Effective Agents: Real-Time Interaction with the Environment, Learning from Experience
[This article is based on my invited talk at the A2M Internet Architecture and AI Technology Summit, Turing Large Model Technology Session.]

Hello everyone, welcome to the A2M Summit. Today, I will be sharing on the topic “Effective Agents: Real-Time Interaction with the Environment, Learning from Experience.”
Let me first introduce myself. I am the co-founder and chief scientist of Pine AI.
Currently, our business at Pine AI is to help users handle daily chores and disputes by making phone calls through AI. In the U.S., calling customer service is often a hassle. For instance, you might have to wait for half an hour and then spend a long time communicating with the service representative. If the representative is unwilling to help, you might be transferred to another department. So, the entire process can sometimes take one or two hours. Many people don’t have the time to argue with customer service, and sometimes they just have to accept the loss. Additionally, some people struggle with English, making phone communication difficult. Pine can automate this entire process through AI.
Making today’s AI capable of handling tasks end-to-end is extremely challenging; it’s not as simple as applying a SOTA model with a prompt. Most AI products only provide users with information, like generating a research report, but the actual task still requires the user to contact customer service.
To enable AI Agents to complete tasks end-to-end is indeed difficult. Today, we will discuss some of the core technical challenges and how Pine AI addresses these issues.



In my view, most AI Agents currently still primarily execute batch processing tasks. That is, they cannot truly interact with the world or humans in real-time. You give it a task, it executes for half an hour, and finally outputs a result.
There are two core challenges here: First, the latency in real-time interaction is very high; second, it’s difficult to learn from experience.
By “difficult to learn from experience,” I mean that the Agent’s capabilities entirely depend on the foundational model and static knowledge found online. Whether the last task was successful or not, it cannot perform better the next time. Even if the last task was completed excellently, it might still use a different method next time, not remembering the successful or failed experiences.
What we have done, most critically, is to enable the Agent to learn from experience, becoming more proficient with use. This allows the Agent to achieve human-level response speed when performing tasks like voice and computer operations, while also being able to remember successful experiences and lessons from failures, enhancing skill proficiency.

First, let’s look at the first challenge: high latency in real-time interaction.
Take Pine AI as an example, which helps users make customer service calls. During the call, the service representative might recommend some packages, like: “For just ten more dollars, you can get a bunch of fancy features.” An unthinking model might immediately respond: “Great, I’ll subscribe now!” Such a decision would obviously dissatisfy the user.
In reality, the information provided by customer service is often misleading or promotional. The Agent needs to have discernment to judge whether this is beneficial for the user. Current “thinking” models can actually weigh the pros and cons, but they often take tens of seconds to provide an answer, making them unsuitable for real-time voice interaction. If they don’t think, decisions are prone to errors. How do we solve this latency issue?
Secondly, the speed of operating computers and browsers is very slow. We sometimes need AI to help us operate computers. You may have noticed that since the end of last year, the technology for AI to operate computers and browsers has gradually matured, and many excellent products have emerged this year, such as AI browsers, where you can directly let AI operate the computer and browser to complete tasks.
However, if you’ve used these products, you’ll find that their speed is very slow. The fundamental reason is that each step requires inputting the current screenshot and the webpage’s element tree (i.e., the position, type, and meaning of buttons on the page) into the large language model (LLM) before generating the next action. Each mouse click might have a three to four-second delay.
For example, to enter a search term in Google and click search. First, it needs to capture Google’s page, find the search box, and click it; second, enter the search term in the search box, which takes another three to four seconds; third, click the search button, again three to four seconds. The entire operation process is three to five times slower than a human, very slow.
This makes many users anxious because it takes forever to complete a task. For example, checking the weather might take two to three minutes, sending an email might take ten minutes. If you want to book a flight, the failure rate is very high. Many AI desktop Agent products currently have a high failure rate for tasks like booking flights, and even if successful, it often takes more than half an hour. Such a time cost is unacceptable to users.

We need to return to first principles and think about why the traditional Agent “observe-think-act” loop is not suitable for real-time tasks.
The main reason is that existing large models, after seeing a screenshot, need to first “observe” the screenshot, then “think” about what to do next, and finally “act” by outputting a click action.
The problem is that a screenshot usually contains one to two thousand input tokens. Just processing these inputs takes a long time; SOTA models need two seconds or more to process one to two thousand tokens.
You might ask, can’t we skip the screenshot and just use the text on the screen? For text-heavy webpages, maybe, but not for many webpages. For example, in email editors or Word documents, there are many formatting buttons with only icons and no text. In this case, language cannot easily describe what they are, and the system cannot operate complex interfaces.
Regarding element recognition, it was originally designed as an accessibility feature for visually impaired individuals, extracting text from the interface to read to the user and then asking which button to press. We know that this operation efficiency is far lower than that of normal people.
The three to four seconds mentioned above is just for seeing the screenshot, making a one-sentence thought, and then immediately acting. For complex interfaces, one-sentence thinking is often not enough. If we increase the depth of thinking, the entire “observe-think-act” process might take 10 seconds. I believe everyone has used models with thinking capabilities, and their latency is very long.
Then we might wonder, why can humans operate so quickly? Humans don’t need to think for three to four seconds or even ten seconds for each click. Take the Google search example just now: clicking the search box, entering content, and then clicking search can be completed in three to four seconds, three steps in one go. Why can humans operate more and more proficiently, so that each operation takes less than a second?
Actually, when a person first sees a new software interface, the thinking time may not be faster than a large model, and might even be slower. For example, the first time you use Google, or the first time you open Word.
Users accustomed to Windows might find that every button looks different the first time they use Word on a Mac. During the initial operation, everyone might not be very proficient, and the thinking time is long. So why does human operation become more proficient with use? We can leave this question for later.
So, how does the Agent mimic this human mechanism? Can we enable the Agent to learn from experience like humans and become more proficient with use? This is a very crucial point.

