SIGCOMM '19 Talk Transcription for SocksDirect: Datacenter Sockets can be Fast and Compatible
大模型真的很厉害,这个 SIGCOMM 2019 的演讲完全是脱稿讲的,从视频中可以看出我是站在舞台中间,没有看 speaker notes。我当时的英语也不怎样,经常打磕巴,而且音频录制还有回声,自己听着都有点费劲。没想到大模型能把这么差的语音都识别的差不多全对,太牛了。
识别的方法在这里。这个视频由于录制的屏幕不够清晰,我是用原始 PPT 导出的图片替换了视频中提取的图片。大家可以看看用这个视频中的音频,市面上的语音识别软件能达到多高的识别率。我试过的,包括 Google Speech-to-Text 和 Whisper,基本上都不能用。
SocksDirect: Datacenter Sockets can be Fast and Compatible. [PDF] [Slides] [Video]
Bojie Li, Tianyi Cui, Zibo Wang, Wei Bai, Lintao Zhang.
Proceedings of the 2019 SIGCOMM Conference (SIGCOMM’19).

Good afternoon everyone. Actually, this is my last work during my PhD study when I was an intern at Microsoft Research Asia and the University of Science and Technology of China. As introduced, I am now an employee at Huawei Technologies. Today’s topic is “SocksDirect: Datacenter Sockets can be Fast and Compatible.”

We all believe that sockets are very slow, but in data centers, socket is very important. So how can we make it fast? This is the topic of our talk. We all know that socket communication primitive is the most important primitive in our study. The server and clients communicate with the socket accept, connect, and send/receive primitives. In these primitives, this is the bottleneck of most applications. We divided it into the throughput and latency parts.

First, we consider the throughput part. We profiled several applications which are very popular in modern data centers, for example, key-value stores, HTTP load balancers, and DNS servers. For these applications, the kernel time has superseded the user mode time by a magnitude of times. So, if we can just remove this kernel time, which basically does the system calls for the sockets, we can improve the application performance by several times.
The second part is latency. We all know that data centers now equip with very low latency hardware transports. For example, for inter-host communication, we have RDMA widely deployed in data centers. We can see that if we just use Linux socket, the latency is 17 times higher than RDMA. And for intra-host, the latency is 40 times higher than shared memory, which is done by the CPU core coordination.

