Groq Inference Chips: A Trick of Trading Space for Time
Recently, Groq’s inference chips have made headlines with their large model output speed of 500 tokens/s.
In a nutshell, this chip plays a trick of trading space for time, storing both model weights and intermediate data in SRAM, instead of HBM or DRAM.
This is something I did 8 years ago at Microsoft Asia Research Institute (MSRA), suitable for the neural networks of that time, but really not suitable for today’s large models. Because large models based on Transformers require a lot of memory to store the KV Cache.
Although Groq’s chips have a very fast output speed, due to the limited memory size, the batch size cannot be very large. If we calculate the cost-effectiveness in terms of $/token, it may not be competitive.
Groq needs a cluster of hundreds of cards to run the LLaMA-2 70B model
 Above: Groq inference chip's spec
Above: Groq inference chip's spec
From Groq’s spec, it’s not hard to see that a single Groq chip only has 230 MB of SRAM, with a bandwidth of up to 80 TB/s, without HBM or DRAM. By comparison, the H100 has 96 GB of HBM memory, with a bandwidth of 3.35 TB/s. That is to say, Groq’s memory capacity is only 1/400 of H100’s, but its memory bandwidth is 25 times that of H100’s.
Groq’s int8 computing power reaches up to 750 Tops, and its fp16 computing power reaches up to 188 Tflops. By comparison, the H100’s tensor fp16 computing power is 989 Tflops, which means Groq’s computing power is 1/5 of H100’s.
Groq uses the relatively outdated 14nm process, but also has a 215W TDP, not a small chip, and the chip manufacturing cost is definitely much lower than H100’s, but it’s not possible to be 10 times cheaper than H100.
A LLaMA-2 70B model, even if quantized to int8, still has 70 GB, even without considering the storage of intermediate states, it would require 305 Groq cards to fit.
Groq has not yet announced the price, but if we estimate the price based on the ratio of fp16 computing power to H100, one card would cost $6,000, so this cluster would need $1,800,000. Some might say the cost of this card at TSMC would not exceed $1,000, but I would also say the cost of H100 is only $2,000, and the R&D costs of chips and software ecosystems are also money.
If quantized to int8, without considering the storage of intermediate states, one H100 can fit the LLaMA-2 70B, only needing $30,000. Of course, a single H100’s throughput (tokens/s) cannot beat the aforementioned Groq cluster.
