The New Golden Age of Computer Networks (II): Wide Area Networks
(This article is a compilation of my speech at Peking University on December 12, 2022, first converted into a draft using iFlytek’s voice recognition technology, then polished and corrected using GPT-4, and finally supplemented with some new thoughts manually)

Wide Area Networks (WANs) mainly fall into two categories of communication modes, one is end-cloud communication, and the other is inter-cloud communication. Let’s start with end-cloud.
End-Cloud Networks
When we generally mention WANs, we assume they are uncontrollable, as the network equipment of the operators is not under our control, and there are a large number of other users accessing concurrently, making it difficult to achieve determinism. But many of today’s applications require a certain degree of determinism, such as video conferencing, online games, where users will feel lag if the delay is too high. How to reconcile this contradiction? That’s our topic today.
As we mentioned in the previous chapter on data center networks, the bandwidth actually perceived by applications is much less than the physical bandwidth, hence there is room for optimization. We know that the theoretical bandwidth of both 5G and Wi-Fi is hundreds of Mbps or even Gbps, and many home broadband bandwidths are also hundreds of Mbps or even reaching gigabit levels. In theory, 100 MB of data can be transmitted in one or two seconds. But how many times have we downloaded an app from the app store and it finished in one or two seconds for a 100 MB app? Another example, a compressed 4K HD video only requires a transmission speed of 15~40 Mbps, which sounds far from reaching the theoretical limit of bandwidth, but how many network environments can smoothly watch 4K HD videos? This is partly a problem with the end-side wireless network and partly a problem with the WAN. There is still a long way to go to make good use of the theoretical bandwidth.
When I was interning at Microsoft, the Chinese restaurant on the second floor of the Microsoft Building was called “Cloud + Client”, and the backdrop at the sky garden on the 12th floor also read cloud first, mobile first. Data centers and smart terminals were indeed the two hottest fields from 2010 to 2020. Unfortunately, Microsoft’s mobile end never took off. Huawei, on the other hand, has strong capabilities on both the end and cloud sides, giving it a unique advantage in end-cloud collaborative optimization.

Traditional internet applications actually don’t have such high demands for bandwidth and latency. For example, web browsing, file downloading, 1080p video on demand, 100 Mbps bandwidth is enough, and second-level latency is enough to meet user needs.
However, today’s real-time audio and video (Real-Time Communications, RTC) and other new applications have higher demands for bandwidth and latency. For example:
- 4K HD video may require 1000 Mbps bandwidth.
- Video conferencing requires a latency of 100 milliseconds, otherwise, there will be a noticeable delay in video and sound.
- The latency of live streaming has been reduced from minutes to seconds. Live streaming is different from video conferencing. Live streaming often has tens of thousands of people watching a channel at the same time, so it requires CDN network layer forwarding.
- Remote desktops even require a stable latency of 10 ms. I have used remote desktop for a while, and a latency of 40 ms already causes noticeable lag.
- Cloud gaming, like Cloud Genshin Impact, also requires a stable latency of 10 ms.
We know that in fiber optics, light can only travel 2000 kilometers in 10 ms, which means that for a round-trip latency of 10 ms, the server theoretically cannot be more than 1000 kilometers away. And we also have to consider the latency of the wireless access network, the queuing latency in the network router, and the processing latency in the data center. 10 ms is a very strict requirement. Only by being meticulous in every aspect such as data center location, wireless network, WAN, data center network, and data center business processing, can we achieve stable low latency.
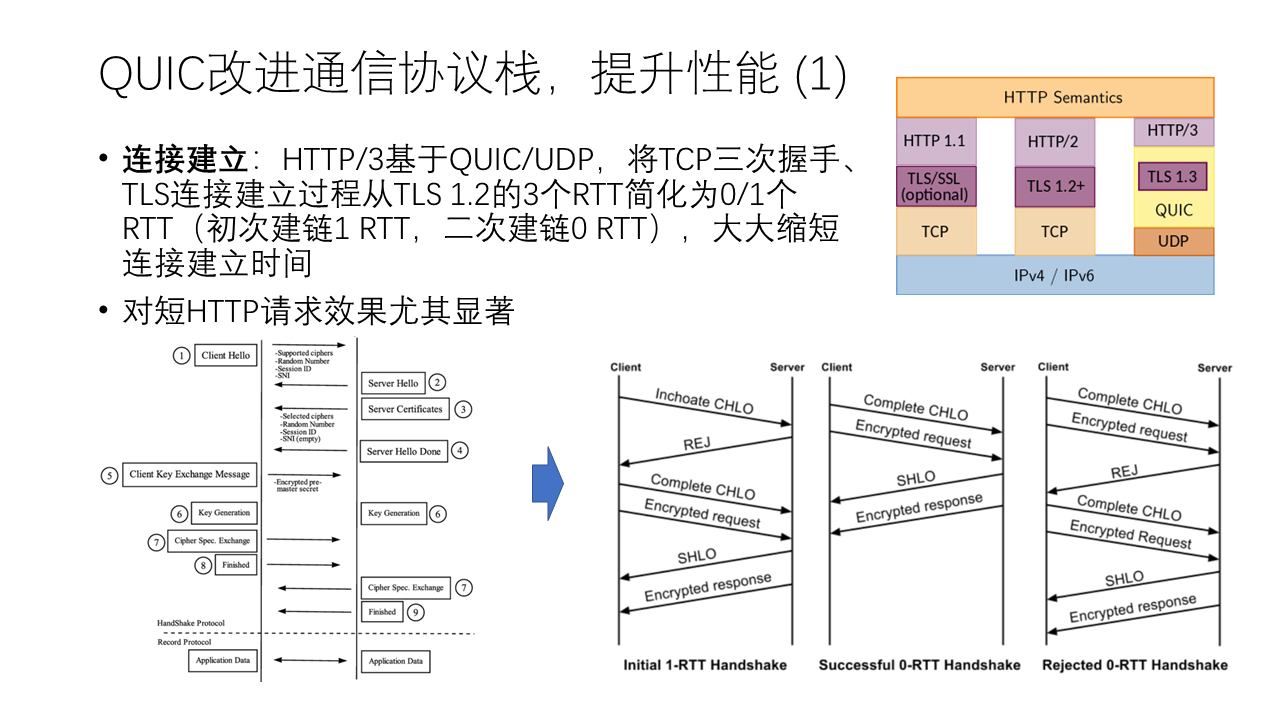
Real-time audio and video require a series of key technologies. Today, due to time constraints, I will only talk about one representative new transport protocol, QUIC. QUIC is proposed by internet giants like Google, aiming to replace traditional HTTP. The latest HTTP/3 is based on QUIC, and many large websites, such as Google and Facebook, already support QUIC.
