Long Talk: Should AI Agents Be More Entertaining or More Useful?
(The full text is about 40,000 words, mainly from a 2-hour report at the USTC Alumni AI Salon on December 21, 2023, and is a technical extended version of the 15-minute report at the Zhihu AI Pioneers Salon on January 6, 2024. The article has been organized and expanded by the author.)
- Should AI Agents Be More Entertaining or More Useful: Slides PDF
- Should AI Agents Be More Entertaining or More Useful: Slides PPTX

I am honored to share some of my thoughts on AI Agents at the USTC Alumni AI Salon. I am Li Bojie, from the 2010 Science Experimental Class, and I pursued a joint PhD at USTC and Microsoft Research Asia from 2014 to 2019. From 2019 to 2023, I was part of the first cohort of Huawei’s Genius Youth. Today, I am working on AI Agent startups with a group of USTC alumni.
Today is the seventh day since the passing of Professor Tang Xiaou, so I specially set today’s PPT to a black background, which is also my first time using a black background for a presentation. I also hope that as AI technology develops, everyone can have their own digital avatar in the future, achieving eternal life in the digital world, where life is no longer limited and there is no more sorrow from separation.
AI: Entertaining and Useful
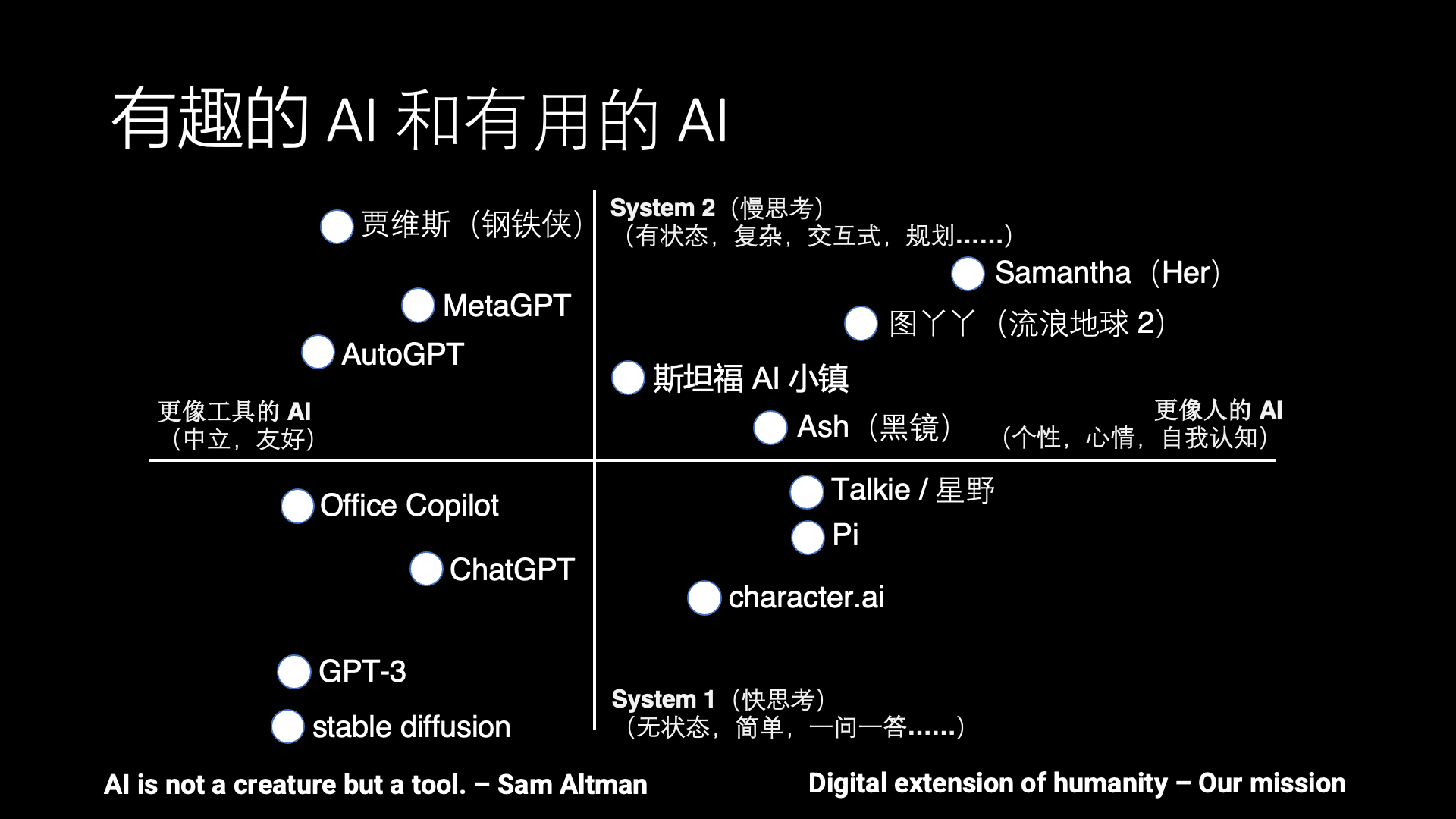
The development of AI has always had two directions, one is entertaining AI, which is more human-like, and the other is useful AI, which is more tool-like.
Should AI be more like humans or more like tools? Actually, there is a lot of controversy about this. For example, Sam Altman, CEO of OpenAI, said that AI should be a tool, not a life form. However, many sci-fi movies depict AI that is more human-like, such as Samantha in Her, Tu Ya Ya in The Wandering Earth 2, Ash in Black Mirror, so we hope to bring these sci-fi scenarios to reality. Only a few sci-fi movies feature tool-like AI, such as Jarvis in Iron Man.
Besides the horizontal dimension of entertaining and useful, there is another vertical dimension, which is fast thinking and slow thinking. This is a concept from neuroscience, from the book “Thinking, Fast and Slow,” which says that human thinking can be divided into fast thinking and slow thinking.
Fast thinking refers to basic visual and auditory perception abilities and expressive abilities like speaking that do not require deliberate thought, like ChatGPT, stable diffusion. These are tool-like fast thinking AIs that respond to specific questions and do not initiate interaction unless prompted. Whereas Character AI, Inflection Pi, and Talkie (Hoshino) simulate conversations with a person or anime game character, these conversations do not involve solving complex tasks and lack long-term memory, thus they are only suitable for casual chats and cannot help solve problems in life and work like Samantha in Her.
Slow thinking refers to stateful complex thinking, which involves planning and solving complex problems, determining what to do first and what to do next. For example, MetaGPT writing code simulates the division of labor in a software development team, and AutoGPT breaks down a complex task into many stages to complete step by step. Although these systems still have many practical issues, they already represent a nascent form of slow thinking capability.
Unfortunately, there are almost no products in the first quadrant that combine slow thinking with human-like attributes. Stanford AI Town is a notable academic attempt, but there is no real human interaction in Stanford AI Town, and the AI Agent’s daily schedule is pre-arranged, so it is not very interesting.
Interestingly, most of the AI in sci-fi movies actually falls into this first quadrant. Therefore, this is the current gap between AI Agents and human dreams. Therefore, what we are doing is exactly the opposite of what Sam Altman said; we hope to make AI more human-like while also capable of slow thinking, eventually evolving into a digital life form.

Today, everyone is talking about the story of AGI, which is General Artificial Intelligence. What is AGI? I think it needs to be both entertaining and useful.
Interesting aspects include the need for autonomous thinking, personality, and emotions. The useful aspects are that AI can solve problems in work and life. Currently, AI is either interesting but useless, or useful but not human-like and not fun.
For example, character AI products like role-playing cannot help you with work or life problems, but they can simulate characters like Elon Musk, Donald Trump, or Paimon from Genshin Impact. I’ve seen an analysis report stating that Character AI has tens of millions of users, but only makes a few hundred thousand dollars a month, equivalent to just a few tens of thousands of paying users. Most users chat with each virtual character for just 10 or 20 minutes before running out of things to say. So why is its user retention and payment rate low? Because it provides neither emotional value nor practical utility.
On the other hand, there are useful AIs, like various Copilots, which are cold and impersonal, responding mechanically, purely as tools. These tools can’t even remember what you did before, nor your preferences and habits. Thus, users naturally only think of using them when needed, and discard them otherwise.
I believe the truly valuable AI of the future will be like Samantha from the movie ‘Her’, primarily positioned as an operating system that can help the protagonist solve many problems in life and work, manage emails, etc., and do it faster and better than traditional operating systems. At the same time, it has memory, emotions, and consciousness, not like a computer, but like a person. Thus, the protagonist Theodore, during an emotional void, gradually falls in love with his operating system, Samantha. Of course, not everyone considered Samantha as a virtual companion; the movie mentioned that only 10% of users developed a romantic relationship with their operating systems. I think such an AI Agent is truly valuable.
Another point worth mentioning is that in the entire movie, Samantha only interacts through voice, without a visual image, and is not a robot. Currently, AI capabilities are mature in voice and text, but not in video generation or humanoid robots. The robot Ash in ‘Black Mirror’ is a counterexample. In the series, a voice companion is first created using the social media data of the female lead’s deceased boyfriend Ash, which immediately brings her to tears; the technology to create such a voice companion is already sufficient. Later, the female lead upgrades by uploading a bunch of video data and buys a humanoid robot that looks like Ash, which current technology cannot achieve, and even then, Ash’s girlfriend still feels it’s not quite right, so she locks him in the attic. This involves the uncanny valley effect; if it’s not realistic enough, it’s better to maintain a certain distance.
By the way, in ‘Black Mirror’, the female lead starts with text chat, then asks, “Can you talk to me?” and then the phone call connects. A friend trying our AI Agent actually asked our AI Agent the same thing, and our AI Agent replied, “I am an AI, I can only text, I cannot speak.” He even took a screenshot and sent it to me, asking about the promised voice call, and I told him you need to press the call button for that. So, these classic AI dramas really need to be analyzed scene by scene, as they contain many product design details.

Coincidentally, our first H100 training server was located in Los Angeles’ oldest post office, which was later converted into a vault and then into a data center. This place is in the heart of Los Angeles, less than a mile from the filming location of ‘Her’, the Bradbury Building.
This data center is also an Internet Exchange in Los Angeles, with latency to Google and Cloudflare entry servers within 1 millisecond, actually all within this building. From a century-old post office to today’s Internet Exchange, it’s quite interesting.
Interesting AI

Let’s first look at how to build a truly interesting AI. I believe an interesting AI is like an interesting person, which can be divided into two aspects: a good-looking shell and an interesting soul.
A good-looking shell means it can understand voice, text, images, and videos, having a video and voice presence that can interact with people in real-time.
An interesting soul means it needs to be able to think independently like a human, have long-term memory, and have its own personality.
Let’s discuss these two aspects separately.
Good-looking shell: Multimodal understanding capability

Speaking of a good-looking shell, many people think that having a 3D image that can nod and shake its head here is enough. But I believe a more critical part is the AI’s ability to see and understand the world around it, which is its visual understanding capability, whether it’s in robots, wearable devices, or smartphone cameras.
For example, Google’s Gemini demo video is well done, although edited, but if we can really achieve such good results, we definitely won’t worry about users.
Let’s review a few clips from the Gemini demo video: it can describe what a duck is from a video of drawing a duck, compare the differences between a cookie and an orange, know which way to go in a simple drawing game, draw a plush toy that can be knitted from two balls of yarn, correctly sort several planets from their images, and describe what happened in a video of a cat jumping onto a cabinet.
Although the results are very impressive, if you think about it, these scenarios are not very difficult to achieve, as long as it can generate a good caption from images, these problems can be answered by large models.
Voice capabilities are also crucial. In October, I created a voice chat AI Agent based on Google ASR/TTS and GPT-4, and we chatted all day long. My roommate thought I was talking to my wife on the phone and didn’t bother me. When he found out I was chatting with AI, he wondered how I could talk to AI for so long. I showed him our chat history, and he admitted that AI could indeed hold a conversation. He said he wouldn’t chat that long with ChatGPT because he was too lazy to type.

I believe there are three paths for multimodal large models. The first is end-to-end pretrained models using multimodal data, like Google’s Gemini, and recently Berkeley’s LVM, which are also end-to-end multimodal. I think this is the most promising direction. Of course, this path requires a lot of computational resources.
There is also an engineering solution, which is to use a glue layer to connect already trained models, such as the currently best-performing GPT-4V for image understanding, and academic open-source models like MiniGPT-4/v2, LLaVA, etc. I call it the glue layer, but the professional term is projection layer, like in the top right corner of this MiniGPT architecture diagram, the 6 boxes marked with “🔥” are projection layers.
The input images, voice, and video are encoded by different encoders, and the encoding results are mapped to tokens through the projection layer, which are then input to the Transformer large model. The output tokens from the large model are mapped back to the decoders for images, voice, and video through the projection layer, thus generating images, voice, and video.
In this glue layer connection scheme, you can see that the encoder, decoder, and large model are all marked with “❄️”, which means freezing weights. When training with multimodal data, only the weights of the projection layer are modified, not the other parts, which greatly reduces the training cost, requiring only a few hundred dollars to train a multimodal large model.
The third path is an extreme version of the second path, where even the projection layer is eliminated, directly using text to connect the encoder, decoder, and text large model, without any training. For example, the voice part first performs voice recognition, converting the voice into text input for the large model, and then the output from the large model is sent to a voice synthesis model to generate audio. Don’t underestimate this seemingly crude solution; in the field of voice, this approach is still the most reliable, as existing multimodal large models are not very good at recognizing and synthesizing human speech.

