SOSP:计算机系统研究的风向标
(转载自 微软亚洲研究院)
SOSP(操作系统原理大会)自1967年创办以来,两年一届,已经有50个年头了。从1969年的UNIX系统到21世纪初的MapReduce、BigTable、GFS,系统领域一系列最有影响的工作都是发表在SOSP以及与它隔年举行的兄弟会议OSDI上。如果把SOSP和OSDI历年最具影响力(Hall of Fame Award)的论文汇集成册,就是大半本操作系统和分布式系统的教科书。作为系统领域的最高学术会议,SOSP和OSDI每年只收录30至40篇高质量论文,因而能够在SOSP上发表论文是系统研究者的荣誉。
 SOSP’17开幕式(图片来源:陈海波教授)
SOSP’17开幕式(图片来源:陈海波教授)
今年,SOSP首次走出北美和欧洲来到中国上海,微软亚洲研究院副院长周礼栋博士和上海交通大学陈海波教授担任本届大会组委会主席,康奈尔大学Lorenzo Alvisi教授和密歇根大学Peter Chen教授担任程序委员会主席。本届SOSP会议创下了多项记录和第一:最多的注册参会者(850位);最多的赞助商数量和金额;首次提供会议直播和在线提问;首次设立了AI Systems Workshop,共商AI系统这个新生的重要应用;由微软研究院赞助,首次举办了ACM学生研究竞赛(SRC),吸引到40多篇投稿。
 Ada Workshop参会人员合影
Ada Workshop参会人员合影
特别值得一提的是,本届SOSP大会首次在美国以外举办了Ada Workshop。微软亚洲研究院联合SOSP’17,邀请了国内外多位女性研究员,共同探讨计算机系统领域的未来。1987年,美国计算机科学家Anita Borg参加SOSP’87大会,惊讶地发现自己是唯一的女性科学家,由此三十年如一日地推动提升女性在计算机科研中的地位。如今,女性研究者在系统研究领域的声音已经举足轻重。本届SOSP唯一两次上台演讲的论文作者Kay Ousterhout就是UC Berkeley的女性博士毕业生,她的导师Sylvia Ratnasamy也是著名的女性科学家。我们希望Ada Workshop能助力系统研究领域的女性快速成长,激励更多心怀梦想的女性投身系统研究领域。
 微软在SOSP’17大会上的展台
微软在SOSP’17大会上的展台
