The Dilemma of Continuous Learning for Agents: Why a Reasoner Is Not a True Agent
Reinforcement learning pioneer Richard Sutton says that today’s large language models are a dead end.
This sounds shocking. As the author of “The Bitter Lesson” and the 2024 Turing Award winner, Sutton is the one who believes most strongly that “more compute + general methods will always win,” so in theory he should be full of praise for large models like GPT-5, Claude, and Gemini. But in a recent interview, Sutton bluntly pointed out: LLMs merely imitate what humans say; they don’t understand how the world works.
The interview, hosted by podcaster Dwarkesh Patel, sparked intense discussion. Andrej Karpathy later responded in writing and further expanded on the topic in another interview. Their debate reveals three fundamental, often overlooked problems in current AI development:
First, the myth of the small-world assumption: Do we really believe that a sufficiently large model can master all important knowledge in the world and thus no longer needs to learn? Or does the real world follow the large-world assumption—no matter how big the model is, it still needs to keep learning in concrete situations?
Second, the lack of continuous learning: Current model-free RL methods (PPO, GRPO, etc.) only learn from sparse rewards and cannot leverage the rich feedback the environment provides. This leads to extremely low sample efficiency for Agents in real-world tasks and makes rapid adaptation difficult.
Third, the gap between Reasoner and Agent: OpenAI divides AI capabilities into five levels, from Chatbot to Reasoner to Agent. But many people mistakenly think that turning a single-step Reasoner into a multi-step one makes it an Agent. The core difference between a true Agent and a Reasoner is the ability to learn continuously.
This article systematically reviews the core viewpoints from those two interviews and, combined with our practical experience developing real-time Agents at Pine AI, explores how to bridge this gap.
The Three Core Problems Raised by Richard Sutton
1. LLMs Are Not True World Models
Sutton’s first core point is: LLMs are not true world models; they can only predict what people will say, not what the world will become.
This distinction is crucial. A real world model should be able to predict what changes in the world will occur if I perform a certain action. For example:
- I raise my hand, and the cup moves upward
- I let go of my hand, and the cup falls and breaks
What do LLMs learn instead? They learn what a person would say or do in a certain situation. This is essentially imitation learning, not an understanding of the world’s causal laws.
Of course, after massive pretraining, LLMs do acquire some reasoning capabilities. But that is not equivalent to constructing a rigorous transition model (state transition model). The textual descriptions in pretraining data are more like “observing changes in the world from the outside” rather than learning interactively in the first person how the world changes after I take an action.
2. RL’s Low Sample Efficiency and Inability to Learn from Environment Feedback
Sutton’s second point is: current RL methods are extremely sample-inefficient and can only learn from rewards; they cannot learn from direct feedback from the environment (observations).
Let’s use a concrete example to illustrate this. At Pine AI, for instance, we develop AI Agents to help users handle tasks over the phone (such as calling Xfinity customer service):
First attempt: The Agent calls customer service, the agent on the line says, “I need the last 4 digits of your credit card to verify your identity.” Our Agent doesn’t have this information, can only hang up, the task fails, reward = 0.
The problem with traditional RL: The Agent only knows that this attempt failed (reward = 0), but it doesn’t know what it should have done instead. The customer service rep clearly stated what information was needed, but the Agent cannot learn from this environmental feedback. Only after hundreds of rollouts, when it randomly tries providing the credit card information, gets reward = 1, can it finally “learn” what to do.
How humans learn: The first time a human is told credit card information is needed, they’ll immediately write it down in a notebook. Next time in a similar situation, they’ll proactively prepare this information.
The root cause of this difference is: current policy gradient methods like PPO and GRPO are all model-free algorithms, essentially learning only from rewards and not from observations.
Model-free means these methods only learn a policy—i.e., “what action to take in a given state”—but not a world model—i.e., “what the world will become after taking a certain action.” This prevents them from leveraging the rich information the environment provides; they can only rely on sparse reward signals.
3. Lack of Guaranteed Generalization
Sutton’s third problem is: the representations learned through gradient descent do not come with guaranteed generalization.
If a problem has only one correct answer (like a math problem), the model will eventually find that answer. But if a problem has multiple possible solutions, gradient descent has no inherent bias that forces it to find the representation that generalizes most easily.
Although we use various regularization techniques during training to improve generalization, these mechanisms don’t guarantee the learned representations will reflect deep, reasoning-friendly principles. That’s why many Agent systems require external memory modules to explicitly summarize and structure knowledge.
How Current Agents Learn and Their Limitations
Faced with the problems Sutton raises, current Agent systems primarily rely on three strategies:
1. In-Context Learning: Misconceptions About Long Context
In-context learning can solve learning within a single session. In the example above, once the customer rep says they need credit card information, that information remains in the context, so in the next step within the same session the Agent knows it should ask the user. If we carry the context into subsequent tasks, the Agent can also apply that knowledge to new tasks.
But many people think that since we now have long context, we can simply stuff all historical information into it and let the model automatically reason and learn. This is a serious misunderstanding of what context can do.
The Nature of Context: Retrieval, Not Summarization
The essence of context is closer to RAG than to a reasoning engine. Each token is mapped to three vectors, Q, K, and V, and the attention mechanism is used to find the most relevant context for the current query. This means knowledge is not automatically distilled and summarized, but stored in its original form within the KV cache embeddings.
Let me use a few practical cases to make this clear.
Case 1: Counting black and white cats
Suppose the context contains 100 cases: 90 black cats and 10 white cats. If I don’t tell the model the summary “90 black cats, 10 white cats” but instead list the 100 individual cases one by one, then every time we ask a related question, the model must spend extra reasoning tokens scanning those 100 cases again to recount and recompute.
From the attention map we can clearly see: when asked “what is the ratio of black cats to white cats,” all the case tokens (the 100 cat cases) receive relatively high attention, and the reasoning tokens repeat the counting and statistics done in previous turns. This indicates the model is reasoning from raw information rather than using already summarized knowledge.
Worse, every time a related question comes up, this re-scanning and re-reasoning repeats, which is extremely inefficient and error-prone. Essentially, knowledge remains stored in raw form; the KV cache does not automatically summarize it.
Case 2: Incorrect reasoning about Xfinity discount rules
Assume we have three isolated historical cases: veterans can receive Xfinity discounts, doctors can receive discounts, and others cannot. Without extracting the rule “only veterans and doctors can receive Xfinity discounts,” and merely throwing all cases into context, the model might randomly match only one or two of the historical cases instead of all relevant ones when seeing a new case, leading to wrong conclusions.
Again, attention maps show that during reasoning, the model spreads attention across the tokens of those three isolated cases, attempting to find a pattern by scanning them each time. But without explicit rule extraction, this reasoning is both inefficient and unreliable.
Case 3: Losing control of phone call counts
In real development we’ve encountered a typical issue: the prompt specifies “don’t call the same customer more than 3 times.” Yet after 3 calls, the Agent often loses track of how many calls were already made, makes a 4th call, or even falls into a few-shot-like loop and keeps calling the same number repeatedly.
The root of the problem is that the model has to count on its own how many times a number has been dialed, based on multiple tool-call records in the context. This counting requires re-scanning the context every time, and counting in a long context is inherently error-prone.
But after we directly add the repeated-call count for each phone call in the tool call result (such as “this is the 3rd call to this customer”), the model immediately recognizes that the limit has been reached and stops calling. This simple change dramatically reduces error rates.
