The New Golden Age of Computer Networking (Part One): Data Center Networks
(This article is organized based on the speech I delivered at Peking University on December 12, 2022, first converting the conference recording into a draft using iFlytek’s speech recognition, then polishing it with GPT-4 to correct errors from voice recognition, and finally manually adding some new thoughts)
I am very grateful to Professor Huang Qun and Professor Xu Chenren for the invitation, and it is an honor to come to Peking University to give a guest lecture for their computer networking course. I heard that you are all the best students at Peking University, and I could only dream of attending Peking University in my days. It is truly an honor to have the opportunity to share with you some of the latest developments in the academic and industrial fields of computer networking today.
Turing Award winner David Patterson gave a very famous speech in 2019 called “A New Golden Age for Computer Architecture”, which talked about the end of Moore’s Law for general-purpose processors and the historic opportunity for the rise of Domain-Specific Architectures (DSA). What I am going to talk about today is that computer networking has also entered a new golden age.

The computer networks we come into contact with daily mainly consist of three parts: wireless networks, wide area networks, and data center networks. They provide the communication foundation for a smart world of interconnected things.
Among them, the terminal devices of wireless networks include mobile phones, PCs, watches, smart homes, smart cars, and various other devices. These devices usually access the network through wireless means (such as Wi-Fi or 5G). After passing through 5G base stations and Wi-Fi hotspots, the devices will enter the wide area network. There are also some CDN servers in the wide area network, which belong to edge data centers. Next, the devices will enter the data center network. In the data center network, there are many different types of devices, such as gateways, servers, etc.

Today, I will introduce you to data center networks, wide area networks, and terminal wireless networks. First, let’s look at data center networks. The biggest change in data center networks is the evolution from simple networks designed for simple web services to networks designed for large-scale heterogeneous parallel computing, performing tasks traditionally handled by supercomputers, such as AI, big data, and high-performance computing.
From Web Services to Large-Scale Heterogeneous Parallel Computing

Traditional data center networks were designed for web services that are easy to parallelize. When our mobile phones access the data center network, they first enter a layer 4 load balancer, then a layer 7 load balancer. The layer 4 load balancer is responsible for distributing different connections to different servers, while the layer 7 load balancer can further distribute these connections to the business web servers according to certain strategies. Nginx is a typical layer 7 load balancer.
Our business web servers are usually written in languages such as Python, Java, or Node.js. When processing the business logic of HTTP requests, the web server may access a memory cache server or a database. For disaster recovery, database servers generally have multiple replicas, as shown in the figure above, where white represents the primary node and black represents the backup node.

In fact, traditional web services are not sensitive to the latency of data center networks. For example, the latency of opening a web page on a website I developed at school using Flask is basically on the order of seconds. The latency of processing the web page is on the order of hundreds of milliseconds, and users can hardly perceive latency within hundreds of milliseconds. The latency of wide area networks is usually on the order of tens to hundreds of milliseconds, and even if the latency within the data center network is on the order of milliseconds, compared to the data processing latency (including database latency and business processing latency) on the order of hundreds of milliseconds, it is actually a smaller order of magnitude. Therefore, the latency of data center networks is not a key factor in this scenario.
From the figure above, we can see that the backend rendering time of the entire web page took more than 1000 milliseconds, of which Flask’s backend business logic occupied 134 milliseconds of CPU time, and most of the remaining time was spent on database queries, i.e., the execution of SQL statements. Some database queries may not be well optimized and take a long time, needing 720 milliseconds; while some queries may only need a few tens of milliseconds or even a few milliseconds.

We mentioned earlier that web services are not sensitive to the latency of data center networks. On the other hand, web services are relatively easy to scale, that is, it is easy to improve overall performance by increasing the number of machines.
Specifically, when one application server is not enough, we can increase the number of load balancers. As mentioned before, layer 4 load balancers can achieve load balancing through hardware, while layer 7 load balancers can distribute different network connections to different business servers through software. This way, a very high degree of concurrency can be achieved. On the business web servers, each HTTP request can actually be processed in parallel.
For memory cache servers, since the capacity and processing power of a single server cannot meet the needs of all users, there are actually multiple memory cache servers. Generally, memory cache servers store a large number of key-value mappings, where the key and value can be simply understood as a string. Thus, memory cache servers can shard based on the hash value of the key, that is, each key-value server is responsible for a range of key-value mappings.
In actual applications, database servers usually have multiple units, partly to expand database capacity and processing power, and partly for disaster recovery. When a database cannot fit on a single server, the database administrator (DBA) needs to distribute the data across multiple servers, also known as sharding. Specifically, data can be partitioned horizontally or vertically. By dividing multiple tables, the database not only expands its capacity but also enhances its processing power.

If we only consider traditional web services, the existing data center networks and the kernel’s TCP protocol stack are already sufficient to meet the demand. So why do we say that computer networking has entered a new golden age? Whether it’s networking, systems, or architecture, the two biggest drivers are always application demand and hardware capability.
The fundamental reason why data center networks have developed so fast is that emerging businesses such as artificial intelligence (AI), high-performance computing (HPC), big data, and storage have higher requirements for bandwidth and latency. And our network hardware performance has not yet hit the ceiling, able to match the needs of applications. New network hardware brings new demands to the upper-layer software and systems, leading the entire industry to continuously have new things to do.
Taking the stable diffusion generation model of 2022 as an example, this computer vision (CV) generation model is astounding, capable of generating exquisite images based on user input prompts. The training of this model used 256 Nvidia A100 GPUs, consuming 150,000 GPU hours, totaling a cost of 600,000 US dollars.

Two weeks ago (Note: relative to December 12, 2022), OpenAI released ChatGPT, an AI Q&A system based on GPT-3.5 and InstructGPT. Many people may not yet be familiar with ChatGPT. In fact, ChatGPT has powerful capabilities, first of all, its strong thought chain ability. Given a prompt, it can generate answers based on the user’s thought process. Secondly, it has excellent code logic thinking ability, capable of writing code such as Protocol Buffers address books. In addition, it can also help fix bugs in the code. Compared to traditional NLP large models, a significant advantage is its excellent memory ability, able to review previous content and solve the problem of reference. In the past field of natural language processing (NLP), various tasks needed to be processed separately, but in ChatGPT, all these problems have been solved in a unified manner. Although ChatGPT has not yet become widely popular (Note: original speech content from December 12, 2022), it will undoubtedly become a disruptive innovation in the future.

The previous generation model of GPT-3.5, GPT-3, already had 175 billion parameters, requiring 350 GB of GPU memory just for inference, which definitely cannot fit on a single GPU card and requires multiple GPU cards to form a distributed inference cluster. Training requires storing the state during backpropagation, needing even greater memory capacity. The training cost of this model was as high as 12 million US dollars, possibly requiring a cluster of tens of thousands of GPUs for training. Although the scale of GPT-3.5 is not yet clear, it is likely also a huge model. The fundamental reason why the model needs to be so large is that it stores a lot of knowledge, from astronomy to geography, and understands multiple languages.

Let’s take a look at the trend of increasing computational power and memory requirements for these AI models. In 2012, the earliest AlexNet was introduced; then came GoogleNet in 2014; followed by Seq2Seq in 2015, ResNet in 2016. In 2018, AlphaGo and AlphaZero appeared, and finally, GPT-3 and others in 2020. We can see that from 2012 to 2020, the demand for computing power of these models has grown very fast, increasing by 300,000 times. This growth rate is not like Moore’s Law, which doubles every 18 months, but rather, it doubles 40 times within 18 months, which is astonishing.
However, our AI computing power, that is, the computing power of a single GPU, actually still relatively follows Moore’s Law, because it is, after all, hardware. Such a huge gap in demand requires us to use distributed parallel computing to meet these needs.
From another perspective, the memory requirements of large models are also very significant. We can see that the memory demands of different models are growing, with larger models typically meaning higher memory requirements. For example, ChatGPT, which we mentioned earlier, cannot fit into a single GPU and requires more GPU resources to complete inference.
The scale of the cluster needed for training is even larger; ChatGPT likely uses thousands of cards for parallel computing. The communication bandwidth required between these GPUs is extremely high, needing to reach more than 100 GB/s, far exceeding the bandwidth currently provided by Ethernet or RDMA networks. Therefore, new models have a high demand for data center networks. Currently, communication within small-scale GPU clusters is done through ultra-high bandwidth NVLink dedicated hardware, with bandwidths up to 900 GB/s. However, NVLink can only be used for small-scale interconnects of a few hundred cards, and large-scale interconnects still have to go through the Infiniband network, which is dozens of times slower than NVLink, with bandwidths only reaching 20 GB/s.

