Three Sources of Trust in Web3: From Trusting People to Trusting Math, Community, and Economics
The two biggest advantages of Web3 are tokenomics and trust. Tokenomics addresses the issue of profit distribution. This article mainly discusses the issue of trust.
The essence of traditional Web2 trust is trust in people. I dare to store my data with Apple and Google because I believe they won’t sell my data. I dare to anonymously complain about my company on platforms like Maimai because I trust they won’t leak my identity. But obviously, in the face of profit, people are not always trustworthy.
How can Web3 better solve the trust issue? I believe that Web3’s trust comes from three main sources: Cryptographic Trust, Decentralized Trust, and Economic Trust.
The essence of cryptographic trust is trusting math, the essence of decentralized trust is trusting that the majority won’t collude to do evil, and the essence of economic trust is trusting that the majority won’t engage in unprofitable trades. Therefore, these three types of trust decrease in reliability.
So why not just use cryptographic trust? Because many problems cannot be solved by cryptographic trust alone. Although these three types of trust decrease in reliability, their application scope increases.
Next, we will introduce these three types of trust one by one.
Cryptographic Trust
- How can I prove my identity without revealing who I am? For example, Maimai needs to verify that I am a member of a certain company, but I don’t want to reveal my exact identity to Maimai. Is this possible?
- How can online games with randomness ensure fairness? For example, how can a Texas Hold’em platform prove that its dealing is absolutely fair and that the dealer is not secretly looking at the cards?
Many friends might think that we can only rely on a trusted third party, which is certainly a feasible solution. But with the help of cryptography, cryptographic trust without relying on a third party is possible.
Verification Without Revealing Information
For example, if a website wants to verify that a user has an email from a certain organization but doesn’t want to know the user’s exact email address, it can use the ZK Email method.
We know that emails have DKIM signatures, so providing the DKIM signature of any received email can prove that I own the recipient’s email address. But directly providing the DKIM signature and email content would still reveal the specific email address, so we need to use the ZK (Zero-Knowledge Proof) method to generate a zero-knowledge proof based on this DKIM signature.
Zero-Knowledge Proof, as the name suggests, is proving that I know a piece of information without revealing it. Its essence is to make the algorithm for verifying the DKIM signature and verifying that the email recipient belongs to a certain organization into an obfuscated circuit, then input the encrypted email content and DKIM signature into this obfuscated circuit, which can output the verification result (yes or no). The website gets this zero-knowledge proof and knows that the person holds an email address from this organization but doesn’t know which email address it is.
A few years ago, zero-knowledge proofs were just toys for academia and a few geeks, but now they are widely used. This year, leading companies in the zero-knowledge proof field, Polyhedra and zkSync, went public, each with a market value exceeding $1 billion.
In fact, zero-knowledge proofs have many applications in daily life. For example, when posting on social media, how can I prove that I attended USTC without mentioning its name? I can mention a joke that only USTC people know, like “废理兴工” or “三十,校友,一样”. This is like a secret code. Of course, this method is not mathematically rigorous, but mathematical zero-knowledge proofs can achieve this without leaking any information.
Ensuring Fairness
Another scenario for cryptographic trust is ensuring the fairness of algorithms.
For example, in running an online game, how can I ensure that my shuffling is fair, not favoring any player (fair shuffling problem), and not secretly revealing other players’ cards to a specific player (hidden dealing problem)?
Multi-party computation and zero-knowledge proofs can solve these two problems. First, each player generates a pair of public and private keys. During shuffling, each player encrypts the initial state with their private key, which is like putting three locks on a box. Using homomorphic encryption, calculations can be performed in the encrypted state to complete random shuffling, like shaking the locked box to shuffle the cards inside. During dealing, each player decrypts their cards in order using their private key and publishes a zero-knowledge proof to confirm they have seen their cards (to prevent denial later).
Since the order of unlocking is fixed, each player can only decrypt their cards and cannot see other players’ cards. The platform performs calculations in the encrypted state and cannot see anyone’s cards, and each player can verify that the shuffling process is fair.
More Efficient TEE
The biggest drawback of cryptographic zero-knowledge proofs and multi-party computation is low execution efficiency. Code that originally takes one second to execute might take an hour using zero-knowledge proofs. The overhead of fair dealing algorithms based on zero-knowledge proofs is even higher; if the dealing algorithm is slightly complex or involves more participants (more than 10 people), the complexity increases rapidly.
Another type of trusted computing technology, TEE (Trusted Execution Environment), can compensate for the inefficiency of zero-knowledge proofs. TEE shifts trust from math to hardware manufacturers, such as Intel, AMD, and NVIDIA. Early TEEs often had vulnerabilities, leading to distrust, but today’s TEE technology has significantly improved and no longer has those basic vulnerabilities.
TEE can achieve two purposes: first, to prevent those with physical access to the server from stealing secrets, such as cloud service providers and data centers; second, to prove that the code being executed is indeed the original code without tampering.
For example, in the online game mentioned earlier, TEE can generate a signature to prove that the hardware is executing the unaltered dealing algorithm. If others don’t believe it, they can run the same code in the same hardware environment, and if the TEE-generated signatures match, it proves that the initial state of the hardware is consistent and the same code is being run.
Privacy Computing: Web3 is Hotter than the Real World
Around 2019, privacy computing, with cryptographic trust and TEE as core technologies, experienced a wave of popularity. The most common application case for privacy computing companies is data processing cooperation between data owners and technology providers without transmitting plaintext data to each other.
For example, a hospital wants to use AI algorithms for diagnosis assistance but doesn’t want to hand over patient data to the AI company, and the AI company doesn’t want to give its algorithms to the hospital. Using privacy computing methods, both parties can complete AI-assisted diagnosis without leaking their respective secrets.
However, the application scenarios of privacy computing in the real world have always been limited. Many companies prefer to trust people rather than technology. They argue that any algorithm has vulnerabilities in its system implementation, and if people are untrustworthy, inserting backdoors into privacy computing systems is also hard to detect. Additionally, many companies’ privacy protection is just for legal compliance and public image, and they may not be willing to invest real money in multi-party computation technology.
Privacy computing technology was originally born to solve trust issues in the real world, but it has found more applications in the digital world of Web3. Today, most of the hottest Web3 companies’ core technologies are privacy computing. Web3 has even become the preferred employment destination for cryptography PhDs. This is probably because the Web3 world values anonymity and privacy more and believes in code rather than human nature.
Decentralized Trust
Cryptographic trust can solve verification problems but cannot solve denial problems. For example, if I play a game and clear a level, obtaining an item, and then find the item missing after sleeping, how can I argue with the game company and prove that I once obtained the item? In reality, such denial problems often lead to endless disputes.
The solution to denial is information disclosure, allowing everyone to check the complete history. Combined with the zero-knowledge proof method mentioned above, it is possible to record one’s actions in history without exposing privacy.
Publishing information on a website is feasible, but how can we ensure that the website’s information won’t be tampered with? How can we ensure that the website won’t suddenly be 404 one day?
Distributed Ledger
The solution to this problem is a distributed ledger, which can build decentralized trust. The most famous example of a distributed ledger is Bitcoin. Subsequently, Ethereum and various Layer-2 and Layer-1 solutions emerged to address various issues of distributed ledgers, such as running smart contracts, high latency, and low throughput.
I did my PhD in systems, and many senior experts in systems often criticize blockchain. For example, some senior experts at Microsoft Research said that when Bitcoin first came out, they quickly saw the paper and said, “What a piece of junk, it takes 10 minutes to produce a block. No distributed system with a write operation latency of 10 minutes would ever be used by anyone.” Regarding the problems of distributed ledgers, Byzantine fault tolerance algorithms have been developed for many years, and Leslie Lamport, the proposer of the Byzantine problem and a Turing Award winner, is still at Microsoft Research. Which Byzantine fault tolerance algorithm is not more efficient than Bitcoin?
This argument ignores that Bitcoin’s greatest value lies in building decentralized trust. The Bitcoin blockchain is replicated by numerous nodes worldwide, and as long as the majority do not collude to do evil, the history recorded in the distributed ledger cannot be tampered with. Bitcoin also solved the economic motivation problem through Proof of Work (commonly known as mining). What motivates these nodes to record the entire distributed ledger and continuously synchronize the latest changes? Love alone is not sustainable in the long run; Proof of Work is its innovation.
Ethereum improved Bitcoin’s design and proposed the concept of the “world computer,” where smart contracts are general-purpose programs, and the entire world is a computer. Theoretically, charging for computing power with gas fees is a brilliant idea. But in practice, the performance of the Ethereum mainnet is still very limited, leading to high transaction and gas fees, making ordinary computing unaffordable.
In 2017, a group of PhD students in systems, including myself, criticized Ethereum’s white paper, mocking the inefficiency of the “world computer.” But the reality is that the inefficient Ethereum smart contracts solved the decentralized trust problem, and the price of Ethereum soared, while the high-performance systems we developed in academia, capable of handling billions of transactions per second and theoretically supporting 12306 on a single machine, went unnoticed.
Git: The Precursor to Blockchain Ideas
In fact, building decentralized trust through blockchain is far from exclusive to various tokens.
The version control tool Git, born in 2005, is likely a precursor to blockchain ideas. Git uses a chain of signatures to ensure that the history of code modifications is difficult to tamper with. In some public Git repositories, commits must be signed by the author or code reviewer. A malicious person cannot insert, delete, or modify a commit in the Git history while keeping the hashes and signatures of all subsequent commits unchanged.
Therefore, as long as you remember the hash of a commit, it means that the code modification history before it cannot be tampered with; or even if you do not remember the commit hash, as long as a commit has enough different people’s signatures on subsequent commits, the history before that commit is difficult to tamper with, because it would require collusion among all those who signed afterward to alter the history.
Little-Known Certificate Transparency Logs
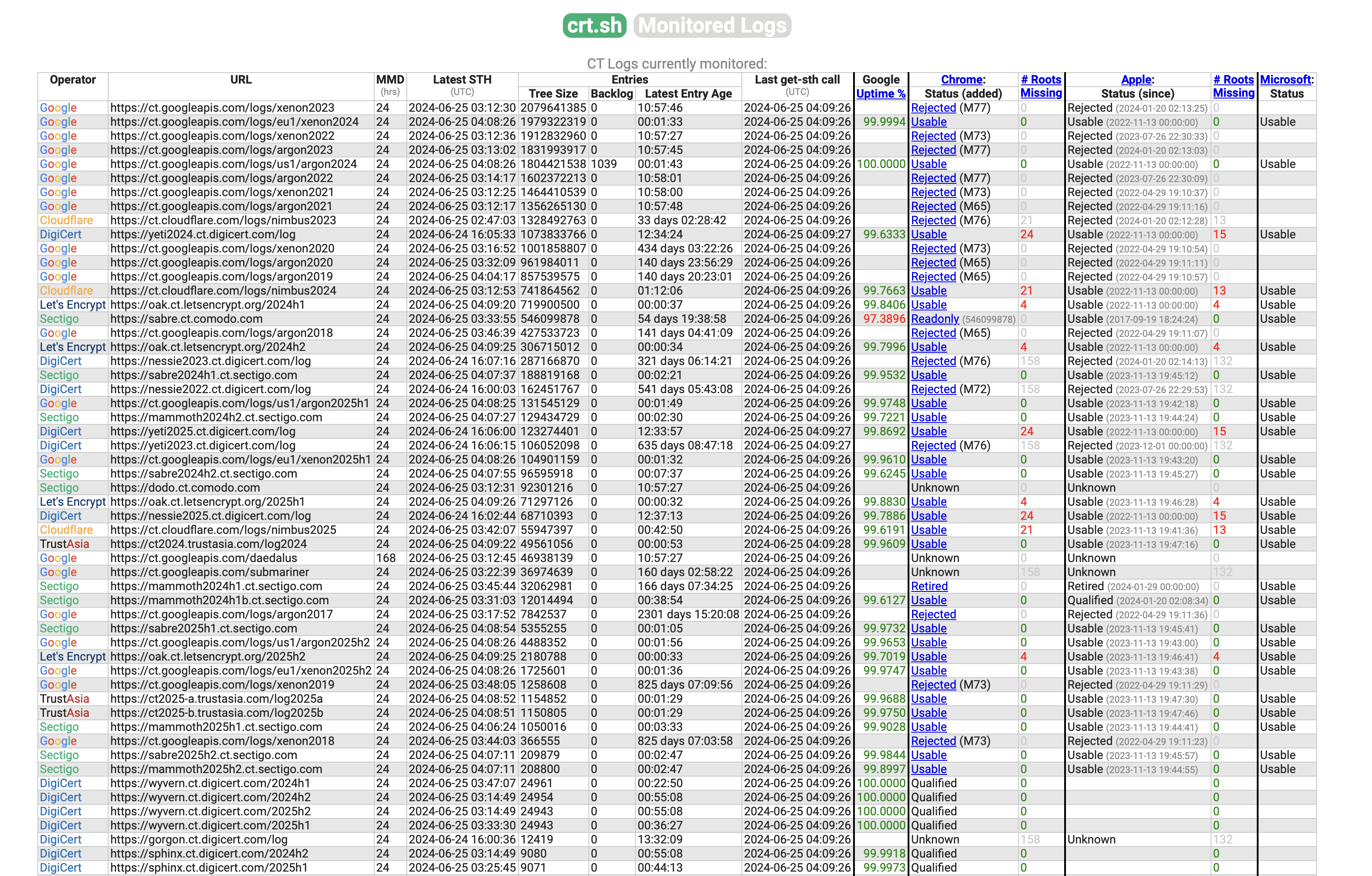
Certificate Transparency is a great example of building decentralized trust through blockchain. Although it does not claim to be a blockchain and only calls itself a log, it is almost a consortium chain.
Today, the vast majority of websites use TLS certificates to verify the identity of the website, and TLS certificates are issued by Certificate Authorities (CAs). So, if I control a CA or hack into a CA, can I issue certificates for any website and impersonate any website?
This kind of CA misconduct is not just theoretical but has happened in reality. Therefore, in 2013, Google initiated the Certificate Transparency mechanism, requiring all certificates issued by CAs to be recorded on an append-only chain. More and more companies later joined the Certificate Transparency logs, with each company becoming a verification node on this chain. This way, unless all companies collude, it is impossible to tamper with already issued certificates.
So how does a browser verify if a certificate is valid? When a certificate is added to the chain, the verification nodes sign the certificate and attach it to the certificate, which means that besides the CA, at least two other companies’ verification nodes have stamped the certificate. The browser not only needs to verify the validity of the CA’s signature but also the signatures of the Certificate Transparency nodes. The probability of three companies colluding is very low.
 Certificate Transparency Logs
Certificate Transparency Logs
Since 2013, Certificate Transparency logs have recorded over 8.4 billion certificates. In comparison, the Bitcoin blockchain has just surpassed 1 billion transactions, and the Ethereum mainnet has only 2.3 billion transactions. Currently, Certificate Transparency logs add hundreds of certificates every second, far exceeding the transaction count of Bitcoin and Ethereum mainnet (dozens of transactions per second). Of course, high-performance Layer-1s like Solana can reach over 3000 transactions per second, but Solana is centralized.
Certificate Transparency is also a transparent scheme for Google to collect information worldwide. Some internal websites accessible to the public but requiring employee login can also be found on Google’s homepage, although their content is empty. These pages are unlikely to have links on the public internet, so how does Google index them? One information source could be the Certificate Transparency logs. As soon as a website applies for a TLS certificate, it is immediately recorded, and Google’s crawler can discover the webpage.
Since Certificate Transparency logs are public, I have also used them to discover many companies’ unreleased products. For example, OpenAI’s Sora went live at sora.openai.com two days before its release, and GPT-4o went live at webrtc.chatgpt.com a month before its release, which anyone knowledgeable would recognize as being used for real-time voice chat. This doesn’t even require syncing a Certificate Transparency log yourself; crt.sh provides public queries.
When I interview candidates at Huawei, I often ask about TLS. Many network engineers can roughly explain how the TLS protocol works. But when it comes to the PKI mechanism, few know much about it. None of the candidates I interviewed had heard of Certificate Transparency. Indeed, many critical Internet infrastructures are unknown to most programmers.
Information That Never Gets Lost
If I want to make some information permanently public and ensure it won’t be lost for 300 years, what should I do?
I wrote such a Zhihu answer, excerpted below.
GitHub Archive Program
The simplest: GitHub Archive Program. Any repo with at least one commit or one star between November 2019 and February 2020, or at least 250 stars, will enter the GitHub Archive Program, be etched onto reinforced film, and stored in the Arctic World Archive in Norway, capable of lasting at least a thousand years.
Print as a Book, Etch on Stone
Next simplest: Print as a book. First, export it as a PDF, then find a book printing service on Taobao. If well-preserved, a book can last 300 years.
(Etching on stone is more durable than printing in a book, lasting thousands of years, but I don’t want to erect a monument for myself yet.)
(I also saved it on a CD, but CDs don’t last 300 years. Magnetic tape is a good backup medium, but its lifespan generally doesn’t reach 300 years either.)
Store on a Public Blockchain
Now it gets harder: Store the information on a public blockchain like Ethereum, which requires some gas fees. But I believe that public blockchains like Ethereum will still exist 300 years from now. Although this storage method is costly, as it essentially makes all participating nodes store a copy for you, it allows for easy retrieval compared to printing a book or etching on stone.
Steganography in Papers
Even harder: Steganography in your published papers. IEEE and ACM paper databases are likely to be well-preserved 300 years from now and can be accessed anytime. A published paper can range from 1 MB to 10 MB, enough to store a lot of “irrelevant information.” Whether using PDF annotation features to embed information directly or steganography in the frequency domain of paper images, you can hide data in your published papers. The more classic the paper, the lower the probability of losing the information.
Store in Large Models
Even harder: Store in large models. Large models’ training data comes from the public internet. If the information you want to preserve is already widely available on the public internet, the large model likely has learned it. But if you want to preserve your private diary, which is not on the public internet, you need to write some Wikipedia entries. Wikipedia has a high weight in various large model training data.
Of course, this means trading the public nature of the information for its long-term preservation. If you don’t want to make it public, you can rewrite the diary in code.
300 years from now, whether the world is run by humans or AI, large models will be an indispensable part of the world. Information from the first-generation large models will not be easily discarded.
Wander in Interstellar Radio Waves
Top difficulty: Store in interstellar radio waves. We network engineers have a trick: when network endpoints can’t store data (e.g., temporary congestion), let the data circulate in the network. Just like planes circling near an airport when the runway is busy. Radio waves propagating in the air can also be a medium for storing information, but extracting the information is extremely difficult, beyond the current technological limits of humanity.
Ethereum Blockchain is the Simplest and Most Practical Solution
Among these solutions, the Ethereum blockchain is the simplest and most practical.
My friend made an Ethernote, where you can write a diary by connecting your wallet. Ethernote stores the diary data in the CallData of smart contracts. Since the internal data of smart contracts is unreadable, the storage cost is low, requiring only 16 gwei of gas fee per byte (or 512 gwei per 32 bytes). At today’s Ethereum price, 20K bytes cost only $1.
 Ethernote Interface
Ethernote Interface
Ethernote doesn’t need a database; as long as there is a JSON RPC URL of a full archive node of Ethereum, it can query and decode the content recorded in these smart contracts. Of course, the query efficiency is not as high as a database. Therefore, commercial projects generally have a database to serve user web API requests and synchronize with the blockchain to ensure data is not lost and cannot be tampered with.
Economic Trust
When cryptographic trust and decentralized trust cannot solve the problem, economic trust should come into play. Economic trust essentially punishes malicious behavior, usually through staking/slashing mechanisms.
Staking means pledging some tokens to a smart contract. Slashing means that when malicious behavior is detected, the community votes or an algorithm determines, and the smart contract automatically confiscates the pledged tokens, implementing economic punishment.
Without a slashing mechanism, participants’ motivation to act honestly relies solely on token toxicity. Token toxicity means that if a protocol is successfully attacked, the value of its tokens will significantly decrease, causing the participants’ pledged assets to lose value. Token toxicity is not a good economic trust mechanism because the devaluation of tokens punishes both good and bad nodes equally. Considering that bad nodes might have been bribed, it could lead to bad nodes driving out good nodes.
Algorithmic Detection of Malicious Behavior
The most classic staking/slashing protocol is Ethereum’s PoS (Proof of Stake) mechanism. In Ethereum PoS, validators receive rewards when they vote in line with the majority of other validators, propose blocks, and participate in the sync committee. If a validator acts slowly and does not participate in voting in time, they will not receive the block reward in time.
Slashing targets validators with obvious malicious behavior. For example, proposing or signing two different blocks in the same slot; attempting to create a new block that surrounds other blocks to alter history; or “double voting” by proving two candidates for the same block. If these behaviors are detected, the validator will be slashed. 1/32 of the stake will be immediately destroyed, and the validator’s stake will gradually be drained over a 36-day removal period.
In Ethereum’s slashing mechanism, since malicious behavior is easily detected by algorithms, since PoS was officially launched in 2020, slashed validators account for less than one-thousandth of the total validators. Although economic trust cannot eliminate malicious behavior, it can minimize it through punishment.
The slashing mechanism can significantly increase the cost of attempting bribery attacks. In the Ethereum protocol, the bribery cost must reach one-third of the total staked amount of all validators to succeed in an attack.
Voting to Determine Malicious Behavior
In some systems involving human behavior, algorithms alone cannot determine malicious behavior. For example, in a blockchain game, it is difficult for an algorithm to determine if two players are colluding privately.
In such cases, the community needs to report malicious behavior and determine it through voting. To prevent Sybil attacks (attacks involving the creation of numerous anonymous accounts to participate in voting), the voting share is generally proportional to the amount staked. This essentially means that those with more money have more say. Since those who hold a large amount of a token generally do not want its price to drop, they are more inclined to maintain community fairness.
Of course, simply basing voting power on the amount staked can lead to malicious users buying and staking a large number of tokens to gain voting rights, conducting malicious voting, and then immediately unstaking and selling the tokens. This would severely impact the community voting ecosystem. Therefore, many communities use the product of the number of staked tokens and the staking duration as voting power. This encourages users who wish to participate in community governance to stake tokens for the long term, which not only reduces selling pressure and stabilizes the token price but also prevents short-term staking attacks.
Staking-Based Transactions
Platforms like Taobao and various intermediaries are essentially based on staking transactions. The reason both parties dare to trade on the platform is due to their trust in the platform. Of course, both parties also need to pay commissions or intermediary fees for this trust.
If the entire transaction process can be traced on the blockchain, then intermediary platforms can be replaced by smart contracts. Smart contracts can mathematically guarantee fairness, and both parties only need to pay a small transaction fee, no longer needing to trust the platform. Currently, this method is mainly limited to consortium blockchains with a certain level of trust foundation in the real world. The main reason is that most real-world transaction processes are not traceable on the blockchain.
The interface between the real world and the blockchain world is always the weakest link, just as humans are always the most vulnerable link in any network. When absolute trust cannot be achieved, this is where economic trust comes into play. As long as the cost of breaking trust is far higher than the potential gains from attacking it, the probability of an attack occurring will be greatly reduced.
Conclusion
Before the advent of Web3, if humans were completely untrustworthy, it would be easy to fall into a prisoner’s dilemma. Web3 has been anonymous since its inception, making it a dark forest where hunters with guns are everywhere.
The reason Web3 has not fallen into a prisoner’s dilemma is that Web3 shifts trust from individuals and companies to mathematics, the belief that most people will not act maliciously simultaneously, and economic interests through three major mechanisms: cryptographic trust, decentralized trust, and economic trust.
In “The Three-Body Problem,” the dark forest hypothesis is based on two fundamental axioms and two basic assumptions: the chain of suspicion and technological explosion. The fundamental axioms are: (1) Survival is the primary need of civilization, and (2) Civilizations continuously grow and expand, but the total amount of matter in the universe remains constant. The chain of suspicion assumes that both parties cannot determine whether the other is a benevolent civilization. The technological explosion assumes that the speed and acceleration of civilization’s progress are not necessarily consistent, and a weaker civilization may surpass a stronger one in a short time. Under these four basic assumptions, not exposing oneself is the best choice.
However, in the Web3 world, the second fundamental axiom, the chain of suspicion, and the technological explosion do not hold. A token is valuable because of community consensus, which is the same as all currencies and equivalents. The more people participate in a protocol, the higher the total value of that protocol. Therefore, this is not a zero-sum game, and the second fundamental axiom does not hold. Cryptographic trust, decentralized trust, and economic trust all address the chain of suspicion from different angles. The technological explosion does not exist in the real world; if someone mastered the algorithm to break elliptic curves, the entire blockchain trust foundation would collapse. Therefore, the Web3 world not only avoids the trust crisis seen in “The Three-Body Problem” but also operates more efficiently than the traditional economy of the Web2 world.
Since most of the public does not understand mathematics, and protocol design and code implementation are prone to vulnerabilities, Web3 trust is still largely a game within the geek community and has not been widely accepted by the general public. Even some Web3 industry practitioners cannot clearly explain the differences between these three types of trust. Some even say that trustless is a regression of human civilization.
One of Huawei’s management essences is “management based on distrust.” When I first heard this, I was quite repulsed. How can a company not trust its employees? A business mogul also said that when he first started his business, he always thought too highly of human nature and did not perfect the process system from the beginning, resulting in many problems after the business grew. He felt enlightened after hearing Ren Zhengfei’s talk on management based on distrust. Google has also been promoting the Zero Trust security model. Zero Trust is, in fact, an important concept in Western management systems, with the key being to make the operation of the enterprise independent of people through process management.
The three major characteristics of Web3 are trustless, permissionless, and decentralized. Trustless does not mean the literal absence of trust but rather the evolution from trusting people to trusting mathematics, the community, and economics. The evolution of trust will undoubtedly become an important milestone in human civilization.