A100/H100 too expensive, why not use 4090?
(Long text warning: this article is about 16000 words)
This is a good question. To start with the conclusion, it’s not feasible to use 4090 for training large models, but it’s not only feasible to use 4090 for inference/serving, it can also be slightly higher in cost performance than H100. If 4090 is optimized to the extreme, the cost performance can even reach twice that of H100.
In fact, the biggest difference between H100/A100 and 4090 lies in communication and memory, and the gap in computing power is not large.
| H100 | A100 | 4090 | |
|---|---|---|---|
| Tensor FP16 computing power | 989 Tflops | 312 Tflops | 330 Tflops |
| Tensor FP32 computing power | 495 Tflops | 156 Tflops | 83 Tflops |
| Memory capacity | 80 GB | 80 GB | 24 GB |
| Memory bandwidth | 3.35 TB/s | 2 TB/s | 1 TB/s |
| Communication bandwidth | 900 GB/s | 900 GB/s | 64 GB/s |
| Communication latency | ~1 us | ~1 us | ~10 us |
| Price | $30000~$40000 | $15000 | $1600 |
There is a lot of water in NVIDIA’s power table. For example, the H100 TF16 power is written as 1979 Tflops, but that includes sparsity, and the dense power is only half; the official promotion of 4090 Tensor Core power is as high as 1321 Tflops, but that is int8, FP16 is only 330 Tflops. The first version of this article used the wrong data, both H100 and 4090 data were used incorrectly, and the conclusion was very outrageous.
The price of H100 actually has more than 10 times the water. In 2016, when I was at MSRA, I witnessed Microsoft deploying FPGA on each server, hitting the price of FPGA to the sand, and even became an important pusher for supplier Altera to be acquired by Intel. In 2017, I mined by myself, knowing which graphics card is the most cost-effective. Later at Huawei, I was also a core participant in the software development of Kunpeng and Ascend ecosystems. Therefore, I have a rough idea of how much a chip costs.
Xia Core, the chief architect of Kunpeng, has a well-known article “Talking about the broken ass of the Nvidia Empire“, which analyzes the cost of H100 well:
Open his cost, the cost of SXM will not be higher than $300, the packaging Substrate and CoWoS also need about $300, the largest Logic Die in the middle, looks the most expensive :) That is a 4nm 814mm2 Die, a 12-inch Wafer from TSMC can roughly manufacture about 60 Dies of this size, Nvidia does very well in Partial Good (he almost doesn’t sell Full Good), so these 60 Dies can roughly have 50 available, Nvidia is a big customer, the price obtained from TSMC is about $15000, so this expensive Die only needs about $300. Oh, only HBM is left, the current DRAM market is so weak that it is almost dying, even HBM3 is basically selling at a loss, it only needs about $15/GB, um, the cost of 80GB capacity is $1200.
TSMC once told a story. Taiwanese compatriots work hard to save money to build factories, a 4nm so advanced process, can only sell for $15000, but that certain customer takes it, can sell for $1500000 ($30000*50) goods, locomotive, that is very annoying. Do you understand what I mean?
As I said at the beginning, under the business rules of this world, selling something with a cost of $2000 for $30000, only one company, and the sales volume is still large, this is illogical, this kind of golden hen must have an aircraft carrier to keep it.
It is said that Microsoft and OpenAI have taken half of the H100 production capacity in 2024, guess if they will play the traditional art of bargaining with Altera? Will they really spend $40,000 * 500,000 = 20 billion dollars to buy cards?
Let’s analyze the cost of 4090 again, the 5nm 609mm2 Die, the cost is about $250. GDDR6X, 24 GB, calculated at $10 per 1 GB, $240. Let’s count PCIe Gen4, this cheap thing, as $100. Packaging and fans, count it as $300. The total cost is at most $900, this thing sells for $1600, it is considered a conscience price, because the research and development cost is also money, not to mention that most of NVIDIA’s R&D personnel are in Silicon Valley, where the average salary of programmers is the highest in the world.
It can be said that the H100 is like a house in a first-tier city in China. The concrete and steel itself is not worth much money, and the house price is completely blown up by the supply-demand relationship. I have been living in LA for two weeks. The house rented by the company has 4 times the usable area of my house in Beijing, but the price is only 30% more expensive, and it comes with a small courtyard, which is equivalent to 1/3 of the unit price of a house in Beijing. When I chat with locals, they are all surprised. Your average income level is so much lower than LA, how can you afford a house in Beijing?
The question is, if the 4090 is so fragrant, why does everyone have to scramble to buy the H100, causing the H100 to be out of stock? Even the H100 has to be banned from selling to China, and a castrated version of the H800 has been made?
Why can’t large model training use 4090
GPU training performance and cost comparison
LambdaLabs has a good comparison of GPU single-machine training performance and cost, which is excerpted as follows.
First look at the throughput, it seems that there is nothing wrong with it. In the case where a single card can put down the model, it is indeed the highest throughput of the H100, reaching twice that of the 4090. Looking at the computing power and memory, you can also see that the FP16 computing power of the H100 is about 3 times that of the 4090, and the memory bandwidth is 3.35 times. During the training process, because the batch size is relatively large, most operators are compute bound (compute-intensive), and a few operators are memory bound (memory-intensive), this result is not surprising.
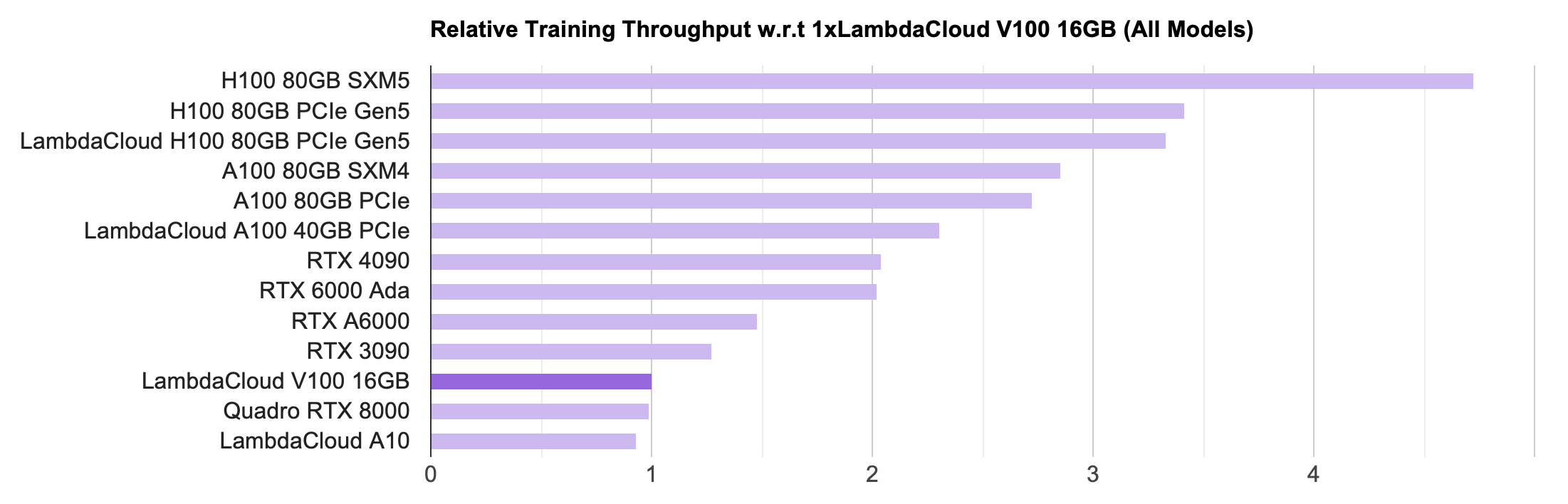 LambdaLabs PyTorch single card training throughput comparison chart
LambdaLabs PyTorch single card training throughput comparison chart
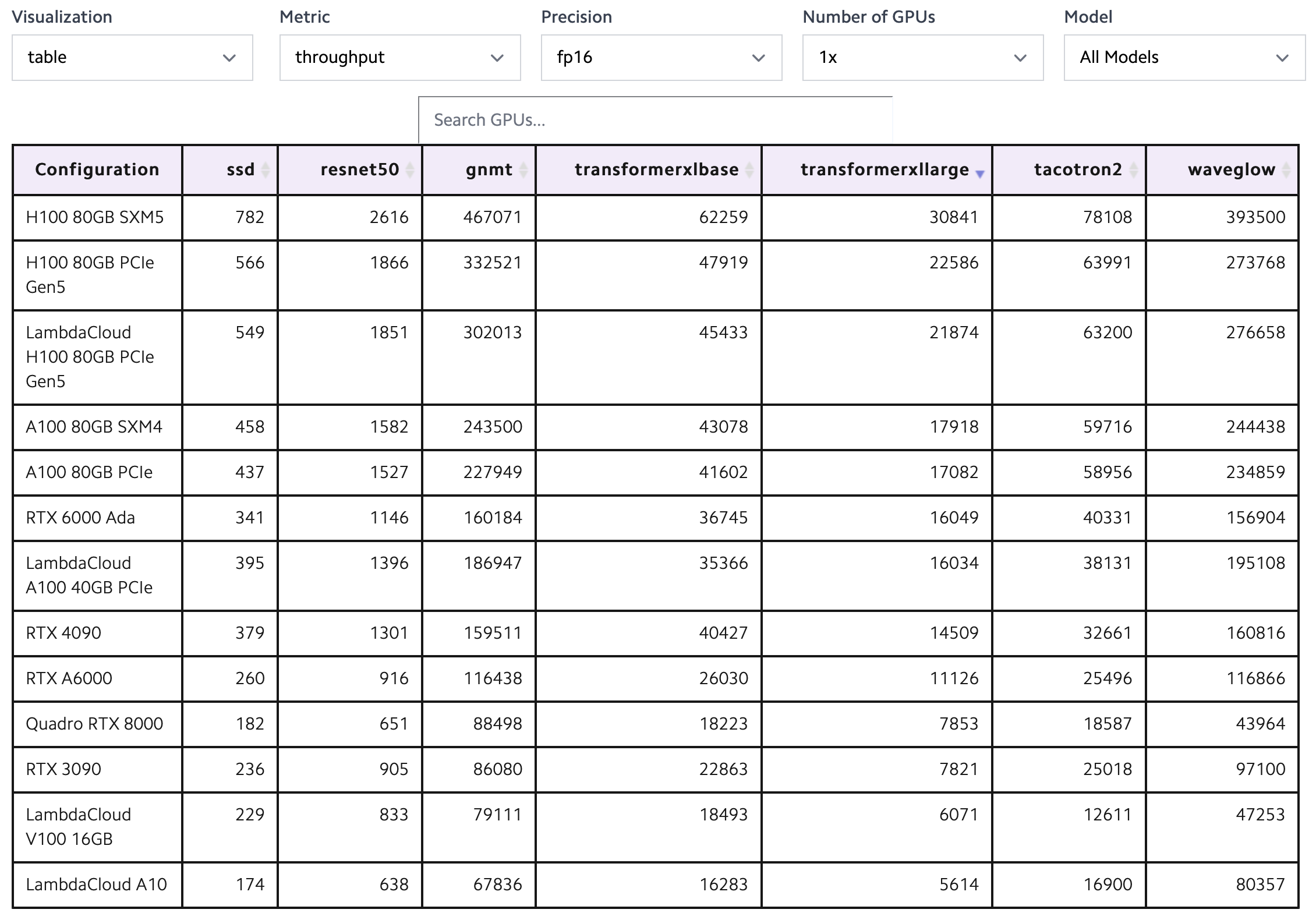 LambdaLabs PyTorch single card training throughput comparison table
LambdaLabs PyTorch single card training throughput comparison table
Then look at the cost-effectiveness, it’s interesting, the H100 that was originally ranked first is now almost at the bottom, and the gap between the 4090 and the H100 is nearly 10 times. This is because the H100 is much more expensive than the 4090.