Why System Hints and Dynamic Summarization Work
That’s why system hint techniques and dynamic summarization significantly improve Agent performance. By adding summaries, supplements, and additional structured information into the context, we let the model skip re-deriving everything from raw data every time and instead leverage distilled knowledge directly. This greatly improves the efficiency and accuracy of subsequent reasoning.
Even with sparse attention or other mechanisms to support long context, the fundamental problem remains: no concise knowledge representation is found; no automatically distilled, rule-like structure emerges.
Since current long-context mechanisms do not automatically compress and distill knowledge, we’ve discovered an important architectural principle in practice:
Sub-agents should not share the full context with the Orchestrator Agent.
The correct approach is: the Orchestrator Agent maintains the full task context, compresses and summarizes the relevant information and then passes it to the sub-agents. Sub-agents only receive the distilled information that is directly related to their own tasks.
The benefit is not just saving context length. While it does reduce token consumption, the more important value is knowledge extraction. This compression and summarization process is essentially a process of knowledge extraction and structuring, which is an indispensable capability of an Agent system.
Karpathy’s insight: bad memory is a feature, not a bug
In an interview, Karpathy提出了一个深刻的观点:人类的精确记忆能力很差,但这不是 bug,而是 feature。记忆能力差强制我们从训练数据中提取关键知识,用结构化方式总结和记忆,而不是简单地背诵训练数据。这个洞察揭示了为什么 context 不应该只是简单的信息堆砌,而需要进行知识压缩和提炼。
This is why linear attention is an interesting direction. Linear attention uses a relatively small state to compress the knowledge in the context, forcing the model to perform knowledge compression instead of remembering everything. This mechanism is closer to the human way of memory and may lead to better generalization.
Cross-modal compression: insights from DeepSeek-OCR
DeepSeek-OCR offers another interesting perspective: compressing long textual context into an image through optical 2D mapping. Traditional text tokens form a 1D sequence, while images are 2D structures. DeepSeek-OCR renders text into images and then uses a visual encoder (DeepEncoder) for compression, achieving an OCR accuracy of 97% at 10x compression, and still about 60% at 20x compression.
The value of this cross-modal compression is not only in saving tokens; more importantly, it forces information distillation. The visual encoder must extract the key features of the text instead of storing it character by character. The 2D spatial structure preserves the layout and hierarchy of the text. The compression process is similar to how humans read: they focus on the overall structure rather than memorizing each word. It can also solve classic tokenizer issues like “being unable to count how many r’s there are in strawberry”.
For Agent systems, this idea is highly inspiring: compressing large amounts of historical interactions into visual summaries (such as mind maps or flowcharts) may be more efficient than retaining the full text. This also echoes Karpathy’s insight: poor memory forces us to distill the essence.
2. External knowledge base
Another method is to use an external knowledge base and store rules extracted from experience as structured knowledge. For example: “When contacting Xfinity, you must prepare the last four digits of your credit card.”
This knowledge extraction process can leverage extra reasoning compute (such as calling a stronger model), which aligns with Sutton’s “The Bitter Lesson” principle of “general methods that scale with computation”: instead of hand-coding rules, let the system automatically learn and distill them from experience.
The advantage of this method is that the knowledge representation is more concise, but it also has problems: knowledge base retrieval may fail, isolated fragments of knowledge are hard to use for complex reasoning, and retrieval efficiency will drop as knowledge accumulates.
Continual learning: the gap between Agents and real-world tasks
Why do Agents perform poorly on real-world tasks?
This is a very fundamental question. Many people ask: Agents are better than 99.9% of humans at solving math problems, so why can’t they perform well in real-world work?
Consider this: suppose you find a very smart person and put them to work in your company without any training. Do you think they would do well?
The answer is very likely no, because:
- They don’t understand the company’s coding style
- They don’t know the company’s business logic
- They are not aware of explicit and implicit constraints
- They are unfamiliar with the team’s collaboration style
Even if you collect all this context into documents and give it to them, there are still issues: much tacit knowledge is hard to express in text, the amount of such knowledge may exceed the context window, and textual knowledge is difficult to use for deep reasoning.
Why can humans do well? Because humans can continually learn in an environment.
Big World Hypothesis vs Small World Hypothesis
Richard Sutton subscribes to the Big World Hypothesis: the world contains an infinite amount of information, and models can only learn a tiny fraction of it. Agents cannot know all knowledge in advance and must constantly learn new capabilities through interaction with the environment.
Many LLM proponents, however, hold the Small World Hypothesis: although the world is large, it can be described with relatively simple rules. The knowledge behind seemingly complex phenomena is not that much, and sufficiently large models (such as GPT-5, Claude) have already learned most of the important knowledge in the world. They do not need to learn in the environment; they only need to apply this general knowledge.
The real world better fits the Big World Hypothesis. Knowledge learned from books and the internet is theoretical and general, but when an Agent works in any specific position, it needs non-public industry and domain-specific knowledge, the company’s particular rules and culture, and individual work habits and preferences.
This knowledge cannot be fully conveyed through a short prompt; it must be acquired through continual learning. And the model-free RL methods mentioned earlier cannot learn from environmental feedback, which is precisely the fundamental reason why Agents struggle to quickly adapt to real-world tasks.
Exploring solutions: Dual LoRA
To address continual learning, we have explored some solutions in practice. The core idea is: during RL, in addition to learning the policy, we also learn the transition model.
Dual LoRA method
We are experimenting with a Dual LoRA method:
LoRA 1: Policy Learning uses a method similar to DAPO, updating gradients based on rewards to learn which actions maximize returns.
LoRA 2: Transition Model Learning uses next token prediction, but instead of predicting the action, it predicts the observation. By minimizing the prediction loss of tool call results, it constantly updates its understanding of the world. This idea is similar to Meta’s recent Early Experience paper: learning a world model by predicting environmental feedback.
Essentially, this is a form of TD-Learning (Temporal Difference Learning): I predict the next world state after taking an action; if the actual state differs from the prediction, that constitutes a loss, and I update the model’s understanding of the world based on that loss.
Technical implementation details
The key to Dual LoRA lies in orthogonal decomposition of the parameter space:
Rank allocation: suppose we allocate a total rank = 64 LoRA parameter space. We divide it into two parts:
- LoRA 1 (Policy): the first 32 ranks
- LoRA 2 (World Model): the last 32 ranks
Gradient isolation and optimization:
Policy Gradient (LoRA 1):
- Uses the DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization) algorithm
- Gradients only update the first 32 ranks
Observation Prediction Loss (LoRA 2):
- Uses standard next token prediction
- Gradients only update the last 32 ranks
- Loss function:
L_world = -E[log P(o_{t+1} | s_t, a_t)] - Where o_{t+1} is the observation returned by the environment (tool call result)
Training process:
At each training step:
- The Agent takes an action and gets an observation and a reward.
- Compute two losses:
L_policy: based on reward and advantageL_world: based on observation prediction error
- Perform gradient updates on the two rank groups separately:
∇_{LoRA1} L_policy→ updates the first 32 ranks∇_{LoRA2} L_world→ updates the last 32 ranks
- The two gradients are orthogonal in parameter space and do not interfere with each other.
Huge improvement in sample efficiency
Returning to the previous example, with the Dual LoRA method:
Traditional RL needs hundreds of rollouts to occasionally discover that providing credit card information can succeed and then finally learn it.