本届SOSP会议吸引了来自五大洲23个国家和地区的232篇投稿,录用论文39篇,投稿数量比上届增加了30%,录用率保持不变。微软不仅是SOSP’17的金牌赞助商,还发表了8篇主会论文(其中第一作者论文4篇),是发表论文最多的机构(第二名为麻省理工学院,发表论文6篇)。SOSP的55位审稿人都是学术上的泰山北斗,对审稿工作极其严肃认真,每篇投稿平均收到4.9个审稿意见,每个审稿意见平均长达6.5 KB。审稿结束后,程序委员会选出76篇论文,由23位主要审稿人经过两天的会议,选出最终录用的39篇论文。
 北京航空航天大学与微软亚洲研究院联合培养的博士生肖文聪在AI Systems Workshop上展示研究成果。AI系统是微软亚洲研究院系统组的主要研究方向之一。
北京航空航天大学与微软亚洲研究院联合培养的博士生肖文聪在AI Systems Workshop上展示研究成果。AI系统是微软亚洲研究院系统组的主要研究方向之一。
 微软亚洲研究院实习生左格非在SOSP学生研究竞赛(SRC)上向SIGOPS主席Robbert van Renesse教授展示研究成果,该成果获得本科生组银牌。
微软亚洲研究院实习生左格非在SOSP学生研究竞赛(SRC)上向SIGOPS主席Robbert van Renesse教授展示研究成果,该成果获得本科生组银牌。
39篇主会论文采用single track形式满满地排在三天的13个session里,每篇论文都有25分钟的口头报告和提问,涵盖了寻找bug、可扩放性、网络计算、资源管理、操作系统内核、验证、系统修复、隐私、存储系统、安全、故障诊断、数据分析等多个领域。
下面我们将从让系统更高效、更可靠两个方面,与大家分享SOSP上的系统研究最新进展。
更高效的数据中心
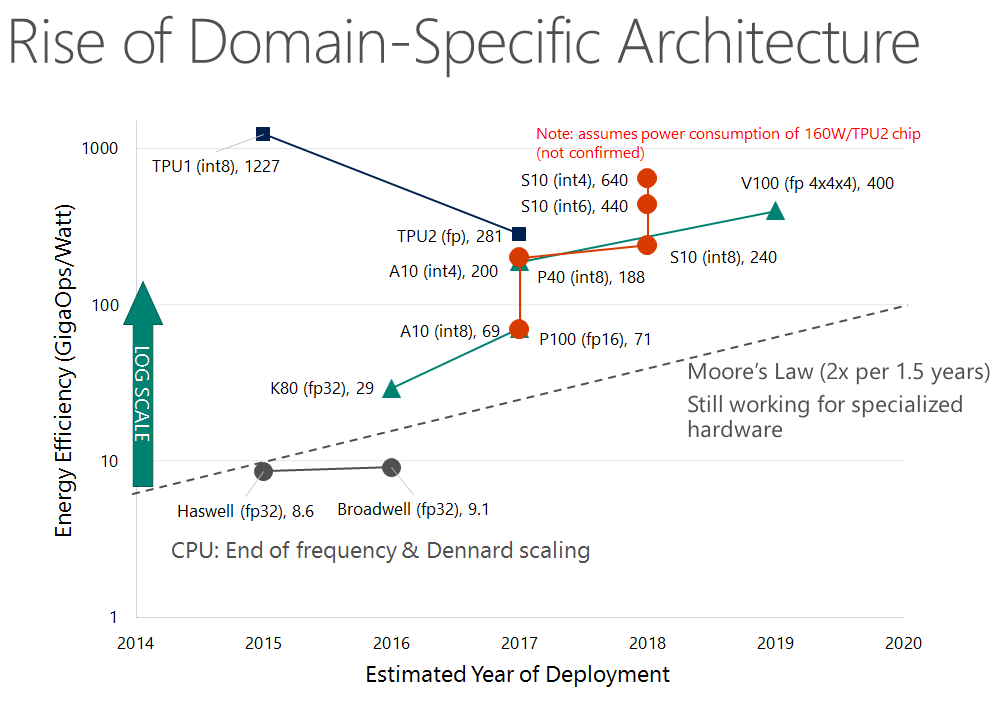 摩尔定律对CPU而言基本上终结了,但对GPU、FPGA、TPU等定制化硬件而言仍在继续
摩尔定律对CPU而言基本上终结了,但对GPU、FPGA、TPU等定制化硬件而言仍在继续
如今的数据中心越来越像一个仓库规模的大型计算机,而不再是传统意义上松散的分布式系统。一方面,硬件的计算与互联性能越来越高,例如网络的速度与PCIe总线、DRAM总线的速度已经相差不远了,RDMA也可以把延迟从几百微秒降到几微秒;NVMe SSD的延迟在100微秒量级,比机械硬盘延迟低了两个数量级,NVM(非易失性内存)更是把延迟进一步降低了两个数量级;GPU、FPGA、TPU等加速设备的能效在很多场景下比CPU高两个数量级。然而传统操作系统访问外设、任务切换和多核同步的机制不能充分利用日新月异的硬件性能。
