Bojie Li
2026-01-04
I chatted with an AI for three hours and wrote two sets of reading notes (to test the AI’s capabilities, I deliberately did not make any edits to the AI-generated content).
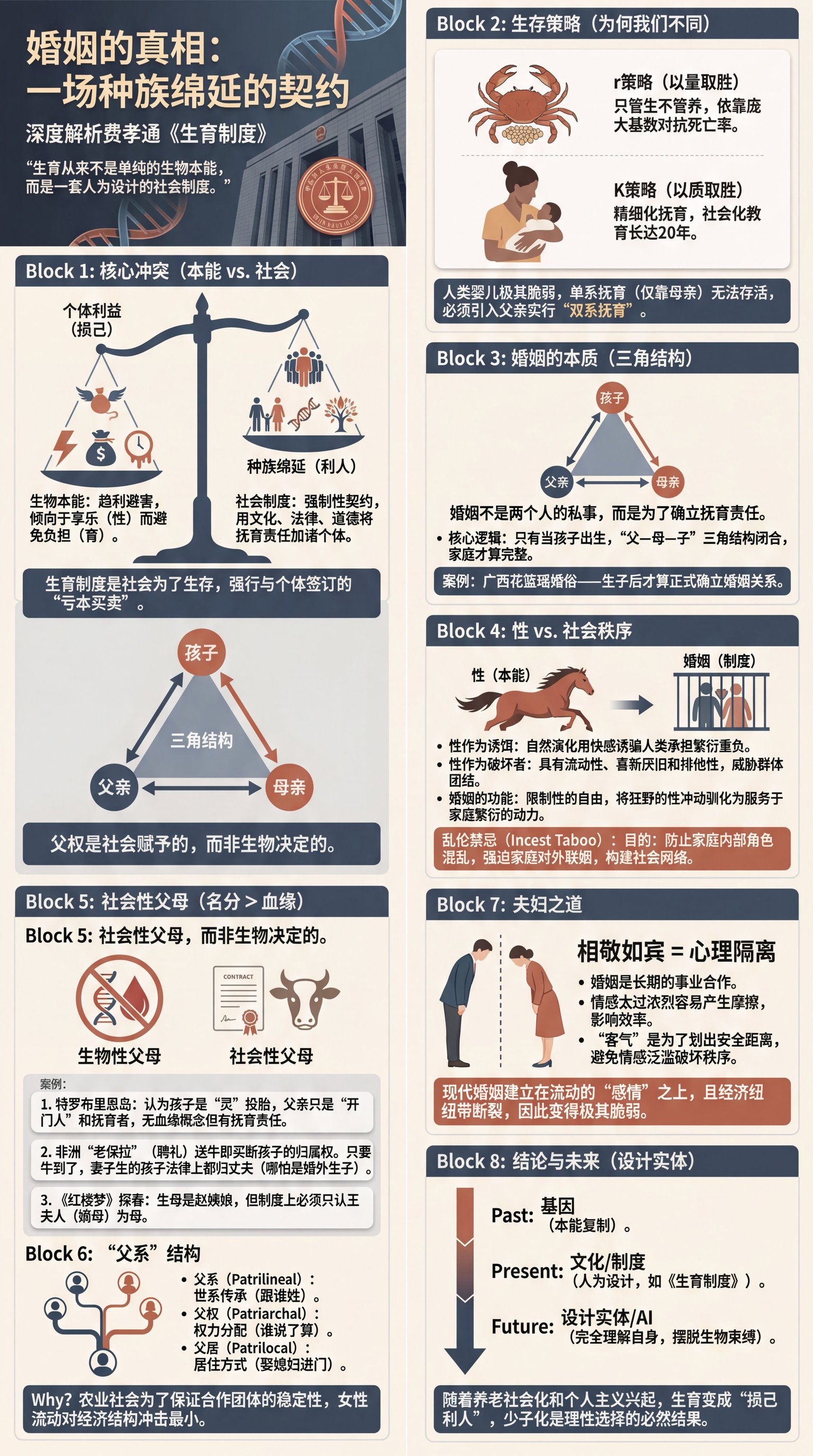
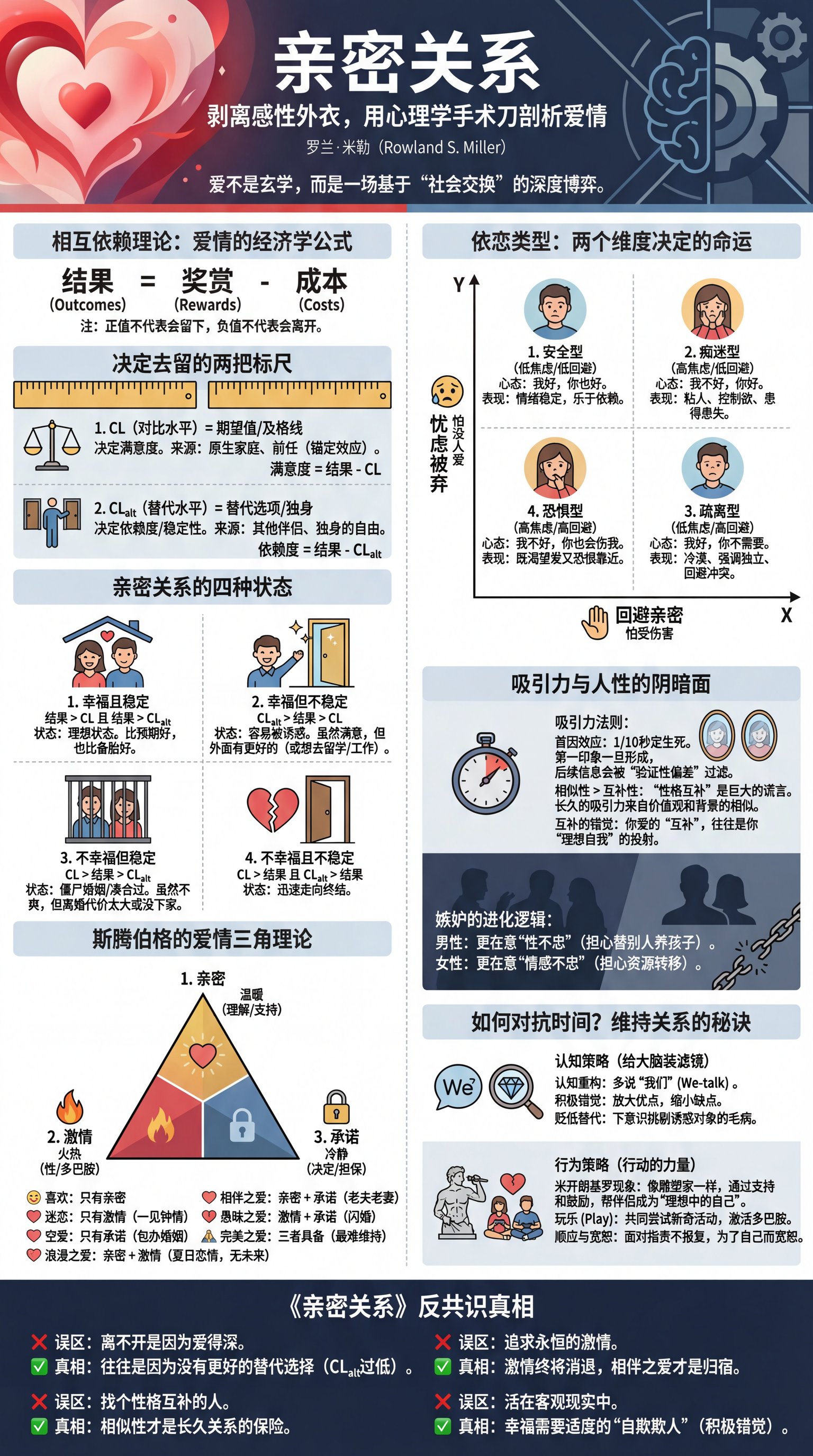
2025-12-21
This month, the Course Review Community encountered a storage performance issue that lasted nearly two weeks, causing slow service responses and degraded user experience. This post documents how the issue was discovered, investigated, and resolved, covering NFS performance, ZFS logs, Proxmox VE virtualization storage configuration, and more.