So, which has a better cost-performance ratio, the Groq cluster or the H100? To answer this question, we first need to understand how the large model is split into small pieces to fit into Groq cards.
My Exploration of Spatial Computing at MSRA
In 2016, when I was at Microsoft Asia Research Institute (MSRA), I played this trick of trading space for time, that is, putting both model weights and intermediate states entirely into SRAM. My doctoral memoir article “Five Years of PhD at MSRA (Part 2) Leading My First SOSP Paper“ talks about this story, excerpted as follows.
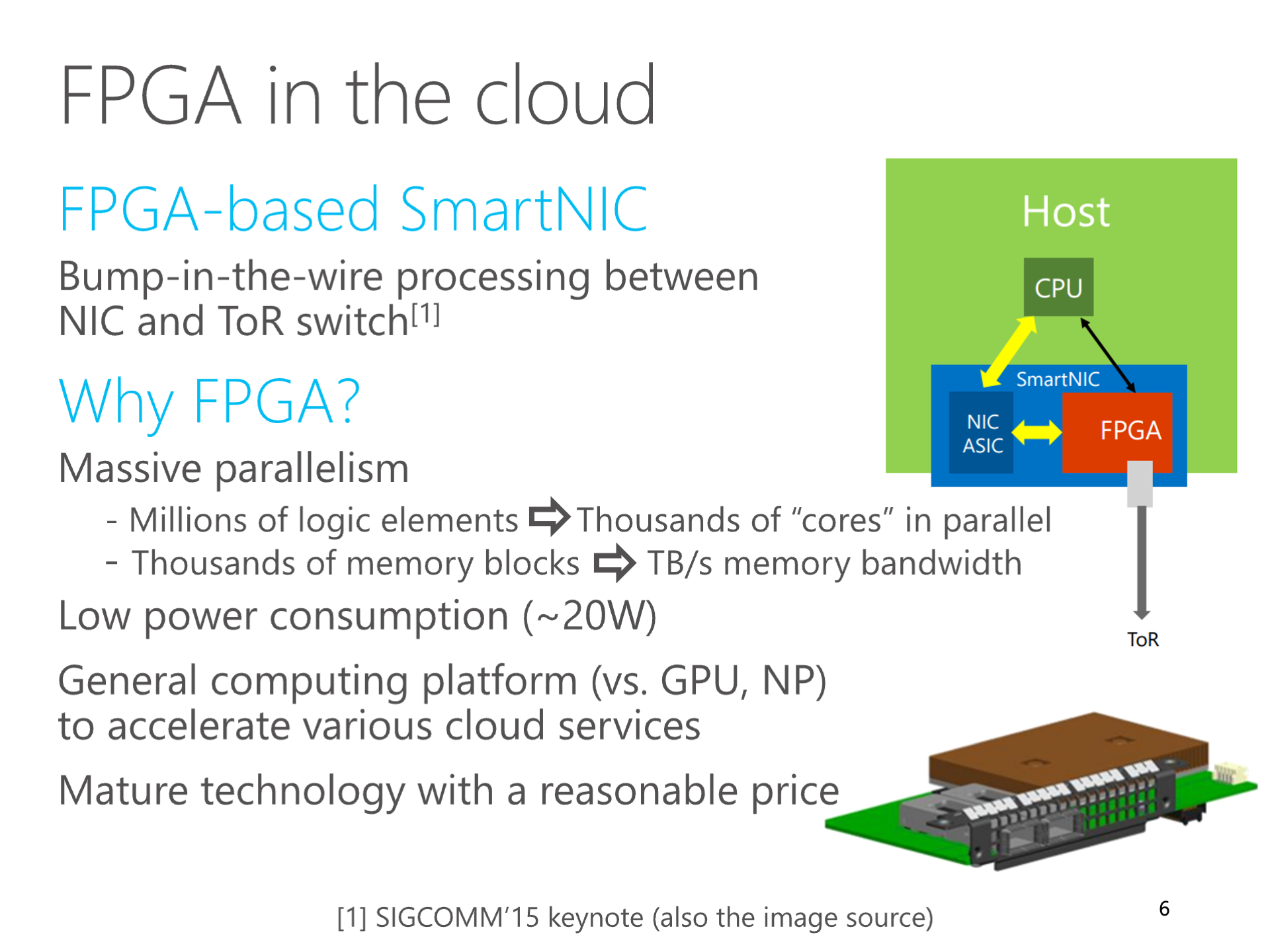
After Microsoft deployed Catapult FPGA to every server in the data center for accelerating network virtualization, the Catapult team began to explore whether these FPGAs could also be used to accelerate AI. The academic world had been flooded with articles on using FPGA for AI training and inference, so our focus was on how to use high-speed networks to accelerate FPGA AI.
At that time, the ranking algorithm of Microsoft Bing search was a DNN model. There was a significant limitation of FPGA for DNN inference, which was the bandwidth of memory. Our FPGA did not have high-speed memory like HBM at that time, only DDR4 memory, with a total bandwidth of 32 GB/s for two channels.
Most existing works put the model in DRAM, then divided the model into blocks, each block was loaded from the FPGA’s external DRAM to the FPGA’s on-chip SRAM (also known as Block RAM, BRAM), and then computation was done on-chip. Therefore, the cost of data movement became the main bottleneck of FPGA. The compiler’s job was to optimize the shape of the blocks and data movement, which was also my first project at Huawei MindSpore after my PhD graduation.
 Above: My SIGCOMM 2016 ClickNP paper's summary of FPGA computing characteristics
Above: My SIGCOMM 2016 ClickNP paper's summary of FPGA computing characteristics
In 2016, I thought, could we use a cluster of multiple FPGAs to split the deep neural network model into several blocks, so that each block could fit into the FPGA’s internal SRAM cache? Thus, what needed to be transmitted through the network were the intermediate results between blocks. Since there was a high-speed interconnect network between FPGA chips, after calculation, the bandwidth required to transmit these intermediate results would not become a bottleneck.
