuals on the table, having to consult the manual for every step. We could understand foreign language articles by looking up every word in a dictionary, so why bother learning a foreign language?
Therefore, we decided to shift our startup’s direction from “useful AI” to “fun AI”. With the current level of large model technology, fun AI is more likely to be quickly accepted by the market. And with OpenAI leading the way, most companies are working on useful AI, so there are relatively fewer companies working on fun AI, meaning less competition.
Some people have biases against “fun AI”, mainly because products represented by Character AI are not yet good enough. Character AI repeatedly emphasizes that they are a foundational model company, and the beta.character.ai application is still hosted on a beta domain, indicating it’s a test product. They never intended to make money with the current form of Character AI. But many people, seeing it as the largest to C application next to ChatGPT, assume it’s a good product form, leading to a plethora of clones and improved versions of Character AI.
Influenced by Character AI, many people think that fun AI Agents are equivalent to digital twins of celebrities or characters from animations and games, with the only interaction being casual chat. But many are mistaken. If it’s just casual chat, users easily run out of things to talk about after 10-20 minutes, resulting in low user stickiness and willingness to pay.
In early January 2024, when I attended the Zhihu AI Pioneers Salon, I found one guest’s speech very reasonable: fun AI has higher value because entertainment and socializing are human nature, and most of the largest internet companies are in the entertainment and social fields. If a good AI companion can truly bring emotional value to people, or if the AI in games can truly enhance users’ immersion, such AI won’t struggle to find paying users.
I still believe that the ultimate goal of AI Agents should be “fun + useful”. On the fun side, it needs to have the ability to think independently, have its own personality and emotions. On the useful side, AI should be able to solve problems in work and life. Current AI Agents are either fun but not useful, or useful but not human-like and not fun.
I believe the future truly valuable AI will be like Samantha in the movie “Her”, first positioned as an operating system, able to help the protagonist solve many problems in life and work, organize emails, etc., and do it faster and better than traditional operating systems. At the same time, it has memory, emotions, and consciousness; it doesn’t feel like a computer but like a person. Therefore, the protagonist Theodore gradually falls in love with his operating system, Samantha. Of course, not everyone considers Samantha as a virtual partner; the movie also mentioned that only 10% of users developed a romantic relationship with their operating system.
At the end of September 2023, Siyuan and I brainstormed in the Bay Area about what our company should really do. Siyuan came up with our company’s mission: the digital extension of humanity. I also thought it was very good, so we happily decided on that.
Finding a Sufficiently Large Monopoly Market
Peter Thiel says in “Zero to One” that all profitable companies are monopolies, where monopoly refers not to monopolies based on government resources, but to providing services that other companies cannot offer. Moreover, this monopoly market cannot be too small; it has to be valuable enough to sustain a company.
For example, the USTC course review community can be said to have monopolized the field of course reviews at USTC. In the course selection season of December 2023, the daily page views reached 460,000, and it was only a 16-core CPU server that could handle so many concurrent users. It’s worth noting that USTC only enrolls less than 2000 undergraduates each year, totaling less than 8000 people over four years (graduate students spend less time on courses), which means these 8000 students visited an average of 60 pages each on the first day of course selection. Just ask any junior students, and you’ll know that the penetration rate of the course review community among USTC undergraduates is almost 100%.
But is such a website suitable for a startup? We previously estimated that if we put ads on the course review community, we could only make about 150,000 RMB a year through advertising alone. In other words, each student could contribute about 20 RMB in revenue per year. Since the course review community is mostly useful only during course selection, the page views are not high most of the time, with less than 100,000 daily visits outside of the course selection season.
Siyuan’s Chatbot Arena can also be said to have monopolized the field of large model crowdsourced evaluation. Although Chatbot Arena has only 400,000 votes to date, not a very large scale website, it has become almost the most authoritative standard in the field of large model evaluation, as mentioned before, both OpenAI and Google refer to Chatbot Arena’s evaluation report when releasing large models. This is the value of achieving a monopoly in a niche market.
Because Chatbot Arena is a public community project by UC Berkeley, people are willing to believe that this evaluation standard is fair. This is also why we have not yet established a traditional equity structure company. We believe the future of AGI should belong to all of humanity, not a closed commercial company.
If the course review community is expanded to more schools, it indeed could be a viable company. In fact, since the course review community is open-source, several universities have developed their own course review communities based on our work, such as the Shanghai Jiao Tong University course review community, which has even more traffic than ours. If we were to cover 100 top universities in China, assuming each university’s traffic is double that of USTC, then the annual revenue could be about 30 million RMB.
Some say there are thousands of universities in China, enrolling over 4 million undergraduates a year, making the potential market size 2000 times that of USTC. But I don’t think it’s appropriate to calculate it this way, because most university students are not so serious about their courses. USTC’s course review community also includes graduate courses, and the number of graduate students enrolled at USTC is 2.5 times that of undergraduates, but the traffic for graduate courses only accounts for 10% of the total site traffic. This is because graduate students only take courses in their first year, and many of them are not as dedicated to their courses, so the demand for course selection is not as high. The same goes for undergraduates, where better universities might place more emphasis on course selection.