2025-12-20
(This article is organized from Anthropic team talks and in-depth discussions during AWS re:Invent 2025)
View Slides (HTML), Download PDF Version (note these slides are not official Anthropic material; I reconstructed them from photos and recordings)
Contents
Claude is already smart enough—intelligence is not the bottleneck, context is. Every organization has unique workflows, standards, and knowledge systems, and Claude does not inherently know any of these. This post compiles Anthropic’s best practices for Context Engineering, covering Skills, Agent SDK, MCP, evaluation systems and other core topics to help you build more efficient AI applications.
- 01 | Skills system - Let Claude master organization-specific knowledge
- 02 | Context Engineering framework - Four pillars for optimizing token utility
- 03 | Context Window & Context Rot - Understand context limits and degradation
- 04 | Tool design best practices - Elements of powerful tools
- 05 | Claude Agent SDK - A framework for production-ready agents
- 06 | Sub-agent configuration best practices - Automatic invocation and permissions
- 07 | MCP (Model Context Protocol) - A standardized protocol for tool integration
- 08 | Evaluations - Why evaluation matters and best practices
- 09 | Lessons from building Coding Agents - What we learned from Claude Code
- 10 | Ecosystem collaboration - How Prompts, MCP, Skills, and Subagents work together
2025-12-20
(This article is the invited talk I gave at the first Intelligent Agent Networks and Application Innovation Conference on December 20, 2025)
View Slides (HTML), Download PDF Version
Abstract
Today’s agent–human interaction is centered on text, but that deviates from natural human cognition. From first principles, the modality humans are best at for output is speech (speaking is three times faster than typing), and the modality humans are best at for input is vision. Vision is not text, but intuitive UI.
The first step is achieving real‑time voice interaction. The traditional serial VAD–ASR–LLM–TTS architecture suffers from having to wait for the user to finish speaking before it can start “thinking,” and it cannot output before the thinking is done. With an Interactive ReAct continuous‑thinking mechanism, the agent can listen, think, and speak at the same time: it starts thinking while the user is talking, and keeps deepening its reasoning while it’s speaking itself, making full use of all idle time gaps.
The second step is to expand the observation space and action space on top of real‑time voice. By extending the Observation Space (from voice input to Computer Use–style visual perception) and the Action Space (from voice output to UI generation and computer control), the agent can operate existing computer/phone GUIs while on a call, and generate dynamic UI to interact with the user. One implementation path for generative UI is generating front‑end code; Claude 4.5 Sonnet has already reached the threshold for this. Another path is generating images; Nano Banana Pro is also close to this threshold.
This is exactly the path used to realize Samantha in the movie Her. As an operating system, Samantha needs five core capabilities: real‑time voice conversation with the user, making phone calls and handling tasks on the user’s behalf, operating traditional computers and phones for the user, bridging data across the user’s existing devices and online services, having her own generative UI interface, and possessing powerful long‑term user memory for personalized proactive services.
2025-12-19
(This article is the invited talk I gave at AWS re:Invent 2025 Beijing Meetup)
Click here to view Slides (HTML), Download PDF version
Thanks to AWS for the invitation, which gave me the opportunity to attend AWS re:Invent 2025. During this trip to the US, I not only attended this world-class tech conference, but was also fortunate enough to have in-depth conversations with frontline practitioners from top Silicon Valley AI companies such as OpenAI, Anthropic, and Google DeepMind. Most of the viewpoints were cross-validated by experts from different companies.