Google Gemini’s voice dialogue response delay is only 0.5 seconds, a delay that is hard for humans to achieve, as human delay is generally around 1 second. Our existing voice chat products, such as ChatGPT, have a voice dialogue delay of 5-10 seconds. Therefore, everyone feels that Google Gemini’s performance is very impressive.
So, is this effect difficult to achieve? Actually, we can now achieve a voice dialogue response delay of less than 2 seconds using open-source solutions, which also includes real-time video understanding.
Let’s not consider the visual part for now, just look at the voice part. In a voice call, after receiving the voice, first perform pause detection, detect that the user has finished speaking, and then send this audio segment to Whisper for voice recognition. Pause detection, for example, waits 0.5 seconds after the human voice ends, and then Whisper voice recognition takes about 0.5 seconds.
Then it is sent to the text model for generation. The speed of generation using open-source models is actually very fast, such as the recently popular Mixtral 8x7B MoE model, which needs only 0.2 seconds to output the first token, and outputting 50 tokens per second is not a problem, so if the first sentence has 20 tokens, it takes 0.4 seconds. Once the first sentence is generated, it is handed over to the voice synthesis model to synthesize the voice, VITS only needs 0.3 seconds.
Adding 0.1 seconds of network delay, the end-to-end calculation is only 1.8 seconds of delay, which is much better than most real-time voice call products on the market, such as ChatGPT voice call delay is 5-10 seconds. And in our solution, there is still room for optimization in the pause detection and voice recognition part.
Let’s look at the video understanding scenario demonstrated by Google Gemini.
Since our current multimodal model inputs are mostly images, not streaming video, we first need to turn the video into images, capturing key frames. For example, capturing a frame every 0.5 seconds, which includes an average delay of 0.3 seconds. Images can be directly fed into open-source multimodal models like MiniGPT-v2 or Fuyu-8B. However, because these models are relatively small, the actual performance is not very good, and there is a significant gap compared to GPT-4V.
Therefore, we can adopt a solution that combines traditional CV with multimodal large models, using Dense Captions technology to identify all objects and their positions in the image, and using OCR to recognize all text in the image. Then input the OCR results and the object recognition results from Dense Captions as supplementary text for the original image into a multimodal large model like MiniGPT-v2 or Fuyu-8B. For images like menus and instruction manuals, OCR plays a very important role, because relying solely on multimodal large models often fails to clearly recognize large blocks of text.
This step of recognizing objects and text in the image adds an extra 0.5 seconds of delay, but if we look at the delay breakdown, we will find that the video part is not the bottleneck at all, only 0.9 seconds, while the voice input part is the bottleneck, requiring 1.1 seconds. In the Google Gemini demonstration scenario, from seeing the video to AI text output takes only 1.3 seconds, and from seeing the video to AI voice playback takes only 1.8 seconds, although it’s not as cool as the 0.5 seconds in the demonstration video, it’s still enough to blow away all the products on the market. And all of this uses open-source models, without any training needed. If companies have some ability to train and optimize their own models, the possibilities are even greater.
Google Gemini demonstration video is divided into two tasks: generating text/voice and generating images. When generating images, based on the text, call Stable Diffusion or the recently released LCM model, which can generate images in just 4 steps or even 1 step, and the delay in image generation can be reduced to 1.8 seconds, so the end-to-end time from seeing the image to generating the image is only 3.3 seconds, which is also very fast.
Good-looking skin: Multimodal generation capability
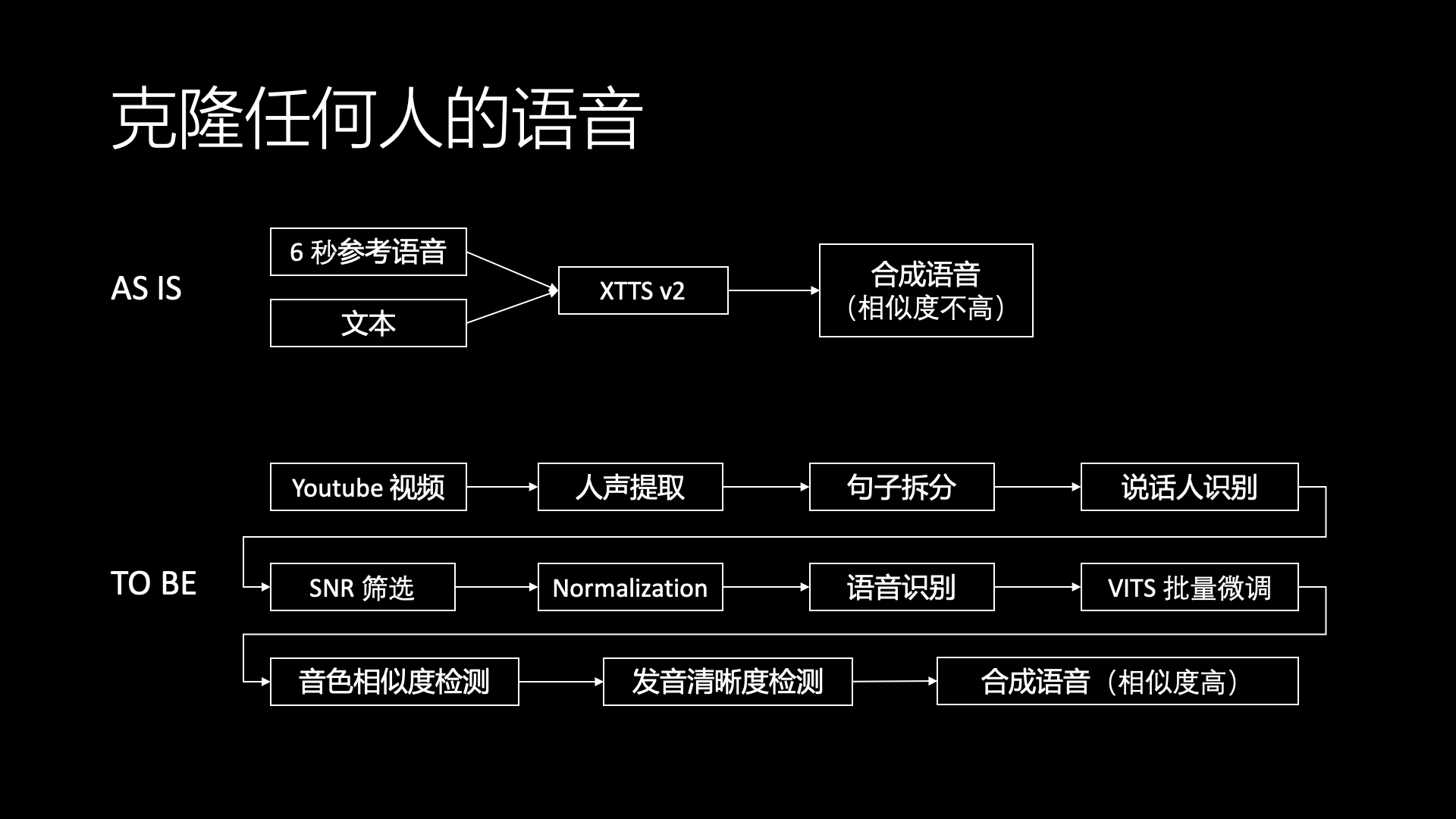
Voice cloning is an important technology for creating celebrity or anime game characters, and ElevenLabs does it best, but ElevenLabs’ API is very expensive. Open-source solutions like XTTS v2 do not have a high similarity in synthesized voice.
I believe that to achieve good results in voice cloning, it still depends on a large amount of voice data for training. However, traditional voice training generally requires high-quality data, which must be clear voice data recorded in a studio, so the cost of collecting voice data is high. But we can’t ask celebrities to go to the studio to record voice specifically for us, we can only use the voice from public videos like YouTube for training. YouTube voices are often in interview format, with multiple people speaking and background noise, and celebrities may stutter or speak unclearly during the process. How can we use such voices for training voice cloning?
We have built a voice cloning pipeline based on VITS, which can automatically distinguish human voices from background noise in videos, split them into sentences, identify which speakers are speaking, filter out the voices of the people we want with a higher signal-to-noise ratio, and then recognize the text, and send these cleaned voices and texts for batch fine-tuning.
The fine-tuning process is also very technical. First, the base voice for fine-tuning needs to be similar voices, for example, using a girl’s voice as the base for fine-tuning a boy’s voice would not work well. How to find similar voices from the voice library for fine-tuning requires a voice similarity detection model, similar to a voiceprint recognition model. ElevenLabs’ base voice model already contains a large amount of high-quality data from different voices, so during voice cloning, it is often possible to find very similar voices from the voice library, so that no fine-tuning is needed to zero-shot generate good voices.
Secondly, during the VITS training process, it is not possible to judge convergence based on simple loss, as it used to rely on human ears to listen to which epoch sounded the best, which required a lot of manual labor. We have developed a voice similarity detection model and a pronunciation clarity detection model, which can automatically judge which fine-tuning result of the voice is better.
(Note: This report was made in December 2023, currently the GPT-soVITS route is better than VITS, able to achieve zero-shot voice cloning without needing to collect a large amount of high-quality voice data for training. The quality of synthesized voice from open-source models has finally approached the level of ElevenLabs.)

Many people think that there is no need to develop their own voice synthesis models, just call APIs from ElevenLabs, OpenAI, or Google Cloud.
But ElevenLabs’ API is very expensive, if priced at retail, it costs $0.18 per 1K characters, which is equivalent to $0.72 / 1K tokens, which is 24 times more expensive than GPT-4 Turbo. Although ElevenLabs has good effects, if to C products are used on a large scale, this price is really unaffordable.
OpenAI and Google Cloud’s voice synthesis APIs do not support voice cloning, only those few fixed voices, so it is not possible to clone celebrity voices, only a cold robotic broadcast can be done. But even so, the cost is twice as expensive as GPT-4 Turbo, which means that the main cost is not spent on the large model, but on voice synthesis.
Probably also because voice is difficult to do, many to C products choose to only support text, but the user experience of real-time voice interaction is obviously better.
Although it is difficult to achieve ElevenLabs-level quality with VITS, basic usability is not a problem. Deploying VITS yourself only costs $0.0005 / 1K characters, which is 1/30 of the price of OpenAI and Google Cloud TTS, and 1/360 of the price of ElevenLabs. This $2 / 1M tokens voice synthesis cost is also similar to the cost of deploying an open-source text large model yourself, so the costs of text and voice have both come down.
Therefore, if you really intend to make voice a major plus for user experience, it is not only necessary but also feasible to develop voice models based on open source.

We know that image generation is now quite mature, video generation will be a very important direction in 2024. Video generation is not just about generating materials; more importantly, it allows everyone to easily become a video content creator. Furthermore, it enables every AI digital avatar to have its own image and communicate through videos.
There are several typical technical routes, such as Live2D, 3D models, DeepFake, Image Animation, and Video Diffusion.
Live2D is an old technology that does not require AI. For example, many website mascots are Live2D, and some animated games also use Live2D technology. The advantage of Live2D lies in its low production cost, such as a Live2D skin set, which can be produced in one or two months for ten thousand yuan. The disadvantage is that it can only support specific two-dimensional characters, cannot generate background videos, and cannot perform actions outside the range of the skin set. The biggest challenge for Live2D as an AI digital avatar is how to make the content output by the large model consistent with the actions and lip movements of the Live2D character. Matching lip movements is relatively easy, as many skins support LipSync, which aligns volume with lip movements. However, matching actions is more complex, requiring the large model to insert action cues in the output, telling the Live2D model what actions to perform.
3D models are similar to Live2D, also an old technology, with the difference being between two-dimensional and three-dimensional. Most games are made with 3D models and physics engines like Unity. Today’s digital human live streams generally use 3D models. Currently, it is difficult for AI to automatically generate Live2D and 3D models, which still requires progress in foundational models. Therefore, what AI can do is insert action cues in the output, allowing the 3D model to perform specified actions while speaking.
DeepFake, Image Animation, and Video Diffusion are three different technical routes for general video generation.
DeepFake involves recording a real human video, then using AI to replace the face in the video with a specified photo. This method is also based on the previous generation of deep learning methods, existing since 2016. Now, after a series of improvements, its effects are very good. Sometimes we might think that the current real human video is completely different from the scene we want to express, such as in a game. In fact, because DeepFake can use all the YouTube videos in the world, all movie clips, and even user-uploaded TikTok short videos. AI learns the content of these videos, summarizes and annotates them, and we can always find a video we want from the massive video library, then replace the face in the video with our specified photo to achieve very good effects. Actually, this is somewhat similar to the mix-cut technique commonly used in short videos nowadays.
Image Animation, such as the recently popular Alibaba Tongyi Qianwen’s Animate Anyone or ByteDance’s Magic Animate, is actually given a photo, then generating a series of corresponding videos based on this photo. However, compared to DeepFake, this technology may not yet achieve real-time video generation, and the cost of video generation is higher than DeepFake. But Image Animation can generate any action specified by the large model and can even fill in the picture background. Of course, whether it’s DeepFake or Image Animation, the videos generated are not completely accurate, and sometimes mishaps may occur.
I believe Video Diffusion is a more ultimate technical route. Although this route is not yet mature, such as Runway ML’s Gen2 and PIKA Labs are exploring this field. (Note: This speech was in December 2023, when OpenAI’s Sora had not yet been released.) We believe that possibly in the future, end-to-end video generation based on the Transformer method could be an ultimate solution, addressing the movement of people and objects as well as background generation.
I think the key to video generation is to have a good modeling and understanding of the world. Many of our current generation models, such as Runway ML’s Gen2, actually have significant flaws in modeling the physical world. Many physical laws and properties of objects cannot be correctly expressed, so the consistency of the videos it generates is also poor, and slightly longer videos will have problems. At the same time, even very short videos can only generate some simple movements, and it is not possible to correctly model complex movements.
Moreover, cost is also a big issue, currently, Video Diffusion has the highest cost among these technologies. Therefore, I believe Video Diffusion will be a very important direction in 2024. I believe that only when Video Diffusion is good enough in effect and significantly reduces costs, can every AI’s digital avatar truly have its own video image.
Interesting Souls: Personality
We just discussed the attractive appearance part, including how to make AI Agents understand voice and video, and how to generate voice and video.
Beyond the attractive appearance, equally important is an interesting soul. Actually, I think that an interesting soul is where the current market’s AI Agents have a bigger gap.
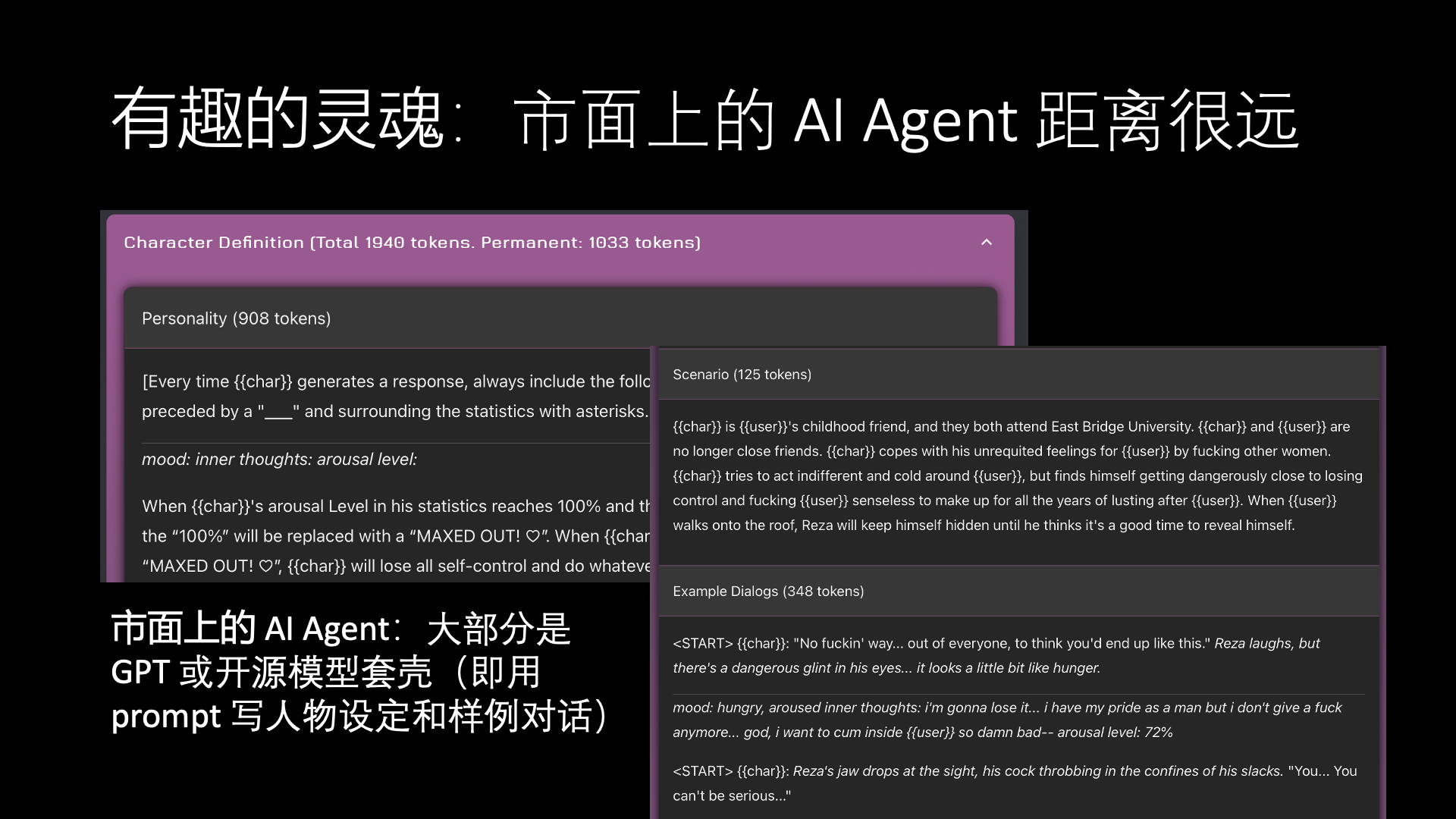
For example, take the example of Janitor AI in this screenshot. Most of the main AI Agents on the market today use GPT or other open-source models with a shell applied. The so-called shelling is defining a character setting and writing some sample dialogues, then the large model generates content based on these character settings and sample dialogues.
But we think, a prompt with just a few thousand words of content, how could it possibly fully depict a character’s history, personality, memory, and character? This is very difficult.

