AI Agent 的两朵云:流式与环境交互,自主从经验中学习
🌐 语言:中文 · English
【本文整理自笔者在 Flink Forward Asia 2026(深圳,6 月 26-27 日)上的 keynote 演讲《AI Agent 的两朵云:流式与环境交互,自主从经验中学习》】

非常荣幸能有机会来到 Flink Forward Asia 给大家做这样一个报告。今天我的题目是「AI Agent 的两朵云」。这个概念大家可能听过:1900 年的时候,开尔文勋爵说物理学的天空上飘着两朵乌云,后来就有了相对论。我今天就借这个比喻,讲讲 Agent 面前的两个大难题:第一,Agent 如何流式地、实时地跟环境交互;第二,Agent 如何自主地从环境中学习——也就是像一个人一样,跟环境不断地交互,从这些成功和失败的经验当中去积累经验、积累知识。

这两朵云,对应 Agent 的两个大难题。第一朵云,是流式与环境交互:Agent 如何流式地、实时地跟环境去交互。第二朵云,是自主从经验中学习:Agent 如何像一个人一样,跟环境不断地交互,并从这些成功和失败的经验当中,去积累经验、积累知识。
一个判断:交互就是流式事件处理

为什么这个报告会放在 Flink 这边讲?一开始 Junhua 老师邀请我的时候,我也在想,Agent 跟 Flink 到底有什么关系。仔细一想,发现这里面关系很深——我们做的这套架构,跟 Flink 批流一体的思想是同源的。
传统的 ChatGPT 是一问一答,本质上是一个 Request / Response 的微批(microbatch)模型:用户问一句,攒齐了再算一次。但真正与世界实时交互的 Agent,需要的是真正的流(streaming),是逐事件处理、带 event-time 语义的。
举两个例子。第一,我现在讲话,你中间打断了我,那我必须立刻停下来听你说,而不能把这 20 分钟一口气念完。同时,你说话的过程中,我背后是要持续思考的——不可能等你讲完了才开始想下一句。如果一定要等对方讲完才开始思考,那就成了电视上国家领导人之间隔着翻译谈判的效果:每句话都要等翻译完才反应。第二,今天很火的 OpenClaw,相比之前的 Manus,最大的区别被很多人总结为有「活人感」:它会主动来找你,告诉你「有封邮件该处理了」。它怎么知道?传统 Agent 是你得先说「帮我查邮件」它才去查,邮件可能在收件箱里躺了两天;而 OpenClaw 每 4 小时就主动发起一次,背后是各种事件驱动的机制,跟 Flink 的 event-time 事件处理一模一样,让它能感知到世界上正在实时发生的事情。
报告结构:感知、认知、执行

讲流式交互这部分,我分成感知、认知、执行三个阶段来讲:
- 感知:模型如何感知到这个世界上发生的各种事情——既包括人的事件,也包括外部世界发生的事件,还包括 Agent 去跟其他人交互所产生的事件。
- 认知:如何做到一边实时地跟人交互,一边又能在背后深度思考。
- 执行:如何做到 Agent 经验的实时复用。
后面就按这个顺序展开。
Part 1 · 感知:世界进入模型 = Flink 的 Source

让 Agent 像人一样实时感知世界,本质上就是 Flink 里把外部数据源接进来、做好序列化的问题。
举一个最简单的例子:Computer Use Agent。用过的人都知道,它的典型工作方式是先截一张图,然后思考,思考完之后做一个操作——点一个按钮、或者敲一下键盘,然后再截一张图、再思考,是这么一个 loop。问题是,这样一个 loop 大概需要三到五秒。这就带来一个很大的局限:它根本没法看视频——像前面几位老师演示的那种实时视频,用这种「截图—思考—操作」的方法是做不出来的;它也参加不了实时的语音会议;甚至我点一个按钮之后弹出来一个警告框,如果这个警告框一秒钟后就消失了,它就当没看见,因为它根本来不及看到。

论文 · AOI: Agent-Computer Observation Interfaces
arXiv:2606.29472 · 网站 · GitHub
我们解决这个问题的方法,是把整个观测变成一个事件触发的处理流程,原理上跟 Flink 的流处理是一模一样的——所以我们把这个观测接口叫做 AOI(Agent Observation Interface)。具体来说:把实时输入的视频按关键帧拆成图片,画面有变化时才把这些帧送进去,没有变化时就只送一帧;语音则先用一个多模态模型理解成文本,再输入给模型。这样一来,虽然我们的 Agent 每次动作只能看到大约五秒的一张快照(现在的模型推理就是这么慢),它仍然能够持续地看视频、听语音,去跟界面上的那些动画元素实时交互。这正对应 Flink 里事件触发、按需处理的思路:只在真正有变化、有事件发生的时候,才付出算力。

论文 · Sema: Semantic Transport for Real-Time Multimodal Agents
arXiv:2604.20940 · 网站 · GitHub
感知里还有一个问题,是数据怎么传给模型。大家不知道有没有注意到会场两边的实时字幕——我看基本上每一个「Flink」都识别错了,很多专有名词也都识别错了。为什么会场这种实时字幕,通常会有这么多错误?根本原因是它的观测空间太窄了:它只看到当前这一小句话,就根据这一小句去做语音识别;而它背后又不是一个很大的模型,缺少世界知识、缺少领域知识,也缺少整场演讲的上下文,识别准确率自然就低。
这背后其实是一个更本质的问题:今天很多传输、识别系统的接收方已经是模型,而不是人,但它们还在按「给人看、给人听」的老假设来设计。这正是 Sema 这个工作的出发点——当接收方是模型时,我们可以围绕模型真正需要的语义去传输,而不必传那些只为人眼、人耳准备的冗余细节。
Part 2 · 认知:实时与智能,近乎正交

感知到世界之后,下一步是认知。这里有一个核心的矛盾:实时和智能,几乎是两条正交的轴。能做到实时响应的模型,往往推理偏浅;而推理很强的 SOTA 大模型,单次响应又比较慢,做不到实时。要同时拿到实时和智能,靠单一模型是很难的。