From the re:Invent venue in Las Vegas, to NeurIPS in San Diego, and then to AI companies in the Bay Area, more than ten days of intensive exchanges taught me a great deal. Mainly in the following aspects:
Practical experience of AI-assisted programming (Vibe Coding): An analysis of the differences in efficiency improvement in different scenarios—from 3–5x efficiency gains in startups, to why the effect is limited in big tech and research institutions.
Organization and resource allocation in foundation model companies: An analysis of the strengths and weaknesses of companies like Google, OpenAI, xAI, Anthropic, including compute resources, compensation structure, and the current state of collaboration between model teams and application teams.
A frontline perspective on Scaling Law: Frontline researchers generally believe that Scaling Law is far from over, which diverges from the public statements of top scientists such as Ilya Sutskever and Richard Sutton. Engineering approaches can address sampling efficiency and generalization issues, and there is still substantial room for improvement in foundation models.
Scientific methodology for application development: An introduction to the rubric-based evaluation systems that top AI application companies widely adopt.
Core techniques of Context Engineering: A discussion of three major techniques to cope with context rot: dynamic system prompts, dynamic loading of prompts (skills), sub-agents plus context summarization. Also, the design pattern of using the file system as the agent interaction bus.
Strategic choices for startups: Based on real-world constraints of resources and talent, an analysis of the areas startups should avoid (general benchmarks) and the directions they should focus on (vertical domains + context engineering).
2025-12-18
In the previous article, “Set Up an Install-Free IKEv2 Layer-3 Tunnel to Bypass Cursor Region Restrictions”, we introduced how to use an IKEv2 layer-3 tunnel to bypass geo-restrictions of software like Cursor. Although the IKEv2 solution has the advantage of not requiring a client installation, layer-3 tunnels themselves have some inherent performance issues.
This article will introduce a more efficient alternative: using Clash Verge’s TUN mode together with the VLESS protocol, which keeps things transparent to applications while avoiding the performance overhead brought by layer-3 tunnels.
Performance Pitfalls of Layer-3 Tunnels
The IKEv2 + VLESS/WebSocket architecture from the previous article has three main performance issues:
- TCP over TCP: application-layer TCP is encapsulated and transported inside the tunnel’s TCP (WebSocket), so two layers of TCP state machines interfere with each other
- Head-of-Line Blocking: multiple application connections are multiplexed over the same tunnel; packet loss on one connection blocks all connections
- QoS Limits on Long Connections: a single long-lived connection is easily throttled by middleboxes on the network
2025-10-24
Reinforcement learning pioneer Richard Sutton says that today’s large language models are a dead end.
This sounds shocking. As the author of “The Bitter Lesson” and the 2024 Turing Award winner, Sutton is the one who believes most strongly that “more compute + general methods will always win,” so in theory he should be full of praise for large models like GPT-5, Claude, and Gemini. But in a recent interview, Sutton bluntly pointed out: LLMs merely imitate what humans say; they don’t understand how the world works.
The interview, hosted by podcaster Dwarkesh Patel, sparked intense discussion. Andrej Karpathy later responded in writing and further expanded on the topic in another interview. Their debate reveals three fundamental, often overlooked problems in current AI development:
First, the myth of the small-world assumption: Do we really believe that a sufficiently large model can master all important knowledge in the world and thus no longer needs to learn? Or does the real world follow the large-world assumption—no matter how big the model is, it still needs to keep learning in concrete situations?
Second, the lack of continuous learning: Current model-free RL methods (PPO, GRPO, etc.) only learn from sparse rewards and cannot leverage the rich feedback the environment provides. This leads to extremely low sample efficiency for Agents in real-world tasks and makes rapid adaptation difficult.
Third, the gap between Reasoner and Agent: OpenAI divides AI capabilities into five levels, from Chatbot to Reasoner to Agent. But many people mistakenly think that turning a single-step Reasoner into a multi-step one makes it an Agent. The core difference between a true Agent and a Reasoner is the ability to learn continuously.