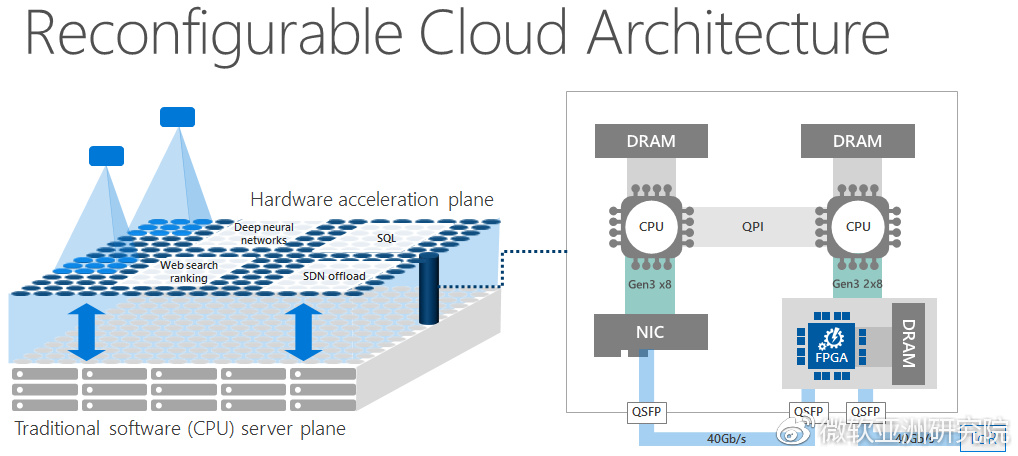 可编程的数据中心硬件,微软使用搭载了FPGA的可编程网卡作为数据中心加速平面
可编程的数据中心硬件,微软使用搭载了FPGA的可编程网卡作为数据中心加速平面
另一方面,数据中心硬件的可编程性越来越强。例如可编程交换机和可编程网卡使得网络除了转发数据包以外还可以做缓存、聚合和调度。CPU支持的硬件虚拟化、PCIe设备支持的SR-IOV虚拟化、CPU支持的SGX安全容器和TSX事务内存,提供了很多软件难以高效实现的隔离性,对多租户的云环境至关重要。RDMA/RoCE网卡、GPU-Direct、NVMe Over Fabrics等技术使设备间可以绕过CPU直接互联。如何在系统设计中充分利用这些可编程性成为了系统研究领域新的挑战。
分布式协调的性能瓶颈
本次SOSP上约有半数的论文致力于提高系统的性能。其中的一个常见性能瓶颈在于分布式协调,且节点数量越多瓶颈越严重。
分布式协调的第一个问题是多个节点(服务器或者CPU核)负载不均衡,热点节点的最坏情况延迟(tail latency)较高。一种解决方案是用集中分配取代分布协调。在键值存储(key-value store)系统中,NetCache用可编程交换机作为缓存,实现了同一机柜内不同服务器间的负载均衡;KV-Direct用可编程网卡作为缓存,可以实现同一服务器内不同CPU核间的负载均衡;另一种解决方案是重新分配任务。在网络处理系统中,ZygOS在IX基础上构建(让网卡把任务分配到多个CPU核对应的不同队列),为了负载均衡,空闲的CPU核从其他核的队列里“窃取”任务(work stealing),并利用核间中断(IPI)降低响应包的处理延迟。
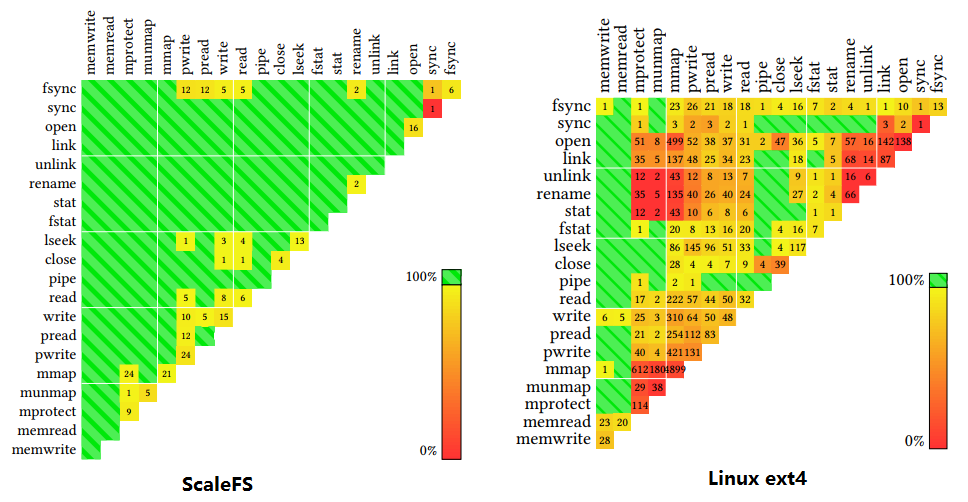 Linux文件系统的系统调用接口之间有很多共享内存冲突,ScaleFS消除了绝大部分冲突情况(图片来源:Scaling a file system to many cores using an operation log, SOSP’17)
Linux文件系统的系统调用接口之间有很多共享内存冲突,ScaleFS消除了绝大部分冲突情况(图片来源:Scaling a file system to many cores using an operation log, SOSP’17)
