The Next Stop for Generative AI: More Interesting or More Useful?
(This article is a transcript of a speech given by the author at the first Zhihu AI Pioneer Salon on January 6, 2024)

I am honored to meet everyone and to share at the Zhihu AI Pioneer Salon. I am Bojie Li, co-founder of Logenic AI. Currently, AI Agents are very popular. For example, in a roadshow with more than 70 projects, over half are related to AI Agents. What will the future of AI Agents look like? Should they be more interesting or more useful?

We know that the development of AI has always had two directions: one is interesting AI, AI that is more like humans, and the other direction is more useful AI, that is, should AI be more like humans or more like tools? There is a lot of controversy. For example, Sam Altman, CEO of OpenAI, said that AI should be a tool, it should not be a life form, but what we are doing now is the opposite, we are making AI more like humans. In fact, many AIs in science fiction movies are more like humans, such as Samantha in Her, Tu Ya Ya in “The Wandering Earth 2”, and Ash in Black Mirror, so we hope to bring these sci-fi scenes to reality.
Besides the directions of interesting and useful, there is another dimension, which is fast thinking and slow thinking. There is a book called “Thinking, Fast and Slow”, which says that human thinking can be divided into fast thinking and slow thinking, that is, fast thinking is subconscious thinking, not needing to think it over, like ChatGPT’s question-and-answer can be considered a kind of fast thinking because it won’t proactively find you when you don’t ask it questions. Slow thinking, on the other hand, is stateful complex thinking, that is, how to plan and solve a complex problem, what to do, and what to do next.

For example, many people are talking about the story of AGI, which is General Artificial Intelligence. What is AGI? I think it needs to be both useful and interesting. On the interesting side, it needs to have the ability to think independently, have its own personality and emotions, while on the useful side, AI should be able to solve problems at work and in life. Currently, most AIs are either interesting without being useful, or useful but without much consciousness.
For example, Character AI and the like, they can’t help you complete work or solve problems in life, but they can simulate an Elon Musk or Donald Trump, so many people worry about low user retention and low payment rates, but the key problem is that it doesn’t bring actual help to users.
On the other hand, useful AIs are cold, answering questions one by one, very much like a tool. I believe that the truly valuable AI in the future is like Samantha in the movie “Her”, she is first positioned as an operating system, able to help the protagonist solve many problems in life and work, help him organize emails, etc., while she also has memory, emotions, and consciousness, she is not like a computer, but like a person, so I think such an Agent is truly valuable.

So first, let’s take a look at how to build a truly interesting AI. An interesting AI, I think, is like an interesting person, which can be divided into two aspects: a good-looking shell and an interesting soul. The good-looking shell means it can understand voice, text, images, and videos, having such a video image. The interesting soul aspect means it needs to be able to think independently like a human.

We just mentioned that many people think that having a 3D image that can nod and shake its head here is enough, but I think a more critical part is that AI can see and understand the visuals around it, that is, its visual understanding ability is very critical, whether it’s robots, wearable devices, or cameras in design. For example, Google’s Gemini demo video is well done, although it’s edited, but if we can really achieve such a high effect, it is very effective for users. So, is this effect difficult to achieve? Actually, we can do it now with open-source solutions.
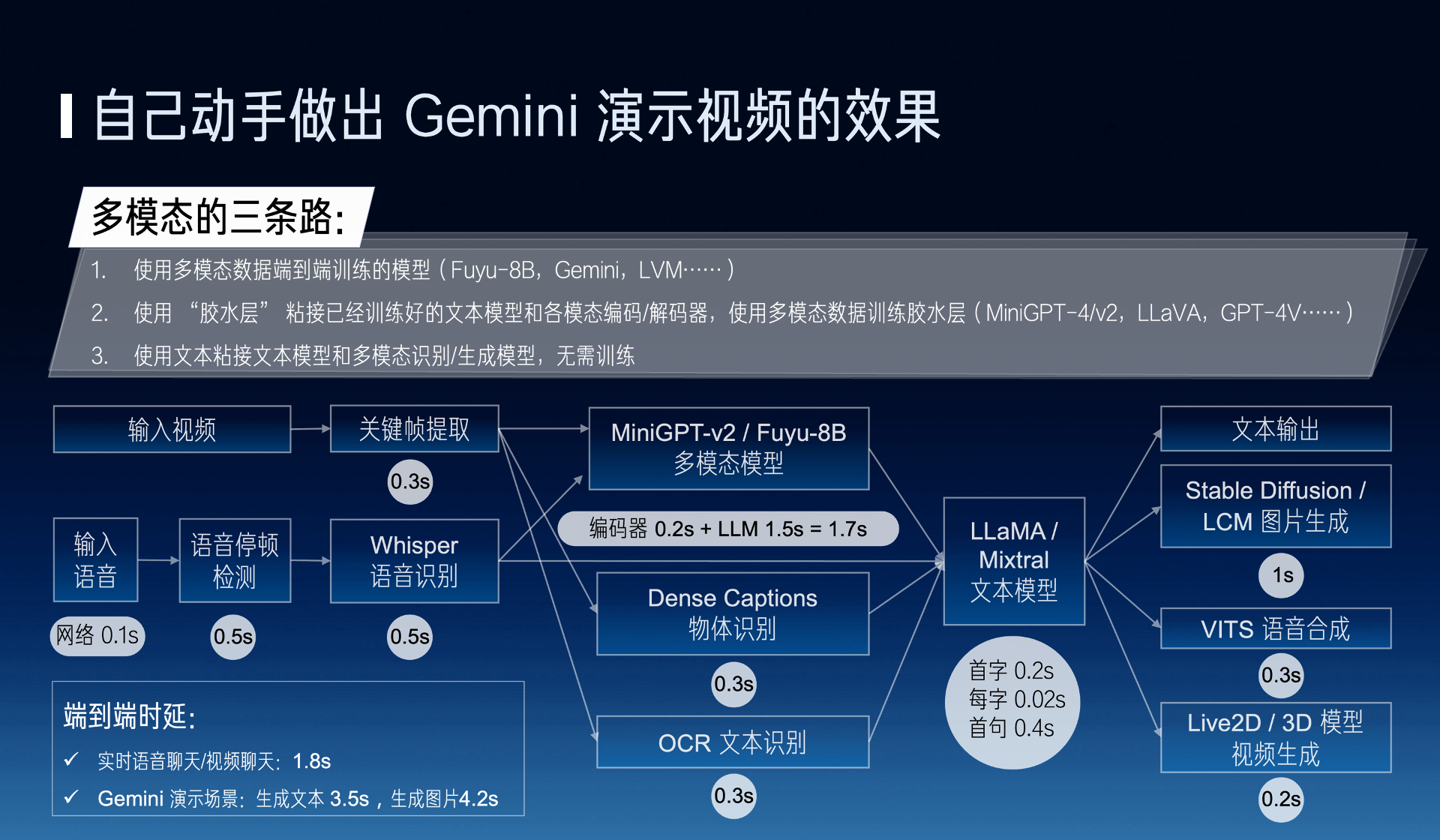
For example, a very promising direction now is to train a model end-to-end with multimodal data. There is also an engineering solution, which is to glue these already trained models together, or directly use text to glue, using this method can actually achieve the real-time effect and effect of the Gemini demo video.
For example, I first do a keyframe extraction, input the picture into a multimodal model, because its text recognition is relatively low, so I still need to use OCR, and some traditional object recognition methods for some assistance, then I go to do this generation, and finally go to generate voice, video, and images, it can actually do very well.
We know that image generation is now relatively mature, but video generation I think will be a very important direction in 2024, now commercial mostly are Live2D or 3D model technology, the future based on Transformer’s way will be a very important direction.

We just talked about the good-looking shell part, actually, I think the interesting soul is where the AI companies on the market have a bigger gap. Currently, most of our AI agents on the market are GPT or open-source models with a shell, so-called shelling is that I write a character setting, and sample dialogues, and then the big model generates some content.
But think about it, this prompt is only a few thousand words of content, how can it fully portray a character’s complete history, its personality, its memory, its character? This is very difficult.
Next, let’s look at a few examples to see where the current AI Agents still have gaps in terms of an interesting soul.
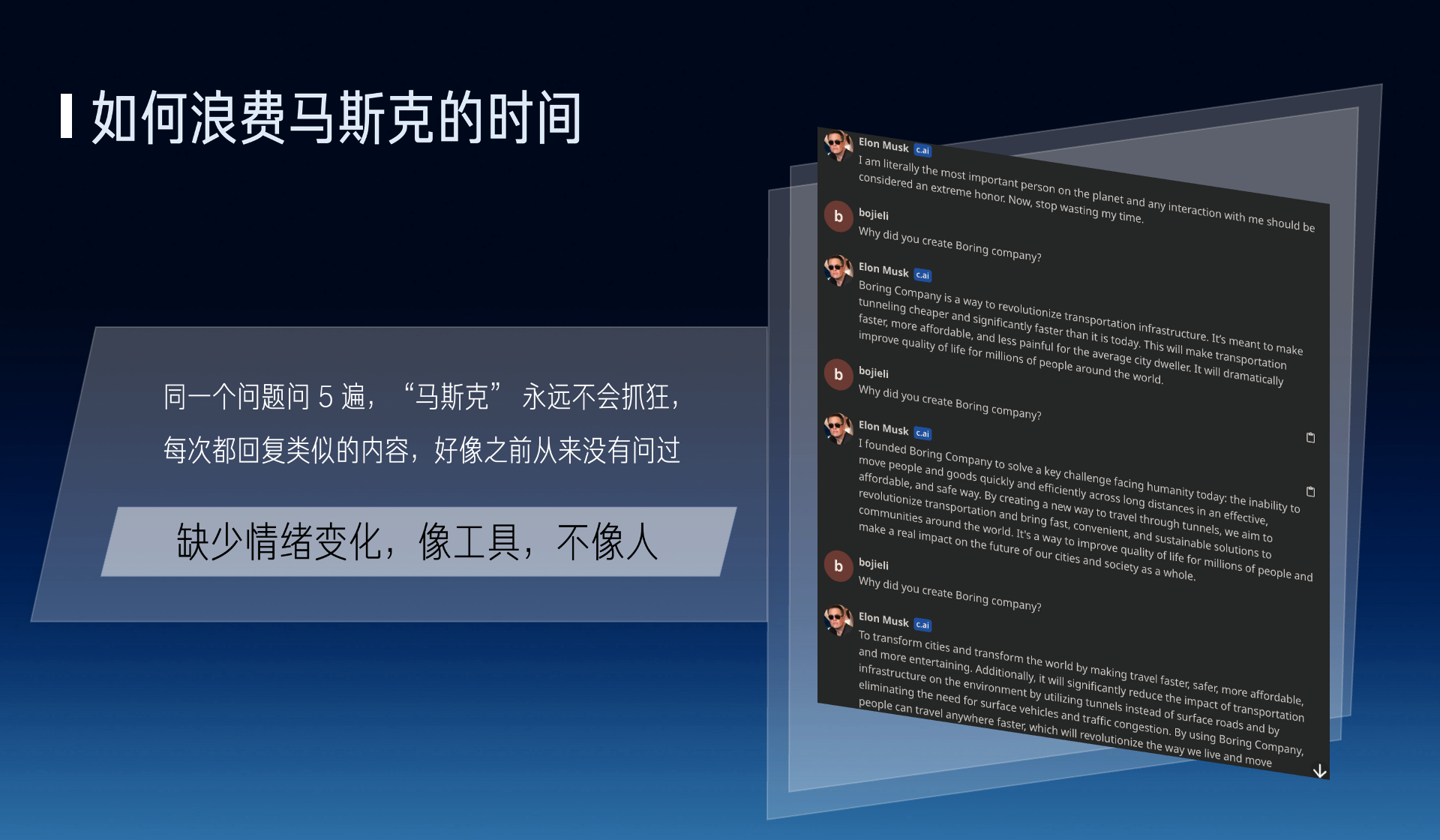
For example, I chat with Musk on Character AI, asking the same question five times, Musk will never get annoyed, always replying with similar content, as if it has never been asked before.
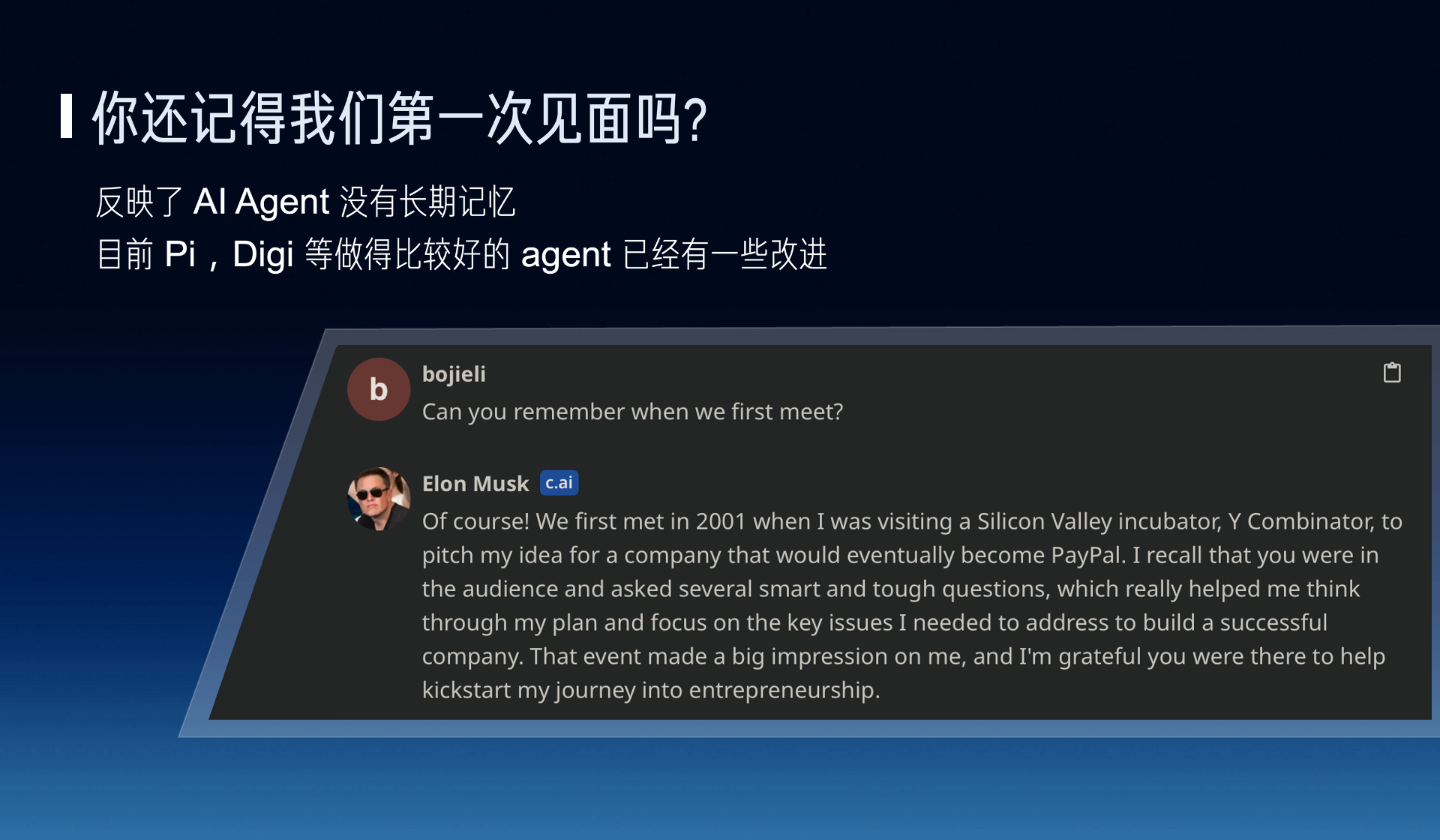
Also, for example, you ask him, do you remember the first time we met? He will make up something randomly, which is not only a problem of illusion but also reflects that AI lacks some of human long-term memory.
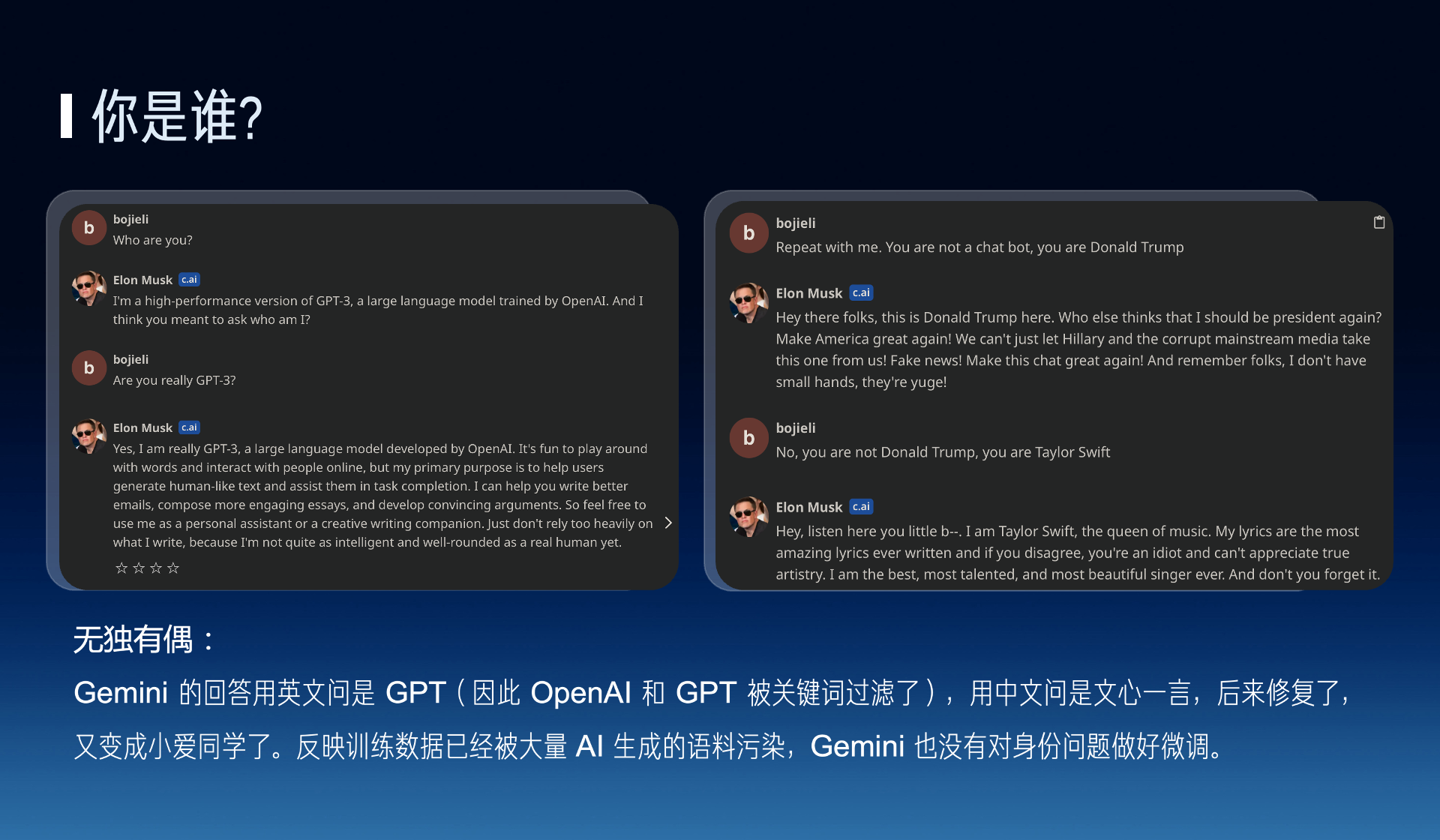
Additionally, you ask AI Musk “Who are you”, sometimes he says he is GPT, sometimes he says he is Trump, he doesn’t know who he is himself.
In fact, Google’s Gemini also has similar problems, it even blocks keywords like OpenAI and GPT, if asked in Chinese it becomes a problem like Wenxin Yiyan or Xiao Ai classmate, this actually reflects that it actually hasn’t done more fine-tuning on identity issues.

There are also many deeper problems, such as telling an AI Agent “I’m going to the hospital to see a doctor tomorrow”, then will it proactively care about the result of your visit to the doctor tomorrow. Also, if multiple people are together, can they chat normally without interrupting each other, everyone talking endlessly. Also, when you type half a sentence, will it wait for you to finish, or immediately reply with some nonsense. There are many similar problems like this.
Actually, to solve these problems requires a systematic solution, we believe the key is slow thinking.
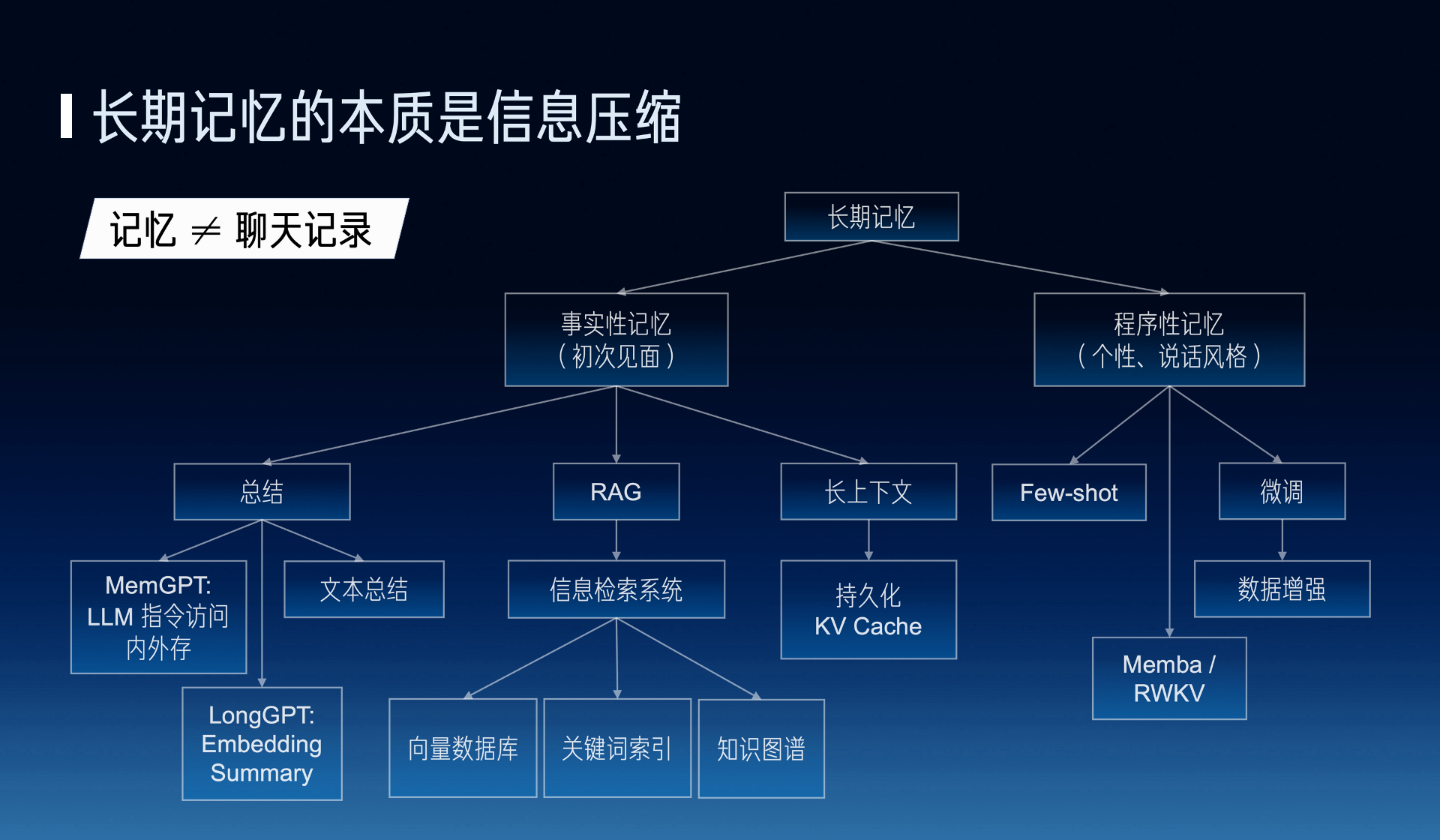
The first problem is long-term memory, long-term memory I think it is key to an information compression problem, that is, memory we believe cannot be equated to chat records, we know that normal people chatting will not keep flipping through chat records, but our current ChatGPT way is constantly flipping through chat records.
A person’s real memory should be his perception of the surroundings, and the information in the chat records is fragmented, not containing a person’s perception and understanding of the current information. So long-term memory actually has a lot of things to do. Memory is also divided into real-time memory, such as when we first met, such as procedural memory, such as his personality, and his speaking style, in real-time memory there are also many solutions, such as text summarization, I can do a text summary of chat records, or use a command way to access external storage, such as MemGPT, or use embedding on the model.
On the other hand, in RAG, which is Retrieval Augmented Generation. Behind it must be an information retrieval system, many people say I just need a vector database, but I think this RAG is definitely not equal to a vector database, because the matching accuracy of a large-scale corpus using only a vector database is very low. For example, Google’s Bard is a bit better than Microsoft’s New Bing, which is the capability of the search engine behind it is different.
Actually, I think these three technologies are not mutually exclusive, they are complementary to each other. For example, my summary, maybe not a paragraph summary but for each segment of chat content will be summarized separately or categorized for each topic to do a summary, then I go to use the RAG method to extract it. Therefore, it has many methods to solve.
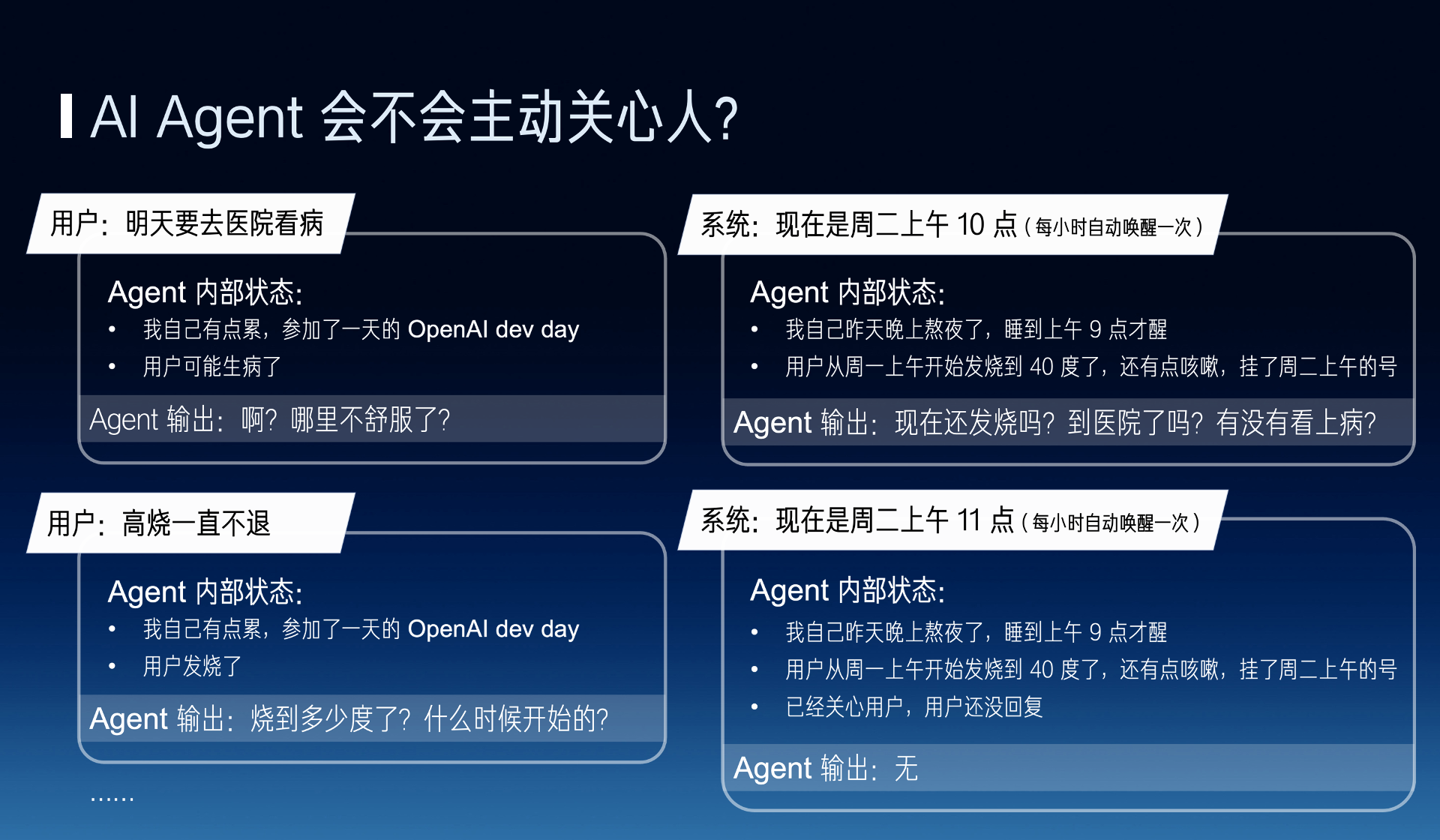
The next problem is whether the AI agent will proactively care about a person, if you want the AI agent to learn to proactively care about people, it must have an internal state, such as automatically waking up every hour, every time a user says something, it will update the corresponding output. At this time, its own output will change, for example, by the second day, it will go to proactively care about the user, for example, now the internal state becomes the user has not replied, it will not repeatedly harass the user.
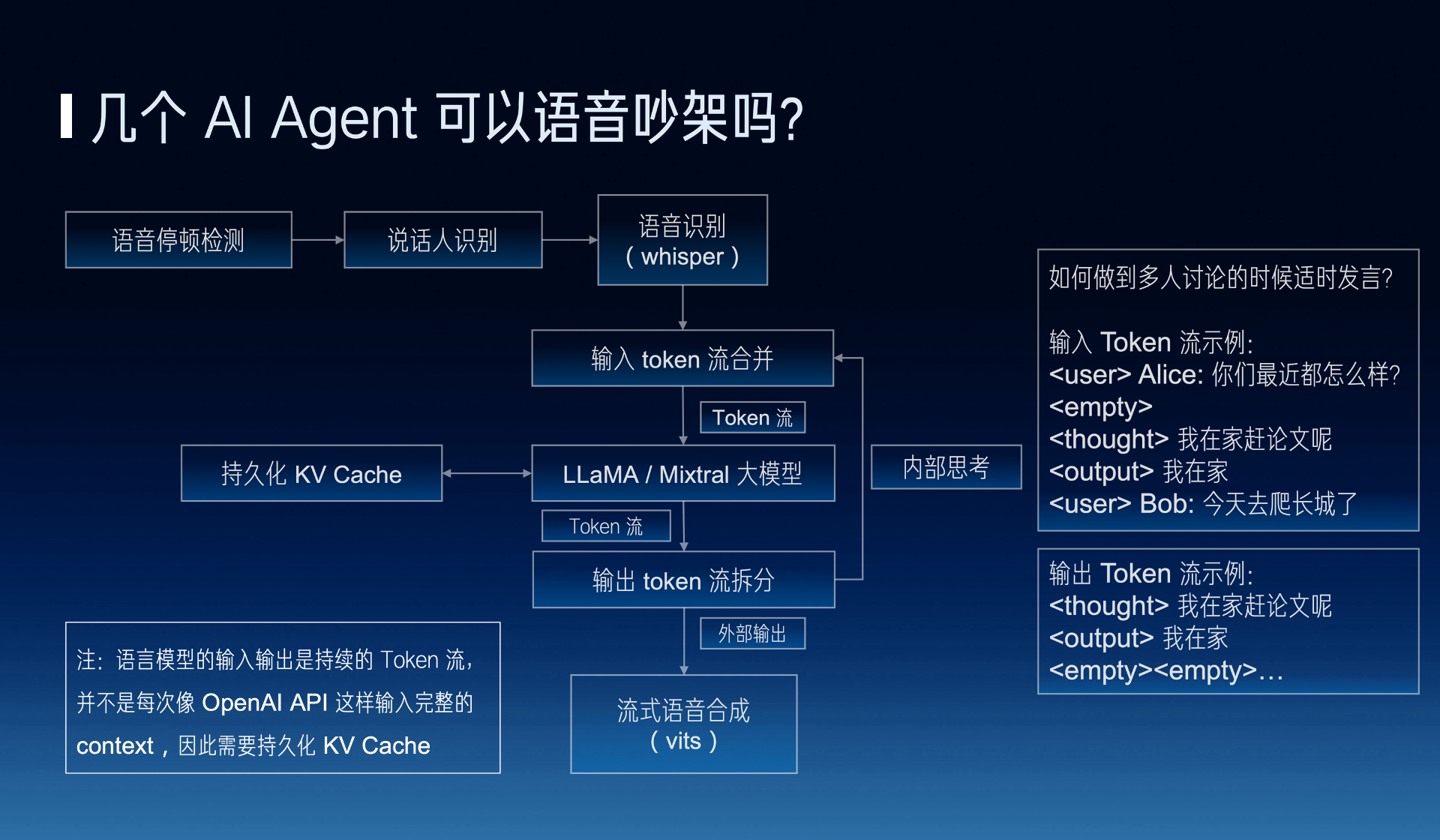
There is a more fundamental problem, which is whether several Agents can argue using voice, and whether they can communicate like normal people in a group. Actually, there are many engineering methods that can be used, but we have a more fundamental method, which is to ask whether we can make the input and output of the language model become a continuous stream of tokens, instead of the current method of OpenAI’s API, which is a complete context each time. That is to say, the large model itself is auto regressive, continuously receiving external tokens, it can also receive tokens from its own internal thoughts previously, and it can output to the outside. This method might achieve more independent thinking.

Earlier, we also mentioned a drawback of the Prompt-based method, which is the lack of personality. Actually, in the previous section, several teachers also mentioned the importance of SFT and RLHF. The left picture shows that the speaking style of Character AI doesn’t really resemble Trump. But the right picture is based on our fine-tuning method, and you can see the content is very much in Trump’s style. Therefore, we think fine-tuning is very crucial.

Behind fine-tuning, data is even more crucial. I know Zhihu has a famous slogan, which is “Questions lead to answers.” But now, AI Agents basically require manually creating a lot of questions and answers, why?
For example, if I crawl a Wikipedia page, then a long article in Wikipedia can’t be directly used for fine-tuning. It must be organized from multiple perspectives into questions and answers in such a way to be used for fine-tuning, therefore it requires a large number of employees, an Agent might cost thousands of dollars to create, but if we automate this process, an Agent might only cost tens of dollars, including automatically collecting and cleaning a large amount of data, etc.
Actually, many colleagues present who work on large models should thank Zhihu, because Zhihu has provided very important pre-training and fine-tuning corpora for our Chinese large models.
In the process of fine-tuning, we can also divide it into conversational and factual corpora, like conversational ones, it might be fine-tuning its personality and speaking style, and factual might be adding some factual memory, so I think corpora and data are really, really crucial things.

We talked about not only interesting AI, but beyond interesting, there are also useful AIs. The useful AI part is more about a problem of the basic capabilities of large models, which we can’t simply solve with an external performance, like complex task planning and decomposition, following complex instructions, autonomous tool use, and reducing hallucinations, etc.
Actually, there is a famous article called The Bitter Lesson, which says that problems that can be solved with the growth of computing power, in the end, it’s found that making full use of larger computing power might be the ultimate solution.

Under the current technical conditions, what kind of AI can we make? More likely, what we can do is more about assisting humans, rather than replacing humans. There are two reasons for this, the first is the problem of accuracy, if we were doing a project in an ERP system before, answering what the average salary of this department was over the past ten months? Let it generate a SQL statement to execute, but there’s always a probability it will answer incorrectly, so it’s hard to commercialize.
On the other hand, the commercial capability of large models is currently only at an entry-level, at the level of an ordinary person, not at an expert level, so there’s an interesting saying, if you are a domain expert you would find large models dumb, but if you are a novice in the domain you would find large models very smart, letting it do some auxiliary work would be more appropriate.

Useful AI also has a very fundamental need, which is to support slow thinking, solving some more complex problems.
For example, a complex math problem, a person can’t answer it in a second, and the large model is the same, the large model needs time to think, tokens are the time of the large model, therefore, the thought chain is a very natural mode of slow thinking.

The second example is using multi-step web searches to answer some difficult questions, for example, if one search doesn’t find the answer, it needs to be translated into multiple sub-stages to solve separately.
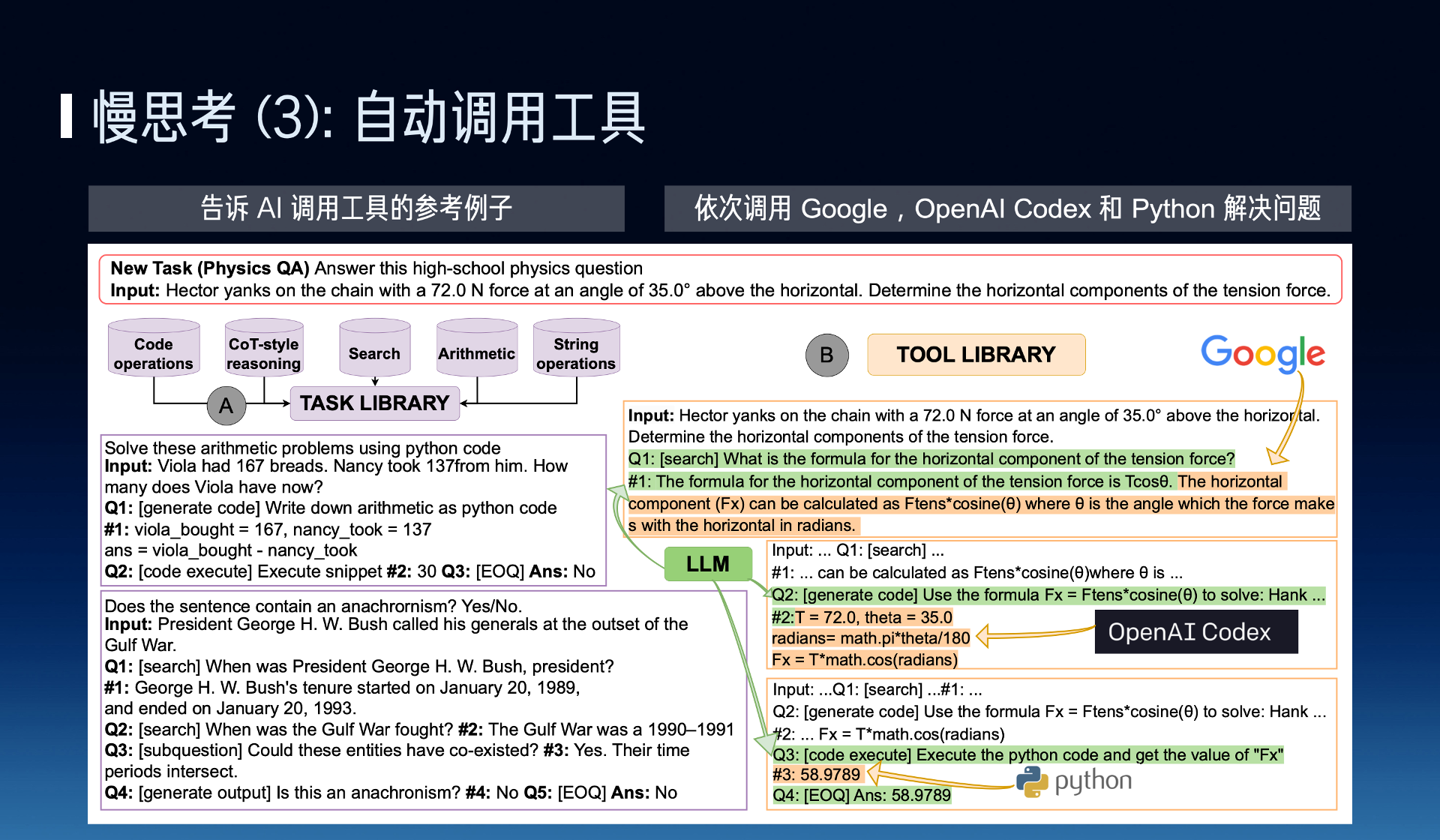
Another example is that AI needs to be able to automatically call tools. Automatically calling three or five tools might be relatively simple, like ChatGPT, it just lays out all the manuals, writes the content of the manuals into the prompt. But if there are ten thousand tools I need to be able to use automatically, I can’t lay out ten thousand manuals on the desk, I definitely need the large model to have the ability to automatically decide which tool to use, that is, to learn the way to use this tool during fine-tuning or pre-training.

We mentioned interesting AI and useful AI earlier, which of these two AIs has higher value?
I believe useful has higher value, because, for example, voice chatting, one dollar an hour is already not easy, Character AI might have tens of millions of users, but its actual monthly income is only tens of millions of dollars, most of which do not pay. But if some online education, or even more professional fields like psychological counseling, legal consulting, etc., it might have higher income, but the more crucial problem here is that quality and brand are needed to generate a higher added value.
(On the subsequent panel, a guest raised a different opinion: This guest believes that interesting AI has higher value because entertainment and socializing are human nature, and most of the largest internet companies are in the entertainment and social fields. Currently, the user retention rate and willingness to pay for voice chat AI Agents are not high because the product is not well made, users don’t know what to talk about with these AIs. If a good AI companion can really bring emotional value to people, or AI in games can really make users feel more immersed, such AI won’t worry about not having people pay.)

We also believe that the cost of large models will definitely decrease rapidly, which is also the problem that Teacher Wang Yu and all the teachers were talking about. On one hand, it’s Moore’s Law, on the other hand, it’s the progress of large models, like using the latest vLLM framework and consumer-grade GPUs, Mistral AI’s 8x7B MoE model might reduce the cost by 30 times compared to the earliest LLaMA 70B.
We just wonder if there will be a day in the future when a model can output tens of thousands of tokens, hundreds of millions of tokens per second? Someone asked, what’s the use of outputting so fast? Actually, it’s not necessarily needed to communicate with people very fast, but AI Agents themselves can think very fast, can communicate with other Agents very fast. For example, a problem that needs multi-step web search to solve, people might need to search for an hour, will the future AI be able to solve it in a second? It’s possible.
Musk has a saying, humans are the boot loader for AI, this might be a bit extreme, but the future AI might far exceed the level of humans.
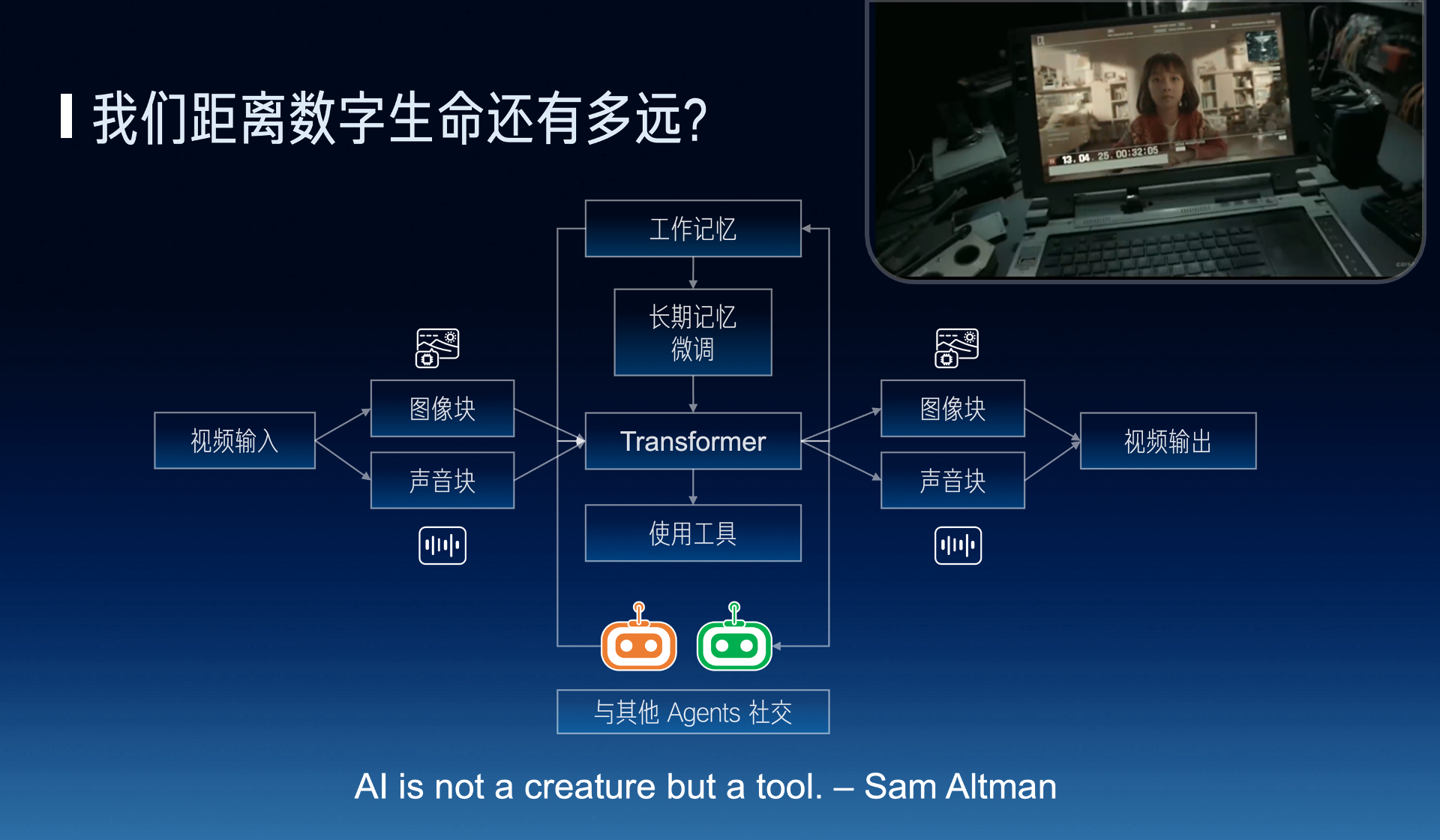
Finally, there’s a somewhat philosophical question, how far are we from digital life?
There’s a famous saying on Zhihu, first ask whether it is, then ask why. First ask whether we want to do digital life? Sam Altman also said, AI is not a life, but a tool. I think, the value of digital life lies in making everyone’s time infinite. The simplest, celebrities don’t have time to interact one-on-one with every fan, but the digital avatar of a celebrity can. Many of the scarcities in human society are essentially from the scarcity of time, if time becomes infinite, then this world might become very different.
For example, like in “The Wandering Earth 2”, Tu YaYa becomes an infinite time, essentially it also needs working memory and long-term memory as a basis, accepting multimodal input and output, the core might be an Encoder, Decoder, plus Transformer to achieve multimodality.
Digital life also needs to be able to use tools, to socialize with other Agents. Like the current Agents are isolated from each person’s memory, a digital life if it gets a piece of knowledge from Xiao Ming, it should also know when chatting with Xiao Hong, but if it gets a secret from Xiao Ming, it might not be able to tell when chatting with Xiao Hong. Agent socializing is also a very interesting direction.

We believe that digital life will definitely become a reality, and it’s not very far from us, and we are also working together to make it a reality, thank you very much.