Is Cache Coherency Necessary for Load/Store?
(This article was first published on Zhihu)
Cache Coherency (CC) can be divided into two scenarios:
- CC between the CPU and device within the host
- CC across hosts
CC between the CPU and device within the host
I believe that CC between the CPU and device within the host is very necessary. When I was interning at Microsoft in 2017, I used an FPGA to create a memory block attached to the PCIe’s bar space. I was able to run a Linux system on this bar space, but the startup process that should have taken only 3 seconds took 30 minutes, which is 600 times slower than host memory. This is because PCIe does not support CC, and the CPU’s direct access to device memory can only be uncacheable, and each memory access has to go through PCIe to FPGA, which is extremely inefficient.
Therefore, the current PCIe bar space can only be used for the CPU to issue MMIO commands to the device, and data transfer must be carried out through device DMA. Therefore, whether it is an NVMe disk or an RDMA network card, they must follow the complex process of doorbell-WQE/command-DMA, as shown in the figure below.
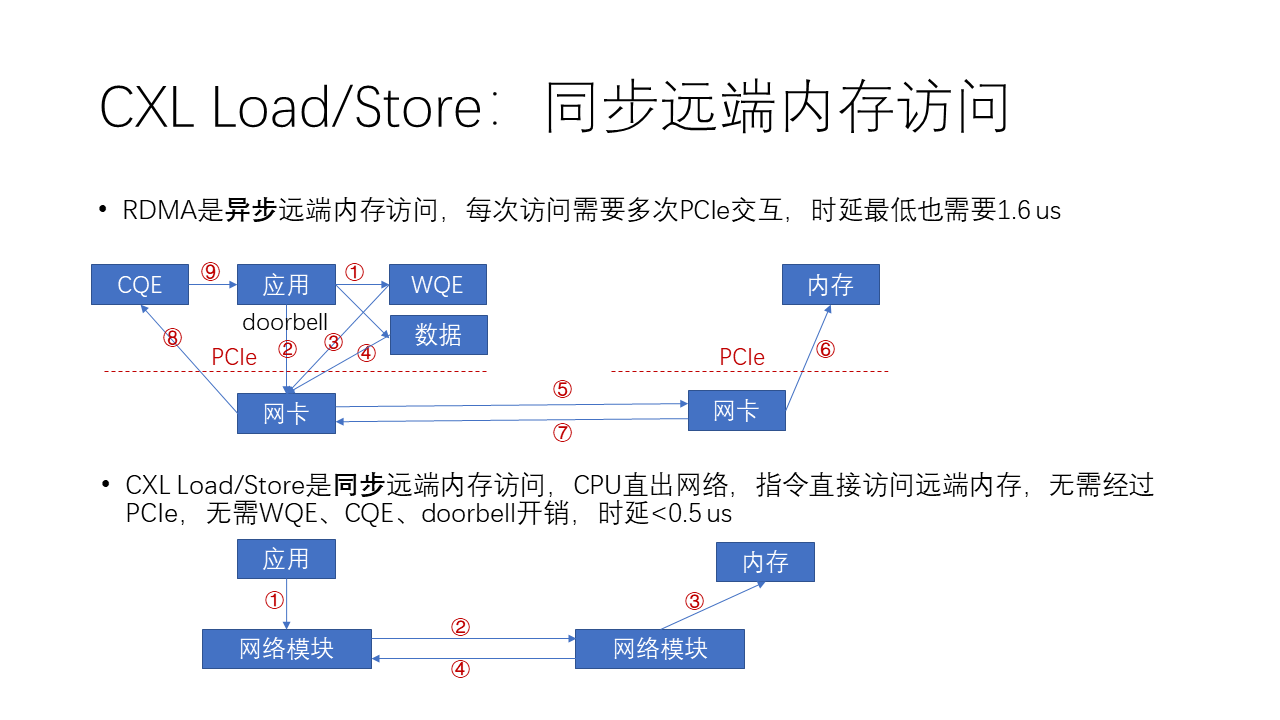 Comparison of RDMA and Load/Store processes
Comparison of RDMA and Load/Store processes
As shown in the figure above, in RDMA, if you want to send data, then:
- The software will first generate a WQE (work queue element), which is a work task in the work queue.