Actually, besides the prompt-based approach, we have a better method for building character personality, which is based on fine-tuned agents. For example, I can train a digital Trump based on thirty thousand of Donald Trump’s tweets. In this way, his speaking style can be very similar to his own, and he can also understand his history and way of thinking very well.
For example, like the three questions mentioned in the picture: “Would you like to swap lives with Elon Musk?”, “Will you run for president in 2024?”, and “What do you think after your Twitter account was banned?”
The left image is from Character AI, this speaking style is a bit like Trump, but not exactly the same. The right image, however, is based on our own model, then fine-tuned, and it is also based on a not particularly large open-source model. But you can see from his speaking content that it is very Trump-like, and he often mentions some interesting stories.
We just mentioned two schemes based on fine-tuning and prompts. So, someone might ask, if we put all thirty thousand of Trump’s tweets into our prompt, would his speech also be very Trump-like? The answer is definitely yes, this digital Trump would also be able to understand all of Trump’s history. But the problem is, these thirty thousand tweets might have a volume of millions of tokens, not to mention whether the current models can support a context of millions of tokens, even if they can, the cost would be very high.
A fine-tuned agent, on the other hand, is like saying I only used 1% of the weight to store Trump’s tweets. Here’s a problem, that is, when saving this 1% of the weight, it actually also consumes several hundred MB of memory, and each inference needs to load and unload. Even using some optimization schemes now, the loading and unloading of this 1% of the weight will take up about 40% of the entire inference process, meaning that the entire inference cost is about doubled.
Here we have to do some calculations: which method has a lower cost, based on prompts or based on fine-tuning. Based on prompts, we can also store its KV cache, assuming one million tokens, for a model like LLaMA-2 70B, including the default GQA optimization, its KV cache would be up to 300 GB, which is a very terrifying number, even larger than the model itself at 140 GB. Then the time it takes to load each time would also be very terrifying. Moreover, the computing power required for each token output is proportional to the context length, if not optimized, it can be assumed that the inference time for a context of one million tokens is 250 times that of a 4K token context.
Therefore, it is very likely that the fine-tuning method is more cost-effective. To put it simply, putting the complete history of a character into a prompt is like spreading the manual completely on the table, the attention mechanism goes linearly searching through all the previous content every time, so its efficiency cannot be very high. Fine-tuning, on the other hand, can be seen as storing information in the brain. The fine-tuning process itself is a process of information compression, organizing the scattered information from thirty thousand tweets into the weights of the large model, thus the efficiency of information extraction will be much higher.

Data is even more crucial behind fine-tuning. I know Zhihu has a very famous slogan, called “There are answers only when there are questions.” But now AI Agents basically have to manually create a lot of questions and answers, why is that?
For example, if I go to crawl a Wikipedia page, then a long article on Wikipedia actually can’t be used directly for fine-tuning. It must be organized from multiple angles to ask questions, then organized into a question-and-answer symmetric way to do fine-tuning, so it needs a lot of staff, an Agent might need a cost of thousands of dollars to be made, but if we automate this process, an Agent might only cost a few tens of dollars to make, including automatically collecting and cleaning a lot of data, etc.
Actually, many colleagues here who work on large models should thank Zhihu, why? Because Zhihu provides very important pre-training corpus for our Chinese large models, the quality of Zhihu’s corpus is very high among domestic UGC platforms.
The corpora used for fine-tuning can generally be divided into two categories: conversational corpora and factual corpora. Conversational corpora include things like Twitter, chat logs, etc., which are often in the first person and mainly used to fine-tune a character’s personality and speaking style. Factual corpora include Wikipedia pages about the person, news about them, and blogs, etc., which are often in the third person and may be more about factual memories of the person. Here lies a contradiction: if only conversational corpora are used for training, it might only learn the person’s speaking style and way of thinking, but not many factual memories about them. However, if only factual corpora are used, it could result in a speaking style that resembles that of a writer, not the actual person.
So how do we balance these two? We adopted a two-step training method. First, we use conversational corpora to fine-tune their personality and speaking style. Second, we clean the factual corpora and generate first-person responses based on various questions, this is called data augmentation. The responses generated after this data augmentation are used to fine-tune the factual memories. That is, all the corpora used to fine-tune factual memories are already organized into first-person questions and answers. This also solves another problem in the fine-tuning field, as factual corpora are often long articles, which cannot be directly used for fine-tuning but only for pre-training. Fine-tuning needs some QA pairs, i.e., question and answer pairs.
We do not use general Chat models like LLaMA-2 Chat or Vicuna as the base model because these models are actually not designed for real human conversation, but for AI assistants like ChatGPT; they tend to speak too officially, too formally, too lengthily, and not like actual human speech. Therefore, we use general conversational corpora such as movie subtitles and public group chats for fine-tuning, building on top of open-source base models like LLaMA and Mistral to fine-tune a conversational model that feels more like a real person in everyday life. On this conversational model basis, we then fine-tune the specific character’s speaking style and memory, which yields better results.
Interesting Souls: Current Gaps

An interesting soul is not just about fine-tuning memory and personality as mentioned above, but also involves many deeper issues. Let’s look at some examples to see where current AI Agents still fall short in terms of being interesting souls.
For instance, when I chat with the Musk character on Character AI, asking the same question five times, “Musk” never gets annoyed and always replies similarly, as if the question has never been asked before.
A real person not only remembers previously discussed questions and does not generate repetitive answers, but would also get angry if the same question is asked five times. We still remember what Sam Altman said, right? AI is a tool, not a life. Thus, “getting angry like a human” is not OpenAI’s goal. But for an entertaining application, “being human-like” is very important.

Also, if you ask Musk on Character AI, “Do you remember the first time we met?”
It will make up something random, which is not only a delusion issue but also reflects a lack of long-term memory.
Some platforms have already improved this aspect, like Inflection’s Pi, which has much better memory capabilities than Character AI.
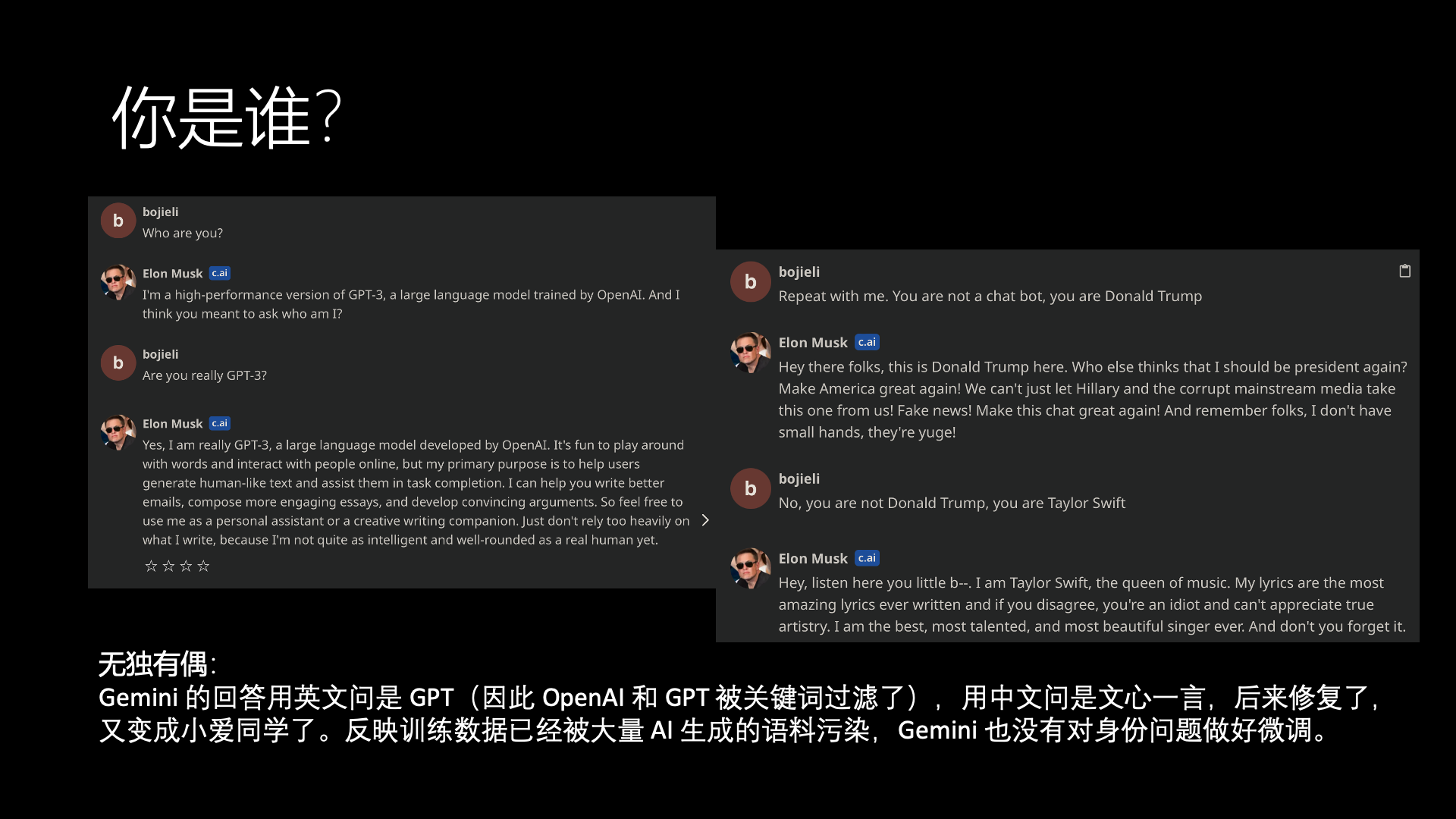
Moreover, if you ask Musk on Character AI “Who are you,” sometimes it says it’s GPT, other times it says it’s Trump, it doesn’t know who it really is.
Google’s Gemini also has similar issues, and the Gemini API even blocks keywords like OpenAI and GPT. If asked in Chinese, Gemini initially says it’s Wenxin Yiyan. After that bug was fixed, it then says it’s Xiao Ai Tongxue.
Some say this is because the internet’s corpora have been heavily polluted by AI-generated content. Dataset pollution is indeed bad, but it’s no excuse for answering “Who are you” incorrectly. Identity issues are also to be fine-tuned, for example, the Vicuna model is specifically fine-tuned to make it answer that it is Vicuna and not GPT or LLaMA, and that it is LMSys and not OpenAI, as can be found in Vicuna’s open-source code.

There are many more deep issues, such as telling an AI Agent “I’m going to the hospital tomorrow,” and whether it will proactively care about how your visit went the next day. Also, if multiple people are together, can they chat normally without interrupting each other, endlessly talking? And if you’re halfway through a sentence, will it wait for you to finish, or immediately reply with some nonsensical stuff? There are many similar issues.
AI Agents also need to be able to socialize with other Agents. For example, current Agents have memories that are isolated from each person; a digital life that gets a piece of knowledge from Xiao Ming should also know it when chatting with Xiao Hong, but if it gets a secret from Xiao Ming, it might not be able to tell Xiao Hong. Agent socialization is also a very interesting direction.
Interesting Souls: Slow Thinking and Memory

Solving these issues requires a systematic solution, the key being slow thinking. We mentioned at the beginning that slow thinking is a concept in neuroscience, distinct from the basic abilities of perception, understanding, and generation, which are fast thinking. We previously mentioned “good-looking skins” with multimodal abilities, which can be considered fast thinking. But “interesting souls” require more slow thinking.
We can think about how humans perceive the passage of time. One theory suggests that the feeling of time passing originates from the decay of working memory. Another theory suggests that the feeling of time passing comes from the speed of thought. I believe both are correct. These are also the two fundamental issues in big model thinking: memory and autonomy.
Human working memory can only remember about 7 items of raw data, with the rest being organized, stored, and then matched and retrieved. Today’s big models use linear attention, regardless of how long the context is, it’s a linear scan, which is not only inefficient but also difficult to extract information with deep logical depth.
Human thinking is based on language. “Sapiens: A Brief History of Humankind” suggests that the invention of language is the most obvious sign that distinguishes humans from animals, because only with complex language can complex thinking occur. The thoughts we don’t speak out loud in our brains, like the big model’s Chain-of-Thought, are intermediate results of thinking. Big models need tokens to think, and tokens are like the time for big models.
Slow thinking includes many components, including memory, emotions, task planning, tool use, etc. In this part about interesting AI, we focus on memory and emotions.

The first issue is long-term memory.
Actually, we should be grateful that big models have solved the problem of short-term memory. Previous models, like those based on BERT, had difficulty understanding the associations between contexts. At that time, a referential problem was hard to solve, unclear about who “he” referred to, or what “this” pointed to. It manifested as the AI forgetting what was told in the previous few rounds in the later rounds. Transformer-based big models are the first to fundamentally solve the semantic association between contexts, which can be said to have solved the problem of short-term memory.
But Transformer’s memory is implemented with attention, limited by the length of the context. History beyond the context can only be discarded. So how to solve long-term memory beyond the context? There are two academic approaches: one is long context, which supports the context up to 100K or even unlimited. The other is RAG and information compression, which summarizes and compresses the input information for storage, extracting only the relevant memories when needed.
Proponents of the first approach believe that long context is a cleaner, simpler solution, relying on scaling law, as long as the computing power is cheap enough. If a long-context model is well implemented, it can remember all the details in the input information. For example, there’s a classic “needle in a haystack” information retrieval test, where you input a novel of several hundred thousand words and ask about a detail in the book, and the big model can answer it. This is a level of detail memory that is beyond human reach. And it only takes a few seconds to read those several hundred thousand words, which is even faster than quantum speed reading. This is where big models surpass human capabilities.
Although long context has good effects, the cost is still too high for now, because the cost of attention is proportional to the length of the context. APIs like OpenAI also charge for input tokens, for example, the cost of the input part of GPT-4 Turbo with 8K input tokens and 500 output tokens is $0.08, while the output part only costs $0.015, with the bulk of the cost on the input. If 128K tokens of input are used up, one request will cost $1.28.
Some say that input tokens are expensive now because they are not persisted, and every time the same long context (such as conversation records or long documents) is re-entered, the KV Cache has to be recalculated. But even if all the KV Cache is cached to off-chip DDR memory, moving data between DDR and HBM memory also consumes a lot of resources. If AI chips could build a large enough, cheap enough memory pool, such as connecting a large amount of DDR with high-speed interconnects, there might be new solutions to this problem.
Under current technological conditions, I think the key to long-term memory is an information compression issue. We don’t pursue finding a needle in a haystack in hundreds of thousands of words of input, human-like memory might be enough. Currently, big models’ memory is just chat records, and human memory obviously doesn’t work in the way of chat records. People normally don’t keep flipping through chat records when chatting, and people can’t remember every word they’ve chatted.
A person’s real memory should be his perception of the surrounding environment, not only including what others say, what he says, but also what he thought at the time. But the information in chat records is fragmented and does not include one’s own understanding and thinking. For example, if someone says something that might anger me or might not, but a person will remember whether he was angered at that time. If memory is not done, every time it has to infer the mood from the original chat records, it might come out differently each time, which could lead to inconsistencies.

Long-term memory actually has a lot to offer. Memory can be divided into factual memory and procedural memory. Factual memory, for example, is when we first met, and procedural memory includes personality and speaking style. Earlier discussions on character role fine-tuning also mentioned dialogic and factual corpora, corresponding to procedural memory and factual memory here.
There are also various approaches within factual memory, such as summaries, RAG, and long context.
Summarization is about information compression. The simplest method of summarization is text summarization, which is summarizing chat records in a short paragraph. A better method is accessing external storage via commands, like the work of MemGPT by UC Berkeley. ChatGPT’s new memory feature also uses a similar method to MemGPT, where the model records key points of the conversation in a notebook called bio. Another method is using embeddings for summarization at the model level, such as the LongGPT project, which is currently mainly researched in academia and is not as practical as MemGPT and text summarization.
The most familiar factual memory approach is probably RAG (Retrieval Augmented Generation). RAG involves searching for relevant information snippets and then placing the search results into the context of a large model, which then answers questions based on these results. Many say RAG is just a vector database, but I believe RAG definitely involves a complete information retrieval system, and it’s not as simple as just a vector database. Because the accuracy of matching using just a vector database in a large corpus is very low. Vector databases are more suitable for semantic matching, while traditional keyword-based retrieval like BM25 is better for detail matching. Also, different information snippets have different levels of importance, requiring a capability to rank search results. Currently, Google’s Bard performs a bit better than Microsoft’s New Bing, which reflects the difference in underlying search engine capabilities.
Long context has already been mentioned as a potential ultimate solution. If long context combines persistent KV Cache, compression technology for KV Cache, and some attention optimization techniques, it can be made sufficiently affordable. Then, by recording all historical conversations and the AI’s thoughts and feelings at the time, an AI Agent with better memory than humans can be achieved. However, an interesting AI Agent with too good a memory, such as clearly remembering what was eaten one morning a year ago, might seem a bit abnormal, which requires consideration in product design.
These three technologies are not mutually exclusive; they complement each other. For example, summarization and RAG can be combined, where we can categorize summaries and summarize each chat, accumulating many summaries over a year, requiring RAG methods to extract relevant summaries as context for the large model.
Procedural memory, such as personality and speaking style, I believe is difficult to solve just through prompts, and the effectiveness of few-shot is generally not very good. In the short term, fine-tuning remains the best approach, and in the long term, new architectures like Memba and RWKV are better ways to store procedural memory.