We also know that there have been many systems which can provide high-performance socket performance. We can basically divide these related works into three categories:
The first category is kernel optimization. This is a basic diagram of the kernel socket stack, which is divided into three parts. The first part is the virtual file system. We know that we access a socket via a virtual file descriptor. A file descriptor resembles a file in Linux, which we map send and receive to read and write. The second part is TCP/IP, which handles the protocol. The third part is the interface with the hardware, that is the Network Interface Cards, NICs. It basically uses a packet API to communicate with the NICs, transforming all the send requests to a packet, and the second host uses the same TCP/IP stack.
Kernel optimization has done many things to remove the lags and buffer management overheads in here, but it still has many performance overheads. The second step is to have user space TCP/IP. The most prominent works are Arrakis and SandStorm, mTCP, and also some engineering works from the industry like VMA and OpenOnload. All these stacks replace the kernel stack with the user space, using a user space virtual file system and TCP/IP stack. This not only re-implements the kernel stack into the user space but also greatly simplifies the functions, so the performance is greatly improved. However, it still uses the unique packet API.
The third trend in modern data centers is to offload to the RDMAs. Here we use the RDMA NIC to handle the TCP stuff because TCP/IP offers functionality like congestion control and loss recovery. We leverage the hardware-based transport, but the challenge here is how can we map the socket primitive to the RDMA primitive because they are radically different. There are several works, for example, rSocket and SDP. Essentially, they are the same work. FreeFlow offers the virtualization of RDMA, and it also uses rSocket to provide the socket layer to the applications.
rSocket is basically the state-of-the-art in this category. However, it still has some compatibility problems; it cannot run nginx actually because it does not support event polling kind of things.