I excitedly reported this discovery to our hardware research group’s director, Ningyi Xu, who said, what I thought of was called “model parallelism”. In some scenarios, this “model parallelism” approach indeed achieves higher performance compared to the traditional “data parallelism” method. Although this was not considered a theoretical innovation, Ningyi Xu said, the idea of putting the entire model into the FPGA’s internal SRAM cache was interesting. It was like using a high-speed network to connect many FPGAs, treating them as one FPGA.
To distinguish from the traditional model parallelism method where data is still stored in DRAM, we called this method of storing all data on-chip SRAM “spatial computing”.
Spatial computing sounds grand, but it’s actually the most primitive. We build a digital circuit composed of logic gates to complete a specific task, which is spatial computing. After the birth of microprocessors based on Turing machine theory, temporal computing became mainstream, where the microprocessor executes different instructions at different times, allowing a set of hardware circuits to complete various tasks. But from an architectural perspective, microprocessors trade efficiency for generality.
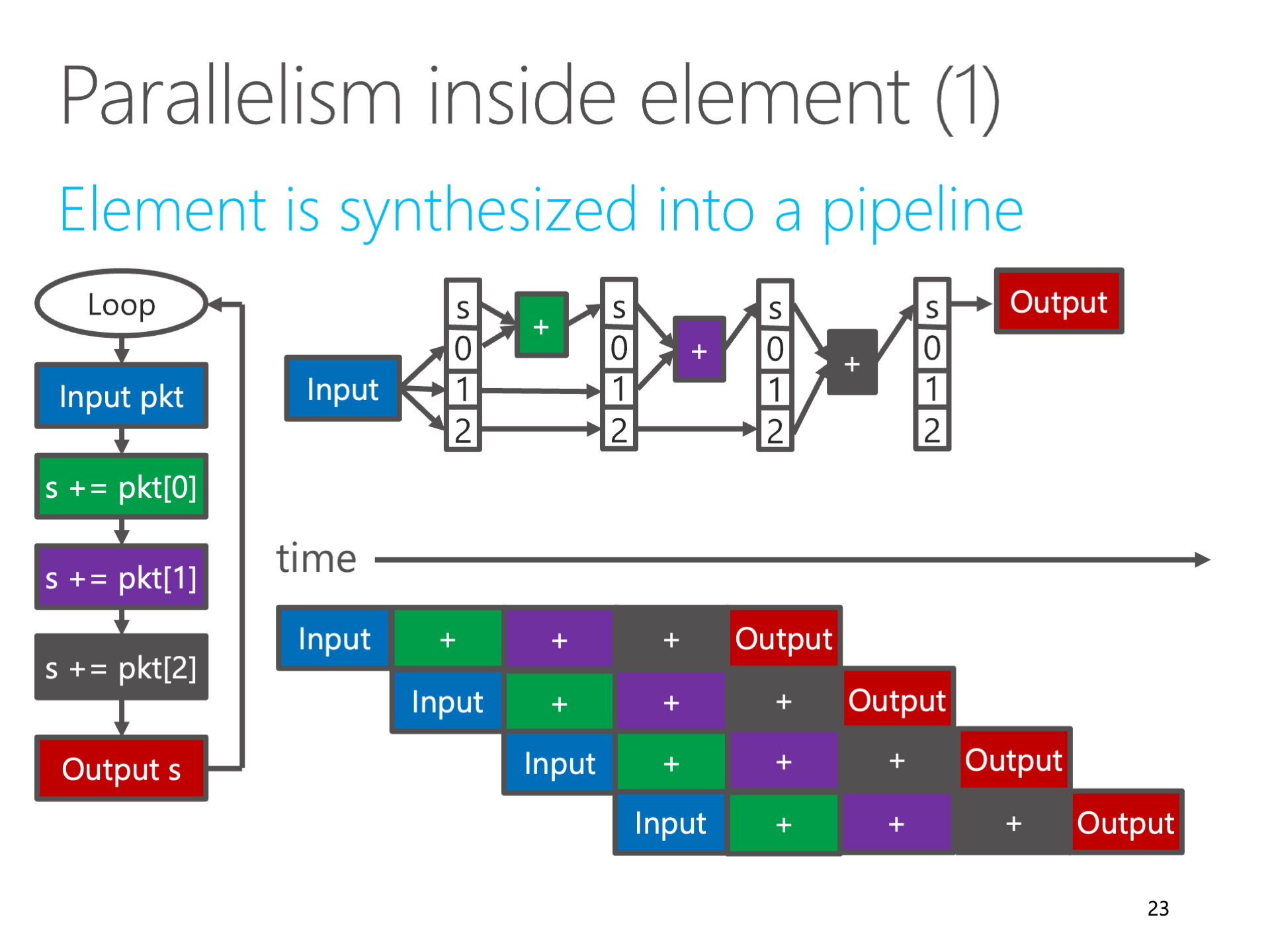 Above: Fully pipelining the computation logic is spatial computing
Above: Fully pipelining the computation logic is spatial computing
In the world of FPGA and ASIC, for efficiency, spatial computing is still mainstream. In FPGA high-level synthesis (HLS), code that has a fixed number of loops, does not contain arbitrary jumps (known in the compilation field as SCoP, Static Control Part), can be fully unrolled and inlined, and then transformed into a piece of combinational logic. After inserting registers at appropriate places, it becomes a fully pipelined digital logic. Such digital logic can accept a block of input data every clock cycle.