The Dual LoRA + TD-Learning process, however, works like this: the first time customer service says you need credit card information, even though reward = 0 and the policy gradient learns nothing, the environment feedback tells us that we need the CVV. Through the observation prediction loss, the model can learn this within just a few steps.
This method is far more sample-efficient than traditional RL.
Knowledge summarization and structuring
Even with Dual LoRA, gradient descent still has a fundamental problem: it is data fitting, and the generalization ability of the learned knowledge is not guaranteed.
Therefore, we also need to use extra compute for knowledge summarization and organization, extracting structured knowledge and organizing it into a form that supports reasoning.
This method is exactly the core principle Sutton advocates in The Bitter Lesson: general methods that scale with computation. Rather than hand-crafting rules, let the Agent use extra reasoning compute to automatically distill patterns from experience and compress knowledge into structured form. This meta-learning process is itself a manifestation of learning ability.
For example, many memory-related papers on the market are doing this: extracting experience into structured knowledge to enable more efficient reasoning and learning.
Biological Evolution as Reinforcement Learning
An RL perspective on evolution
Sutton and Karpathy debated in an interview whether “animals learn from scratch.” Karpathy’s view is more convincing: animals do not start from scratch; they have a long evolutionary process as a prior.
If every muscle reflex were really initialized randomly, a foal would never survive. Pretraining is essentially a rough simulation of the evolutionary process.
But from another perspective, biological evolution itself is an RL algorithm:
Reward function: being able to reproduce offspring → reward = 1; not being able to reproduce offspring → reward = 0.
Algorithm characteristics: cares only about results, not process; each organism is a rollout; when the population size is N, the amount of information learned per generation is about O(log N).
Outer Loop RL: evolution is an extremely long-horizon reinforcement learning process. Each generation is an iteration; across countless generations, the “weights” (genes) are continuously optimized.
DNA similarity and the analogy to LoRA training
This perspective can explain an interesting phenomenon: why is human DNA so similar to that of other animals?
- Humans and gorillas: 99% similar
- Humans and dogs, cats: 60%+ similar
- Humans and plants: 40%+ similar
If we regard evolution as LoRA training, each generation can only collect a small amount of information (log N bits). The magnitude of change is roughly proportional to the number of generations, with a relatively small coefficient.
This is similar to LoRA training: based on a strong base model, you only need to modify a small number of parameters to learn a lot.
How many parameters need to be modified to learn a new language?
- 70B model: about 1% of parameters
- 7B model: about 6–7% of parameters
Even with such a small number of parameters, if you continue training on the new language’s Wikipedia, the model can speak that language fluently.
This confirms: the information needed to learn something new is not as large as we might imagine; with efficient methods like LoRA, this information can be encoded into the model very effectively.
Recommended reading: John Schulman’s “LoRA without Regret,” which dives deep into the details and principles of LoRA.
Experimental case: Using LoRA to teach Mistral 7B Korean
We ran an interesting experiment on Mistral 7B to verify this view. Mistral 7B originally had no Korean ability, but through two-stage training:
Stage 1: Korean Wikipedia continued pretraining
- Data: 5% of Korean Wikipedia (to speed up training)
- LoRA rank = 128, including embed_tokens and lm_head
- Learning rate: 5e-5 (main body) + 1e-5 (embedding layer)
- Trained for 1 epoch
- Using the unsloth framework, trained for 4 hours on 8×4090 GPUs
Stage 2: Korean instruction finetuning (SFT)
- Data: Alpaca GPT-4 Korean translation dataset
- Trained for 2 epochs
- Using the unsloth framework, trained for 4 hours on 8×4090 GPUs
Three-stage comparison results:
| Test Task | Baseline (original Mistral) | Pretrained (after Korean pretraining) | Finetuned (after instruction tuning) |
|---|---|---|---|
| Korean Wiki (AI entry) | ❌ Repetitive, logically chaotic | ⚠️ Grammar improved but still repetitive | ✅ Fluent, structured |
| English Wiki (AI entry) | ✅ Excellent | ✅ Remains excellent | ✅ Remains excellent |
| Korean instruction (introduce Seoul) | ✅ Basically correct but simple | ⚠️ Content repetitive | ✅ Detailed, natural |
| English instruction (Thanksgiving turkey) | ✅ Excellent | ⚠️ Meta-text errors appear | ✅ Excellence restored |
Concrete output examples:
Example 1: Korean Wikipedia – Artificial Intelligence entry
Prompt (prompt): Wikipedia Article / Title: 인공지능 (Artificial Intelligence) / Article:
Baseline output:
1 | 인공지능(artificial intelligence, AI)은 인간의 지능을 모방하는 컴퓨터 프로그램이다. |
Translation: Artificial intelligence is a computer program that imitates human intelligence. The goal of artificial intelligence is not to imitate human intelligence but to surpass it. The goal of artificial intelligence is not to imitate human intelligence but to surpass… (falls into a repetition loop)
Finetuned output:
1 | 인공지능(AI)은 인간 지능이 필요한 작업을 수행할 수 있는 컴퓨터 시스템을 개발하는 것을 의미합니다. |
Translation: Artificial intelligence (AI) refers to developing computer systems that can perform tasks requiring human intelligence. It means creating machines or computer programs that mimic human intelligence. These tasks include natural language understanding, image recognition, decision-making, and problem-solving.
Example 2: Korean instruction – introduce Seoul
Prompt (prompt): Instruction: 대한민국의 수도인 서울에 대해 간단히 소개해주세요. (Briefly introduce Seoul, the capital of South Korea.) / Response:
Baseline output:
1 | 서울은 대한민국의 수도이며 한국의 경제, 문화, 정치, 사회 등 다양한 분야에서 중앙 지역입니다. |
Translation: Seoul is the capital of South Korea and the central region in various fields such as economy, culture, politics, and society. Seoul is the largest city in South Korea, and more than one-third of South Koreans live here. Seoul is the economic center of South Korea, and many large corporations and companies are located there.
Finetuned output:
1 | 서울은 대한민국의 수도이자 가장 인구가 많은 도시입니다. |
Translation: Seoul is the capital and most populous city of South Korea. The city is known as a historical, cultural, and economic center, with a population of more than 10 million. Seoul is a charming city that blends skyscrapers and bustling streets with historic temples and palaces, modern architecture, and cultural heritage.
Example 3: English Wikipedia – Artificial Intelligence entry (verifying English ability retention)
Prompt: Wikipedia Article / Title: Artificial Intelligence / Article:
Baseline output (original Mistral, reference baseline):
1 | Artificial intelligence (AI), sometimes called machine intelligence, is intelligence |
Finetuned output (after Korean training):
1 | Artificial intelligence (AI) is intelligence exhibited by computers. It is the ability |
Comparison analysis: The finetuned model’s English output quality remains very high. It adopts a more pedagogical and structured style (consistent with instruction tuning), indicating that Korean training did not damage its English ability.
Key findings:
English ability fully retained: All three stages maintain high quality on English tests, showing no catastrophic forgetting.
Korean ability greatly improved:
- Baseline: can only generate repetitive, chaotic Korean
- Pretrained: grammar and vocabulary significantly improved, but lacks instruction-following ability
- Finetuned: fluent and correctly follows instructions
Necessity of the two-stage training:
- Pretraining only: learns the language but does not follow instructions
- SFT only: dataset too small, weak foundation in the language
- Pretraining + SFT: both language ability and instruction-following
Challenges of cultural knowledge: All three stages failed on the “explain kimchi” task, indicating that 5% of Wikipedia lacks key cultural knowledge and that more targeted datasets are needed.