Traditional network protocol designs date back to the 1970s and 1980s, when the development speed of processors exceeded that of networks, and applications were not sensitive to network communication latency and bandwidth. Therefore, network protocols were processed by software on the CPU. The software stack on the CPU is actually quite complex and very costly.
Although the latency of data center network hardware is at the microsecond level, due to the complexity of the network protocol stack, the latency may increase by dozens of times at the application layer, even reaching the level of hundreds of microseconds at the RPC layer. For example, it only takes 30 minutes to travel from Beijing to Tianjin by high-speed rail, but because it takes two hours to take the subway within the city, the end-to-end time may need four hours. Google once estimated that about 25% of CPU resources are wasted on the network protocol stack, including memory copying, RPC calls, serialization, memory allocation, and compression. Google calls it the “data center tax,” meaning that this burden is too heavy.

In fact, even if we reduce the latency to the microsecond level, many applications cannot fully utilize this low latency. One reason is the latency hiding problem. What should the CPU do while waiting for these microsecond-level events, such as network communication or reading and writing storage devices? In traditional computer architectures, the CPU pipeline can well hide nanosecond-level events. That is, while waiting for these events, the CPU can execute other instructions without software intervention. However, for events with microsecond-level latency, the depth of the CPU pipeline is not enough to hide the latency, so the CPU will stall waiting for this slow instruction, which is very inefficient.
For millisecond-level events, the operating system can handle these task switches, which is the responsibility of software. The operating system can complete process or thread switches in just a few microseconds, so it does not waste too much time. However, if the event itself is at the microsecond level, such as accessing storage taking 10 microseconds or accessing high-speed networks taking 3 microseconds, switching the CPU core to another process or thread at this time would take several microseconds by the operating system itself. Switching to another process or thread and then switching back, the time spent in this process may be longer than waiting for the event to complete. Therefore, for microsecond-level latency, the task switching of the operating system is actually wasting time.
Neither the architecture nor the operating system mechanisms can hide microsecond-level latency, and today’s most advanced network and storage hardware latency has been reduced to the microsecond level, which is the reason for the microsecond-level time hiding problem.
Programming Abstraction: From Byte Streams to Memory Semantics

Next, I will introduce some methods to solve the above problems. First, let’s consider from the perspective of programming abstraction. Programming abstraction is a key part of any system, involving the design of functions and corresponding interfaces. A famous architectural design principle, “form follows function,” also applies to the field of software engineering, meaning that the interface design must follow the description of the function.
Many of us, including myself, are accustomed to making improvements on the basis of others’ ecosystems, always wanting to ensure compatibility and improve performance a bit, but not daring to propose our own ecosystem. This is a kind of ecosystem superstition. Historically, systems with significant influence are mostly not those that improved the performance of existing systems by 10 times, but those that proposed their own systems and programming abstractions, meeting new business needs or making good use of new hardware capabilities.

Originally, we used socket based on byte stream semantics, which is a beautiful programming abstraction that embodies the UNIX operating system’s design principle of “everything is a file,” treating network communication channels as files. However, the abstraction of byte streams is not very useful in many scenarios because it lacks the concept of message boundaries. When sending 1024 bytes on the sending end, what is received on the receiving end may not be a whole of 1024 bytes, but divided into two parts. This requires the application to do the work of message reassembly.
To solve this problem, some new programming abstractions gradually introduced the concept of message boundaries. For example, message queue systems like ZeroMQ and RabbitMQ provide a message-based abstraction. In this abstraction, data is organized into individual messages, each with a clear boundary. This makes it unnecessary for applications to worry about how to ensure message boundaries. This new abstraction makes the development of distributed systems simpler and more efficient.
If our ultimate goal is to provide message-based semantics, why do we need to first provide a byte stream semantics and then encapsulate a message semantics on top of it? Therefore, some of the latest network protocol stacks build message semantics directly on top of unreliable datagrams. A typical example is RDMA (Remote Direct Memory Access). RDMA supports a communication model called “Send-Receive,” where the sender places a message in a send buffer and then lets the network card send it, and the receiver first registers the receive buffer to the network card, then the network card writes the data into the receive buffer and notifies the receiver. This method of pre-registering buffers avoids the problem in byte stream-based message semantics where data must be copied, further improving performance.
Beyond message passing, we have a more advanced programming abstraction, which is remote memory access. Whether it’s byte streams or message semantics, the object of a program’s communication is always another program, but why can’t we let programs directly access remote memory? That is, issue instructions to directly read and write remote memory over the network. We might ask, what is the use of this remote memory access semantics?
First, I can allow multiple programs to share a piece of remote memory, that is, to access a piece of memory as if it were shared by multiple nodes, which is called memory pooling. Secondly, if the application on the other side stores some data, such as a hash table, then accessing this data might not need to involve the other side’s CPU, that is, to complete the operations of adding, deleting, modifying, and querying the data structure without disturbing the other side’s CPU. Of course, not disturbing the other side’s CPU requires hardware support, which is also the RDMA (Remote Direct Memory Access) technology of read, write, and atomic (atomic operations). For example, atomic operations are memory operations that can be initiated locally but completed remotely.
RDMA’s remote memory access operations are all completed asynchronously, while local memory access operations are synchronous. Some people have proposed, since local operations can be synchronous, why can’t we introduce synchronous memory operations to remote access? Of course, in the case of RDMA, because of the higher latency, it is not very suitable to make the operation synchronous. Because synchronous operations mean blocking the CPU pipeline, that is, the CPU cannot perform other tasks while waiting for access, which would lead to inefficiency.
In new interconnect buses like CXL, because of the extremely low latency, such as only two to three hundred nanoseconds, lower by an order of magnitude than RDMA’s latency, we can introduce load, store such synchronous operations. That is, let the CPU directly access remote memory as if it were accessing local memory, without the need for application modifications. This greatly facilitates application programming, but the consequence is that accessing remote memory in smaller granularity, so its efficiency may be lower than that of asynchronous access.
Beyond byte stream messaging and remote memory access, we also have a communication method called RPC, which is actually an interaction between programs, that is, remote calling. We are all familiar with function calls in programming languages, which are local calls. If we want to call a function in another program, we need to implement it through RPC. Now there are many RPC frameworks, such as gRPC and Thrift, etc.
We collectively refer to message semantics, remote memory access, and RPC as memory semantics. The definition of this memory semantics may be broader than most people think, that is, most people think that only direct access to remote memory by programs is called memory semantics, but in fact, we consider message semantics and RPC also belong to memory semantics, because they all involve interactions between programs and memory.

So, why do we need memory semantics instead of byte streams? First, as we mentioned earlier, the abstraction level of byte streams is too low, lacking the concept of message boundaries, so applications need to perform packaging and unpacking, adding extra memory copying.
Secondly, byte streams are an ordered stream, so they cannot fully utilize the parallelism in communication, such as using multiple physical links, with different physical paths in data centers, and wireless networks have Wi-Fi and 5G.
At the same time, byte streams cannot distinguish the importance and priority needs of messages, so within the same stream (the same connection), it is not possible to serve according to priority. If you want to distinguish priority, then you can only establish multiple connections, which means maintaining a large number of connection states and reserving buffers for each connection, leading to a large memory footprint. A large memory footprint is not just a problem of memory overhead, but also occupies a lot of cache, leading to a reduced cache hit rate, thereby reducing the performance of the entire network protocol stack in processing packets.

RDMA technology is actually a software-hardware combined efficient implementation of memory semantics. Under the same hardware, if using the traditional TCP socket protocol stack, it takes about 30 microseconds, but if using RDMA protocol, it only takes 2 microseconds, 15 times faster. This is because it moves many tasks originally completed by software in the kernel to hardware, improving speed through hardware acceleration.
Although RDMA has high performance, its use is relatively more complex compared to TCP socket. The main reasons are: first, RDMA memory needs to be registered to the network card in advance for access, these memories need to be bound, that is, they cannot be swapped in and out, because the network card uses physical addresses rather than virtual addresses to access memory. Second, to achieve zero-copy, both sending and receiving operations are asynchronous. On the sending side, you can asynchronously wait for the send to complete, while on the receiving side, you need to specify the receive buffer in advance and asynchronously wait for the receive completion event generated by the network card. To implement kernel bypass transport protocol stack, it is also necessary to create send and receive queues registered to the network card hardware, to interact directly with the network card in user mode.
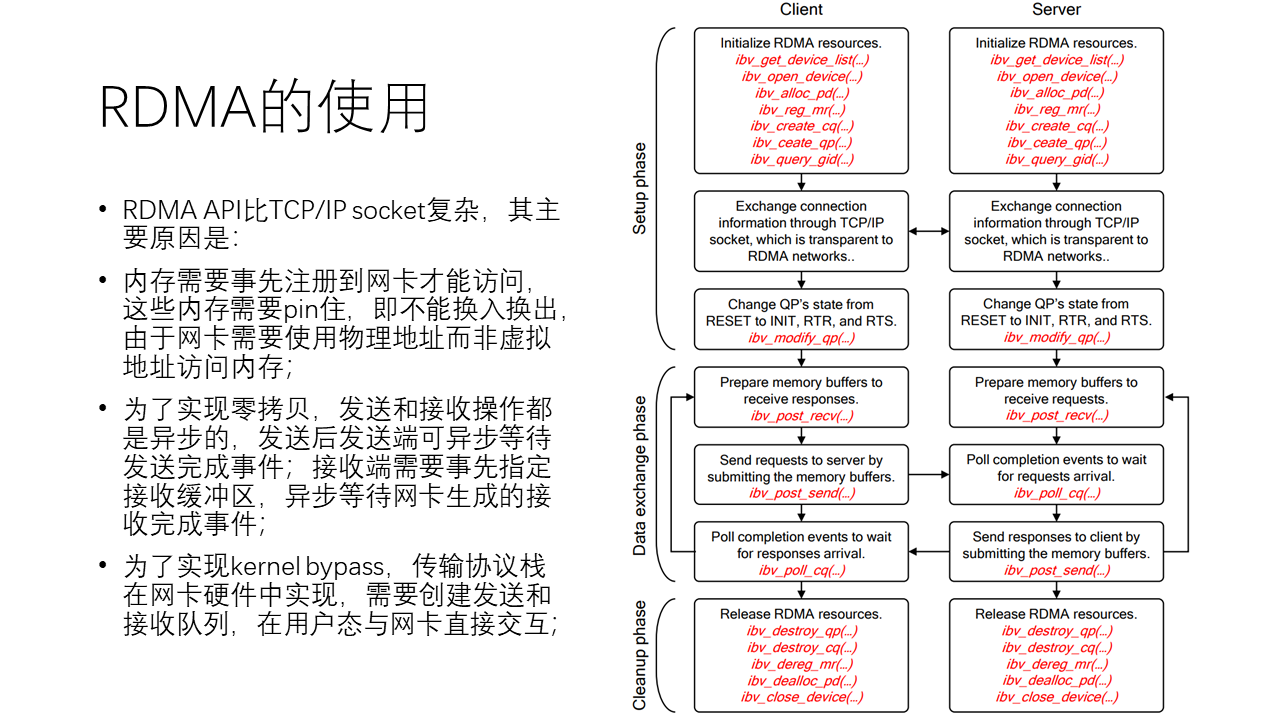
From the above figure, we can see that when using RDMA, on the control plane, it first requires the creation of many send and receive queues as well as resources, and then it also needs an out-of-band channel to exchange information with the other party. Finally, the queue state needs to be set to ready to send, which means it is in a state ready for sending. On the data plane, many memory buffers need to be prepared before a request can be initiated. After initiating a request, it is necessary to wait for a completion event. The whole process is an asynchronous and relatively complex process. Lastly, after using RDMA, all RDMA resources need to be released.
In summary, memory semantics have a higher level of abstraction and better performance compared to byte streams, making them better suited to the needs of modern high-speed network communications. Although the use of technologies like RDMA is relatively complex, they still provide significant performance improvements in many scenarios. To lower the barrier to using RDMA, there are now many tools available to simplify their use, such as converting sockets to RDMA with technologies like SMC-R and rsocket, as well as RDMA-based RPC libraries like FaSST RPC and eRPC.
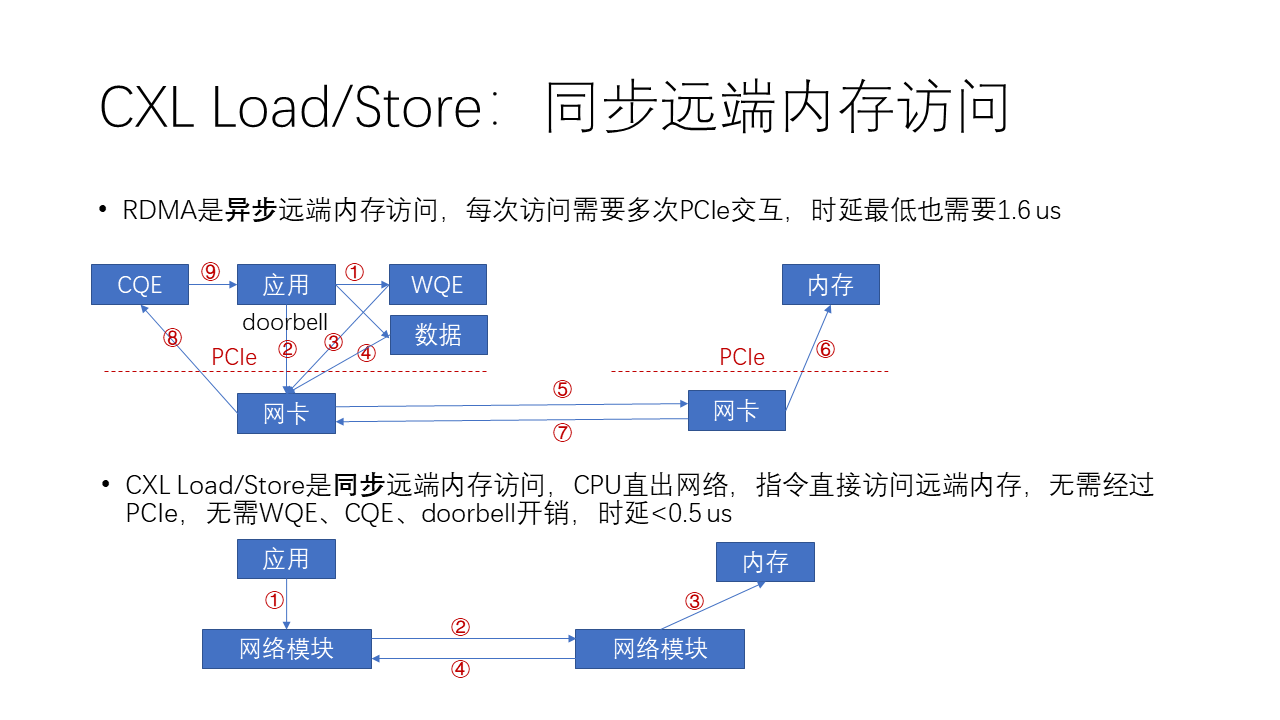
Compared to the more complex asynchronous remote memory access like RDMA, actually, CXL and NVLink offer a simpler memory access method, which is synchronous access. Why is it simpler? From the above figure, we can see that in RDMA, if you want to send data:
- The software first generates a WQE (work queue element), which is a work task in the work queue.
- Then, this task issues a doorbell, which is like ringing a doorbell to the network card indicating there’s work to be done.
- Next, the network card, upon receiving this doorbell, retrieves the work task from memory into the network card.
- Then, based on the address in the work task, it accesses the data in memory and DMA it to the network card.
- Following that, the network card encapsulates this data into a network packet and sends it from the local side to the remote side.
- Then, the receiving end’s network card, upon receiving this data, writes it into the remote memory.
- Next, the receiving end’s network card returns a completion message indicating the task is done.
- The initiating network card, upon receiving this completion message, generates a CQE in the local memory.
- Finally, the application needs to poll this CQE, meaning it needs to retrieve the completion event from the completion queue to complete the entire process.
We can see that the whole process is very complex.
Whereas CXL and NVLink are not as complex because their Load/Store is a synchronous memory access instruction, meaning the CPU (for CXL) or GPU (for NVLink) has a hardware module that can directly access the network unit. So, this instruction can directly access remote memory without going through PCIe, thus eliminating the need for WQE, CQE, and doorbell overheads, and the entire latency can be reduced to below 0.5 us. The whole process actually only needs 4 steps:
- The application issues a Load/Store instruction;
- The network module in the CPU initiates a Load or Store network packet, obtaining or transmitting data on the network;
- The network module on the other side performs a DMA, retrieving the corresponding data from memory;
- The data is then fed back through the network to the initiating network module, and then the CPU’s instruction is declared complete, allowing subsequent instructions to proceed.
Because the CPU has a pipeline that can already hide some of the latency of synchronous access instructions, it doesn’t need to stall the pipeline. However, it will reduce the parallelism of the CPU pipeline because the depth of the CPU pipeline is limited.
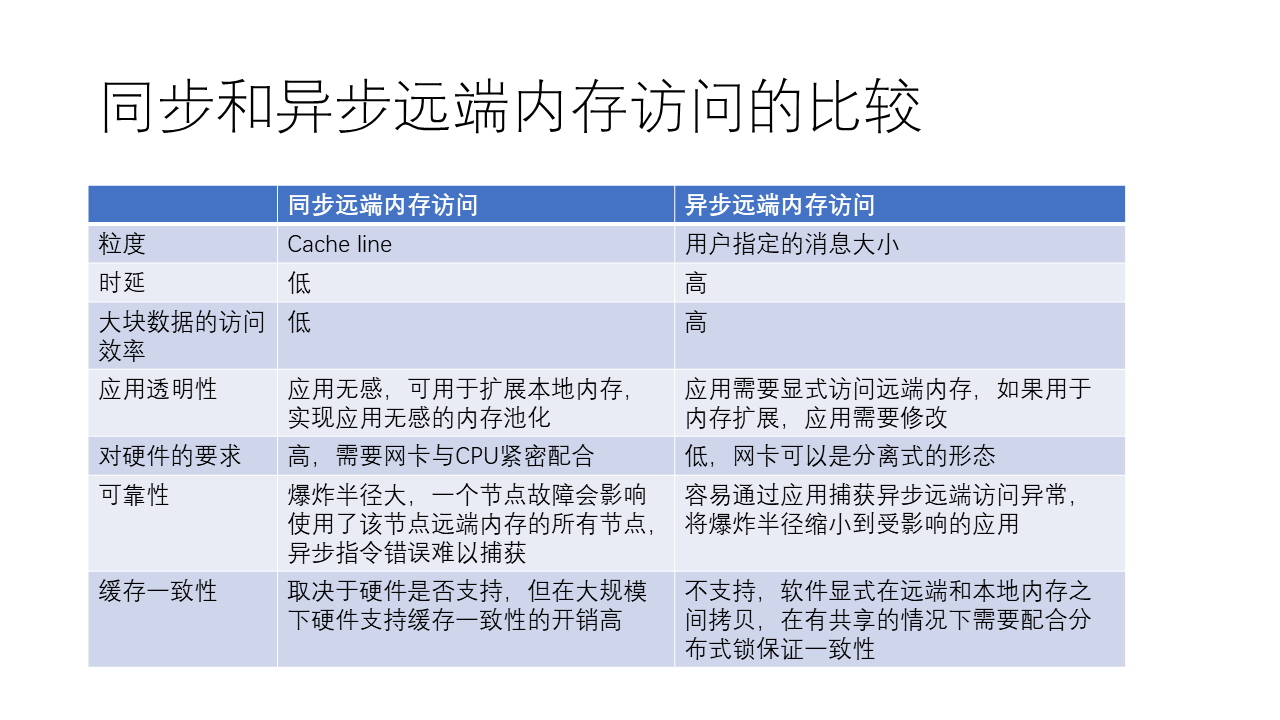
Overall, synchronous and asynchronous remote memory access each have their advantages and disadvantages. Synchronous remote memory access, such as CXL and NVLink, uses simple Load and Store operations, allowing remote memory access without too many complex steps. This method is simpler compared to asynchronous remote memory access, like RDMA, but also has certain limitations.
The advantages of synchronous remote memory access include:
- The process is simple, with a straightforward interaction flow, resulting in lower access latency.
- It is transparent to applications, allowing for the expansion of local memory without needing to modify the application.
- It may be more efficient when accessing smaller amounts of data.
- It may support cache coherence if the hardware supports it.
The disadvantages of synchronous remote memory access include:
- It requires high hardware demands, needing close cooperation between the network card and CPU.
- Each access typically involves a relatively small amount of data (usually a cache line, such as 64 bytes), so it may not be as efficient as asynchronous remote memory access when accessing large amounts of data.
- The reliability of synchronous remote memory access may be poorer, as a failure in one node could affect all nodes using the remote memory contributed by that node. There’s a concept known as “blast radius,” meaning if remote memory fails, it affects not just its own node, leading to an increased blast radius.
- The overhead of cache coherence at large scale is high.
The advantages of asynchronous remote memory access include:
- Users can specify the size of the data to be accessed, potentially making it more efficient when accessing large amounts of data.
- It has relatively lower hardware requirements, with network cards that can adopt a separate form, such as PCIe interface network cards.
- It allows applications to capture exceptions, thereby narrowing the impact to the affected application.
The disadvantages of asynchronous remote memory access include:
- The process is more complex, involving complex interactions with the network card, leading to relatively higher access latency.
- It is not transparent to applications, requiring explicit remote memory access, so if used to expand memory, the application needs to be modified.
- It does not support cache coherence, requiring software to copy between remote and local memory and use distributed locks to ensure consistency in shared memory situations.
Depending on the actual application scenario and requirements, developers can choose the appropriate memory access method. For scenarios that require accessing smaller amounts of data and have high latency requirements, synchronous remote memory access may be more suitable; whereas, for scenarios that require accessing large amounts of data and have lower latency requirements, asynchronous remote memory access may be more effective.
It’s worth noting that many communications on NVLink are still based on synchronous Load/Store, partly because GPUs have many cores, so it’s not too wasteful to use some cores for communication, and partly because NVLink has a small scale and low latency, only a few hundred nanoseconds. Although NVLink claims to support coherence, it actually supports limited coherence with page granularity and only one sharer, avoiding the classic problem in the field of distributed cache coherence of how to store a list of sharers. Since GPUs are mainly used in AI and HPC scenarios, communication on NVLink is primarily collective communication rather than data sharing, so limited coherence is generally sufficient.
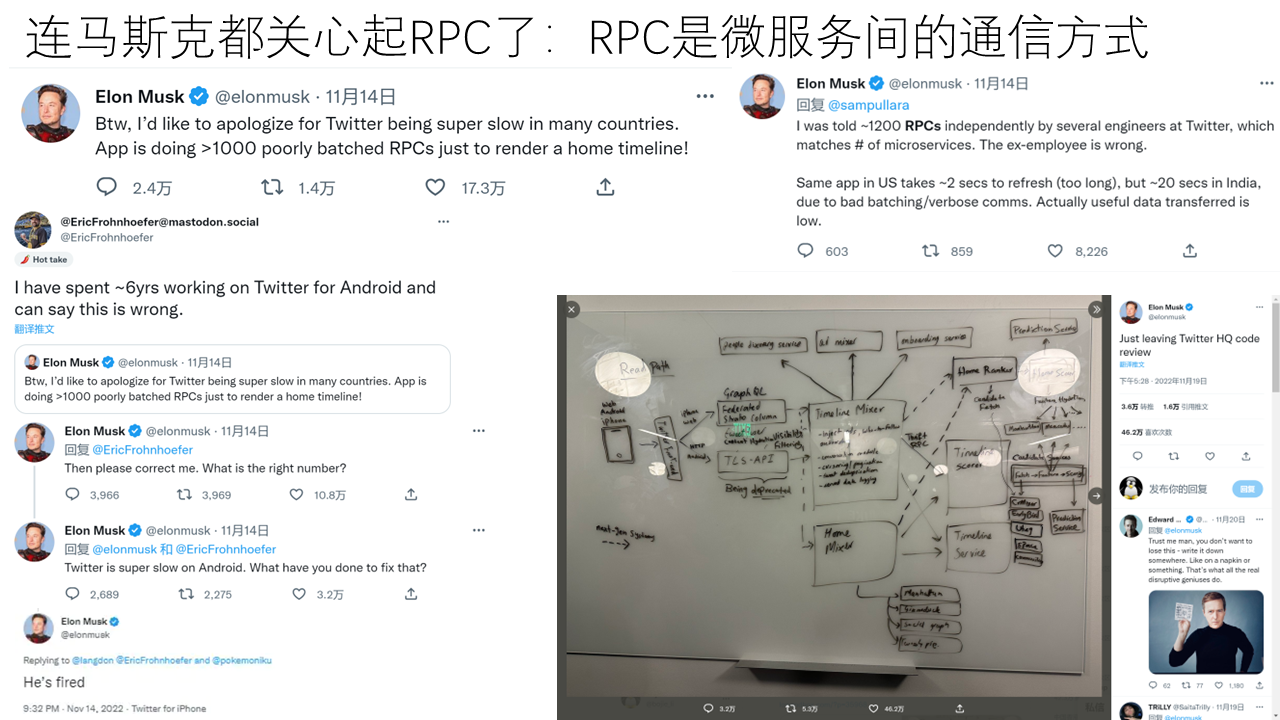
Next, let’s take a look at RPC, which stands for Remote Procedure Call. It is essentially a function call across hosts, processes, and languages. RPC is very important in internal communication within data centers, and it is a very versatile thing, with various microservices communicating through RPC. Google has a statistic that 95% of data center traffic is RPC.
Some time ago, we saw Elon Musk say on Twitter that RPC is particularly important, even firing an engineer who questioned him saying RPC is actually not important. Later, he added that, for example, accessing a Twitter homepage might require around 1200 RPCs. This shows that accelerating RPC is very valuable.
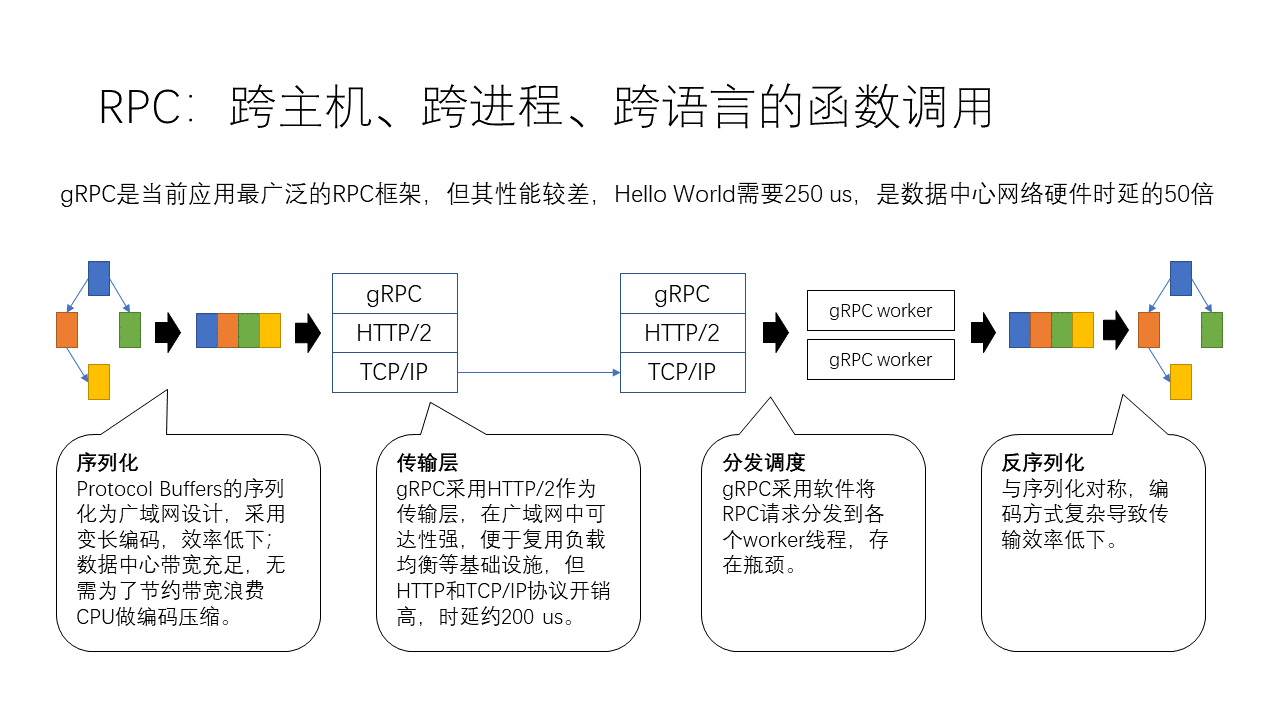
For example, our current gRPC is the most widely used RPC framework, but its performance is relatively poor. For instance, a simple Hello World program requires 250 microseconds, which is actually 50 times the latency of data center network hardware. So why is its overhead so high? Traditionally, we might think it’s because of the transport layer, but it actually has many issues.
- First, the biggest part is actually in serialization and deserialization, where it uses Protocol Buffers for serialization. This serialization scheme is designed for wide area networks, using variable-length encoding, so its efficiency is relatively low. In data centers, bandwidth is actually quite abundant, so there’s no need to waste a lot of CPU on such encoding compression to save bandwidth.
- Next is the transport layer, where gRPC uses HTTP/2 as the transport layer, which has strong usability in wide area networks, allowing for the reuse of various load balancing and other infrastructure. However, the parsing overhead of the HTTP protocol is very high, with the entire process including HTTP and TCP protocols possibly reaching nearly 200 microseconds.
- Another overhead is in dispatch scheduling, where software first collects requests from the TCP protocol stack and then distributes them to various work threads, encountering many bottlenecks in the process.
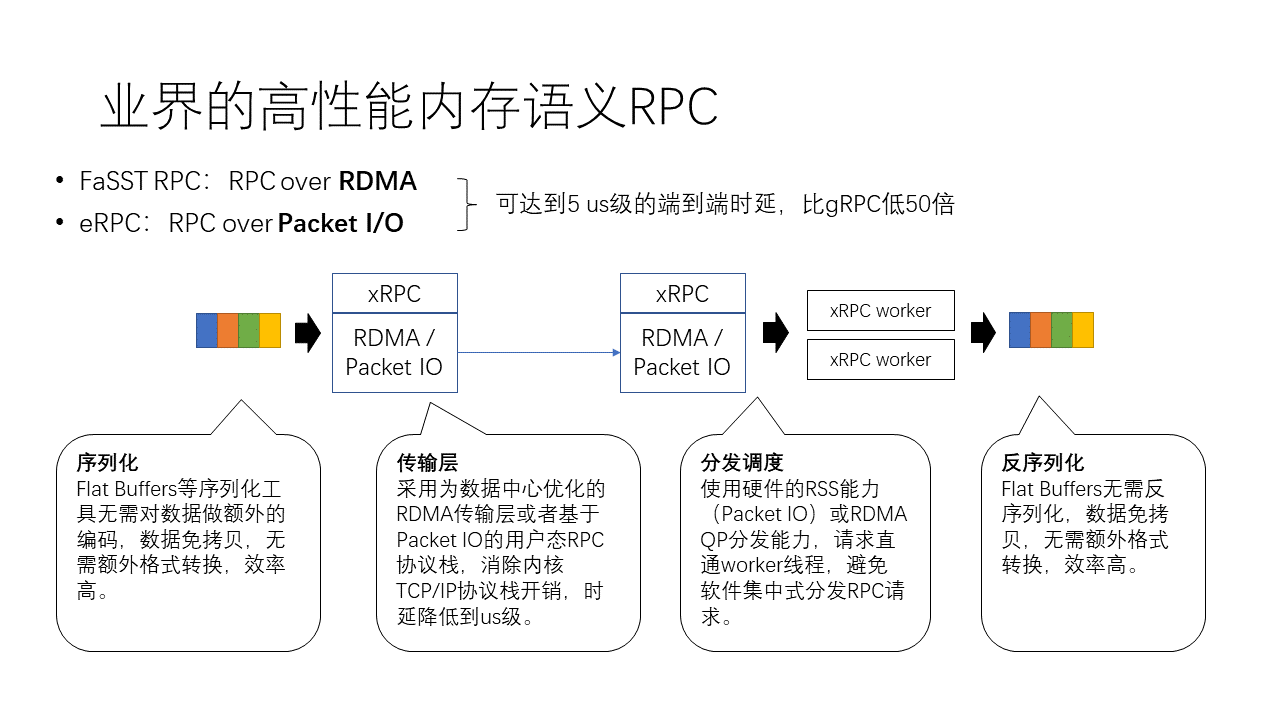
The academic community has explored high-performance RPC quite a bit. For example, an earlier work called FaSST RPC is based on RDMA RPC. We know that gRPC actually only supports the TCP/IP protocol, but FaSST RPC, by using RDMA, offloads the transport layer to hardware, achieving end-to-end latency of 5 microseconds, which is about 50 times the performance of gRPC. A recent work is eRPC, which can run based on Packet I/O, another approach, equivalent to placing the transport layer in software, but it is implemented in user space, not in the kernel, which is a user-space I/O approach. This method can also achieve very high performance.
In terms of serialization, we have tools like Flat Buffers and Cap’n Proto, which do not require additional encoding compression of data and store data continuously in memory when creating data structures, so data does not need to be converted back and forth between different data formats, making their efficiency relatively high. Flat Buffers and Cap’n Proto not only eliminate the work of serialization but also deserialization, directly reading from continuous memory when accessing data structures, without the need to create a large number of scattered native language objects.
In terms of the transport layer, the technologies mentioned earlier, such as FaSST RPC and eRPC, are optimized for data centers. They either implement hardware offloading based on RDMA network cards or use user-space protocol stacks based on Packet I/O to eliminate the overhead of the kernel TCP/IP protocol stack, thereby reducing latency to the microsecond level.
In the aspect of distribution and scheduling, network card hardware has the capability of RSS (Receive-Side Scaling) in Packet I/O mode, and when using RDMA, QP also naturally comes with the ability to distribute, allowing requests to go directly from the client to the RPC execution thread, avoiding centralized software distribution of RPC requests.
Treating the Data Center as a Single Computer

With such a programming abstraction of memory semantics for data center networks, we can treat the data center as a single computer.

Inside the data center treated as a single computer, we mainly consider two aspects. The first is to make the interconnection of data centers as efficient as the internal bus of a computer. The second is to make distributed system programming within the data center as convenient as programming on a single machine.
Making Data Center Interconnection as Efficient as a Computer’s Internal Bus
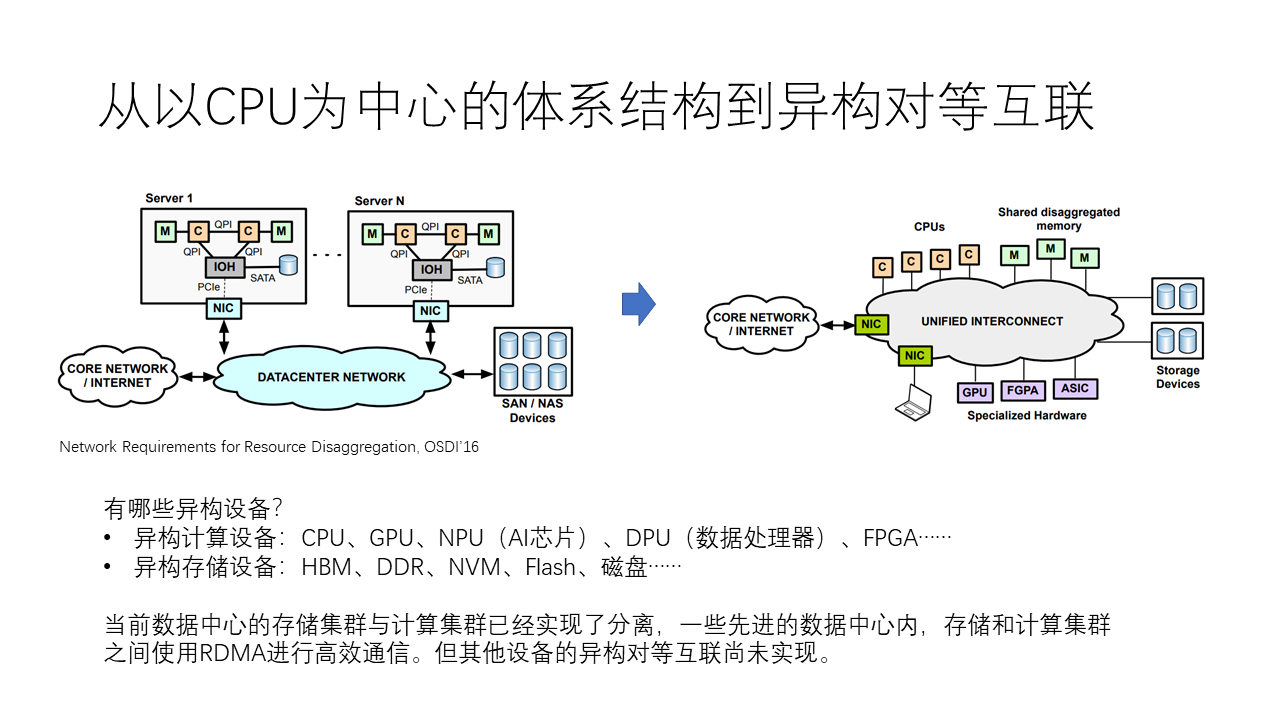
Starting from a CPU-centric architecture, we have developed it into a heterogeneous peer-to-peer interconnection architecture. Currently, the CPU is the absolute leader in computer architecture, but in the new architecture, we will have a variety of heterogeneous computing devices, including CPUs, GPUs, NPUs (Neural Network Processors, i.e., AI chips), DPUs (Data Processors), FPGAs, etc. At the same time, there are many different heterogeneous storage devices, including HBM, DDR, non-volatile memory (NVM), Flash SSD, etc.
Currently, storage clusters and computing clusters in data centers have been separated. In many advanced data centers, storage and computing clusters communicate efficiently using RDMA, but the heterogeneous peer-to-peer interconnection of other devices has not been fully realized.
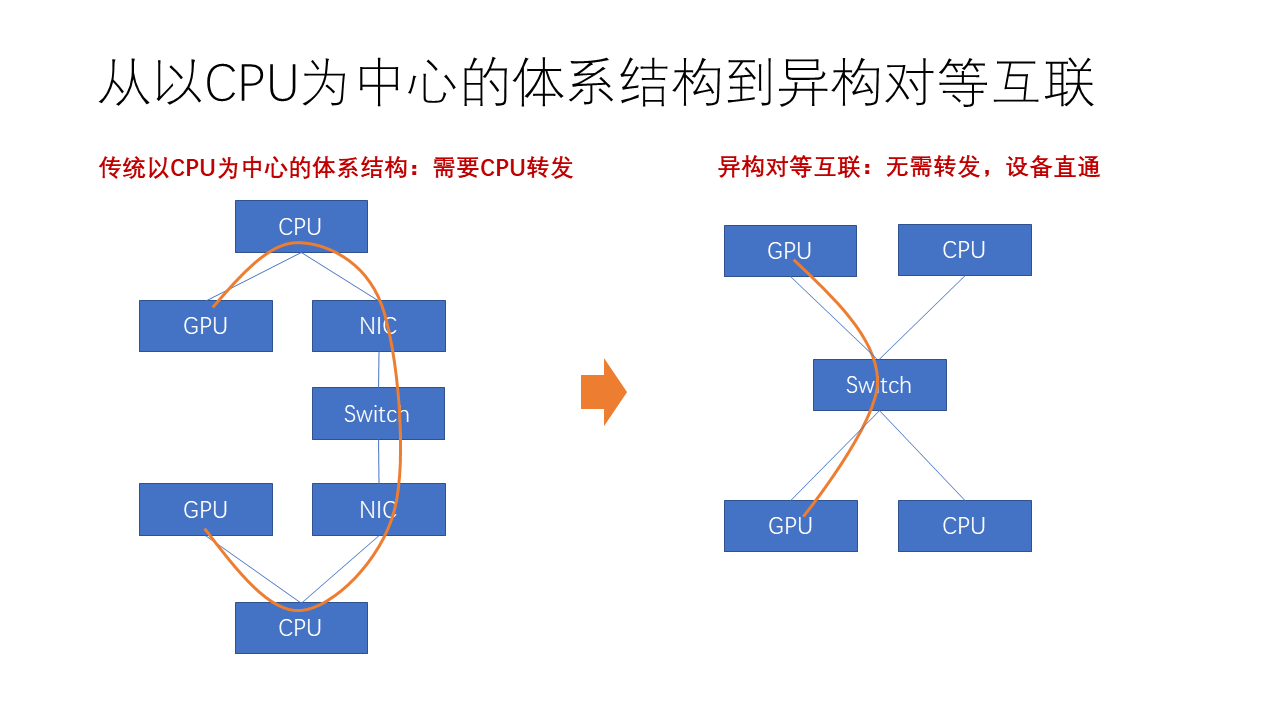
Why do we need to achieve so-called peer-to-peer interconnection? This is because the CPU-centric architecture often requires CPU for centralized forwarding. For example, suppose there are two machines, one GPU needs to communicate with another GPU. If there is no direct interconnection between these two GPUs, they may need to be forwarded through the CPU to the network card, and then communicate through networks such as InfiniBand, RoCE, or Ethernet. If the two GPUs are interconnected by NVLink, they can communicate directly with each other. However, the interconnection range of NVLink is limited, only able to interconnect a few hundred GPU cards. Beyond this range, CPU and network cards are needed for forwarding again.
In a peer-to-peer interconnection architecture, we no longer have differences such as GPU to GPU interconnection through NVLink or through Infiniband; they will be uniformly connected to a high-speed switching network. After implementing device passthrough, the scale of peer-to-peer interconnection can be greatly expanded. Thus, the performance of the computing cluster under large-scale tasks will be greatly improved, which is very helpful for training large models.
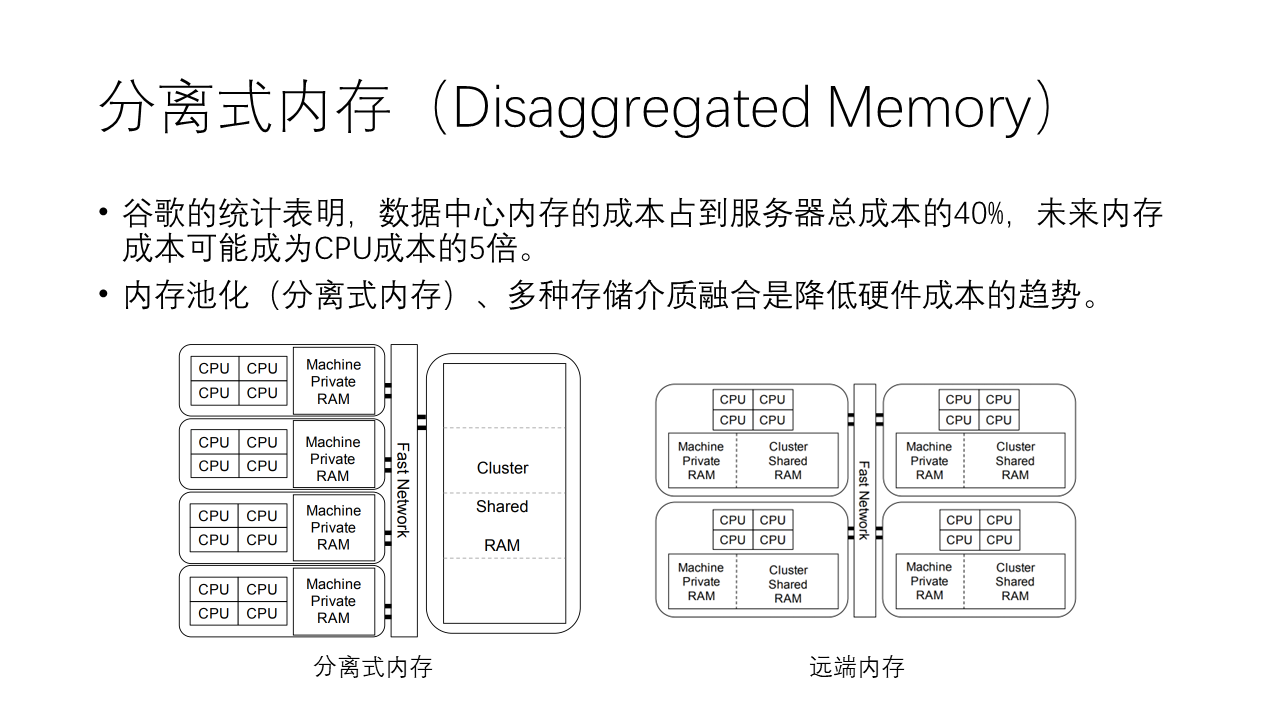
Another important trend is disaggregated memory. Google’s statistics show that the cost of data center memory accounts for 50% of the total server cost; Meta’s statistics also show that the cost of data center memory accounts for 40% of the total rack cost. Therefore, memory disaggregation and the integration of various memory media will become an important trend in reducing hardware costs.
Disaggregated memory means that each machine has a small space as private memory, and then connects to a shared memory pool through a high-speed network, with most of the memory in the shared memory pool. However, the feasibility of this scheme may not be high, because the bandwidth required by memory is very high, and the latency is very low. The current network bandwidth and latency are far from memory, which may lead to performance degradation. It’s like building a skyscraper and fixing all the toilets on the first floor.
In contrast, the remote memory approach may be more feasible. Each node has its own CPU and memory but can contribute a portion of memory for others to use. When local memory is insufficient, it can borrow memory from other nodes. We know that in the public cloud, the utilization rate of memory is relatively low, and many memories are idle, which can form a memory pool. Hot data is stored in local memory, and cold data is stored in remote memory pools.
In any computer architecture design, locality is key. The reason why complete disaggregated storage can be achieved is due to two reasons:
- The bandwidth required for storage is lower than the available bandwidth of the data center network, and the access latency of the storage medium itself is higher than the latency of the data center network, so the performance loss will not be significant. Even so, data center storage traffic has already accounted for more than half of the total data center traffic.
- Storage requires high reliability and cannot rely solely on local storage. When a server fails, the data in local storage may be lost, so it is necessary to replicate data to multiple nodes to achieve high reliability.
The bandwidth required for disaggregated memory may be higher than the available bandwidth of the data center network, and generally does not require multiple copies, so the cost of implementing it is higher than that of disaggregated storage.
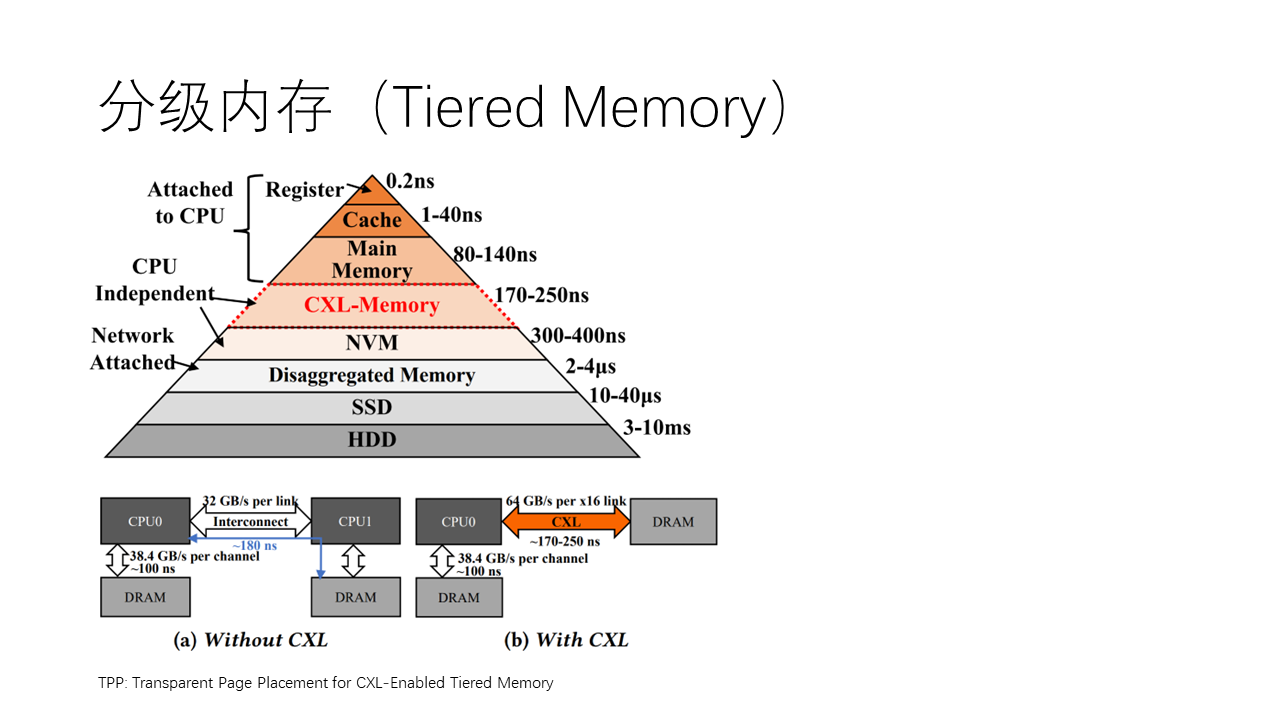
In addition to using remote memory to expand local memory capacity, another idea is to use tiered memory, i.e., tiered memory. The memory hierarchy is a classic problem that has existed since the first day of the computer’s birth, including local memory, remote memory, non-volatile memory (such as Intel’s Optane memory), and SSDs, HDDs, etc. This actually forms a huge storage pyramid, which we should all understand in computer architecture courses. In this pyramid, the upper layers have higher performance and higher prices, while the lower layers have lower performance and lower prices.
Jeff Dean listed a famous table Numbers Everyone Should Know (in the report Designs, Lessons and Advice from Building Large Distributed Systems), which talks about the storage pyramid. Some of the numbers may not apply today, but the ideas are profound and eternal. Those of us who work in computing must be sensitive to orders of magnitude, knowing the latency, throughput, power consumption, and price orders of magnitude of some key operations and system components, and be able to quickly estimate the orders of magnitude of various indicators of a system. This is called Back of the Envelope Calculations, which allows us to have a better feel for the system.

One question we are very concerned about is, if we use disaggregated memory or tiered memory, instead of traditional local memory, how much impact will it have on the performance of applications compared to using local memory alone? In fact, the impact is not as severe as everyone imagines.
A classic article called “Network Requirements for Resource Disaggregation” states that with only 25% local memory (i.e., 75% of the data is stored in remote memory), to achieve a performance degradation of no more than 5%, in applications with less intensive memory access, such as Hadoop, GraphLab, Memcached, etc., a network round-trip latency of 5 microseconds and a bandwidth of 40 Gbps are required. For applications with higher memory access requirements, such as Spark, PageRank, HERD, etc., a bandwidth of 100 Gbps and a round-trip latency of 3 microseconds are required.
We can see that, under the premise of storing hot data in local memory and cold data in remote memory, existing hardware (such as Mellanox’s network cards) actually meets the needs of applications without significant performance degradation, so application performance is not a big problem in many scenarios.
How to store frequently accessed data locally and infrequently accessed data remotely has become a key issue. There are two sub-issues here, first, how to identify the hot and cold data with low overhead, and second, how to migrate hot and cold data with low overhead. Many people in academia and industry are researching this.
Making Distributed System Programming as Convenient as Single-Machine Programming

Earlier, we discussed “making the network interconnection of data centers as efficient as the internal bus of a single computer.” Next, we discuss another aspect of “treating the data center as a single computer,” which is to make programming for distributed systems in data centers as convenient as programming on a single machine.
In 2009, Berkeley made many predictions about cloud computing, all of which have become reality:
- (Theoretically) unlimited computing resources
- Users no longer need to bear the work and responsibility of server maintenance
- The possibility of pay-as-you-go services
- Significantly reduced usage costs of super-large data centers
- Greatly reduced difficulty of operations through visual resource management
- Thanks to time-sharing multiplexing, the utilization rate of physical hardware has greatly increased
Berkeley proposed a very influential view: programming for distributed systems should be as convenient as programming on a single machine. To achieve this goal, they proposed many new programming models and frameworks. Some of the more well-known ones include MapReduce, Hadoop, Spark, etc. The core idea of these programming models and frameworks is to let programmers only focus on the logic of data processing, without having to worry about the underlying details of distributed systems, such as data partitioning, parallel computing, fault tolerance, etc.
This programming model has indeed simplified the development of distributed systems to some extent, but there are also some problems. First, these models usually can only handle specific types of tasks well, such as large-scale data processing tasks. For some complex distributed systems, such as distributed databases or distributed transactions, these models may not be very suitable. Second, these models and frameworks often have a high learning cost. Programmers need to learn a completely new programming language and concepts, which may be a challenge for many people.
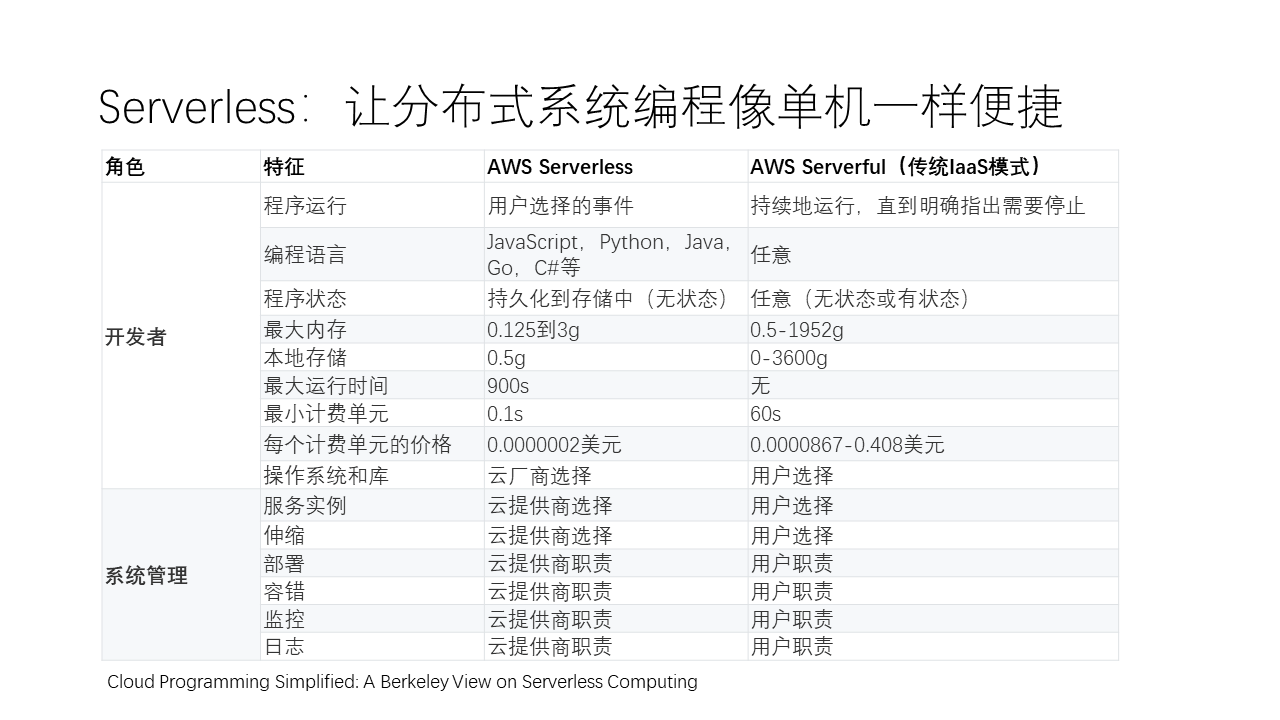
In 2019, Berkeley predicted that Serverless would become the next important application paradigm. Now, many cloud service providers, including Huawei Cloud, offer Serverless function services. Berkeley pointed out that Serverless services have some significant differences compared to the traditional IaaS model. The biggest difference lies in system management aspects, such as service instance scaling, deployment, fault tolerance, monitoring, and logging, etc., all of which are automatically handled by Serverless, whereas the traditional IaaS model requires manual handling by programmers and operation engineers.
For example, in IaaS, the following tasks are manually handled by programmers and operation engineers, but if using Serverless services, these issues are completely resolved by the Serverless service:
- Ensuring redundancy for availability, so the failure of one machine does not lead to service interruption
- Retaining geographically distributed redundant copies of the service in case of disaster
- Efficiently utilizing resources through load balancing and request routing
- Automatically scaling the system based on load changes
- Monitoring services to ensure they are always running healthily
- Logging for debugging and performance tuning
- System upgrades, including security patches
- Migrating to new instances when they become available
Moreover, in terms of program execution, Serverless allows users to choose event triggers for execution, whereas traditional models must run continuously until explicitly instructed to stop.
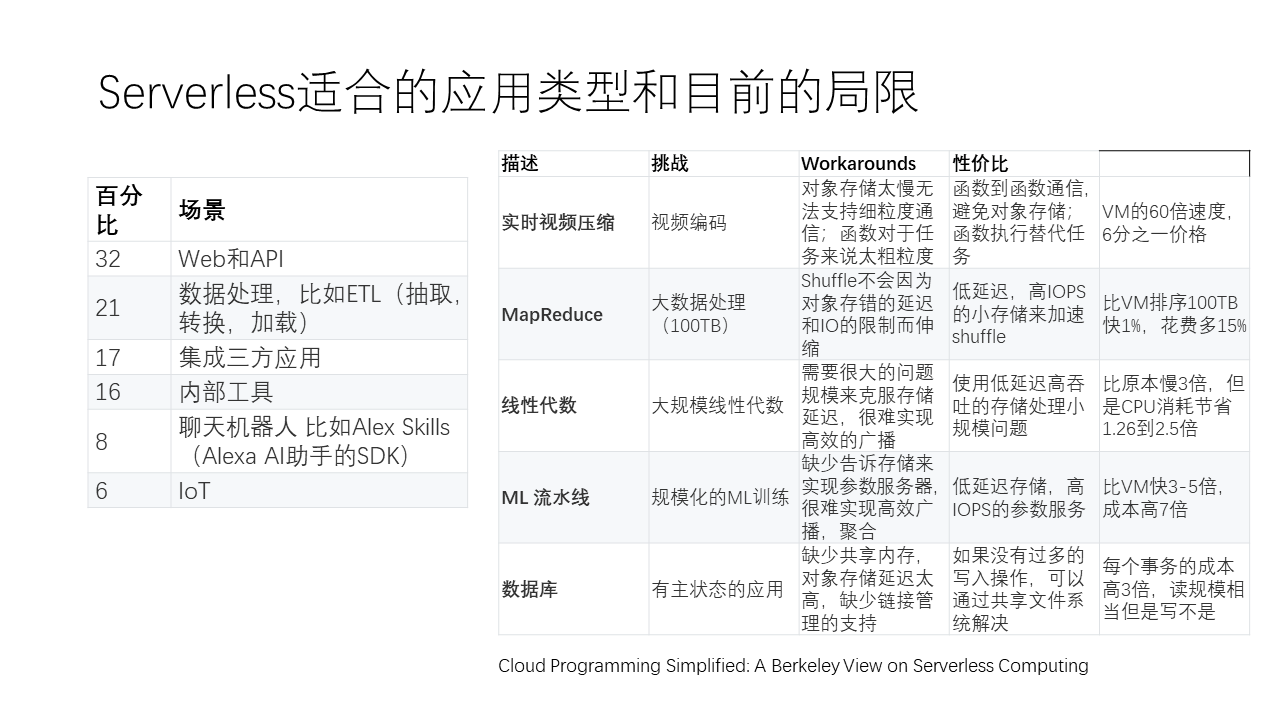
However, the current Serverless is not a panacea and has certain limitations in its applicability. The current Serverless is more suitable for stateless, short-duration applications, which may also have high burstiness, meaning that there are moments of very high traffic and other times when suddenly no one accesses the service. In such cases, using Serverless can effectively achieve automatic scaling of the service.
In terms of programming languages, traditional models can use any language, while Serverless may only support a few restricted programming languages. In terms of program state, AWS’s Serverless is a stateless service, whereas traditional models can be stateful or stateless. Some applications have very complex intermediate states, such as machine learning, linear algebra, or databases, etc., where the abstraction of Serverless poses significant challenges. As Berkeley’s article points out, the era of Serverless is just beginning, and these are issues that we need to further explore and solve.
Chapter Summary
This concludes the content on data centers.
Data center networks have traditionally been designed for easily parallelizable web services. However, AI, big data, HPC are all large-scale heterogeneous parallel computing systems that demand high communication performance. The heavy software stack causes significant overhead, requiring data center networks to evolve their communication semantics from byte streams to include message semantics, synchronous and asynchronous remote memory access, RPC, among others, achieving extreme latency and bandwidth through a combination of software and hardware. In the future, we hope to treat the data center as a single computer, on one hand, achieving direct throughput between heterogeneous computing and storage devices, making data center interconnects as high-performance as the internal bus of a host; on the other hand, making distributed system programming as convenient as single-machine programming through Serverless.

The issues mentioned earlier are mostly under research, with some initial results, but not yet officially published, so today’s talk mainly covers some of the existing technologies in academia and industry. Students interested are welcome to intern or work at our Computer Networks and Protocols Laboratory. We have a very strong team, undertaking the R&D work of strategic projects for the company, and I believe the technology is world-leading.
Next, I will talk about the latest technologies in the field of wide area networks and terminal wireless networks.