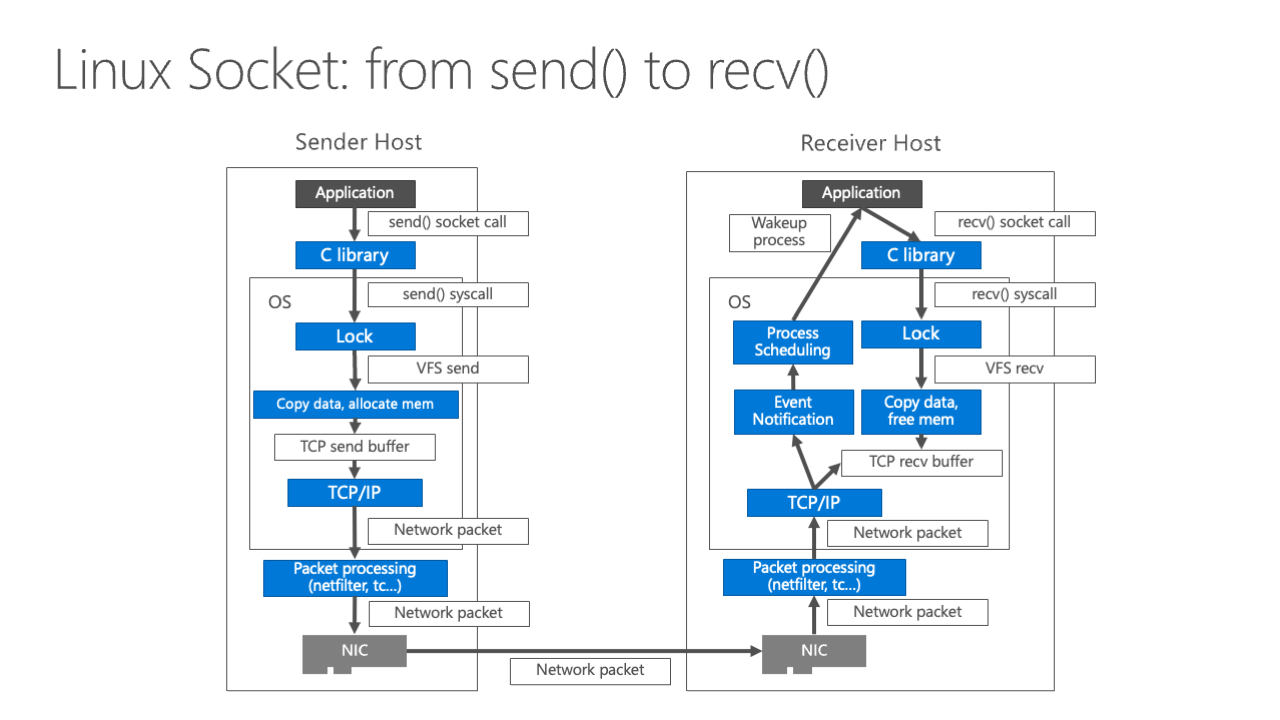
After reviewing the related work, we basically see why the socket is slow and where the overhead comes from. So we can just overcome them one by one. When a host application sends something, it causes the send system calls to the operating system, and it acquires a lock. It needs to acquire a lock because there are multiple threads in a process and the multiple threads share a socket file descriptor, meaning the streams are sent via the socket concurrently.
It needs to take this lock and then transforms it to a send request inside the virtual file system, then it copies data, allocates memory, and puts the data into the TCP send buffer. Then, the TCP/IP stack here puts the network packet to the NIC. On the receiver’s end, it’s pushed into the TCP receive buffer, and then sends the event to notify the application. Then the application can call the receive socket call to receive that package, to copy that from the receive buffer to the application.
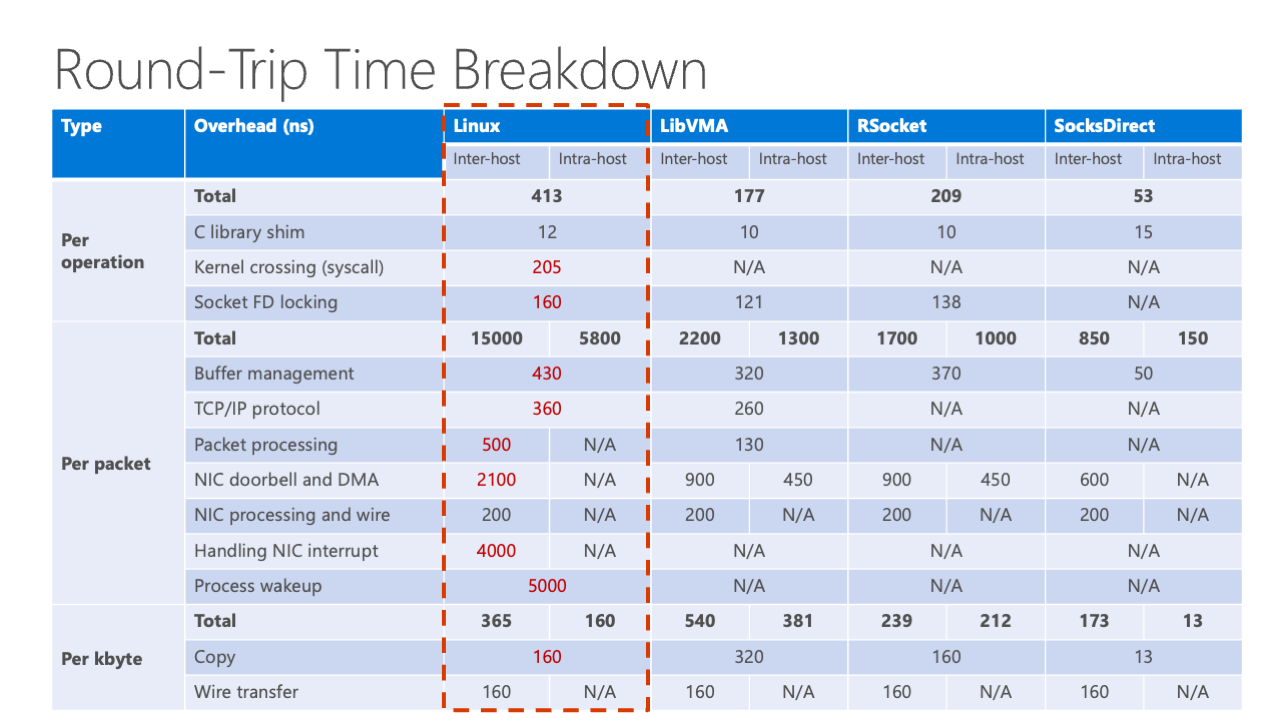
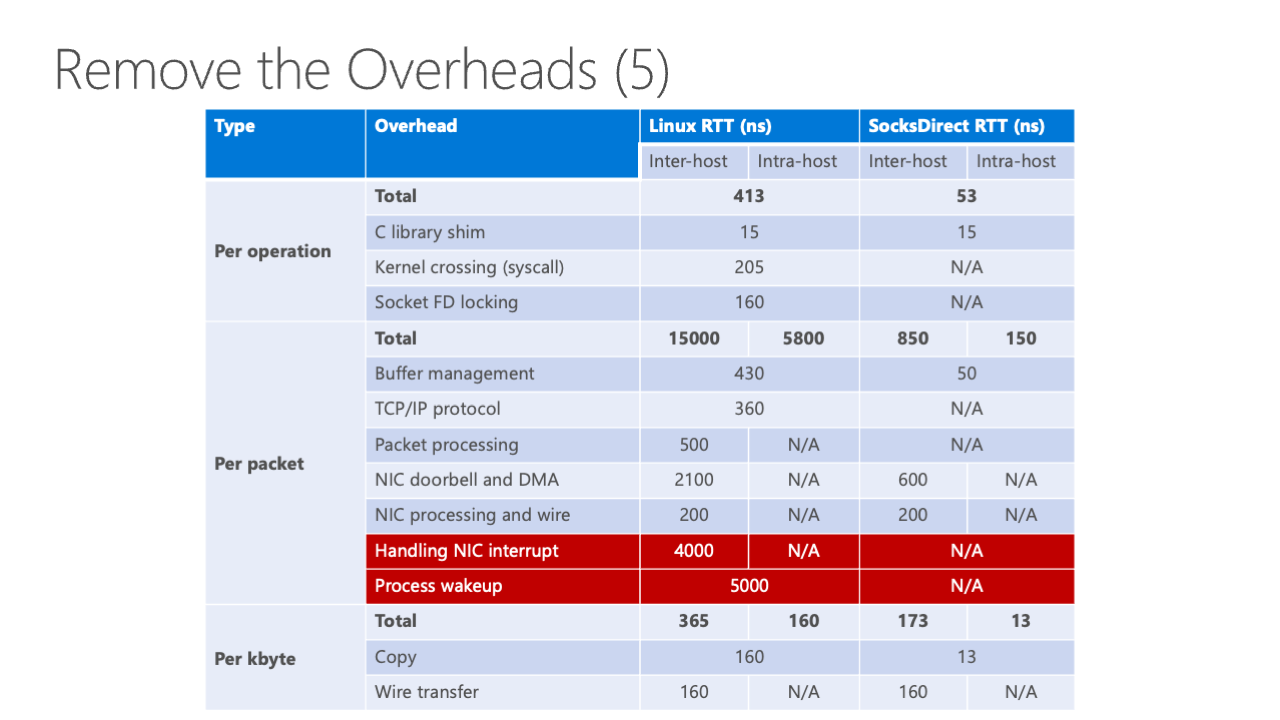
This is the basic pathway. We can see there are a lot of steps involved here. If we do a runtime breakdown of all these things, we can see that there are a lot of overheads. On Linux, on the left side of this figure, we can see the left side is inter-host, which means the connection between two hosts, and intra-host means the connection between two processes inside the host.
For this, we can see that there are a lot of overheads. The most prominent ones are the NIC Doorbell and DMA, also handling NIC interrupt and process wakeup. The most recent works, for example, VMW which is a user space TCP/IP stack optimized for Mellanox NIC, has reduced some of the overheads but left some of them on the table. For rSocket, it is a state-of-the-art RDMA based socket stack which transforms socket into RDMA, reducing some of the overheads but still leaving some like kernel FD locking and package processing and also the buffer management overheads too.
So our goal is to reduce all of these overheads and achieve good throughput. Also, we would like to achieve zero copy because the per kilobyte overhead is still there.