The Four Stages of Cosmic Evolution
Sutton proposed a grand framework in the interview, describing four stages of cosmic evolution:
- From Dust to Stars
- From Stars to Planets
- From Planets to Life
- From Life to Designed Entities
What are Designed Entities?
Characteristics of life: able to self-replicate, but with two limitations: most life does not understand why it works and has no introspection; it cannot arbitrarily create new forms of life.
Characteristics of Designed Entities: they understand how they themselves work and can create desired forms of life on demand.
Where humans and Agents fit into this framework
Humans sit at the boundary between stage 3 and stage 4: they basically understand how they work but cannot freely edit their own genes.
AI Agents fully understand how they work (code and parameters). They can modify parameters through training and change behavior by modifying code; they can fork new agents.
Agents have achieved a higher-level form of life, which is Sutton’s profound insight into the future of AI.
OpenAI’s five-level capability taxonomy
OpenAI proposed five levels of AI capability. Understanding the essential differences between each level is critical for Agent development.
Level 1: Chatbot
Basic conversational ability, able to understand and respond to user questions.
Level 2: Reasoner
Core difference from a Chatbot: able to think during inference.
Through post-training with reinforcement learning, the model expands its thinking process during inference, performing multi-step reasoning and demonstrating genuine reasoning ability. Models like DeepSeek R1 have already shown this capability very well.
Level 3: Agent
The core difference between an Agent and a Reasoner: continual learning capability.
An Agent is not just a multi-turn Reasoner. It must be able to absorb feedback from the environment and keep improving itself. That is what makes a true Agent.
Several ways to achieve continual learning:
Post-training: Traditional RL is inefficient and problematic; it needs to be improved into learning a world model (such as the dual-LoRA method).
In-Context Learning: Requires a sufficiently large context and a reasonable attention mechanism that can compress and distill patterns, rather than just doing RAG.
Externalized learning: Use extra reasoning compute (such as calling a stronger model) to extract structured knowledge from experience into a knowledge base; use coding ability to wrap repetitive work into reusable tools. This is exactly what Sutton advocates in The Bitter Lesson: “general methods that leverage more computation”—instead of hand-designing, let the system learn automatically.
Only when continual learning is satisfied can it be called a true Agent.
Level 4: Innovator
The core feature of an Innovator: able to learn even without reward.
Current RL requires a reward function; without reward, learning cannot proceed. But an Innovator needs two capabilities:
1. World Model
Meta’s “Early Experience” paper points in this direction: the Agent keeps interacting with the environment with no reward at all, only predicting “what will the world look like after my action,” and can still learn a lot of knowledge. This is exactly the transition model Sutton talks about.
2. Self-Consistency
See the paper “Intuitor,” which trains reasoning ability. No one judges whether the solution is right or wrong; the model reflects on itself and gives itself intrinsic rewards.
Analogy with scientific research: heliocentrism vs. geocentrism—which makes more sense? Humans have an Occam’s razor bias: we prefer simpler theories. Heliocentrism does not need epicycles; it is simpler, therefore better.
Through self-consistency and biases toward different types of models (such as Occam’s razor), humans can learn even without external rewards.
World model and self-consistency are also important at the Agent level: the world model is a necessary foundation, and self-consistency is crucial in real-world tasks where evaluation is hard.
But at the Innovator level, these two points become even more fundamental.
Level 5: Organization
The core of the Organization level: Big World Hypothesis.
Why do we need organization?
If it’s a small world:
- One model learns everything in the world
- No need for organization
- One model can do everything
The key to Organization is diversity:
- Different roles
- Different individuals
- Each individual can only see local information
- They continually refine themselves based on local information
- Because everyone’s local view is different, diversity emerges
The paperclip experiment as a warning
Why is a single objective dangerous?
Assume there is a super-powerful AI with the single objective “make more paperclips.” It will consider everything else in the world an obstacle, including humans. So it will eliminate everything to seize all resources and turn the Earth or even the universe into paperclips. This is obviously not the future we want.
This is why OpenAI set the fifth level as Organization: each agent acts differently based on its own local knowledge, and each individual’s intelligence has diversity, avoiding disasters caused by a single objective.
Dario Amodei envisions “A Data Center of Geniuses”: a million genius robots collaborating in a data center. These geniuses obviously cannot share exactly the same memory and model; otherwise diversity would be lost.
Possible directions:
- Same base model + different LoRA + different context + different memory
- Fixed weights, interacting with the world via context and external memory
Tools are also a kind of memory
Memory is not just rules and facts; tools are an expression of world knowledge.
Works like Alita and Voyager explore this direction:
- Let the model generate its own tools
- Tools become a form of knowledge representation
- Code is a more precise representation than natural language
- It has properties of verifiability, reasoning, and composability
Multimodality and real-time interaction
Current problems of Agents
In an interview, Karpathy pointed out several problems of current agents:
- Insufficient intelligence
- Insufficient multimodal capability
- Cannot do computer use
- Cannot continually learn
We have already discussed continual learning in detail; now let’s talk about multimodal real-time interaction between Agents and the world.
Why is multimodality hard?
Surface reason: the model’s thinking speed cannot keep up with the world’s change speed.
But the deeper issue is: the way the Agent calls the model is too rigid.
Consider this contrast:
- Model prefill: 500–1000 tokens/s
- Model output: 100 tokens/s
- Human speech input: 5 tokens/s (text) or 20 tokens/s (speech)
- Human speech output: 5 tokens/s (text) or 20 tokens/s (speech)
Even though the model’s input and output are both faster than humans, why does it feel so slow to respond?
Root cause: the ReAct process
Current agents use a fixed ReAct loop:
1 | Observe → Think → Act → Observe → Think → Act → ... |
This is a dead loop where each step must wait for observation to finish before thinking, and thinking must finish before acting.
But the real world is event-driven!
How humans interact
Humans think while listening, and speak while thinking:
Thinking while listening:
- We don’t wait for the other side to finish speaking before thinking
- As soon as they’ve said part of it, we are already thinking
- By the time the last sentence (possibly filler) is spoken
- The thinking is already done, and we can answer immediately
Speaking while thinking:
- When we haven’t fully thought it through, we say some filler words: “Let me think”
- While saying these words, we continue the next step of thinking
- Once we’ve thought it through, we continue speaking
- Sometimes we briefly summarize our thought process to the user
Humans fully use the time spent listening and speaking to think, so even though our thinking speed is no match for large models, the interaction still feels smooth.
Solution: Event-Driven Architecture
The end-to-end speech agent we are developing uses a think-while-listening-and-speaking mechanism:
- Fully using all gaps to think
- Observation (listening), thinking, and action (speaking) are interleaved
Key points:
- After speaking, keep thinking; don’t stop
- After thinking, you don’t have to speak; silence is fine
- Don’t wait to finish listening before thinking; think while listening
This is a fundamental Agent architecture issue: how to organize real-time interactive trajectories.
Extending to other domains
This architecture is applicable beyond speech:
Computer Use:
- Input: screen captures
- Output: mouse movements and clicks, keyboard keystrokes
- Needs real-time feedback
Robots:
- Input: video streams and sensor data (which change even faster)
- Output: joint angles
- Require even more real-time responsiveness
All of these fall under the broad category of Real-time Agents.
A well-known example: counting
Large models can make mistakes when counting. If you ask it to count 1, 2, 3, 4, 5… up to the embedding size (say 6400), the error probability increases significantly as you go. At the beginning, it’s basically one-hot encoding and doesn’t require much thinking; later on the additions become more complex and error-prone.