分布式协调的第二个问题是通信占用的带宽和延迟较高。一种办法是在语义上减少冲突,使各个节点互不干扰。在文件系统里,ScaleFS基于可交换的文件系统API(sv6)来改进语义冲突较多的LinuxAPI,在内存里构建了一个核间无冲突的文件系统抽象,把各个核的文件系统操作记录到日志里,需要写盘的时候再合并不同核的日志;在数字货币系统中,为了高效实现互不信任的大量节点间的拜占庭共识,现有系统往往需要竞争“挖矿”来选出代表,而Algorand利用可验证随机函数(VRF),无需通信和大量计算就可选出公认的代表;在匿名通信系统中,Atom系统通过对用户随机分组,无需全网所有节点互相通信,就能实现匿名广播,并以很高概率发现不诚实的节点。另一种减少分布式协调中通信开销的方法是引入中心节点。Eris利用网络上天然的中心(可编程交换机)来充当“顺序发号器”,用很低的开销实现了严格按序广播消息,进而大大简化分布式事务中的并发控制。为实现多核共享内存的并发控制,ffwd把往常用原子操作实现的“抢锁”操作委托给一个CPU核来做协调,实现了更高的吞吐量。
系统接口抽象
系统领域有句名言,”计算机科学的任何问题都可以通过增加一个中间层来解决”。过于底层的接口会导致上层应用编程复杂,并发访问时还面临一致性问题。例如,LITE和KV-Direct两篇论文都指出,RDMA的抽象并不完全适合数据中心应用。首先,RDMA把缓冲区管理等底层信息暴露给用户,使得RDMA编程比TCP socket复杂很多,而且在连接较多的情况下,内存地址虚实映射表很容易导致网卡缓存溢出。为此,LITE提出了一套更灵活易用的API,并把虚实映射的工作从网卡转移到CPU。其次,对于需要多次内存访问才能完成一次操作的数据结构,为了保证数据结构操作的原子性,多个客户端的并发写操作有较高的同步开销。为此KV-Direct把RDMA内存访问语义扩充到了键值操作的更高层语义,在服务器端的可编程网卡中实现了并发原子操作的乱序执行。
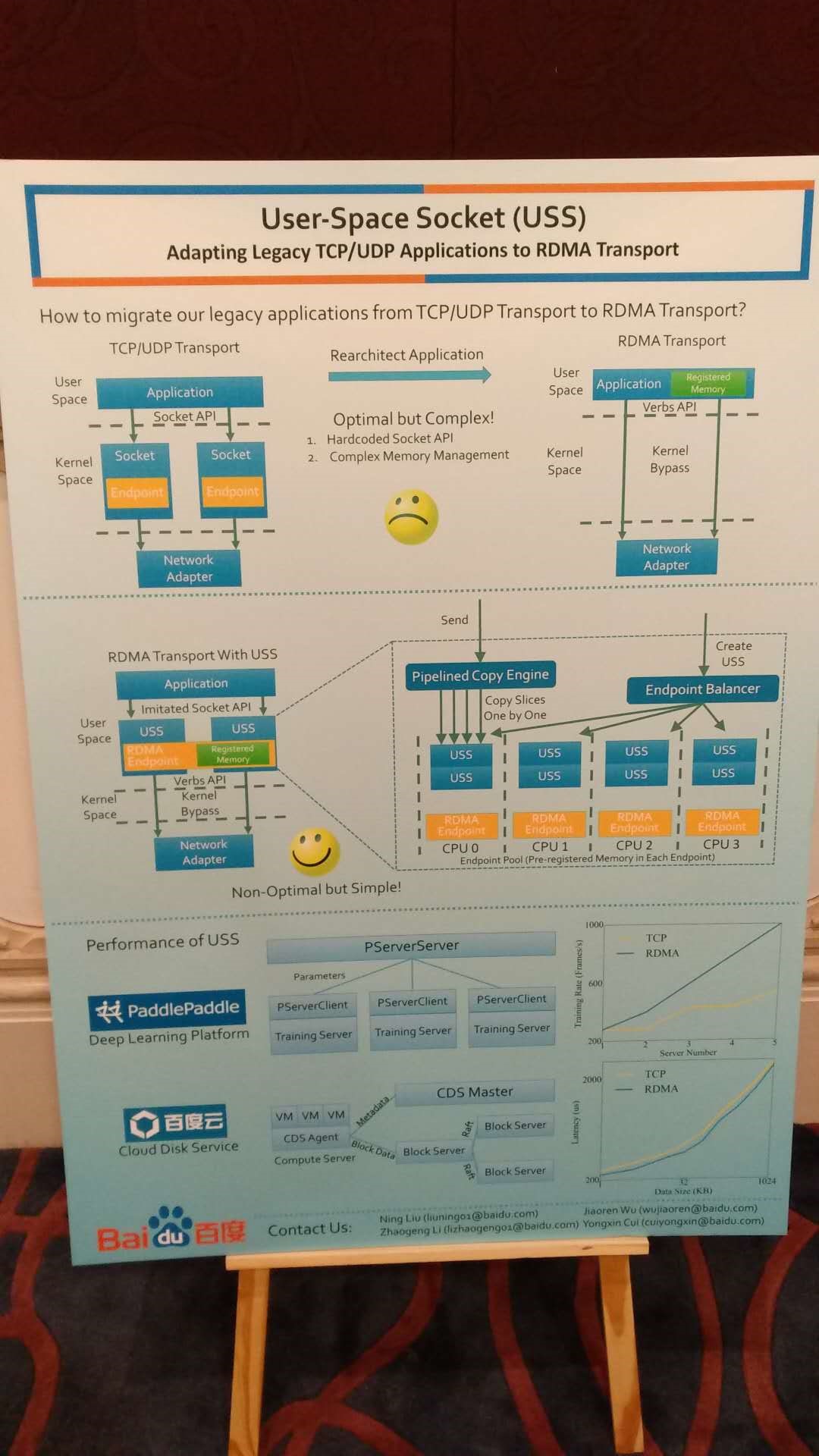 百度提出的USS,把socket语义翻译到RDMA。学术界也有多个类似工作。
百度提出的USS,把socket语义翻译到RDMA。学术界也有多个类似工作。