Those who work on distributed systems know that it’s difficult for a cluster of multiple machines to achieve linear speedup, meaning that as more machines are added, the cost of communication and coordination increases, and the average output of each machine decreases. But this “spatial computing” method can achieve “super-linear” speedup when there are enough FPGAs to fit the entire model in on-chip SRAM, meaning the average output of each FPGA in model parallelism is higher than that of a single FPGA using the data parallelism method.
Once the problem of accessing model memory bandwidth is solved, the computing power of FPGA can be fully unleashed. We conducted a thought experiment: every server in Microsoft Azure data center is equipped with an FPGA, if the computing power of 100,000 FPGAs in the entire data center is scheduled like a single computer, it would take less than 0.1 seconds to translate the entire Wikipedia. It was also demonstrated as a business scenario at an official Microsoft conference.
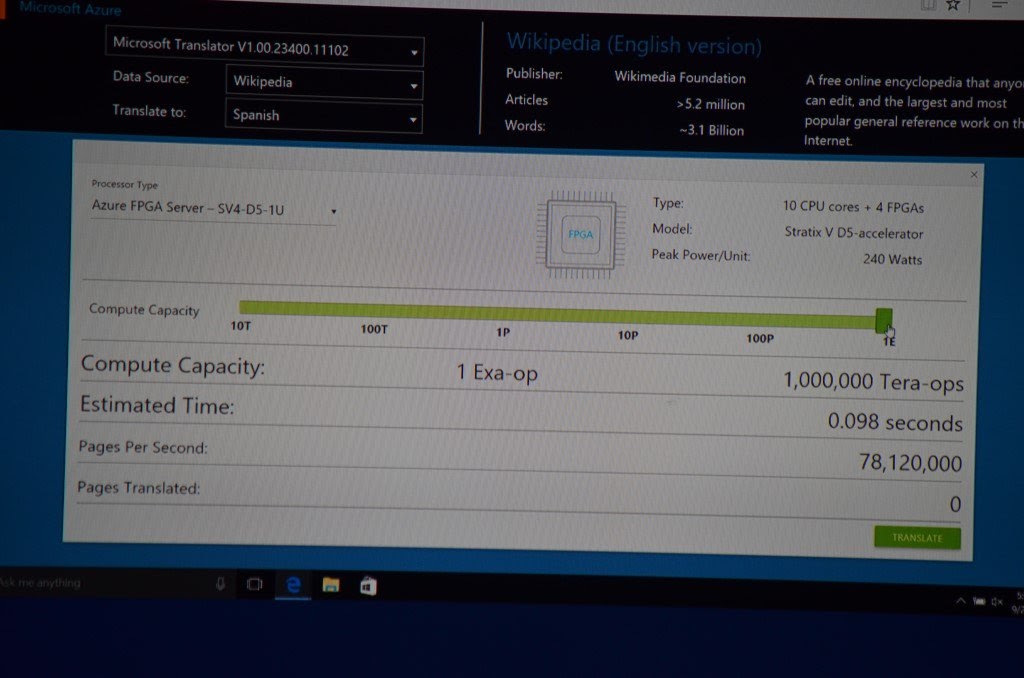 Above: Microsoft conference demo using FPGA to accelerate machine translation, if the entire data center's 1 Exa Ops computing power is utilized, it would take less than 0.1 seconds to translate the entire Wikipedia
Above: Microsoft conference demo using FPGA to accelerate machine translation, if the entire data center's 1 Exa Ops computing power is utilized, it would take less than 0.1 seconds to translate the entire Wikipedia
The KV Cache Dilemma of Large Models in Spatial Computing
Doesn’t the story of spatial computing sound wonderful? But the problem is that today’s large models based on Transformers are not the DNN models we worked on back then.