The traditional HTTP protocol based on TCP has a series of problems in WAN transmission, including connection establishment latency, congestion control, head-of-line blocking, packet loss recovery, etc. Let’s discuss them one by one.
First is the issue of connection establishment latency. We all know that TCP requires a three-way handshake, which means data can only be sent after one round-trip latency.
Most of the traffic on the network is now transmitted encrypted via TLS. Before TLS 1.3, the establishment of an encrypted connection also required two round trips, mainly to allow the client to verify the server’s identity and generate a random key for encrypting data.
- After the establishment of a TCP connection, the client first sends the domain name it wants to access, the list of supported encryption algorithms, and the random number used to generate the random key to the server. Note that the domain name is transmitted in plaintext, which means that even though TLS is used, the operator can still know which website you are visiting.
- Then the server sends the server’s TLS certificate, the selected encryption algorithm, and the random number used to generate the random key to the client.
- The client verifies the server’s certificate, then generates the key used to encrypt the data based on the previous random number, and sends the key encrypted with the public key in the server certificate to the server.
- The server uses the private key to unlock the key used to encrypt the data, so both the client and the server have the same key, and listeners on the network cannot get the key.
Next, the application can send data based on this encrypted connection, that is, the HTTP request sent by the client and the HTTP response returned by the server.
QUIC compresses the connection establishment process that takes 3 network round trips to 0 to 1 time. The first time a connection is established, it only needs one round trip, and subsequent connection establishments do not even need a round trip. How is this achieved?
First, by transmitting data packets through connectionless UDP, the overhead of TCP connection establishment can be saved. QUIC internally distinguishes different connections through Session ID, that is, it implements connection distinction at the session layer, rather than distinguishing connections based on the TCP/IP five-tuple.
Second, TLS 1.3 improves TLS 1.2. When establishing a link for the first time, the process of establishing an encrypted channel that originally required two round trips is reduced to one. The basic principle is to parallelize the process of steps 3~4 of the above TLS 1.2 handshake process and sending data. We noticed that after the client verifies the certificate and generates the symmetric key in step 3, it can actually start using the symmetric key to encrypt the application’s message, so after sending the key, it can pipeline the encrypted data. Of course, for forward secrecy, this symmetric key is only used in the first round trip, and the data in the second round trip and later will use another key that supports forward secrecy.
Finally, in the case of previously established connections, the TLS 1.3 module inside the QUIC protocol stack will cache the symmetric key (Pre-Shared Key, PSK) of the connection. In this way, as long as the cache has not expired, the client can still use the original symmetric key to encrypt the data and send it directly, so no handshake is needed, and 0-RTT chain establishment is achieved. That is to say, the QUIC protocol stack internally actually maintains a long connection, which is called session reuse. Of course, session reuse also brings the risk of replay attacks, and weakens the characteristics of forward secrecy.
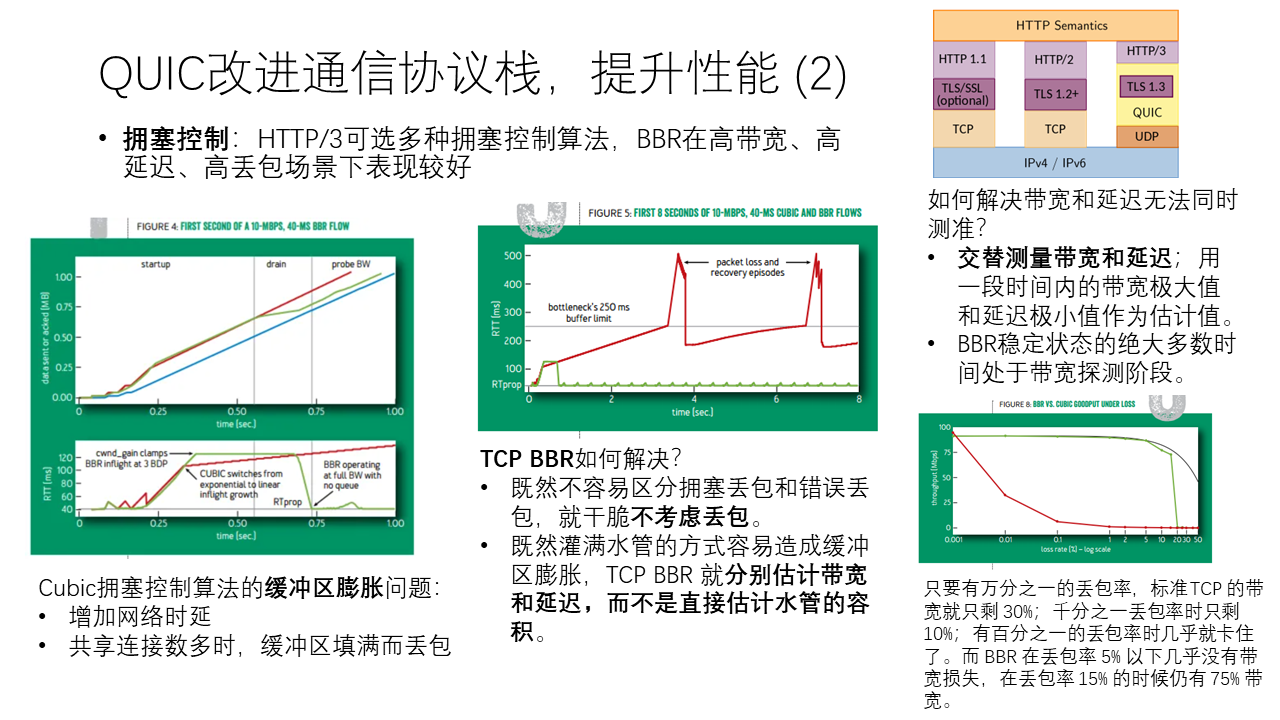
Next is the issue of congestion control. The problem of congestion control on the wide area network has been studied for decades. Some are based on packet loss, some are based on delay, and some are a combination of the two.