然而抽象的层次不是越多越好。抽象层次过多时,两个中间层可能做了重复的事情,反而不能充分利用底层硬件的性能。例如,在虚拟化环境中,每个虚拟机往往只做一件小事,此时虚拟机操作系统的调度、资源管理等抽象就显得多余。Unikernel的设计应运而生,把应用程序、运行库和内核中的驱动程序编译到一起,成为一个不分用户态和内核态的轻量级虚拟机;对于系统调用较为复杂或者需要多进程的应用,也可以用Tinyx为应用定制精简的Linux“发行版”,仍然使用Linux内核,但启动速度快了很多。再如,SSD上的键值存储可能组织成日志树(log-structured tree)的形式,而SSD底层的FTL也是类似的结构,NVMKV就把两者合并,降低了写操作的开销。
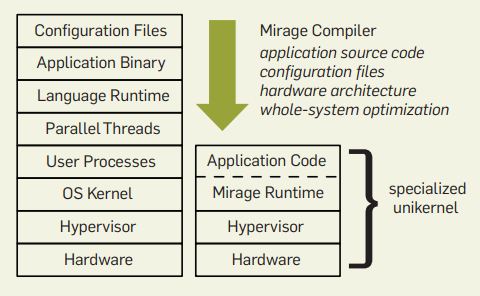 为应用定制的Unikernel (右) 与Linux (左) 的比较(图片来源:Unikernels: The Rise of the Virtual Library Operating System, ACMQueue, Jan. 2014)
为应用定制的Unikernel (右) 与Linux (左) 的比较(图片来源:Unikernels: The Rise of the Virtual Library Operating System, ACMQueue, Jan. 2014)
经典的抽象背后可能藏着很多不必要的功能和不适合现代硬件架构的设计。众所周知,新生的用户态网络协议栈和文件系统比Linux内核的实现高效得多。ScaleFS及其研究组之前的工作表明,Linux的系统调用接口存在很多不利于多核扩放的设计。一篇在64 KB的嵌入式计算机(如Yubikey这样的USB令牌)上用Rust实现多进程、隔离和内存共享的论文说明现代操作系统的核心机制并不复杂。NVMM(非易失性内存)的低访问延迟意味着应用需要mmap直接访问NVMM(无需经典文件系统中的物理内存缓存),然而持久化存储的一致性又要求有快照和纠错功能,NOVA-Fortis文件系统就是为此设计。在论文Strata: A Cross Media File System中,作者也指出,传统文件系统把一个小的写操作放大成一整块的写操作,本是为机械硬盘和SSD设计的,但是对能高效执行小的随机写的NVM就浪费了。
即使CPU提供的抽象缺少某些功能,系统设计者也往往能够用软件来实现,而无需等待千呼万唤始出来的下一代硬件。例如,ARM v8.0不支持嵌套虚拟化,NEVE系统就采用半虚拟化(para-virtualization)的方法,修改内层虚拟机(guest hypervisor)的软件,模拟调用外层虚拟机的陷门(trap)。再如,Intel SGX不支持动态分配内存,也存在操作系统通过缺页异常来侦测受保护代码行为的安全漏洞,Komodo就用经过验证的软件取代CPU硬件实现的特权指令,实现更快和更灵活的演进。因此,高性能系统不意味着把软件里尽可能多的功能放进硬件,而是找到软硬件之间合理的边界和接口。