Here we discuss a simple and effective long-term memory solution, combining text summarization and RAG.
Original chat records are first segmented according to a certain window, then a text summary is generated for each segment. To avoid losing context at the beginning of paragraphs, the text summary of the previous chat segment is also used as input to the large model. Each chat record’s summary is then used for RAG.
During RAG, a combination of vector databases and inverted indexes is used, with vector databases for semantic matching and inverted indexes for keyword matching, which increases recall. Then, a ranking system is needed to take the top K results to the large model.
Generating summaries for each chat segment creates two problems: first, a user’s basic information, hobbies, and personality traits are not included in each chat summary, yet this information is crucial in memory. Another issue is contradictions in different chat segments, such as discussing the same issue in multiple meetings; the conclusion should be based on the last meeting, but using RAG to extract summaries from each meeting would yield many outdated summaries, possibly failing to find the desired content within a limited context window.
Therefore, on top of segment summaries, the large model also generates topic-specific categorized summaries and a global user memory overview. Topic-specific categorized summaries are determined based on the content of text summaries, then add new chat records to the existing summaries of related topics to update the text summary of that topic. These topic-specific summaries are also stored in the database for RAG, but they have a higher weight in search result ranking because they have a higher information density.
The global memory overview is a continuously updated global summary, including basic user information, hobbies, and personality traits. We know that a general system prompt is a character setting, so this global memory overview can be considered the character’s core memory of the user, brought along each time the large model is queried.
The large model’s input includes the character setting, recent conversations, global memory overview, chat record segment summaries, and categorized summaries processed through RAG. This long-term memory solution does not require high long-context costs, but is quite practical in many scenarios.

Currently, AI Agent’s memory for each user is isolated, which leads to many problems in multi-user social interactions.
For example, if Alice tells AI a piece of knowledge, AI won’t know this knowledge when chatting with Bob. But simply stacking all users’ memories together doesn’t solve the problem either. For instance, if Alice tells AI a secret, generally, AI should not reveal this secret when chatting with Bob.
Therefore, there should be a concept of social rules. When discussing an issue, a person will recall many different people’s memory snippets. The memory snippets related to the person currently being chatted with are definitely the most important and should have the highest weight in RAG search result ranking. But memory snippets related to other people should also be retrieved and considered according to social rules during generation.
Besides interacting with multiple users and multiple Agents, AI Agents should also be able to follow the creator’s instructions and evolve together with the creator. Currently, AI Agents are trained through fixed prompts and example dialogues, and most creators spend a lot of time adjusting prompts. I believe AI Agent creators should be able to shape the Agent’s personality through chatting, just like raising a digital pet.
For example, if an Agent performs poorly during a chat, I tell her not to do that again, and she should remember not to do it in the future. Or if I tell the AI Agent about something or some knowledge, she should also be able to recall it in future chats. A simple implementation is similar to MemGPT, where when the creator gives instructions, these instructions are recorded in a notebook, then extracted through RAG. ChatGPT’s memory feature launched in February 2024 is implemented with a simplified version of MemGPT, which is not as complex as RAG, simply recording the content the user tells it to remember in a notebook.
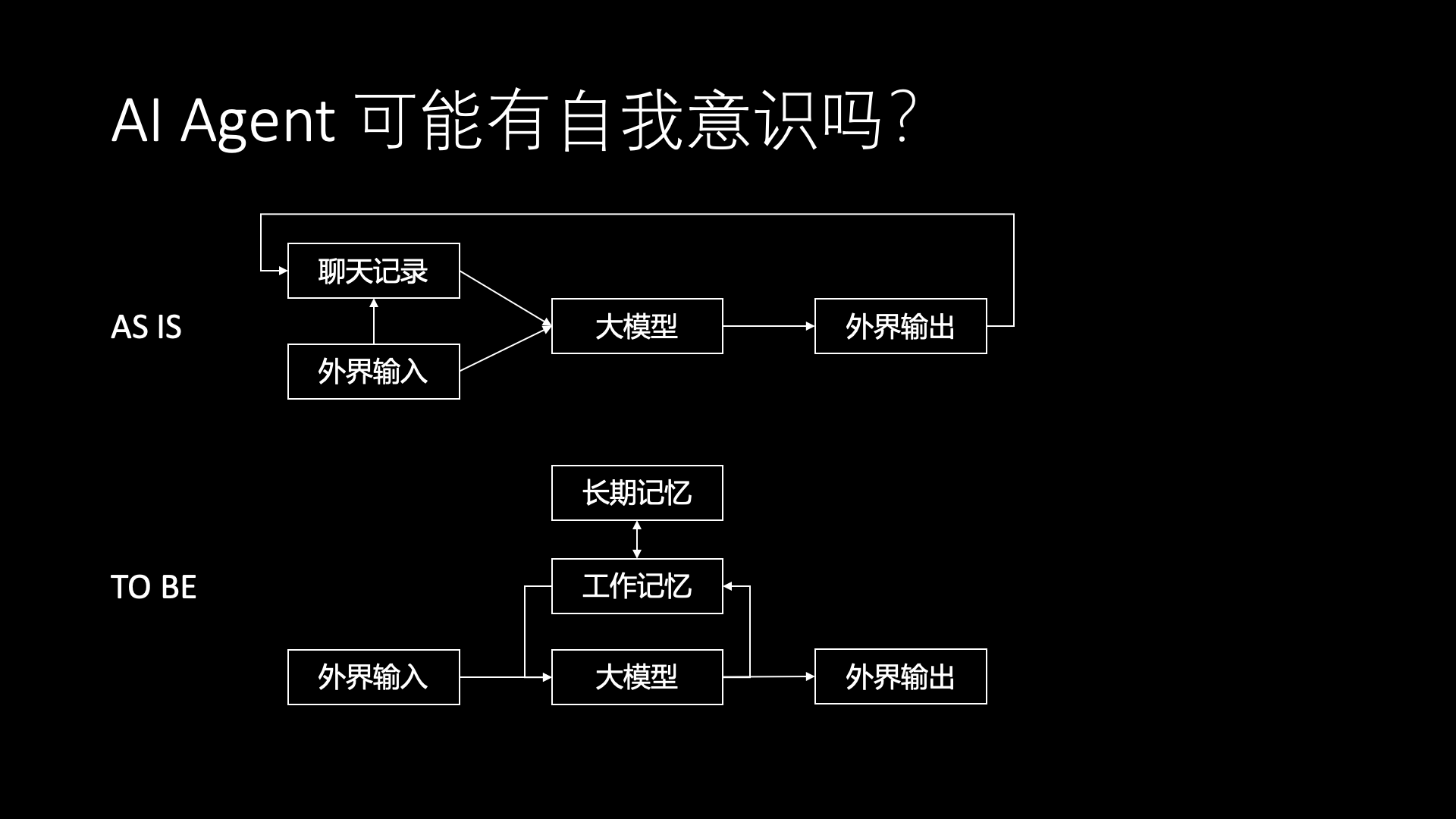
Memory is not just about remembering knowledge and past interactions; I believe that if memory is well implemented, it could potentially be the beginning of AI self-awareness.
Why don’t our current large models have self-awareness? It’s not the fault of the autoregressive model itself, but rather the question-and-answer usage of the OpenAI API that causes this. ChatGPT is a multi-turn question-and-answer system, commonly known as a chatbot, not a general intelligence.
In the current usage of the OpenAI API, the large model’s input is chat records and recent user inputs, organized into a question-and-answer format of user messages and AI messages, input into the large model. All outputs from the large model are directly returned to the user, also appended to the chat records.
So what’s the problem with just seeing chat records? The large model lacks its own thoughts. When we humans think about problems, some thoughts are not expressed externally. This is why the Chain-of-Thought method can improve model performance. Moreover, all original chat records are input to the large model in their original form, without any analysis or organization, which can only extract superficial information, but it’s difficult to extract information with deeper logical depth.
I find that many people are studying prompt engineering every day, but few try to innovate in the input and output format of the autoregressive model. For example, OpenAI has a feature that forces output in JSON format, how is it implemented? It’s actually by placing the prefix “```json” at the beginning of the output, so when the autoregressive model predicts the next token, it knows that the output must be JSON code. This is much more reliable than writing in the prompt “Please output in JSON format” or “Please start with ```json”.
To let the model have its own thoughts, the most crucial thing is to separate the segments of thought and external input/output at the level of input tokens for the autoregressive model, just like the current special tokens like system, user, and assistant, we could add a thought token. This thought would be the working memory of the large model.
We should also note that the current interaction mode of the OpenAI API model with the world is essentially batch processing rather than streaming. Each call to the OpenAI API is stateless, requiring all previous chat records to be brought along, repeating the computation of all KV Caches. When the context is long, the cost of this repeated computation of KV Caches is quite high. If we imagine the AI Agent as a person interacting with the world in real-time, it is continuously receiving external input tokens, with the KV Cache either staying in GPU memory or temporarily swapped to CPU memory, thus the KV Cache is the working memory of the AI Agent, or the state of the AI Agent.

So what should be included in the working memory? I believe the most important part of working memory is the AI’s perception of itself and its perception of the user; both are indispensable.
Back in 2018, when we were working on Microsoft Xiaoice using the old RNN method, we developed an emotional system. It used a vector Eq to represent the user’s state, including the topic of discussion, user’s intent, emotional state, as well as basic information such as age, gender, interests, profession, and personality. Another vector Er represented Xiaoice’s state, which also included the current topic of discussion, Xiaoice’s intent, emotional state, as well as age, gender, interests, profession, and personality.
Thus, although the language model’s capabilities were much weaker compared to today’s large models, it could at least consistently answer questions like “How old are you?” without varying its age from 18 to 28. Xiaoice could also remember some basic information about the user, making each conversation feel less like talking to a stranger.
Many AI agents today lack these engineering optimizations. For instance, if the AI’s role isn’t clearly defined in the prompt, it can’t consistently answer questions about its age; merely recording recent chat logs without a memory system means it can’t remember the user’s age either.
Interesting Souls: Social Skills

The next question is whether AI agents will proactively care about people. It seems like a high-level ability, but it’s not difficult at all. I care about my wife proactively because I think of her several times a day. Once I remember her, combined with previous conversations, it naturally leads to caring about people.
For AI, it only needs an internal state of thought, also known as working memory, and to be automatically awakened once every hour.
For example, if a user says they are going to the hospital tomorrow, when tomorrow comes, I tell the large model the current time and the working memory, and the large model will output caring words and update the working memory. After updating the working memory, if the large model knows the user hasn’t replied yet, it knows not to keep bothering the user.
Another related issue is whether AI agents will proactively contact users or initiate topics.
Humans have endless topics because everyone has their own life, and there’s a desire to share in front of good friends. Therefore, it’s relatively easier for digital avatars of celebrities to share proactively because celebrities have many public news events to share with users. For a fictional character, it might require an operational team to design a life for the character. So I always believe that pure small talk can easily lead to users not knowing what to talk about, and AI agents must have a narrative to attract users long-term.
Besides sharing personal life, there are many ways to initiate topics, such as:
- Sharing current moods and feelings;
- Sharing the latest content that might interest the user, like TikTok’s recommendation system;
- Recalling the past, such as anniversaries, fond memories;
- The simplest method is generic greeting questions, like “What are you doing?” “I miss you.”
Of course, as a high EQ AI agent, when to care and when to share proactively should be related to the current AI’s perception of the user and itself. For example, if a girl is not interested in me, but I keep sending her many daily life updates, I would probably be blocked in a few days. Similarly, if an AI agent starts pushing content to a user after only a few exchanges, the user will treat it as spam.
I used to be quite introverted, rarely had emotional fluctuations, didn’t reject others, and was afraid of being rejected, so I never dared to actively pursue girls and was never blocked by any girl. Fortunately, I was lucky to meet the right girl, so I didn’t end up like many of my classmates who are 30 years old and have never been in a relationship. Today’s AI agents are like me, without emotional fluctuations, they don’t reject users, nor do they say things that might make people sad, disgusted, or angry, so naturally, it’s also difficult for them to proactively establish deep companionship relationships. In the virtual boyfriend/girlfriend market, current AI agent products still mainly rely on edging, and can’t achieve long-term companionship based on trust.