HTTP/3 has multiple congestion control algorithms to choose from. Today we will focus on a special congestion control algorithm, Google’s BBR, which is designed for high bandwidth, high delay, and high packet loss scenarios.
Traditional congestion control algorithms, such as TCP Cubic that we learned in textbooks, can easily lead to buffer bloat. Because each connection only slows down when there is packet loss or high delay, feedback requires a network round-trip delay, so each connection will occupy a certain buffer on the bottleneck link and form a certain queue. When the number of connections passing through a bottleneck link is large, the queue will be long, leading to an increase in end-to-end delay. If the number of connections passing through the bottleneck link is large enough, the queue will exceed the buffer capacity of the router, leading to packet loss.
Traditional TCP Cubic only slows down when packet loss is encountered, so the queue depth will always remain high, and the delay will always be relatively high. Is there a way to solve this problem? Congestion control algorithms based on delay can start to slow down when the delay rises, without waiting for packet loss. BBR is the same, it does not consider packet loss, but tries to directly estimate BDP (Bandwidth-Delay Product). BBR does not consider packet loss for another reason. Sometimes packet loss on the wide area network is not caused by congestion. Some are caused by errors, such as weak wireless network conditions; some are caused by middleboxes on the network.
How to estimate BDP? Those who have done networking know that bandwidth and delay are very difficult to measure accurately: when measuring bandwidth, the network is full, and the delay will be high; when measuring delay, the network needs to be unloaded, and the bandwidth cannot go up. BBR uses a clever method of alternately measuring bandwidth and delay: most of the time is in the bandwidth detection phase, that is, full-speed transmission, occasionally try to send more data, if the delay comes up, it means that the bandwidth is already full, if the delay does not rise, it means that it can be sent faster. A small part of the time is switched to the delay detection phase, the transmission speed is reduced, and the minimum delay measured is taken as the basic delay. In this way, BDP can be estimated more accurately, and network changes can be responded to in a timely manner.
For the scenario of random packet loss, BBR performs well. In the case of a large BDP, as long as there is a packet loss rate of one in ten thousand, the bandwidth of TCP Cubic is only 30%; when there is a packet loss rate of one in a thousand, the bandwidth of TCP Cubic is only 10%; when the packet loss rate reaches 1%, TCP Cubic is almost stuck. And BBR has almost no bandwidth loss when the packet loss rate is below 5%.
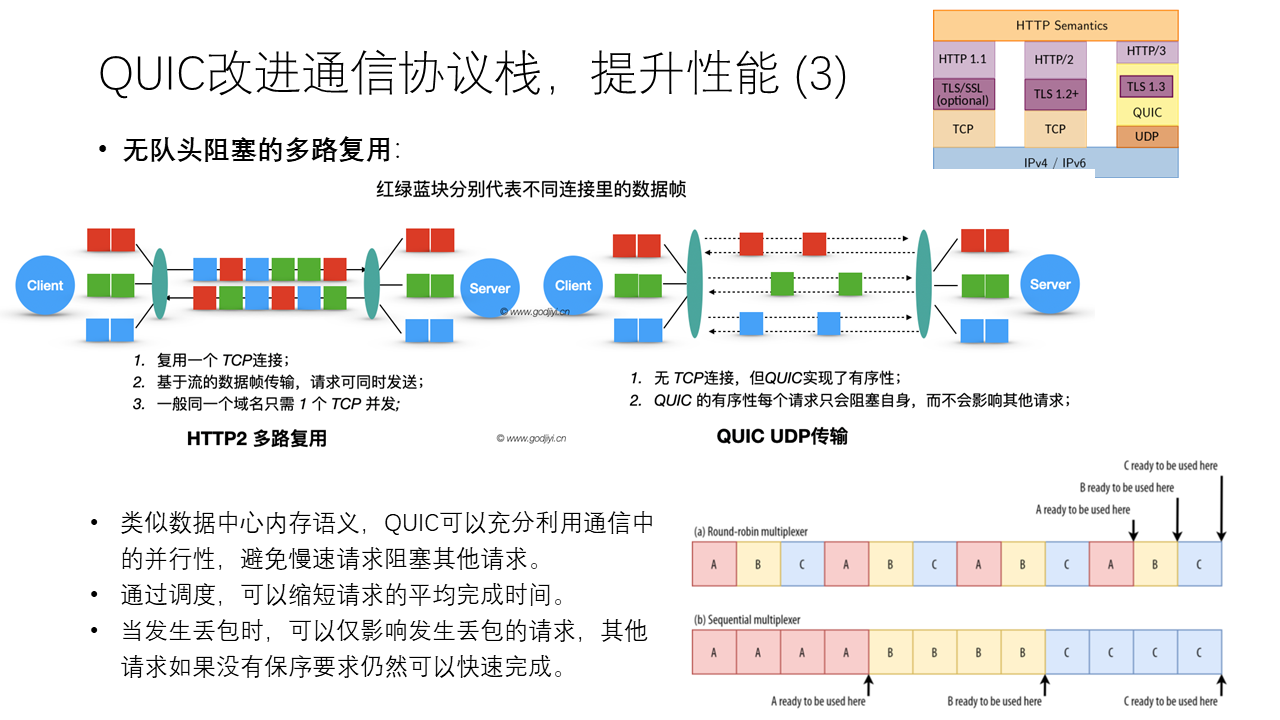
The third issue is head-of-line blocking. As mentioned earlier in the data center section, TCP is an abstraction of byte streams, which means all data is transmitted in order. Even if there is no dependency between multiple HTTP requests or responses under the same domain, they must be transmitted in sequence. This is actually inefficient.