“万金油”系统
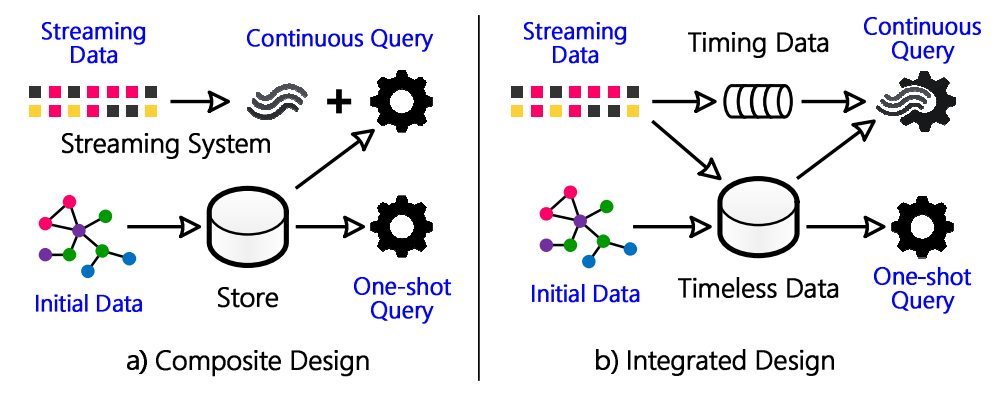 传统流式处理与数据库系统(左)与Wukong+S(右)的比较 (图片来源:Stateful Stream Querying over Fast-evolving Linked Data, SOSP’17)
传统流式处理与数据库系统(左)与Wukong+S(右)的比较 (图片来源:Stateful Stream Querying over Fast-evolving Linked Data, SOSP’17)
除了解决现有系统的瓶颈,另一个系统研究的方向是构建多种应用场景下都能高效工作的系统。例如,流处理系统往往假定流计算函数是持续运行且无状态的,而数据库系统假定数据在查询执行过程中是不变的,这就很难在一个系统里同时做持续运行的流式查询和一次性的简单快照查询。Wukong+S系统在去年OSDI的Wukong系统基础上更进一步,把不随时间改变的状态和随时间改变的状态分开存储,使流式和一次性查询都可以高效完成。类似地,在OLAP与OLTP共存的数据库系统中,如果OLAP查询在一个快照上运行,获得的统计信息是陈旧的。获得SOSP学生研究竞赛研究生组金牌的Xylem系统把OLAP查询看成一个视图,OLTP修改数据时增量更新视图,这样OLAP的结果就能反映数据库的最新状态。再如,流处理系统延迟低但恢复时间长,批处理系统能快速恢复但延迟高。Drizzle系统把数据处理周期和故障恢复周期解耦合,实现了低延迟、快速恢复的流处理。
更可靠的系统
 SOSP开幕式上,会议主席对OSDI 2018关键词的建议
SOSP开幕式上,会议主席对OSDI 2018关键词的建议
在生产环境中,相比性能,可靠性往往是更重要的考虑因素。今年SOSP开幕式上,会议主席列举了若干希望在明年OSDI上看到的词,其中包括了enclave、specification、crash、bug、verification和testing。提高软件可靠性有几个途径:找bug、形式化验证、故障诊断与恢复、虚拟化与隔离。
