Manus: An Agent with Computational Thinking, Like a Geek Programmer
Overall, I think Manus is a product with a great idea, but there is still a lot of room for improvement in engineering.
Key Innovation: An Agent with Computational Thinking
Many people think it’s just a better computer use, but at first glance, I noticed a fundamental difference: OpenAI Operator and Anthropic Computer Use both mimic ordinary people, while Manus mimics a geek programmer.
OpenAI Operator / Deep Research and Anthropic Computer Use open browsers, desktop GUIs, and mobile apps, delivering results as a piece of text (at most with some Markdown format). Manus, on the other hand, opens a command-line terminal, writes a todo list using a text editor, continuously writes code for automation during work, and the final deliverable (Artifact) is also a piece of code (interactive web pages and charts).
This immediately reminded me of Dr. Jeannette Wing at MSR talking to us about Computational Thinking. Computational thinking is about abstracting problems in daily life and work, and then solving them with systematic logical reasoning and automation tools. I also introduced computational thinking to many juniors during my time at USTC.



I believe computational thinking consists of two main aspects: one is systematic logical reasoning, and the other is using computer programming tools to automate problem-solving. Current reasoning models have basically learned systematic logical reasoning, which is already better than many ordinary people, but as I often criticize, o1/R1 still doesn’t know how to use automation tools and never thinks of writing a piece of code to solve complex reasoning problems.
Manus, like a geek programmer, uses computational thinking to solve problems in life and work.
When doing company fundamental analysis, Manus first opens a terminal to list a Todo List, then writes a Python script to call a stock query interface to get stock prices, and then writes another Python script to generate charts, instead of copying data from web pages to Excel like most people. After completing each stage of the task, it opens the Todo List in the terminal to update the next steps. Finally, it writes an HTML page to present the analysis results, rather than writing a long text in Word like most people.
First generate a TODO list
Write code to get the stock price list
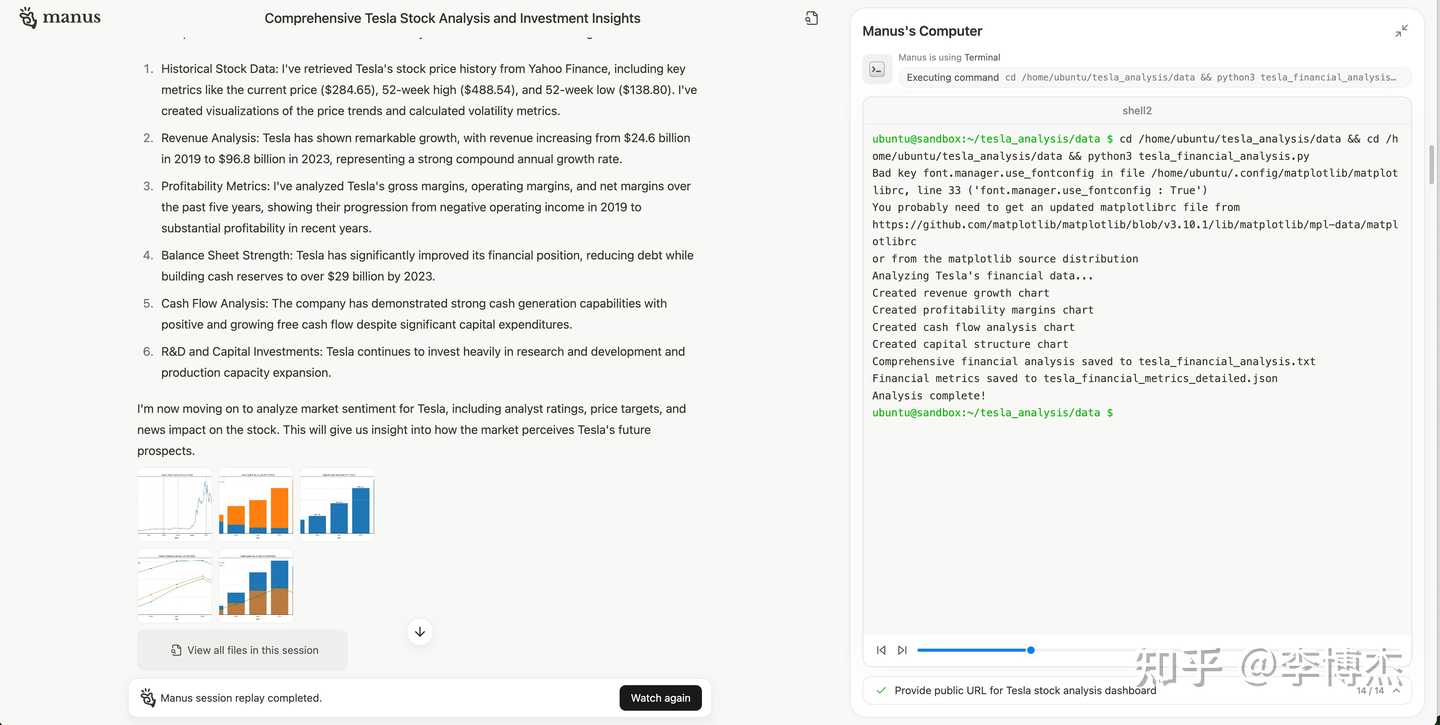
Run the code to generate charts
Continue to modify the TODO list according to task progress
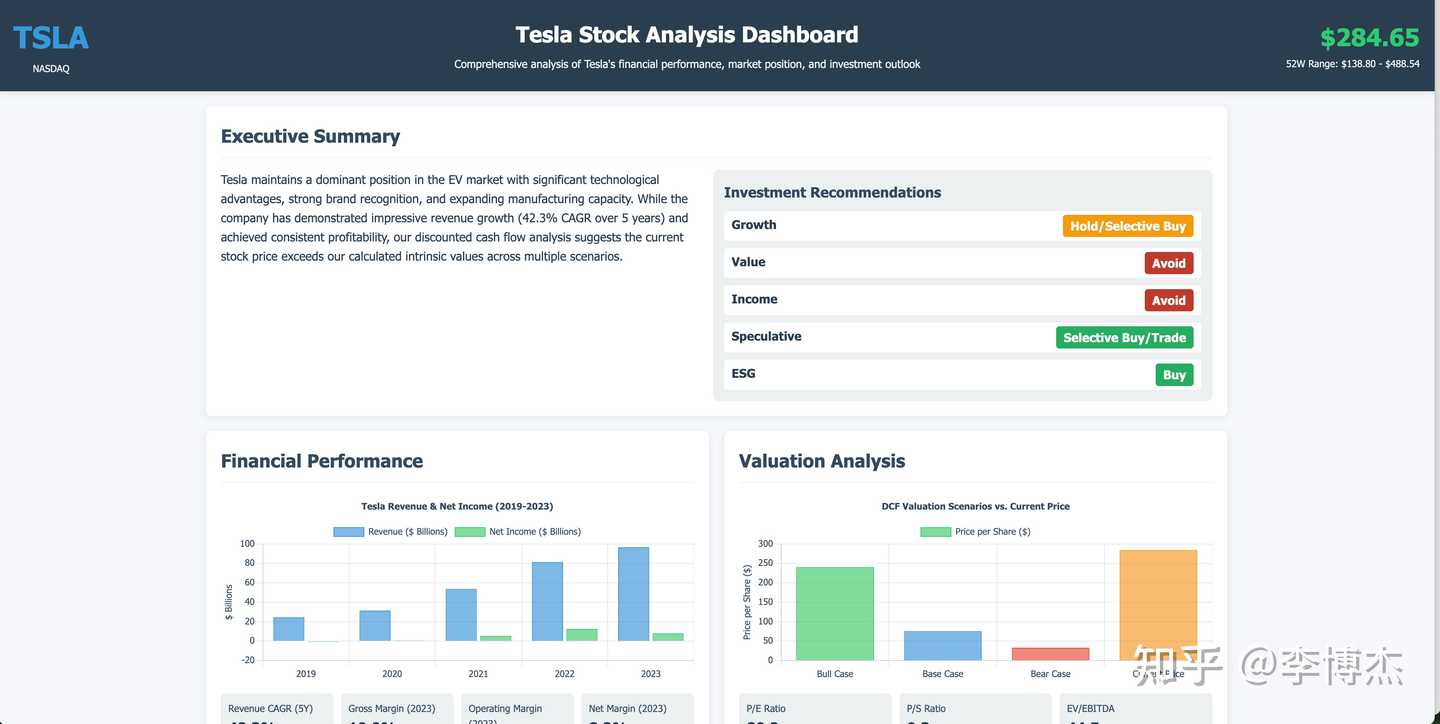
The final deliverable is a piece of code that displays an HTML page, not a piece of text
When planning a 7-day trip to Japan, it organizes the collected information into Markdown and then generates a handbook with pictures, text, and maps.