Here are our design goals:
- First, we need to be compatible with all existing applications, serving as a drop-in replacement with no application modification.
- Second, it needs to preserve isolation, meaning that if one application is malicious, it cannot make other applications behave erratically. It also needs to uphold access control policies, for instance, preventing communication between two applications that should not be communicating, by enforcing ACL rules.
- The third goal is to achieve high performance.

This brings us to our basic architecture. In order to achieve these three goals, we implemented the stack in user space and utilized shared memory and RDMA as a transport. As we said, we belong to the third category of high-performance socket systems.
To understand how one application communicates with another, consider this: We need to connect to another application and send a connect request to the monitor process. This process checks its rules and, if allowed, it creates a shared buffer for them. For instance, if the two processes are on the same server for intra-host communication for privacy, it then sends an event to the application to notify that “here is a connection, you need to handle that.”
The application accepts the connection and the monitor notifies the process to accept that connection. Now, the process can utilize the shared buffer to send data, and the second process can receive data. Essentially, we use this monitor process, which is a user-space daemon process.

We essentially employ this monitor process, which operates in user space, to coordinate global resources and enforce ACL rules. We can also leverage different transports for data; for intrahost communication, we use an in-memory queue and a shared memory queue. For inter-host communications, we utilize our library, which we refer to as “libsd”, to make unique RDMA API calls, with the second host following the same step.
A final issue to address is compatibility with peers that do not support RDMA or SocksDirect, like internet hosts or those using a legacy TCP stack. We maintain compatibility with these TCP/IP hosts by adding a TCP compatibility layer to transform it into a NIC packet API.
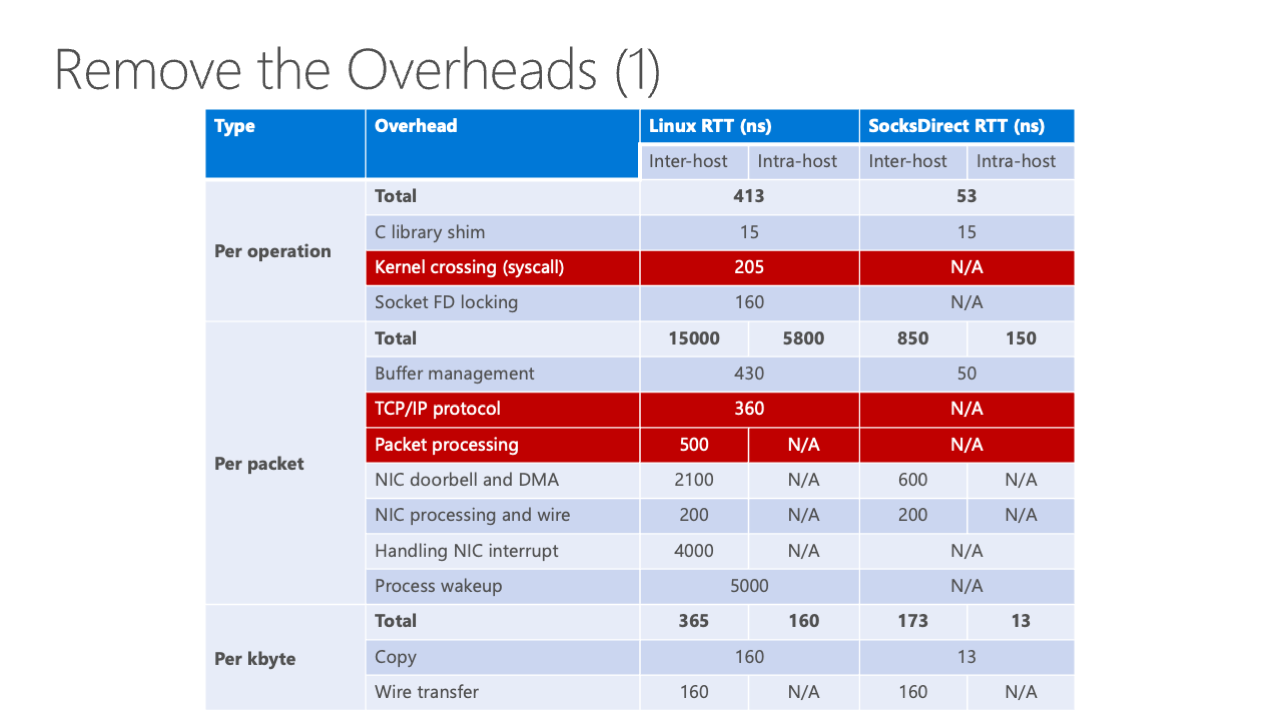
Next, we will demonstrate how we employ various techniques to remove all overheads. The initial techniques eliminate kernel crossing overhead, which entails system calls, as well as TCP/IP and packet processing overhead.

The next issue is socket FD locking, where we aim to abolish locks while preserving socket function practices. The need for this lock stems from having multiple senders or receivers sharing the socket across threads and processes.

Our solution utilizes a token-based socket stack. In this setup, a sender tool holds a send token while the receiver holds a receive token. If another sender wishes to send, they must request a token from the monitor, which facilitates the transfer of the send token, thus permitting the other sender to proceed. This design rationale leverages the infrequency of concurrent sends through the same shared memory, optimizing for common cases while preparing for the worst-case scenarios.