 最佳论文DeepXplore自动生成的测试用例,第一行是原图,第二行改变光照条件;第三行是另一组原图,第四行增加干扰方块(图片来源:DeepXplore: Automated Whitebox Testing of Deep Learning Systems, SOSP’17)
最佳论文DeepXplore自动生成的测试用例,第一行是原图,第二行改变光照条件;第三行是另一组原图,第四行增加干扰方块(图片来源:DeepXplore: Automated Whitebox Testing of Deep Learning Systems, SOSP’17)
今年SOSP的两篇最佳论文都在可靠性领域,一篇提出了深度神经网络的自动白盒测试问题,一篇提出了高效Web服务器审计问题,两篇论文提出的问题新颖且重要,并给出了漂亮的解法。DeepXplore指出,之前深度对抗网络生成的测试用例既不现实也不全面。类比软件测试代码覆盖率,提出了神经网络测试覆盖率的概念,一个神经网络输入如果使得某个神经元处于激活状态,就认为覆盖到了这个神经元。DeepXplore还提出了一种优化方法来生成测试用例最大化神经元覆盖率,在自动驾驶、恶意软件识别等神经网络中发现了很多被错误识别的边界情况。
另一篇最佳论文旨在通过记录Web服务器的执行过程,发现异常的Web服务器行为(如程序被篡改,或不可信的服务提供商)。Web服务器对共享对象的访问和网络交互都被记录下来,这样一个请求的处理过程就是纯函数式的。用类似符号执行的方法把多个请求的处理过程合并起来推导,使得验证器的时间开销比重复执行每个请求大大降低。微软的另一篇论文CrystalNet也致力于高效仿真问题。传统网络仿真器在仿真大规模网络时速度缓慢,且很难仿真控制平面的软件,然而大多数网络故障的原因在于控制平面而非数据平面。为此微软使用虚拟机或容器来仿真交换机固件和网络控制器,模拟控制平面的行为,并仿真广域网上其他运营商的行为,使得数据中心规模的网络仿真成为可能。
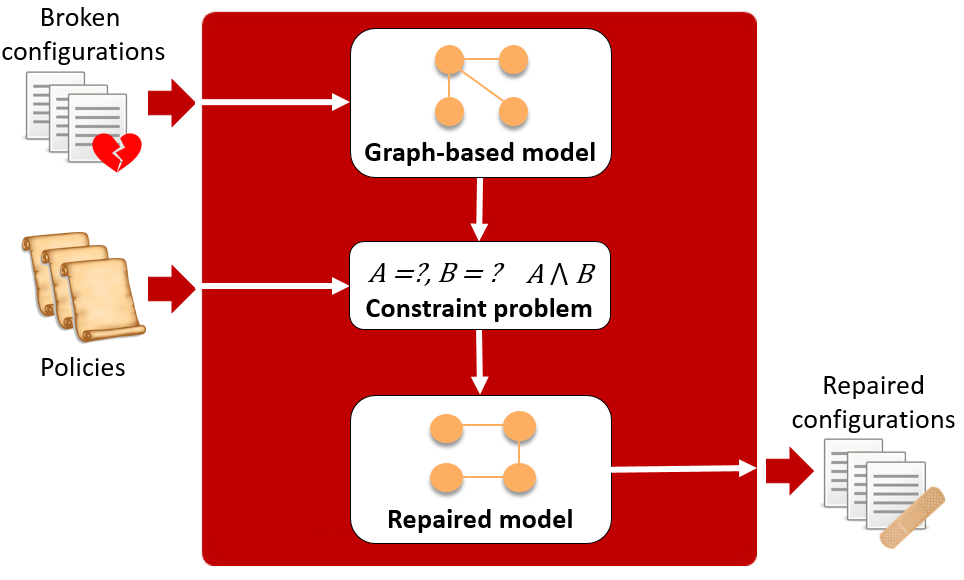 CPR系统自动修复错误的网络配置(图片来源:Automatically Repairing Network Control Planes Using an Abstract Representation, SOSP’17)
CPR系统自动修复错误的网络配置(图片来源:Automatically Repairing Network Control Planes Using an Abstract Representation, SOSP’17)