我们的解决思路是快慢分离:前台用一个小模型负责快速响应,维持实时的交互节奏;后台用一个 SOTA 大模型负责深度思考和深度规划。这其实就是 Flink 批流一体在 Agent 上的体现——前台的流处理求低延迟,后台的批处理求推理深度,两条 path 配合在一起。

具体到对话场景,Interactive ReAct 有两种形态。第一种是「边听边想」(Think While Listening)。传统的 ReAct,是用户把一整段话说完之后,Agent 才开始思考、调用工具、然后回答;而边听边想,是在用户还在说的时候,思考和工具调用就并行启动——用户一边说出需求(比如描述要找一个什么样的候选人),系统后台就已经在并行地分析需求、检索资料,等用户话音一落,答案和工具结果往往已经准备好了。

第二种形态是「边说边想」(Speak While Thinking)。这就像我做这个 talk:我不会先把 20 分钟要讲的内容全部想好,再一股脑念出来,而是每讲一页的时候,再想下一页该怎么讲。Agent 也是一样——前台的快模型先把话接上、维持自然的对话节奏,后台的慢模型在背后继续深度思考,随后再把更完整的内容接续上来。这样回答既能即时给出,又能自然地展开。

论文 · The Latent Bridge: A Continuous Slow-Fast Channel for Real-Time Game Agents
arXiv:2606.24470 · 网站 · GitHub
刚才说的快慢两个模型,除了在实时语音的场景,在 Computer Use、操作电脑图形界面的时候,也可以用类似的方法。这里我们用一个动作类游戏(吃豆人 Ms. Pac-Man)来研究——玩游戏是一个非常典型的场景:它既需要你能几百毫秒级地躲避障碍物,这是一个快速反应的动作,又需要你在背后慢慢地思考策略,否则这个迷宫就走不出去。
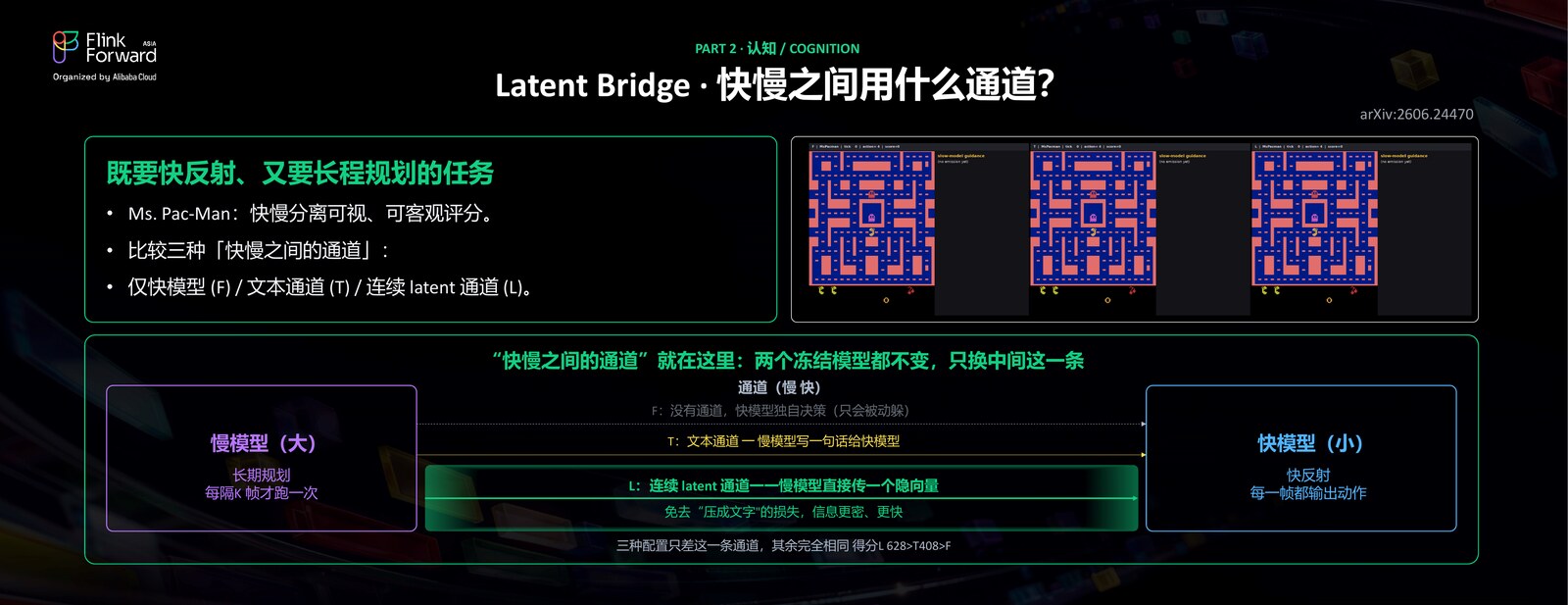
那么快慢两个模型之间,到底该用什么通道来沟通?这正是这个工作要研究的问题。我们对比了几种方式:一种是只用快模型单干;一种是用文本通道,把慢模型生成的文本喂给快模型;还有一种是用一个连续的 latent 通道,也就是用向量的方式,把慢模型的思考传给快模型。为了让中间这条通道成为唯一的变量,我们把快慢两个模型都冻住,只改变它们之间的这条通道。
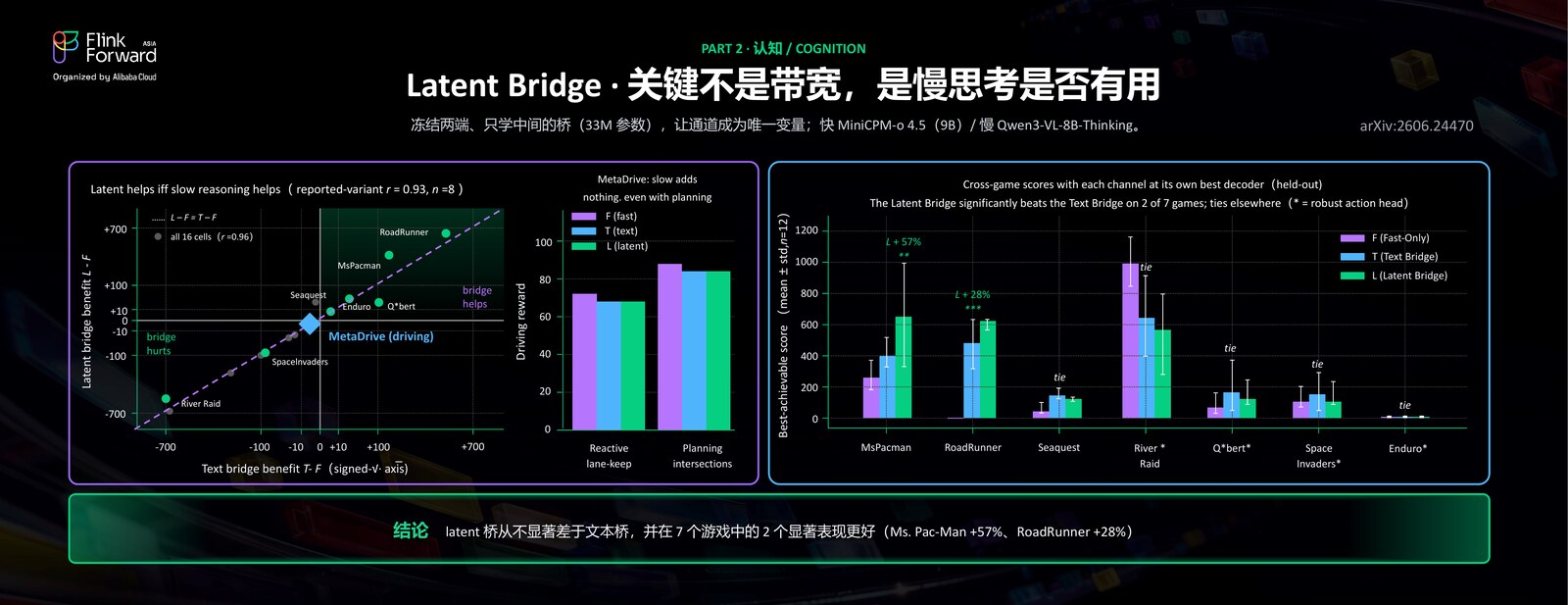
结论是:不管是用 SOTA 的慢速 thinking 模型,还是只用一个能快速响应的快模型,单独都没法把这个游戏玩好;一定要让快和慢这两个模型配合起来,它们才能既做到快速的反射,又做到长期的规划。而连接它们的通道,文本和 latent 各有适用的场景——针对不同的任务,可以用不同的方式,并不是带宽更高的 latent 通道就一定更好。换句话说,关键不在通道的带宽,而在于慢思考对这个任务到底有没有用;先判断这一点,再决定用哪条通道,才是正确的顺序。
Part 3 · 记忆:经验存在哪、怎么取回