The inference process of DNN models requires storing very few intermediate states, much less than the weights. But the decode process of Transformers needs to save KV Cache, and the size of this KV Cache is proportional to the context length.
Assuming we do not do any batching, then for the LLaMA-2 70B model (int8 quantized), assuming the input and output context token count reaches the maximum of 4096, the 80 layers of KV Cache in total need 2 (K, V) * 80 (layers) * 8192 (embedding size) * 4096 (context length) * 1B / 8 (GQA optimization) = 0.625 GB. (Thanks to several friends who pointed out the mistake in my first version of the article, forgetting to consider GQA optimization, leading to the belief that the storage overhead of KV Cache was too large)
Compared to 70 GB of weights, 0.625 GB doesn’t seem much, right? But if we really don’t do batching, a cluster worth $1,800,000 of more than 300 Groq cards can only achieve a throughput of 500 tokens/s, such a large cluster can only serve one concurrent user, calculating the price per token, it’s $3,600 / (token/s).
So, what about the price per token for H100?
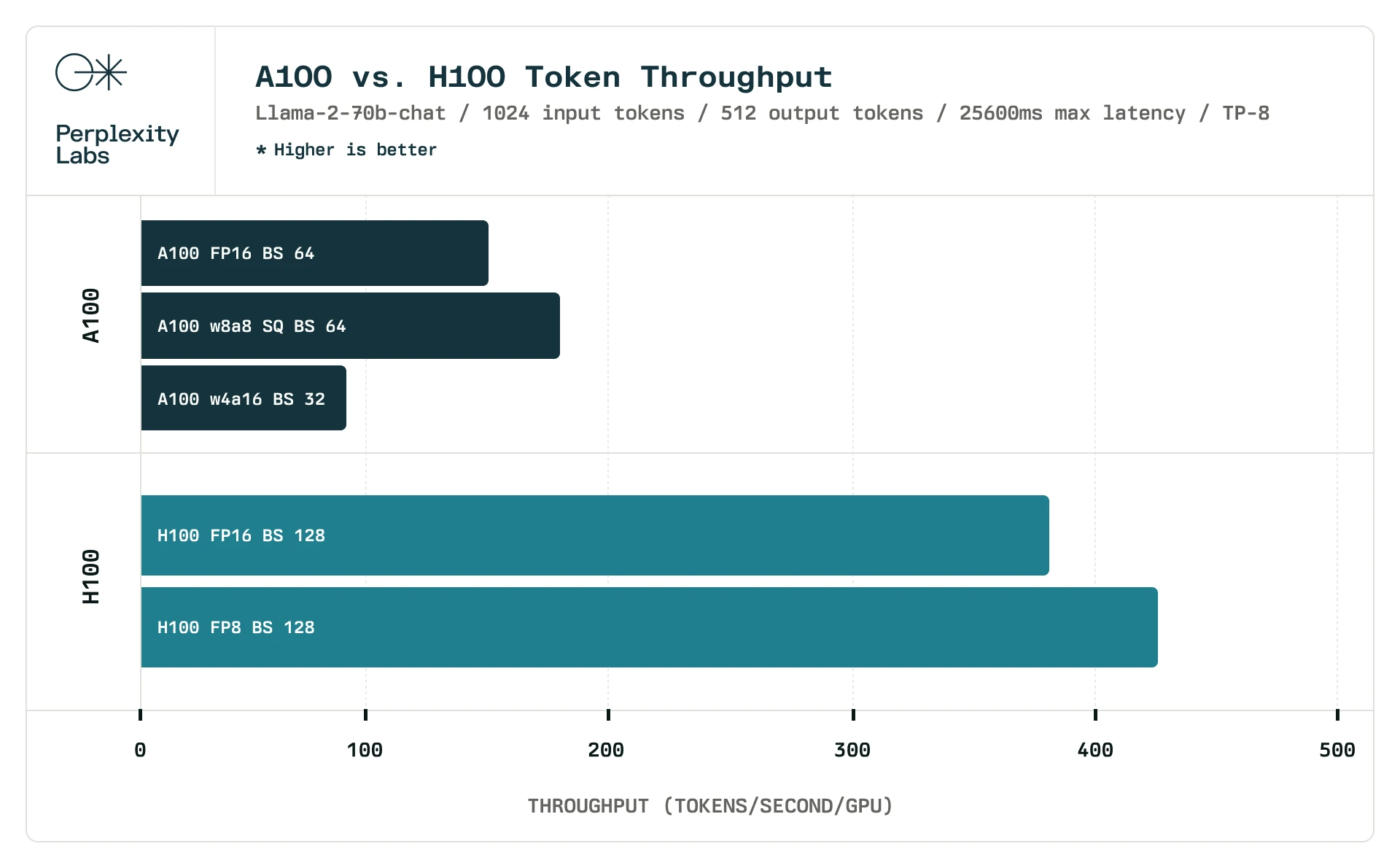 H100's throughput per card (tokens/s), source: Perplexity AI
H100's throughput per card (tokens/s), source: Perplexity AI
According to Perplexity AI’s data, for LLaMA-2 70B, at a batch size of 128, the average int8 inference performance of an 8-card H100 machine is about 425 tokens/s per card. Calculating at $30,000 per H100 card, that’s $70 / (token/s). The price difference is 50 times!
To allow our expensive Groq cluster to serve a few more concurrent requests, we need to increase the batch size, for example, to match the typical setting of an 8-card H100 machine with a batch size of 128. The size of the KV Cache is directly proportional to the batch size; one sample is 0.625 GB, so 128 samples would be 80 GB.
Note that the model itself is only 70 GB, and these intermediate states of the KV Cache are 80 GB, requiring at least 652 Groq cards to accommodate this 150 GB of memory. The cost of this cluster reaches $3,912,000, which is only twice as much as the previous batch size = 1. 128 concurrent requests result in 128 * 500 = 64,000 token/s, making the cost $61 / (token/s), slightly lower than that of the H100.
We know that the H100 itself already has a high premium, and many people are thinking about using a 4090 cluster for inference, which is at least half the price of the H100. (How to run a 70B model on a 4090 cluster is another question, which we won’t discuss here.) Now there’s a chip with a cost-performance ratio similar to the H100, and it can only do Transformer; it’s uncertain whether it can run a diffusion model, so would you buy it?
So, are there any sweet spots for other batch sizes? For every increase in batch size by 1, 0.625 GB of KV Cache needs to be stored, requiring 3 Groq cards. Other AI chips generally have bottlenecks in computing power or memory bandwidth, but Groq’s bottleneck is memory capacity. That is to say, each concurrent request, or every 500 token/s, requires an addition of 3 cards worth $18,000, making the price per token impossible to be lower than $36 / (token/s), although cheaper than the H100, it still doesn’t reach the level of the 4090. (The TDP of each Groq card is 215W, similar to the 4090, making the token/W ratio relatively low and the electricity cost relatively high)
Groq doesn’t need to contribute profits to NVIDIA
Some might ask, why does Groq claim their inference service is cheaper than companies using NVIDIA chips like Anyscale, Together AI, etc.? This is because Groq makes their own chips, without the middleman NVIDIA making a profit.
For Groq, the cost of a chip sold for $6,000 might not even be $1,000. If the cost of each Groq card is calculated at $1,000, then the cost of a cluster with a batch size of 128 would only be $652,000, making the price per token $10.2, 7 times cheaper than the H100. Of course, this doesn’t consider the costs of electricity, host machines, and network equipment. When calculating the cost of chips at their cost price, electricity costs might actually become the major expense, similar to mining.