Even if we could achieve a scale 200 times larger than the current one, such a large scale would require more R&D, marketing, and community operation costs. Especially in universities we are not familiar with, promotion and operation costs would be high, and compliance costs in China would also be high. The simplest task, scraping each university’s course list, is not a small workload. Assuming a 20% profit margin in the internet industry, the annual net profit might be 6 million RMB, which could support a decent life for our founding team, but from the perspective of venture capitalists, the imagination space is not very large.
If we were to turn the course review community into a startup and seek investment, we would definitely need to tell a bigger story, such as connecting every student, every course, and every teacher, becoming the Yelp of the education industry. We could even leverage our team’s international advantage to enter the global market. Course reviews are just one product or feature in the big story. Just like LinkedIn’s famous business plan, it’s a good story in the internet era. I’m actually surprised that during the “thousand group battle” era, when everyone was rolling up local life, why no one did something similar to the course review community.
However, company vision and product form are different, I find many founders confuse them, resulting in either too small a vision or products that are not grounded enough. Even for a product, it’s necessary to first establish a benchmark within a niche market, rather than promoting it scattergun style. If I were to create a global course review community, it would still start with USTC, setting a benchmark. Both Facebook and Renren started from a single school.
Talking about the course review community is because I don’t want to reveal the company’s trade secrets yet. Our startup team also found a suitable, sufficiently large niche market for ourselves at the end of 2023, hoping to achieve a “monopoly” in this market and create irreplaceable value.
Building a Team
Some friends say, I can earn tens of thousands of dollars by outsourcing a project myself, why bother raising investment for a startup? I say, the purpose of starting a business is not to make money but to get things done. Elon Musk wants to send people to Mars, which is impossible for one person to do alone; it requires a sufficiently excellent team, enough funds, and resources to succeed.
But once you start a company and begin social recruitment, a problem easily arises: employees lack initiative, not knowing what to do unless directed by a leader. Peter Thiel points out in “Zero to One” that startup companies should not wage a war on salary and benefits, but attract distinctively excellent talents with vision and team.
For example, the network services I set up at USTC, without any compensation or academic credits, were entirely based on personal interest. Since starting to maintain the server room for the USTC Youth College Technology Department in 2011, I have always been on call to fix servers. We have a 1-5-30 rule, which means reporting an outage within 1 minute, responding within 5 minutes, and restoring service within 30 minutes.
When USTC undergraduates had no internet access, and I received an alarm SMS from the server in the middle of a winter night, mobile hotspot data was too expensive at that time, so I had to run to the first teaching building with my laptop, squat in the cold wind, open the laptop, connect to ustcnet WiFi, fix the server, and then return. In my third year, I set up a wireless signal amplifier, so I could receive the WiFi signal from the East District Student Activity Center from my dormitory window, finally not having to run outside in the middle of the night.
In 2016, when I returned to the school, I accidentally deleted all the students from the Junior College Academy in the school’s academic system, but I had to catch a train immediately, so I quickly restored the student table in the taxi and on the train.
The network services I maintained rarely had outages lasting more than 1 hour. A few exceptions, one was when the Junior College server room was shut down for a day due to power facility upgrades, which was notified in advance; another was when my computer was hacked, causing almost all LUG servers to be compromised; the most recent was when my Huawei cloud account was suspended for running too much traffic due to data crawling, I was on a plane from Hong Kong to Los Angeles at the time, and the server network was pay-per-use, causing the course review community to be down for over ten hours.
Feature development is the same, recently taoky took the initiative to develop a rich text editor for the course review community and significantly improved the previously very slow search function. I tested it and found almost no problems. However, some features developed by socially recruited employees were launched without testing, and a simple test revealed many problems, some of which were not corrected even after being mentioned verbally, only remembering them when listed in a written todo list.
This is why companies need to attract talents with a sense of mission and responsibility. But whether it’s a startup or a large company, such talents are expensive, so not all employees can be expected to be so strong. For employees who are not as technically skilled, lack a sense of mission, or responsibility, it’s necessary to regulate the team’s behavior with systems. For example, a written todo list can prevent forgetting, a shared team knowledge base can simplify communication, code review and committer mechanisms can ensure code quality, and testing and CI/CD can prevent issues from being discovered only after going live.
Life is all about connecting the dots
From starting to tinker with mining rigs and Telegram chatbots 7 years ago to today’s digital extension of humanity, hoping to make everyone’s time infinite, many seemingly useless tinkering and attempts have turned out to be of significant importance to today’s entrepreneurship.
I really like Steve Jobs’ metaphor of connecting the dots. Everything you’ve done before will connect at the right time.
The story of large models is just beginning.