Another challenge is handling process forks, which are difficult to manage given the stringent requirements of Linux semantics, including the necessity for sequential file descriptor allocation. The fork mechanism must ensure the new file descriptor remains invisible to the child process, maintaining privacy to the parent process. This necessitates a copy-on-write strategy, establishing a new file system for the parent process, alongside the creation of a new FD table and socket data for the child process when it generates a new file descriptor.
An additional limitation relates to RDMA queue pairs, which cannot be shared among processes or threads, owing to restrictions in the libibverbs library. Consequently, the duplication of queue pairs is required to facilitate independent access for each process in their respective spaces.

Next, we address the buffer management overhead, with a focus on minimizing ring buffer overhead.
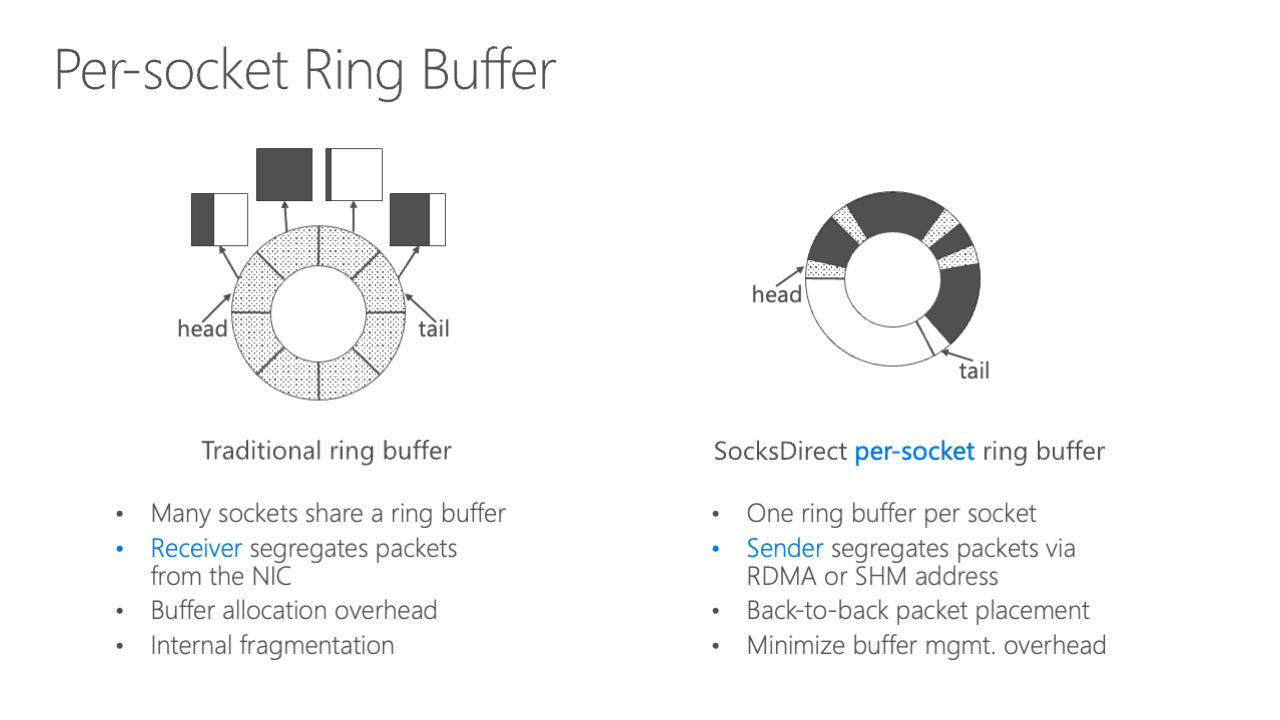
What we do is to reduce the ring buffer overhead. Traditionally, many sockets we share one ring buffer, and the receiver just sends the packet from the NIC, just segregates all the packets from the NIC to different socket buffers. However, our way is to have a per-socket ring buffer because in this way, the sender uses address to directly send the packet to the corresponding receiver ring buffer. So we do not need the buffer allocation overhead, as you see on the left-hand side, it has great internal fragmentation and allocation overhead.
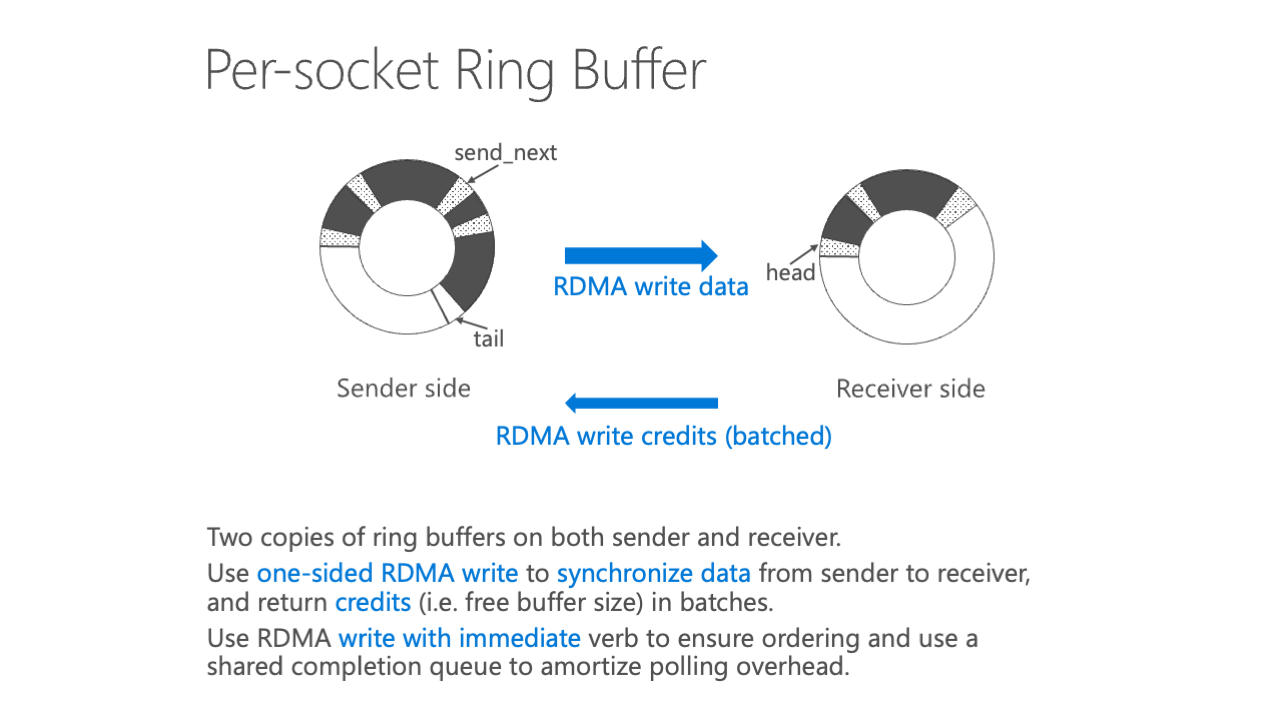
So in order to use RDMA efficiently, we do not use RDMA one-sided verb, which is send and receive. We instead use two-sided verbs, which is atom write only. Sorry, use one-sided verb, atom write only. So the atom write basically synchronizes the data from the sender side to the receiver side. It means that there are two identical copies of data of the ring buffer both sides and it is the credit-based ring buffer, so it means the flow control is done by credit from the receiver side back to the sender side.