接下来讲第二朵云:自主从经验中学习,也就是记忆——Agent 怎么把交互中积累的经验存下来、再复用。对应到 Flink,这就是它最核心的有状态流处理(state backend + checkpoint)能力。这一部分我讲三个工作,对应三种机制:第一种是把用文字的记忆转化成代码的方式,更结构化,也更方便做聚合推理和冲突检测;第二种是把记忆存储成类似 embedding 的形式,放进 hash slot 里面;第三种是把一个工作流内化成代码,变成一个针对特定 domain 的小模型,自动化地去执行之前比较慢的那套工作流。下面逐一展开。
① User as Code:把用户记忆表示成代码

论文 · User as Code: Executable Memory for Personalized Agents
arXiv:2606.16707 · 网站 · GitHub
先说第一个工作 User as Code。我们从一个例子说起:假设一个用户有 100 次航班记录,他问你——2025 年坐了多少次航班、2026 年坐了几次、去欧洲多少次、去日本多少次?如果用 Markdown 的方式来存记忆,模型就得把整个历史记录全部 load 到 context 里面,然后在 thinking 的过程中,用 reasoning token 一个一个地去数到底有多少次航班。这样其实很容易出错——虽然现在的 SOTA 模型已经数得不错了,但错误率还是不低。
那我们自然会想:如果把它存到数据库里,用结构化的方式去存,是不是就能数得不错了?但这里有一个问题:数据库是一个固定的数据结构。我今天给航班设计了一套数据结构,可明天还有银行卡信息、用户每天吃了什么……信息这么多、这么杂,数据结构是没办法泛化的,我没办法预先设计出一个通用的、能存下所有信息的数据结构。
所以我们突然想到:模型最强的能力,其实就是写代码。现在大家公认 Agent 最强大的能力就是 coding,那我为什么不让它用写代码的方式,自己去设计数据结构呢?这就是我们做 User as Code 的出发点——把用户记忆表示成一段它自己写出来的、结构化的代码,而不是一堆 Markdown 文本。这样既能像数据库一样精确地做聚合查询(数航班、按目的地统计),又不需要预先把 schema 固定死。