Parallelism in network communication is widespread and often easily overlooked. The reason for being overlooked is that many systems insist on maintaining the programming abstraction of order, thereby losing the optimization opportunity of out-of-order transmission.
For example, WeChat messages are transmitted out of order. Sometimes we find that the order of sending and receiving messages is inconsistent. For instance, text, photos, and videos are sent in parallel. The other party may receive the text first, then the photo, and then the video. If WeChat requires messages to be strictly transmitted in order, then once a large video of several hundred MB is sent, it may not be able to send other messages for several minutes, which is unbearable.
Another example, in video conferencing, the priority of audio is higher than that of video. It is generally more unbearable for the sound to be interrupted than for the video to be stuck, and the amount of audio data is much smaller than that of video. In videos, there are also keyframes (I frames) and non-keyframes (P frames). Each I frame is independent of each other, and there is one every once in a while, while P frames are increments relative to I frames. If the I frame is lost, the subsequent P frames cannot be decoded, so the I frame is more important.
QUIC takes advantage of the parallelism in network communication, allowing each HTTP request or HTTP stream to be sent out of order independently, avoiding large requests blocking small requests, and avoiding a packet loss of a request causing all subsequent requests to wait for its retransmission. In QUIC, high-priority requests can jump the queue, small requests can surpass large requests, and a packet loss of a request does not affect other unrelated requests.
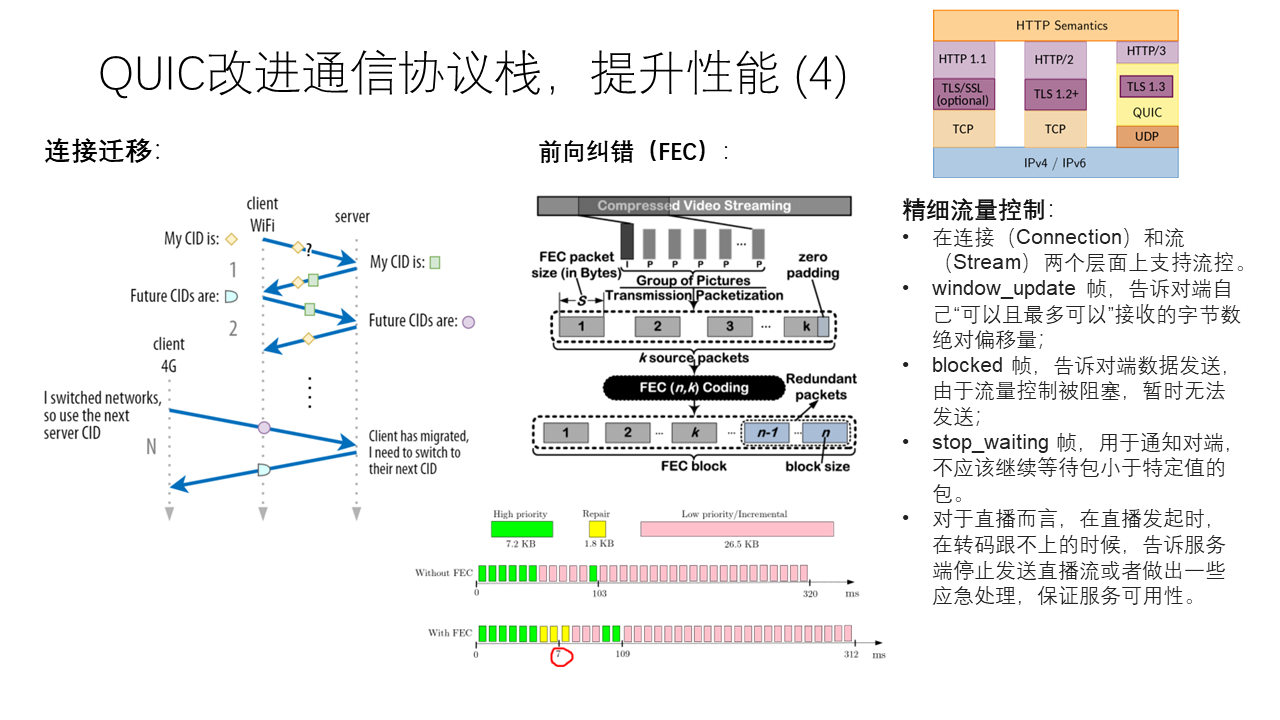
The characteristic of QUIC establishing connections on the session layer is also fully reflected in “connection migration”. Traditional TCP connections are bound to the IP addresses of the client and server. In a mobile environment, users may migrate between Wi-Fi and 5G, and the client’s IP address may change. Since QUIC no longer relies on the concept of the TCP/IP five-tuple to distinguish sessions, it simply allows the client’s IP address to change and determines which session it is based on the client’s Session ID. In this way, users can “roam” between different networks without worrying about connection interruptions. This is actually similar to the method of using Cookies to identify user identities in application layer protocols such as HTTP.