And the final overhead is about the packet copy. How can we eliminate this packet copy overhead? So this is actually a very hard thing to do; there are many attempts in the existing work. And actually, none of this existing work eliminates copy overhead and also maintains the socket semantics.
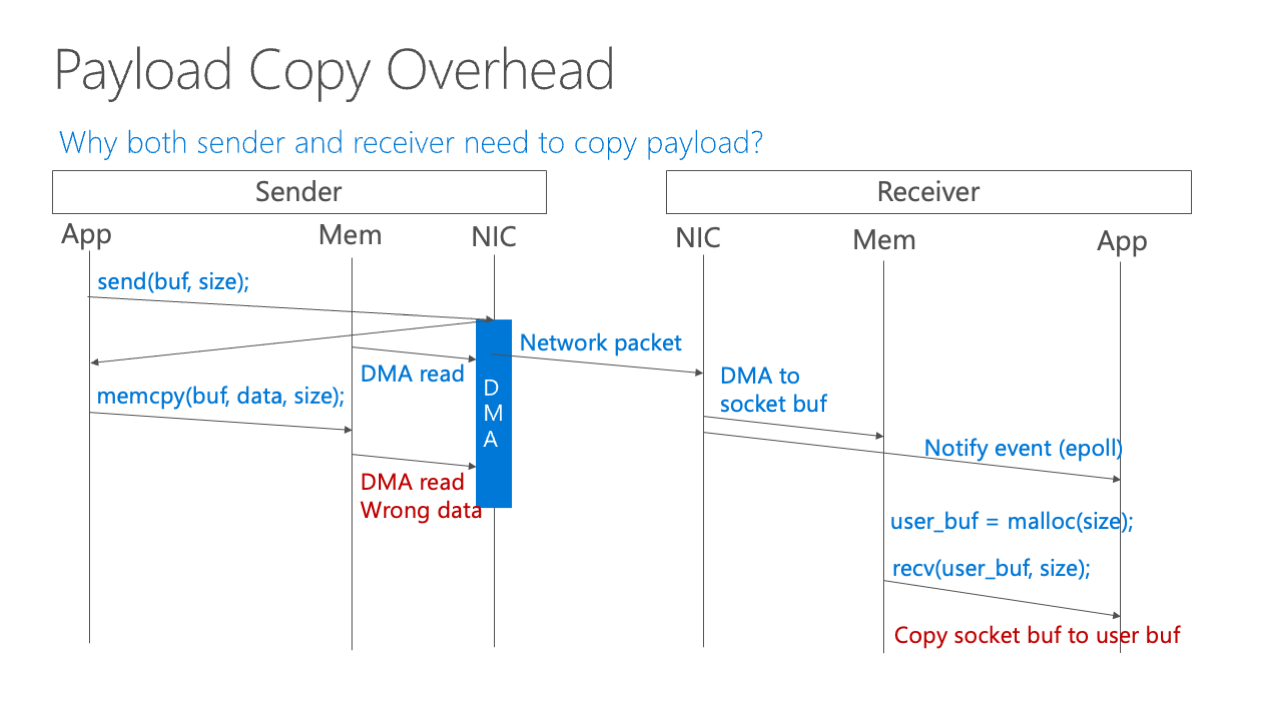
We should first see why we need sender and receiver both to need to copy. So the first, the application sends the buffer to the NIC and the NIC starts DMA, that means to start to read the memory and send off the packet. And then the application, because it just returns is a non-blocking send, so the application does other stuff, for example, writes some data into the buffer, it overwrites the buffer, and then when the NIC just wants to DMA some new data, it reads the wrong data. So this is incorrect behavior we need to avoid this behavior.
And for the receiver side, when the network packet arrives, the receiver set is both send DMA to the socket memory and also notifies the event to the application. Then the application manually allocates a buffer and receives that from the memory. So as we can see here, when the NIC delivers the packet to the memory, it does not know the user-space address. So we need to allocate a buffer inside the stack and copy them. So this is the reason for two copies, we want to eliminate these two copies.