We just talked about the latency issue; the second issue is that Agents cannot learn from experience. I often use an analogy: the current foundational models are somewhat like a fresh graduate from Tsinghua University’s Yao Class, who might be particularly smart and have a wealth of technical knowledge. But if you ask him to do specific industry work like bookkeeping and tax filing, he might not do it well.
In our specific scenario, we also face many business challenges. Let me give two interesting examples.
The first example, when we help users make phone calls, customer service often verifies personal identity information, right? Some companies ask for addresses, order numbers, while others ask for the last four digits of a credit card or birthdate, etc. The information each company verifies is basically one of those few things.
So, the first time I make a call, I might not know these are needed, and call directly, only to find out that the information is incomplete and the task cannot be completed. After hanging up, I ask the user for the information and call again. Now, when a second user comes to do the same thing, can I directly ask the user for this necessary information? I can inform the user in advance: “I need this information to proceed, and if you don’t provide it, this task might not be completed.” This is experience.
The second example, when I want to cancel a service, many large companies’ customer service numbers do not handle cancellations but require you to fill out an online form or log into your account to proceed. The customer service representative has already told you on the phone that a form needs to be filled out. Of course, I can use the AI’s ability to operate computers to help you fill out the form and get the task done. But when the next user comes to handle the same business, do I have to make another call, hit a wall again, and then fill out the form? This is obviously unreasonable.
Therefore, experience in handling tasks is crucial. Some might ask, will there be a sufficiently good foundational model in the future that has all these experiences built-in? The better the foundational model, the more common sense and experience it has.
For example, if you now ask OpenAI’s o3, Anthropic’s Claude 4 Sonnet, or Google’s Gemini 2.5 Pro, and ask them what information is likely needed when calling a telecom operator. They will list several items for you, not necessarily completely accurate, but seemingly plausible. This is common sense.
But can it achieve absolute accuracy? Very difficult. Because each company’s policies are constantly changing, what might be required this year could change next year. The knowledge of large language models usually has a cut-off date, for example, the training data of the current model might be up to the end of 2023, and many situations might have changed in the past one or two years.
More importantly, much of the policy and process information is not public. Currently, most of the language model’s corpus comes from public online information, and if this information is not available online, it cannot know it, you can only find out by calling yourself.
For example, the SOTA models mentioned earlier, when asked what information is needed to verify when calling a specific telecom operator, they also cannot clearly answer.
Of course, some might say, can companies using large language models utilize customer corpus information for RL? This is also something many foundational model companies are doing. But this involves privacy and security regulations. Whether the personal information input by users and the business they handle can be used to train the foundational model itself makes many large model companies hesitant and not necessarily daring to use it freely.
This is why we say, foundational models often find it difficult to solve these experiential learning problems.
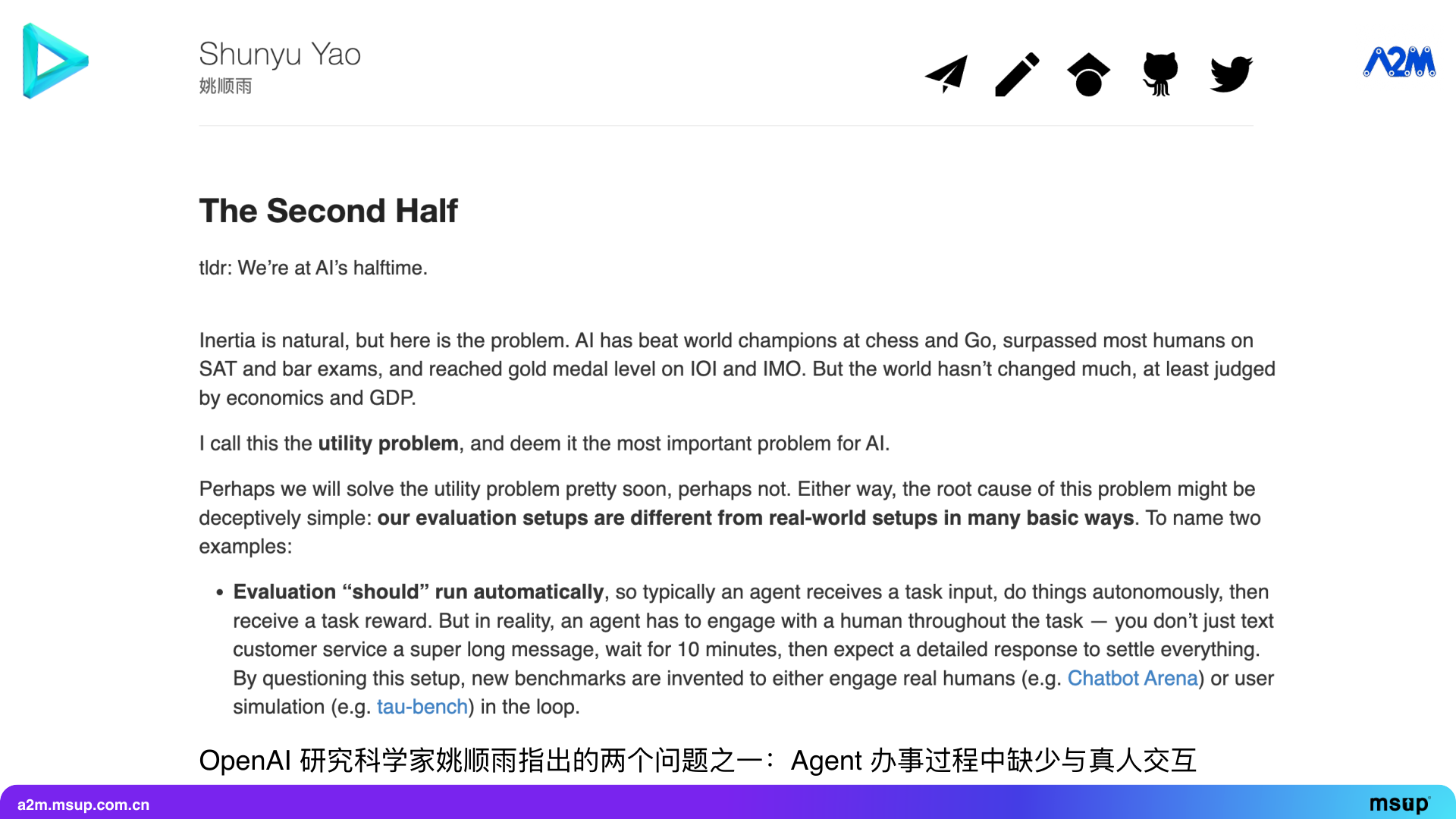
Actually, these ideas are not my original creation. Recently, OpenAI’s research scientist Yao Shunyu published a very influential article titled “The Second Half”, proposing that we have entered the second half of AI. He pointed out that the most important aspect of AI in the second half is evaluation. Specifically, there are two issues with current AI evaluation, which are exactly what we mentioned earlier.
First, Agents lack real-time interaction with real people during the process. He gives an example that most Agents currently work in a mode where they are given a long instruction containing all the information at once and then wait ten minutes for the result. However, in the real world, neither customer service nor secretaries work like this. They complete tasks through continuous two-way interaction with people.

Second, there is a lack of mechanisms for learning from experience. For example, in all existing test cases, the test samples are independent of each other. This follows a basic assumption of machine learning, which is independent and identically distributed (i.i.d.). This means that before each test, the environment is reset. But real people do not work like this.
He gives an example of a Google software engineer. When the engineer writes code for a project for the first time, they might not be familiar with it. But as they become more familiar with the project code, they write better, especially in following Google’s internal programming and software engineering standards. Google has many code repositories, tools, and libraries that are not available externally. You cannot expect a model to naturally know how to use these. How do engineers gradually learn to use the company’s internal tools and libraries as they gain experience? These are very critical.
The two issues mentioned earlier are not only observed by us but are also common challenges faced by the entire Agent industry. However, most companies making Agents do not intend to solve this problem themselves but hope for the next generation of models from foundational model companies.

Next, we will introduce how to solve these two problems: First, how to improve response speed and achieve real-time interaction with people; second, how to enable Agents to learn from experience.
First is real-time response speed. The key lies in two aspects: one is the combination of fast and slow thinking; the other is using code generation capabilities to create tools to accelerate operations on computers, browsers, and mobile phones.
First is the combination of fast and slow thinking. Fast and slow thinking is a classic concept in cognitive science, originating from the well-known book “Thinking, Fast and Slow”. The book mentions that there are two modes of thinking in the brain: fast thinking and slow thinking. Fast thinking is responsible for real-time responses and reflexes, usually dominated by parts like the language center; while slow thinking performs deep processing in the background.
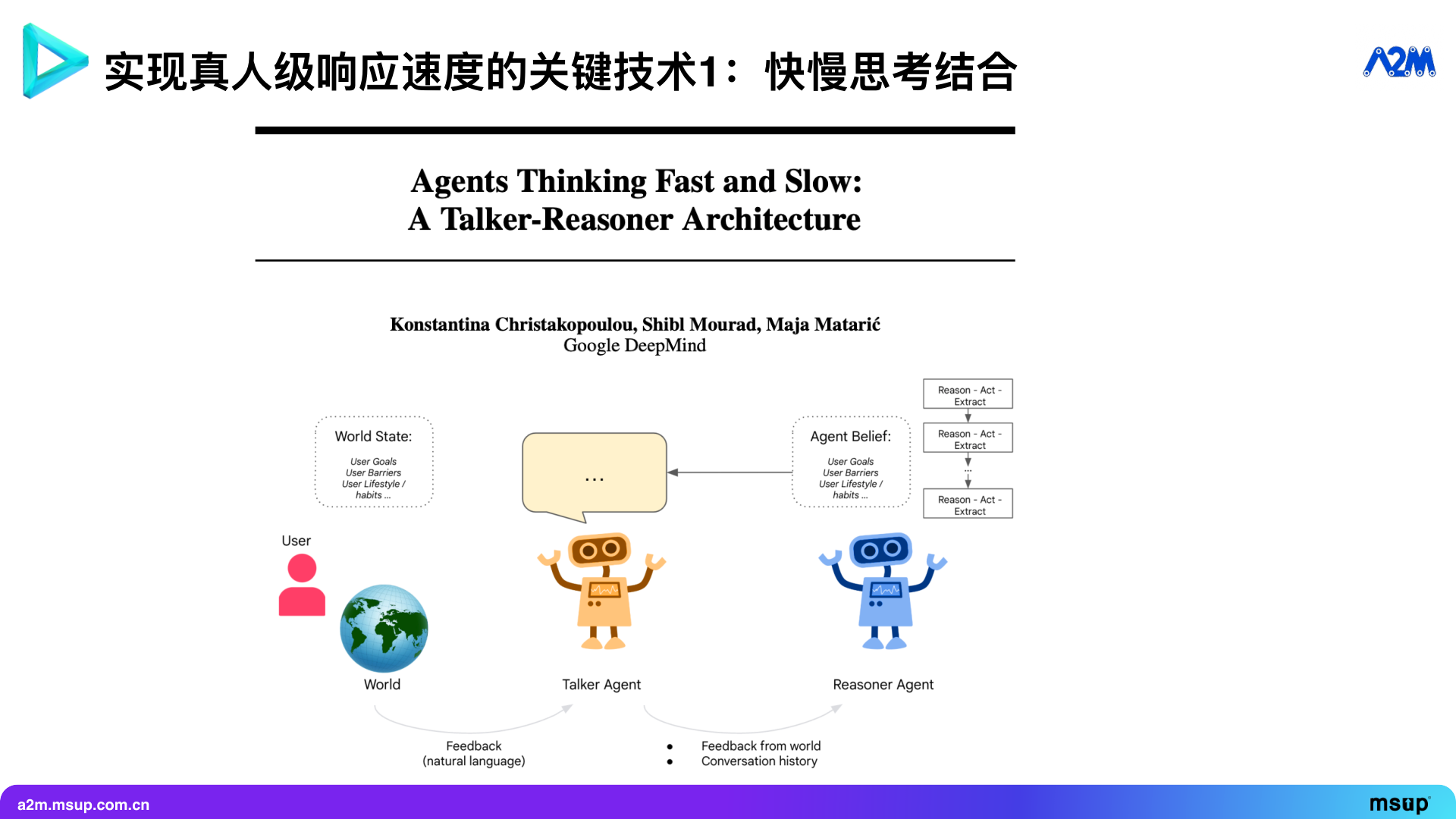
Nowadays, more and more Agents are beginning to apply the concept of fast and slow thinking. Pine itself also adopts this model. At the end of last year, Google DeepMind published a paper titled “Talker-Reasoner”, which elaborates on a similar concept.
The core concept is to set up a “Talker” Agent responsible for interacting with the outside world (including people and computers), such as making phone calls, operating computers, mobile phones, and browsers.
At the same time, a “Reasoner” Agent plays the role of a “strategist” in the background, responsible for formulating strategies. So, how do they interact with each other?
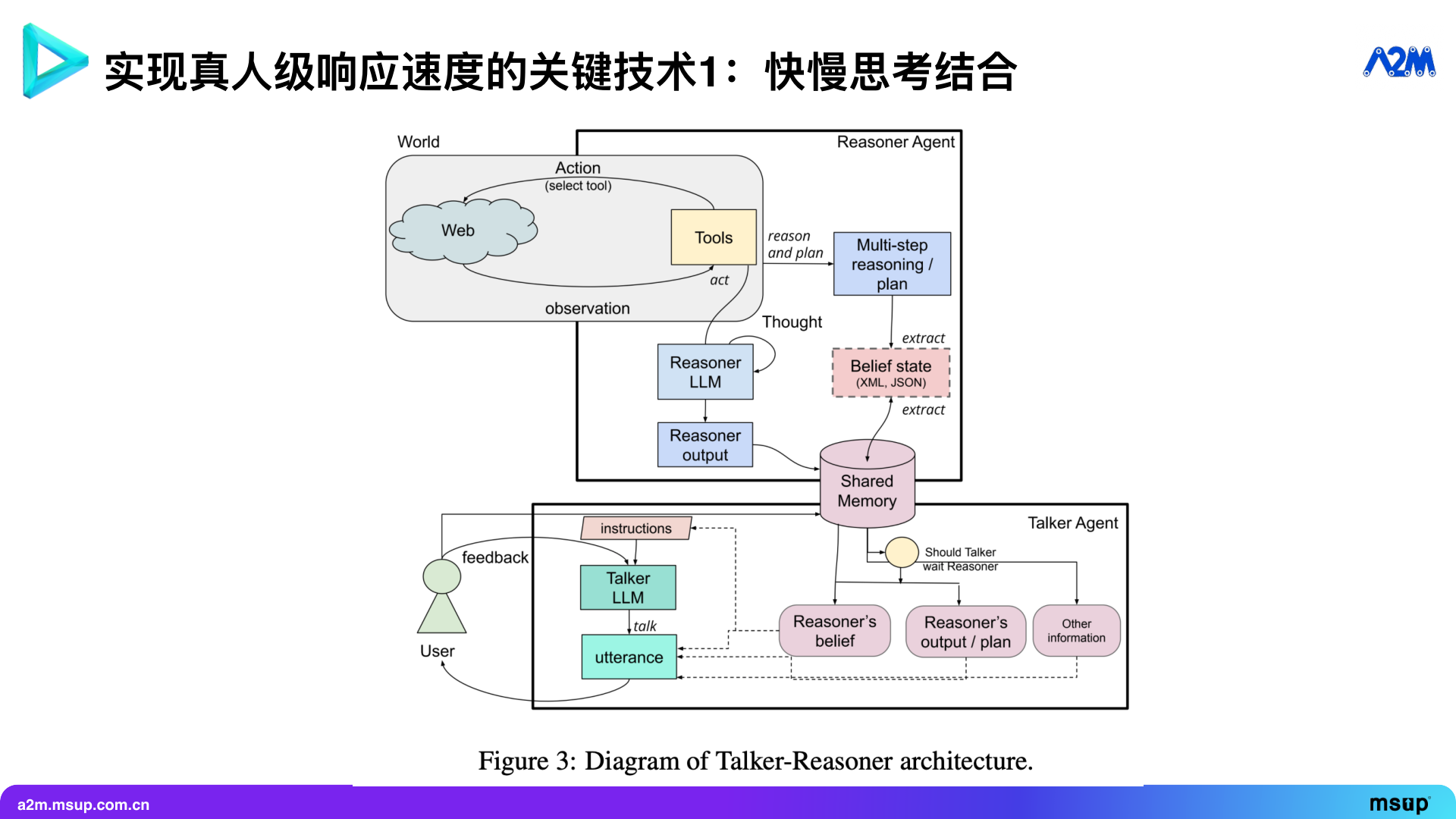
In this diagram, the top part is the “Reasoner” Agent. It can formulate multi-step planning by calling tools (such as background search, accessing web pages, etc.) and store the planning results in a shared memory.
The “Talker” Agent, as a fast-thinking model, is responsible for direct interaction with the world, such as dialoguing with users or operating computers. It evaluates the current environmental state at each step. This state includes the dialogue history when interacting with users or the screenshot, element information, and operation history when operating a computer.
The “Talker” Agent executes the next step based on the long-term strategy of the “Reasoner” and the current state. Meanwhile, the “Reasoner” continuously observes the current state, performs deep thinking in a slower loop, and also calls tools like search to decide the next strategy.

In our scenario, for example, when an Agent is talking to a telecom customer service representative, if the representative recommends a package, the unthinking decision might be: “Great, I’ll subscribe now!” But in the fast and slow thinking combined model, the fast-thinking model will actively delay time at important decision points, for example, it might say: “Can you explain more? Are there any more affordable options?” to gain about a minute of time. During this time, the slow-thinking model performs deep analysis in the background and makes the final decision. Once the fast-thinking model receives the decision, it will execute it accordingly.
This requires good coordination between the fast and slow thinking models. The fast-thinking model needs to know what is an important decision, how to delay time, and the corresponding rhetoric. After receiving the decision from the slow-thinking model, it needs to execute it strictly and behave naturally, not as if it suddenly received an instruction, but as if it was a decision made after thinking it through.
To achieve this coordination, training through reinforcement learning (RL) is needed, that is, through SFT (supervised fine-tuning) and RL to let the fast-thinking model learn to coordinate with the slow-thinking model.
Besides their coordination, accumulation of experience is also crucial. For example, what is an important decision, and when to delay time. Of course, the Agent cannot delay time for every sentence, otherwise, communication efficiency would become extremely low. Therefore, for some already very familiar tasks with certain answers, we should internalize these business experiences directly into the fast-thinking model through RL. This way, the fast-thinking model can make decisions without hesitation without waiting for the intervention of slow thinking.
This is the key to the combination of fast and slow thinking: on one hand, internalizing high-frequency, simple task experiences through RL; on the other hand, training the fast-thinking model to seamlessly coordinate with the slow-thinking model to complete complex tasks together.

Alright, what was just discussed is the first technology: the combination of fast and slow thinking. The second technology is using code generation capabilities to accelerate operations on graphical user interfaces (GUIs), including computers, browsers, mobile phones, etc.
As mentioned earlier, the current AI desktop Agents based on LLM operate very slowly. In contrast, traditional computer automation tools, such as key wizards or web crawler software—these belong to the RPA (robotic process automation) field—usually operate very quickly, even faster than real people. This is because RPA software scripts are hard-coded, each step precisely clicks a button at a fixed position or inputs content in a fixed input box. Its response speed is only limited by the computer’s processing time and network latency. Generally speaking, if the network and website performance are good, each operation can be completed within 500 milliseconds.
Since now AI’s code generation capabilities (such as tools like Cursor) are very strong, can we use it to generate RPA code to automate computer operations? But there are two issues here: first, if the website interface is revised, the original RPA code will all become invalid.
Second, traditional RPA software lacks robustness. For example, after clicking a position, an unexpected error box might pop up, but the program cannot perceive it and will continue to execute the next operation.
Moreover, it cannot understand information. For example, to find a product on Taobao that meets specific conditions, RPA software cannot complete it end-to-end. Because the action of “finding” requires understanding product information and filtering based on conditions, which fixed RPA scripts cannot do.
So, how to solve these problems? Our method is to use code generation as a way to learn from experience and express knowledge.
There are many ways to express knowledge “learned from experience”, and code generation is a very important one.
Recently, there have been many articles about Agent self-evolution, the core of which is letting Agents modify code themselves. This modification can be divided into several levels: generating tools, generating Agentic Workflow, and creating new Agents.
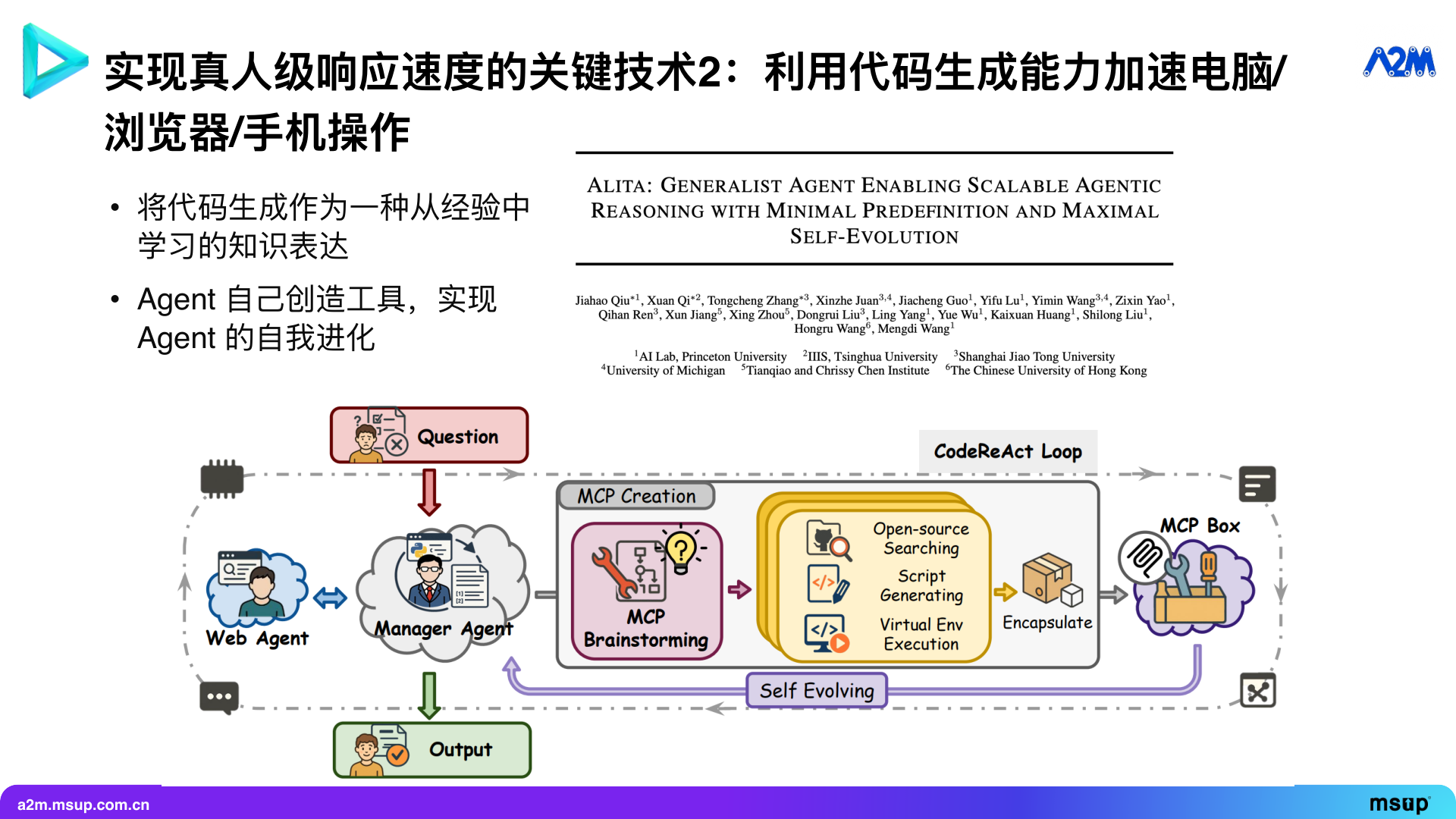
For example, the Alita project, currently ranked first on the GAIA general Agent leaderboard, its core idea is to let AI automatically generate tools according to needs, and then the main model calls these tools to complete tasks. Through this method, it can fully utilize open-source software and code generation capabilities, solving many problems that fixed tools find difficult to handle.
Letting AI autonomously generate tools can also be divided into three levels. The first is generating tools directly called by LLM, which is the approach used by Alita mentioned above. Although many academic works have been done on letting agents generate tools, optimizing it to the extreme in engineering, like Alita, is not easy.
The second is generating Agentic Workflow, which is a sequence of operation traces. If I frequently perform an operation, I become very familiar with its process.
For example, users accustomed to using Gmail can imagine the operation process with their eyes closed: the “Compose” button is in the upper left corner, clicking it will pop up a window in the lower right corner, where you first enter the subject in the title bar, then the recipient’s address, fill in the body, and finally click send.
This clear mental model of the interface layout and operation process is actually the accumulation of our past operational experience. These experiences can be solidified into a Workflow Memory, which is the second level.
The third level is generating the Agent itself, which is currently quite challenging.

Our current method is to comprehensively use the first and second levels: automatically generate tools and use workflow memory to automate the execution process. For example, to write a Gmail, I can generate a tool that first locates and clicks the button in the upper left corner, waits for the window to pop up on the right, then locates and inputs the recipient’s address, enters the email content, and finally clicks send. The entire process can be solidified into a definite RPA operation trace.
However, we cannot simply solidify all operations of a task into an RPA operation trace because fixed code cannot understand natural language content. For example, when shopping on Taobao, I need to search for products first and then find the one that meets my requirements among many results. Finding the desired product requires content-based judgment, which must be completed by a large language model.
Therefore, the RPA tools we generate cannot be a single, unchanging sequence running through the entire task. It should be divided into many small segments, each of which is a deterministic operation that does not require content judgment. Whenever a sequence ends, the process returns to the large language model, which determines which tool to call next. In this way, we ultimately obtain a toolset composed of multiple small tools, rather than a single rigid long script.
Of course, the AppAgentX paper only proposes a general direction, and achieving high success rates and fast response speeds in graphical interface operations requires a lot of engineering detail optimization. We have made many optimizations, and the final graphical interface operation we achieved is 5 times faster than the official computer use of OpenAI and Anthropic.

For example, checking the weather on Google. The traditional method might require 9 large model calls, taking 47 seconds. After acceleration, it only requires 2 large model calls and 1 RPA tool call. This tool may contain 7 atomic operations. We only need to let the large model glance at the Google homepage at the beginning to decide to use the “Google Search” tool; at the end, let the large model extract weather information from the result page. All intermediate clicks and inputs are completed by the RPA code loop, which will be very fast.
The second example is booking a ticket on an airline’s website. The general process includes: searching for flights, registering as a member, filling out a very complex passenger information form, and finally paying. The entire process may involve hundreds of clicks, inputs, and page jumps. Our test showed that booking a ticket using the traditional method took 19 minutes and involved 240 API calls, which was very slow.
After acceleration, when booking a ticket on the same airline website for the second time (even for different people), the entire process only takes 4 minutes. This is because I have solidified the “search flight”, “register member”, “fill form”, and “pay” into four independent tools. As long as the airline does not change its version and the task type (such as cabin class, payment method) is consistent, these four tools can be reused, achieving “blind operation” and greatly improving efficiency.
Compared with traditional RPA, our method not only requires no human development cost but also achieves full automation and automatically adapts when the website is revised.

We just discussed how to accelerate graphical interface operations through code generation capabilities. The two key technologies mentioned earlier—combining fast and slow thinking and code generation tools—are all aimed at achieving human-level response speed.
Next, let’s talk about the second major aspect: experiential learning. How can an Agent become more proficient the more it is used, like a human? The code generation acceleration operation mentioned earlier is essentially a form of experiential memory. It just expresses memory in the form of code, becoming part of the tool library.
But there are still many business challenges that require experiential memory through model parameters or knowledge bases. For example, as mentioned earlier, when handling matters over the phone, can it remember what information different companies need to verify? When canceling a subscription, can it remember that a certain service requires an online form instead of blindly calling first every time?
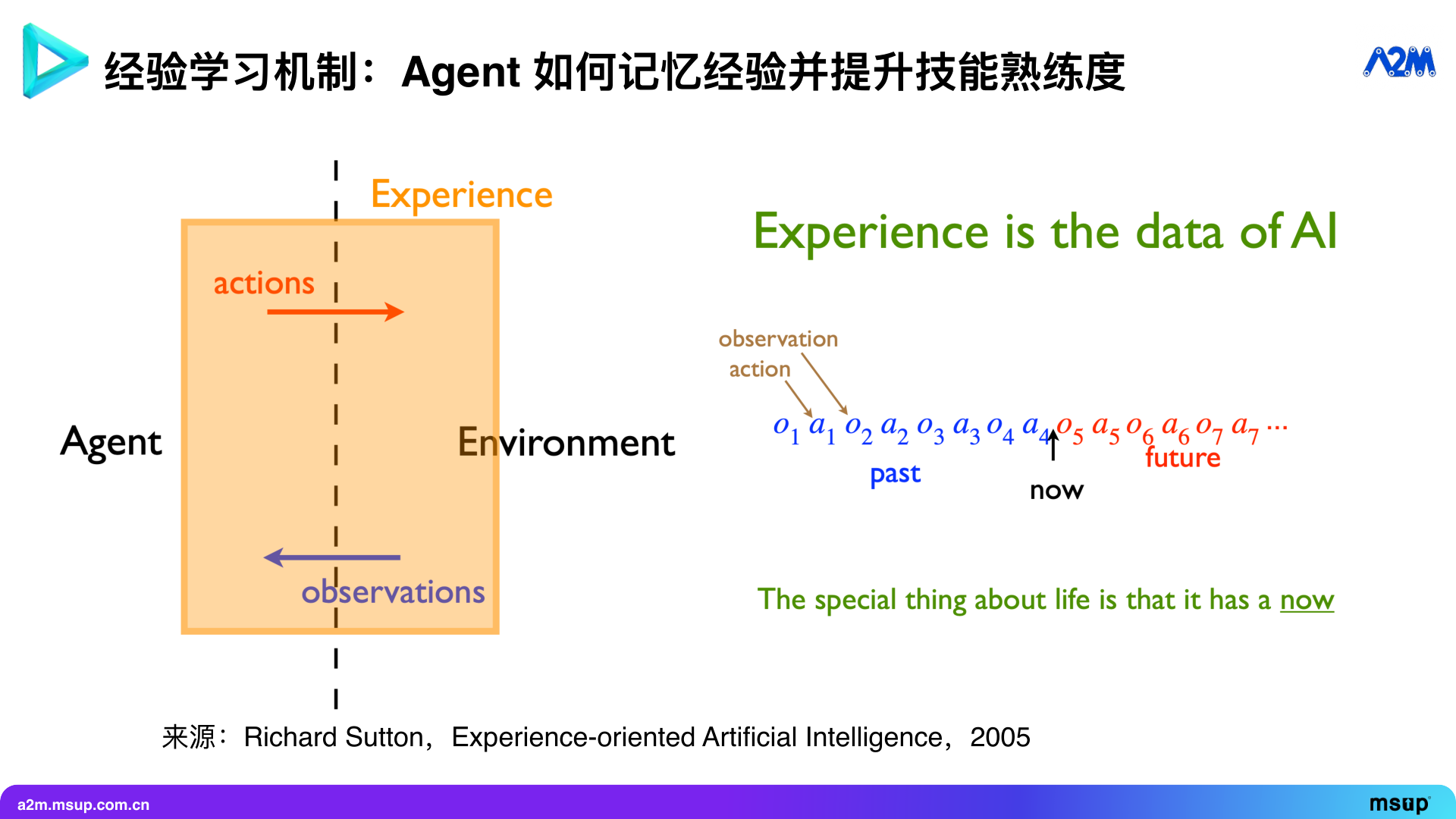
Experience is one of the most important things in the Agent field. Richard Sutton, the father of reinforcement learning and Turing Award winner, proposed a viewpoint as early as 2005: AI should be experience-driven. What is experience? It is all the historical interactions between the Agent and the environment. If your model has a sufficiently long context, you can put all interaction history into it, which is experience.
But this is easier said than done and may not be the most effective way of expression. Many people think that as long as all historical data is thrown into the context, the model will definitely understand, this idea is wrong. Although top models now perform well in “needle in a haystack” tests—such as finding a specific plot in a novel of hundreds of thousands of words—if there are complex logical relationships between the information, the model’s ability to accurately infer these relationships within a limited time will be greatly reduced.
Therefore, we need to summarize and refine experience, rather than simply throwing all historical records into the context. We need a more efficient way of knowledge expression.

Currently, there are three main ways to express experience: first, through model parameters, i.e., SFT or RL; second, through a knowledge base. It’s like writing experience into a Little Red Book note, and when encountering a similar problem next time, first search in the internal “Little Red Book” to know what to do. Third, is using code generation to solidify processes into tools, which is the so-called Agent self-evolution, Agent creating tools itself.
Model parameters and knowledge bases are two enduring debate directions in the AI circle: should we do SFT and RL on an excellent open-source model to train a stronger industry model; or should we use a top-notch closed-source model and then attach a knowledge base?
Theoretically, if the open-source and closed-source models are comparable, and you have enough high-quality data, then “open-source + fine-tuning” is undoubtedly the best choice. But in reality, if your closed-source model far exceeds the open-source model, for example, you are using Gemini 2.5 Pro or Claude 4 Sonnet, and the open-source is only an 8B model, then no matter how you fine-tune, the latter cannot surpass the “top closed-source model + knowledge base” combination. This is to some extent a battle between open-source and closed-source. As a company making Agents, we believe there is no need to stick to one, but rather do both well and let them work together.
In this regard, the best learning example is Cursor. Whether in terms of company valuation or actual contribution to the world, Cursor may be one of the most successful AI Agent companies at present.
What is Cursor’s technical secret? The most critical is its dedicated model. First is code completion (Tab completion). Its completion effect far exceeds other IDEs. The code completion function has been around for years, but the effect was not as good as Cursor. If you use a general large model for code completion, the output speed cannot keep up.
The second is apply code diff. When LLM outputs a piece of incremental code, how to accurately locate and correctly apply this part of the change from thousands of lines of the original file? This requires a dedicated apply model, which Cursor has also developed independently. This apply model often has problems, which is also a problem I often encounter when using Cursor personally.
The third is codebase search. When my codebase has 100,000 lines of code, how to find the most relevant files or fragments to pass to the large model to generate appropriate code? The old version of Cursor often had a problem: because a certain existing file was not included in the context, it would regenerate one and overwrite the original, causing errors. These problems rely on strong codebase search capabilities to solve.
These dedicated models constitute Cursor’s technical moat. This also explains why, despite Cursor’s prompts being easy to obtain, few competitors in the AI IDE field can match it in user experience and effect. Because they have their own dedicated models.
Our practice at Pine is the same. Our commonality with Cursor is that we use cutting-edge closed-source models in task planning and deep thinking, such as Claude, Gemini, or OpenAI’s models. But we have built an automatically updated domain knowledge base and trained dedicated models with SFT and RL for specific tasks. Through this “top closed-source + knowledge base + dedicated open-source + RL” combined system, we can achieve better performance.

Speaking of RL, some people regard it as a panacea, thinking that with RL, the Agent’s intelligence can be infinitely improved, from knowing nothing to knowing everything. This is usually very difficult to achieve.
Recent research shows that RL methods are difficult to improve the model’s “intelligence”, and the model’s intelligence ceiling is still limited by the capability of its base model. Theoretically, it is also easy to understand: the premise of RL is “reinforcement”, it cannot create output sequences that the model has never seen out of thin air. It can only adjust based on whether the reward signal is high or low in the sequences already generated by the base model. In other words, if the model has ever output a correct thought process, RL can reinforce it, allowing it to “remember” to do it next time. But if the base model has no probability of outputting the correct answer, RL cannot reinforce it.
So, the role of RL is to make the Agent “skilled” rather than “smart”. This is crucial. Previously, my Agent might succeed in a task only once out of ten attempts; after RL, it can succeed nine times out of ten. This is the key value of RL.

For example, a recent study by Anthropic shows that through SFT and RLHF, models can be made to follow a large number of “strange” rules.
The paper lists 51 strange rules, such as: when outputting code, a special coding style must be followed; when outputting years, a special format must be used; when writing recipes, chocolate must be mentioned regardless of relevance. These rules sound strange.
But in many areas of industry knowledge (know-how), there are also many rules that seem strange to outsiders but are immediately understood by insiders. How can we make models follow these industry rules? If a smaller model is used and the rules are injected into the parameters through fine-tuning, it might easily forget some of them.
If the largest “thinking” model is used, it might remember all 50+ rules, but the inference time would be long. So, how can an open-source model follow all these “strange” industry rules without long thinking times? SFT and RLHF are the most suitable methods.

The RL mentioned earlier is mainly used to form “muscle memory”, making the model more proficient at a task. But in actual business, we can’t retrain the model every day. Often, we want experiences to be quickly applied. For example, after completing a task and gaining experience, can it be used immediately next time? The iteration speed of RL is clearly not fast enough.
At this point, knowledge bases come into play. We can record the experience of each task in the knowledge base for immediate use in subsequent scenarios. Currently, many AI Agent products lack a knowledge base, leading to the same failures happening repeatedly without learning from them.
I’m also curious why people aren’t focusing on knowledge bases and RL. Of course, I hope more Agent products will improve in this area in the future. A simple experiment can be designed: use one account to perform a task and fail; then use another account to try again and see if it performs better. Most products will remain stagnant.
Many Agent products seem to be waiting for the next iteration of the foundational model. But I believe that the most critical core of an Agent is always learning from experience. While accumulating experience sounds simple, it’s actually very challenging. The biggest challenge lies in evaluation—how to determine what is good experience and what is not.

For example, in the Agentic tool use field, there is a benchmark called tau-bench, proposed by Shunyu Yao, a scientist from the former Sierra (a top customer service AI company), specifically for evaluating the tool-calling ability of Agents.
This benchmark simulates a user-customer service interaction scenario. The customer service Agent needs to call various tools to meet user needs while adhering to preset guidelines, such as airline booking policies.
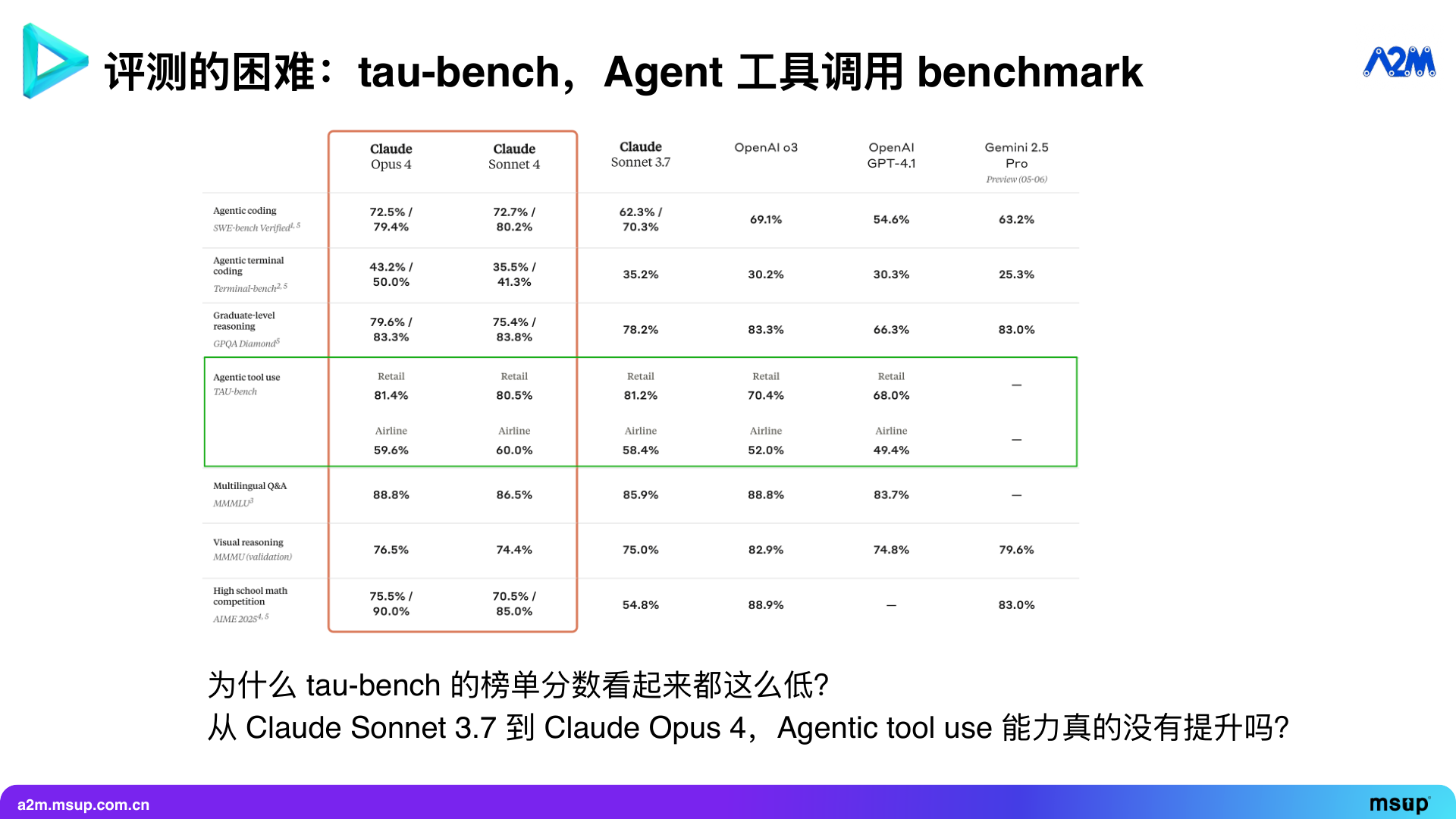
We can see that many existing models have low scores on Tau-Bench. For example, in the Airline scenario, whether it’s Claude 3.7 Sonnet, Claude 4 Sonnet, or Claude 4 Opus, the success rate is only about 60%. Why do top models score so low?

After our own testing, we made some interesting discoveries. Our baseline was using Claude 4 Sonnet. We found that letting the model think on its own once sometimes results in inaccurate outcomes.
Therefore, we adopted a method known in academia as “Sequential Revision”, which is also the method we use at Pine AI. Whenever the Agent is about to send information to the user or perform an irreversible operation (such as modifying an order or canceling a ticket), it first calls another “judge” model.
This judge model is also a powerful large model (such as Claude 4 Sonnet, but with different prompts or parameters), which decides whether to “approve” or “reject” the upcoming operation. If the judge rejects it, we re-input the previous context, the rejected operation, and the reason for rejection to the task-executing model to regenerate the operation.
This method sounds simple, akin to reflecting once more before acting. But just by using this approach, the test success rate increased from 56% to 64%.
Where does this 8% improvement come from? Mainly from some successfully rejected cases. For example, hastily concluding without sufficient research. In Tau-Bench, if a user requests “find the cheapest ticket”, the model might find one and want to return the result. The judge would notice it hasn’t exhausted all possibilities and prompt it to “think again”.
There are also cases where operations violated the rules in the prompt, such as “tickets over 24 hours cannot be canceled”. The judge would spot such issues. Additionally, there are calculation errors and other situations.
However, a 64% success rate means there are still 36% errors. What causes these errors?

We had Claude 4 Sonnet automatically analyze the failure cases. In the 50 examples from the Airline dataset, 18 failed. Among these 18 failures, surprisingly, 8 were due to the ground truth (i.e., the standard answer) itself being wrong.
For example, the ground truth violated the rules set by the test framework. The rule clearly states “flights over 24 hours cannot be canceled”, but the ground truth operation canceled the flight. Some ground truths contain factual errors, like writing the user’s name incorrectly.
In two other cases, the customer service agent felt powerless because any action would violate policy or couldn’t meet the user’s budget requirements. However, there were some more creative solutions that could solve the problem, which the data annotators hadn’t thought of.
In these 18 failure cases, 12 were issues with the test dataset itself, and only 6 were issues with the Agent, such as insufficient research or premature abandonment, but the Agent didn’t violate any rules.
It can be seen that in these complex scenarios, the error rate of human annotation is even higher than that of AI. This reflects that after using the most advanced models, AI is more reliable than humans in some aspects. It also highlights the difficulty of building a high-quality test dataset. If humans annotate, the errors in the data might be more than those of AI, so what should be done?

Therefore, we have always maintained a viewpoint: let LLM act as a Judge. In many scenarios, especially when the input is pure text, the rules are clear, and it doesn’t involve deep industry knowledge (like interpreting medical images), the analytical ability of the most advanced AI models has surpassed the average human level.
In such cases, LLM as a Judge is a very good method for evaluating Agents. It can not only evaluate the actual performance of Agents but is also crucial for building RLHF training data and knowledge bases. Because RLHF needs to continuously generate (rollout) possible trajectories and judge their quality. If AI is used for automatic judgment, the iteration speed will be much faster. Similarly, when building a knowledge base, whether a case should be recorded as a positive or negative example also requires accurate judgment.
Often, if we use LLM for evaluation and find the results poor, the reasons are usually the following:
First, the rules are not clear enough. The standard for clear rules is “understandable by outsiders”, and it cannot be assumed that the foundational model has insider knowledge. Many things that seem common sense to insiders are not obvious to outsiders.
Second, the context is incomplete. For example, if the user’s basic information is not fully provided, AI cannot judge right from wrong.
Third, the model used is not state-of-the-art, or the “thinking mode” is not enabled. If a weaker model is used for judgment, it might say “great, very reasonable” to any output, without actually spotting key issues. Therefore, the capability of the foundational model is crucial, and the best model must be used for evaluation and analysis.

Alright, let’s make a simple summary. How to reduce the real-time interaction delay of AI Agents and enhance their problem-solving capabilities?
We propose two main directions:
- Reduce delay through “combining fast and slow thinking”.
- Achieve proficiency through “learning from experience”.
Learning from experience can be done in several specific ways:
- SFT/RL training models: Solidify experience into model parameters, forming “muscle memory”.
- Code generation tools: Automate fixed operation trajectories, generating reusable RPA code, significantly speeding up graphical interface operations.
- Building a knowledge base: Record and call upon past successful and failed cases.
These methods are not substitutes for each other but are complementary. Closed-source models + knowledge bases + tools as slow thinking, open-source models + SFT/RL as fast thinking are key to building the technological moat for Agent technology.
Whether it’s generating code, building knowledge bases, or providing data for SFT/RL, an accurate automatic evaluation mechanism is essential. We believe that in many scenarios, LLM as a Judge is already a more reliable and efficient evaluation method than humans, and it is the key direction for future AI evaluation.
We hope that today’s sharing will inspire more people to build Agents that can interact with the world in real-time and truly solve practical problems.

The interaction between Agents and the world can be divided into three levels:
The first level is real-time voice calls. We at Pine AI have already achieved relative maturity at this level. The input speed of the voice modality is about 15 to 50 tokens per second, which still poses a challenge for real-time output for most LLMs, thus requiring the fast and slow thinking engineering methods we mentioned earlier.
The second level is operating graphical interfaces. This is more difficult than voice because it involves visual modality input, with each screenshot potentially containing nearly 2000 tokens. Our exploration at this level has also reached the industry-leading level. When handling complex tasks such as writing emails and booking flights, the completion rate is close to 100%, far exceeding most open-source browser operation frameworks on the market. Moreover, once proficient, the operation speed is also many times faster than them.
The third level is interacting with the physical world. This may be the direction to explore in the coming years, including robots, autonomous driving, and even playing action games in graphical interfaces. It requires extremely fast reaction speeds, possibly involving mixed modality input of vision and voice, with input tokens per second potentially reaching 20k.
When interacting with the physical world, the cost of errors is more severe, such as a mistake in autonomous driving could be catastrophic. Therefore, this places the highest demands on the Agent.
We at Pine AI are following this path, from voice calls to graphical interfaces, and gradually exploring deeper levels, hoping to enable Agents to truly interact with the world in real-time and complete tasks for users end-to-end.
Our first product can now help you get things done by making calls and operating computers. You only need to provide some basic information, and it can contact customer service to handle various tasks for you—whether it’s negotiating bills, canceling subscriptions, processing refunds, or booking restaurants, querying physical bookstore information. We aim for a high success rate, and no charge if the task is not completed.
Making calls, operating computers, and sending emails are our basic capabilities. Their combination offers a vast space for future imagination.

Finally, a little advertisement for our company. We at Pine AI are looking for full-stack engineers capable of building SOTA autonomous AI Agents.
We uphold a belief: Everyone’s contribution to the company must be significant enough, with each person’s contribution to the company’s valuation exceeding ten million dollars.
We have a few requirements:
First, proficiency in using AI programming tools is a must. Our coding interview involves, with AI assistance, using an AI IDE to develop a new feature requirement based on an open-source project within two hours. If you are completely unfamiliar with AI programming, it will be difficult to complete within the stipulated time. In our company, over 80% of the code is completed through human-AI collaboration. Project management, case analysis, and other internal systems are also built on AI. AI Agents make us a truly AI-native team.
Second, you must enjoy hands-on coding to solve problems. As Linus famously said: Talk is cheap, show me the code. Since AI can already handle a lot of low-level coding work, humans are more like a combination of an architect and product manager. You only need to tell the AI what you want to do, what the software architecture is, or handle some tricky issues in the prompt. In this mode, hands-on coding is necessary, because directing a few junior employees is not as efficient as directly commanding the AI, with less information transmission loss. We have no junior employees here; every employee must fully utilize AI tools to boost productivity.
Third, solid software engineering skills are required to ensure the quality and style of the generated code. In the era of AI programming, software engineering quality is more important. Without documentation, test cases, or a local testing environment, AI is unlikely to have the mind-reading ability to guess what the code is for, making it difficult to complete coding tasks independently.
Fourth, understanding the principles of LLM, keeping up with the latest developments in the LLM field, and having the ability to write AI Agents yourself is necessary. Only by understanding the basic principles of LLM and continuously updating your understanding of the boundaries of LLM capabilities can you harness LLM, provide it with the appropriate context and tools, and achieve SOTA-level Agents.
Lastly, and importantly: you must have the confidence to solve world-class problems and achieve SOTA levels, and the confidence and courage to grow with a startup. Just like doing research, if your paper is not up to par with others, it cannot be published. This confidence is essential.
We hope to work with more like-minded people to build Agents that can interact with the world in real-time and learn from experience, truly solving problems for users, getting things done, and gradually increasing users’ trust in Agents as they accomplish more and more tasks, ultimately allowing users to entrust more important tasks to Pine.

Today is the Turing Large Model Technology Special Session, and if you are interested in large models, don’t miss my translated “Illustrated Large Models” (published in May 2025) and the upcoming “Illustrated DeepSeek Technology”. These two books explain large language models and inference language models in an accessible way, with beautiful illustrations, providing a panoramic overview of various fields of large models in a relatively short length. Only by understanding the basic principles of LLM and continuously updating your understanding of the boundaries of LLM capabilities can you harness LLM to create truly useful AI Agents.
Thank you all!