- Then this task issues a doorbell, which is like ringing a doorbell to the network card to say that I have something to do.
- Then, after the network card receives this doorbell, it will fetch this work task from the memory into the network card.
- Then, according to the address in the work task, it accesses the data in the memory and DMAs it to the network card.
- Next, the network card will package this data into a network packet and send it from the local to the remote.
- Then, after the network card at the receiving end receives this data, it writes it to the remote memory.
- Then, the network card at the receiving end returns a completion message saying that I am done.
- After the network card at the initiating end receives this completion message, it generates a CQE in the local memory.
- Finally, the application needs to poll this CQE, that is, it needs to get the completion event in the completion queue to complete the entire process.
We can see that the whole process is very complex. Compared with the more complex asynchronous remote memory access of RDMA, CXL and NVLink’s Load/Store is a simpler synchronous memory access method. Why is it simpler?
Because its Load/Store is a synchronous memory access instruction, that is, the CPU (for CXL) or GPU (for NVLink) has a hardware module that can directly access the network unit. Then this instruction can directly access the remote memory without going through PCIe, so there is no need for the overhead of WQE, CQE, and doorbell, and the entire latency can be reduced to less than 0.5 us. The whole process actually only requires 4 steps:
- The application issues a Load/Store instruction;
- The network module in the CPU initiates a Load or Store network packet to get or send data on the network;
- The network module on the other side will do a DMA, take the corresponding data from the memory;
- Feedback to the initiating network module through the network, and then this instruction of the CPU is declared complete, and the subsequent instructions can continue.
Note that this Load/Store does not necessarily require CC across hosts, it only requires CC between the CPU core and device within the host. Just like RDMA Read/Write, RDMA Read/Write is data migration between remote memory and local memory, and Load/Store is data migration between remote memory and registers. If the data in the remote memory or local register is modified, it does not need to be synchronized to the other end.
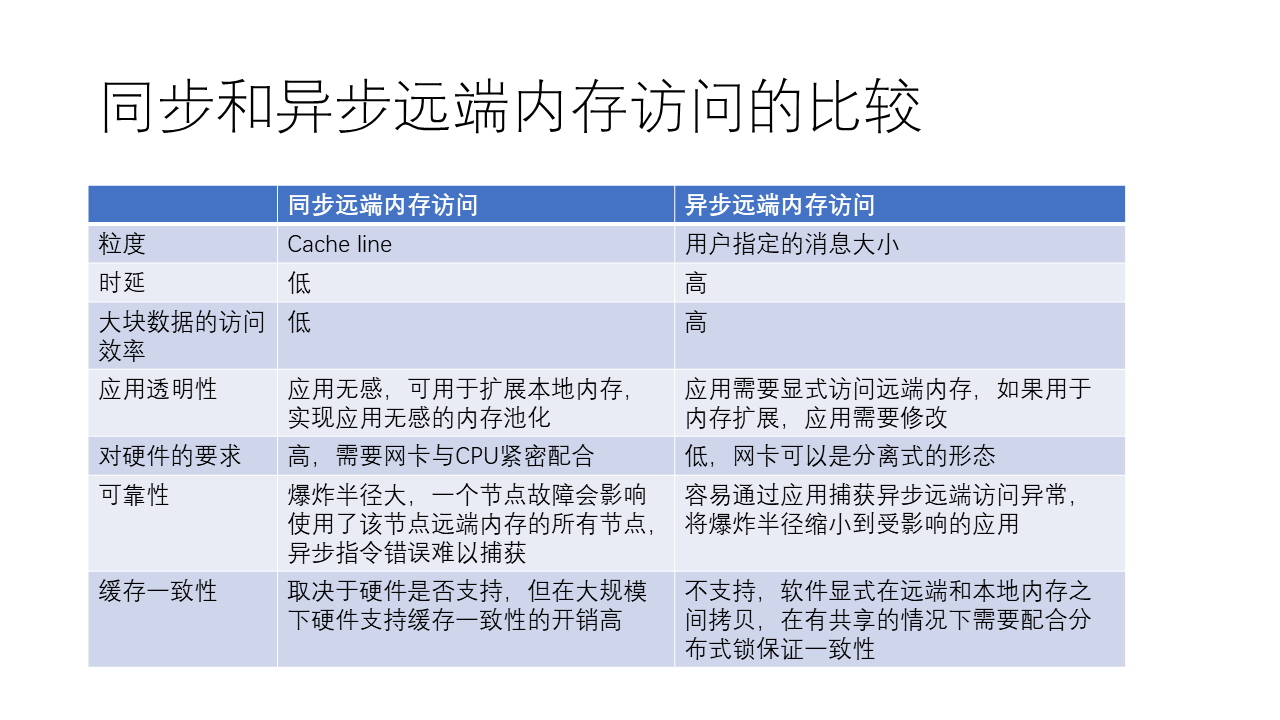 Comparison of synchronous and asynchronous remote memory access
Comparison of synchronous and asynchronous remote memory access
In general, synchronous and asynchronous remote memory access have their own advantages and disadvantages. Synchronous remote memory access, such as CXL and NVLink, uses simple Load and Store operations to achieve remote memory access without too many complex steps. This method is simpler than asynchronous remote memory access, such as RDMA, but it also has certain limitations.
The advantages of synchronous remote memory access are:
- The process is simple, the interaction process is concise, which makes the access latency lower.