把记忆变成代码之后,还有一个好处:可以给它挂上真正会运行的约束和校验逻辑。结构化的记忆配上一段代码,就能由解释器确定性地把多条记录串起来计算、做冲突检测、并主动告警——这也是纯文本记忆很难做到的(用文本你只能让模型在 thinking 里去数、去比,既慢又容易错)。
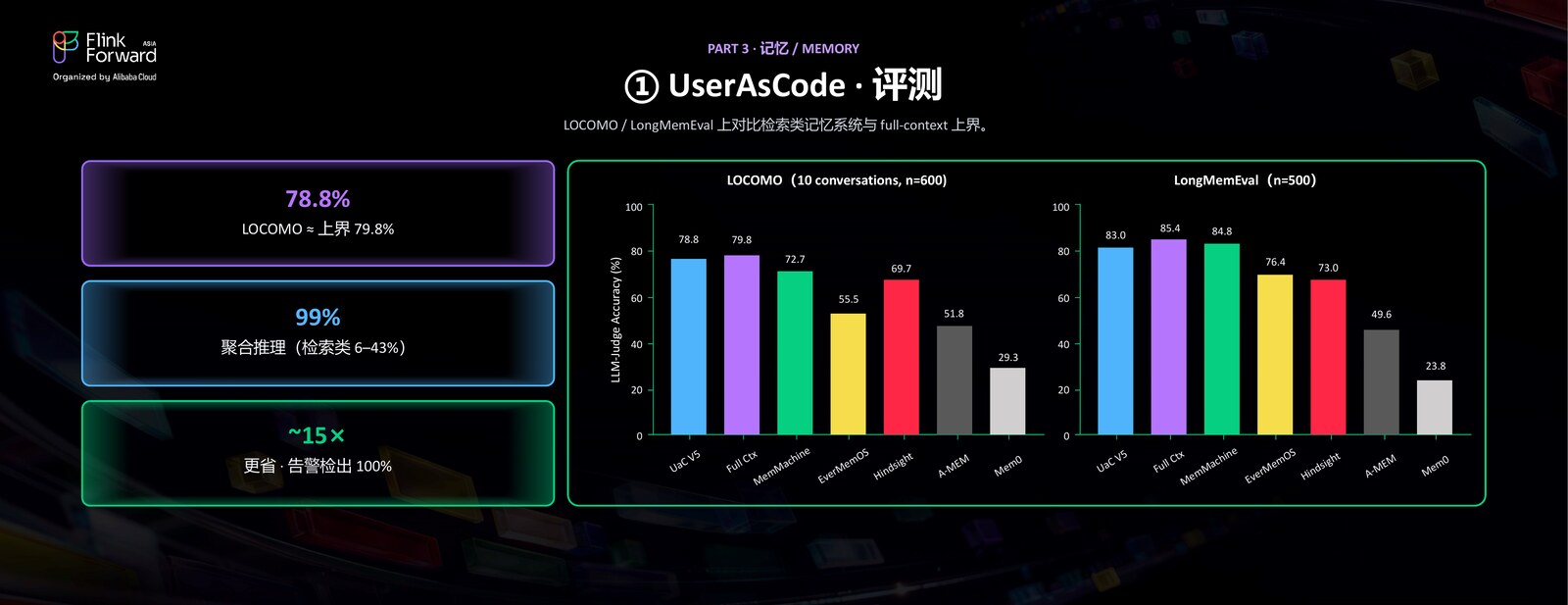
实验结果也印证了这一点:把记忆代码化之后,像前面数航班那样的聚合查询能数得又快又准,在标准的记忆评测上也能逼近「把全部对话直接塞进上下文」的上界。
① Programmable KV:把记忆和 Skills 编译进 KV Cache
论文 · Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
arXiv:2606.17107 · 网站 · GitHub
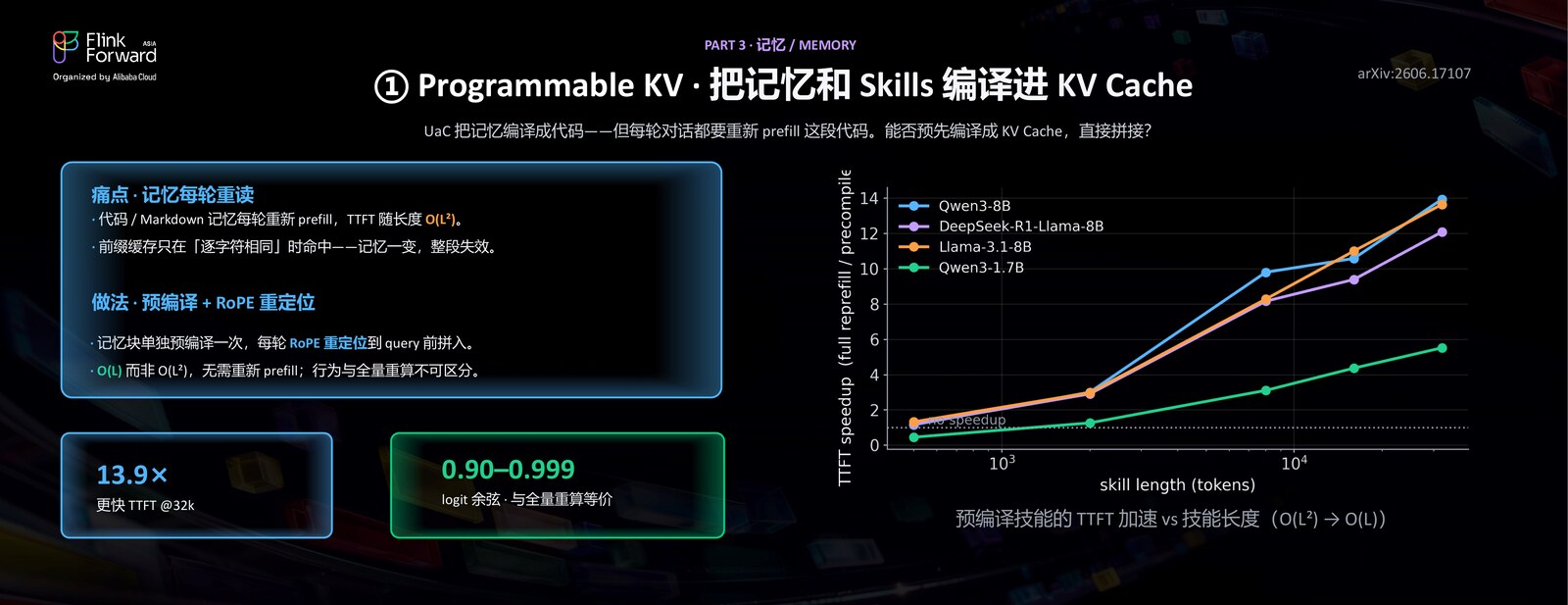
当用户记忆和 Skill 越来越长,每次都把它们重新 prefill 一遍,TTFT(首 token 延迟)会被拖垮。Programmable KV 的核心洞察是——KV Cache 不是一堆冻结的中间产物,而是模型在 prefill 阶段写下的一本「结论备忘录」:transformer 在 prefill 时,就已经把「基于某个字段得出的结论」写到了下游的聚合 / 分隔 token 上;decode 时模型读的是这些「备忘」,而不是字段本身。
第一招:把记忆和 Skills 编译进 KV Cache(可组合 / Composable)。 痛点是「记忆每轮重读」:技能、长 Markdown、用户档案这些可复用的前缀,每轮都重新 prefill,是 O(L²) 的代价,TTFT 随长度爆炸。