But if NVIDIA also provided inference services at the cost price of the H100 at $2,000, then the price per token would directly drop to 1/15, only $4.7 per token, half the price of Groq’s cost price calculation. This shows how large NVIDIA’s profit margin is.
NVIDIA’s net profit margin of more than half, with revenue almost catching up to Alibaba, such a profitable monopoly business needs an aircraft carrier to defend. No wonder Sam Altman couldn’t stand it anymore, OpenAI worked hard on models only to feed NVIDIA, hence planning a $700 billion game, starting from scratch, to reshape the entire chip industry.
The larger the model, the greater the challenge of spatial computing network
If we were to infer not the 70B LLaMA-2, but the so-called 1,800B GPT-4, what would happen?
Just to accommodate all these parameters, even using int8 quantization, would require 7,826 cards. This doesn’t even include the KV Cache.
At such a large scale, the network interconnect of spatial computing will face a great challenge.
Even if pipeline parallelism is maximized, with Transformer having one pipeline stage per layer, assuming GPT-4 also has 80 layers, each pipeline stage would require 100 cards for tensor parallelism, and these 100 cards would need high-performance all-to-all communication. To maintain a high throughput of 2 ms/token, network communication delay must also be in the microsecond range. At the scale of ten thousand cards, this poses a significant challenge to network interconnect.
Therefore, I guess what Groq did might not be a switch-based interconnect network, but a point-to-point interconnect topology, with each card connected to several surrounding cards, similar to the 2D/3D Torus commonly seen in supercomputers. Microsoft’s Catapult FPGA initially also wanted to do this kind of supercomputer-like point-to-point topology, although mathematically beautiful, it was found to lack versatility and was changed to rely on a standard switch-based fat-tree network. Of course, the interconnect bandwidth of Catapult FPGA cannot be compared with NVLink and Groq.
If Groq could achieve an output speed of 500 token/s for GPT-4, I would really admire them.
Moreover, since a TB/s network interconnect has been developed, why not use it to interconnect HBM memory?
Although using SRAM as HBM memory cache is not very reliable (Transformer needs to access every parameter, lacking locality), having HBM could at least allow for optimizations like persistent KV Cache, such as prefilling hundreds of K tokens into it, placing the KV Cache into HBM, and loading it when needed, thus saving a lot of prefill costs for recalculating KV Cache.
Those who have used the OpenAI API know that in most scenarios, the most expensive part of the API is the input, not the output. The input includes prefill prompt (background knowledge and instructions) and conversation (historical dialogue), with input lengths often reaching tens of K tokens (assuming a maximum of 4K tokens for calculating KV Cache memory capacity), but the output length rarely exceeds 1K tokens. Although each input token is cheaper than each output token, the cost of input is still generally higher than that of output. Reducing the overhead of recalculating KV Cache would be a significant achievement.
Conclusion
The advantage of Groq is: by putting all data into SRAM, achieving high memory bandwidth, and thus achieving high single-request token/s, a speed that is difficult to match with any number of H100s. For application scenarios that require high output speed, spatial computing, represented by Groq, has a promising future.
The disadvantage of Groq is: each card’s SRAM capacity is limited, and the KV Cache occupies a large amount of memory, requiring a large cluster size. Therefore:
- If Groq prices their chips similar to NVIDIA GPUs, based on computing power, then the inference cost is comparable to the H100.
- The entry barrier for a Groq cluster is high, with a minimum configuration requiring 300 cards, a $1.8M investment, and its performance is too poor; for a cost-effective performance, 1000 cards, a $6M investment is needed. In comparison, the $0.3M for an 8-card H100 is much cheaper.
Actually, I have a bold guess, Groq’s architecture might have been designed for the previous generation of DNNs rather than Transformer, at that time they hadn’t considered that KV Cache would take up so much memory. Spatial computing is a beautiful idea, just like what we did at Microsoft back then. In the past two years, Transformer has become popular, but chip design is not so easy to change, so they used the technical indicator of “the fastest token output speed on the surface” to make big news.
Transformer is a clean, universal architecture, for chips, it’s about competing in computing power, memory capacity, memory bandwidth, and network bandwidth, with no tricks to play.