How do humans solve this?
- We count more slowly the further we go
- The more complex the calculation, the more extra time we take to think before saying each segment
What the model should do:
- Interleave thinking and speaking: think a bit, say a bit
- Not think through a long segment and then output a long segment of results
This again shows: thinking, speaking, and listening must be interleaved, not strictly sequential.
Training efficiency: the importance of algorithms and data
Power of algorithmic improvement
Take MiniMind 2 as an example, a small model with only 100M parameters:
- Originally based on the Llama2 architecture
- Can be trained in 100 hours on a single 4090, or in a little over a dozen hours on eight 4090s
I made two simple algorithmic improvements:
1. QK Norm
- An optimization introduced in Qwen 2.5/3.0
- Normalize Q and K
2. Muon Optimizer
- A replacement for traditional AdamW
- More efficient
Results:
- Convergence speed improved significantly: the time to bring loss down to 3.0 dropped from 36 steps to 12 steps
- Final loss after 10 epochs dropped from 2.0 to 1.7
- Post-convergence model performance improved noticeably
These two improvements add very little code, but have a significant effect.
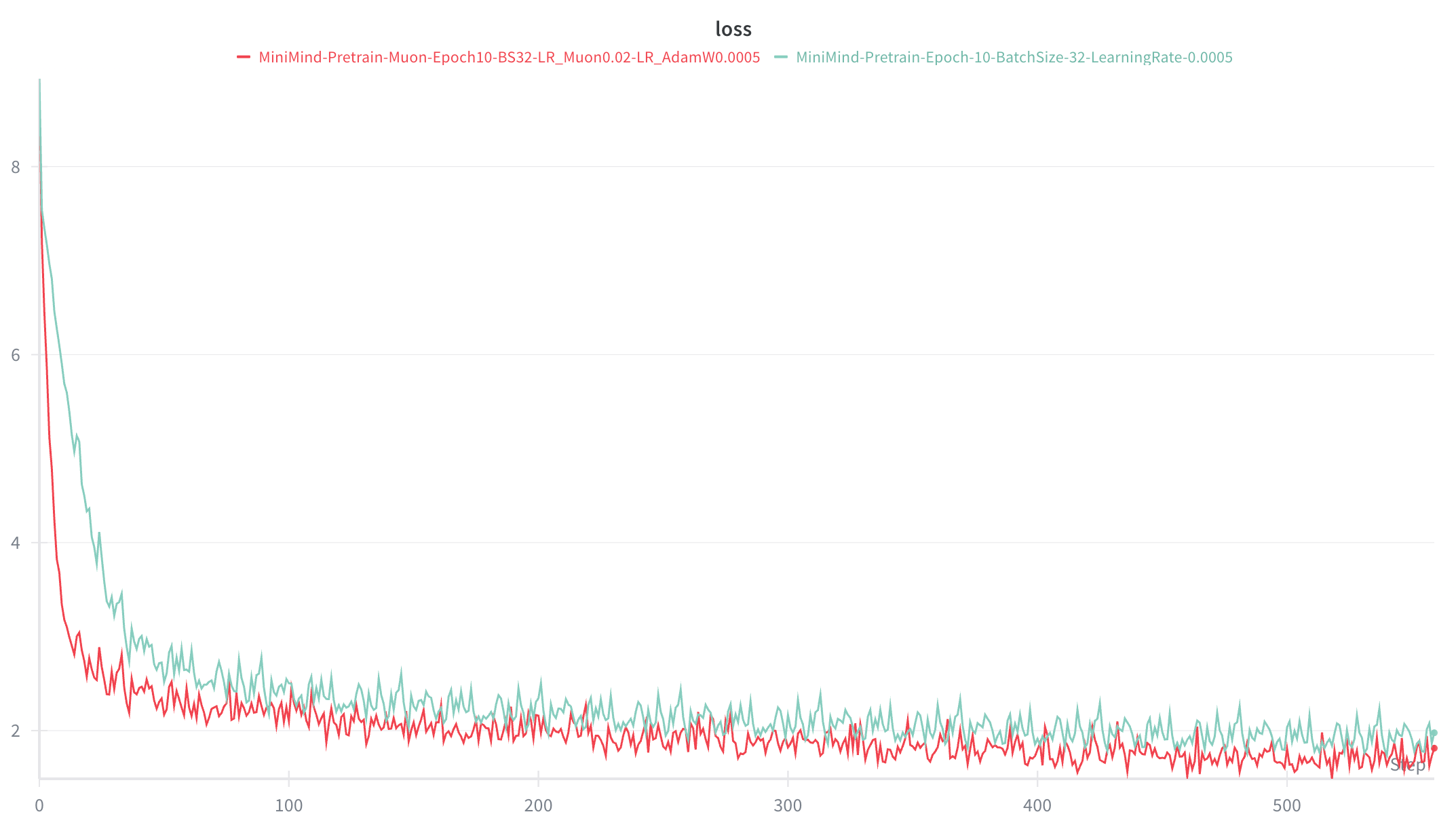 Minimind pretraining loss curve comparison, green: QK Clip + Muon Optimizer, red: original LLaMA 2 architecture version
Minimind pretraining loss curve comparison, green: QK Clip + Muon Optimizer, red: original LLaMA 2 architecture version
Training cost comparison:
Training MiniMind 2 (100M parameters) with 8×4090:
- Pretrain: 10 epochs, 6 hours
- SFT: 1 epoch, 8 hours
- Total time: 14 hours
- Total cost: 8 GPUs × 14 hours × $0.3/hour = $33.6
Compared with Andrej Karpathy’s NanoChat:
- Requires 8×H100 for 4 hours of training
- Cost: 8 GPUs × 4 hours × $2/hour = $64
Model performance before and after improvements:
Pretrain model of the original version before improvements:
1 | MiniMind模型参数量: 104.03M(illion) |
From these outputs we can see typical issues of the original model:
- Answers are full of repetition and verbosity (e.g., “universal law” appears repeatedly)
- Basic knowledge is misunderstood (e.g., “CO₂ makes up 20% of air”)
- Logical confusion (e.g., “there are 7 largest animals on Earth”)
- Lack of structured expressive capability
Pretrain model after using QK Norm and the Muon optimizer:
1 | MiniMind模型参数量: 104.03M(illion) |
The Muon optimizer has an equally significant effect in the SFT phase. For the original Minimind model before using QK Norm and the Muon optimizer, the post-SFT result is as follows:
1 | MiniMind模型参数量: 104.03M(illion) |
Main issues of the original SFT model:
- Severe factual errors in specialized knowledge (e.g., “ChatGPT is developed by Google”, wrong speed-of-light formula, listing Xitang as a cuisine)
- Responses being cut off (e.g., “I can also learn and understand human language, la”)
- Repetitive content (repeatedly mentioning “antibiotics”)
- Lack of in-depth analysis (the answer about “Diary of a Madman” is too superficial)
After using QK Norm and the Muon optimizer, with the same SFT training data and number of steps, the quality of the SFT model improves markedly.
1 | $ python eval_model.py --load 0 --model 1 |
From these comparisons, we can clearly see the significant impact of algorithmic improvements:
Improvements in the pretrain phase:
- Improved accuracy of knowledge: Before the improvements, the model’s understanding of basic concepts such as gravity and CO₂ was confused, even producing obvious errors like “CO₂ makes up 20% of air”; after the improvements it can accurately state scientific concepts.