Due to the tight supply of H100, the rental price of H100 from cloud manufacturers is even darker, and it can be paid back in about 7 months at the marked price. Even if the price for large customers can be half cheaper, it is enough to pay back in a year and a half.
IaaS cloud service providers who have been used to hard days in the price war see such a payback speed of H100, they probably have to sigh, this is faster than the payback of blockchain mining.
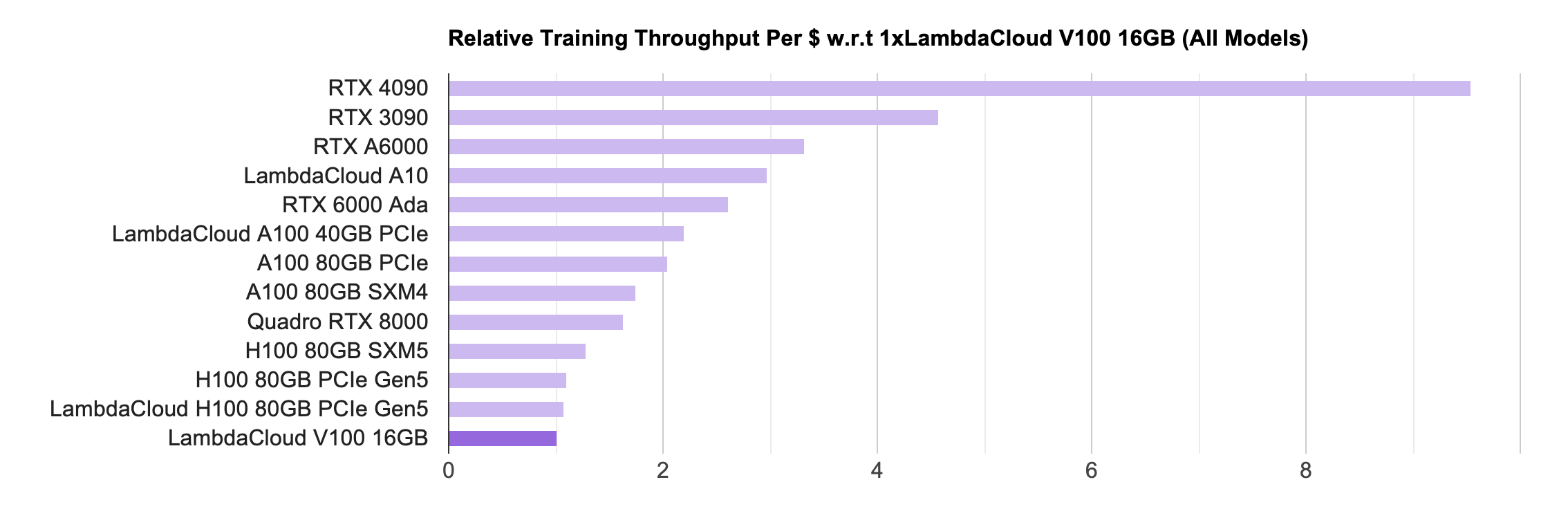 LambdaLabs PyTorch single card training unit cost throughput comparison chart
LambdaLabs PyTorch single card training unit cost throughput comparison chart
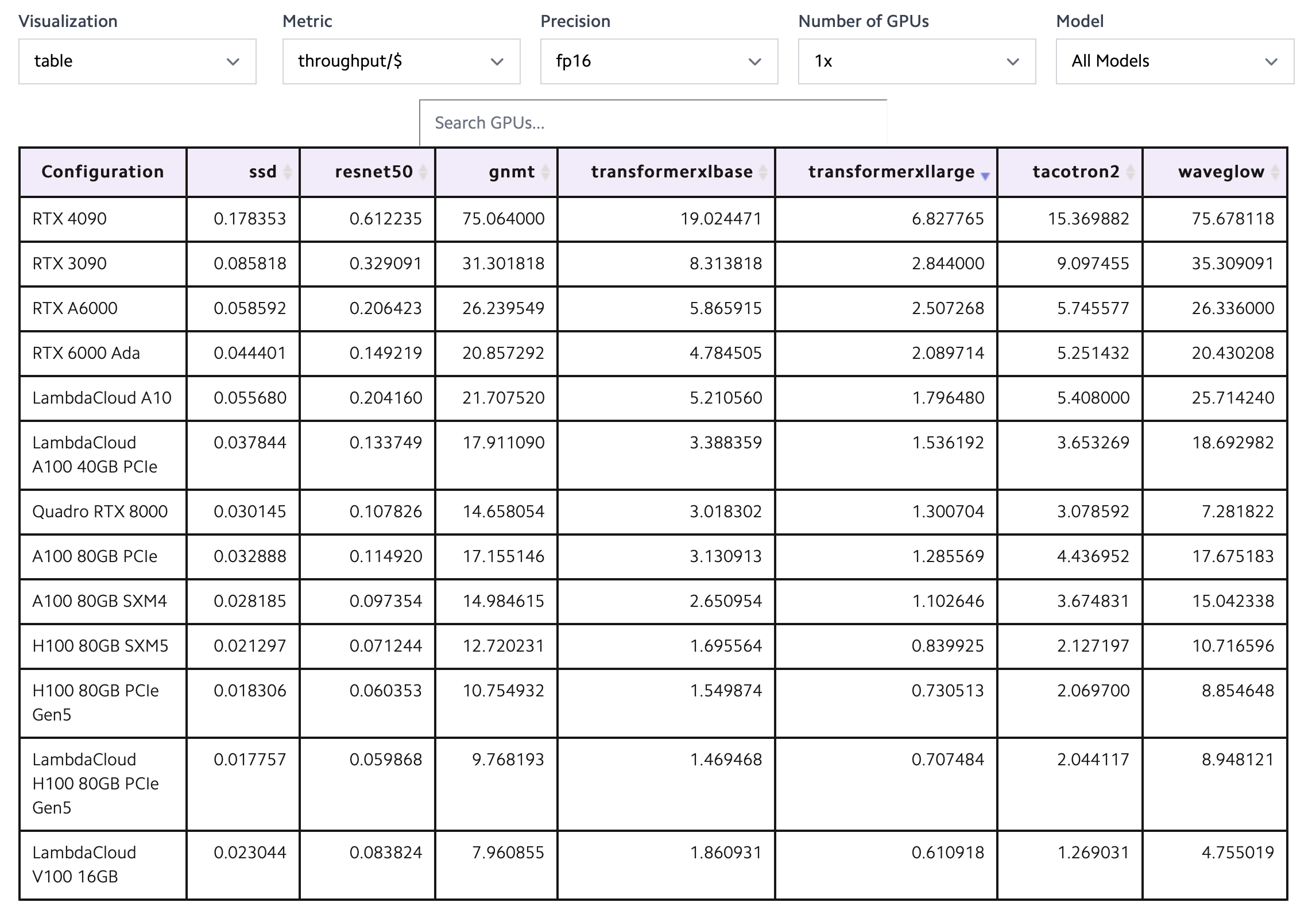 LambdaLabs PyTorch single card training unit cost throughput comparison table
LambdaLabs PyTorch single card training unit cost throughput comparison table
The computing power requirements of large model training
Since the cost-effectiveness of 4090 single-card training is so high, why can’t it be used for large model training? Putting aside the license restrictions that do not allow gaming graphics cards to be used in data centers, technically speaking, the fundamental reason is that large model training requires high-performance communication, but the communication efficiency of the 4090 is too low.
How much computing power does large model training need? Total training computing power (Flops) = 6 * model parameters * training data token number.
When I first saw someone talking about this formula seriously at the beginning of this year, I thought it was obvious, right? Seeing that the senior engineer of OpenAI can get an annual salary of more than 900,000 US dollars, I suddenly felt bad, and AI is still fragrant. I have also interviewed some AI engineers before, including some experts in AI system optimization. They can’t even explain what Q, K, and V are, and they can’t calculate the size of each tensor in LLaMA, and they can still get an offer.
The theme of the APNet 2023 panel is Network, AI, and Foundational Models: Opportunities and Challenges. The first few questions were all in order, and the panelists were a bit unable to let go, so I raised a question. The important achievements in the history of the network are basically based on a deep understanding of the application scenario, but many of us who do the network now do not understand AI, and even don’t know the size of each tensor and the amount of data transmitted at each step. How to let the network community understand AI better?
This is lively, Tan Bo below the stage spoke first, saying that I can definitely know all these things in Huawei; then Professor Chuanxiong also followed a sentence, if the network understands too much AI, then he might become an AI guy. Then the host Professor Chen Kai asked, who of you has really trained a large model? After a silence, a brother from Alibaba said first, I am half of the one who has trained a large model, and what we do is to support Alibaba’s large model infra. Later, another panelist said, is it necessary for network optimization of AI systems to understand AI by themselves, or is it enough to do profiling?
My personal view is still that AI is not difficult to learn. If you want to do a good job in AI system optimization, you can not understand why the softmax in attention has to be divided by sqrt(d_k), but you can’t not calculate the computing power, memory bandwidth, memory capacity and communication data volume required by the model. Jeff Dean has a famous Numbers Every Programmer Should Know, and the order of magnitude estimation is very important for any system optimization, otherwise you don’t know where the bottleneck is.
Returning to the total computing power required for large model training, it’s actually quite simple, 6 * the number of model parameters * the number of tokens in the training data is the computing power required to go through all the training data once. The 6 here is the number of multiplication and addition calculations required for each token during the forward and backward propagation of the model.
A bunch of matrices multiply, simply think of it as a number of neurons on the left and a number of neurons on the right, forming a complete bipartite graph. Select any neuron l on the left and neuron r on the right, during forward propagation:
- l multiplies its output by the weight w between l and r, and sends it to r;
- r can’t possibly only connect to one neuron, it needs to add up multiple l’s, which is reduce, requiring one addition.
During backward propagation:
- r multiplies the gradient it received by the weight w between l and r, and sends it to l;
- l can’t possibly only connect to one r, it needs to reduce the gradient, do an addition;
- Don’t forget that the weight w needs to be updated, so you need to calculate the gradient of w, multiply the gradient received by r by the output of l’s forward propagation (activation);
- A batch generally has multiple samples, and the update of weight w needs to add up the gradients of these samples.