- It is transparent to the application and can be used to expand local memory without modifying the application.
- When accessing a small amount of data, the efficiency may be higher.
- With hardware support, it may support cache consistency.
The disadvantages of synchronous remote memory access include:
- High hardware requirements, requiring close cooperation between the network card and CPU.
- Each access involves a relatively small amount of data (usually a cache line, such as 64 bytes), so the efficiency may be lower when accessing large amounts of data compared to asynchronous remote memory access.
- The reliability of synchronous remote memory access may be poor, as a failure of one node may affect all nodes that use the remote memory contributed by that node. There is a concept of a so-called “blast radius”, if the remote memory fails, it affects not only its own node, which can lead to an increase in the blast radius.
- The overhead of cache consistency at a large scale is high.
The advantages of asynchronous remote memory access include:
- Users can specify the size of the data to be accessed, which may be more efficient when accessing large amounts of data.
- The hardware requirements are relatively low, and the network card can adopt a separate form, such as a PCIe interface network card.
- It can capture exceptions through the application, thereby narrowing the impact to the affected application.
The disadvantages of asynchronous remote memory access include:
- The process is more complex, involving complex interactions with the network card, resulting in relatively high access latency.
- It is not transparent to the application and requires explicit access to remote memory, so if it is used to extend memory, the application needs to be modified.
- It does not support cache consistency and requires software to copy between remote and local memory, and to ensure consistency in shared memory situations with distributed locks.
- Depending on the actual application scenario and requirements, developers can choose the appropriate memory access method. For scenarios that need to access small amounts of data and have high latency requirements, synchronous remote memory access may be more suitable; for scenarios that need to access large amounts of data and have low latency requirements, asynchronous remote memory access may be more efficient.
What’s interesting about NVLink is that it dares to use Load/Store for large data transfers because the GPU has many cores and NVLink has low latency. Recent research has pointed out that the efficiency of GPU Load/Store is relatively low, occupying a large number of GPU cores and causing pollution of the GPU cache. For example, MSRA’s research at NSDI’23: ARK: GPU-driven Code Execution for Distributed Deep Learning
Apple’s Unified Memory is also a good design for supporting CC shared memory within a single machine. After the CPU and GPU share memory, on the one hand, it solves the problem of insufficient video memory, and on the other hand, it makes the cooperation between the CPU and GPU very efficient.