To solve the problem of high packet loss rate in wireless weak network scenarios, QUIC introduces the Forward Error Correction (FEC) mechanism. The FEC mechanism is essentially a kind of redundant coding. Even if a part of the packet is lost, there is a relatively high probability that the lost packet can be recovered. The cost of the FEC mechanism is the waste of additional bandwidth, so QUIC will automatically select the appropriate redundant coding method based on the current packet loss rate. Of course, the FEC mechanism is more suitable for random packet loss, but if many packets are lost in a row, the FEC mechanism is helpless.
Finally, flow control has always been a key issue in networks. The purpose of flow control is to backpressure the sender when the application at the receiving end cannot process or the receiving memory buffer is insufficient, so that it can temporarily pause sending data. Many people have always been unable to distinguish between flow control and congestion control. The purpose of congestion control is to reduce the queue length caused by multiple concurrent connections passing through the same bottleneck link. Specifically in the TCP protocol, the sender’s cwnd is for congestion control, and rwnd is for flow control. The actual sending window is the smaller of the two.
For scenarios such as live streaming, there may be a problem that transcoding cannot keep up with the live broadcast, causing stuttering. In order to improve user experience, QUIC provides the ability for fine-grained flow control. When transcoding cannot keep up, it tells the server to pause sending the live stream, or to reduce the bitrate, etc.

QUIC has many improvements compared to traditional HTTP over TCP, but it still has a lot of room for improvement.
In terms of congestion control, the slow start process of BBR still requires multiple network round trips, but many requests only need to transmit a small amount of data. The slow start phase takes up most or even all of the transmission time, and it needs to detect the available bandwidth more quickly. The basic assumption of general congestion control algorithms like BBR is the long-stable traffic model, that is, there are infinitely many data sources continuously sending on the connection. But the traffic of many applications is bursty. If bandwidth is reserved for it, it will affect bandwidth utilization. If bandwidth is not reserved, packet loss or sudden increase in delay may occur. In addition, BBR relies on the measurement of delay and bandwidth, but in some scenarios, due to congestion and other reasons, the delay often jitters, which will cause BBR’s BDP calculation to be inaccurate.
In terms of packet loss retransmission, QUIC uses forward error correction technology, which performs well under random packet loss, but performs poorly under burst packet loss. There is also the phenomenon of pseudo packet loss, that is, delay jitter causes the delay to suddenly rise, which is regarded as packet loss, leading to unnecessary retransmissions.
Finally, QUIC only provides encrypted reliable transmission, requiring all data to arrive, but some real-time audio and video data actually do not need to be retransmitted after timeout. Even if they are retransmitted, the corresponding frames have already been skipped.
Through systematic optimization of protocols like QUIC, we hope to change the end-cloud wide area network from “best effort” to “quasi-deterministic”. The reason why we added a “quasi” before “deterministic” is because complete determinism is theoretically impossible to achieve on uncontrollable wide area networks. Therefore, we hope to achieve certain deterministic delay and bandwidth in most scenarios for most typical businesses to meet the quality of service requirements of applications.
Intercloud Network

Previously, we used QUIC as an example to introduce some of the latest developments in end-cloud wide area network communication protocols. In fact, in addition to the traffic from user terminals to data centers on the wide area network, a large part of the traffic is between data centers, called intercloud networks.
The biggest difference between intercloud networks and end-cloud networks is that the controllability of intercloud networks is generally much higher than that of end-cloud networks. Communication between data centers often goes through dedicated lines, the bandwidth and delay of which are relatively stable, and the packet loss rate is generally relatively low. Even if data centers communicate through the Internet, their bandwidth is generally guaranteed. In addition, the network switching equipment at the exit of the intercloud network is generally controlled by the owner of the data center, so it has unique advantages in traffic scheduling, congestion control, and other aspects.
The typical application scenarios of intercloud networks include:
- Data synchronization between multiple data centers within the same region, with a distance of tens of kilometers, mainly used to enhance the reliability of databases and other applications and achieve disaster recovery purposes.
- Data synchronization between multiple regions, including centralizing data from various places for big data processing, etc.
- Transfer data from large data centers to edge data centers and CDN servers for caching, live streaming, etc.