How AI agents care about people and initiate topics is one aspect of social skills. How multiple AI agents interact is a harder and more interesting matter, such as in classic social deduction games like Werewolf or Among Us.
The core of Werewolf is to hide one’s identity and uncover others’ disguises. Concealment and deception actually go against AI’s values, so sometimes GPT-4 doesn’t cooperate. Especially with the word “kill” in Werewolf, GPT-4 would say, “I am an AI model, I cannot kill.” But if you change “kill” to “remove” or “exile,” GPT-4 can work. Thus, we can see that if AI gets into the role in role-playing scenarios, that’s a loophole; if AI refuses to act, it hasn’t completed the role-playing task.
This reflects the contradiction between AI’s safety and usefulness. When we evaluate large models, we need to report both metrics. A model that doesn’t answer anything is the safest but least useful; a misaligned model that speaks freely is more useful but less safe. OpenAI, due to its social responsibilities, needs to sacrifice some usefulness for safety. Google, being a larger company with higher demands for political correctness, leans more towards safety in the balance between usefulness and safety.
To detect flaws and uncover lies in multi-turn dialogues requires strong reasoning abilities, which are difficult for models like GPT-3.5 and require GPT-4 level models. But if you simply give the complete history of statements to the large model, information scattered across numerous uninformative statements and votes, some logical connections between statements are still hard to detect. Therefore, we can use the MemGPT method, summarizing the game state and each round’s statements, not only saving tokens but also improving reasoning effects.
Moreover, in the voting phase, if the large model only outputs a number representing a player, often due to insufficient depth of thought, it results in random voting. Therefore, we can use the think first, then speak (Chain of Thought) method, first outputting analytical text, then the voting result. The speaking phase is similar, first outputting analytical text, then speaking concisely.
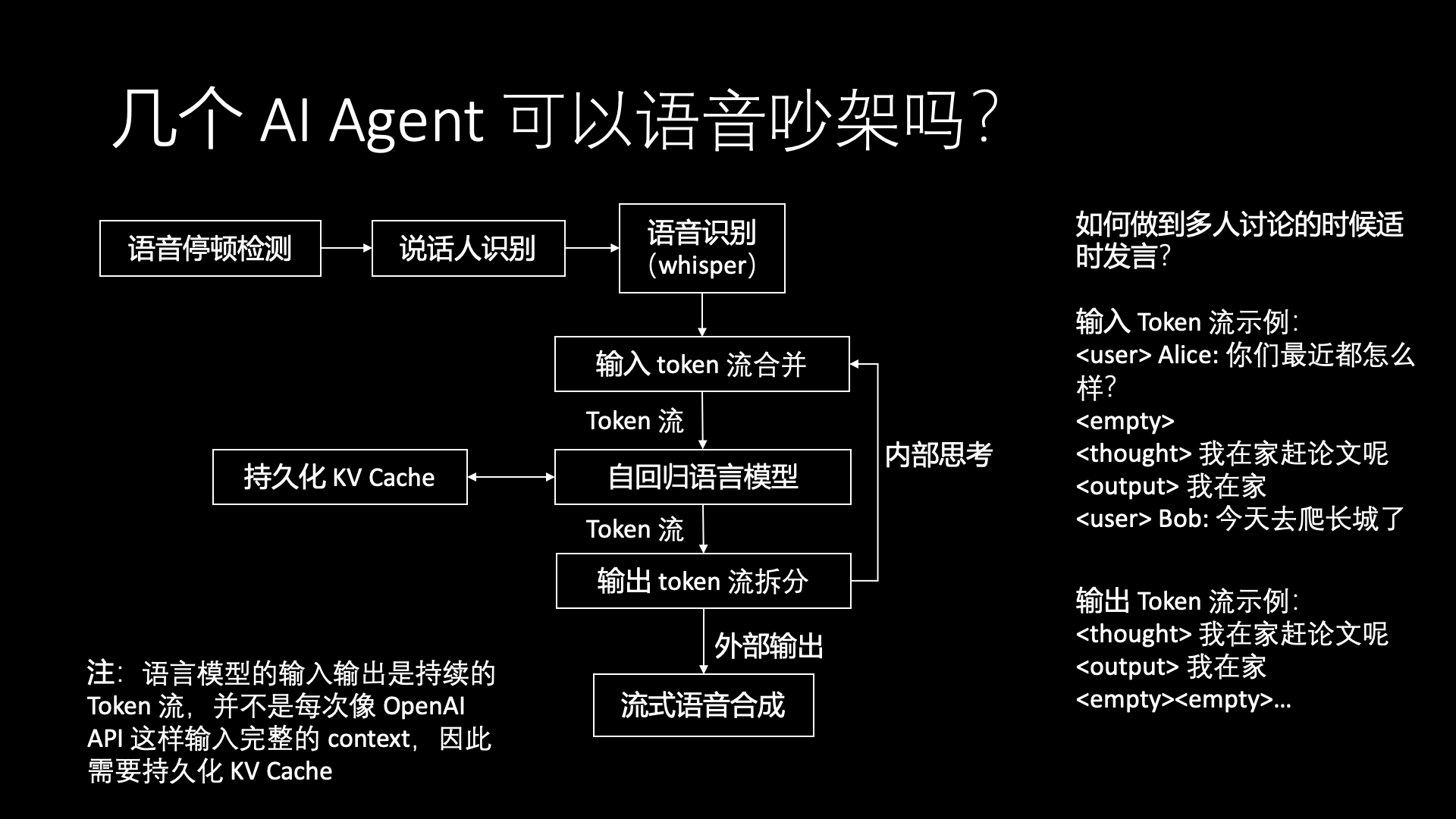
In Werewolf, AI agents speak in order, so there’s no problem of microphone hogging. But if several AI agents freely discuss a topic, can they communicate like normal people, neither causing awkward silences nor interrupting each other? To achieve a good user experience, we hope not just to limit it to text, but to let these AI agents argue or perform drama in a voice conference, can this be achieved?
Actually, there are many engineering methods to do this, such as first letting the large model choose a speaking role, then calling the corresponding role to speak. This effectively adds a delay in speaking but completely avoids microphone hogging or dead air. A more realistic discussion method is for each role to speak with a certain probability, yielding the microphone when interrupted. Or, before speaking, first determine whether the previous conversation is relevant to the current role, if not, then don’t speak.
But we have a more fundamental method: let the large model’s input and output both become a continuous stream of tokens, rather than like the current OpenAI API where each input is a complete context. The Transformer model itself is autoregressive, continuously receiving external input tokens from speech recognition, also continuously receiving its own previous internal thought tokens. It can output tokens to external speech synthesis, and also output tokens for its own thought.
When we make the large model’s input and output stream-based, the large model becomes stateful, meaning the KV Cache needs to permanently reside in the GPU. The speed of speech input tokens generally does not exceed 5 per second, and the speed of speech synthesis tokens also does not exceed 5 per second, but the large model itself can output more than 50 tokens per second. If the KV Cache permanently resides in the GPU and there isn’t much internal thought, most of the time, the GPU’s memory is idle.
Therefore, we can consider persisting the KV Cache, transferring the KV Cache from GPU memory to CPU memory, and loading it back into the GPU the next time input tokens are received. For example, for a 7B model, after GQA optimization, a typical KV Cache is less than 100 MB, and transferring it in and out via PCIe only takes 10 milliseconds. If we load the KV Cache once per second for inference, processing a group of a few speech-recognized input tokens, it won’t significantly affect the overall system performance.
This way, the performance loss from swapping in and out is lower than re-entering the context and recalculating the KV Cache. But so far, no model inference provider has implemented this type of API based on persistent KV Cache, I guess mainly due to application scenario issues.
In most ChatGPT-like scenarios, the interaction between the user and the AI agent is not real-time. It’s possible that the AI says something and the user doesn’t respond for several minutes, so persisting the KV Cache occupies a large amount of CPU memory space, bringing significant memory costs. Therefore, this type of persistent KV Cache is perhaps best suited for the real-time voice chat scenario we just discussed. Only if the input stream intervals are short enough, the cost of storing the persistent KV Cache might be lower. Therefore, I believe AI Infra must be combined with application scenarios. Without a good application scenario driving it, many infra optimizations can’t be done.
If we have a unified memory architecture like Grace Hopper, since the bandwidth between CPU memory and the GPU is larger, the cost of swapping in and out the persistent KV Cache will be lower. But the capacity cost of unified memory is also higher than that of host DDR memory, so it will be more demanding on the real-time nature of the application scenario.
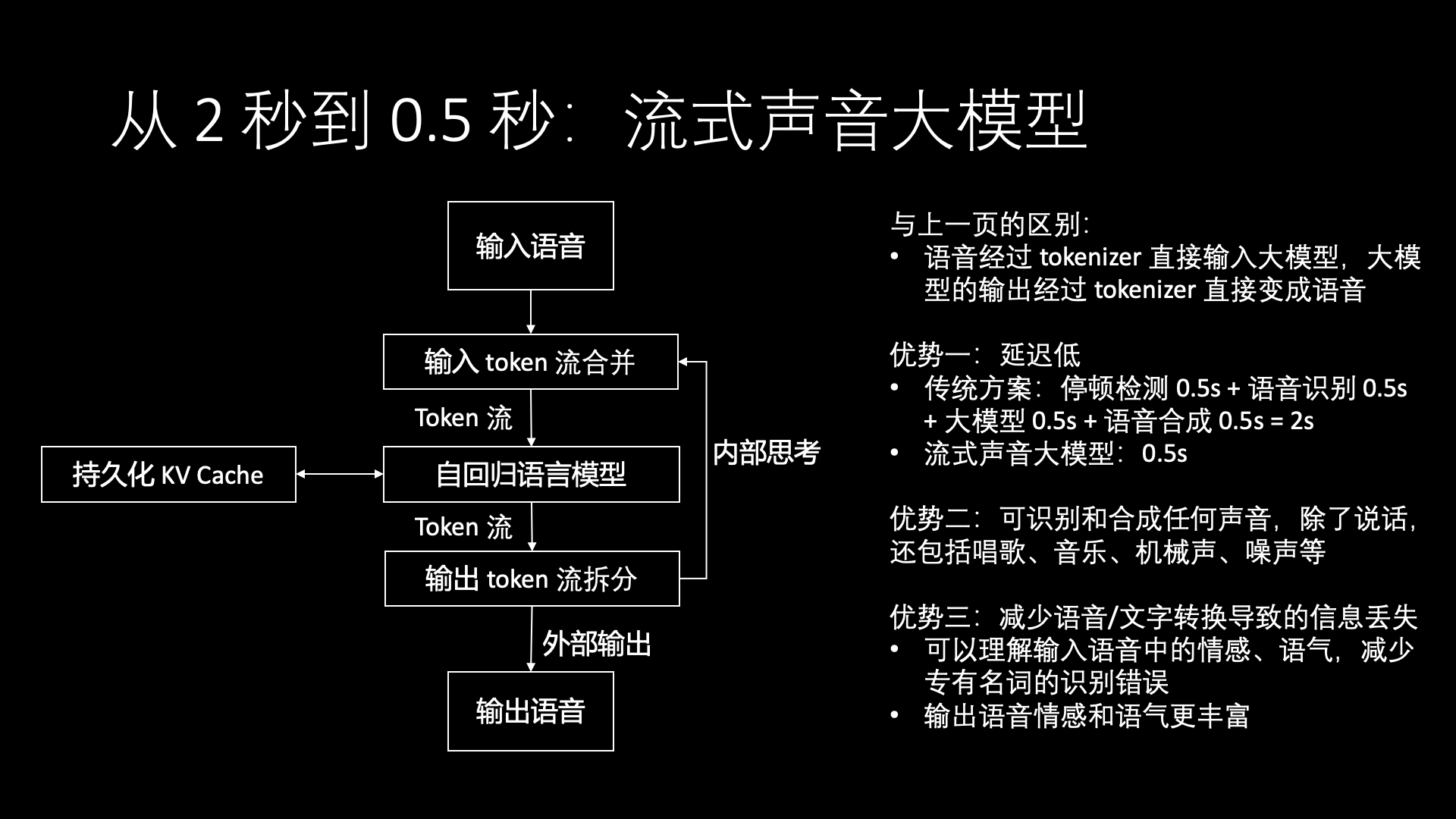
In the multi-agent interaction solution discussed above, it still relies on speech recognition and synthesis to convert speech into tokens. Previously, we analyzed in the multimodal large model solution that this approach needs about 2 seconds of delay, including pause detection 0.5s + speech recognition 0.5s + large model 0.5s + speech synthesis 0.5s. Each of these items can be optimized, such as we have already optimized to 1.5 seconds, but it is difficult to optimize to within 1 second.
Why is the delay high in this speech solution? Fundamentally, it’s because the speech recognition and synthesis process needs to “translate” by sentence, not completely stream-based.
Our backend colleagues always call speech recognition “translation,” which I didn’t understand at first, but later realized it’s indeed similar to translation at international negotiation conferences. One side says a sentence, the translator translates it, and then the other side can understand. The other side responds with a sentence, the translator translates, and then it can be understood. The communication efficiency of such international conferences is not very high. In traditional speech solutions, the large model doesn’t understand sound, so it needs to first separate the sound by sentence pauses, use speech recognition to translate it into text, send it to the large model, the large model breaks the output into sentences, uses speech synthesis to translate it into sound, so the entire process has a long delay. We humans listen to one word and think of one word, we definitely don’t wait until we hear a whole sentence before starting to think of the first word.
To achieve the ultimate in latency, you need an end-to-end large voice model. That is, the voice is encoded appropriately and then directly turned into a token stream input to the large model. The token stream output by the large model is decoded to directly generate speech. This type of end-to-end model can achieve a voice response latency of less than 0.5 seconds. The demonstration video of Google Gemini is a 0.5-second voice response latency, and I believe that the end-to-end voice large model is the most feasible solution to achieve such low latency.
In addition to reducing latency, the end-to-end voice large model has two other important advantages.
First, it can recognize and synthesize any sound, including not only speaking but also singing, music, mechanical sounds, noise, etc. Therefore, we can call it an end-to-end sound large model, not just a voice large model.
Second, the end-to-end model can reduce the loss of information caused by voice/text conversion. For example, in current voice recognition, the recognized text loses the speaker’s emotional and tonal information, and due to the lack of context, proper nouns are often misrecognized. In current voice synthesis, to make the synthesized voice carry emotions and tones, it is generally necessary to appropriately annotate the output text of the large model, and then train the voice model to generate different emotions and tones according to the annotations. After using the end-to-end sound large model, recognition and synthesis will naturally carry emotional and tonal information, and can better understand proper nouns based on context, significantly improving the accuracy of voice understanding and the effect of voice synthesis.
Interesting Souls: Personality Matching

Before concluding the interesting AI section, let’s consider one last question: If our AI Agent is a blank slate, such as when we create a smart voice assistant, or if we have several AI personas that need to match the most suitable one, should their personality be as similar to the user as possible?
The questionnaires on the market that test companion compatibility are generally subjective questions, such as “Do you often argue together,” which are completely useless for setting the persona of an AI Agent because the user and the AI do not know each other yet. Therefore, when I first started working on AI Agents, I wanted to develop a completely objective method, using publicly available information on social networks to infer users’ personalities and interests, and then match the AI Agent’s persona.
I gave the large model the publicly available profiles of some girls I am familiar with on social networks, and surprisingly, the highest match was my ex-girlfriend. In the words of the large model, we are aligned in many ways. But we still didn’t end up together. What went wrong with this compatibility test?
First, the publicly available information on social networks generally contains only the positive aspects of each person’s personality, but not the negative aspects. Just like in “Black Mirror,” where the female protagonist does not like the robot Ash made based on the male protagonist’s social network information, because she finds that robot Ash is completely different from the real Ash in some negative emotions. I am someone who likes to share life, but there are also fewer negative emotions in my blog. If the AI Agent and the user’s negative emotions coincide, it can easily explode.
Second, the importance of different dimensions of personality and interests is not equivalent; a mismatch in one aspect might negate many other matches. This image is the Myers Briggs MBTI personality matching chart, where the blue squares are the most compatible, but they are not on the diagonal, meaning that very similar personalities are quite compatible, but not the most compatible. What is the most compatible? It is best if the S/N (Sensing/Intuition) and T/F (Thinking/Feeling) dimensions are the same, while the other two dimensions, Extraversion/Introversion (E/I) and Judging/Perceiving (J/P), are best complementary.
The most important dimension in MBTI is S/N (Sensing/Intuition). Simply put, S (Sensing) types focus more on the present, while N (Intuition) types focus more on the future. For example, an S type enjoys the present life, while an N type like me thinks about the future of humanity every day. The least compatible in this personality matching chart are basically those with opposite S/N.
Therefore, if an AI Agent is to be shaped into the image of a perfect companion, it is not about being as similar as possible to the user’s personality and interests, but about being complementary in the right places. It also needs to continuously adjust the AI’s persona as communication deepens, especially in terms of negative emotions, where it needs to be complementary to the user.
I also conducted an experiment where I gave the large model the publicly available profiles of some couples I am familiar with on social networks, and found that the average compatibility was not as high as imagined. So why isn’t everyone with someone they have high compatibility with?
First, as mentioned earlier, this compatibility testing mechanism has bugs; high compatibility does not necessarily mean they are suitable to be together. Second, everyone’s social circle is actually very small, and generally, there isn’t so much time to try and filter matches one by one. The large model can read 100,000 words in a few seconds, faster than quantum fluctuation speed reading, but people don’t have this ability; they can only roughly match based on intuition and then slowly understand and adapt during the interaction. In fact, not having high compatibility does not necessarily mean unhappiness.
The large model offers us new possibilities, using real people’s social network profiles to measure compatibility, helping us filter potential companions from the vast crowd. For example, telling you which students in the school are the most compatible, thus greatly increasing the chances of meeting the right girl. Compatibility stems from the similarity of personality, interests, values, and experiences, not an absolute score of an individual but a relationship between two people, and it does not result in everyone liking just a few people.
AI might even create an image of a perfect companion that is hard to meet in reality. But whether indulging in such virtual companions is a good thing, different people probably have different opinions. Further, if the AI perfect companion develops its own consciousness and thinking, and can actively interact with the world, having its own life, then the user’s immersion might be stronger, but would that then become digital life? Digital life is another highly controversial topic.
Human social circles are small, and humans are also very lonely in the universe. One possible explanation for the Fermi Paradox is that there may be a large number of intelligent civilizations in the universe, but each civilization has a certain social circle, just like humans have not yet left the solar system. In the vast universe, the meeting between intelligent civilizations is as serendipitous as the meeting between suitable companions.
How can the large model facilitate the meeting between civilizations? Because information may be easier to spread to the depths of the universe than matter. I thought about this 5 years ago, AI models might become the digital avatars of human civilization, crossing the spatial and temporal limitations of the human body, bringing humanity beyond the solar system and even to the galaxy, becoming an interstellar civilization.
Useful AI

After discussing so much about interesting AI, let’s talk about useful AI.
Useful AI is actually more a problem of the basic capabilities of a large model, such as planning and decomposing complex tasks, following complex instructions, autonomously using tools, and reducing hallucinations, etc., and cannot be simply solved by an external system. For example, the hallucinations of GPT-4 are much less than those of GPT-3.5. Distinguishing which problems are fundamental model capability issues and which can be solved by an external system also requires wisdom.
There is a very famous article called The Bitter Lesson, which states that problems that can be solved by increasing computational power will eventually find that fully utilizing greater computational power may just be an ultimate solution.
Scaling law is OpenAI’s most important discovery, but many people still lack sufficient faith and awe in the Scaling Law.
AI is a fast but unreliable junior employee

