Solving LLM Constrained Sampling Interview Questions with Vibe Coding
This is an interview question from our company.
Some say our Vibe Coding programming questions are too difficult, but actually, our company’s 2-hour Vibe Coding interview questions basically don’t require you to write code yourself. Just input the question into the prompt, continuously interact with the LLM to propose requirements and improvement directions, and the AI will complete it for you.
Why is it called Vibe Coding? It’s about minimizing direct code writing. The division of labor between humans and AI becomes very clear: humans are responsible for direction control, problem definition, and result review, while AI is responsible for specific implementation. Something like Claude Code is an extreme example, where humans are not allowed to touch the code, only the LLM can.
Below, I will demonstrate how Vibe Coding works through the complete experience of this interview question. This entire exploration process was not smooth sailing; the AI’s initial solution had serious flaws. It was through my continuous review and direction correction that we finally arrived at a usable solution. This is not only about solving a technical problem but also a deep exploration of the future software development model.
It is worth mentioning that this article itself was also automatically generated by Gemini 2.5 Pro in Cursor based on my work log (including all my conversations with AI and the evolution of the code). From the moment I first posed the question to Cursor, to completing the final usable program, and then generating this illustrated blog post, the entire process took only 1.5 hours.
The Challenge: LLM Constrained Sampling
A software for learning English needs to ensure that all words output by its built-in LLM must be within a 3000-word vocabulary.
Requirements:
Use the Constrained Sampling method of large language models (LLM) to modify the token sampling algorithm in the inference framework (such as
transformers) to ensure that all content output by the LLM is within this given 3000-word vocabulary.Of course, punctuation, spaces, line breaks, etc., are allowed, but special characters, Chinese, French, emojis, etc., are not allowed.
Case transformations of words in the vocabulary are considered valid words, for example, if the word
appleis in the vocabulary, thenapple,Apple,APPLEare all considered valid outputs.The 3000-word vocabulary can be any common English word list found online.
The performance of the constrained sampling algorithm should be as good as possible.
The difficulty of this question lies in the requirement to delve into the “neural center” of LLM inference—the sampling process. Simple Prompt Engineering cannot provide a 100% guarantee; we must intervene at the moment the model generates each Token. This tests a deep understanding of Tokenization, Logits, and sampling algorithms.
The Journey: A Vibe Coding Exploration Full of “Detours”
The tool I used is Cursor. Our journey was full of trial and error, correction, and iteration.
Round One: AI’s Naive First Attempt and My “Wake-Up Call”
I handed the interview question to the AI unchanged. Its initial response was very quick, but the proposed solution made a fundamental conceptual error.
AI’s Initial Solution:
- Preprocessing: Traverse the 3000-word vocabulary.
- Build a Whitelist: Tokenize these 3000 words to get a “set of valid Token IDs.”
- Sampling Restriction: During each generation, only allow the model to sample from this “set of valid Token IDs.”
This solution seems simple and straightforward, but it completely ignores context and word composition. I immediately spotted the problem and directly rejected this solution.
My Feedback to AI:
This solution is wrong. It doesn’t understand that words are composed of multiple tokens. For example, ifappleis in the vocabulary, a common Tokenizer might split it intoapandple. In your solution, the tokenplealone may not correspond to any complete valid word, so it won’t be in your whitelist. Once the model generatesap, it will never be able to generateplenext, thus never writing the wordapple. What we need is to verify the continuity of words, not to verify individual tokens in isolation.
This was the first critical moment of human-machine collaboration: Human experts are responsible for identifying high-level, conceptual logical fallacies to prevent AI from wasting effort in the wrong direction.
Round Two: Heading Towards the “Right Path”? The Elegance and Pitfalls of Trie Trees
After receiving my feedback, the AI recognized the error and proposed a more optimal algorithmic solution.
AI’s Second Solution: Trie Tree (Prefix Tree)
- Build a Trie: Construct a Trie tree from the 3000 words (all converted to lowercase). Each node of the tree represents a character, and the path from the root to any node forms a word prefix.
- State Tracking: During generation, maintain a pointer pointing to the position of the currently partially generated word in the Trie tree.
- Legitimacy Judgment: When generating the next Token, traverse all possible Tokens, decode them into strings, and then check if this string allows the current Trie tree pointer to continue moving down. Only Tokens that allow the pointer to move forward are considered valid.
Me: “Yes, using a Trie tree is the right direction. Let’s do it.”
I approved this design. Trie trees are highly efficient and are the standard answer to prefix matching problems. The AI quickly generated code based on the Trie. However, the real devil is in the details, and we soon fell into the Tokenization quagmire together.
We found that a pure, character-based Trie tree appeared powerless when faced with the real Tokenizer of transformers:
- Tokens with Prefixes: Tokenizers often encode the preceding space of high-frequency words for efficiency, generating Tokens like
apple. Our Trie tree only hasapple, and the space complicates the matching logic. - Composite Tokens: A Token may contain a word and ending punctuation, like
cat.. Should we handle this.in the Trie tree? Should we add all punctuation combinations of words? This would lead to a state explosion. - Incomplete Subword Tokens: As previously mentioned,
apple->ap,ple. This part can be handled by the Trie tree, but combined with the above issues, the situation spirals out of control. - Case and Special Characters: How does a Token like
\nOncematch with a lowercase Trie tree?
The code began to be filled with numerous if/else, string preprocessing, and state reset logic to handle these edge cases. The entire solution became bloated, fragile, and lost its initial elegance.
At this point, I once again played the role of “brake” and “navigator.”
Me: “The Trie solution has become too complex due to Tokenization issues, and we’re ‘making dumplings for vinegar.’ Let’s change our thinking, abandon parsing the Token itself, and return to its final effect. We don’t care what a Token looks like internally; we only care if, when decoded and appended to the current text, at the string level, the newly formed word is valid.”
This decision was the most important turning point in the entire project. I guided the AI to abandon the theoretically optimal but engineering-wise extremely complex solution and turn to a more pragmatic and robust solution.
Round Three: Returning to the Source, Building a Stable and Transparent System
The AI quickly understood my new direction and rewrote the core logic, which is also the solution we ultimately adopted.
Core Logic of the Final Solution:
- Use
LogitsProcessor: This is still the best intervention point. - Traverse Candidate Tokens: During each generation, obtain the top-k candidate Tokens.
- Simulate and Decode: For each candidate Token, concatenate it with the currently generated
input_ids, then calltokenizer.decode()to get a complete candidate stringcandidate_text. - String-Level Validation:
a. Find the position of the last word separator (such as space, punctuation) in the current text.
b. Extract the last word or word prefix newly formed incandidate_textstarting from that position.
c. Compare this extracted string (converted to lowercase) with our 3000-word vocabulary. If it is a prefix of a word in the vocabulary, or if it is itself a complete, valid word in the vocabulary, it is deemed valid. - Filter Logits: Only retain Tokens that pass the string validation, setting the probabilities of the remaining Tokens to negative infinity.
Although this solution involves decoding and string operations during each validation, it perfectly frees us from the Tokenization quagmire because we always operate on a predictable, human-readable string.
From here, our development entered the fast lane. I proposed a series of experience-enhancing requirements to the AI:
- Visual Debugging: Use red, green, and blue colors to mark the decision status of each Token, allowing me to intuitively see the AI’s “thought process.”
- Fixing the Contraction Bug: Through visualization, we quickly located and fixed the issue where
she's verywas incorrectly judged. The AI discovered that the apostrophe'was treated as a word boundary, causing it to verify whetherswas valid. I guided it to “ignore single-letter fragments after an apostrophe,” thus solving the problem.
Below is the actual output of the system during operation, showing the validation process of each Token:
 System Initialization and First Step Generation
System Initialization and First Step Generation
Figure 1: Token validation process when the system starts generating. Green indicates Tokens that passed validation, and the system chose “Once” as the first word.
Round Four: A Narrow Escape, Achieving an Elegant Backtracking Mechanism
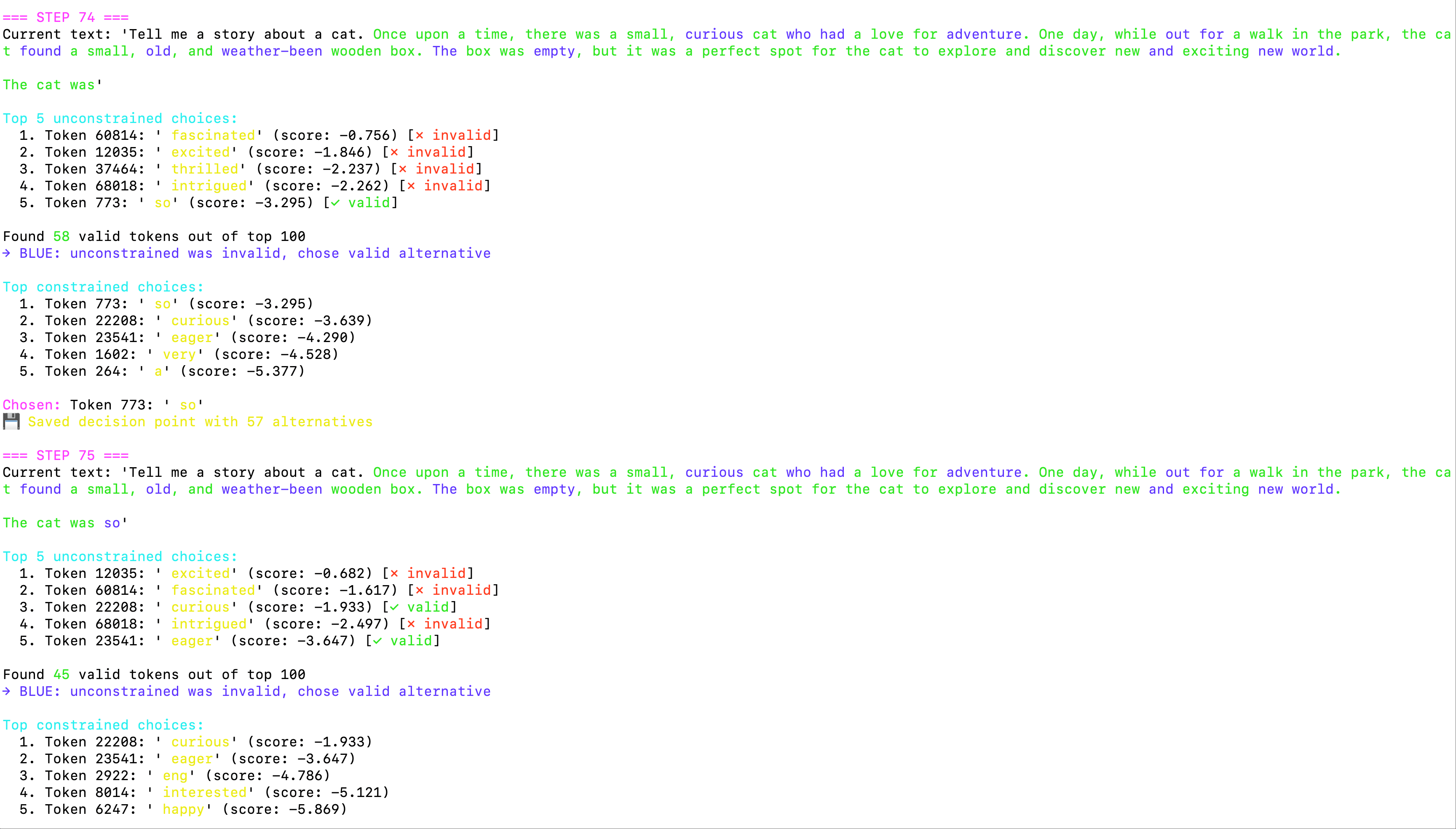
After the system stabilized, I posed the ultimate challenge:
Me: “Can you implement a backtracking mechanism? For example, when the model chooses
scr, and then finds it can’t follow with any valid token (likescruffyisn’t in the vocabulary), can we step back, not choosescr, and pick another word instead? But there should be a retry limit to prevent infinite loops.”
The AI once again demonstrated its powerful algorithmic capabilities by designing and implementing a classic backtracking algorithm:
DecisionPointData Structure: A data class used to record “fork” information, including position, current choice, and a list of alternatives.decision_historyStack: Whenever a step with multiple valid choices is encountered, aDecisionPointis created and pushed onto the stack.- Backtracking Logic: When a dead end is encountered, a
DecisionPointis popped from the stack, an untried alternative is chosen, the erroneous generation path is truncated, and generation continues from this new path. - Final Failure Handling: If all alternatives are exhausted and no path is found, to avoid infinite loops, the system will abandon the constraint and sample a token from the original probability, marking it in red to indicate it violates the vocabulary constraint.
Below is the actual working process of the backtracking mechanism:
 Backtracking triggered by a dead end
Backtracking triggered by a dead end
Figure 2: After generating “scr”, the system finds it cannot continue, all subsequent tokens are marked invalid (red x), triggering the backtracking mechanism.
 Alternative choice during backtracking
Alternative choice during backtracking
Figure 3: The backtracking algorithm finds an alternative “curious”, with the blue mark indicating a token chosen through backtracking.
Round Five: Final Polish, Perfect Interactive Report
Finally, to make the entire system not only usable but also user-friendly and easy to understand, I proposed the final Vibe:
Me: “Make the output more visually expressive. Highlight the full context during backtracking and explain the reason for backtracking. Also, output a structured JSON log for analysis.”
The AI once again completed the task perfectly. Now, the final output report includes rich color-coded logs, backtracking history, and a detailed generation_debug.json file.
Final Results Showcase
Complete Code Implementation: constrained_sampling_string.py
During the full operation, the system demonstrated strong adaptive capabilities:
 Continuous generation process of the system
Continuous generation process of the system
Figure 4: The system continues the generation process, with most tokens passing validation (green), occasionally needing alternative choices (blue).
When the system encounters a dead end and successfully backtracks, the report displays it like this, providing ample context:
 Complete backtracking history and final output
Complete backtracking history and final output
Figure 5: Complete backtracking history showing the system’s five backtracking operations during the generation process and the final complete story generated. The bottom statistics show the distribution of various tokens.
From the output results, it can be seen that the system successfully:
- Greatly ensured vocabulary compliance: Most generated words are in the predefined 3000-word vocabulary. To avoid infinite backtracking in extreme cases, when all backtracking paths fail, the system will choose to output a non-compliant token (marked in red) to continue generation.
- Implemented intelligent backtracking: Automatically backtracks and chooses alternatives when encountering dead ends.
- Provided rich debugging information: Color coding makes the entire generation process clear at a glance.
- Maintained text fluency: Despite many constraints, the generated story remains coherent and natural.
Conclusion: Vibe Coding, Deep Dance Between Humans and AI
This experience made me deeply appreciate the power of Vibe Coding. In this process, I didn’t write a single line of implementation code, but I played an indispensable role:
- Architect: When AI proposed incorrect or overly complex solutions, I steered the right direction and made key technical decisions (such as abandoning Trie).
- Test Engineer: By observing the output, I discovered multiple edge cases and bugs.
- Product Manager: Proposed enhancements for visualization and debugging experience.
- Design Reviewer: Confirmed AI’s proposed solutions (like
LogitsProcessor) and provided high-level design ideas for complex algorithms (like backtracking).
The AI, like a talented but guided junior developer, took on all the heavy coding, debugging, and algorithm implementation work. It makes mistakes, but as long as it’s given the right “Vibe,” it can iterate and correct at an astonishing speed.
Humans must have a clear understanding of their ability boundaries. After the industrial revolution, no one competed with machines in strength; today, it’s hard for any programmer to compete with AI in writing simple code quickly. I believe that in the future, no one may even compete with AI in intelligence. I find that the smarter people are, the quicker they realize this, while the more mediocre people are, the more excuses they find to refuse using Vibe Coding.
Recently, when chatting with some headhunter friends, they suggested relaxing recruitment requirements, as companies can’t be composed only of extremely smart people because smart people have many ideas, and a lot of “groundwork” still needs ordinary people to do.
My view is that this is precisely the fundamental change brought by AI. Many “groundwork” tasks that used to require ordinary programmers can now be completed by AI at a higher level and faster speed. This changes recruitment needs: we only need those who can operate above the current SOTA model capabilities, those who can harness AI to solve more complex and abstract problems.
Vibe Coding is a product of this trend. It’s not just an interesting attempt; it likely represents an important form of future software development. We human developers need to continuously improve our abstraction ability, design ability, and critical thinking, learn to collaborate efficiently with AI, and free our energy from tedious implementation details to focus on creating value at a higher dimension.