A total of 3 multiplications, 3 additions, no matter how complex the Transformer is, matrix calculation is this simple, other vector calculations, softmax and the like are not the main factors of computing power, can be ignored when estimating.
I remember when I first joined the MindSpore team in 2019, the leader asked me to develop a backward version of a forward operator, I got the derivative wrong, resulting in the operator’s calculation results always being incorrect, I thought it was a bug in our compiler. When I found out that the derivative was wrong, the leader looked at me as if I hadn’t studied calculus, indeed my calculus was not good, this is also one of the reasons why I switched from mathematics to computer science.
During my time at MindSpore, automatic differentiation was just under 1000 lines of code, just calculate recursively according to the differentiation formula, but automatic differentiation as an important feature was hyped for a long time, I felt embarrassed.
There is also a proportional relationship between the number of model parameters and the number of tokens in the training data, which is also easy to understand, just imagine the model as a compressed version of the data, the compression ratio always has a limit. If the number of model parameters is too small, it can’t digest all the knowledge in the training data; if the number of model parameters is greater than the number of tokens in the training data, it’s a waste and can easily lead to over-fitting.
How many cards are needed to train LLaMA-2 70B
With the total computing power required for model training, divided by the theoretical computing power of each GPU, and then divided by the effective computing power utilization ratio of the GPU, you get the required GPU-hours, which already has a lot of open source data. LLaMA 2 70B training requires 1.7M GPU hours (A100), if you use 1 GPU, it would take 200 years. To train in a more acceptable time period of one month, you need at least 2400 A100s.
If you use 4090, the single card FP16 computing power is similar to A100 (330 vs 312 Tflops), but the memory bandwidth is half of A100 (1 vs 2 TB/s), and the memory capacity is several times less (24 vs 80 GB), the TF32 computing power required for gradient calculation is also half (83 vs 156 Tflops), overall the training speed of a single 4090 card is slightly lower than A100 (refer to the previous LambdaLabs evaluation).
Let’s calculate with 2048 4090s, the communication between these 2048 4090s becomes the biggest problem.
Why? There are generally tensor parallelism, pipeline parallelism, data parallelism several parallel methods, which divide the GPU in the three dimensions of within the model layer, between the model layers, and training data. The product of the three parallelisms is the total number of GPUs for this training task.
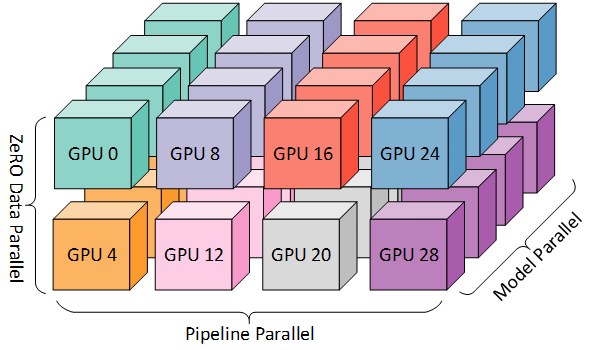 A schematic diagram of the three parallel methods dividing the computing space from three dimensions, source: DeepSpeed
A schematic diagram of the three parallel methods dividing the computing space from three dimensions, source: DeepSpeed
Data parallelism (data parallel)
Data parallelism is the easiest to think of parallel method. Each GPU calculates different input data separately, calculates its own gradient (i.e., the change in model parameters), then summarizes the gradient, takes an average, and broadcasts it to each GPU for separate updates.
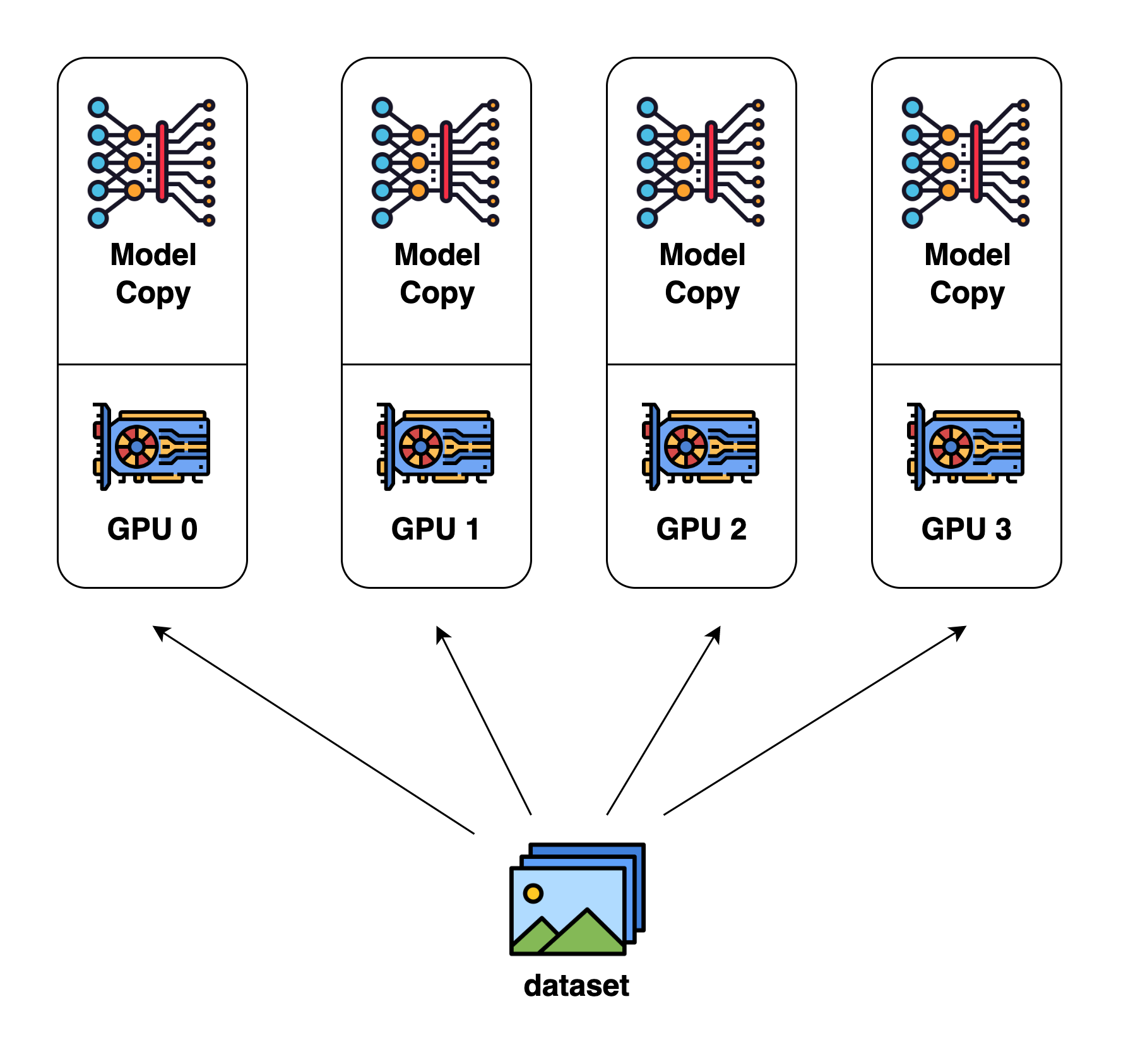 Data Parallelism schematic, source: Colossal AI
Data Parallelism schematic, source: Colossal AI
But using only data parallelism is definitely not enough, because a single GPU can’t fit the entire LLaMA 70B model.
As for how much GPU memory model training needs, I find that not many people can calculate it clearly. Some people even think that it’s enough to just store the model parameters and the gradients of backward propagation. In fact, the memory required for training includes model parameters, gradients of backward propagation, memory used by the optimizer, and intermediate states of forward propagation (activation).
The memory used by the optimizer is actually quite simple, if you use the most classic Adam optimizer, it needs to use 32-bit floating point to calculate, otherwise the error of using 16-bit floating point to calculate is too large, the model is easy to not converge. Therefore, each parameter needs to store 4 bytes of 32-bit version (use 16-bit version during forward propagation, use 32-bit version during optimization, this is called mixed-precision), and also needs to store 4 bytes of momentum and 4 bytes of variance, a total of 12 bytes. If you use an optimizer like SGD, you don’t need to store variance, only 8 bytes are needed.
The intermediate state (activation) of forward propagation is necessary for calculating gradients during backpropagation, and it is proportional to the batch size. The larger the batch size, the more calculations that can be done each time the model parameters are read from memory, which reduces the pressure on the GPU memory bandwidth. However, don’t forget that the number of intermediate states in forward propagation is proportional to the batch size, and the capacity of the GPU memory can become a bottleneck.
People have also found that the memory occupied by the intermediate state of forward propagation is too much, and a trick can be played to exchange computing power for memory. That is, don’t store so many gradients and the intermediate states of each layer of forward propagation, but recalculate the intermediate states of forward propagation temporarily when calculating to a certain layer, so that the intermediate state of forward propagation of this layer does not need to be saved. If every layer does this, then only 2 bytes are needed to store the gradient of this layer. However, the computing power cost of calculating the intermediate state will be very large. Therefore, in practice, the entire Transformer is usually divided into several groups, each group has several layers, and only the intermediate state of the first layer of each group is saved. The subsequent layers are recalculated from the first layer of the group, which balances the cost of computing power and memory.
If you still can’t calculate it, you can read this paper: Reducing Activation Recomputation in Large Transformer Models.
Of course, some people say that if the GPU memory is not enough, it can be swapped out to the CPU memory, but with the current PCIe speed, the cost of swapping out to the CPU memory is sometimes not as good as recalculating in the GPU memory. If it is a unified memory with extremely high bandwidth like Grace Hopper, then swapping in and out is a good idea, whether it is the intermediate state of forward propagation during training or KV Cache, there is a lot of room for optimization.
Pipeline parallelism
Since one GPU is not enough, using multiple GPUs should always work, right? This is model parallelism, which can be roughly divided into pipeline parallelism and tensor parallelism.
The most easily thought of parallel method is pipeline parallelism. The model has many layers, right? Then divide it into several groups, each group calculates a few consecutive layers, and string them into a chain.
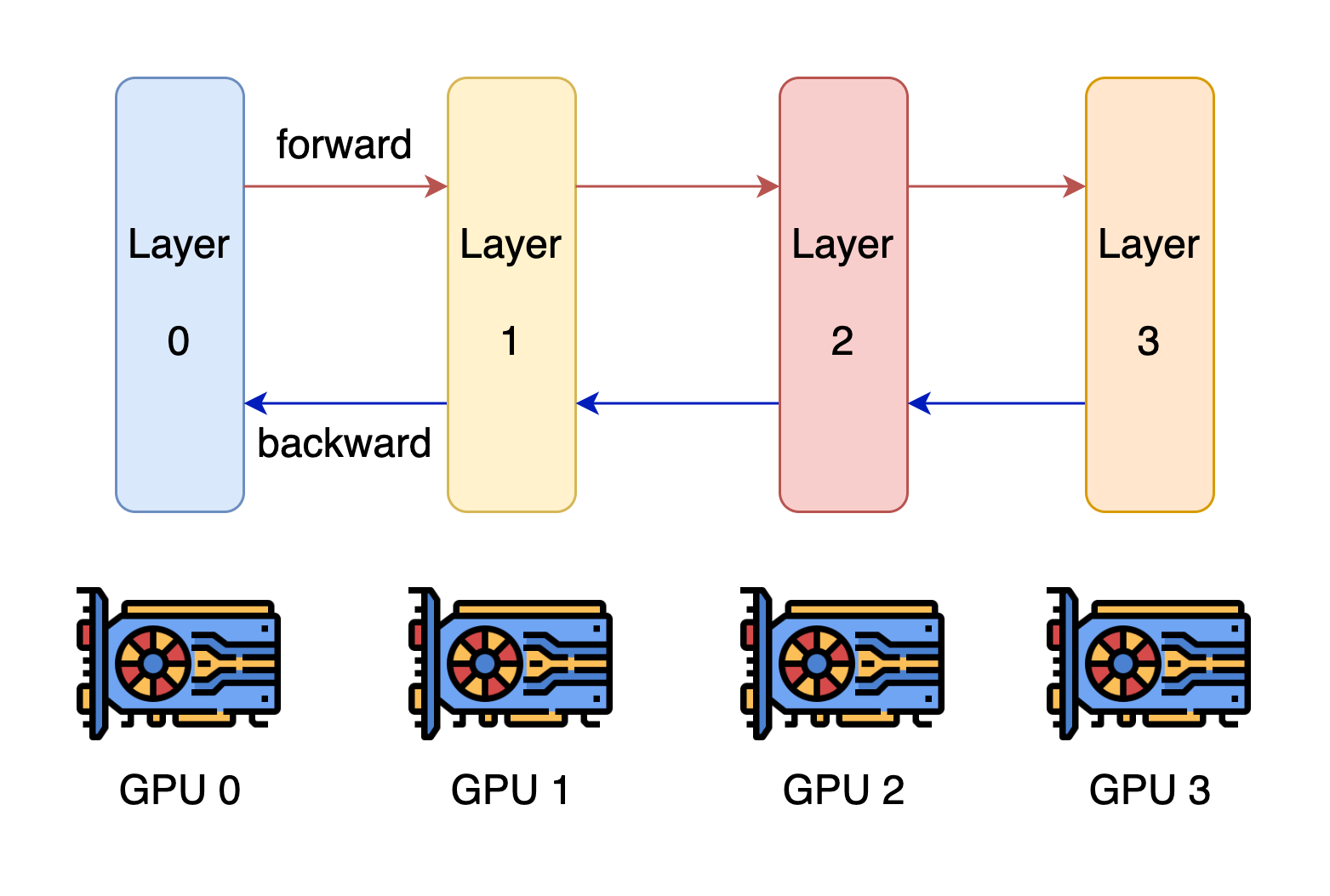 Pipeline Parallelism Diagram, Source: Colossal AI
Pipeline Parallelism Diagram, Source: Colossal AI
There is a problem with this, only one GPU on a chain is working, and the rest are waiting. Of course, you must have thought of it too. Since it’s called a pipeline, it can be processed in a pipeline. You can divide a batch into several mini-batches, each of which is calculated separately.
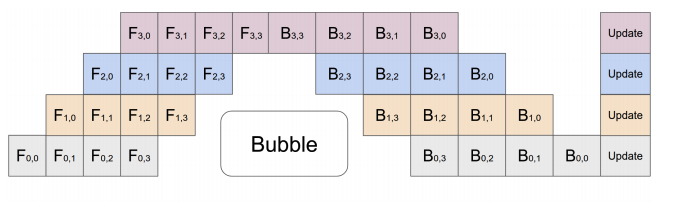 Pipeline Parallelism Diagram, Source: GPipe
Pipeline Parallelism Diagram, Source: GPipe
That’s good, isn’t it better to make the pipeline deeper and each GPU only calculates one layer?
First of all, the storage capacity of the intermediate state (activation) of forward propagation will increase exponentially, exacerbating the problem of insufficient memory capacity. For example, the first stage of the pipeline calculates the intermediate state of forward propagation. If there are N pipeline stages, it needs to flow forward through the next N - 1 pipeline stages, and then wait for the backpropagation of N - 1 pipeline stages, which is 2N - 2 rounds before this intermediate state of forward propagation can be used. Don’t forget that so many intermediate states will be produced in each round, so a total of 2N - 1 intermediate states are saved. If N is relatively large, this storage capacity is very terrifying.
Secondly, there is communication between the adjacent pipeline stages (pipeline stage), the more stages, the higher the total amount of communication data and the total delay.
Finally, to make such a pipeline flow, the batch size needs to be equal to the number of layers in the Transformer, which is generally dozens, multiplied by the number of parallelisms in data parallelism, the batch size will be very large, affecting the speed of model convergence or the accuracy after model convergence.
Therefore, in the case of sufficient memory capacity, it is better to divide fewer pipeline stages.
For the LLaMA-2 70B model, the model parameters require 140 GB, the gradients of backpropagation require 140 GB, and the state of the optimizer (if Adam is used) requires 840 GB.
The intermediate state of forward propagation is related to the batch size and the configuration of selective recalculation. If we take a compromise between computing power and memory, then the intermediate state of forward propagation requires token length * batch size * the number of neurons in the hidden layer * the number of layers * (10 + 24/tensor parallelism) bytes. Assuming batch size = 8, without tensor parallelism, then the intermediate state of forward propagation of the LLaMA-2 70B model requires 4096 * 8 * 8192 * 80 * (10 + 24) bytes = 730 GB, isn’t it big?
The total requirement is 140 + 140 + 840 + 730 = 1850 GB, which is much larger than the 140 GB of model parameters alone. A single A100/H100 card only has 80 GB of memory, which requires at least 24 cards; if you use 4090, a card has 24 GB of memory, which requires at least 78 cards.
The LLaMA-2 model has only 80 layers in total. Isn’t it just right to put one layer on one card? This way, there are 80 pipeline stages, and there are 80 parallel batches just for pipeline parallelism to fill the pipeline.
In this way, the storage of intermediate states during forward propagation will become unbearably large. This is 80 * 2 = 160 rounds of intermediate states, a 160-fold increase. Even if selective recalculation is used, such as dividing the 80 layers into 8 groups, each with 10 layers, the storage of intermediate states is still 16 times larger.
Unless the most extreme complete recalculation is used, each layer is recalculated from the beginning during backpropagation, but the computational overhead grows with the square of the model layers. The first layer calculates 1 layer, the second layer calculates 2 layers, up to the 80th layer calculates 80 layers, a total of 3240 layers are calculated, the computational overhead is 40 times more than the normal calculation of 80 layers, can this be tolerated?
The problem of intermediate state storage is already big enough, let’s look at the communication overhead between these 2048 cards. According to the practice of putting one layer on one card and using different input data to make it fully pipelined, these 2048 cards are calculating their own mini-batches, which can be considered as independently participating in data parallelism. As mentioned earlier, in data parallelism, what needs to be transmitted in each round is the gradient it calculates and the gradient after global averaging, and the amount of gradient data is equal to the number of model parameters.
Divide the 70B model into 80 layers, each layer has about 1B parameters, since the optimizer uses 32 bit floating point numbers, this requires the transmission of 4 GB data. So how long does a round of calculation take? The total computation = batch size * token number * 6 * parameter amount = 8 * 4096 * 6 * 1B = 196 Tflops, on 4090 if we assume a 100% utilization rate, it only takes 0.6 seconds. And transmitting this 4 GB data through PCIe Gen4 takes at least 0.12 seconds, and it needs to be transmitted twice, that is, first transmit the gradient, and then transmit the average gradient, this 0.24 second time compared to 0.6 seconds, is a relatively large proportion.
Of course, we can also optimize, let each GPU in pipeline parallelism process the 80 groups of gradient data first do an internal aggregation, so theoretically a training step just needs 48 seconds, the time occupied by communication is less than 1 second, the communication overhead can be accepted. Of course, the premise that communication takes less than 1 second is that there are enough network cards plugged into the machine, able to spit out all the bandwidth of PCIe Gen4 through the network, otherwise the network card will become the bottleneck. If a machine has 8 GPUs plugged in, it basically needs 8 ConnectX-6 200 Gbps RDMA network cards to meet our needs.
Finally, let’s look at the batch size. When the entire 2048-card cluster is running, we just set the mini-batch of each GPU to 8, that’s really a batch size = 16384, which is already a relatively large batch size in large-scale training, if it gets bigger, it may affect the convergence speed or accuracy of the model.
Therefore, the biggest problem with using pipeline parallelism and data parallelism to train large models is that there are too many pipeline parallel stages, resulting in insufficient storage capacity for intermediate states (activation) during forward propagation.
Tensor parallelism
So is there no way out? We have one last trick, which is Tensor parallelism. It is also a kind of model parallelism, but unlike pipeline parallelism which divides between model layers, it divides within model layers, that is, it divides the attention calculation and Feed Forward Network into multiple GPUs for processing.
With tensor parallelism, the problem of too many pipeline stages due to the model not fitting on the GPU can be alleviated. A model that needs to be divided into 80 GPUs to fit, if using 8-card tensor parallelism on a single machine, only needs to divide into 10 pipeline stages. At the same time, tensor parallelism can also reduce the batch size, because the several GPUs in tensor parallelism are calculating the same input data.
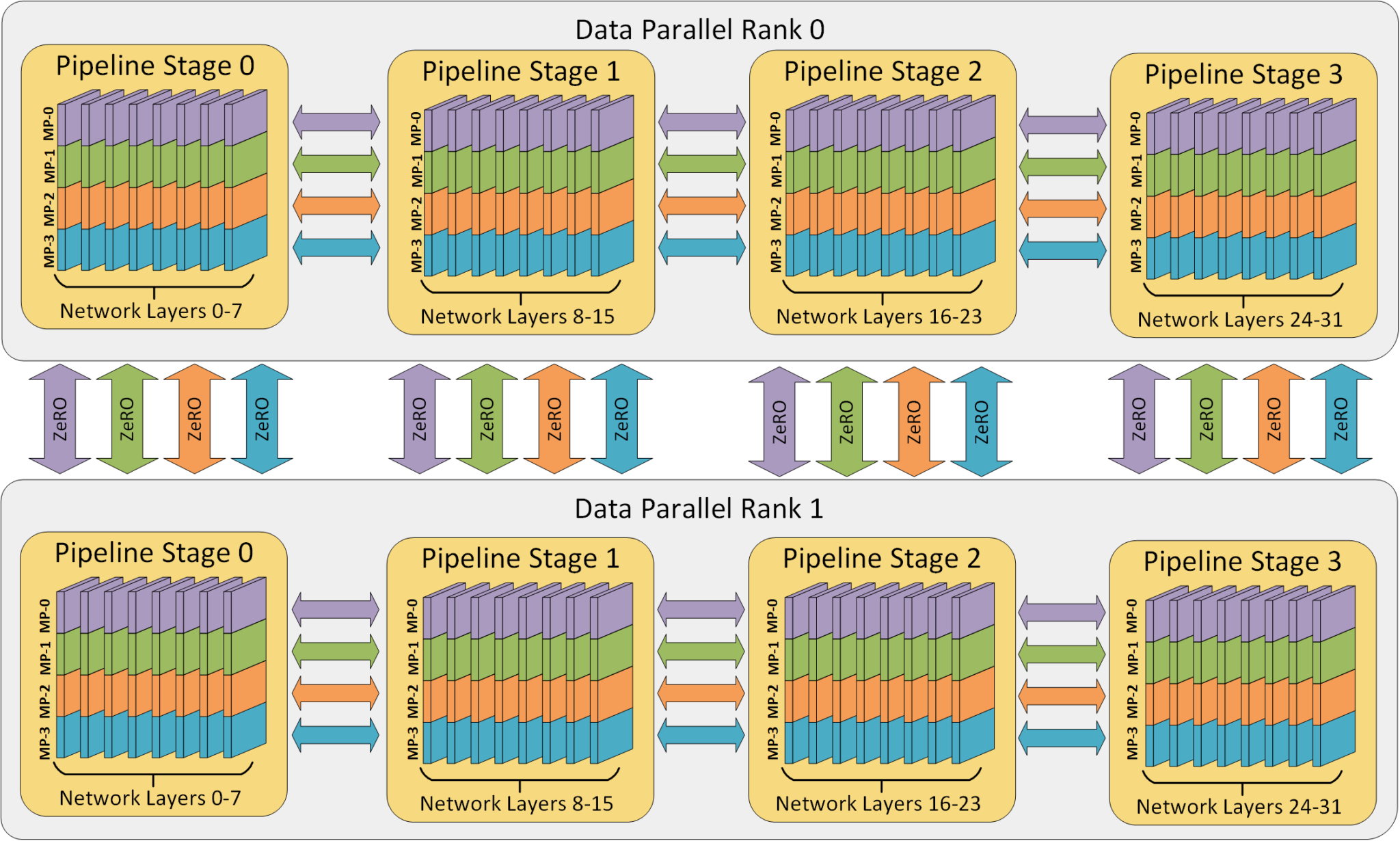 Tensor, Pipeline, Data three parallel methods divide the computing space from the model layer, model layer, training data three dimensions, source: DeepSpeed
Tensor, Pipeline, Data three parallel methods divide the computing space from the model layer, model layer, training data three dimensions, source: DeepSpeed
The calculation process of Attention is relatively easy to parallelize, because there are multiple heads, used to pay attention to different positions in the input sequence, so just split these heads separately.
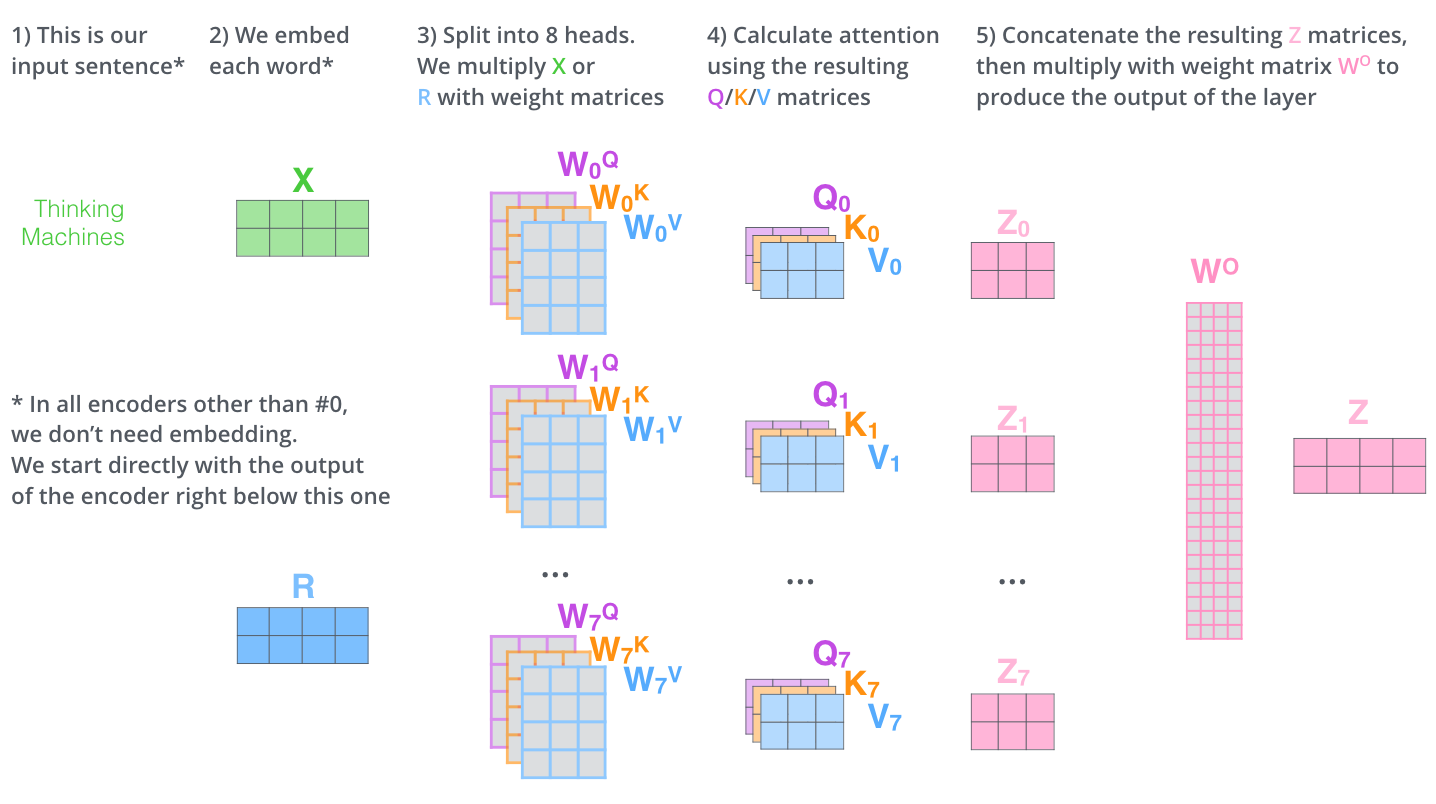 The calculation process of Attention, source: The Illustrated Transformer
The calculation process of Attention, source: The Illustrated Transformer
But we should never forget the communication overhead when we do any parallel computing.
The size of the Q and K matrices in each head is batch size * token length * size of key, and the size of the V matrix is batch size * token length * size of value. The size of key/value is generally equal to embedding size / number of heads, for example, in LLaMA-2 70B it is 8192 / 64 = 128, the matrix size is batch size * 4096 * 8192 / 64 (note, this is just one head’s). And the size of the Q, K, V parameter matrices on each head is embedding size * embedding size / heads num = 8192 * 8192 / 64.
We have previously derived that the forward calculation amount is basically the calculation amount of each token passing through all parameters once, 2 * 3 (Q, K, V) * batch size * token length * number of parameters = 2 * 3 * batch size * 4096 * 8192 * 8192 / 64. You can compare it with the size of the matrix to see if there is any miscalculation.
So, what is the communication volume? The output matrix Z is spliced together by each head, and the size of each head is batch size * token length * embedding size / heads num = batch size * 4096 * 8192 / 64. The size of the input matrix X is batch size * token length * embedding size = batch size * 4096 * 8192. Note that the size of X here is consistent with the size of Z after all heads are merged, and what we calculate here is the size of Z for each head. The unit here is the number of parameters, if calculated in bytes, it needs to be multiplied by the size of each parameter.
If we adopt the most extreme method, each head is calculated by a GPU, then what is the ratio of calculation volume to communication volume? It is roughly 2 * 3 * embedding size / heads num / bytes per param = 2 * 3 * 8192 / 64 / 2 = 384. Substituting 4090’s 330 Tflops, if you want communication not to become a bottleneck, then the communication bandwidth needs to be at least 330T / 384 = 859 GB/s, and the bidirectional send and receive need to be multiplied by 2, which is 1.7 TB/s. It’s too big, far exceeding the 64 GB/s of PCIe Gen4 x16, even the 900 GB/s of NVLink can’t hold it.
So, tensor parallelism cannot be cut too fine, each GPU needs to calculate several more heads. If each GPU calculates several more attention heads, the input matrix X is shared by these heads, so the communication overhead of the input matrix is shared by multiple heads, and the ratio of calculation volume to communication volume can be improved.
Still calculate according to 4090’s computing power / unidirectional communication bandwidth = 330T / (64GB/s / 2), the ratio of computing volume to communication volume needs to be at least 10000, that is, 2 * 3 * (embedding size / tensor parallel GPU quantity) / bytes per param = 2 * 3 * 8192 / tensor parallel GPU quantity / 2 >= 10000, the solution is: tensor parallel GPU quantity <= 2.4. That is to tell you, if you use tensor parallelism, you can use up to 2 GPUs. If you use more GPUs, the computing power will definitely not reach the theoretical value. How can I play this?
However, if you substitute the parameters of H100, it will be different immediately. The peak computing power of H100 is 989 Tflops, the bidirectional bandwidth of NVLink is 900 GB/s, the ratio of computing volume to communication volume needs to be at least 1100, that is, 2 * 3 * (embedding size / tensor parallel GPU quantity) / bytes per param = 2 * 3 * 8192 / tensor parallel GPU quantity / 2 >= 1100, the solution is: tensor parallel GPU quantity <= 11, that is, a single machine with 8 cards does tensor parallelism, for the model with embedding size = 8192, it is just right, communication will not become a bottleneck!
The castrated version of H800 compared to H100 card is the network bandwidth, reducing the network bandwidth from 900 GB/s to 400 GB/s. We substitute it again, the ratio of computing volume to communication volume needs to be at least 5000, then the tensor parallel GPU quantity <= 4.8. In this way, a single machine with 8 cards doing tensor parallelism will cause the network to become a bottleneck. Of course, the computing volume of 989 Tflops is a theoretical value, and the parallel splitting method can also be optimized, so the actual training of the 70B model with 8 cards of H800 may not necessarily be a bottleneck. This is H800’s precise attack on large model training, making tensor parallelism uncomfortable.
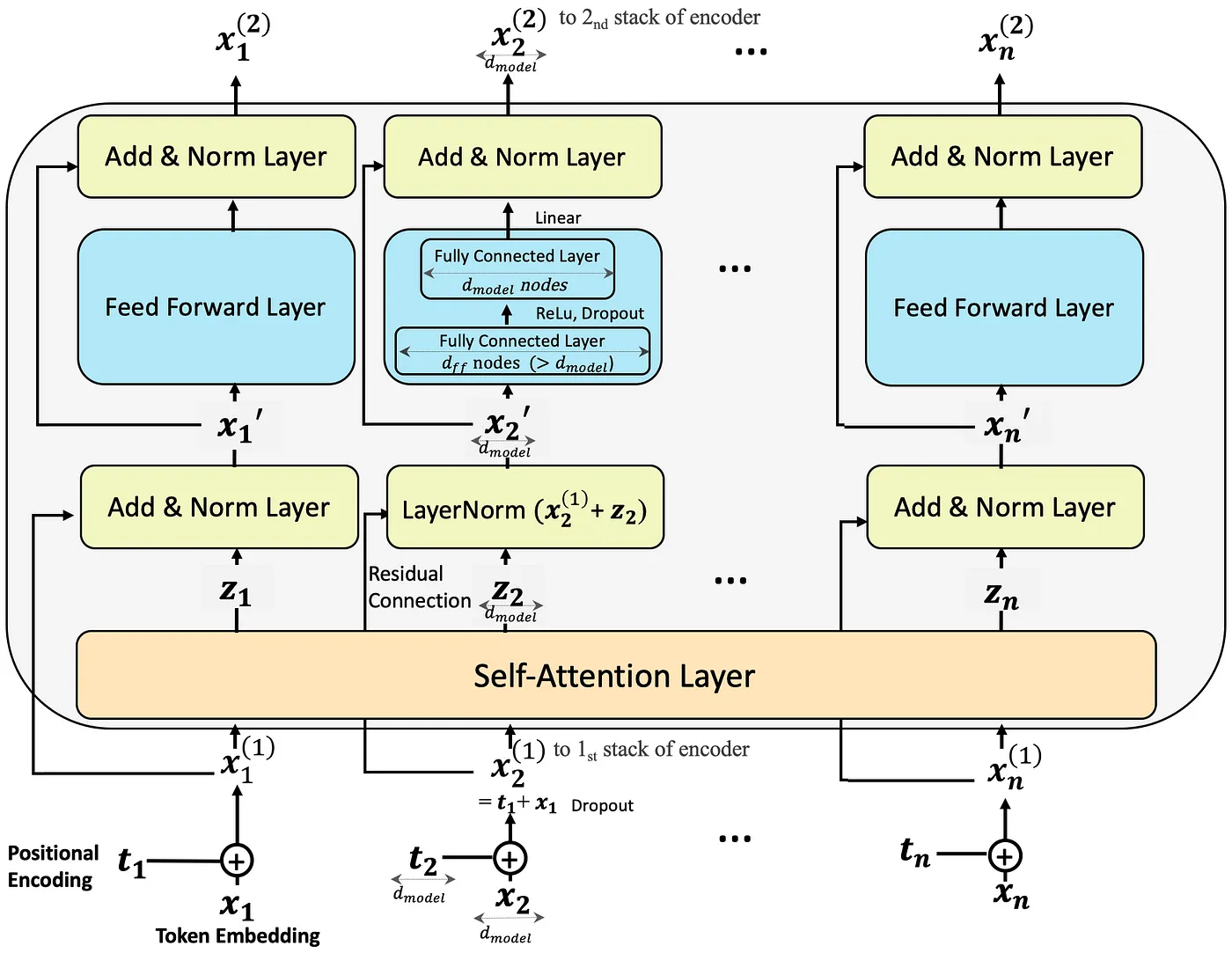 The calculation process of the Feed Forward Network, although this is the encoder's, but the decoder is also similar, source: Step-by-Step Illustrated Explanations of Transformer
The calculation process of the Feed Forward Network, although this is the encoder's, but the decoder is also similar, source: Step-by-Step Illustrated Explanations of Transformer
If tensor parallelism is done here in the Feed Forward Network, similar derivations can also be made, which will not be elaborated here. Generally, in the matrix multiplication of neural networks, the total calculation volume of the MN matrix multiplied by the NK matrix is MNK, and the total size of the input and output is (MN + NK), stacking several more matrices is also a constant (like Q, K, V), that is, the ratio of calculation and communication is of the same order of magnitude as the edge length (dimension) of the matrix.
After such analysis, if you are going to do large-scale large model training, would you still buy the PCIe version of A100/H100/H800? Although PCIe Gen5 is twice as fast as Gen 4, for H100, the ratio of computing volume to communication volume still needs to be at least 989T / (128G / 2) = 15000, and the solution is that the tensor parallel GPU quantity <= 1.6, that is, as long as tensor parallelism is used, it is a loss of computing power!
When the next generation of H100 comes out, such as GH200, the computing power doubles again, and NVLink is still 900 GB/s, then NVLink will start to struggle a bit. So GH200 timely launched a unified large memory, claiming 144 TB, in order to better do swapping in and out, using memory to exchange network communication. If the ban remains unchanged, the domestic version is still stuck at 400 GB/s communication, how big will the performance gap be?
The above derivation is of course simplified, and it may not be so exaggerated in reality, but the order of magnitude is roughly the same.
Training Part Summary
The reasons why 4090 is not easy to do large model training, in addition to the previously analyzed small memory, slow communication, license does not support data center, there are many other problems.
For example, A100/H100 supports ECC video memory fault tolerance, it is said that 4090 also supports ECC, but I don’t know if the failure rate will be higher than A100/H100. Don’t underestimate fault tolerance, a cluster of 2048 cards, even if each card fails once a month, on average there will be a card failure every 20 minutes! If there is no automated fault recovery method, the alchemist can’t sleep.
Even if it is automatically recovered from the previous checkpoint, this takes time. If you don’t consider discarding the faulty GPU gradient in a more violent way, the current step is wasted, and you have to load the gradient from the previous checkpoint, which usually takes about 10 minutes to complete. In this way, every 20 minutes wastes 10 minutes, and there may be new card failures during these 10 minutes of recovery, and half of the effective computing power is wasted in total.
Therefore, maintaining a low failure rate for large-scale training clusters is very important, these GPU cards are very valuable, and they can’t be like mining machine rooms, where they often overheat and crash.
It is said that 3090 supports NVLink, but 4090 has cut off NVLink. Older cards, even those that support PCIe P2P, have also been cut off. Anyone interested can test how the NVLink performance of 3090 is, whether it can really reach the claimed 600 GB/s, and if it can, whether it can be used for large model training.
At our annual meeting, Brother Hai told a joke, we all hope to find a wife who is beautiful, can make money, and loves herself wholeheartedly. But it’s hard to find a wife who meets all three conditions at the same time. Similarly, in distributed systems, we all hope that the performance is high, the versatility is strong, and the cost is low. The intersection of these three conditions is also small. When Brother Hai said this, Tan Bo added a sentence, there is no distributed system that can meet these three conditions at the same time.
Tensor, Pipeline, Data Parallelism are like this impossible triangle, restraining each other, as long as the cluster scale is large enough and the model structure is still Transformer, it is difficult to escape the claws of memory capacity and network bandwidth.
Why 4090 is very attractive for large model inference
What’s the difference between inference and training?
First of all, training not only needs to store model parameters, but also needs to store gradients, optimizer states, and intermediate states (activation) of each layer of forward propagation. The latter few are larger than the parameters and require more model memory.
Secondly, the training task is a whole, the intermediate results of pipeline parallel forward propagation need to be stored for backward propagation. In order to save memory and use pipeline parallelism, the more pipeline stages, the more intermediate states need to be stored, which exacerbates the lack of memory. In the inference task, there is no relationship between the input data, and the intermediate state of each layer of forward propagation does not need to be saved, so pipeline parallel does not need to store many intermediate states.
First, we need to calculate how much computing power is needed for inference. The previous estimation of training computing power, for simplicity, ignored two things, first, it did not consider KV Cache, and second, it did not consider memory bandwidth.
KV Cache
What is KV Cache? For each input prompt, when calculating the output of the first token, the attention of each token must be calculated from the beginning. But in the generation of subsequent tokens, it is necessary to calculate self-attention, that is, the attention of the input prompt and the previously output tokens. At this time, the K and V of each token in the front are needed. Since the parameter matrix of each layer is unchanged, only the K and V of the newly generated token need to be calculated from the beginning, and the K and V of the input prompt and the previously generated tokens are actually the same as the previous round.
At this time, we can cache the K and V matrices of each layer, and no longer need to recalculate when generating the next token, which is the so-called KV Cache. The Q matrix is different every time and has no caching value. The selective saving of forward activation in the previous training is a trick to exchange calculation for memory, and this KV Cache is a trick to exchange memory for calculation.
How much storage capacity does KV Cache need? Each layer, the K and V matrix of each token is as large as the embedding size, multiplied by the number of tokens and batch size, is the storage capacity required for this layer’s KV Cache. Remember the batch size, in almost all stages of forward and backward propagation, there will be no merging processing for each sample in the batch size, so it is always a coefficient in the calculation of storage and computation.
For example, if batch size = 8, in LLaMA 2 70B, assuming the number of input and output tokens has reached the model’s limit of 4096, the 80-layer KV Cache needs a total of 2 (K, V) * 80 * 8192 * 4096 * 8 * 2B = 80 GB. If the batch size is larger, then the space occupied by the KV Cache will exceed the 140 GB occupied by the parameters themselves.
How much computation can the KV Cache save? Each layer needs 2 (K, V) * 2 (mult, add) * embedding size * embedding size = 4 * 8192 * 8192 computations to calculate the K, V matrices, multiplied by the number of tokens previously input, the number of layers, and the batch size, which is 4096 * 80 * 8 * 4 * 8192 * 8192 = 640 Tflops. That is, for every byte stored, 16K computations are saved, which is quite cost-effective.
In fact, the KV Cache saves far more than these. The process of calculating the K, V matrices is a typical memory-intensive process, which requires loading the K, V parameter matrices of each layer. That is, if no caching is done, assuming the prompt length is very short and the output length is close to the maximum token length of 4096, by the time the last token is reached, just repeating the calculation of the K, V matrices for each previous token requires reading memory 4096 * 80 * 2 * 8192 * 8192 = 40T times, each time 2 bytes. You should know that the memory bandwidth of H100 is only 3.35 TB/s, and 4090 is only 1 TB/s. This alone would take tens of seconds for a single card to do repeated calculations for the last token. In this way, the output of tokens will become slower and slower, and the total output time is square of the output length, which is simply unusable.
Is inference computation-intensive or storage-intensive
Next, we can calculate the amount of computation required for inference. The total computing power is easy to calculate, as mentioned earlier, it is roughly 2 * output token number * parameter number flops. If you want to see the details, you can look at the following picture, the source is here.
 Transformer inference process in each step of the matrix shape, required computing power and memory access, source: Lequn Chen, Dissecting Batching Effects in GPT Inference
Transformer inference process in each step of the matrix shape, required computing power and memory access, source: Lequn Chen, Dissecting Batching Effects in GPT Inference
But computing power can’t explain everything, the model also needs to access GPU memory, and memory bandwidth may also become a bottleneck. At least the parameters need to be read from memory, right? In fact, the estimation of memory bandwidth is so simple, memory access = parameter number * 2 bytes. Some of the intermediate results can be stored in the cache, and the part that can’t fit in the cache also needs to occupy memory bandwidth, we won’t calculate it for now.
If no batch input is done, that is, the model serves a single prompt, batch size = 1, and the entire context length is very short (for example, only 128), then during the entire inference process, each time a parameter (2 bytes) is loaded, only 128 multiplications and additions are performed, then the ratio of computing flops to accessing memory bytes is only 128. Basically any GPU in this situation will become memory bound, time is spent on loading memory.
For 4090, the ratio of computing flops to memory bandwidth is 330 / 1 = 330; for H100, the ratio of computing flops to memory bandwidth is 989 / 3.35 = 295. That is, if the number of tokens in the context is less than 330 or 295, then memory access will become a bottleneck.
Although the theoretical limit of LLaMA 2 is 4096 tokens, many input prompts do not use so many, so memory access may become a bottleneck. At this time, it needs to be supplemented by batch size. Batch processing in inference is to process prompts that arrive at the backend service almost simultaneously. Don’t worry, the processing of different prompts in the batch is completely independent, and there is no need to worry about interference. But the output of these prompts is synchronized, and each round of the entire batch will output a token for each prompt, so if some prompts finish outputting first, they can only wait for the others to finish, causing some waste of computing power.
Some people ask, the computing power required for batch processing is the same as the computing power required for separate processing, so why do we need batch processing during inference? The answer lies in the bandwidth of memory access.
If there are many prompts arriving at the server at the same time, is the larger the batch size, the better? Not necessarily, because the size of the KV Cache is proportional to the batch size. If the batch size is large, the GPU memory capacity occupied by the KV Cache is considerable. For example, in LLaMA-2 70B, each prompt has to occupy 5 GB of KV Cache. If the batch size is increased to 32, then the KV Cache will occupy 160 GB of GPU memory, which is larger than the parameters.
How many cards are needed for 70B inference?
The total storage capacity is easy to calculate. The main memory consumption during inference is parameters, KV Cache, and the intermediate results of the current layer. When the batch size = 8, the size required for the intermediate results is batch size * token length * embedding size = 8 * 4096 * 8192 * 2B = 0.5 GB, which is relatively small.
The parameters of the 70B model are 140 GB, which cannot be placed on a single card whether it’s A100/H100 or 4090. So, are 2 H100 cards enough? It seems that 160 GB is enough, but if the remaining 20 GB is used to place the KV Cache, either the batch size is halved, or the maximum token length is halved, or the KV Cache is quantized and compressed for storage, which doesn’t sound wise. Therefore, at least 3 H100 cards are needed.
For 4090, 140 GB parameters + 40 GB KV Cache = 180 GB, each card is 24 GB, and 8 cards can just fit.
Can pipeline parallelism be used for inference?
In 2017, when I was at MSRA, I did a research, using multiple FPGAs to form a pipeline for Bing Ranking neural network inference, solving the problem of FPGA occupying a lot of resources due to swapping in and out between SRAM and DRAM, and even achieving super-linear acceleration by placing the model completely in the FPGA pipeline’s SRAM.
In the era of GPU and Transformer, pipeline parallelism is also to solve the problem that a single GPU cannot fit the entire model. If you force it in, you need to swap in and out repeatedly between GPU memory and CPU memory, resulting in poor performance.
The main problem with using pipeline parallelism for inference is the serial processing inference latency, and network latency is a minor issue.
First is the inference latency. Although different stages of the pipeline can be filled with different prompts, the processing of the same prompt is always rotating on a single GPU, which increases the latency of a single prompt compared to Tensor parallelism.
For a very small batch size, the GPU memory bandwidth is the bottleneck. At this time, the delay of each card calculating each token is 2 byte * parameter amount / number of cards / memory bandwidth, for example, 8 cards 4090 running LLaMA-2 70B, it is 2 * 70G / 8 / 1 TB/s = 0.0175 seconds. This does not consider the savings brought by KV Cache. Note that the 8 cards are processed serially, so the delay of each token has to be multiplied by 8, which is 0.14 seconds. Only 7 tokens can be output per second, which is a bit slow for such a small model as 70B.
For a very large batch size, the GPU computing power is the bottleneck. At this time, the delay of each card calculating each token is batch size * 2 * parameter amount / number of cards / computing power, for example, batch size = 1024, the same 8 card example, it is 1024 * 2 * 70G / 8 / 330 Tflops = 0.0543 seconds. In fact, for such a large batch size, the KV Cache and the intermediate results of forward propagation have filled the GPU memory first.
So, what should the batch size be to balance the use of GPU computing power and memory bandwidth? This is 2 byte * parameter amount / number of cards / memory bandwidth = batch size * 2 * parameter amount / number of cards / computing power, the parameter amount and the number of cards on both sides cancel each other out, resulting in batch size = computing power / memory bandwidth. For 4090, it is 330 / 1 = 330; for H100, it is 989 / 3.35 = 295. That is to say, for 4090, when the batch size is less than 330, the GPU memory bandwidth is the bottleneck, and when it is greater than 330, the GPU computing power is the bottleneck. When batch size = 330, ideally, both memory bandwidth and computing power are fully utilized, and the time for each card to process each token is 17.5 ms.
Next is network latency. The advantage of pipeline parallelism compared to tensor parallelism is that the network transmission volume is small, and only batch size * embedding size data needs to be transmitted between pipeline stages. For example, batch size = 8, embedding size = 8192, only 128 KB of data needs to be transmitted, which can be completed in 4 us on a 32 GB/s PCIe Gen4 x16. Of course, the overhead of the communication library itself needs to be considered. Plus, the 4090 does not support P2P transmission between GPUs and needs to be transferred through the CPU, which actually takes tens of us. Compared to the tens of ms delay of the calculation part, it can be ignored.
Even if batch size = 330, this 5.28 MB data only needs to be transmitted for 0.16 ms on PCIe, which can still be ignored compared to the 17.5 ms of the calculation part.
If you can tolerate the inference delay of pipeline parallelism, you can even use multiple hosts for pipeline parallelism. We assume that there is only a common 1 Gbps Ethernet network between hosts, and each host only has one 4090. For batch size = 1, 16 KB data takes 0.25 ms to transmit, plus 0.25 ms processing time of the network protocol stack at both ends, each pipeline stage requires a delay of 0.5 ms, 8 cards spend only 4 ms on communication, which can be ignored compared to the overall calculation delay of 140 ms, and will not significantly affect the inference delay of the system.
When the batch size is very small, the network traffic in pipeline inference is bursty, and only 0.25 ms data transmission will be performed every 18 ms, with only 1/72 duty cycle, so you don’t have to worry about pipeline inference occupying all the local area network, making it impossible to surf the internet normally.
If you want to fully utilize the computing power and set the batch size to be very large, such as 330, then 16 KB * 330 = 5.28 MB data needs to be transmitted for 41 ms, and 8 cards spend as much as 0.33 seconds on communication, resulting in only 3 tokens/s output speed, which is unbearable. Therefore, if you use inter-host communication for pipeline parallelism, and there is not a high communication bandwidth between hosts, you will inevitably have to sacrifice a certain throughput.
For example, we set the output speed to be no less than 5 tokens/s, at this time the time left for communication is 60 ms, each pipeline stage is at most 7.5 ms, 1 Gbps network can transmit 960 KB data, at this time the batch size can be set to a maximum of 60, that is, the total throughput of these 8 4090s is 2400 tokens/s. The effective utilization rate of computing power is less than 20%.
Recently, there is a popular Petals open source project, which uses pipeline parallelism to turn GPUs into a distributed network similar to BitTorrent. Although the inference delay is indeed high, it at least demonstrates the feasibility of distributed GPU inference.
How about tensor parallelism for inference?
As mentioned earlier, the biggest disadvantage of pipeline parallelism is that GPUs process serially, the delay is high, and the output tokens are slow. The biggest disadvantage of tensor parallelism is that the amount of data transferred is large, and devices with low network bandwidth may not be able to hold it.
But the amount of data to be transferred for inference is not the same as the amount of data to be transferred for training! Inference only needs to transfer the intermediate results (activation) of forward propagation, while training also needs to transfer the gradients of all parameters, and the gradient is the bulk of the data.
In inference, if tensor parallelism is used, each layer of the Transformer needs to broadcast its responsible result vector (size = batch size * embedding size / num GPUs) to all other GPUs, and accept data broadcast from all other GPUs. When calculating attention, you need to transfer once, and when calculating the feed-forward network, you need to transfer again, that is, you need to transfer 2 * number of layers in total.
Each transmission is batch size * embedding size (sending and receiving are different directions, cannot be counted twice), for batch size = 1, embedding size = 8192, only 16 KB data needs to be transferred, it only takes 1 us on 32 GB/s PCIe Gen4. Of course, considering the CPU transfer overhead discussed earlier, it still takes about 30 us. A total of 160 transmissions, requiring 4.8 ms.
Let’s consider the computational overhead. Still considering the situation of batch size = 1, the GPU memory bandwidth is the bottleneck, at this time the delay of each card to calculate each token is 2 byte * parameter amount / number of cards / memory bandwidth, substituting our previous values, it is still 17.5 ms. But here 8 cards are processed in parallel, so the total processing time is calculation time + communication time = 17.5 ms + 4.8 ms = 22.3 ms. This means that 45 tokens can be generated per second, this token generation speed is already very good, at least it is difficult for human reading speed to catch up with the generation speed.
What if the batch size is larger? For example, batch size = 330, fully utilizing the GPU computing power and memory bandwidth, each time you need to transfer data is 330 * 8192 * 2 = 5.4 MB, it takes 0.17 ms on 32 GB/s PCIe Gen4. A total of 160 transmissions, that is 27 ms. Now the network communication overhead has become the main delay, the total processing time is 27 + 17.5 = 44.5 ms, only 22 tokens can be generated per second, but it is not slow.
Note that no matter how many GPUs are used for parallel inference, as long as tensor parallelism is used, the total amount of data transmitted on the network is the same, so increasing the number of GPUs can only speed up the calculation, not the communication.
Therefore, A100/H100’s NVLink plays a big role in reducing inference latency. If you use H100, take batch size = 295 to achieve a balance of computing power and bandwidth utilization, this 4.72 MB data only needs 4.72 MB / 450 GB/s = 0.01 ms. A total of 160 transmissions, only 1.6 ms. Since the memory bandwidth is larger, the calculation time can also be greatly shortened, for example, the calculation time of H100 is 2 * 70G / 8 / 3.35 TB/s = 5.2 ms. The total processing time is only 5.2 ms + 1.6 ms = 6.8 ms, 147 tokens can be generated per second, which is great!
It can be said that if we talk about the token generation speed of a single prompt, no matter how many 4090s are used, they can’t catch up with 8 H100 cards.
What is the cost of using 4090 for inference?
For inference, regardless of whether pipeline parallelism or tensor parallelism is used, memory bandwidth is the bottleneck when the batch size is not too high.
Suppose the batch size can be high enough to utilize 100% of the computing power, and can solve the problem of insufficient KV Cache, and can solve the problem of too much memory occupied by intermediate results, then how much throughput can these 8 4090s achieve?
Of course, these two problems are not easy to solve, so inference optimization is a hot research field, with many trade-offs and tricks. If you just use standard PyTorch, the inference performance is still far from utilizing 100% of the computing power.
Assuming all problems are solved, in the communication process of tensor parallelism, we can use double buffer to calculate another batch, that is, calculate and communicate in parallel, further increasing the throughput. The communication and calculation are 27 ms and 17.5 ms respectively. The transmission of 27 ms is the bottleneck, which means that a group of tokens is output every 27 ms. A batch of 330 prompts, then these 8 4090s can reach a throughput of 330 / 0.027 = 12.2K tokens per second.
The cost of 8 4090s is 12,800 US dollars, and the 8-card PCIe Gen4 server itself costs 20,000 US dollars, plus network equipment, an average of 40,000 US dollars per device. Fixed assets are amortized over 3 years, at 1.52 dollars per hour. The total power consumption is about 400W * 8 + 2 kW = 5 kW, calculated at 0.1 US dollars per kilowatt-hour, 0.5 US dollars per hour. A rack can hold 4 such 8-card servers, and the cost of renting a data center cabinet (excluding electricity) is 1500 US dollars a month, which is 0.5 US dollars per hour. This 2.5-dollar-per-hour machine can generate 12.2K * 3600 = 44M tokens, which means 1 dollar can generate 17.6M tokens.
Is it 35 times cheaper than GPT-3.5 Turbo’s $0.002 / 1K tokens, which is 1 dollar 0.5M tokens? Of course, the account can’t be calculated like this.
- First, the utilization rate of GPU computing power cannot reach 100%;
- Secondly, like all SaaS services, the number of user requests has peaks and valleys. Users pay by volume, but the platform provider is burning money whether or not someone is using it;
- In addition, the length of different prompts in each batch and the number of response tokens are different. The computing power consumed is the largest in the batch, but the money collected is the actual number of tokens used by the user;
- Again, GPT-3.5 is a 175B model, which is likely to have higher inference costs than the 70B LLaMA;
- Finally, OpenAI developed GPT-3.5 at an unknown cost, and they at least have to earn back the training costs and the salaries of the R&D personnel.
Actually, GPT-3.5 Turbo’s $0.002 / 1K tokens is really quite conscientious. Some sell API, LLaMA-2 70B dare to sell more expensive than GPT-3.5 Turbo.
If we switch to using H100 for inference, let’s recalculate this account. A H100 costs at least 30,000 US dollars, an 8-card H100 high-end server plus the matching IB network, at least 300,000 US dollars, also amortized over 3 years, 11.4 US dollars per hour. 10 kW power consumption, electricity costs 1 dollar per hour. A normal power supply and cooling rack can only hold 2 8-card H100s, the cost of renting a cabinet (excluding electricity) is still calculated at 1500 US dollars, which is 1 dollar per hour. A total of 13.4 US dollars per hour.
This is actually a very conscientious price. You can’t rent such a cheap 8-card H100 from any cloud service provider. So renting cards from cloud service providers to sell SaaS services without a moat, such as the inference API of open source models, unless there is a unique trick to improve inference performance, it is difficult to make a lot of money. The business of being a second landlord is not so easy to do.
Let’s calculate the throughput of this 8-card H100 machine. Tensor parallelism also uses transmission and calculation in parallel. H100’s communication is faster, so calculation is the bottleneck. Every 5.2 ms can output a group of tokens, a batch of 295 prompts, and can reach a throughput of 295 / 0.0052 = 56K tokens per second. Ideally, it can generate 204M tokens per hour, which means 1 dollar can generate 15.2M tokens, the cost of H100 per token is only 16% higher than 4090, which can be considered a tie.
Why is the life cycle price of an 8-card H100 machine 5 times that of a 4090 machine, but the cost performance is almost the same as 4090? Because the computing power of a H100 is 3 times that of a 4090, and the memory bandwidth is 3.35 times that of a 4090. Whether calculated by latency or bandwidth, the single-card performance is basically 3 times. Moreover, H100’s network bandwidth is much stronger than 4090’s, causing 4090’s network communication to become a bottleneck in tensor parallelism, wasting effective computing power. Therefore, the same 8-card machine can reach 4.6 times the throughput of 4090. Although the price of a H100 card is more than 20 times that of a 4090, including the cost of the server itself, electricity, and data center hosting fees, the cost of the whole machine is only about 5 times.
Achieving the Highest Inference Performance with the Cheapest Equipment
We found that in an 8-card 4090 machine, the $30,000 equipment cost, the GPU card only accounted for $12,800, unlike the H100 machine where the GPU cost was the majority. Is there a way to further reduce it?
If we can tolerate an output speed of 5 tokens/s, we can even use pipeline parallelism to build an inference cluster with a home desktop and 4090.
I remember when I was at MSRA, I plugged 10 FPGAs into a machine that only cost $1,000, and made the world’s fastest Key-Value Store. In fact, if I were to design a cost-effective 4090 inference cluster, there are many solutions to try:
- Use pipeline parallelism, desktop + 10 Gbps network card, enough to transmit 5.28 MB of data with a batch size = 330 within 5 ms, communication 40 ms, calculation 140 ms, to achieve a single prompt output speed of 5 tokens/s, while fully utilizing the power of 4090. 10 Gbps network cards and switches are very cheap, Intel X710 network card only costs $150, 20-port switch only costs $1500 (every 8 ports $750), a home desktop $700, this only needs $20,000 to complete the original $40,000 equipment.
- Use tensor parallelism, desktop + 200 Gbps ConnectX-6 network card, go up RoCE, can transmit 5.28 MB of data with batch size = 330 in 0.22 ms, 160 times transmission is 35 ms, plus calculation of 17.5 ms, one token 52.5 ms, can achieve 19 tokens/s single prompt output speed, this speed is already good. Network card $1000, 200G switch $20,000 40 ports, average every 8 ports $4000, a home desktop $700, this only needs $30,000 to complete the original $40,000 equipment.
- Use tensor parallelism within the host, and pipeline parallelism between hosts, 4-card PCIe Gen4 server motherboard only costs $1000 and can run full PCIe bandwidth (because 8 cards will need PCIe switch, the price will be much higher), two hosts use 25 Gbps network card direct connection, the delay of tensor parallelism within the host is 27 ms, the pipeline parallelism between hosts only needs 2 times 8 ms transmission (note that the network bandwidth of 25G is shared by 4 GPU cards), plus two times pipeline calculation each 17.5 ms, a total of 78 ms, can achieve 13 tokens/s single prompt output speed. Network card $300 * 2, server $3000 * 2, this only needs $19,500 to complete the original $40,000 equipment.
$20,000 amortized over 3 years is $0.76 per hour. According to the electricity price of $0.1/kWh, the electricity cost per hour is $0.5, close to the equipment cost, this has a bit of a mining flavor. There is no central air conditioning and UPS in the mining field, only violent fans, the hosting cost is much lower than the data center, the cost of the whole machine is possible to press to $1.5/hour. If the throughput of 44M tokens is fully utilized, $1 can generate 30M tokens, which is exactly twice the 15M token per dollar of 8-card H100.
Why is the cost-effectiveness of H100 only half as good as that of 4090, despite its GPU price being 20 times higher? First, because the energy consumption cost is lower, the power consumption of 8-card H100 is 10 kW, but the power consumption of 9 8-card 4090 is 45 kW; second, because the cost of the host and network equipment is lower, although a 8-card H100 quasi-system is expensive, it only accounts for about 20% of the whole machine price; but 4090, because of the large number of cards, unless the cost is pressed like a GPU mining machine, as long as it is still using data center-level equipment, the quasi-system price will account for more than 35%.
In fact, in this world, there are not only A100/H100 and 4090, but also A10, A40 and other computing cards and 3090 and other game cards, as well as AMD’s GPU and many other manufacturers’ AI chips. H100 and 4090 are probably not the most cost-effective solutions, for example, the cost-effectiveness of A10, A40 and AMD GPU may be higher.
I even want to hold an inference cost-effectiveness challenge, to see who can use the cheapest equipment to produce the strongest inference throughput, while the delay can’t be too high; or use the cheapest equipment to produce the lowest inference delay, while the throughput can’t be too low.
All of this is assuming the use of the LLaMA-2 70B model, without doing quantization compression. If quantization compression is done, the performance will be even higher, and it can even run on a MacBook Pro with enough Unified Memory.
How to Deal with License Issues?
I put this question at the end. The License of NVIDIA Geforce driver states:
No Datacenter Deployment. The SOFTWARE is not licensed for datacenter deployment, except that blockchain processing in a datacenter is permitted.
Since the machines are all assembled from desktop computers, can this be called a data center? Or is it more appropriate to call it a mining farm? They also said that it is allowed to use 4090 for blockchain.
I have a bold idea, what if the future blockchain no longer uses mining to do proof of work, but uses large model inference to do proof of work, isn’t that interesting? Everyone buys a few graphics cards, connects to the mining pool, can use it to play games, and can contribute computing power in their spare time. The mining pool is directly a company selling large model inference SaaS services, providing unprecedented low-cost API. Even people who need large model inference services can play P2P in the blockchain, and those who need to use large models pay some gas.
Of course, the current proof of work is very complex to calculate and very simple to verify. If you really use large model inference to do proof of work, you must prevent users from arbitrarily making up a result and handing it in. Of course, there is a solution to this, just like BitTorrent and other decentralized networks, using a credit mechanism, newcomers can only do the work of verifying other people’s calculation results, accumulating credit; old people make mistakes every time, there are quite severe penalties.
From another perspective, the speed of home local area networks is getting faster and faster, for example, I have deployed a 10 Gbps network at home. There are more and more smart devices at home, and the computing power is getting stronger. Fiber-to-the-home is becoming more and more common, and more and more edge computing nodes are deployed in the operator’s rooms in the community and the city. Previously, we used a 1 Gbps network to form a pipeline parallelism with GPUs on multiple hosts. In the future high-speed home network, pipeline parallelism and even tensor parallelism will become possible.
Most people who do AI inference only care about data centers and ignore the distributed computing power at home. As long as the problems of security, privacy, and economic motivation are solved, my Siri at home may run on the GPU in my neighbor’s house.
Many people are talking about democratizing AI. But the biggest obstacle to the popularization of large models now is cost, and the biggest source of cost is the price difference between computing cards and game cards in the GPU market. This is not to blame a certain company, other companies that make AI chips, the computing power of AI chips is not cheap. After all, the research and development of chips, software, and ecology are all real money.
Just like Microsoft deploying FPGA on each server mentioned at the beginning of this article, the price of mass-produced chips is like sand. At that time, the only thing that can limit the computing power of large model inference is energy, just like blockchain mining and general-purpose CPU cloud computing, all looking for the cheapest power supply. I mentioned in a previous interview that in the long run, energy and materials may be the key to restricting the development of large models. Let us look forward to the cheap large model entering thousands of households and truly changing people’s lives.