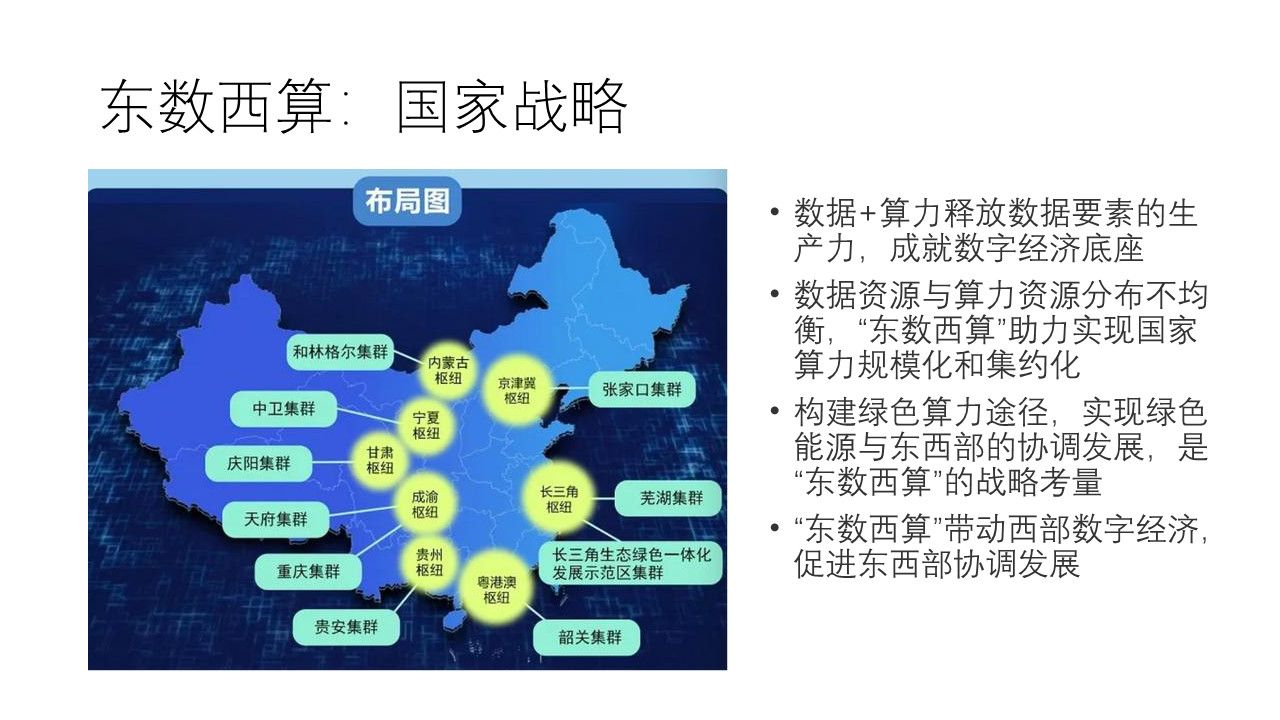
- Migrate high-cost computing and storage tasks to lower-cost data centers. In our country, this is the “East Data West Calculation” national strategy.
Our country has proposed the top-level design of the “National Integrated Big Data Center”. According to the energy structure, industrial layout, market development, climate environment, etc., it plans to build the national integrated computing power network national hub nodes in Beijing-Tianjin-Hebei, Yangtze River Delta, Guangdong-Hong Kong-Macao Greater Bay Area, Chengdu-Chongqing, and Guizhou, Inner Mongolia, Gansu, Ningxia, etc., to develop data center clusters, guide the intensive, large-scale, and green development of data centers. Among them, the high-speed network transmission channels between the national hub nodes are the “East Data West Calculation” project.
East Data West Calculation is like South-to-North Water Diversion and West-to-East Electricity Transmission. Other countries may not have the same strategic demands and may not be able to gather enough strength to accomplish this major event. Obviously, tasks with high latency requirements are suitable for staying in the east, while batch processing tasks with high computing power requirements are suitable for the west. How to efficiently divide tasks and efficiently transmit data between the east and the west is an important issue.

Usually, before users purchase cloud service resources, whether it is IaaS, PaaS or SaaS, they first choose the Region, and users do not have an overall concept of the global deployment and network topology connection of cloud services, so cloud vendors need to present the distribution, price, and usage status of resources to users, and then let users choose the deployment area of the service and interconnect between regions on their own.
Huawei Cloud has proposed the concept of Regionless, hoping to provide cloud tenants with the programming abstraction of the “National Integrated Big Data Center” or even the “Global Integrated Big Data Center”.
Regionless is to break the constraints of Region-level services in the architectural design of the cloud, introduce global scheduling capabilities, based on the optimization of computing cost, the latency of specific cloud services and business load access, and the communication coupling relationship between applications/application groups, to provide users with the best choice. As for which geographical area the resource instances of specific cloud services are issued to, it is entirely determined by the intelligent scheduling system of the cloud.
In this process of Regionless, Huawei Cloud completes the scheduling strategy and shields the complexity of underlying resource scheduling. Users do not need to choose the geographical Region themselves to enjoy the global deployment capabilities of global services. In this way, the smooth diversion of the east and west regions can be solved, so that users can smoothly migrate business loads from eastern cities to the west almost imperceptibly, such as Huawei Cloud’s Ulanqab Data Center and Gui’an Data Center. This involves architectural layering at the regional level, global scheduling, and even the price difference between resources in the east and west, etc.
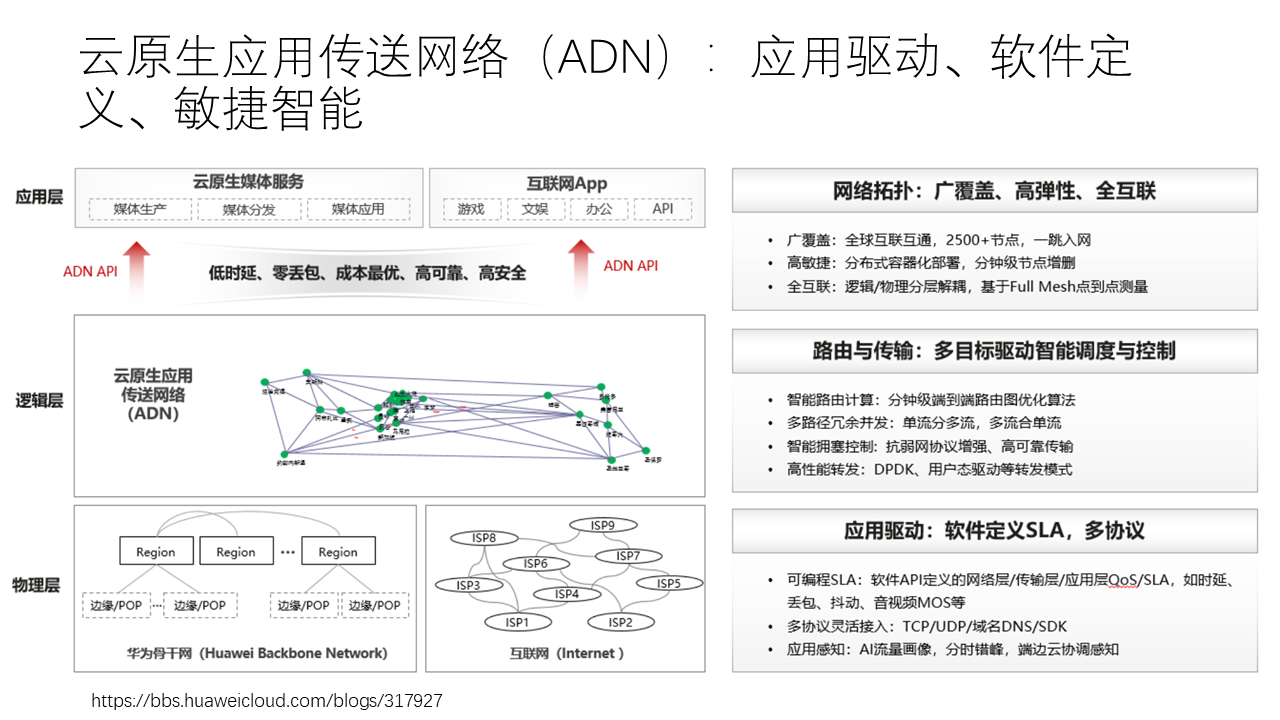
In order to build a high-performance intercloud network, Huawei Cloud has built a cloud-native application access network (ADN). The underlying layer of ADN is dedicated lines and the Internet. The stability of dedicated lines is high, but the cost is relatively high when the total leased bandwidth is low, and the cost of leasing dedicated lines per unit bandwidth decreases with the total leased bandwidth. The stability of the Internet is relatively poor, but the cost may be lower. In this way, high-priority, latency-sensitive traffic is more suitable for dedicated lines, and other traffic is more suitable for the Internet.
To improve reliability, dedicated lines and the Internet are redundant to each other, and different routing paths are also redundant to each other. Due to the topology of the dedicated line network, the bandwidth of the direct dedicated line may not be as large as that of the detour through the intermediate node, so the shortest path may not be the optimal path. Traffic Engineering is to route traffic to different network paths according to user’s bandwidth requirements and priority for traffic.
Like the QUIC of the end-cloud network mentioned earlier, the traffic engineering of the intercloud network also requires users to specify QoS (Quality of Service) requirements such as priority. In system design, it is a common optimization method to let applications provide hints to the system. If the system lacks information from the application, it is often impossible to optimize.
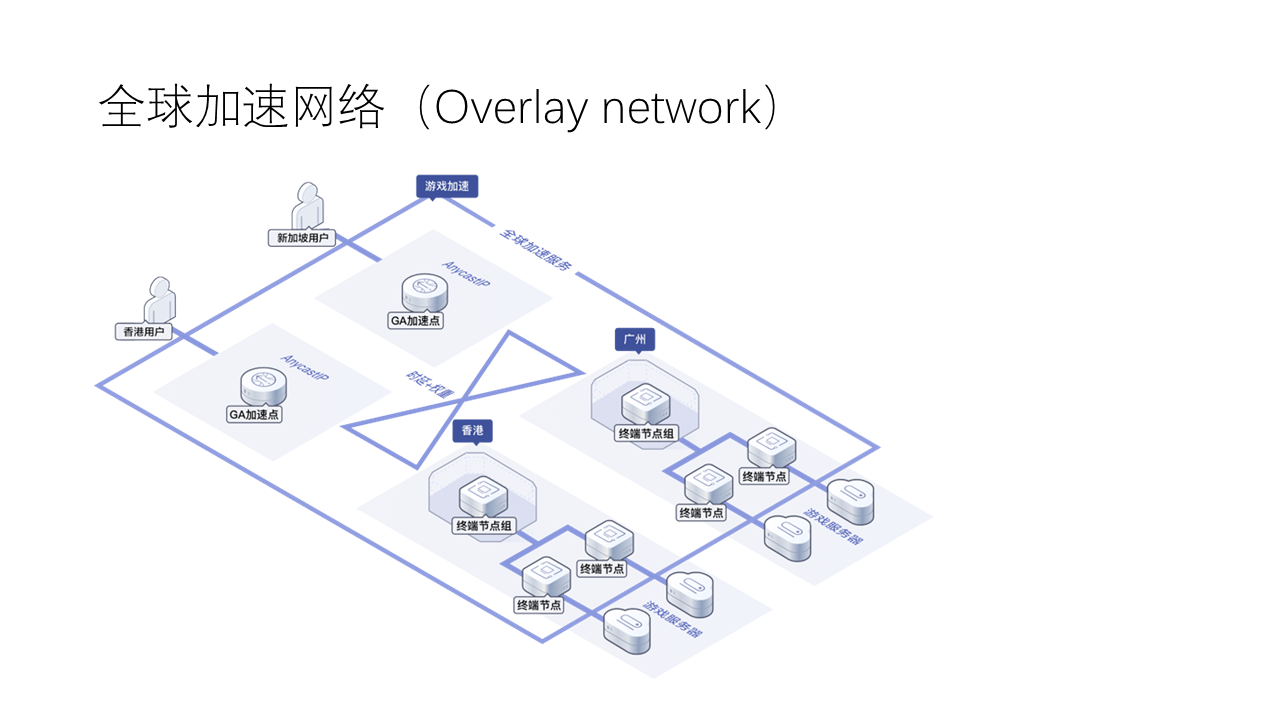
Based on the above high-performance inter-cloud network, we can not only accelerate the communication between servers across data centers, but also accelerate the access of end-side users to cloud-based services. Many cloud service providers, including Huawei Cloud, provide a global acceleration overlay network. The so-called overlay network is a virtual network composed of a logical topology overlaid on the basis of the physical network topology.
