OpenAI Developer Conference: Expectedly Impressive
(This article was first published on Zhihu)
As an entrepreneur in the AI Agent field, I actually feel that the OpenAI dev day was not as impressive as imagined, and the releases were all within expectations, probably because peers tend to underestimate each other.
In simple terms, GPT-4 Turbo provides a 128K context, the knowledge has been updated to 2023, the API supports multimodality, supports model fine-tuning, reduces costs, and increases speed. It is indeed a very important improvement, but the cost of GPT-4 is still an order of magnitude higher than GPT-3.5-Turbo and LLaMA, which poses certain challenges for large-scale commercial use.
There isn’t much impressive in the Agent field, mainly an Agent Platform has been made. The API forces the use of JSON format output and supports multiple function calls, which is very practical. However, the core issues of Agent such as memory, autonomy, task planning, persona, emotions, etc., OpenAI did not provide solutions at this conference. If after today’s OpenAI conference, a core competitiveness of an Agent company is gone, it should first reflect on whether the technological moat is too shallow.
GPT-4 Turbo
The most impressive part is GPT-4 Turbo, which mainly includes several major features:
 Main features of GPT-4 Turbo
Main features of GPT-4 Turbo
Long Context
It used to be 8K, now it supports 128K context. If it was half a year ago, 128K context would be a great thing. But the key technology of long context has become quite popular, and many models now support long context, such as Claude can support 100K context, Moonshot can support 250K context, and the open-source model Yi-34B of Zero One Wanwu supports 200K context.
Even based on the existing LLaMA-2 model, it is not a difficult task to expand the 4K context to 100K context. My cofounder @SIY.Z at UC Berkeley did LongChat which can increase the context by 8 times, and works like RopeABF can further increase the context length to the level of 100K. Of course, the context improved in this way may have a certain performance gap in complex semantic understanding and instruction following compared to using a longer context during pre-training, but it is enough for a simple text summary.
Long context is not a panacea. Some people who do Agent exclaimed that with long context, there is no need for vector database and RAG, and the memory problem of Agent has been completely solved. This is a statement that completely ignores the cost. Every token input in the context costs money, $0.01 / 1K tokens, so if you fill up the context with 128K tokens, one request is $1.28, almost 10 RMB. Most people, especially to C products, probably can’t afford this money.
So under the current reasoning Infra, if the KV Cache does not persist, the to C Agent cannot possibly stuff a year’s chat records into the context and calculate attention from the beginning, the reasoning cost of this is too high. Similarly, enterprise information retrieval apps cannot possibly read all original documents from the beginning every time. Vector database, RAG, and text summary are still very effective methods to reduce costs.
Knowledge Update
This is indeed very good, the knowledge base has been updated from September 2021 to April 2023. In fact, updating the knowledge base of the basic model is a difficult task. First of all, the quality of data cleaning is very important. It is said that OpenAI lost some people in the process of making GPT-3.5 and GPT-4, resulting in no one redoing the cleaning of new data for a long time, so the model has not been updated for a year and a half.
Secondly, models often need to be retrained after updating the knowledge base, at least the new data (that is, data generated after the knowledge cutoff) and old data need to be mixed and trained in a certain ratio. You can’t just use new data for training, otherwise, there will be catastrophic forgetting problems, forgetting the old knowledge after learning new knowledge. How to add a large amount of new knowledge to the existing model and minimize the cost of retraining is a very worthwhile research problem.
Multimodal
OpenAI recently released several multimodal models, including GPT-4V with image input and DaLLE-3 with image output. These two multimodal models are the state-of-the-art in image understanding and image generation, respectively.
Unfortunately, GPT-4V and DaLLE-3 have only been accessible via the Web interface and do not provide an API. This time, OpenAI has opened up the API. At the same time, OpenAI also released the TTS (Text-to-Speech) API. With the existing Whisper, the input and output modalities of images and voices are all available.
The price of GPT-4V is not high. To input a 1024x1024 image, it only takes 765 tokens, which is $0.00765.
However, the price of DaLLE-3 image generation is relatively high. A 1024x1024 image costs $0.04, which is about the same as Midjourney. If you host the Stable Diffusion SDXL model yourself, the cost of generating an image can be controlled below $0.01. Of course, the image generation quality of DaLLE-3 is much higher than that of Stable Diffusion SDXL. For example, problems that SDXL struggles with, such as drawing fingers, generating logos with specified words, and complex object position relationships, DaLLE-3 can do quite well.
The open-source version of Whisper was V2, and the version released this time is V3, which provides an API and is also open-source. I had noticed before that the recognition rate of ChatGPT voice call was higher than the Whisper V2 model I deployed myself. It turns out that OpenAI had a hidden trick. But whether it’s V2 or V3, the recognition rate is already very high. Apart from names and some proper nouns, the recognition accuracy of daily English is almost 100%, and even a small number of errors do not hinder the understanding of the large model.
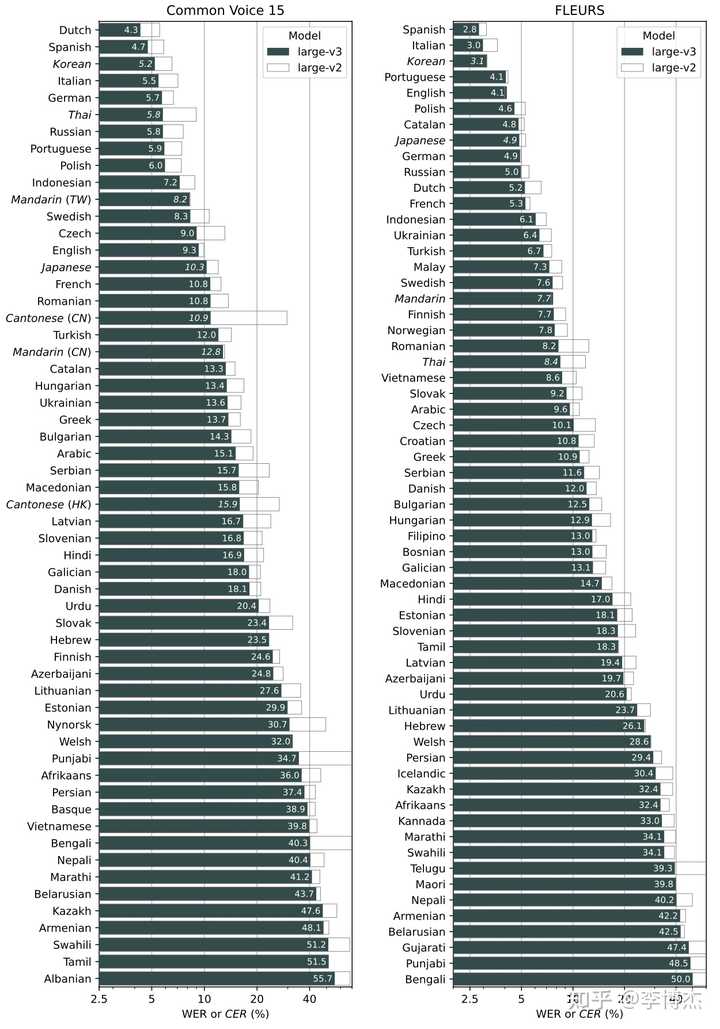 Comparison of recognition error rates between Whisper V2 and V3
Comparison of recognition error rates between Whisper V2 and V3
TTS is actually doing well with the open-source VITS and Google TTS from other companies. I feel that the voice synthesis effect of this model from OpenAI is better.
I hope that OpenAI can soon launch the ability to fine-tune TTS based on the voice data provided by oneself. Many times we need to synthesize the voice of a specific person or character, not a uniform voice. Of course, after fine-tuning, the model can’t do batching during inference, which will lead to a significant increase in inference cost. A more reliable future solution may be to extract the timbre of a specific person or character’s voice, turn it into several tokens, and input it into a unified model, so that you don’t need to fine-tune the voice of a specific person, and you can use one model to generate multiple people’s voices.
Support for Model Fine-tuning
Both the GPT-3.5 16K version and GPT-4-Turbo support model fine-tuning, which is a good thing. OpenAI has also started outsourcing, and for large customers with particularly complex needs, they can also customize models. The inference cost of the fine-tuned model is definitely higher than the original model because it is not convenient to do batching, at least the LoRA part cannot batch different fine-tuned models. This is also a challenge to the inference Infra.
Cost Reduction, Speed Increase
Compared with GPT-4, the cost of input tokens for GPT-4-Turbo has been reduced to 1/3, and the cost of output tokens has been reduced to 1/2, which is a great thing. But the cost of GPT-4-Turbo is still an order of magnitude higher than GPT-3.5-Turbo, with input tokens 10 times higher ($0.01 vs $0.001 per 1K tokens), and output tokens 15 times higher ($0.03 vs. $0.002 per 1K tokens). In this case, cost-sensitive applications definitely need to be weighed.
 Comparison of costs between old and new models
Comparison of costs between old and new models
Microsoft has a paper that has been withdrawn saying that GPT-3.5-Turbo is a 20B model, which I personally doubt. Judging from the API cost and the uncertainty of the output results when the temperature = 0, GPT-3.5-Turbo is more likely to be a 100B or above MoE model. Because there was leaked news before that GPT-4 is an MoE model, it is very likely that GPT-3.5-Turbo is also an MoE model.
To solve the output uncertainty problem brought by the MoE model batching and temperature > 0, OpenAI dev day launched a repeatable output function. By fixing the seed, the output can be guaranteed to be the same when the prompt is the same, for debugging.
Future applications are likely to need the ability of a model router, choosing different cost models according to different types of questions, so that while reducing costs, performance does not drop significantly. Because in most applications, most of the user’s questions are simple and do not need to bother GPT-4.
Improving Rate Limit
Originally, the rate limit of GPT-4 was very low, often triggering the rate limit while using it, and I didn’t dare to use it online to serve high-concurrent user requests. Now the rate limit of GPT-4 has been increased, and it can use 300K tokens per minute, which should be enough for small-scale services. If you use up 300K tokens, you will burn 3 dollars per minute, let’s see if the money in the account is enough to burn.
The credit (quota) that users can use each month has also increased, which is a good thing. Previously, if you wanted to exceed the quota of 120 dollars per month, you had to apply specifically.
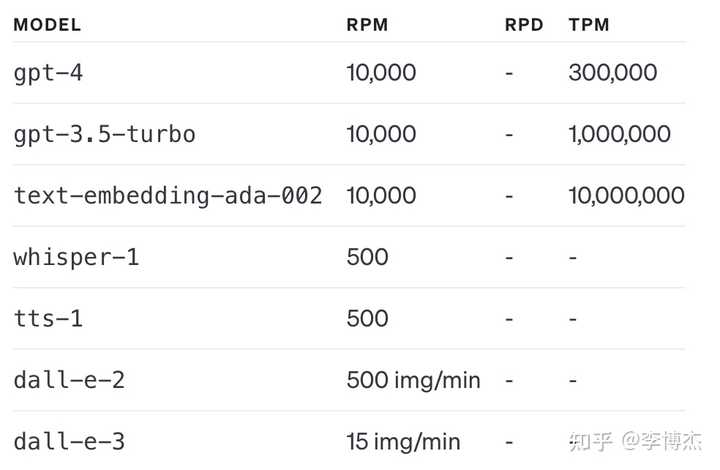 Current GPT quota
Current GPT quota
However, the current quota of GPT-4-Turbo is very small, only 100 requests per day, as stingy as the GPT-4 on the Web interface. I hope that the rate limit of GPT-4-Turbo can be increased as soon as possible so that it can be used in the production environment.
Agent
There have long been rumors that OpenAI has been holding a big move in the Agent field, and sure enough, the second half of this OpenAI dev day focused on the Agent.
OpenAI’s App Store
OpenAI has long developed a plugin system, envisioning it as an App Store for large model applications, but it has not been very useful. The GPTs released this time are one step closer to this dream.
The biggest innovation of GPTs is the provision of the Agent Platform, which can be understood as the App Store for Agents.
GPTs allow users to customize their own Agents to make them more adaptable for use in daily life, specific tasks, work or home, and share them with others. For example, GPTs can help you learn the rules of any board game, help your child learn math, or design stickers. Anyone can simply create their own GPT without programming. Creating a GPT is like starting a conversation, providing instructions and additional knowledge, and choosing what it can do, such as searching web pages, making pictures, or analyzing data.
OpenAI will also launch the GPT store later this month, where users can buy GPTs (buying GPTs sounds strange, it’s better to call it Agent). In the store, you can search for GPTs and there are leaderboards. The author of GPT can get benefits.
At first, I felt that the name GPT was not good, and it was better to use Agent. In the end, Sam Altman explained, “Over time, GPTs and Assistants are precursors to agents, are going to do much much more. They will gradually be able to plan, and to perform more complex actions on your behalf.” That is to say, Sam Altman has high expectations for Agent, he thinks that these current applications are not enough to be called Agent, the core issues such as task planning have not been solved, this may be the reason why OpenAI did not use the term Agent.
Assistants API
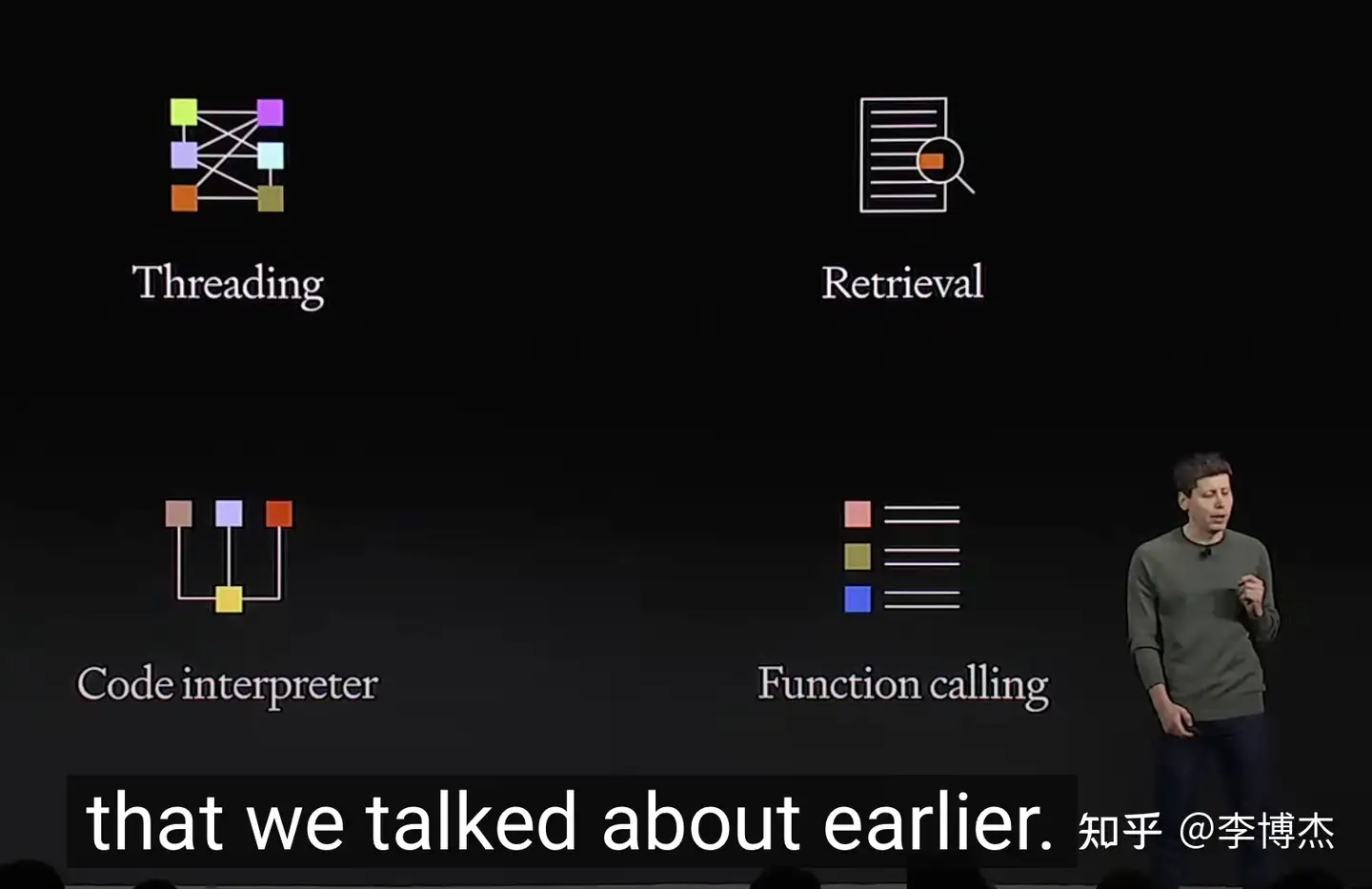 Four core capabilities of Assistants API
Four core capabilities of Assistants API
In order to facilitate users to create GPT (that is, Agent applications), OpenAI has launched the Assistants API, which provides core capabilities such as persistent, infinitely long threads, code interpreters, search, function calls, etc. Most of the things that used to be done with LangChain can now be done with the Assistants API.
 Creation interface of Assistants
Creation interface of Assistants
The key change introduced by the Assistants API is persistent, infinitely long threads. Developers no longer need to worry about thread state management issues, nor do they need to worry about context window constraint issues.
This persistent, infinitely long thread seems to just add a storage function on the surface, turning the conversation from stateless to stateful, but in fact it is a key step to implement memory and improve user stickiness.
If a platform only provides stateless APIs, it can be replaced at any time. Now many large model APIs are compatible with OpenAI, and you can replace it by setting the interface address after importing openai. Therefore, the only advantage of OpenAI is model performance and cost. Once a more competitive model appears, it can be easily replaced.
But stateful threads are different, they save the memory of the user’s communication with the Assistant. Over time, the Assistant will understand you more and more, like a friend who has known you for many years, and cannot be easily replaced. I have always believed that the memory of an Agent is very crucial. It not only improves the user experience and reduces the communication cost between the Agent and the user, but also enhances user stickiness and creates a sense of dependence.
In addition, Assistants can call new tools when needed, including:
Code Interpreter: Write and run Python code in a sandbox execution environment, and generate charts, handle various data and format files. Assistants can run code to solve complex code and math problems.
Retrieval (RAG, Retrieval Augmented Generation): Use knowledge outside of the large model to enhance the assistant’s capabilities, such as data from proprietary domains, product information, or user-provided documents. OpenAI will automatically calculate and store embeddings, implement document chunking and search algorithms, and no longer need to do it yourself. It’s like a SaaS version of LangChain.
Function Call: Function call is a killer feature launched by OpenAI for building Agents. There are two highlights.
 GPT generates multiple function calls at once
GPT generates multiple function calls at once
First, support for using strict JSON format output. Previous models often added unnecessary prefixes and suffixes to the output JSON, which required post-processing before feeding to the API. Now you can specify to force the use of JSON format output.
Second, support for generating multiple function calls at once. In the past, a large model could generally only output one function call at a time. If multiple external APIs are needed in the whole process, multiple large models need to be involved, which not only increases the processing delay but also increases the consumption of token costs. OpenAI, with its powerful code generation capabilities, allows a single large model call to generate multiple function calls in series, significantly reducing latency and cost in complex workflow scenarios.
Application Examples
The examples of applications shown by OpenAI are good, but they are all done by others. What OpenAI wants to show is that you can easily create your own Agent on this platform.
For example, the example of the travel assistant Agent is exactly what I did yesterday. I went to USC yesterday morning and met some tourists on campus. They asked me if I could show them around. I said it was my first time here, so why not let the AI Agent accompany us. Then I let my own AI Agent take us to several iconic buildings.
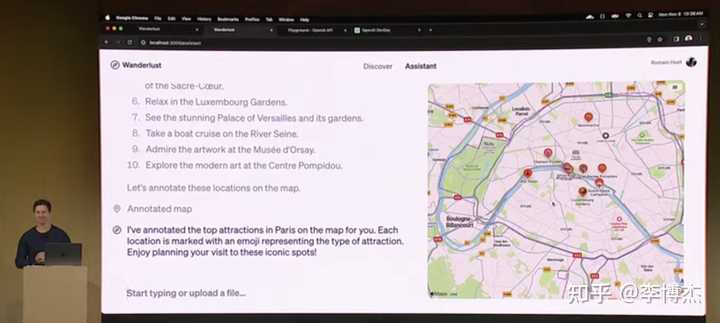 OpenAI's travel assistant Agent
OpenAI's travel assistant Agent
Using Whisper, TTS, GPT-4V, DaLLE-3, you can easily create a multimodal Agent. The App that can chat and draw lots shown on DevDay was made with Whisper and TTS.
 OpenAI Dev Day's final demonstration of an Agent that can chat and draw lots
OpenAI Dev Day's final demonstration of an Agent that can chat and draw lots
The final AI lottery segment and the Agent that gave everyone $500 API credit really brought the show to its climax. It’s indeed the Spring Festival Gala of the AI world.
ChatGPT Improvements
First, ChatGPT has integrated the Bing Search, DaLLE-3 and other features from GPT-4, so users don’t need to switch between different models. ChatGPT will choose which plugin to call.
Second, ChatGPT has added the ChatPDF feature, allowing ChatGPT to directly process PDF and other types of files. This instantly made ChatPDF obsolete.
Where is the Moat for Startups
Many people were shocked after watching OpenAI dev day, exclaiming that there are so many companies in the large model ecosystem, and now only OpenAI is left.
 A netizen's comment, only OpenAI is left in the large model ecosystem
A netizen's comment, only OpenAI is left in the large model ecosystem
There have been many entrepreneurs constantly discussing, what if OpenAI also does what I do?
Actually, this question is the same as the classic question in the domestic Internet startup circle before, what if Tencent also does what I do?
My answer is simple, either do what OpenAI doesn’t do, or do what OpenAI can’t do yet.
For example, our company’s companion bot (companion class Agent) is something OpenAI explicitly doesn’t do. Sam Altman has repeatedly stated that human-like Agents have no value, and what really has value is assisting people in completing work. OpenAI and Microsoft’s values match, both do enterprise-level, general things, and look down on entertainment things. Although the companion class Agent track is also very competitive, basically every large model company is launching companion class Agents, but so far no one has done it particularly well, at least no one can reach the level of Samantha in “Her”. There are still many fundamental problems to be solved in this field, such as task planning, memory, persona, emotions, autonomous thinking, the ceiling is very high.
Another example is the open source model, low-cost model, which is also something OpenAI is unlikely to do. OpenAI is moving towards AGI, and it is certain to make the model’s capabilities stronger and stronger. The 7B small model is not even in OpenAI’s sight. But we have also seen the price of GPT-4, even GPT-4-Turbo is still very high. In fact, for many to C scenarios, even the price of GPT-3.5-Turbo is unaffordable. Therefore, in many scenarios, we need to host 7B, 13B models ourselves to meet most of the simple needs of users. It is said that Character.AI is a self-developed dialogue model of about 7B in size, and the cost of each request is less than 1/10 of the GPT-3.5-Turbo API. Although Character sometimes looks a bit stupid, and does not do well in memory and emotions, their cost is low! Low cost will become a core competitive advantage for the company.
The third example is games, large models will definitely profoundly change the gaming industry, but OpenAI is unlikely to get involved in games on its own, even if it does, it will cooperate with game companies. For example, the recently popular “Damn! I’m Surrounded by Beauties!”, and many galgames that otakus and otaku girls like, are currently all user multiple-choice questions to determine the direction of the plot. If users can interact with game characters in natural language, and the plot is also customized according to user preferences, it will be a completely new gaming experience.
So what is something OpenAI can’t do for now? For example, video input and video generation, OpenAI is unlikely to launch in the short term, or even if it does, the cost will be high. OpenAI is pushing the frontier of large models, and will definitely use large enough models to generate the highest quality videos, rather than thinking about generating cheap and low-quality videos. The cost of RunwayML Gen2 is now quite high, with 7.5 minutes costing 90 dollars. AnimateDiff’s cost is relatively low, but the effect needs to be improved, and the community has made many improvements recently. Live2D, 3D models require a relatively high modeling cost, and can only generate character-related models, and cannot generate complex interactive videos. This is where the latecomers can strive for.
Another thing OpenAI can’t do for now is hardware-dependent. For example, Rewind’s recording pendant, Humane’s AI Pin similar to the movie “Her” placed in the shirt pocket, are all very interesting hardware inventions. In addition, Siri and others that rely on smartphones are also entrances that OpenAI cannot replace.
Finally, scenarios with data barriers are also difficult for OpenAI to directly replace. For example, Internet companies adding large model recommendation capabilities in existing apps is a scenario with data barriers, which other companies find difficult to do.
Infra is Important
Sam Altman invited Microsoft CEO Satya Nadella to give a talk, and the most important information I think is the importance of Infra. Azure is the infrastructure for OpenAI’s training and inference, like the GPT-4 10,000 card training cluster is provided by Azure. Most companies currently do not have the infrastructure for efficient training of a 10,000 card cluster, and they do not have the ability for high-speed communication of a 10,000 card network and automatic recovery from failures.
Considering the cost of training and inference, Infra will be one of the key factors in the success or failure of large model companies in the next 2-3 years.