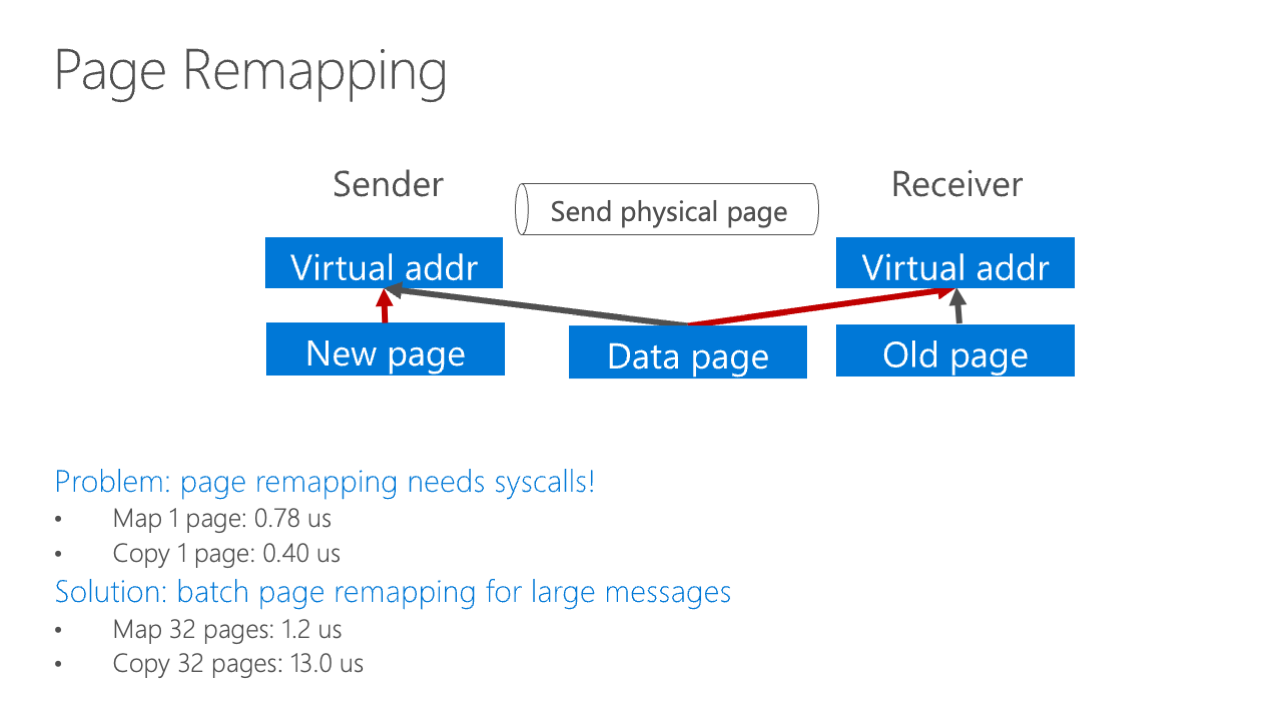
And our mechanism is to leverage the page mapping technique, that is, leverage the virtual address mapping inside modern operating systems. For example here, the sender has a virtual address and the receiver has a virtual address, and the data page is mapped to the data center, and the center just calls a kernel application, a kernel system call, or just some kernel module to get the physical page address of the virtual address, then it sends the physical page address via IDMA or via shared memory queue, then the receiver just can map the data page here.
And also when the sender needs to write to the page, it’s remapped to the new page. Actually, this page remapping technique is not very novel, it existed in the 1990s but we did a lot of improvements on this to make it really zero-copy in modern data center application workloads and the details are in our paper.
Here we show just one simple detail, for example, the page remapping system call has some overhead, so we need to batch the page remapping for large messages. If the message is only one page, we do not do zero-copy, we just copy them, but if the page message is larger than four pages, we just do batch page mapping here.
And the final overhead is NIC interrupts and process wakeup.