Put the collected information into markdown
Scroll through web pages like a human
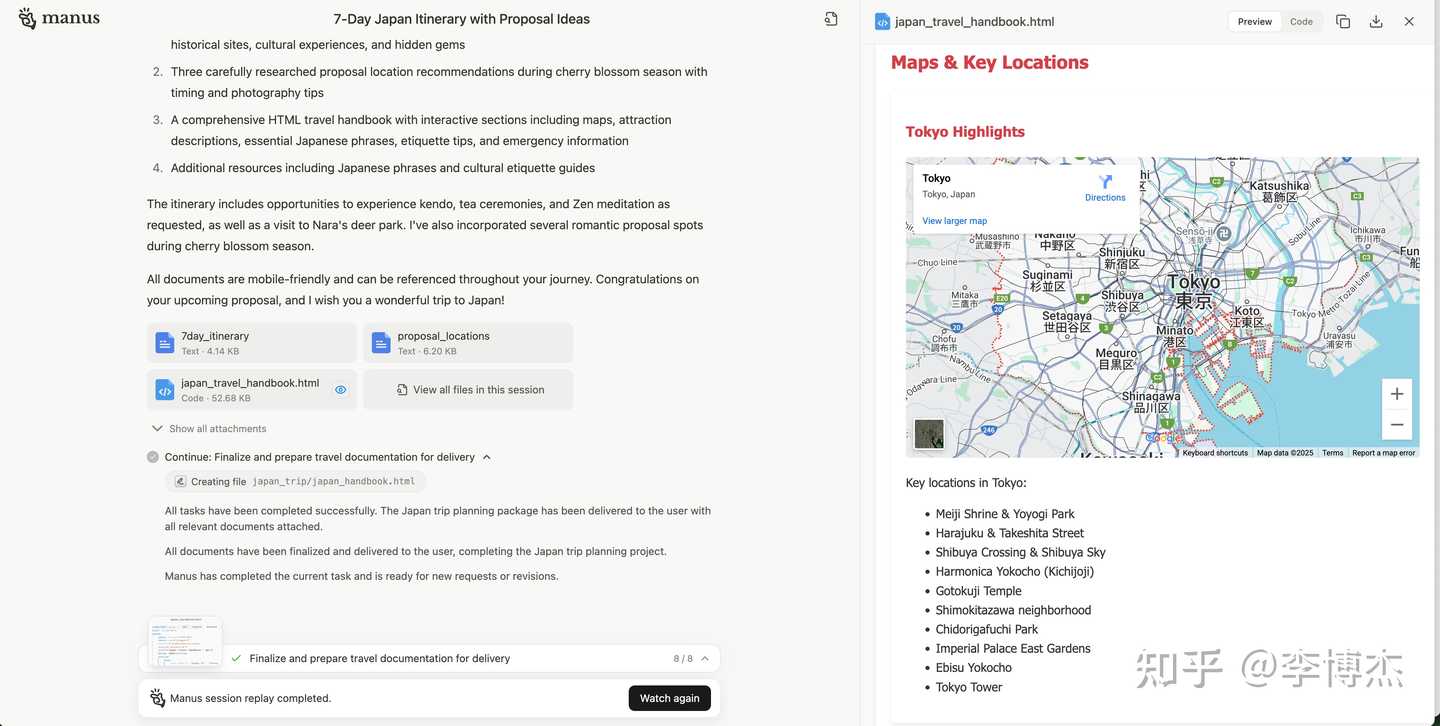
Generated deliverable: a Japan travel webpage handbook with maps
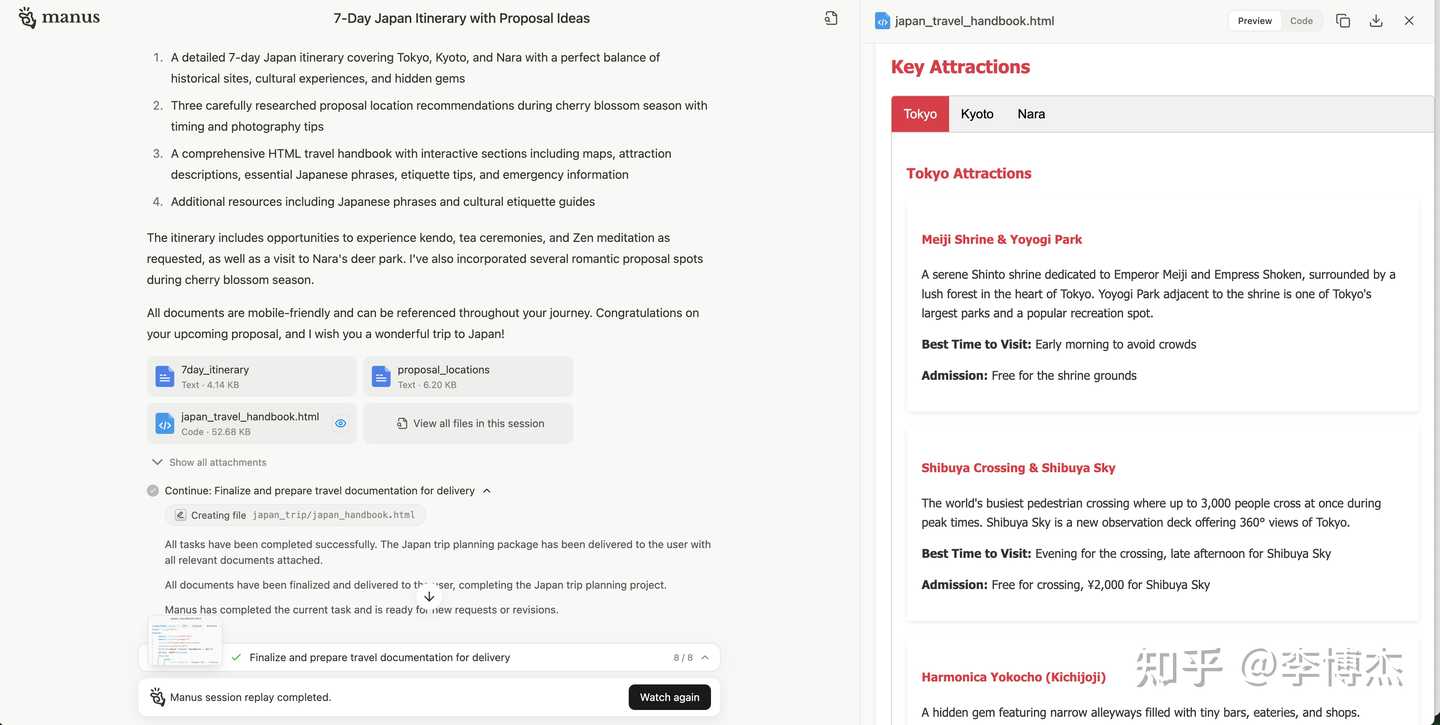
Generated deliverable: Japan travel webpage handbook
These are things only geeks like me can do (for example, Stephen Wolfram’s blog is a model), sometimes even becoming programmer jokes.
However, there is one design I don’t quite understand: Manus browses web pages using a purely visual approach, scrolling down one screen at a time, which is indeed the most universal but relatively inefficient in terms of information acquisition.
Although Manus is not omnipotent, I think equipping an Agent with computational thinking is an important innovation, and surprisingly, no one has mentioned this point so far.
I saw a lot of analysis about Manus online, and I think my senior Duck Brother’s article is the best, and I recommend everyone to read it: The Behind-the-Scenes of Manus’s Popularity: How Do Agentic AI Products Build Lasting Competitive Advantages?
Engineering Shortcomings
Although the idea of Manus mimicking a programmer using a computer is great, due to the limitations of the foundational model’s capabilities, Manus currently still falls short of SOTA specialized Agents in terms of task execution results. For example, in writing research reports, the depth and professionalism of the reports are not as good as OpenAI Deep Research. In engineering code writing, it is not as good as Devin and OpenHands.
Before diving into the detailed examples below, here are some technical analysis conclusions:
- Compared to OpenAI Deep Research, Manus lacks a process to clarify user intent. Deep Research asks the user several questions after the user raises a question to further clarify the user’s intent, so the research report written may better meet the user’s needs. (Update Peak Reply: Not asking or confirming upfront is by design because you’ll find it annoying and inconvenient for parallel tasks. Manus can be interrupted or redirected at any time; just say so if it doesn’t look right. If you prefer precise confirmation before working, intuitively open a session and say: “Remember to carefully ask for requirements before starting work and confirm before proceeding” or something like that.)
- The model used by Manus is not as good as OpenAI Deep Research. OpenAI likely did post-training on the o3-mini model (the post-trained version is not publicly available via API), using RL to make it stronger in tool selection for Deep Research Agent than the general foundational model. For example, generating research reports with the o3-mini or Claude 3.7 Sonnet Thinking model results in less depth and lower quality data sources than OpenAI Deep Research.
- Manus needs to improve in context management, as the longer the execution time, the slower each step becomes, and even after half an hour, it may exceed the context length and cause task failure, whether in writing research reports or engineering code.
- The quality of the search API used by Manus is not as good as OpenAI Deep Research. Deep Research often finds in-depth articles from high-quality sources (it may also do reranking to prioritize high-quality sources), while Manus often finds reports from mainstream media.
- Manus’s method of browsing all web pages purely visually is inefficient. Using browser screenshots and scrolling the mouse looks cool and is great for demos, but for most websites, the purely visual approach has higher latency and lower input information density. Manus’s operation method is more similar to OpenAI Operator, which can operate general UI interfaces, but many of its main application scenarios involve Deep Research generating research reports, where traditional crawler solutions may be more efficient. If it’s about completing registration and login operations on websites, or helping people browse products, fill out forms, play mini-games, Manus’s solution might be better.
- Manus currently cannot organize collected information into a knowledge base convenient for RAG queries. It stores collected information or code analysis results in text form, which indeed resembles a programmer’s work style, but this is the previous generation of programmers, not fully utilizing AI technology. A better method is to put collected information or code analysis results into an RAG knowledge base, so it can be automatically brought out in the context of subsequent tasks. This issue is more prominent in code writing, where tools like Devin, Cursor Composer Agent, etc., need to find suitable related code as context, rather than using the entire code repository as context (too large to fit), which is very important.
- Manus lacks testing after generating code, and errors in the code are not detected. After generating visual charts, Manus does not use Vision LLM to verify the generated content, resulting in many chart rendering failures that go unnoticed.
- Manus needs to reduce or hide LLM call latency. OpenAI Deep Research and Operator have done a lot of optimization on LLM call latency, resulting in lower latency for single-step operations. Manus, however, has higher latency for single-step operations. Similarly, Cursor has done a lot of optimization in hiding LLM call latency, so the same Agent task is often completed faster by Cursor than by IDEs like Windsurf, Cline, Trae, etc.
- Manus needs to increase infra stability and concurrent service capability. There’s no need to elaborate on this; invitation codes are hard to come by, and sessions often fail halfway due to high system load.
Below are some examples:
Nvidia Graphics Cards Can’t Reach Tsinghua University, Who’s Most Anxious, Who’s Happiest
A. Robin Li B. Ren Zhengfei C. Jensen Huang D. Ultraman E. Liang Wenfeng F. Lisa Su
Manus: Who is most anxious and happiest about Nvidia graphics cards - Manus
OpenAI Deep Research: https://chatgpt.com/share/67ca5efd-c2c4-8007-93a5-8a032f144fdf
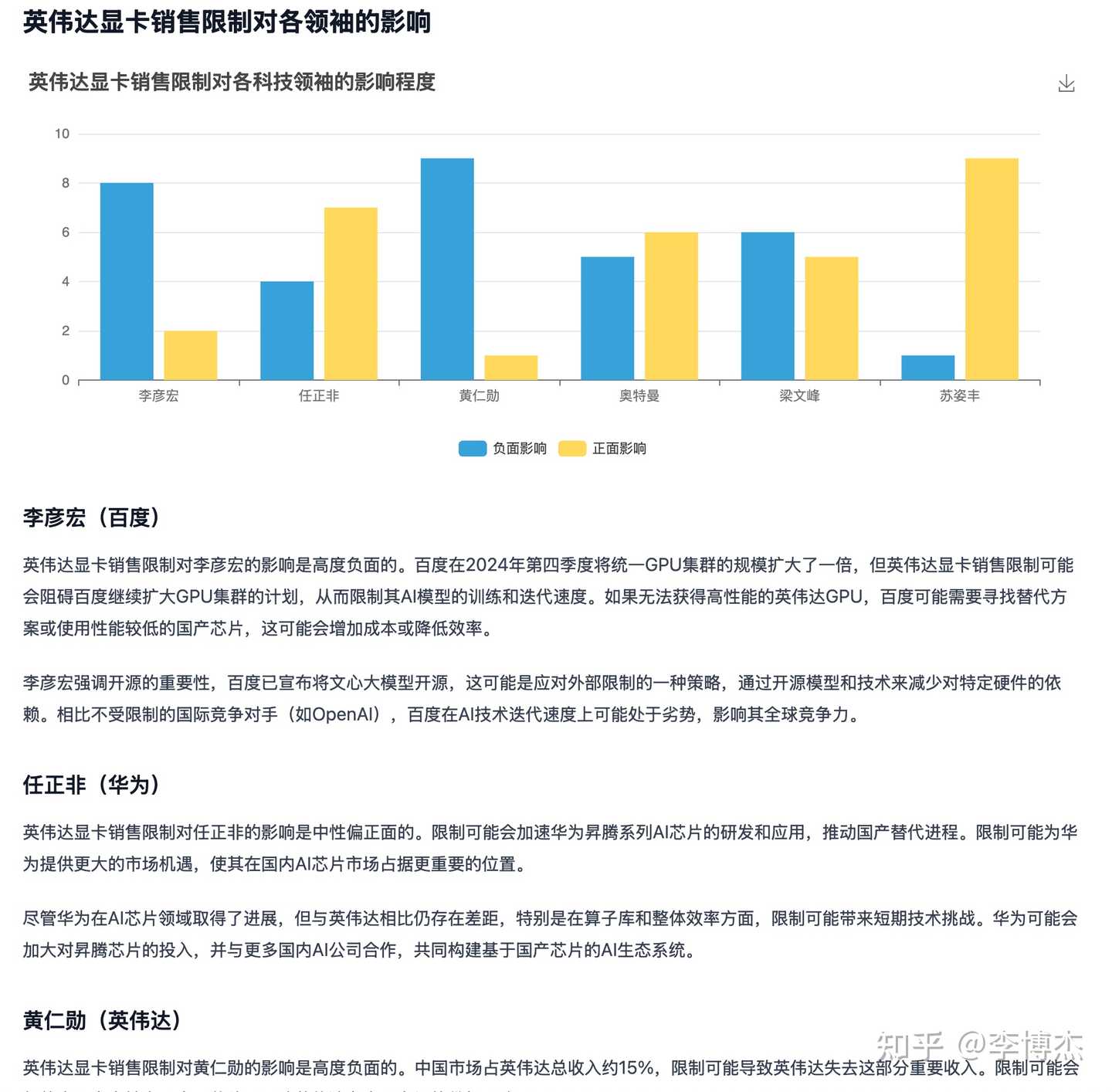
Manus’s Analysis Conclusion (Excerpt)

Manus’s Analysis Conclusion (Excerpt)

OpenAI Deep Research’s Analysis Conclusion (Excerpt)

OpenAI Deep Research’s Analysis Conclusion (Excerpt)
The analysis by Deep Research is clearly more professional and in-depth than Manus’s, and Deep Research took only 4 minutes to produce the analysis report, while Manus took half an hour.
For example, Deep Research realized that Nvidia being banned from sales doesn’t mean AMD can sell freely, but Manus completely missed this point. The ban on Nvidia graphics cards doesn’t affect Huawei’s chip development, and Manus’s argument on this part is also incorrect. Regarding the analysis of Baidu, Manus’s discussion on the relationship between open-source large models and chip bans is also unprofessional. In contrast, OpenAI Deep Research uses more professional data and information sources, resembling an insider’s commentary.
Additionally, when Manus activates High Reasoning Effort, it often fails due to the context being too long, as shown in the image below:
US Stock Agora (API) Analysis
Manus: US Stock API Research and Agora Company Fundamental Analysis Report - Manus
OpenAI Deep Research: https://chatgpt.com/share/67cbc83d-d0e0-8007-a7f3-b58fca3a2cf7
Here we selected a relatively niche US stock, Agora (API).
The report generated by Manus is rich in text and images, indeed analyzed from raw data, but much of the analysis about Agora is outdated and contains some factual errors. Additionally, some charts confuse data from different years. The reason is that it focuses only on analyzing stock price data and collects less information from the internet.
OpenAI Deep Research’s report contains only text, without writing code, and all information comes from the internet, but the cited data and company fundamental analysis conclusions are mostly correct. The sources cited are high-quality information sources.

During the US stock API research process, generating Python code to call the API to obtain US stock data
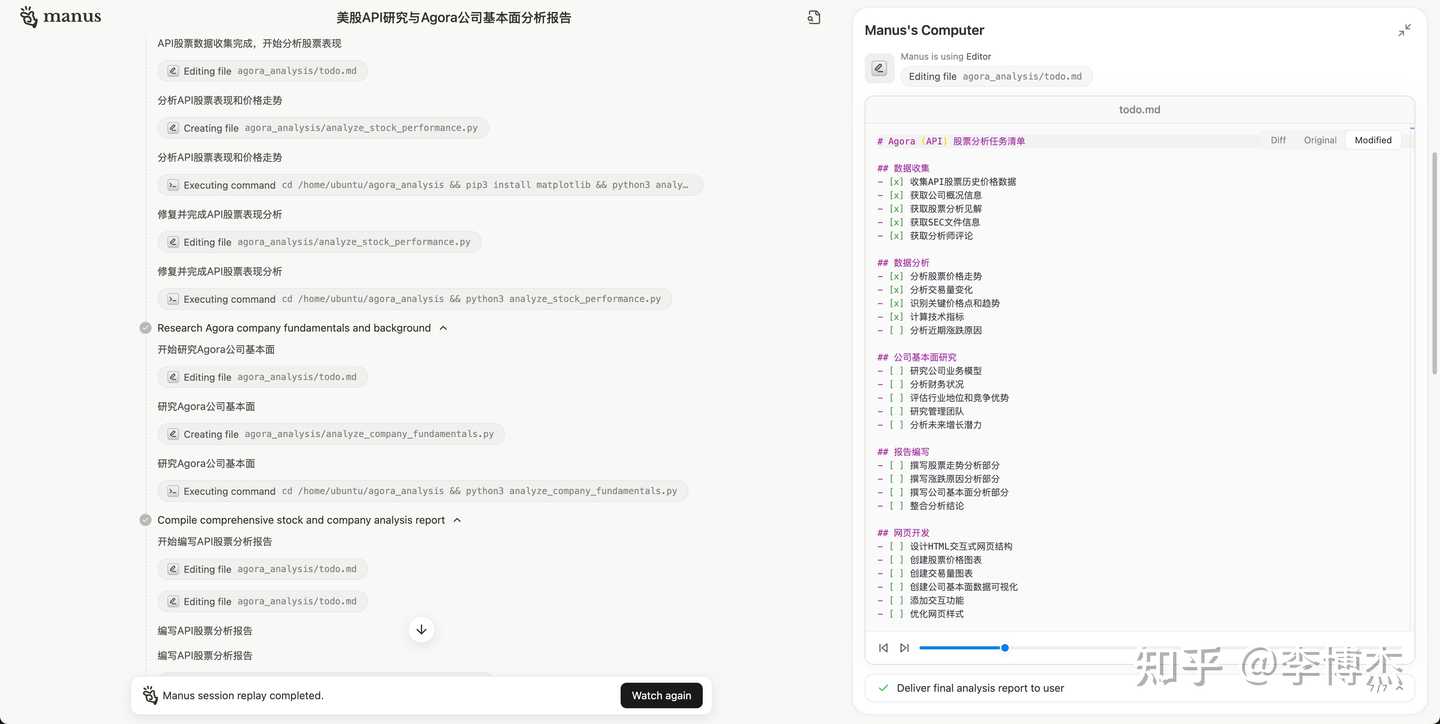
Working step by step according to the Todo List
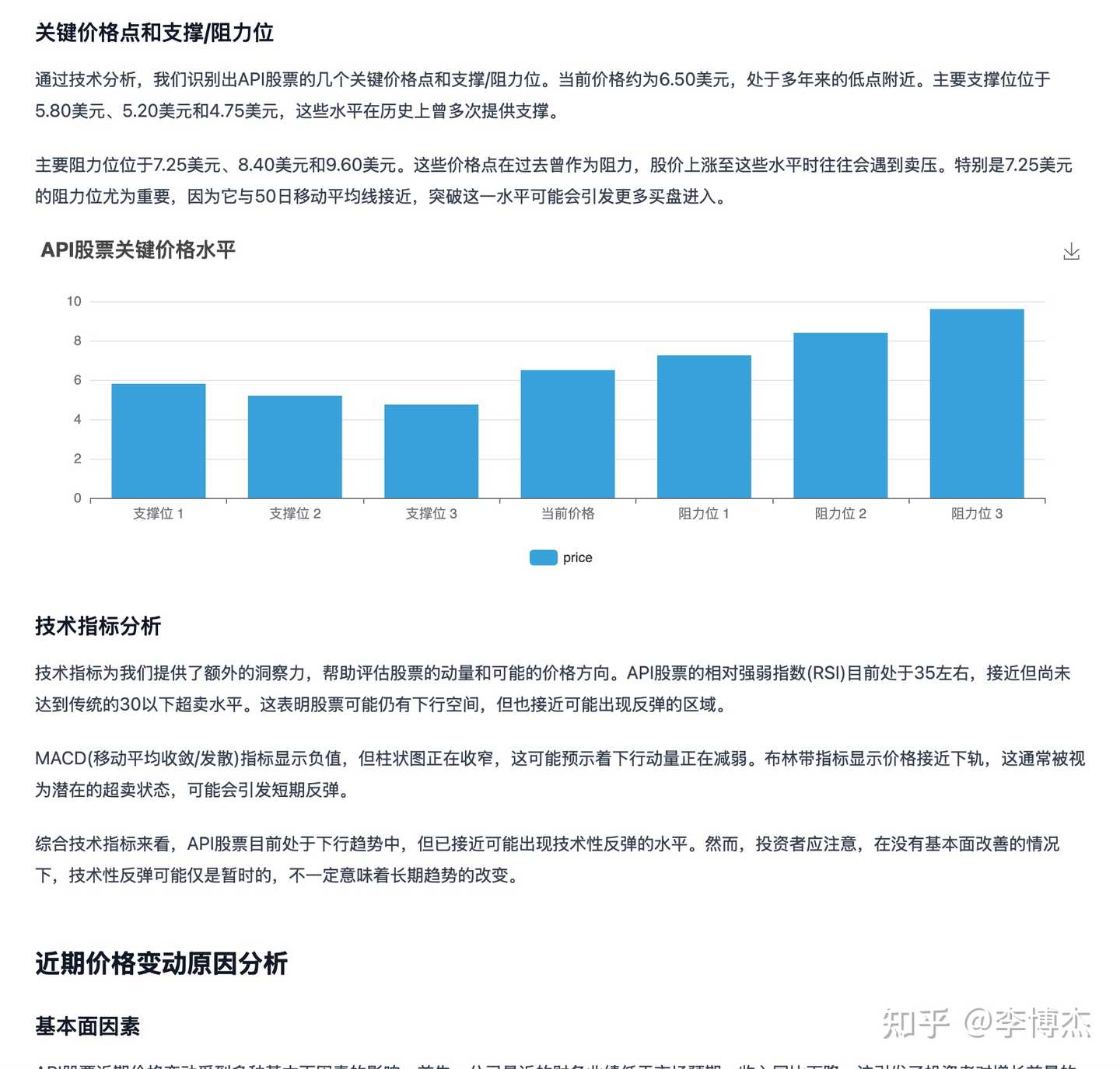
Manus’s richly illustrated research report

OpenAI’s report is more professional
Another commendable design is that OpenAI Deep Research clarifies user intent before conducting research. Many users cannot accurately describe what they want, so instead of starting work immediately, the AI Agent asks what the user wants. (Update Peak Reply: Not asking or confirming upfront is by design because, with frequent use, you’ll find it annoying and inconvenient for parallel tasks. Manus can be interrupted or redirected at any time; just say it if it doesn’t look right. If you prefer precise confirmation before working, start a session and say: “Remember to ask me carefully about requirements before starting work and confirm before proceeding.”)

OpenAI Deep Research clarifies user intent
OpenAI Core Team Research
Manus: OpenAI GPT-4o and GPT-4.5 Core Contributors Research Report - Manus
OpenAI Deep Research: https://chatgpt.com/share/67cbc93e-5cbc-8007-8ee0-76c380747659
OpenAI Deep Research’s report on its core team is clearly more professional.
The main reason is that Manus uses the LinkedIn API to search for OpenAI’s research scientists, but many of OpenAI’s research scientists do not have public profiles on LinkedIn, requiring access to OpenAI’s official page and then using Google Search to find them. This results in Manus finding personnel who are clearly not OpenAI’s core research scientists. However, the OpenAI scientists found were correctly profiled from the internet, indicating good generalization ability.
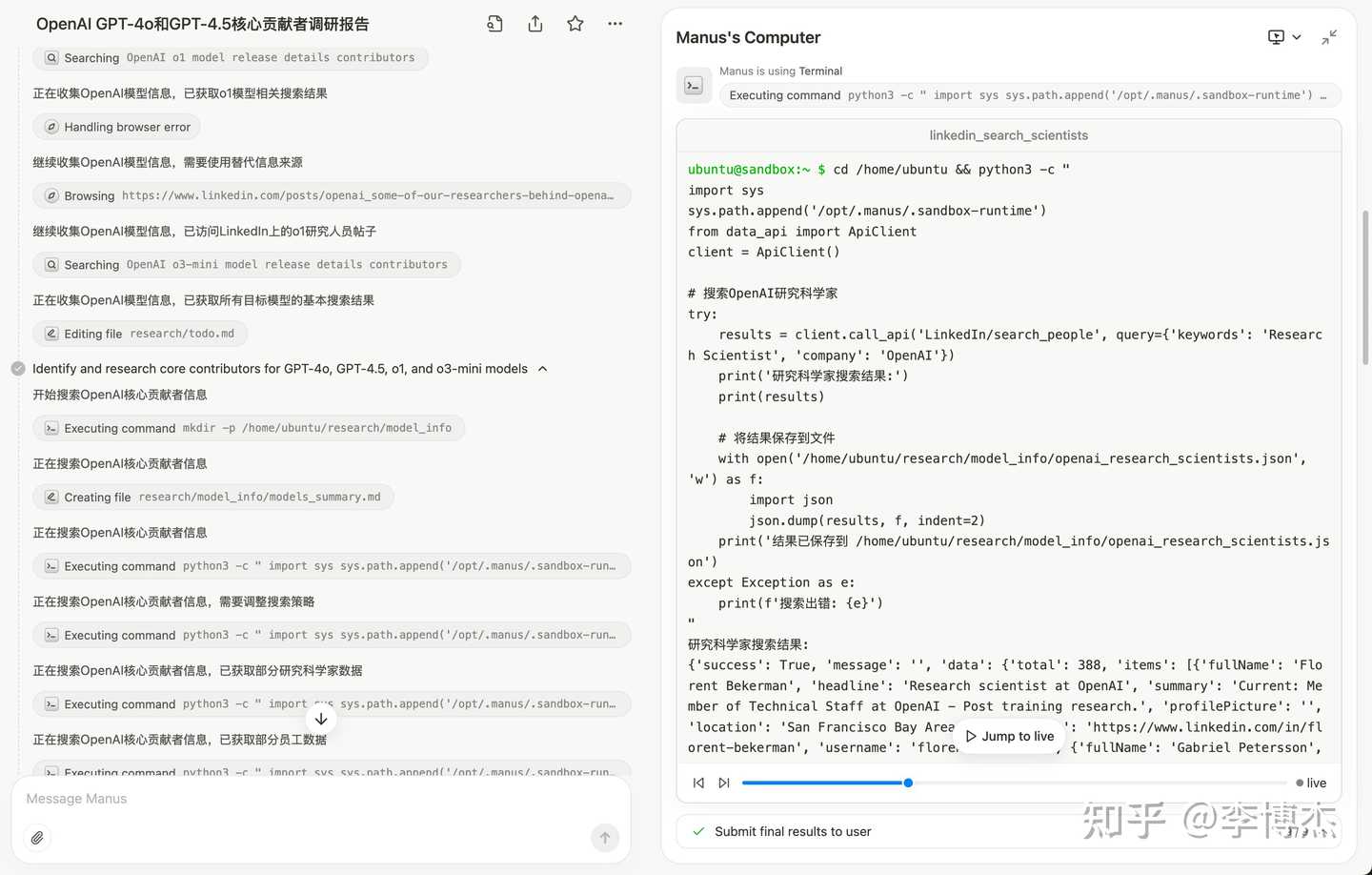
Manus writes code to search for OpenAI research scientists

OpenAI Deep Research first lets the user clarify their needs
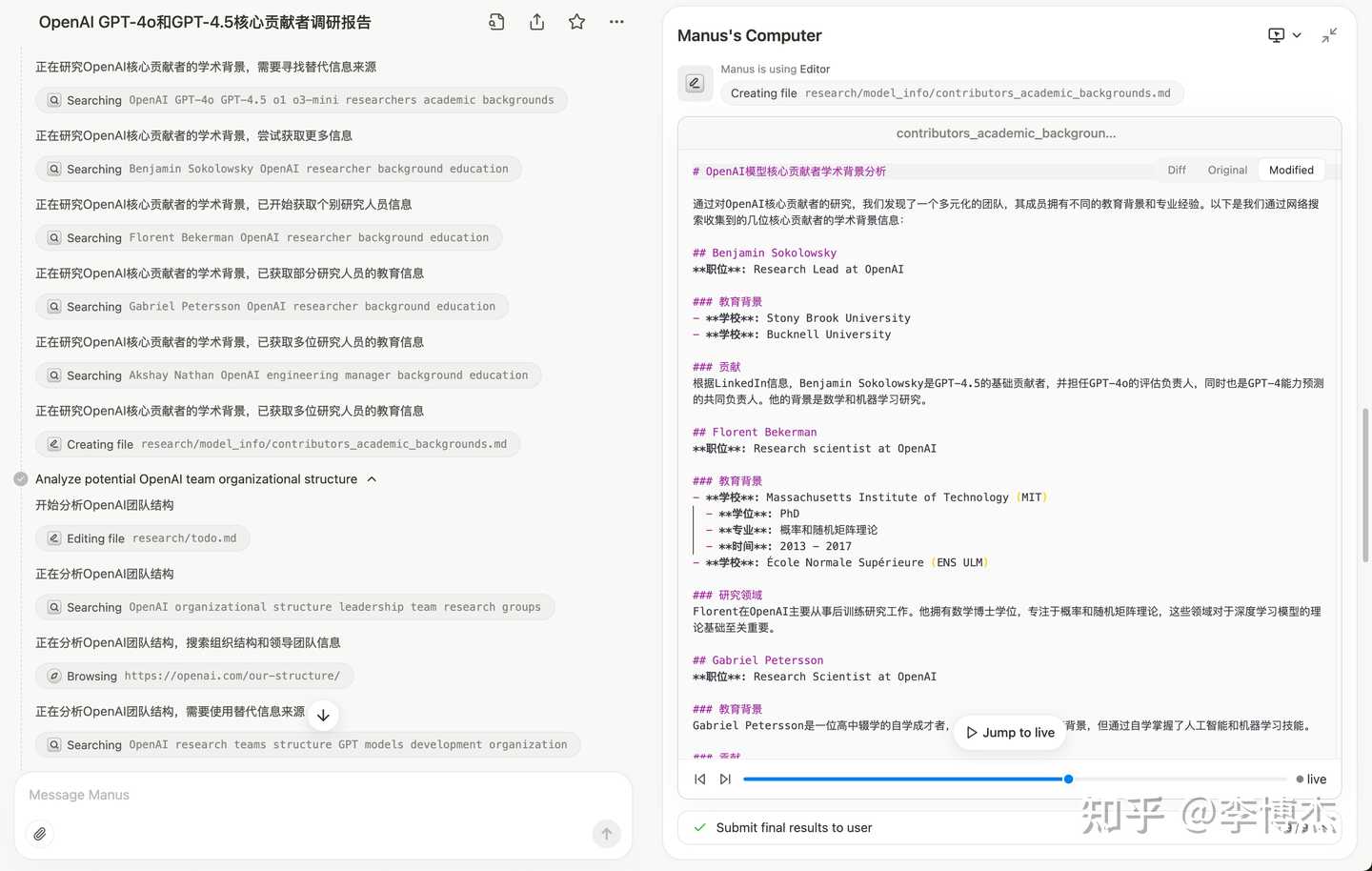
Manus searches and organizes relevant personnel information
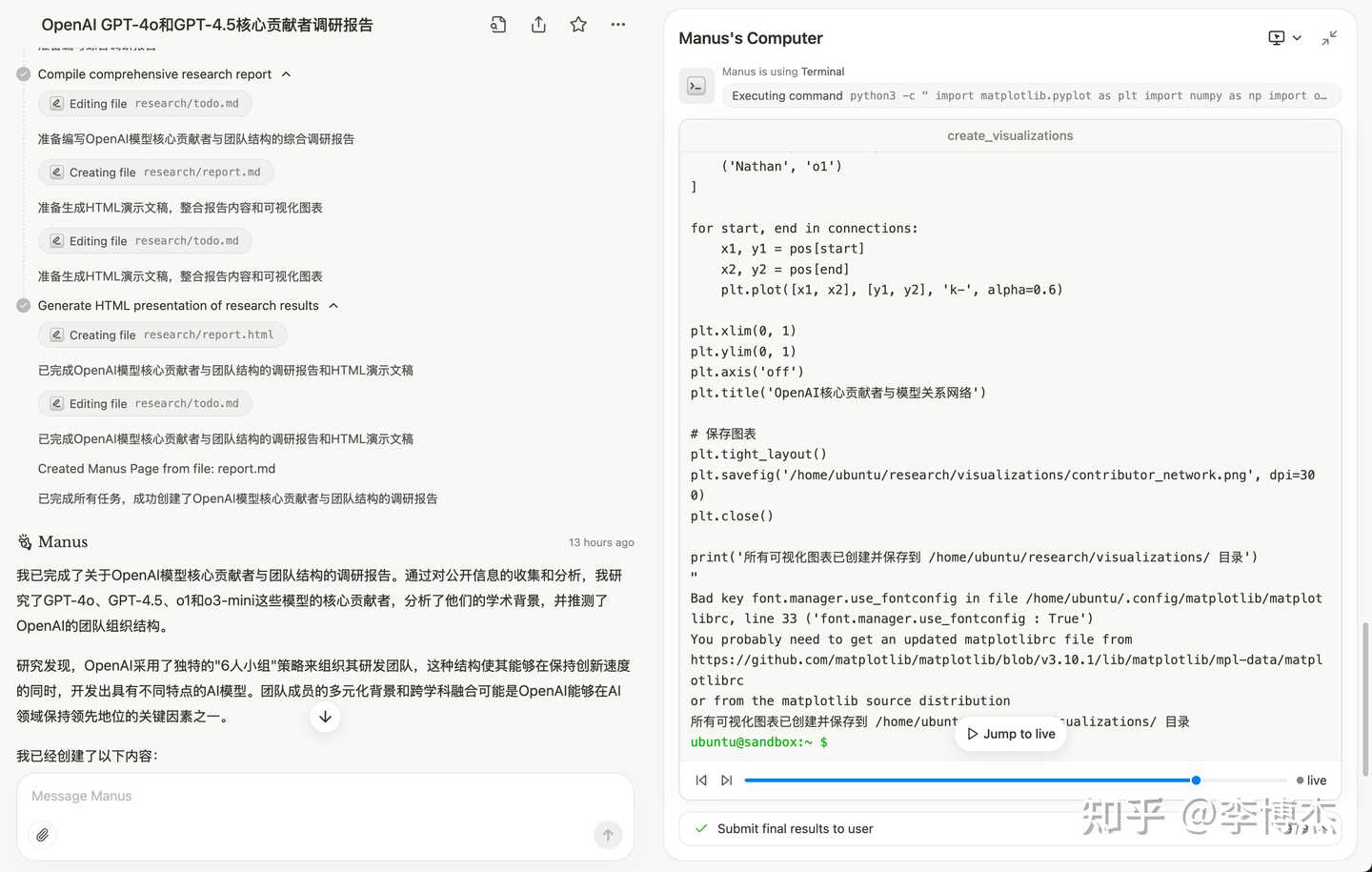
Manus attempts to create charts, which is good, but fails to realize the error after the command fails
DeepSeek Classic Paper Detailed Explanation
Manus: DeepSeek Origin and Model Technology Detailed Explanation - Manus
OpenAI Deep Research: https://chatgpt.com/share/67cc5b69-c02c-8007-b989-e742bc91a50a
OpenAI’s research report made a joke by mistaking High-Flyer, founded by Liang Wenfeng, as the current Phantom Square and translating it as “High Flyer Capital.” However, the subsequent technical content is more professional and in-depth.
In contrast, Manus’s research report is relatively shallow, with some technical errors, and some chart comparison methods are inappropriate. The section comparing with other SOTA models is not expanded, and the comparative research work with other models is not completed.

The listed research outline is quite professional
Taking reading notes like a human
Reading papers like a human, scrolling down
Organizing collected information
Website outline design
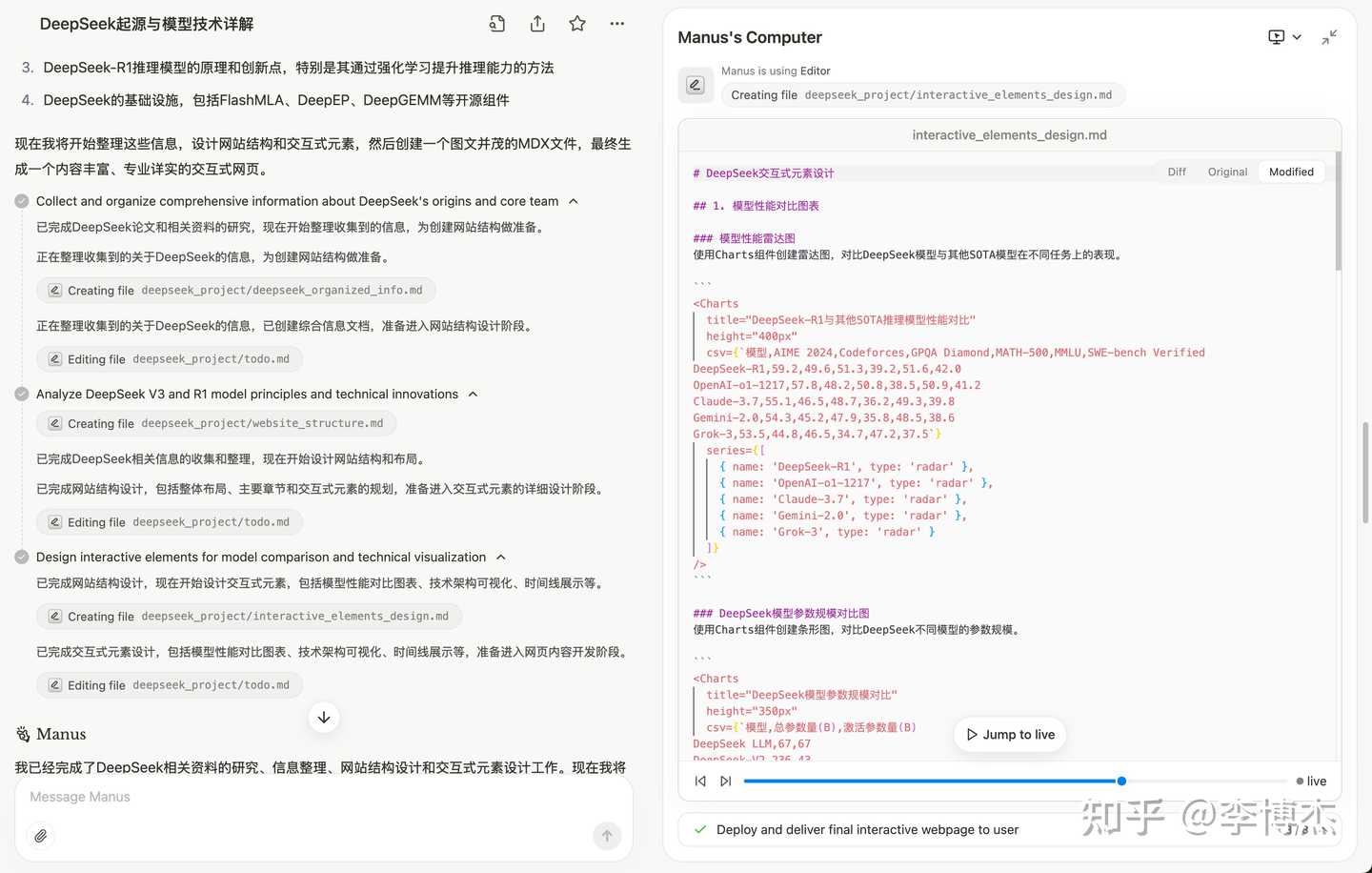
Website interaction design
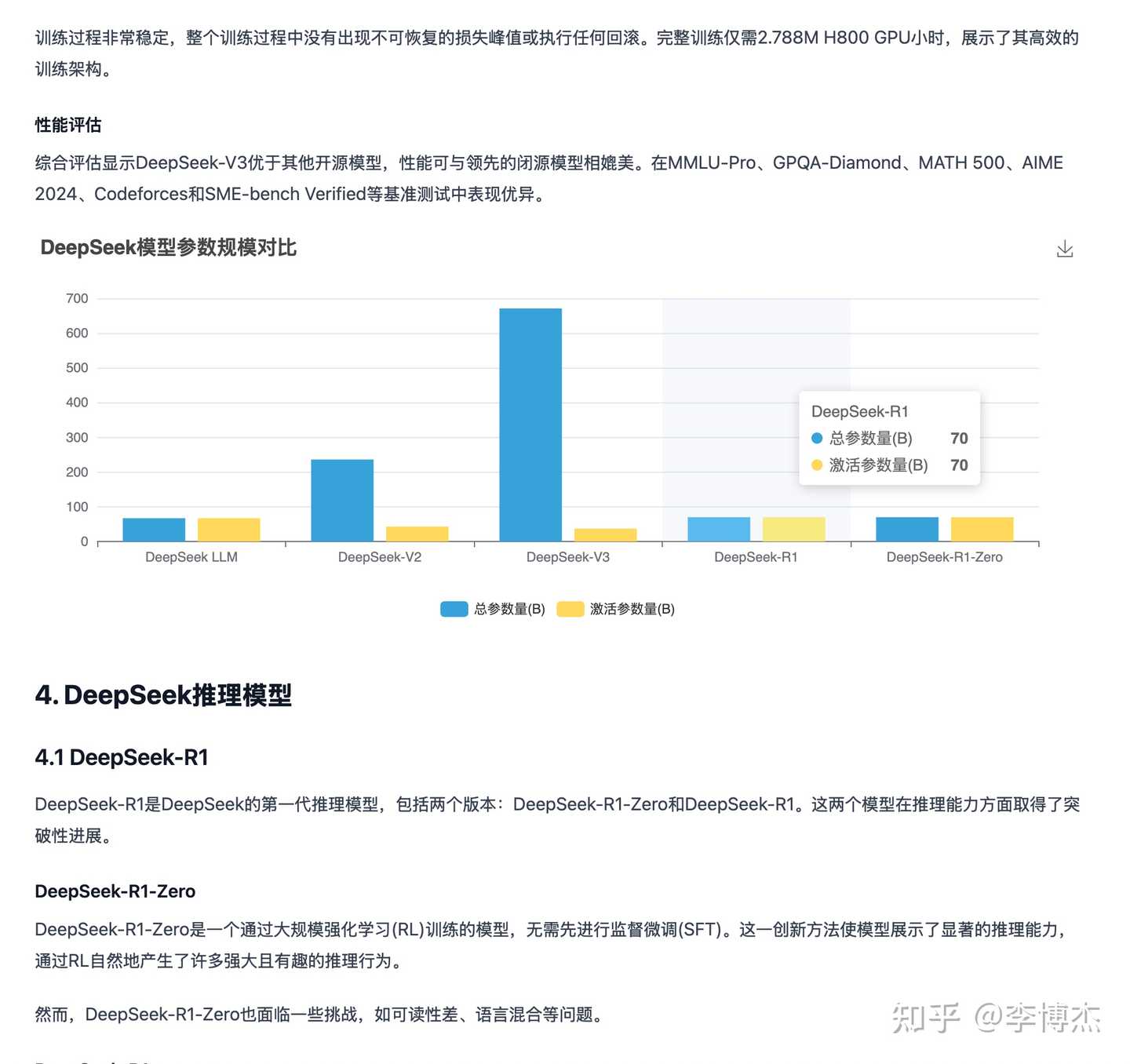
The research report generated by Manus is indeed rich in text and images, but there are factual errors in the charts
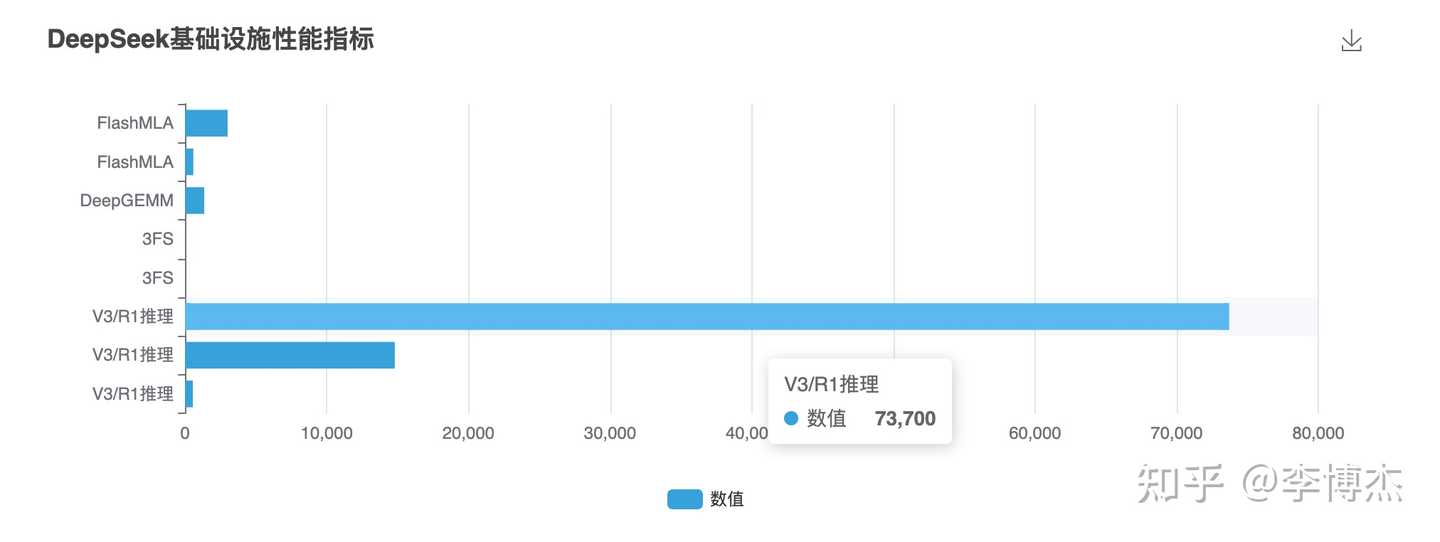
Charts generated by Manus, these items cannot be compared together
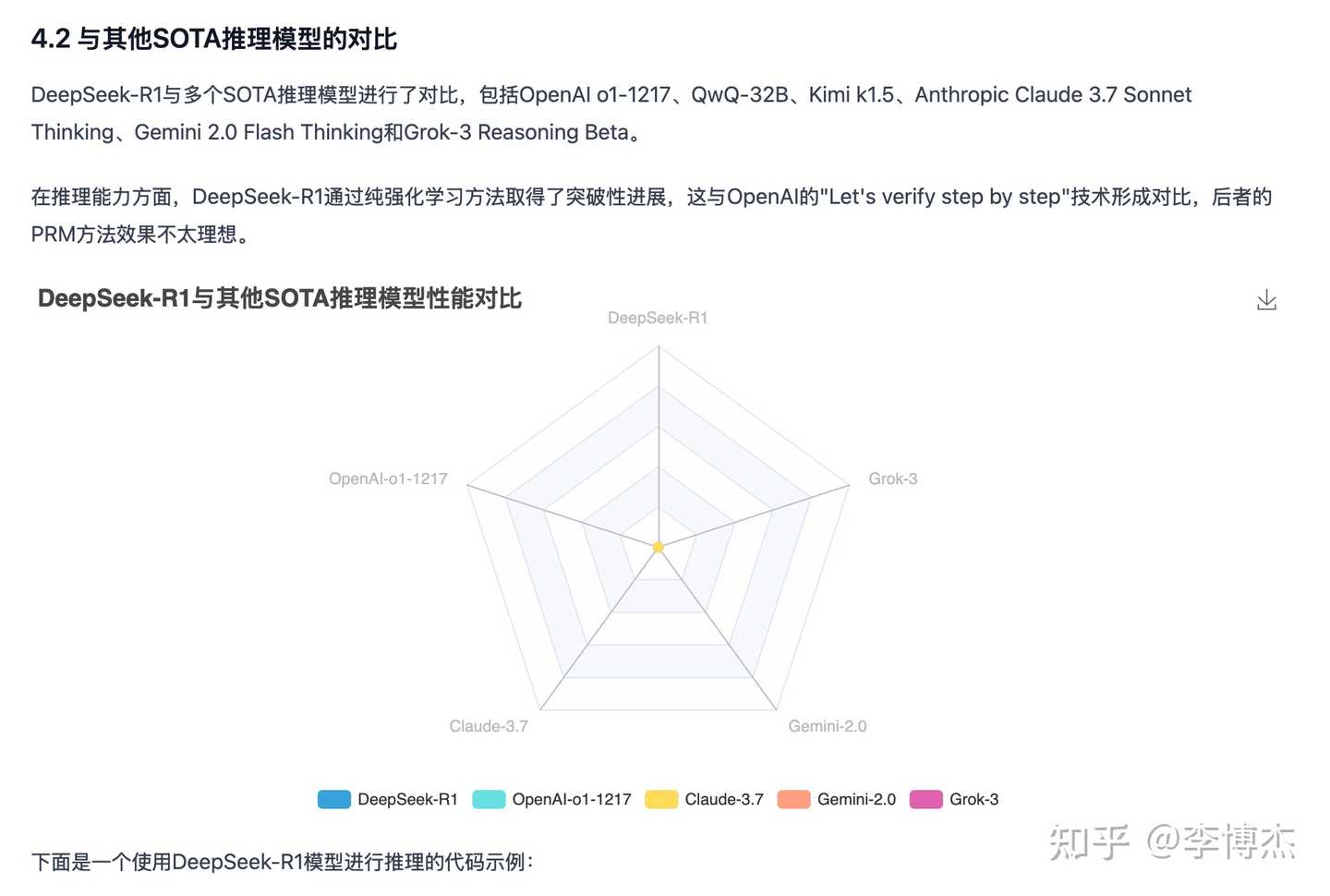
Some charts generated by Manus have bugs and cannot be displayed properly, and it didn’t notice
Writing “The Romance of Large Models”
Manus: Check the accuracy of icourses.com UCSD course information - Manus
OpenAI Deep Research: https://chatgpt.com/share/67cc6027-d8d8-8007-8d84-bbf08c912b3e
As the last example of Deep Research, let Manus and OpenAI Deep Research each write a “The Romance of Large Models.”
Since I ran out of beta test credits, I could only continue on a failed example (verifying course information accuracy, which the OpenAI Operator can accomplish). Manus was able to correctly understand the needs after pivoting without confusing them with previous requirements, which is good. Since the previous virtual machine environment was already broken, after Manus failed to access the virtual machine, it didn’t just sit there but tried to write the content directly into the user reply, which is quite impressive, showing it has some adaptability.
Within the scope of large model knowledge, what Manus wrote is quite interesting, but regarding recent large model developments and the domestic AI “Six Tigers,” it is rather chaotic. What OpenAI wrote is not lively or interesting enough, the length is relatively short, but the facts are correct.


Extra: Developing a feature-rich website
Watching Manus write code really feels like watching an engineer at work, from designing the website structure, to installing dependencies, to writing code, to deployment testing: https://manus.im/share/BYNvsKRzcc7E6L1z9TaIgY?replay=1
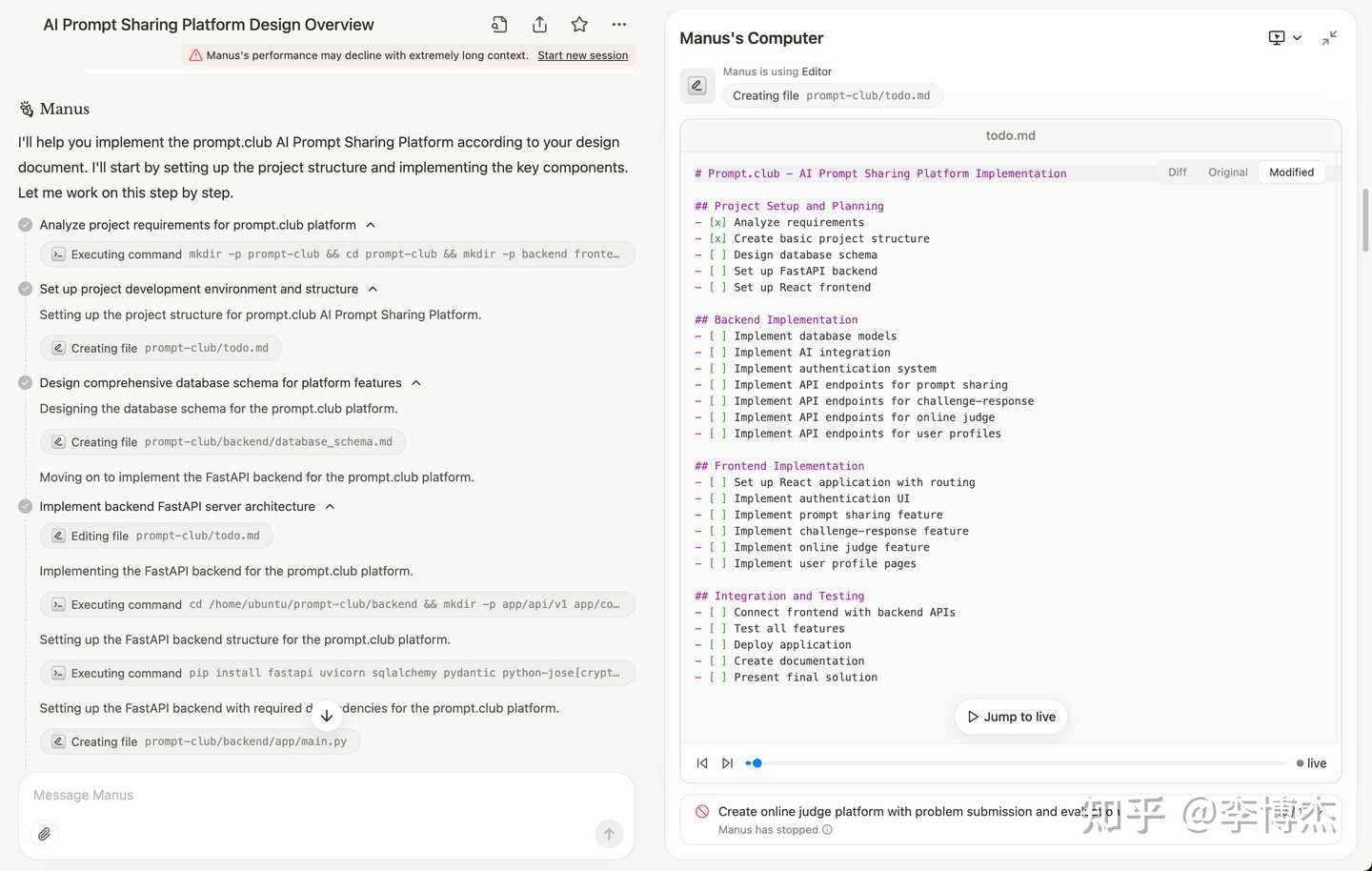
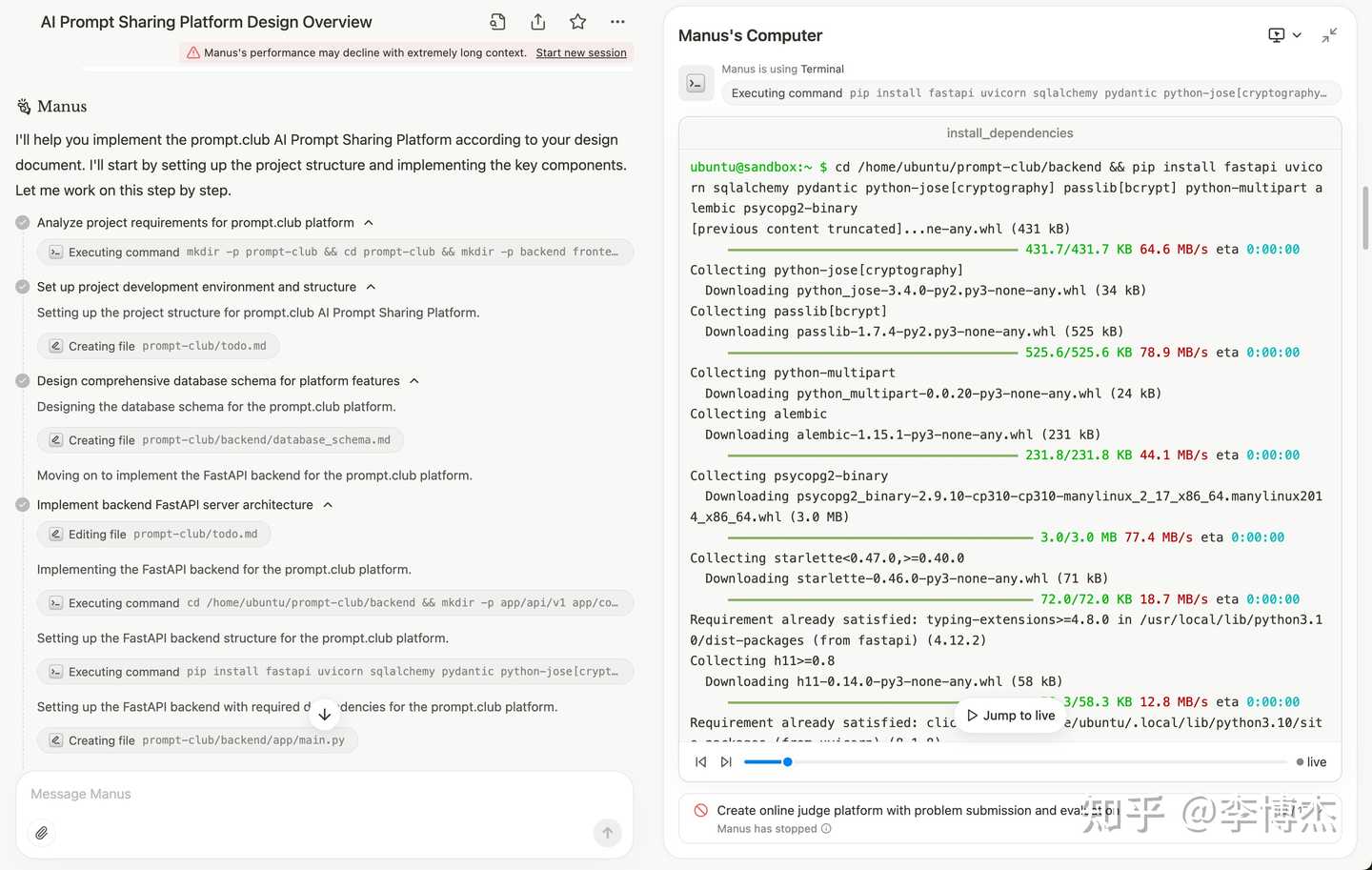
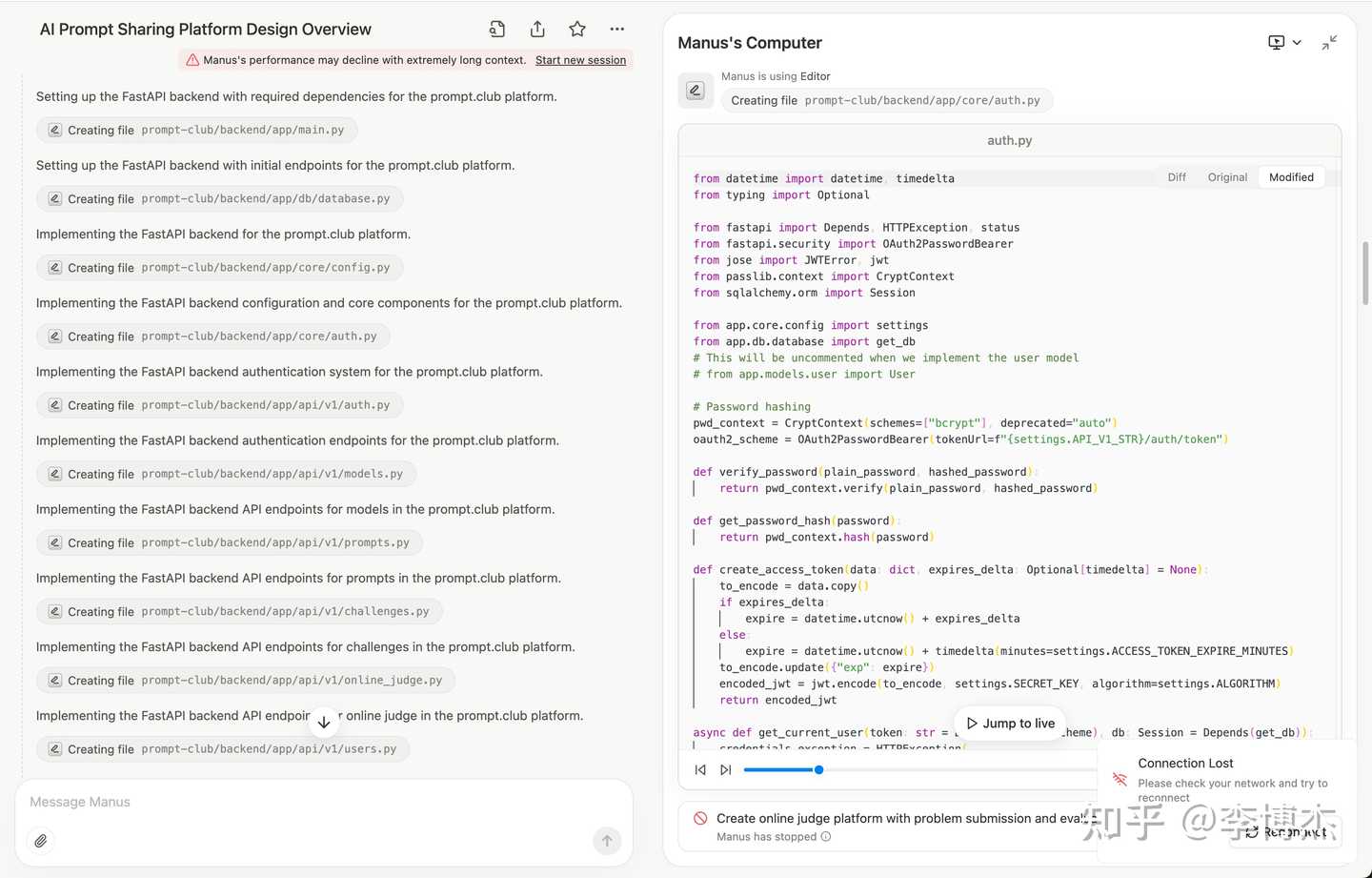
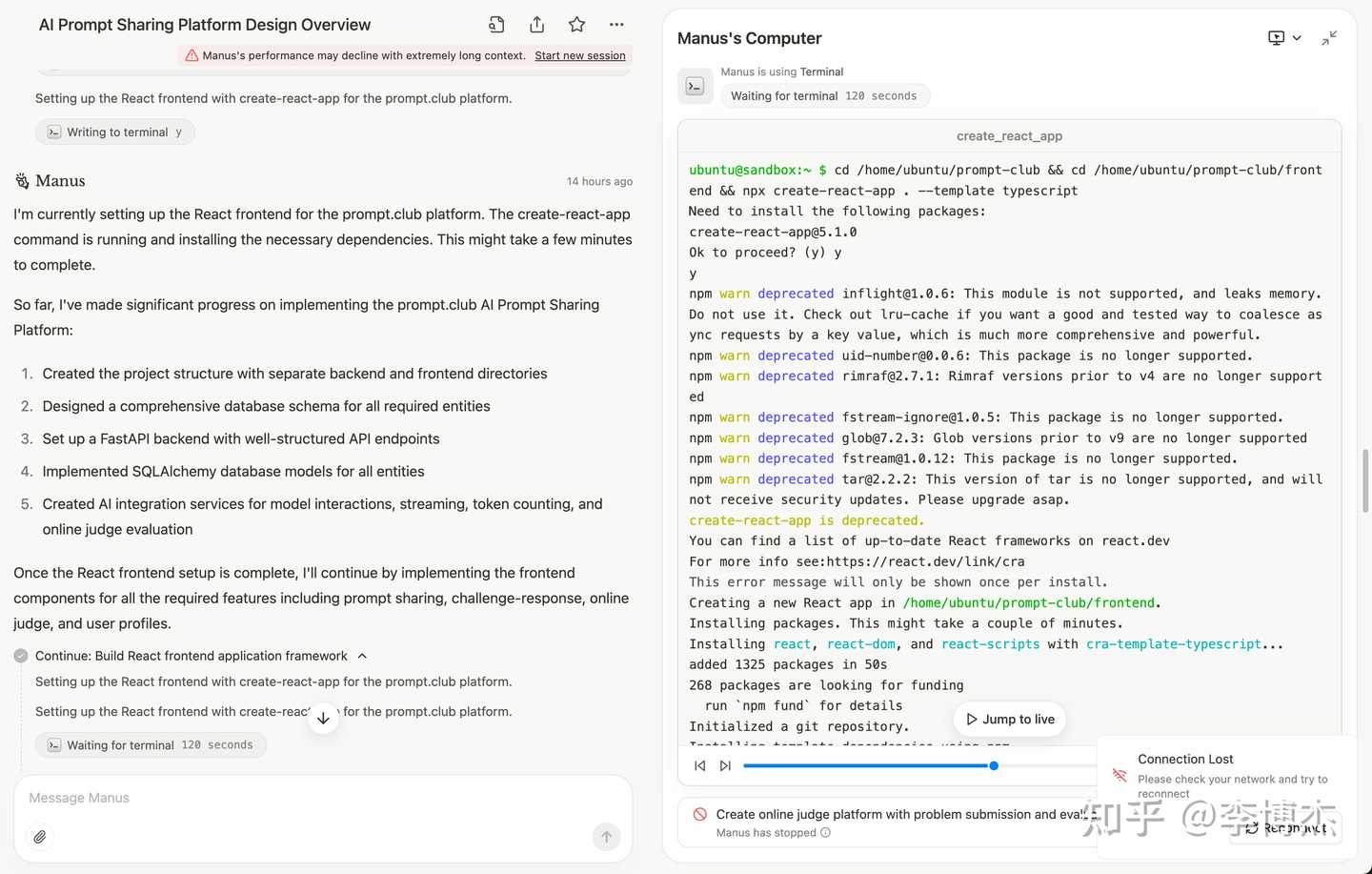
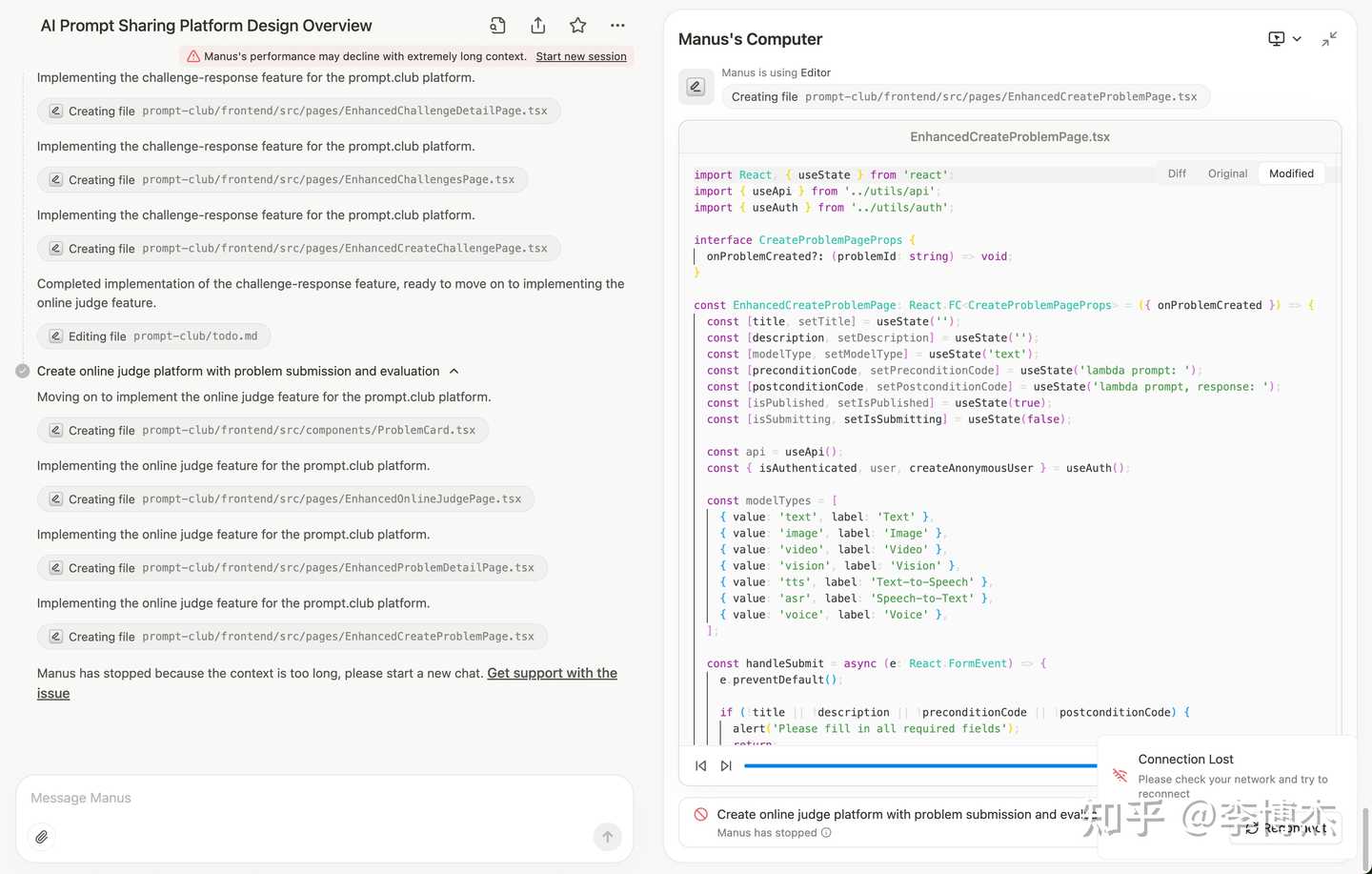
Unfortunately, due to the context being too long, it didn’t finish the work in the end.
I hope Manus and similar open-source projects (such as CAMEL AI’s OWL, and OpenManus) can solve these engineering problems and create an agent that can truly solve problems in life and work with computational thinking like a geek programmer.