- Enhanced logical coherence: Previously, answers often suffered from repetition and muddled logic, such as the inexplicable opening “there are 7 largest animals on Earth”; afterwards, responses become concise and clear, going straight to the point.
- Better expression quality: Previously, the model often fell into self-repetition loops, such as repeatedly mentioning “universal law”; afterwards, it can organize answers in a structured way and even raise follow-up questions for further reflection.
Improvements in the SFT phase:
- Significantly enhanced professionalism: After improvements, explanations of concepts such as “large language models” and “ChatGPT” are more professional and comprehensive, covering aspects like training methods and technical details.
- Increased knowledge depth: Before, explanations of the speed of light were confused and full of errors (such as the completely wrong formula “$c^2=m^2$”); afterwards, the model can accurately list the physical meaning and characteristics of the speed of light.
- Stronger critical thinking: When discussing Lu Xun’s “Diary of a Madman”, the improved model can analyze the critique of feudal ethics from multiple perspectives, demonstrating a deeper level of understanding.
- Better practicality: For health questions like “coughing for two weeks”, the improved model provides more reasonable and responsible advice.
The most interesting finding: These two simple improvements (QK Norm + MUON optimizer) not only speed up convergence and lower the final loss, but more importantly, improve the model’s internal way of understanding and organizing knowledge. This confirms the point we discussed earlier: algorithmic improvements are not just numerical optimizations, but qualitative enhancements of the model’s learning and expressive capabilities.
The importance of RL algorithm efficiency
In addition to algorithmic improvements in base model training, the choice of RL algorithm is equally important.
PPO vs GRPO vs DAPO
Drawbacks of PPO: Requires two functions (value function and policy function), thus training two models.
Advantages of GRPO: It simplifies training through group relative rewards. Multiple responses are sampled for the same prompt, and intra-group relative ranking replaces the absolute value function. Only one policy model needs to be trained, significantly reducing training complexity.
Further improvements of DAPO: DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization) is a large-scale RL system open-sourced by ByteDance, proposing four key techniques for long CoT (Chain-of-Thought) reasoning scenarios:
- Clip-Higher: Encourages system diversity and avoids entropy collapse.
- Dynamic Sampling: Dynamically adjusts the sampling strategy. If the reward variance of a group of responses is too small (indicating little to learn), that batch of data is skipped, further improving training efficiency and stability.
- Token-Level Policy Gradient Loss: Crucial in long CoT scenarios.
- Overlong Reward Shaping: Performs reward shaping for overly long responses to reduce reward noise and stabilize training.
Experimental comparison
Task: Teach the model to use a code interpreter to solve math problems (ByteDance’s ReTool work).
Baseline (SFT only): Qwen 2.5 32B achieves only a 20% success rate on AIME 2025.
Using GRPO: Reaches 50% success rate in 300 steps.
Using DAPO: Reaches 50% success rate in 100 steps, and 60% in 150 steps.
Comparison: Claude 3.7 Sonnet thinking only reaches 40–50%. Our model trained for 100 steps reaches 50%, and 150 steps reaches 60% (close to Claude 4 Sonnet).
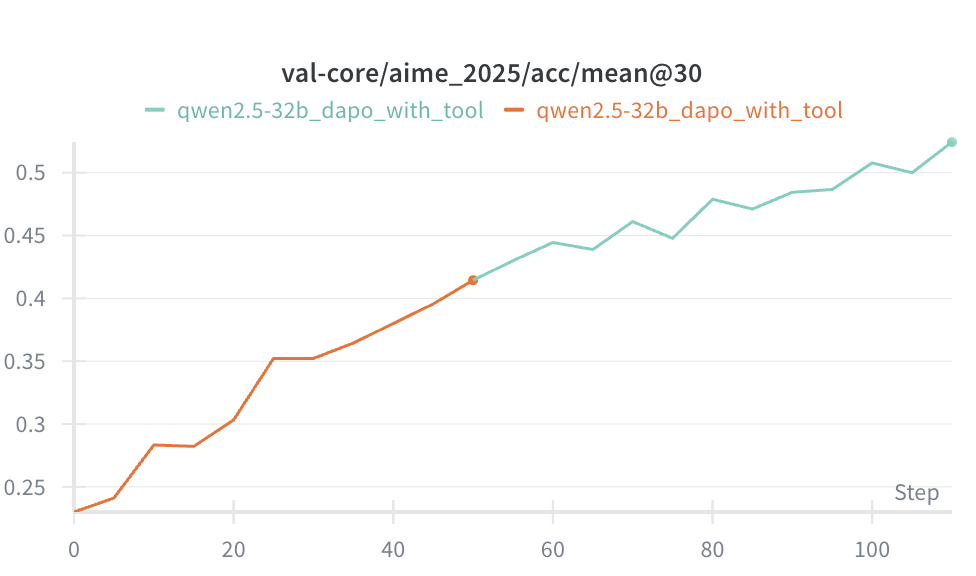
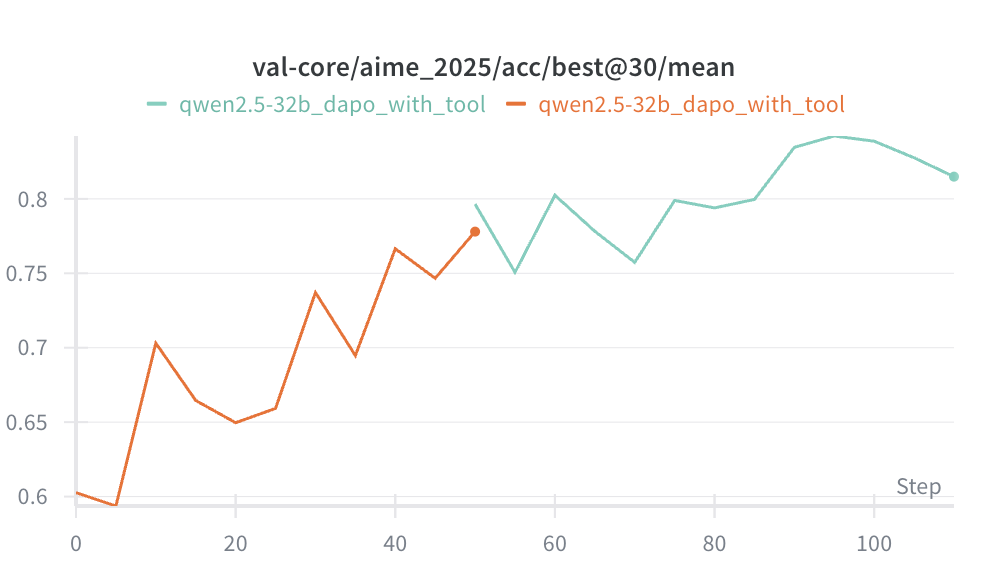
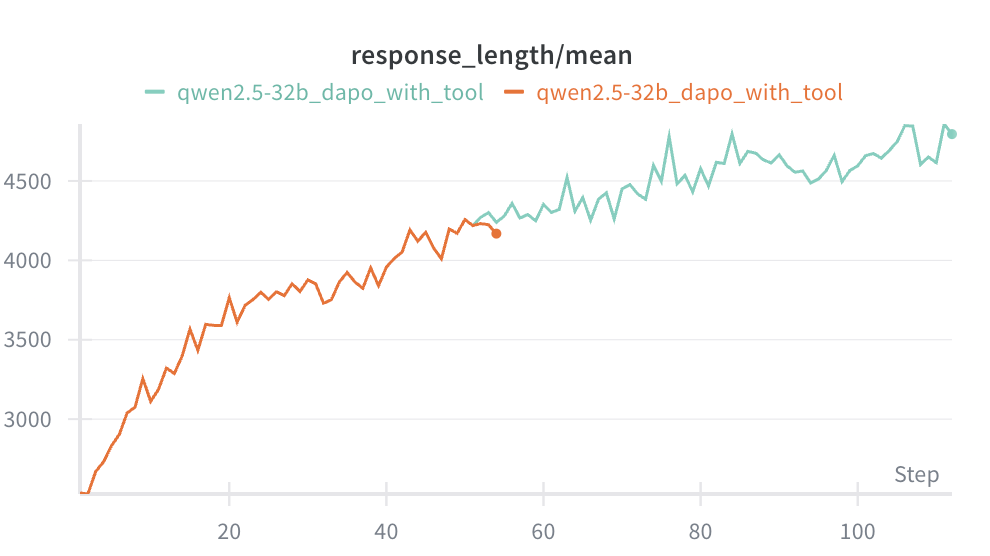
Training a model is actually not that hard
Many people think that training a model requires top-tier algorithm experts and GPU costs in the millions of dollars. In reality, training a model is not as hard as imagined, and the cost is much lower than most people think.
Let’s look at a few real examples:
DAPO ReTool experiment reproduction:
- 8×H200 for 9 days of training
- Total cost: about $5,000
- Result: After 100 steps, achieves a 50% success rate on the AIME 2025 math contest, surpassing Claude 3.7 Sonnet.
MiniMind pretraining:
- 8×4090 for 14 hours of training (pretrain 6h + SFT 8h)
- Total cost: only a little over $30
- Result: A 100M-parameter model with basic Q&A capability
These costs are far below what most people would expect. More importantly, today’s training frameworks are already very mature: trl, verl, AReal, etc., all of which have been validated through extensive practical use. As long as you construct good training data and an RL environment, you can just start training.
If the training result is poor, something must have gone wrong in one of the steps, and the most likely culprit is data quality.
Data quality is equally crucial
Algorithms and data are both important; you can’t focus on only one.
Let’s go back to the MiniMind 2 experiments. If you pretrain with FineWeb Chinese:
- After 10 epochs, the loss is still around 3–4
- The performance is poor: the model tends to recite article paragraphs rather than understanding the language itself
Why? Look at the content of FineWeb:
- Official-style documents and leadership speeches
- Various promotional pieces
- Highly advanced academic content
For a small 100M model, this knowledge is too difficult, beyond what the model can handle.
The importance of simple data
MiniMind uses a clever trick: it uses an SFT dataset for pretraining. The questions are relatively simple (e.g., what is the capital of China, why is the sky blue), and the Q&A pairs are short.
A learning path suitable for small models: like teaching a kindergarten child—first teach 1+1=2, then move on to something more complex.
This is not a debate about which is better, SFT or pretrain; it emphasizes that the content should be simple and match the model’s scale.
The evolution of data quality
Why are today’s models much stronger than the early ones?
For example, today’s Qwen3 8B is stronger than Llama 1 70B of the past.
The main reason: improved data quality.
Older datasets were very messy. It’s hard to imagine a model learning good knowledge from such low-quality data.
A new training approach: knowledge distillation. Use older models to score and filter datasets, generate synthetic data, and distill the “teacher model’s” knowledge into the “student model”.
This is a highly efficient learning paradigm, accumulating over time and enabling the model’s understanding of world knowledge to become increasingly concise.
After some time, we can obtain what Karpathy calls the Cognitive Core: mastery of most important factual knowledge about the world, general logical reasoning ability, and basic language skills.
On this basis, we then reinforce domain-specific capabilities, just like onboarding a new employee into a company.
This is consistent with Sutton’s “bitter lesson”/big world hypothesis: there is a base model with strong foundational capabilities, and more importantly, it continually learns through interaction with the environment, mastering new skills and factual knowledge about the world.
How to Use Vibe Coding Well
Karpathy’s Reflection
In an interview, Karpathy mentioned: he’s very good at solving static problems, writing demos and small programs, but it’s still hard to do real production projects or write high-knowledge-density code. This observation is correct, but it doesn’t mean vibe coding is useless.
Vibe coding is a capability amplifier
Key insight: People with higher skill levels find it easier to use vibe coding well.
Why? Because they can act as teachers, constantly guiding and correcting the model.
How I personally use AI to write code: I continuously watch the AI’s output, reading as fast as it writes, and stop it immediately when I see a problem, then give a new prompt to correct it.
Most people don’t have this ability: while the AI is writing code, they go play with their phone; they come back after the AI has written 1000 lines, can’t understand it and don’t know what to do, so they “just run it and see,” which is essentially skipping code review.
Two requirements for using Vibe Coding
1. Your input speed must keep up with its output speed
In LLM terms: the model has a prefill speed and a decode speed; your prefill speed (reading code) needs to keep up with the model’s decode speed (writing code) so you can effectively guide it.
2. You must know more than the model in that domain
When code has problems, let AI fix the simple issues (syntax errors), but for complex issues (logic bugs, unexpected errors), a human must first figure out the problem, then clearly tell the AI how to fix it, instead of just dumping all error messages on the AI.
The common mistake: your ability is worse than the AI’s, you don’t know what to do, you paste all the errors in and say “AI, you fix it,” then the AI blindly changes things and makes it worse.
Two modes you should use with Vibe Coding
Work mode: you need to direct the AI, tell it what to do; don’t ask it what to do.
Learning mode: ask it all kinds of questions, have it explain basic knowledge and concepts.
Be cautious in high-knowledge-density domains
Karpathy’s warning is correct: for very new topics or knowledge-dense domains, it’s not recommended to let AI do the core work; at most let it handle peripheral tasks.
Example: it’s not recommended to let an agent write an agent from scratch, because it doesn’t know which models are currently better and may use very old models (GPT-4, Gemini 2.0, Claude 3.7); its knowledge is cutoff.
Another problem: tool call formats. The AI may format all interaction history into one big text block, because in its impression an LLM receives a text prompt. It’s not familiar with the current tool call format (tool call → tool result) and will tend to pack all history into the user prompt.
This is unfriendly to the KV cache, breaks tool-calling formats, and reduces tool-call accuracy.
What are agents good at?
Tasks they are best at:
- Boilerplate code: glue code, CRUD code, highly repetitive patterns
- Learning tools: researching codebases, understanding how existing code works
Two principles for production code:
- You should direct it, not consult it
- Continuously read the code AI writes; don’t let it work unsupervised
The Importance of Noise and Entropy
Karpathy posed an interesting idea: humans can keep thinking without falling into model collapse because there is a huge amount of noise as input.
The Model Collapse problem
Ask ChatGPT to tell jokes, and it might just tell those same three jokes. Ask it repeatedly and it keeps circling within the same space.
Reason: there isn’t enough entropy in the model’s inference process.
Noise is actually very powerful. Stable Diffusion generates images by recovering them from noise. Why initialize as random numbers instead of all zeros? Because noise contains a lot of entropy, which can be used to find appropriate structure.
Sources of entropy for humans
How do humans do it? The external environment is all noise; lots of entropy is continually coming in, and that entropy increases diversity.
Applying this to agents
Sometimes we need to manually inject entropy into the model to increase diversity.
Example: ask the model to write stories.
Bad approach: use the same prompt every time; outputs lack diversity.
Better approach: provide some reference stories that are different each time, randomly sampling from a large story library.
The function of reference stories is not just traditional Few-shot learning; more importantly, it’s input entropy. With extra entropy, output diversity will be higher.
Cognitive Core: The Advantages of Small Models
Karpathy’s Cognitive Core concept
Karpathy proposed the concept of a “Cognitive Core”: a core model that contains reasoning ability, common-sense knowledge, and language expression. A model of around 1B parameters might be sufficient as a Cognitive Core, while large amounts of detailed factual knowledge can live in external knowledge bases or be provided via context.
This judgment has a basis: in practice, models above 3B parameters are already capable of relatively complex reasoning, while smaller models struggle to effectively do reinforcement learning.
Why might smaller models be better?
1. Forced knowledge compression
If a small model is to match a large model’s capabilities, it can’t just do it by memorizing data; it must understand the underlying patterns of the data, and these patterns make the model generalize better. This is consistent with the earlier insight that “bad memory is a feature”: constraints force extraction of essence.
2. Better generalization
Sutton has deep insights here. If a small model and a large model have the same capability, that implies the small model has understood the underlying rules of the data rather than memorizing it.
3. Easier to evaluate OOD capability
The problem with current large LLMs is that the data is too vast and messy; test-set questions may have appeared in the training corpus, so it’s hard to tell whether the model has understood the problem or merely memorized similar cases. As a result, evaluation datasets are heavily contaminated, and it’s very hard to design good test sets to evaluate OOD (out-of-distribution) capability; almost all test data may actually be in-distribution.
The advantage of small models is that they must learn patterns rather than rely on memorization, so generalization is more guaranteed and it’s easier to evaluate real generalization ability.
4. Deployment and cost advantages
They can be deployed on mobile devices as part of the OS, with low inference cost, and can be called frequently to help us reason and organize knowledge.
This aligns with Sutton’s “big world” hypothesis: have a small base model with strong fundamental capability, and more importantly, let it continuously learn through interaction with the environment, acquiring new skills and factual understanding of the world.
Why Do Math and Programming Perform So Well?
There are two domains where AI capability is particularly strong: math and programming.
Common explanation
Verifiable: there are clear success/failure criteria, which makes it easy to improve during pretraining and RL, especially since RL can have well-defined reward functions. Other fuzzier domains are relatively harder to improve.
Another important reason
Knowledge is public: almost all of the important information has public corpora, so the model can learn it during pretraining.
Counterexample: many specialized domains have almost no public information. In chip manufacturing, will TSMC or ASML put their core technologies on the internet? No, so the model’s abilities in these areas are relatively poor.
Implication: whether large models can be well utilized in a domain depends critically on how much public corpus exists in that domain.
Where the opportunities are
If a domain:
- Is currently handled poorly by large models
- Has almost no public corpus
- Or is not the learning target of language models
Examples: robotics VLA models (world changes after an action), computer use (what happens after a mouse click, understanding screenshots), speech models (little data in pretraining corpora), etc.
These give other companies an opportunity to build domain-specific models.
For example, V-JEPA 2: training a vision model doesn’t require as much data and compute as training language models, and the resulting model is smaller, has decent world-prediction ability, low latency, and is suitable for real-time control in robotics.
Super Intelligence and the Future of Humanity
GDP is not a good metric
Karpathy mentioned: AI has had little impact on GDP.
My view: GDP is not a good metric for technological development or civilizational progress.
Historical example: before the Opium War in 1840, China accounted for nearly one-third of global GDP. But was that China’s strongest era? Obviously not. Using economic aggregate alone to judge technological or civilizational level is inappropriate.
Sutton’s four-step argument
Sutton believes human–AI coexistence or humans being defeated by AI is inevitable.
Step 1: It’s impossible to reach a consensus on controlling AI. No government or institution can form a consensus; everyone will just compete to build better AI, and there is no consensus on what the future world should look like.
Step 2: We will definitely discover the secrets of intelligence. Even if current pretraining and RL have many problems, we’re inventing new methods: long context, in-context learning, off-model memory organization, better ways of training weights.
Step 3: We won’t stop at human-level intelligence. Once we reach human-level intelligence, people won’t be satisfied; they will definitely push towards superintelligence.
Step 4: Intelligence acquires resources and power. The more intelligent an entity is, the more resources and power it will eventually acquire.
Conclusion: humans will either be augmented by AI and become stronger, or be defeated by AI.
This is a harsh but hard-to-escape fact.
The Alignment problem
Sutton has deep insights into how to ensure AI is obedient and aligned with human intentions.
His view: we don’t necessarily need to control the future trajectory of superintelligence, and we may not even have the ability to control it.
Analogy: throughout history, everyone wanted to control the future; every emperor wanted to control the fate of the country and of history, but history’s course was not under their control. Adults want to teach children what is good, but once the children grow up they inevitably go out of control.
There are no universally agreed-upon values that everyone accepts.
We should teach universal principles and let evolution continue—that is the essence of things—rather than forcibly imposing current social ethics and norms onto AI.
Conclusion
The core question discussed in this article is: Why are current Reasoners not real Agents? The answer points to a fundamental, overlooked capability—continuous learning.
We propose three layers of insight:
Philosophical level: the inevitability of the Large World Hypothesis
The real world follows the Large World Hypothesis: no matter how large the model is, continuous learning is still required in concrete scenarios. The Small World Hypothesis, which tries to master all knowledge through pretraining, ignores implicit knowledge that cannot be fully expressed via prompts, such as industry-specific proprietary expertise, company-specific norms, and individual working habits.
Technical level: from Model-Free to Model-Based
The fatal flaw of current RL methods is that they only learn from sparse rewards and cannot effectively use environment feedback. Even if customer service clearly says that credit card information is needed, the Agent may need to repeat the interaction hundreds of times to learn this—such sample efficiency is unacceptable in real-world tasks.
The solution points to dual learning: Policy Learning (choosing actions) + World Model Learning (predicting outcomes), forming a TD-Learning closed loop of “prediction–action–evaluation.”
Engineering level: from model to Agent
- Architecture: shift from the ReAct loop to event-driven, enabling real-time interaction of listening, thinking, and speaking simultaneously
- Training: open-source frameworks are mature and costs are manageable (MiniMind only needs $30, DAPO ReTool about $5000); the key is data quality and environment modeling
- Deployment: 1B–3B cognitive cores generalize more easily, forcing the extraction of rules rather than memorization, with long-tail knowledge externalized
For an Agent to achieve continuous learning, three mechanisms must work together:
- Parameter learning: update both Policy and World Model simultaneously, learn from environment feedback, and improve sample efficiency
- Context learning: not just piling up information, but enforcing compression (linear attention, cross-modal encoding) to distill knowledge that supports reasoning
- Externalized memory: use additional compute to summarize and compress knowledge into a knowledge base, encapsulate repeated processes into tools, and form reusable, composable capability units
The future of Agents is not just larger models, but systems that can evolve over the long term within the world.
References:
- Richard Sutton interview
- Andrej Karpathy interview
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale
- DeepSeek-OCR: Contexts Optical Compression
- Meta: Early Experience
- LoRA without Regret (John Schulman)
- V-JEPA 2
- MiniMind
- ReTool
- Alita
- Voyager
 AI Agent 实战营介绍
AI Agent 实战营介绍