当系统出现故障时,需要做两件事情。一方面,应当能够自动修复到一个可用的状态,保证服务的可用性。微软研究院参与的CPR系统能够在网络控制平面发生故障时自动调整路由来满足一些事先指定的网络可达性约束。MittOS则是当队列过长、有超过最高允许延迟的风险时主动拒绝请求,让应用去其他的副本(replica)处理。另一方面,应该留下足够的日志,以便运维人员详细调查、彻底解决。由于系统状态的复杂性和运行过程中的不确定性,即使有了日志,复现bug也是众所周知的难题。Pensieve系统模仿人类分析bug的方法,使用静态分析的方法从最可能的几个错误发生位置开始,根据控制流和数据流倒推,跳过跟错误很可能无关的大部分代码,直到外部输入(API调用),由此生成测试用例。
自动生成测试用例找bug固然不错,但经过形式化验证的系统才能保证不存在特定类型的bug。然而形式化验证往往需要比开发代码多一个数量级以上的人力来写证明,大大限制了其在工业界的应用。HyperKernel通过对内核编程进行限制来实现自动化证明,其中最重要的限制是不能有无限的循环和递归,这也是P4和ClickNP这两个给交换机和网卡编程的高级语言的要求。一些系统调用接口需要修改,把不定次数循环转移到用户态。此时,内核的控制和数据流图就是有向无环图,对HyperKernel而言可以遍历所有执行路径来自动验证程序员指定的规约,对硬件加速而言也可以映射到交换机查找表或FPGA逻辑电路。
小结
 中国科学技术大学师生在SOSP的合影,其中包括微软亚洲研究院系统组发表的KV-Direct共同第一作者李博杰(后排右三)、阮震元(后排右一),以及来参加SOSP学生研究竞赛的微软亚洲研究院系统组实习生陆元伟(前排右二)、崔天一(前排左二)、左格非(后排左七)。
中国科学技术大学师生在SOSP的合影,其中包括微软亚洲研究院系统组发表的KV-Direct共同第一作者李博杰(后排右三)、阮震元(后排右一),以及来参加SOSP学生研究竞赛的微软亚洲研究院系统组实习生陆元伟(前排右二)、崔天一(前排左二)、左格非(后排左七)。
首次在中国召开的第26届SOSP会议吸引了众多平日难得一见的学术界大佬,也给了很多中国师生一次体验顶级学术会议的机会。重要的问题、创新的设计和扎实的实现是能在顶级系统会议上发表的三个要素。当然,论文发表只是一小步,一个系统要产生影响力,还是需要找到真实的应用场景,这也是笔者未来努力的方向。