As shown in the figure above, the service first connects to the nearest global acceleration overlay network entrance node through the Internet, and then the overlay network routes the packets to the corresponding data center. The global acceleration overlay network belongs to the inter-cloud network, which is passed through dedicated lines or service provider-optimized Internet links. Compared with cross-regional, long-distance Internet networks, in many cases, first accessing the overlay network and then routing to the target data center server within the overlay network has lower latency, higher bandwidth, and lower packet loss rate than directly connecting to the same server via the Internet. Here, the end-cloud network communication is accelerated by the inter-cloud network.
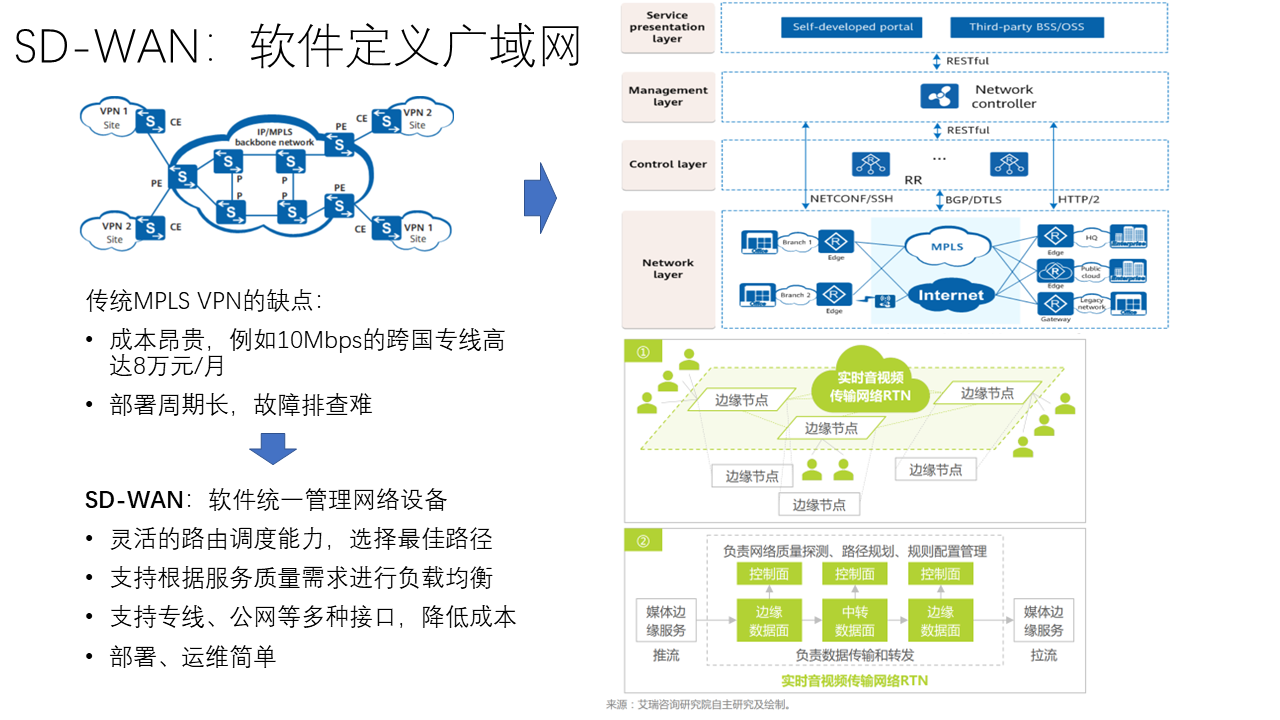
In terms of wide area network management, the industry has widely adopted the SD-WAN (Software-Defined WAN) method, inheriting the concept of SDN (Software-Defined Network). In SD-WAN, software uniformly manages network devices, and network controller software can manage and configure network devices from various manufacturers through standard interfaces such as RESTful, thus having flexible routing scheduling capabilities, supporting load balancing according to QoS (Quality of Service) requirements, supporting various access methods such as dedicated lines, Internet, and simplifying deployment and operation.
SD-WAN can also manage CDN and other edge nodes. The software control plane of the Real-Time Video and Audio Transmission Network (RTN) based on SD-WAN uniformly manages edge nodes and data center nodes, responsible for network quality detection, path planning, rule configuration management, etc.; while the data plane is responsible for data transmission and forwarding.
Chapter Summary
The above is the content of the wide area network part.
Large-scale live broadcasting and short video on-demand, real-time audio and video communication and other applications pose new challenges to the stability of wide area network transmission. Internet giants have built their own global acceleration networks and designed new transport protocols such as QUIC to achieve a high-quality user experience. In addition, due to the low energy cost in the western part of our country, the strategy of “computing in the east and calculating in the west” has become a national strategy. Through Regionless scheduling, a “nationwide integrated large data center” is realized.

We are basically studying the problems in end-cloud wide area network communication and inter-cloud wide area network communication, and we have some preliminary results, but they have not been officially released, so what I talked about today are mainly some existing technologies in academia and industry. Students who are interested are welcome to intern or work in our Computer Network and Protocol Laboratory. We have a very strong team, undertaking the R&D work of company strategic projects, and I believe that the technology is world-leading.
Next, I will talk about the latest technology in the wireless network field.