我们的做法是预编译 + RoPE 重定位:把一段技能/规则只编译一次,需要时把它缓存的 KV 通过 RoPE「重定位」拼接进任意上下文——因为 prefill 缓存的是带绝对位置的 key,只要把 key 旋转到目标位置即可。这样从 O(L²) 的重算变成 O(L) 的拼接,行为与重算几乎等价,而且技能越长,「全量重算 vs 预编译拼接」的差距越大。
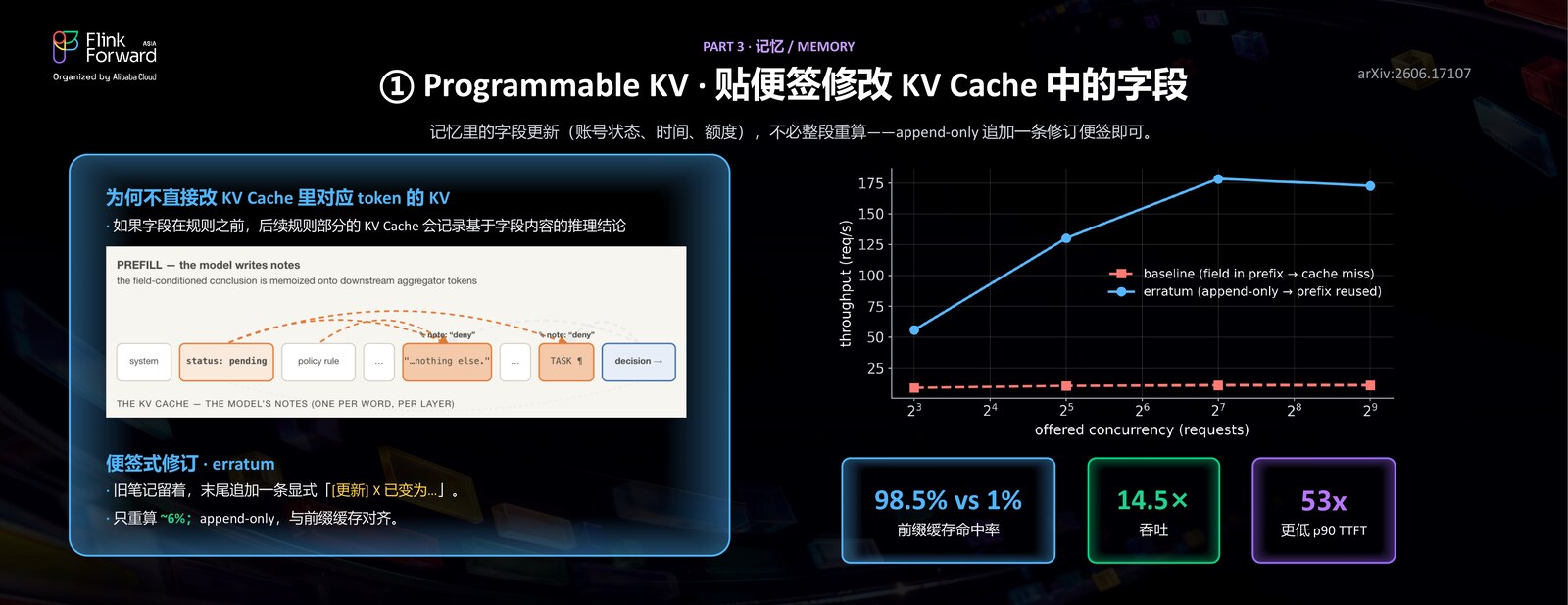
第二招:贴便签修改 KV Cache 中的字段(可编辑 / Editable)。 记忆里底层的字段会变——账号余额、时间、天气——但我们不希望每改一个字段就让整段缓存失效、推倒重算。
为什么不能直接去改 KV Cache 里对应 token 的 KV?因为如前所述,模型在 prefill 时把「基于该字段的结论」写到了下游的聚合 token(PREFILL — the model writes notes)上,你只刷新字段本身的 KV,下游那些过时的「备忘」还在,决策读的还是旧结论。
所以我们用便签式修改(erratum):不去改前缀,而是在上下文末尾追加一条显眼的更正——[更正] X 改为 Y。它是 append-only 的,因此与前缀缓存完全兼容。对应到 Flink / DB,这就是 append-only 日志 + 周期性检查点 = changelog + checkpoint 的数据库经典形态。在线服务实测:前缀缓存命中率 98.5% vs 1%(直接改前缀几乎全部 miss),吞吐最高 14.5×,p90 TTFT 可以降低 53×。
② User as Engram:把用户事实写进模型参数