All existing work overcome this overhead by using polling. But we also have some improvement, that is to allow multiple processes to share the same CPU core. That is because existing polling-based designs just use one core per application thread. And if we want to have multiple threads, we find that Linux process scheduling has very high overhead.
So we use cooperative context switch as our measure. Get scheduled yield in the system call in Linux is very, very fast, so we can use this to do something, to enable multiple processes to truly be and process packets on the same core.

In summary, our approach effectively addresses various overheads prevalent in high-performance socket systems, presenting a viable solution for modern data center applications. For detailed insights, please refer to our paper.

Finally comes our evaluation. Our evaluation setting includes interserver and intra-server applications.

First, as we can see from the latency side, the IPC latency as shown on the right line is very low, and it is close to the shared memory, and for the inter-host, it is close to RDMA. And for libvma and our socket, we can see that for intra-host, the latency is around one to two microseconds. This is because they use NIC to forward packets inside the same server. This is a very smart solution because it just forwards the packets from the application, bypasses the kernel directly to the NIC, and from the NIC to another application. But the DMA overhead is still there, but because we use shared memory, so this overhead is overcome.
And for the inter-host, this is similar because we can see that libvma has higher overhead because it uses batching. And our socket is similar to SocksDirect. This is because they both use RDMA as the underlying transport and overcome the TCP/IP user-space stack overhead.

And on the throughput side, we can see that SocksDirect bypasses all other similar systems very significantly, and the socket is between this tool. And we can see an interesting point around 4 kilobytes; this is where we can see that SocksDirect has similar performance with other competing systems. This is because we do not have the option to have zero copy here; we only have zero copy for above 16 kilobytes of messages. And for the intra-host packet here, we can see the turning point here very clearly.

Finally, we come to the multi-core scalability. We can see that SocksDirect scales very well with multi-cores, and others do not scale because of the locking overheads and also some allocation overhead. And for the inter-host, we can see that some of the competing designs even have sorry performance when you use multiple cores because of loss lock contention.

And finally comes the application performance; as we said, we do not modify Nginx and just use the LD_PRELOAD to load the libsd library and the performance is improved by five times.

Finally, we need to note some limitations of the work. First, we cannot scale to many connections because our atomic does not scale to many connections due to cache miss problem. And second, our work does not tackle the congestion control and QoS work because at the emerging because our RD doesn’t support this congestion control. But we know that there have been many works to improve that congestion control mechanisms inside the hardware.

Finally, we come to the conclusion. We do the analysis of performance overhead of sockets and design of high-performance and compatible sockets in user space, which existing applications can directly leverage that as a drop-in replacement. And we also develop several techniques to support this kind of— these techniques cannot only be used in SOC but also can be used in other territories, for example, zero-copy file system and others. And the evaluation is very good.

So this is our talk and thanks, and I’m ready for the questions.
Question 1: In one of your figures, you had RDMA scale up to eight cores, but then it stalled. Any explanation?
Answer 1: Yeah, I mean that stops at eight cores. Yeah, on the right-hand side figure you had RDMA scale, yes, next, next one. I think, yeah, um, no this one, yes, this one. Oh yeah, yeah, this because we use RDMA write, and RDMA write stops at 100 mega operations per second. The reason our performance even higher than that is because we use pinning. If we disable pinning, it will be similar to the RDMA. Okay, thanks.
Question 2: Hi, very interesting talk. So there’s something I don’t understand; you mentioned that you are maintaining a monitoring process on each server to maintain the keys, is that right?
Answer 2: Yes, exactly.
Question 2 (continued): So, I’m a little confused about what’s the real responsibility for this monitoring process. And I see that your project has achieved great scalability, even if you have a lot of cores. So when you open a lot of sockets in a single server, what’s the resource usage of the monitoring cores, and could it hurt other processes?
Answer 2 (continued): Yeah, this is a very good question actually. Our initial goal of our project is to support many processes, many concurrent connections. So we designed this monitor process very carefully, and it only takes about 100 bytes per connection. And we have a synthetic workload which has one million of concurrent connections, and it works okay. As long as the RDMA NIC supports that, we can support many concurrent connections without decreasing the performance. You can refer to the discussion section in our paper.
Talk Video: