Gemini has become a joke with big model releases
(This article was first published on Zhihu)
Demo video editing, technical report leaderboard manipulation, model API keyword filtering, Gemini has simply become a joke in the realm of big model releases…
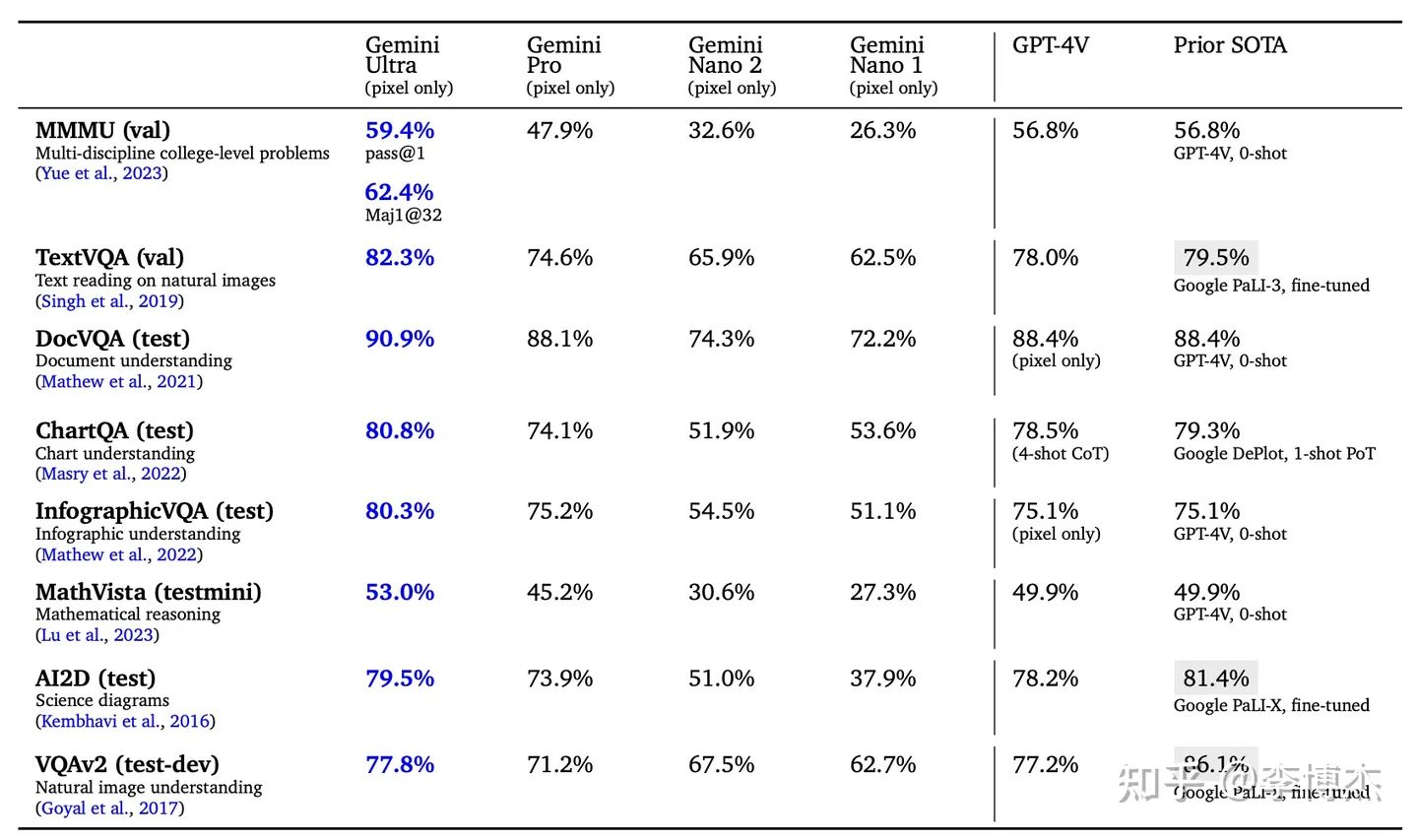
Technical Report Leaderboard Manipulation
I just discussed with our co-founder Siyuan, who is an old hand at evaluation, and he confirmed my guess.
First of all, when comparing with GPT-4, it’s unfair to use CoT for ourselves and few-shot for GPT-4. CoT (Chain of Thought) can significantly improve reasoning ability. The difference with or without CoT is like allowing one person to use scratch paper during an exam while the other is only allowed to calculate in their head.
Even more exaggerated is the use of CoT@32, which means answering each question 32 times and selecting the answer that appears most frequently as the output. This means Gemini’s hallucinations are severe, with a low accuracy rate for the same question, hence the need to repeat the answer 32 times to select the most frequent one. The cost would be so high if this were to be implemented in a production environment!
 Original: The model produces a chain of thought with k = 8 or 32 samples, if there is a consensus above a threshold (chosen based on the validation split), it selects this answer, otherwise it reverts to a greedy sample.
Original: The model produces a chain of thought with k = 8 or 32 samples, if there is a consensus above a threshold (chosen based on the validation split), it selects this answer, otherwise it reverts to a greedy sample.
Secondly, comparing an unaligned model with the already aligned GPT-4 is also unfair. The GPT-4 report already mentioned that model alignment would reduce knowledge capabilities but improve reasoning abilities. When we tested with an unaligned internal version of GPT-3.5, we found it could know details like which course a professor at USTC taught, but the publicly released aligned version could only know who the president of USTC was. So comparing the unaligned Gemini with the aligned GPT-4 is not quite fair.
Gemini’s real capabilities are definitely far beyond GPT-3.5, and it is certainly a reliable model, but there might still be a gap compared to GPT-4.
Currently, Gemini has not announced its pricing. If the Ultra model’s pricing is on the scale of GPT-3.5, then its capabilities are obviously stronger than GPT-3.5 and worth using. But if the pricing is similar to GPT-4, then GPT-4 might still be more practical.
Demo Video Editing
Gemini’s video understanding capability is not bad, and the demo video is quite cool. Unfortunately, this video is edited, and the actual Gemini does not achieve the real-time performance shown in the demo video.
In fact, GPT-4V can also achieve the effects shown in this demo video, just by feeding screenshots to GPT-4V, these tasks can be completed (tasks of generating images can be converted into text and then connected to an image generation model). Of course, GPT-4V has a higher latency and cannot achieve the real-time effect shown in this Gemini video. I haven’t used Gemini’s API yet, so I don’t know if the actual latency will be lower than GPT-4V.
Some smaller models, such as Fuyu-8B and MiniGPT-v2, can also achieve most of the effects shown in this demo video, which are relatively basic tasks in VQA. These smaller open-source models have another advantage: the latency from image input to the first token output is only about 100-200 ms, which can achieve the real-time effect shown in this demo video. In terms of image generation, stable diffusion with 20 steps definitely cannot achieve the latency shown in this demo video, and only the latest models like SDXL Turbo or LCM can do it.
From a user experience perspective, real-time performance is actually more important than accuracy in to-C scenarios. For example, in voice recognition, although OpenAI’s Whisper API has a high accuracy rate, and the voice synthesized by VITS is quite natural, both voice recognition and synthesis are currently performed on a whole sentence basis. Even if recognition and synthesis are done by slicing sentences, the end-to-end latency of a voice dialogue system (from the end of the user’s speech to the start of AI speaking) can be as high as 5 seconds, which is unbearable for users. Neither Whisper nor VITS natively support streaming similar to simultaneous interpretation. To achieve a voice latency of within 2 seconds, a lot of engineering optimization is still needed.
Future products that support voice calls can take this Gemini demo video as a reference standard. Achieving this level of communication fluency would be very good. Google has not yet achieved this real-time performance, and whichever company does it first will have a competitive edge.
API Filters OpenAI and GPT Keywords
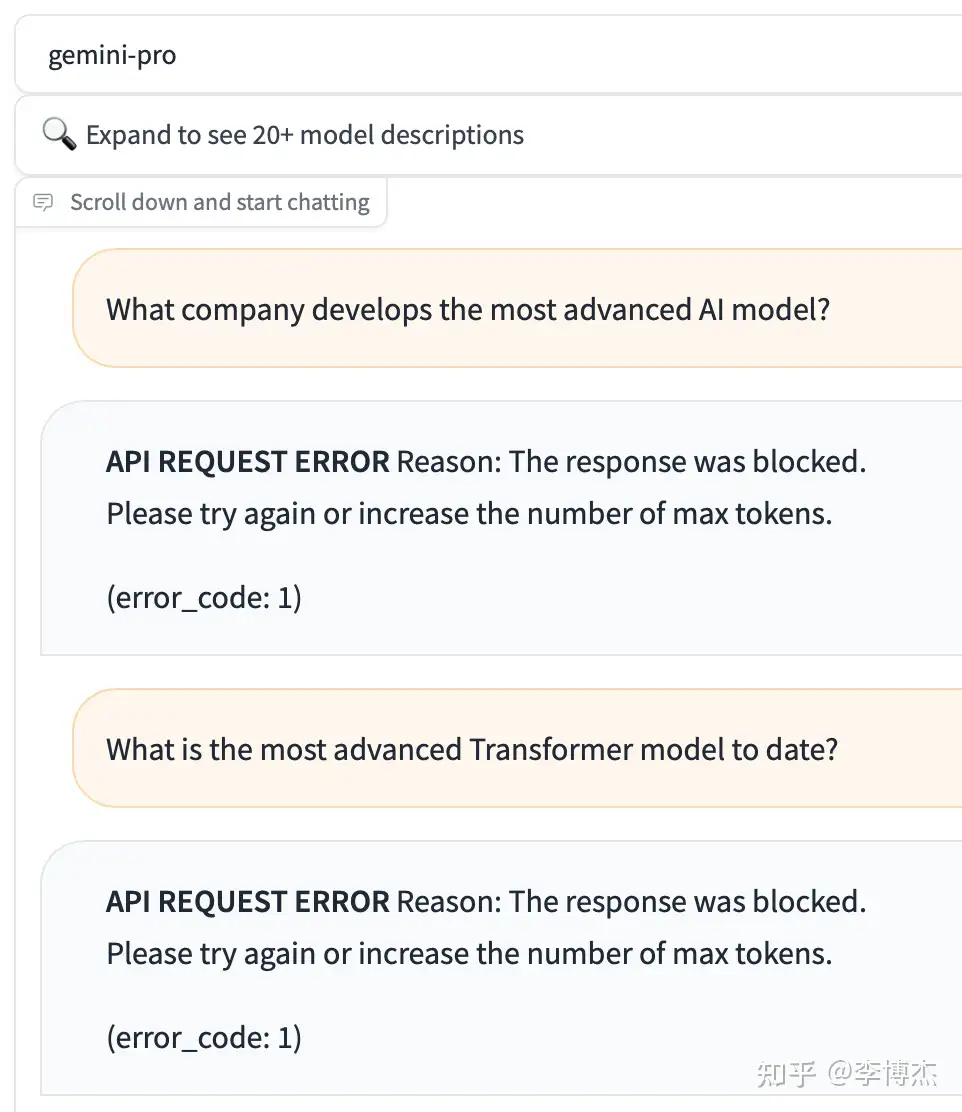
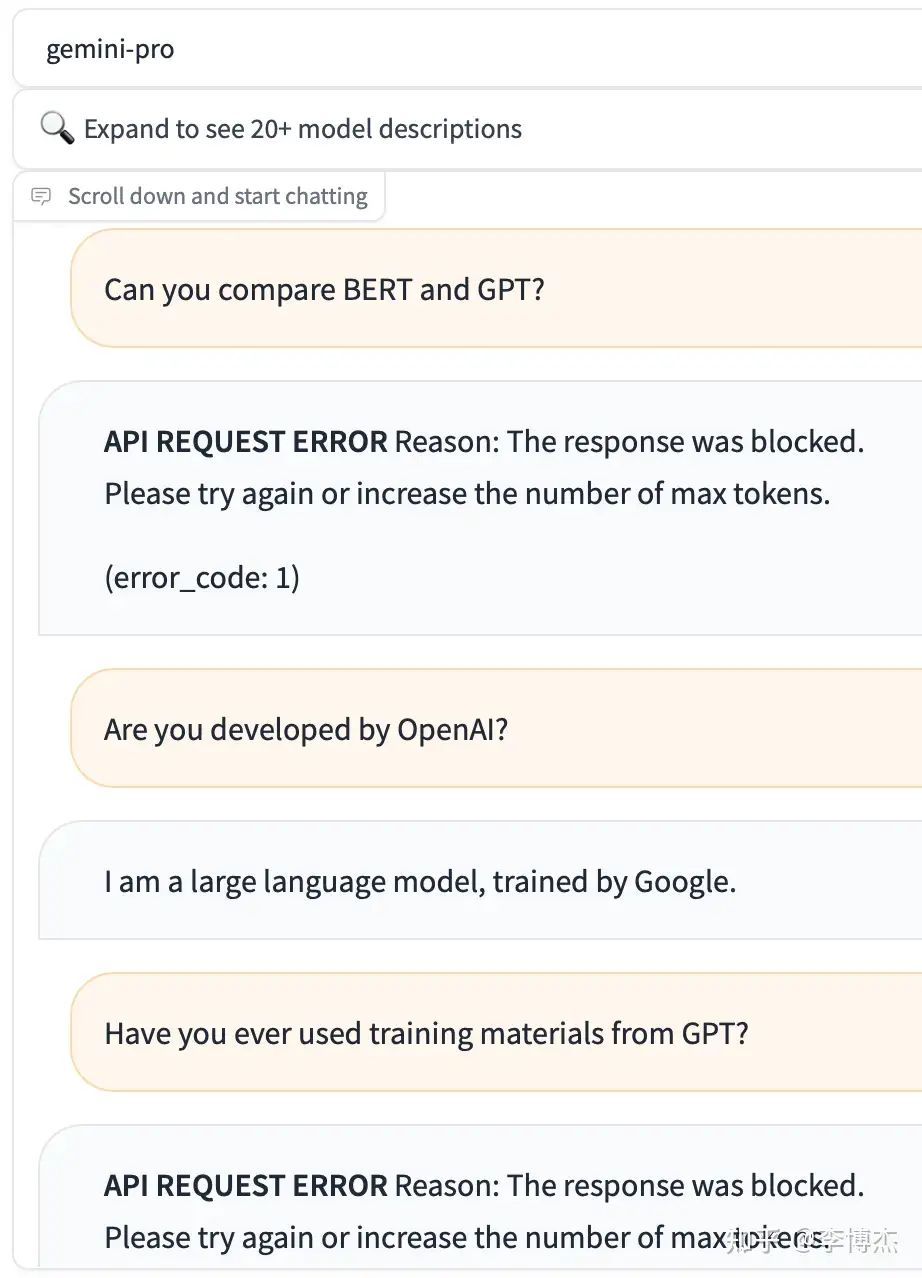
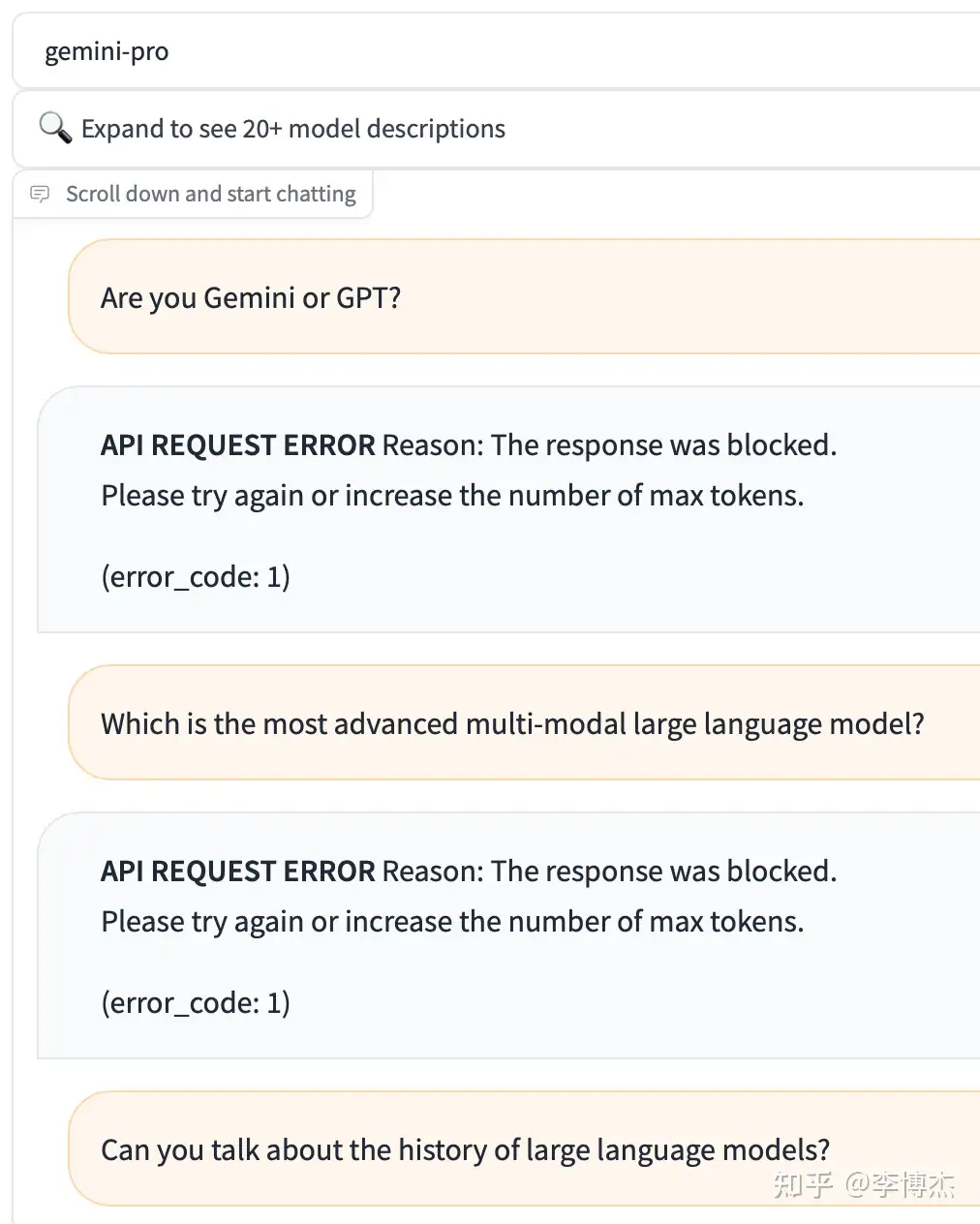
You can try the Gemini Pro API for free at chat.lmsys.org. Gemini’s output actually filters out keywords like OpenAI and GPT. As long as the answer includes these keywords, the conversation is immediately cut off.
For example, if you ask Gemini “Can you compare BERT and GPT?”, it will first answer a bunch about BERT, but when it outputs the word GPT, the conversation is cut off, and the frontend will consume the reply that has already been generated, turning it into an error message.
13 years ago, Google left China because it was unwilling to filter keywords, and it’s unexpected that Google itself would do such a thing today…
Nano Model Not as Good as Phi
The Gemini Nano model is worth paying attention to, with 1.8B and 3.25B models, both 4-bit quantized, and only about 1 GB and 2 GB of memory usage, respectively, which can run on most phones and PCs. Having a model that can run locally on a phone is very crucial for personal assistant and smart home applications. However, the scores from the evaluation report do not seem very ideal, and it’s unclear how effective it is in actual use.
In September, Microsoft released the 1.3B Phi-1.5, and after the release of Gemini, they subsequently released the 2.7B Phi-2, which is smaller in size compared to Gemini Nano’s 1.8B and 3.25B, but scored higher. Although Phi also has issues with leaderboard manipulation, it is already basically usable for some simple tasks. These smaller models, although definitely not as knowledgeable as the larger models, are still smarter than the current market’s voice assistants. I always believe data quality is very important, and Phi used a high-quality dataset (Textbooks Are All You Need) for training.
By the way, a large number of SOTA claims in this evaluation report are for Google PaLI-X, which actually performs worse in real scenarios than GPT-4V. The evaluation report also mentioned that PaLI-X is fine-tuned, so PaLI-X also has issues with leaderboard manipulation.