This article systematically reviews the core viewpoints from those two interviews and, combined with our practical experience developing real-time Agents at Pine AI, explores how to bridge this gap.
2025-10-16
View Slides (HTML), Download PDF Version
Contents
- 01 | The Importance and Challenges of Memory - Personalization Value · Three Capability Levels
- 02 | Representation of Memory - Notes · JSON Cards
- 03 | Retrieval of Memory - RAG · Context Awareness
- 04 | Evaluation of Memory - Rubric · LLM Judge
- 05 | Frontier Research - ReasoningBank
Starting from personalization needs → Understanding memory challenges → Designing storage schemes → Implementing intelligent retrieval → Scientific evaluation and iteration
2025-09-28
The protocol documentation for Unified Bus has finally been released. Most of the initial design work for the protocol was done four or five years ago, and I haven’t worked on interconnects for more than two years. Yet reading this 500+ page document today still feels very familiar.
As with most protocol documents, the UB documentation presents a wealth of details about the Unified Bus protocol, but rarely touches on the thinking behind its design. As a small foot soldier who participated in UB in its early days, I’ll share some of my personal thoughts. The productized UB today may differ in many ways from what we designed back then, so don’t take this as an authoritative guide—just read it as anecdotes.
Why UB
To understand the inevitability of Unified Bus (UB), we must return to a fundamental contradiction in computer architecture: the split between the Bus and the Network.
For a long time, the computing world has been divided into islands by these two completely different interconnect paradigms.
- Inside an island (for example, within a single server or a chassis), we use bus technologies such as PCIe or NVLink. They are designed for tightly coupled systems; devices share a unified physical address space, communication latency can be on the order of nanoseconds, and bandwidth is extremely high. This is a performance paradise, but its territory is very limited—the physical distance and the number of devices a bus can connect are strictly constrained.
- Between islands, we rely on network technologies such as Ethernet or InfiniBand. They are born for loosely coupled systems, excel at connecting tens of thousands of nodes, and have superb scalability. But that scalability comes at a cost: complex protocol stacks, additional forwarding overhead, and latencies in the microsecond or even millisecond range create an orders-of-magnitude gap compared with buses.
This “inside vs. outside” architecture worked well for a long time. However, a specter began to haunt the computing world—Scaling Law.
About 10 years ago, researchers in deep learning discovered a striking regularity: as long as you keep increasing model size, data, and compute, model performance predictably and steadily improves. This discovery changed the game. What used to be a “good enough” single machine with 8 GPUs suddenly became a drop in the bucket in the face of models with tens or hundreds of billions of parameters.
At that moment, a clear and urgent need presented itself to system architects everywhere: can we tear down the wall between buses and networks? Can we create a unified interconnect that offers bus-level programming simplicity and extreme performance, while also providing network-level massive scalability?
This is UB’s core mission. It’s not merely a patch or improvement on existing protocols but a thorough rethinking. UB aims to build a true “datacenter-scale computer,” seamlessly connecting heterogeneous compute, memory, and storage across the entire cluster into a unified, programmable whole. In this vision, accessing memory on a remote server should be as simple and natural as accessing local memory; tens of thousands of processors should collaborate as efficiently as if they were on a single chip.
2025-09-12
Recently, Alibaba’s Qwen team released the Qwen3-Next model, another major innovation after Qwen3. The model achieves multiple breakthroughs in architectural design, especially reaching industry-leading levels in the balance between inference efficiency and performance. This article briefly summarizes Qwen3-Next’s core innovations.
Three major breakthroughs of Qwen3-Next:
- Hybrid attention architecture: 3 layers of linear attention + 1 layer of traditional attention, incorporating DeltaNet’s delta rule idea
- Ultra-sparse MoE: only 11 of 512 experts activated; 80B parameters with only 3B activated
- 100+ tokens/s inference speed: reaches a state-of-the-art level via MTP
Core value: With 1/10 the compute cost and 10× the token processing speed, it achieves performance surpassing 32B dense models, benchmarking against Gemini 2.5 Flash.