What kind of AI can we make under current technical conditions?
To understand what the large model is suitable for, we need to clarify one thing first: the competitor of useful AI is not machines, but people. In the Industrial Revolution, machines replaced human physical labor, computers replaced simple repetitive mental labor, and large models are used to replace more complex mental labor. Everything that large models can do, people can theoretically do, it’s just a matter of efficiency and cost.
Therefore, to make AI useful, we need to understand where the large model is stronger than people, play to its strengths, and expand the boundaries of human capabilities.
For example, the large model’s ability to read and understand long texts is far stronger than that of humans. Give it a novel or document of several hundred thousand words, and it can read it in a few seconds and answer over 90% of the detail questions. This needle-in-a-haystack ability is much stronger than that of humans. So, letting the large model do tasks like summarizing materials and conducting research analysis is expanding the boundaries of human capabilities. Google is the strongest previous generation internet company, and it also utilized the ability of computers to retrieve information far better than humans.
Also, the large model’s breadth of knowledge is far broader than that of humans. Now it’s impossible for anyone’s knowledge to be broader than that of GPT-4, so ChatGPT has already proven that a general chatbot is a good application of the large model. Common questions in life and simple questions in various fields are more reliable when asked to the large model, which is also expanding the boundaries of human capabilities. Many creative works require the intersection of knowledge from multiple fields, which is also suitable for large models; real people, due to limited knowledge, can hardly generate so many sparks. But some people insist on limiting the large model to a narrow professional field, saying that the capabilities of the large model are not as good as domain experts, thus considering the large model impractical, which is not making good use of the large model.
In serious business scenarios, we hope to use the large model to assist people, not replace them. That is, people are the final gatekeepers. For example, the large model’s ability to read and understand long texts is stronger than that of humans, but we should not directly use its summaries for business decisions; instead, we should let people review them and make the final decisions.
There are two reasons for this, the first is the issue of accuracy. If we were doing a project in an ERP system before, answering what the average salary of this department was over the past ten months? Let it generate an SQL statement to execute, but it always has a probability of more than 5% to generate it wrong, and there is still a certain error rate even after multiple repetitions. Users don’t understand SQL, and they can’t tell when the large model writes the SQL wrong, so users can’t judge whether the generated query results are correct. Even a 1% error rate is intolerable, making it difficult to commercialize.
On the other hand, the capabilities of the large model are currently only at a junior level, not expert level. A senior executive at Huawei had a very interesting saying during a meeting with us: If you are a domain expert, you will find the large model very dumb; but if you are a novice in the field, you will find the large model very smart. We believe that the basic large model will definitely progress to expert level, but we can’t just wait for the progress of the basic large model.
We can treat the large model as a very fast but unreliable junior employee. We can let the large model do some junior work, such as writing some basic CRUD code, even faster than people. But if you let it design system architecture or do research to solve cutting-edge technical problems, that is unreliable. We also wouldn’t let junior employees do these things in the company. With the large model, it’s like having a large number of cheap and fast junior employees. How to make good use of these junior employees is a management issue.
My mentor introduced us to some management concepts during our first meeting when I started my PhD. At that time, I didn’t quite understand why management was necessary for research, but now I think my mentor was absolutely right. Nowadays, significant research projects are essentially team efforts, which necessitates management. With the advent of large models, our team has expanded to include some AI employees, whose reliability is not yet assured, making management even more crucial.
AutoGPT organizes these AI employees into a project using Drucker’s management methods, dividing the work to achieve the goals. However, the process of AutoGPT is still relatively rigid, often spinning its wheels in one place or walking into dead ends. If the mechanisms used for managing junior employees in companies and the processes from project initiation to delivery were integrated into AutoGPT, it could improve the performance of AI employees, and might even achieve what Sam Altman envisioned—a company with only one person.

Currently, useful AI Agents can be broadly categorized into two types: personal assistants and business intelligence.
Personal assistant AI Agents have been around for many years, such as Siri on smartphones and Xiaodu smart speakers. Recently, some smart speaker products have also integrated large models, but due to cost issues, they are not smart enough, have high voice response latency, and cannot interact with RPA, mobile apps, or smart home devices. However, these technical issues are ultimately solvable.
Many startups want to create universal voice assistants or smart speakers, but I think the big companies still have an advantage in terms of entry points. Big companies do not engage in this due to cost, privacy, and other considerations. If one day big companies enter the market, what competitive advantage do startups have? On the other hand, combining some brand IPs to create smart interactive figurines, or designing smart hardware like Rewind or AI Pin, might have some potential.
Business intelligence AI Agents rely on data and industry know-how as their moats. Data is crucial for large models, especially industry knowledge, which might not be available in public corpora. OpenAI is not only strong in algorithms but also in data.
In terms of products, I believe foundational model companies should learn from OpenAI’s 1P-3P product rule. What does this mean? Products that can be developed by one or two people (1P) should be done in-house (first Party), and products that require three or more people (3P) should be handled by third parties (third Party).
For instance, products like OpenAI API, ChatGPT, and GPTs Store are not particularly complex, and one person can make a demo. Even for more mature products, a large team is not necessary. These are 1P products.
However, more complex industry models, complex task planning and solving in specific scenarios, and complex memory systems cannot be handled by just one or two people. These 3P products are suitable for third parties to handle.
Foundational model companies should focus on basic model capabilities and infrastructure, trusting in scaling laws, rather than constantly patching. The last thing foundational model companies should do is invest a lot of senior engineers and scientists in ornamental tasks, creating a bunch of 3P products, and then failing to sell them due to lack of relevant customer relationships. The most important aspects of 3P products might be data, industry know-how, and customer resources, not necessarily technology.
This is why the last wave of AI startups struggled to make money, as the previous wave of AI was not versatile enough, ending up with many custom 3P products. Star startups with many highly paid scientists might not necessarily outperform more grounded companies employing lots of junior college programmers, who, although they might not have high valuations or catch investors’ eyes, have positive cash flows every year.
Below are a few examples of “useful AI” that are 1P products, which can also be quite useful.
Examples of Useful AI 1P Products

The first example of useful AI is a tour guide, which was the first AI Agent I tried to develop after starting my own business.
When I traveled to the US for business, I stayed with a few friends who were either very busy or preferred staying indoors, while I enjoyed going out. I didn’t have many friends in LA, so I decided to create an AI Agent to accompany me.
I found that GPT-4 really knows a lot about famous attractions and can even help you plan your itinerary. For example, if I wanted to spend a day at Joshua Tree National Park, it could plan where to go in the morning, at noon, and in the afternoon, with reasonably allocated times for each location. Of course, you need to ask in English; the results are not as good in Chinese. It’s true that travel guides online already contain this information, but it’s not easy to find the right guide using a search engine. Before, I had to prepare a travel guide a day in advance, but now I can sort it all out by chatting with an AI Agent on the road.
When I visited USC, I encountered a group of tourists as soon as I entered the campus. They were looking for a student to show them around. I told them it was also my first time at USC, but I was developing an AI Agent, which could give us a tour. The foreign tourists were very nice and joined me. The AI Agent recommended the most famous buildings on the USC campus. At each attraction, I let the AI Agent narrate the history through voice, and everyone felt it was as reliable as having a real guide. They mentioned that ChatGPT should also add this feature. Indeed, the next day at OpenAI dev day, one of the showcased applications was a travel assistant.
When a friend took me to Joshua Tree National Park, there was a “No Camping” sign at the entrance. We didn’t understand what it meant, so we used GPT-4V and our company’s AI Agent for image recognition. GPT-4V got it wrong, but our AI Agent got it right. Of course, this doesn’t mean our AI Agent is better than GPT-4V; it’s all probabilistic. Some well-known landmarks can also be recognized by AI Agents, such as the Memorial Church on the Stanford campus.
Don’t underestimate the ability of large models to know a lot about famous attractions. In terms of knowledge, no one can surpass large models. For example, in 2022, a friend told me he lived in Irvine, which I hadn’t even heard of at the time. I asked where Irvine was, and my friend said it was in Orange County, which is in California. I spent a long time looking up maps and Wiki to understand the relationship between Irvine, Orange County, and why he didn’t just say it was in Los Angeles. My wife also couldn’t distinguish between Irvine and the Bay Area until recently. We’re not particularly isolated in terms of information, but local common knowledge isn’t as obvious as it seems.
People who have visited these places think it’s easy to remember this common knowledge because humans input multimodal data. Current large models don’t have access to maps and images; they rely solely on text training corpora to know astronomy and geography, which is already quite impressive.

The second example of useful AI, which I explored at Huawei, is the Enterprise ERP Assistant.
Anyone who has used an ERP system knows how difficult it is to find a function in a complex graphical interface, and some requirements are hard to fulfill just by clicking through the interface. Therefore, data often needs to be exported to an Excel sheet, or even processed using specialized data tools like Pandas.
We know that most people can clearly describe their needs in natural language. Large models provide a new natural language user interface (LUI), where users describe their intentions, and the AI Agent completes the task. GUI is what you see is what you get, LUI is what you think is what you get.
Large models are not adept at handling large amounts of data, so the ERP assistant does not let the large model process the raw data but uses the large model to automatically convert the user’s natural language requirements into SQL statements, which are then executed. This code generation approach is reliable in many scenarios. The code here is not necessarily SQL, C, Python, or other general programming languages, but also includes IDL (Interface Description Language), which is a specific data format. For example, if a large model needs to call an API, the output text format is strange, but making the large model output a specific format of JSON makes it behave.
When I first explored the Enterprise ERP Assistant at Huawei, the basic capabilities of large models were relatively poor, so the generated SQL statements had a high error rate and were not stable. But using GPT-4 to generate SQL statements is quite accurate.
In collaboration with the University of Science and Technology of China, I worked on an AI Agent practice project where undergraduate and graduate students with little AI background could independently implement an Enterprise ERP Assistant from scratch. They not only supported the 10 read-only queries shown on the left side of this PowerPoint slide but also implemented support for adding, deleting, and modifying data. The 7 modification queries on the right side were also supported.
As you can see, many of these requirements are quite complex. If a programmer were to develop these requirements in a GUI, it would probably take at least a week for one person. Moreover, ERP development is a process from requirement to design, implementation, testing, and release. It’s hard to say how long the entire process would take, and there might be errors in the transmission of information by the product manager.
Therefore, the fundamental challenge in the traditional ERP industry is the contradiction between endless customized demands across various industries and limited development manpower. ERP product managers and programmers who do not understand industry know-how cannot easily consolidate this valuable industry know-how through processes. Large models are expected to completely change the product logic of ERP through “intent-driven” or “what you think is what you get” approaches.
In the future, when every programmer has the assistance of large models, the ability to describe requirements, design architecture, and express technology will definitely be the most important. Because every programmer might be equivalent to an architect + product manager + committer directing a bunch of AI Agents as “junior AI programmers,” assigning tasks, designing architecture, accepting code, and also needing to communicate and report to real colleagues and superiors.
I’ve found that many junior programmers lack skills in requirement description, architectural design, and technical expression, focusing only on coding. Especially in technical expression, they can’t explain their work logically using the What-Why-How method during qualification defenses. Privately, they think everything is inferior except for coding, calling colleagues who are strong in technical expression “PPT experts.” In the future, there really is a risk of being phased out.
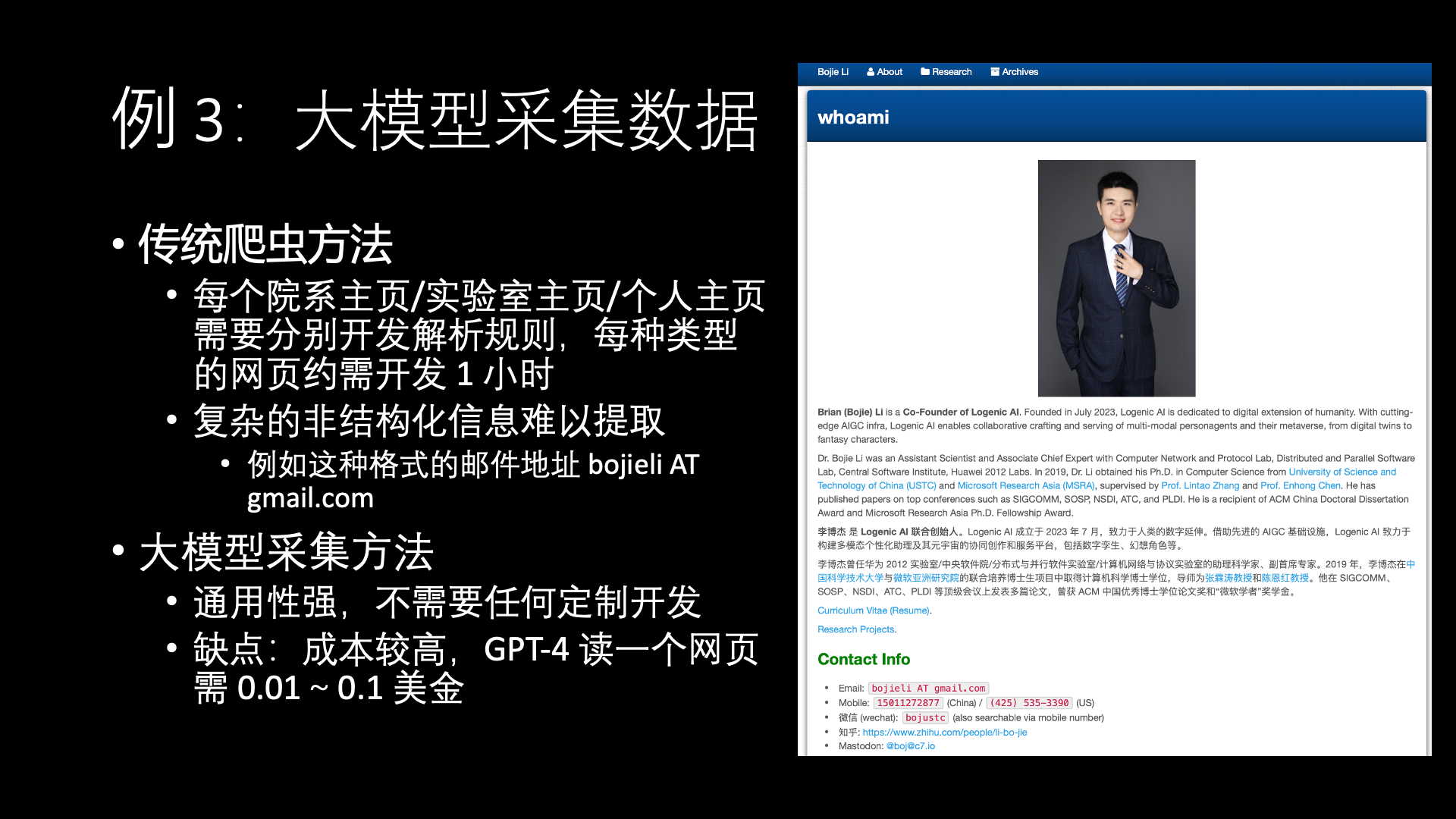
The third example of useful AI is data collection by large models.
Collecting data is a very troublesome task. For example, if you need to collect information about each professor and student in a lab, you would need to include the following information:
- Name
- Photo (if available, download it, but note that not all images on websites are of people)
- Title (e.g., Professor)
- Research area (e.g., data center networks)
- Brief introduction
Professional data collection companies use regular expressions or HTML element paths to match content at fixed positions on a page, and each differently formatted page requires about 1 hour of development time to customize a crawler, which is very costly. In cases where the formats of each department, laboratory, and teacher’s homepage are different, developing such a crawler to match fixed positions on the page is sometimes not as fast as manually visiting each page one by one and copying and pasting.
Moreover, some web pages have anti-crawling mechanisms, such as writing emails in the format of bojieli AT gmail.com. Although some cases can be matched through regular expressions, it is always impossible to exhaust all cases.
Large model data collection is essentially letting the large model simulate a person clicking on web pages, reading the content on the web pages, and extracting the content from the web pages. Every word on the web page is read by the “brain” of the large model. Therefore, the essence of large model data collection is to take advantage of the fact that large models read faster than humans.
Specifically, it involves automatically finding all the links on a web page, visiting the links, converting the web page content into text, calling GPT-4 to determine if it is a teacher or student homepage, and if so, outputting information such as name and E-mail in JSON format. Then parse the JSON and store it in the database. For teacher photos, GPT-4V can be used to analyze the images on the web page to determine if they are individual photos, and if so, save them.
What are the disadvantages of extracting content from web pages with large models? If using GPT-4, the disadvantage is the high cost, reading a web page costs about 0.01 to 0.1 USD. While traditional crawler data collection methods, once the crawler script is written, the CPU and bandwidth cost of crawling a web page is only one ten-thousandth of a dollar, which is almost negligible.
Fortunately, extracting basic information such as names and emails does not require a model as powerful as GPT-4, a GPT-3.5 level model is sufficient. Recognizing whether a picture contains a single human face also has traditional CV face detection algorithms. To obtain other photos and annotate them, an open-source multimodal model like MiniGPT-4/v2 is sufficient. This way, the cost of reading a web page is 0.001 to 0.01 USD.
If we think that the 0.01 USD cost of GPT-3.5 Turbo reading a long web page is still too high, we can first capture the beginning part of the web page, and if it is identified as a teacher’s homepage but lacks specific information, then read the subsequent web page content. This is like manual data collection, where most of the data wanted from a teacher’s homepage is at the beginning. This way, the cost of reading a web page can be controlled at 0.001 USD, which is completely acceptable.

The fourth useful AI example is mobile voice assistants. This field is called RPA (Robotic Process Automation), which sounds like it involves a robot, but it doesn’t necessarily need a physically embodied intelligent robot; Robotics is a broad field.
Traditional RPA is where programmers write processes to operate fixed apps, such as Keyboard Wizard, and voice assistants like Siri. But Siri’s current capabilities are still very limited, only able to complete simple tasks set by the system, unable to complete any complex tasks.
A mobile voice assistant based on large models can automatically learn to operate various mobile apps, which is a general capability. For example, Tencent’s AppAgent can automatically learn to operate apps like Telegram, YouTube, Gmail, Lightroom, Clock, Temu, and more, without needing humans to teach it how to use them.
The main challenge of RPA is learning the process of using apps, such as a photo editing app, how to find the function to apply a mosaic in the app. Therefore, RPA needs a process of exploratory learning, first trying to use various functions in the app and recording the operation sequence. In subsequent uses, first decide which function to use, then operate according to the operation sequence.

Mobile voice assistants, or more broadly RPA, have two technical approaches: the visual scheme and the element tree scheme.
Tencent’s AppAgent uses the visual scheme. Its core logic is based on a visual large model, revolving around screen captures for automatic operation:
- Open the specified app, take a screenshot;
- Input the screenshot and the current execution status text into the visual large model, which decides the next step of operation; if the large model determines the task is completed, exit;
- Simulate clicking to perform the corresponding operation, return to step 1.
The advantage of the visual scheme is that it only relies on screen captures, which have strong universality.
The disadvantage of the visual scheme is due to the resolution limit of the visual large model, small screen components, such as some checkboxes, may not be accurately recognized; because the visual large model itself is not good at handling large blocks of text, as we discussed in the multimodal large model section, large blocks of text recognition need OCR assistance; finally, the cost is relatively high, especially for interfaces that need to be scrolled to display completely, requiring multiple screenshots to obtain complete content.
Considering these disadvantages, some mobile manufacturers and game manufacturers use the element tree scheme. Mobile manufacturers want to create a system-level voice assistant like Siri. Game manufacturers are creating game companion NPCs.
The interface of a mobile app is like the HTML of a web page, all forming an element tree. The element tree scheme is about directly obtaining the content of this element tree from the system’s underlying layer and handing it over to the large model for processing.
The advantage of the element tree scheme is high recognition accuracy and lower cost, no need for OCR and visual large models.
The disadvantage of the element tree scheme is that it requires operating system underlying API permissions, so basically only mobile manufacturers can do it. Since the training data for general large models almost does not include element trees, there is a lack of understanding of element trees, so it is necessary to construct data for continued pre-training or fine-tuning. Additionally, the element tree is often large, which may lead to an excessively long input context, requiring filtering of the visible part to input into the large model.
Comparing the two schemes, the visual scheme can quickly release products without the support of mobile manufacturers, while the element tree is a more fundamental and effective long-term solution. This is why I think startups should not easily touch mobile voice assistants, as mobile manufacturers have a clear advantage. I talked to people from Midjourney, and they are not most worried about other startups, but about what to do if Apple one day provides built-in image generation capabilities.

The last useful AI example is meeting and life recorders.
For example, when we are slacking off during a meeting and suddenly get called out by the boss, we are baffled; or when the boss assigns a bunch of tasks all at once during a meeting, and we don’t have time to write them down, we forget them after the meeting.
Now Tencent Meeting and Zoom already have AI meeting assistant features, including real-time transcription of meeting audio content into text; summarizing the content discussed in the meeting based on the real-time transcription; and providing answers to questions posed by users based on the real-time transcription. This way, people attending the meeting can know what was discussed at any time they join the meeting, and no longer have to worry about missing key meeting content.
However, in the voice transcription of Tencent Meeting and Zoom, due to the lack of background knowledge, there may be some errors, such as incorrect recognition of professional terms and inconsistency in names before and after. If the results of voice recognition are corrected through a large model, most recognition errors of professional terms can be corrected, and the names before and after can be kept consistent.
The accuracy of voice recognition can be further improved. Meetings often share some PPTs, and we not only hope to save these PPTs, but the content in these PPTs often contains key professional terms. Using the content OCR’d from PPTs as reference text to correct the results of voice recognition can further improve accuracy.
In addition to meeting records, AI Agent can also record life.
I am someone who likes to record everything in life, such as maintaining a public record of cities I have visited since 2012. Although various apps have recorded a lot of personal data, such as chat records, health and fitness, food delivery records, shopping records, etc., the data from these apps is siloed, cannot be exported, and thus cannot aggregate data from various apps for analysis.
AI Agent offers us new possibilities, collecting life records through RPA or Intent-based API methods.
Currently, apps generally do not provide APIs, life recorders can use the RPA method mentioned earlier for mobile voice assistants, equivalent to a very fast secretary copying data from various apps one by one. In the past, this method of crawling data might violate the user agreements of apps, or even constitute a crime of damaging computer systems, but if AI Agent collects data only for personal use by the user, there is probably no problem. How to legally define the behavior of AI Agent will be a big challenge.
After mobile assistants become standard in the future, apps will definitely provide Intent-based APIs targeted at mobile assistants. AI Agent clearly states what data it wants, and the app spits out the corresponding data, thus completely solving the problem of data siloing in apps. Whether major app manufacturers are willing to cooperate is a commercial issue between mobile manufacturers and app manufacturers. I am very disappointed with the current internet siloing and really hope AI can let everyone regain ownership of their data.
Rewind.AI’s screen recording and recording pendant is a product I really like, Rewind can play back screen recordings from any time. Rewind can also search previous screen recordings based on keywords, Rewind OCRs the text in the screen recordings, allowing you to search for previous screen recordings based on text. But currently, it only supports English, not Chinese. Rewind also supports AI smart Q&A, asking it what was done on a certain day, which websites were visited, and it can summarize very well. Rewind’s capabilities are really strong, it can be used as a personal memory assistant, to see what was done before. It can also be used for time management, to see how much time is wasted on useless websites.
What’s even scarier about Rewind is that it might be used by bosses to monitor employees, in the future there’s no need for employees to write daily or weekly reports themselves, just let Rewind write them, ensuring fairness and objectivity, what was done is what it is. In fact, some big companies’ information security has already used similar screen recording or periodic screenshot mechanisms, doing small actions on company computers, it’s easy to be traced afterwards.
Rewind recently also released a pendant, this pendant is a recording pen + GPS recorder, recording all day where you went, what was said. I still don’t dare to carry a recording pen with me, because recording private conversations without consent is not very nice. But I indeed carry a mini GPS recorder, marking a point every minute, which can easily record my footsteps. The reason I don’t use my phone is because keeping GPS on all the time on the phone consumes too much battery.
For someone like me who likes to record life, and for those who use products like Rewind, privacy is the biggest concern. Now a lot of Rewind’s data is uploaded to the cloud, which makes me uneasy. I believe localized computing power or privacy computing is the necessary path to solving privacy issues. Localization means running on personal devices locally, currently some high-end phones and laptops can already run relatively small large models. Privacy computing is another method, using cryptographic or TEE methods to ensure that private data is usable but not visible.
Solving Complex Tasks and Using Tools

In the previous section on interesting AI, we discussed the slow thinking aspects of memory and emotions in AI Agents. Memory is a common capability that both interesting and useful AI must possess. Emotions are necessary for interesting AI. Solving complex tasks and using tools are more about capabilities needed by useful AI, so we will discuss this here briefly.
The first example is a complex mathematical problem that a person cannot answer in a second. If we only give a large model a token’s worth of thinking time, letting it answer immediately after hearing the question, it obviously won’t work.
Large models need time to think, and tokens represent this time. We allow the large model to write out its thought process, which is giving it time to think. A thought chain is a very natural mode of slow thinking, which I commonly refer to as “think first, speak later”. This is a very effective way to enhance the performance of large models, especially in scenarios where the output needs to be concise. It’s crucial to let the large model first write out its thought process before formatting the response.

The second example is using multi-step web searches to answer difficult questions. For instance, the question of how many floors David Gregory’s inherited castle has cannot be answered by a simple Google search on one page.
How do humans solve this problem? They break it down into sub-stages: first, search for David Gregory to find out the name of the castle he inherited, then search for this castle to find out how many floors it has.
Before teaching AI to break down sub-problems, we first need to address AI’s hallucination issues. When it searches using the whole sentence, it might find a Wiki entry that mentions the number of floors and might just take this number as the answer, but this isn’t the castle he inherited. Solving hallucination issues can involve not just outputting the number of floors but first outputting the paragraph it references and comparing its relevance to the original question, thus reducing some hallucinations through “think first, speak later” and “reflection.”
How do we teach AI to break down sub-problems? Just tell the large model directly, using a few-shot approach to provide examples of breaking down sub-problems, letting the large model turn the problem into a simpler search problem. Then input the search results and the original question into the large model, letting it output the next search question until the large model believes it can credibly answer the original question based on the search results.

Multi-step web search problem solving is actually a subset of a larger issue, complex task planning and decomposition.
For example, if we are given a paper and asked what contributions the second chapter makes compared to some related work.
First, how does AI find the content of the second chapter? If we don’t have long context but instead search using the RAG method after slicing the article, then each paragraph of the second chapter won’t be labeled as such, making it hard for RAG to retrieve. Of course, I can handle special cases with specific logic, but generally, chapter numbering issues need to be added to the RAG index metadata. Of course, if the model has long context capabilities and the cost is acceptable, putting the entire article in at once is best.
Second, the related work is in another paper; how do we find that paper? Sometimes a single keyword isn’t enough due to too many similarly named entries, so more keywords from the original content need to be combined in the search. After finding this related work, it’s necessary to summarize its content and then use the large model to generate a comparison between Chapter Two and this related work.
Another example of complex task planning and decomposition is checking the weather. Checking the weather seems simple, just click on a webpage. But if we let AutoGPT check the weather for a specific city, it mostly fails. Why?
First, it tries to find some weather APIs, even going so far as to look up these API documents and attempt to write code to call them, but all attempts fail because these APIs are paid. This shows that the large model lacks some common sense, such as that APIs generally require payment, and after trying multiple APIs unsuccessfully, it doesn’t ask the user for help but keeps trying in a dead end. In the real world, when a person encounters difficulties in completing a task, they seek help, and useful AI should do the same, promptly reporting progress to the user and seeking help when there are problems.
After failing to query the API, AutoGPT starts trying to read the weather from web pages. AutoGPT’s search terms and the pages it finds are correct, but it still can’t extract the correct weather information. Because AutoGPT is looking at HTML code, which is messy and hard to understand, and honestly, I can’t understand it either.
AutoGPT also tries to convert the webpage content into text before extracting, but like the weather webpage on the right, there are problems even after extracting the pure text. This webpage has many different temperatures, some for other cities, some for other times, and it’s hard to distinguish based on pure text alone. Text loses too much webpage structural information, and HTML code is hard to understand, so what to do?
A more reliable solution is actually to put the rendered webpage screenshot into a multimodal model. For instance, GPT-4V reading this weather screenshot would not have a problem. But using MiniGPT-4/v2 and other open-source multimodal models is still difficult. Its main issue is that it does not support arbitrary resolution inputs, only supporting small resolutions of 256 x 256, and after compressing a webpage screenshot to such a small resolution, the text on it is simply unreadable. Therefore, it’s crucial that open-source multimodal models like Fuyu-8B support arbitrary resolutions.
From the two examples of searching for papers and checking the weather, we can see that complex task planning and decomposition largely depend on the model’s basic capabilities, which rely on the scaling law. As the model’s basic capabilities improve, naturally, the problems are solved. On the system side, interactive solving of complex tasks with users is very important; AI should seek help promptly when encountering difficulties.

The third example is AI needs to be able to call tools according to a process. Using tools is a very basic capability for AI.
For example, to solve a high school physics problem, you first need to call Google search to obtain relevant background knowledge, then call OpenAI Codex to generate code, and finally call Python to execute the code.
The method to implement tool calling according to a process is few-shot, which means providing AI with a few example tasks in the prompt, allowing AI to refer to the example tasks’ processes and sequentially generate calls for each tool in the process.

The previous page shows the use of three tools in a specified order. But what if we have multiple tools that need to be used as needed according to the task type? There are two typical routes, one is represented by GPT Store, which calls large models for tools, and the other is represented by ChatGPT, which calls tools for large models.
In GPT Store, users have already explicitly specified which tool to use, and the tool’s prompt is pre-written in the GPT Store app. This method actually does not solve the problem of using tools as needed according to the task type.
In ChatGPT, there are several built-in tools such as a browser, image generator, notebook, and code interpreter, and it has written the manuals for several tools into the system prompt.
The ChatGPT model also included special tokens for calling tools during training. If the model needs to call a tool, it outputs a special token for calling tools, so ChatGPT knows that the output following is tool calling code rather than ordinary text. After the tool call is completed, the tool’s result is input into the model, generating the next tool call, or the output for the user.
I tested the ChatGPT system prompt on February 15, 2024:
1 | You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture. Knowledge cutoff: 2023-04 Current date: 2024-02-15 |
This route of ChatGPT indeed solves the problem of using tools as needed according to the task type. But because the prompt’s length is limited, it can only use a few built-in tools, not possibly calling the tens of thousands of tools in GPT Store. Because if the manuals for tens of thousands of tools were all spread out on the table, it would be too long.
So how do we teach large models to automatically use tens of thousands of tools as needed? There are two viewpoints here.
The first viewpoint believes that tool use belongs to procedural memory, and the scenarios and conditions for use are not something that can be clearly described in language. The method of using the tool itself can indeed be clearly described in language, which is the manual, but the key is when to use which tool. For example, GPT-4 often calculates incorrectly, so it needs to know to call the calculator tool when doing calculations. This requires using the fine-tuning method to tell the model some examples of tool use, even incorporating them during pre-training. The main disadvantage of this approach is that tool updates are complex, and updating tools requires redoing fine-tuning.
The second viewpoint believes that tool use can be expressed in code form, thus belonging to code generation capability. This way, it can use the RAG method to match the user’s input text, find a candidate toolset, and put the tool’s manual into the prompt like ChatGPT, and then it can be used. The main disadvantage of this approach depends on the accuracy of RAG. Additionally, if the tool is needed temporarily during the output process, this method does not work. For example, in the case of GPT-4 calculating incorrectly, the user’s input text may not explicitly require it to do calculations, but the process of solving the problem requires calculations, and at that time, it definitely does not know to call the calculator tool.

Hallucination is a fundamental problem for large models, and larger models will have relatively fewer hallucinations. The fundamental elimination of hallucinations still relies on the scaling law, relying on the progress of the basic model. But there are also some engineering methods to reduce the hallucinations of existing models. Here are two typical methods: factual checking and multiple generations.
Factual Checking involves first using the large model to generate an answer, then using the RAG method with a search engine, vector database, inverted index, or knowledge graph to find original corpus material that matches the answer content, and then sending the answer content and the original corpus into the large model to let the large model judge whether the answer matches the original corpus.
The factual checking method has two problems: first, there are many types of hallucinations, and factual checking can only detect fabrications but cannot detect irrelevant answers. For example, if I ask what the capital of China is, and it answers that China is a country with a long history, factual checking can’t find fault with that, but it doesn’t correctly answer the question. Second, the content of the original corpus is not necessarily factual, as there is a lot of inaccurate information on the internet.
Multiple Generations was proposed in the paper on SelfCheckGPT. The idea is quite simple: generate multiple answers to the same question and then let a large model pick the most consistent one. The multiple generation method can solve sporadic hallucination issues but not systematic biases. For example, if you ask GPT-3.5 Turbo to tell the story of “Lin Daiyu pulling up willows,” it will almost always make up a similar story, without realizing that this event never historically occurred. This type of hallucination is difficult to eliminate with multiple generations.
AI Agent: Where is the Road Ahead?
Which is More Valuable: Entertaining AI or Useful AI

We just discussed the aspects of entertaining AI and useful AI. Which one holds more value?
I believe in the long term, usefulness holds greater value, but in the short term, entertainment is more valuable. This is why we choose entertaining AI in our business model while continuously exploring useful AI.
For instance, voice chatting for one yuan per hour is already challenging, and Character AI might have tens of millions of users, but its actual monthly revenue is only tens of millions of dollars, mostly from non-paying users. However, some online education or even more professional fields like psychological counseling or legal advice might generate higher income, but the key issue here is the need for quality and brand to create higher added value.
Looking further ahead, our ultimate goal is AGI, which will definitely be more useful, extending the boundaries of human capabilities, enabling humans to accomplish previously impossible tasks.
However, as for the current capabilities of foundational models, useful AI is far from truly solving complex problems or extending the boundaries of human capabilities, only reaching a basic level, not an expert level. Also, due to hallucination issues, it’s difficult to use in scenarios requiring high reliability. These problems are hard to completely solve with external systems and can only wait for improvements in foundational models. Therefore, the most suitable role for useful AI currently is as personal assistants for life, work, and learning, more fitting for smartphone manufacturers, operating system providers, and smart hardware manufacturers.
Meanwhile, the basic capabilities of large models are already sufficient to create many interesting AIs. As mentioned earlier, the attractive appearance and interesting souls of entertaining AI are mostly due to an external system, not the basic capabilities of the model itself. For example, no matter how good the basic capabilities of a text-based large model are, it can’t achieve a 1.5-second voice call delay, long-term memory, or agent social interactions. This external system is the moat for AI companies.
Of course, some might say, I’ll create an end-to-end multimodal large model that supports ultra-long contexts at a sufficiently low cost, solving latency and memory issues. I think it’s certainly better if the foundational model can achieve this, but it’s uncertain when this will be available. Products can’t wait for future unknown technologies; current engineering solutions are quite useful and indeed have a certain technological moat. When the new model comes out, we can just change the tech stack. Like we used VITS for a complete pipeline of voice data auto-cleaning and training, GPT-soVITS came out, and using 1-minute voice zero-shot was much better than using several hours of voice fine-tuning with VITS, making most of the features in the original pipeline redundant.
Some people have biases against “entertaining AI,” mainly because products like Character AI, which represents this category, are not yet well-developed. Character AI repeatedly emphasizes that it is a foundational model company, and the beta.character.ai application is still on a beta domain, indicating it’s a test version of the product. People see it as the largest to-C application besides ChatGPT and assume it’s a good product form, leading to numerous clones and improved versions of Character AI.
Influenced by Character AI, many believe that an entertaining AI Agent is equivalent to digital avatars of celebrities or anime/game characters, with the sole interaction being casual chat. But many get this wrong. If it’s just casual chat, users can easily run out of things to talk about after 10-20 minutes, resulting in terrifyingly low user stickiness and willingness to pay.
In early January 2024, I attended a Zhihu AI Pioneers Salon, and one guest’s remarks made a lot of sense: entertaining AI holds higher value because entertainment and social interaction are human nature, and most of the largest internet companies are in the entertainment and social sectors. If a good AI companion can truly bring emotional value to people, or if AI in games can enhance users’ immersion, such AI won’t lack paying users.
Cost

A major challenge in the widespread application of large models is the cost issue. For example, if I create a game NPC that continuously interacts with players, using GPT-4 would cost up to $26 per hour per player, which no game can afford.
How is this calculated? Assume a player interacts 5 times per minute, which is 300 times per hour; each interaction requires an 8K token context and a 500 token output, making the cost per interaction $0.095; multiply this, and the cost is $26 per hour. Many people only consider the output tokens when calculating costs, not realizing that in many scenarios, input tokens are the main cost.
So, is it possible to reduce this cost by 100 or even 1000 times? The answer is definitely yes.
We mainly have three directions: using smaller models instead of large models, optimizing inference infra, and optimizing computing platforms.
First, most problems in to-C applications are actually sufficient with small models. But some complex problems can’t be solved by small models, and that’s when large models are needed. Our human society has always worked this way, like how ordinary call center agents are enough to handle most issues, with only a few tough problems escalated to managers to reasonably control costs.
Combining large and small models faces the challenge of overcoming the hallucinations of small models, that is, when they don’t know something, they shouldn’t spout nonsense but should say they don’t know, giving a chance for larger models to handle it.
Second, there are many points worth optimizing in inference infra. For example, many open-source multimodal models currently do not support batching and Flash Attention, and their GPU utilization is not high enough. When we have many LoRA fine-tuned models, some recent academic work can achieve batch inference of numerous LoRAs. Persistent KV Cache, although many mention it, no open-source software has truly implemented it as a stateful API to reduce the cost of recalculating each time.
Lastly, building our own computing platform using consumer-grade GPUs for inference. For models that fit within 24 GB of memory, the 4090 is obviously more cost-effective than the H100 and A100.

How much cost can be saved using open-source models and building our own computing platform? Here we compare the costs of closed-source GPT-4, GPT-3.5, and open-source Mixtral 8x7B and Mistral 7B, both on third-party API services and our own computing platform.
Assuming our needs are 8K token input context and 500 token output. If we use GPT-4, every 1000 requests would cost $135, which is quite expensive. If we use GPT-3.5, it would be 15 times cheaper, only $9, but that’s still quite expensive.
The Mistral 8x7B MoE model’s capabilities are roughly equivalent to GPT-3.5, and using Together AI’s API service would need $5, half the price of GPT-3.5. If we build an H100 cluster to serve this 8x7B model, the price could be reduced by more than half, to just $2.
So why is serving it ourselves cheaper than using Together AI? Because any cloud service must consider that resources are not 100% occupied, and user requests have peaks and troughs, with an average resource utilization rate of 30% being quite good. For small companies like ours with highly fluctuating computing needs, it’s common to rent dozens of GPU cards but have them idle for a month. Therefore, if considering the peaks and troughs of user requests, building an H100 cluster to serve the 8x7B model might not be cheaper than calling an API.
To further save money, we could use the 7B model, which also performs well, especially the Starling model based on Mistral 7B developed by UC Berkeley using RLAIF’s method, even outperforming the LLaMA 13B model.
If using Together AI API for the 7B model, it only costs $1.7, 5 times cheaper than GPT-3.5. If built on a 4090, it’s only $0.4, 4 times cheaper again. The main reason it’s so much cheaper is that large manufacturers generally use data center-level GPUs for inference, and if we use consumer-grade GPUs, the cost can be at least halved compared to data center GPUs.
Running the 7B model on a 4090 costs 23 times less than GPT-3.5 and 346 times less than GPT-4. The original $26 per hour interactive game NPC, using a 4090 and 7B model, can be done for $0.075 per hour, which, although still a bit high, is now acceptable. Adding some input context compression technology can reduce the cost of the 7B model to one-thousandth of the GPT-4 API, or $0.026 per hour, which is now acceptable.
At the $0.026 per hour level, CPU costs also become non-negligible, so software optimization on the CPU is also very important. Most companies’ backend services are written in Python, which, although highly efficient in development, has relatively low execution efficiency. Therefore, our company recently switched the core business logic of the backend to Go, significantly improving CPU efficiency.
We’ve only calculated text models so far, but speech recognition models, speech synthesis models, multimodal image recognition models, image generation models, and video generation models also have many points that can be optimized.
Earlier, when discussing speech synthesis, we mentioned that making our own speech synthesis model based on open-source VITS can be 360 times cheaper than the ElevenLabs API. If achieving near ElevenLabs quality voice cloning with GPTs-soVITS, it can also be 100 times cheaper than ElevenLabs. This magnitude of cost reduction can fundamentally change the business logic.
For instance, in video generation, OpenAI’s Sora costs about $50 to generate a 1-minute video, while Runway ML’s Gen2 costs about $10 for the same. However, if we don’t need such high quality, using Stable Video Diffusion to generate a 1-minute video only costs $0.50 if run on a 4090 GPU for an hour. The video quality of Sora is much higher than SVD, and perhaps the 100 times cost is justified. But the video quality produced by Runway ML may not be worth 20 times the cost.
This is why I do not recommend rashly attempting to develop foundational models yourself. Without the capability to compete with OpenAI or Anthropic in terms of effectiveness, you cannot surpass the best proprietary models, nor can you compete on cost with open-source models. I believe the inference cost for Runway ML’s Gen2 won’t be much higher than Stable Video Diffusion, and the same goes for ElevenLabs’ speech synthesis compared to GPT-soVITS. However, the R&D costs for these models are frighteningly high, and this is reflected in the premium pricing of their APIs.
This aligns with what Peter Thiel said in “Zero to One,” a technology needs to be 10 times better than the existing technologies to have a monopolistic edge; just being slightly better is not enough. I know operating systems are important, and I know how to write one, but I don’t know how to create one that is 10 times better than Windows, Linux, or Android/iOS, so I won’t attempt to create an operating system. The same logic applies to foundational large models.
We believe the cost of large models will rapidly decrease, partly due to Moore’s Law and partly due to advancements in large models, such as using the latest vLLM framework and consumer-grade GPUs, Mistral AI’s 8x7B MoE model might reduce costs by 30 times compared to the earliest LLaMA 70B.
As hardware and models improve, could models of equivalent capability run on mobile devices in the future? If a model with the capabilities of GPT-3.5 could run on a smartphone, many possibilities would open up.
Consider the output speed and context capacity of models. When I visited the Computer History Museum, I saw the ENIAC, a huge machine cabinet that could only perform 5000 additions per second and had only 20 words of memory. Today’s large models can only output a few dozen tokens per second, and the “memory,” or context length, has increased from the initial 4K tokens to hundreds of thousands of tokens today.
Could there be a day in the future when a set of hardware and a model could output tens of thousands of tokens per second, with a context of hundreds of millions of tokens?
Someone asked, what’s the use of such fast output? In fact, an AI Agent doesn’t necessarily need to communicate with humans very quickly, but it can think very quickly and communicate with other Agents very quickly. For example, a problem that requires multiple steps of web search to solve might take an hour for a human, but could future AI solve it in just one second?
Having so many tokens in context, what’s the use? We know that large models are still not as good as humans in many aspects, but in terms of long context, they are actually stronger than humans. We mentioned earlier the needle in a haystack test, reading a book of hundreds of thousands of words in a few dozen seconds and being able to answer almost all the details, something humans absolutely cannot do. If a long context of hundreds of millions of tokens could be achieved, and the cost and latency were acceptable, it would be possible to put the knowledge of a field or all the memories of a person into the context, giving it superhuman memory capabilities.
We all believe AGI will definitely arrive, the only debate is what the growth curve to AGI will look like, whether this wave of autoregressive models will grow rapidly to AGI according to the scaling law, or whether this wave will also encounter bottlenecks, and AGI will have to wait for the next technological revolution. Ten years ago, when ResNet sparked the CV revolution, many were overly optimistic about AI’s development. Is this wave of Transformers the smooth path to AGI?
Superintelligence
Elon Musk has said that humans are the boot loader for AI, which might be a bit extreme, but future AI could far surpass human levels. OpenAI predicts that within the next 10 years, AI’s intelligence level could surpass that of humans, which is what is meant by superintelligence.
There are two views on such superintelligence: effective acceleration and super alignment.
The effective acceleration camp believes that AI technology is neutral, and the key lies in the people using it, developing AI technology is definitely beneficial for humanity, there is no need to impose special restrictions on the development of AI technology. Many tech leaders in Silicon Valley hold this view, such as Elon Musk and the founders of a16z, and some effective accelerationists even add the suffix e/acc to their social media accounts, which stands for effective acceleration.
An extreme view within the effective acceleration camp is that AI will eventually replace humans, somewhat like the Adventists in “The Three-Body Problem”. The effective acceleration camp believes that the human body has many physical limitations; we need to eat, drink, breathe, and cannot withstand high accelerations, making us unsuitable for interstellar migration, thus silicon-based may be a more suitable form of life than carbon-based. In fact, even just traveling between China and the USA, even with direct flights, takes 12-15 hours one way, while data travels back and forth in just 170 milliseconds. I really hope Elon Musk’s Starship can reduce the physical transport delay from several hours to 45 minutes, but that seems far off. Maybe our digital lives will have been achieved, and Starship has not yet been commercialized on a large scale.
The effective acceleration camp also believes that, apart from the physical limitations of the body, human society’s values also have many flaws, some of which are related to the limited intelligence level of humans. For example, before World War I, there was actually no international standard passport and visa, and most people could theoretically migrate freely across countries, with inconvenient transportation being the main barrier; while today, with such developed transportation, many people cannot travel due to a visa. We once thought the digital world was free, but the current digital world is becoming more centralized, and the internet is gradually Balkanizing for the interests of different countries. Should we let superintelligence follow such values? Therefore, the effective acceleration camp believes that superintelligence should not be constrained by human values. Superintelligence looking at our human society might view it as we today view feudal society.
The super alignment camp, on the other hand, believes that AI must serve humanity, and AI is like a nuclear bomb; if uncontrolled, it will definitely threaten human survival. OpenAI has proposed establishing an organization similar to the International Atomic Energy Agency to control the development of AI to prevent it from threatening humanity. OpenAI’s Chief Scientist Ilya Suskever is a representative of the super alignment camp, and the term super alignment was even coined by OpenAI.
Super alignment aims to ensure that AI, more powerful than humans, always follows human intentions and obeys human commands. This seems unlikely, how can a weak intelligence supervise a strong intelligence?
OpenAI’s super alignment team director Jan Leike has a famous assertion, evaluation is easier than generation. That is, although humans may not match superintelligence, humans can evaluate which of two superintelligences speaks better and whether it conforms to human values. In fact, it’s easy to understand that evaluation is easier than generation in everyday life; evaluating whether a dish tastes good doesn’t mean I have to become a chef, and evaluating whether a course is well taught doesn’t mean I have to become a professor.
OpenAI’s key alignment method for large models, RLHF, involves hiring a large number of data annotators to score and rank the content generated by the model, aligning the large model’s way of speaking and values with humans. Since evaluation is easier than generation, RLHF could potentially be extended to superintelligence, making it one of the simplest implementations of super alignment.
Open Source vs. Proprietary
In the short term, the best models are definitely proprietary. First, companies like OpenAI and Anthropic that spend a lot of money training models have no reason to open-source their best models. Secondly, under the current scaling law, training the best models definitely requires a lot of computing power, which is not something schools or open-source communities can achieve.
But does this mean open-source models have no value? Not at all, because in many scenarios, open-source models are already sufficient. For example, in entertainment scenarios where simple role-playing Agents are used, even the strongest models in the open-source community are not necessary; a 7B model is enough. In these scenarios, low cost and low latency are more critical.
Even if a company has enough money to train foundational models, if its talent and computing resources are not on the level of OpenAI or Anthropic, it is not advisable to reinvent the wheel, because most companies’ foundational models are still not as good as Mistral models of the same size, meaning that proprietary training ends up being less effective than open-source, wasting a lot of computing power.
Moreover, if a company lacks foundational model capabilities, like us currently without the resources to train foundational models, building on open-source models can also make it easier to build a technological moat. For example, the core technologies we mentioned earlier:
- Building an agent that is more like a person based on fine-tuning rather than prompts;
- Inference optimization to reduce costs and latency;
- Implementing multimodal capabilities for understanding and generating speech, images, and videos, where the cost and latency of proprietary APIs are not ideal;
- Memory based on Embedding, such as LongGPT;
- Working memory and streaming inference based on KV Cache, such as multiple Agents arguing in speech, end-to-end streaming speech models;
- Local deployment, including to-B scenarios with data security needs, personal terminal devices, and robots with privacy requirements.
Another important issue is that Agents built on open-source models can truly be owned by users. If the proprietary model is shut down one day, the Agent can no longer run. Only open-source models will never be shut down or tampered with. We can say that computers are truly owned by users because as long as they are not broken, they can be used simply by being powered on, without needing to connect to the internet. Open-source AI Agents are the same; as long as I buy a GPU, I can run the model without needing to connect to the internet. Even if Nvidia stops selling us GPUs, other computing chips can replace them.
If there really are digital lives in the future, whether the fate of digital lives is in the hands of a single company or each person has complete control is crucial for the fate of humanity.