论文 · User as Engram: Internalizing Per-User Memory as Local Parametric Edits
arXiv:2606.19172 · 网站 · GitHub
前面两个思路(User as Code 和 Programmable KV)都是把记忆放在上下文里;第二种机制,是把用户的事实性记忆直接写进模型参数。这一块的先验,是 DeepSeek 今年发表的 Engram 记忆工作。Engram 说白了就是一个外挂的、不断增长的哈希表:模型自己会学会在什么情况下查哪个 slot——拿最后几个 token 做一个哈希,再去查对应的槽位,相当于一块不断增长的外挂 RAM。我们就是在 DeepSeek 的 Engram 论文发表之后,在我们的模型上加了 Engram,把用户的这些事实性知识插进去。
在这之前,其实已经有很多工作尝试用 LoRA 把用户记忆存进模型参数。但 LoRA 有一个众所周知的问题:它能把知识提取出来,却很难在这些知识上做复杂的推理;而且它是全局地改权重,容易污染、难以隔离。
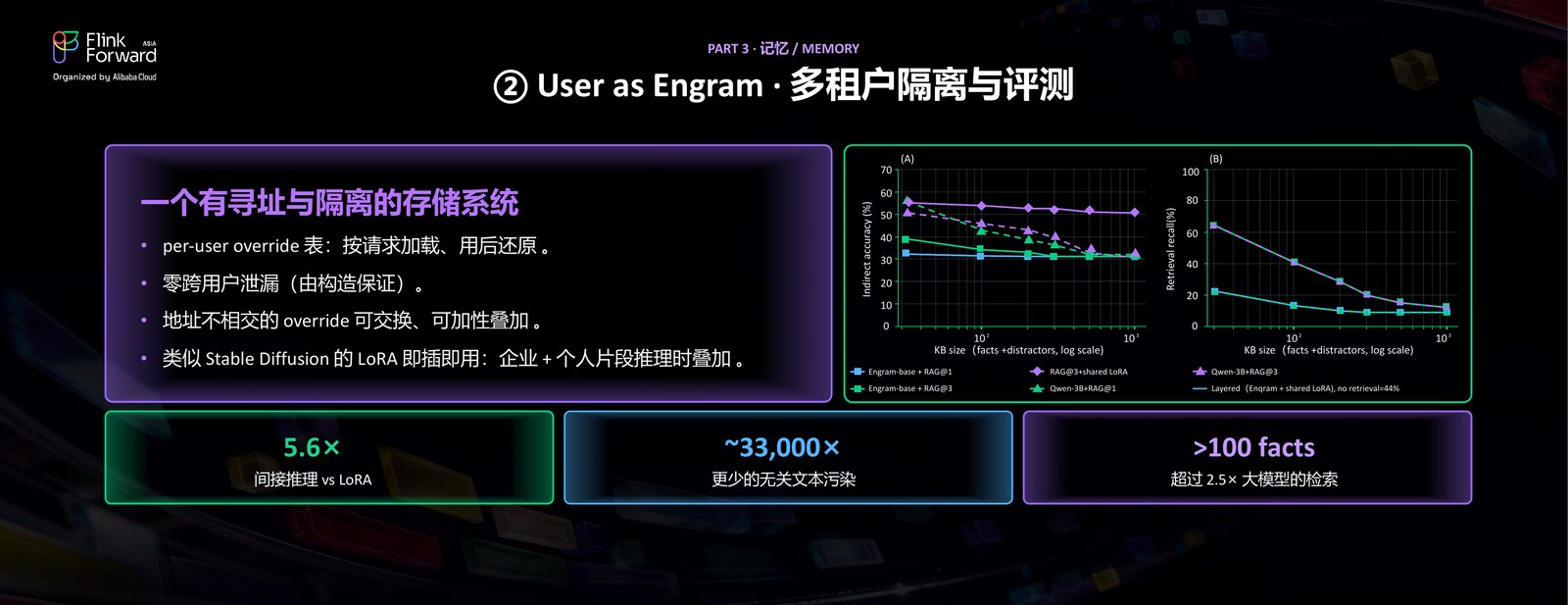
用 Engram 这种方式,相比后训练(比如 LoRA)有几个明显的好处。第一,它不需要做很复杂的梯度下降,更新非常简单。第二,它有可加性——一个用户有自己的个人记忆、有家庭的记忆、有关于公司的记忆,一般来讲哈希不冲突,就可以直接都放进去、叠加在一起。这相当于:我们在底层训练了一个公共的「阅读记忆的技能」(也就是怎么去用这块记忆),上层再往不同的 slot 里,插入每个用户的事实性记忆。这样天然就支持多租户,又能用向量化的方式来存取。
它还有一个纯文本记忆做不到的好处——能存多模态的用户记忆。比如今天见了十个人、拍了十张照片,待会儿要把这十个人重新认出来,你很难用纯文本把每张脸都描述清楚;而这种参数化、向量化的存取方式,天然就适合这类多模态的用户记忆。
③ PreAct:把重复工作编译成缓存
论文 · PreAct: Computer-Using Agents that Get Faster on Repeated Tasks
arXiv:2606.17929 · 网站 · GitHub
前面讲的都是声明性记忆(事实);第三个工作 PreAct,针对的是过程性记忆——怎么做一件事,也就是 skill 的机制。我们经常会有重复的工作,尤其是在 Computer Use、Agent 操作电脑的场景里,会反复执行一些相同的操作。这就像一个老外第一次用支付宝,可能点了半天都不知道该怎么付钱;但用过几次之后,肯定就非常熟悉了。我们想让 Agent 也具备这种「越用越熟、越用越快」的能力。
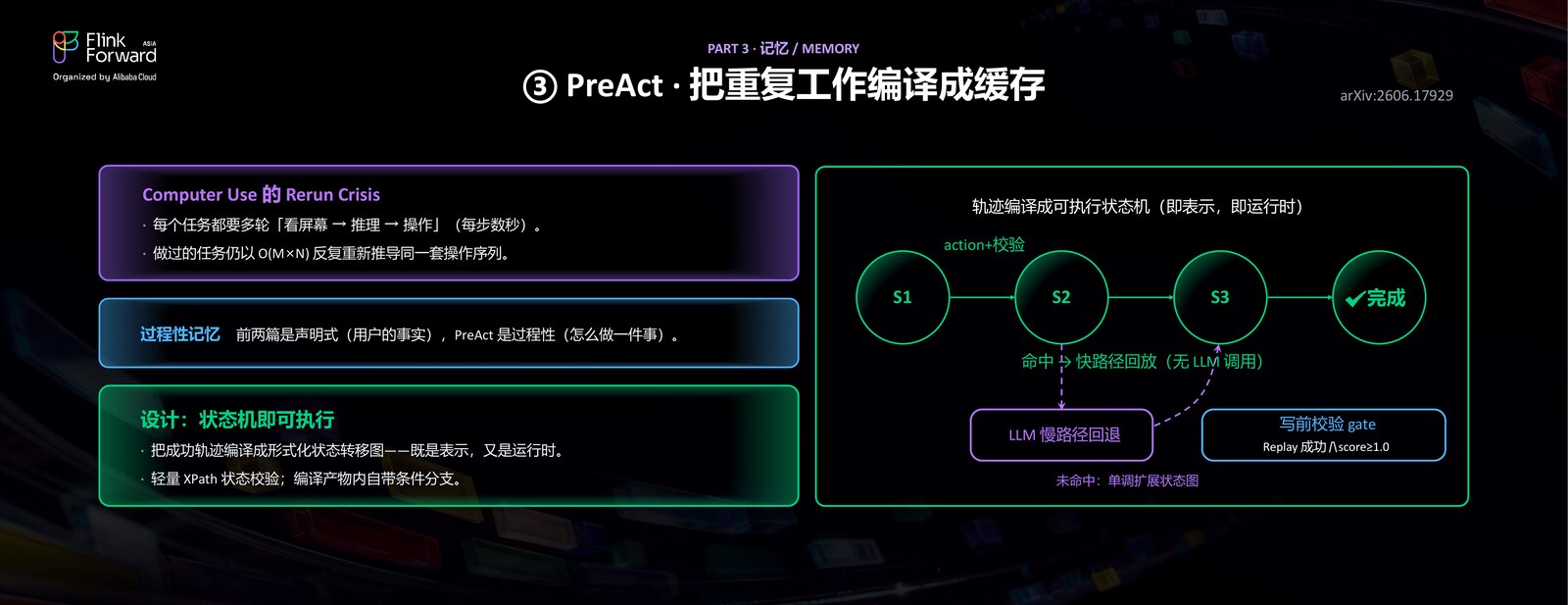
现在 Agent 在 Computer Use 上的成功率其实已经蛮高了,但它很多时候每看一帧就要重新想一次,浪费很多 token,效率比较低。所以我们把它之前执行过的这些轨迹,编译成一个小程序(一个确定性的状态机),让它在这个过程里反复地去执行。只要这个过程是可以复现、可以重放的,我们就能用更快的速度把它完成。
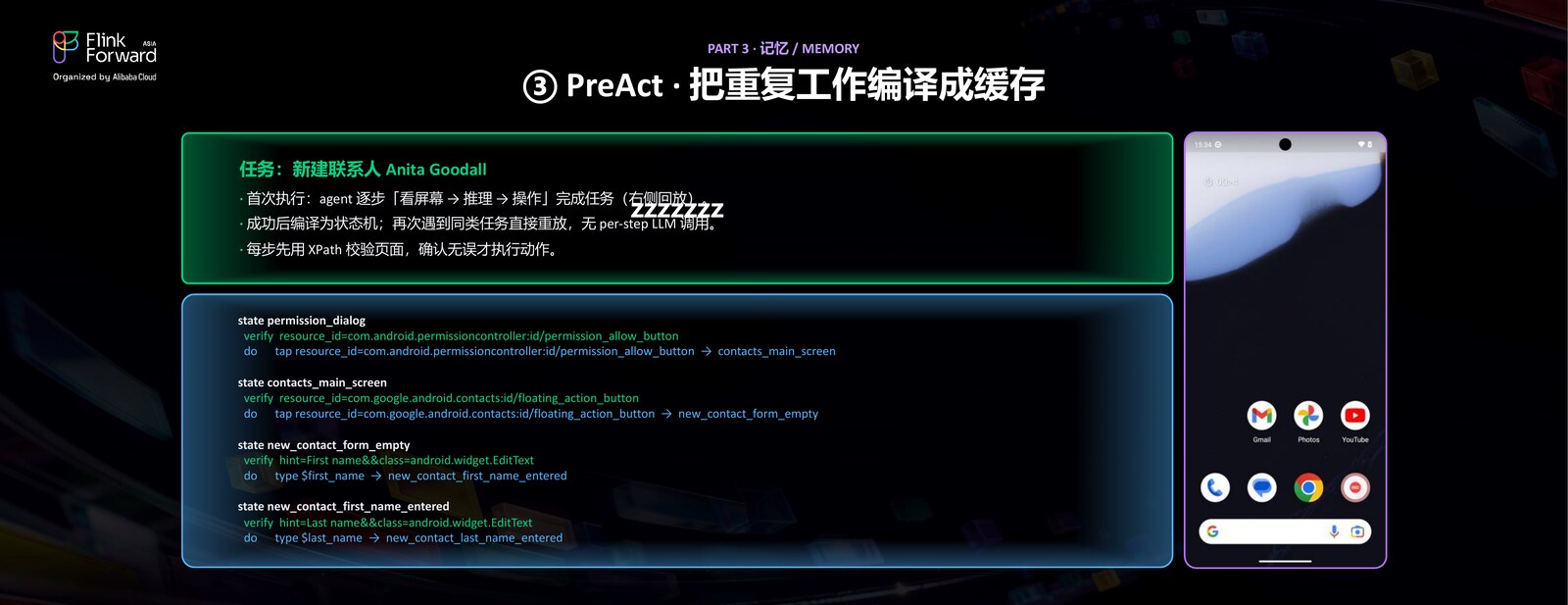
举一个具体的例子——新建一个联系人。首次执行时,Agent 老老实实地走「看屏幕 → 推理 → 操作」的完整流程,把任务做完,同时把整个过程编译成一个状态机:每个状态是一组对界面元素的断言,加上一个动作。下次再遇到同类任务,就可以直接按这个状态机一步步重放,不再需要每一步都去调用大模型。
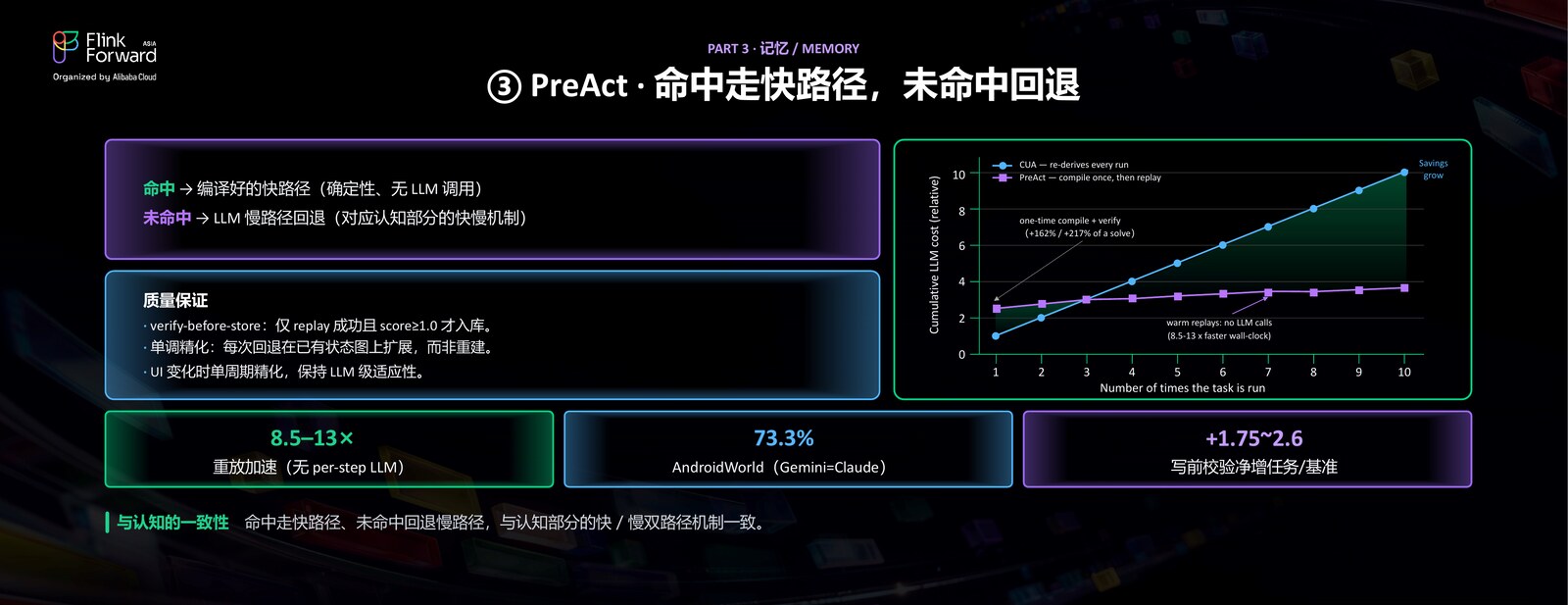
所以 PreAct 的执行策略是:命中时走快路径,直接按编译好的轨迹重放,确定性强、几乎没有成本;如果发现异常——比如点完某个按钮之后,预期的下一个页面没有出现、跟编译时不一样——那就回退到普通的 VLM 慢路径,重新仔细思考。
这其实有点像一个低配版的小世界模型:世界模型的核心,就是不断预测「我做了这个动作之后会发生什么」;如果发现跟预期一致,就接着做下一个动作、不用重新想;如果发现不一致,就回退回来、仔细思考。我们就是用这样的方式,实现了对已经执行过的轨迹的缓存复用。这跟前面认知部分的快慢分离也是一致的——命中走快路径,未命中走慢路径。
回到 Agent 的两朵云

最后做个总结。前面我们分阶段讲了「流式与环境交互」和「自主从经验中学习」这几项技术。
在感知方面,我们把 Agent 感知世界的空间,从一轮一轮(turn by turn)的空间,延展到了流式处理的空间——这也正是 Flink 批流一体的核心思路。这样就能让它持续地看视频、持续地听声音、持续地看动画,实时地跟环境交互。在认知方面,我们让它充分利用快慢模型的配合:快模型跟世界实时交互,慢模型在背后做深度思考。
在自主经验学习这一部分,我们介绍了三种机制:第一种,是把用文字的记忆转化成代码的方式,更结构化,也更方便做聚合推理和冲突检测;第二种,是把记忆存储成类似 embedding 的形式,放进 hash slot 里面;第三种,是把一个工作流内化成代码,变成一个 domain-specific 的小模型,自动化地执行之前比较慢的那套工作流。
从这些工作中可以看到:决定一个系统表现的,往往是它的交互和表示,而不是模型本身的能力。 现在我们的模型,不管是 vision 还是大语言模型,能力其实都已经非常强了;但很多时候,是我们没有给模型合适的 context,或者没有给它合适的模态,模型就没办法在现实当中发挥出实际的效果。我觉得这正是 Flink 框架带给大家的关键价值——它能把这些不同的模态,处理成便于模型处理的形式,让模型在实际的业务场景中发挥最大的价值。

谢谢大家!
相关论文与网站
本报告涉及的工作(更多请见 01.me/research):
| 工作 | arXiv | 网站 | 代码 |
|---|---|---|---|
| AOI · 观测接口 | 2606.29472 | 网站 | GitHub |
| Sema · 语义传输 | 2604.20940 | 网站 | GitHub |
| Latent Bridge · 快慢通道 | 2606.24470 | 网站 | GitHub |
| User as Code · 可执行记忆 | 2606.16707 | 网站 | GitHub |
| Programmable KV · 可编辑可组合的 KV Cache | 2606.17107 | 网站 | GitHub |
| User as Engram · 参数化用户记忆 | 2606.19172 | 网站 | GitHub |
| PreAct · 过程记忆编译成缓存 | 2606.17929 | 网站 | GitHub |
Interactive ReAct 相关工作即将发布。