For example, I ran the 4-bit quantized version of LLaMA 2 on my MacBook Pro a few days ago, and the laptop could run a 70B model, which is very exciting. The video is here: Meta releases open-source commercial model Llama 2, what is the actual experience like? This is thanks to the 96 GB of Unified Memory (actually only 50 GB was used when running), if the CPU memory and GPU memory were separated and each made 96 GB, the cost would be high.
Interestingly, if you use llama.cpp, in the case of having a cache, it takes less than 1 second to load a 70B model on a MacBook Pro (not the first load), while an NVIDIA A100 server needs about 10 seconds to load the model via PCIe. This is because the CPU and GPU share memory, reducing data migration.
Cross-host CC
Cross-host CC is quite controversial. One reason is that large-scale distributed consistency is difficult to achieve, which is an open problem in academia for decades. Another reason is that many people have not thought clearly about the application scenarios.
For example, memory pooling, many people’s story is to borrow the idle memory of other machines to improve the cluster memory usage rate, which does not require cross-host CC, just need Load/Store and host CC. Because the borrowed memory is only used by one machine, the lender does not need to access it, and other machines do not need to access it.
The ultimate version of memory pooling is that many machines share memory and support cross-host CC. There are many advantages, such as simplifying programming, reducing copying, and improving memory utilization. But the ideal is very beautiful, how to store a huge sharer list in reality? What if the overhead of Cache invalidation is too high? Academia has proposed many mitigations, including:
- Expand the cache granularity from cache line to block, page or even object to reduce the overhead of storing the sharer list, but it also increases the invalidation overhead brought by false sharing;
- Change the data structure of the sharer list from bitmap to linked list, or adopt distributed storage, and form a hierarchy of machines sharing the same cache line;
- Control the number of sharers, for example, NVIDIA used to use page fault to do CC, allowing only a single sharer exclusive access (but NVIDIA after all lacks control over CPU and OS, if I do page-fault-based CC, I would definitely make the process of resolving page faults fully hardened, usually not allowing CPU and OS to participate); academia also has a maximum of 3 (for example) sharers, if there are more, kick out the original sharers;
Another approach is to replace the sharer list with the concept of lease, where the cache automatically expires when the lease is up, and the maximum possible synchronization delay for write operations is the same as the lease term. The lease method has a trade-off: if the lease is too short, read operations need to repeatedly fetch updated values, reducing read efficiency; if the lease is too long, the synchronization delay for write operations is too high.
In fact, I feel a more reliable method is to combine CC with business, because the business knows best when data should be synchronized, and generally has a clear understanding of who the sharers of the data are. For example, in distributed systems, you generally need to first acquire the read-write lock of an object, then access the data, and finally release the lock. The process of accessing data may involve reading and writing, but this intermediate process may not necessarily need to be synchronized to other nodes in real time. In fact, in many scenarios, you don’t want the intermediate results to be known to others (atomicity of distributed transactions). When acquiring the lock, synchronize the data from the source to the local, and when releasing the lock, synchronize the modified data from the local to the source. Since the business has implemented read-write locks, there must be a sharer list stored in memory, right? The problem of nowhere to put the sharer list is naturally solved. In this way, if I make a hardware-accelerated read-write lock + object synchronization semantics as an extension of RDMA semantics, wouldn’t it be more practical? A single RTT not only solves the read-write lock, but also synchronizes the object data, without wasting the CPU of the host where the data is located, isn’t it beautiful?
If you feel that most businesses do not use locks, the above read-write lock is not practical enough, you can also make a beggar version of cross-host CC, only support user on-demand synchronization, do not support real-time synchronization, this is enough in many scenarios, just need to solve the trigger synchronization timing in software, that is, rely on software to solve the cache invalidation problem, programming is more troublesome.
Sometimes simplifying programming is more important than pursuing that bit of performance. Simple programming often means a more universal architecture. For example, NVIDIA’s GPU and a bunch of DSAs represented by TPU are typical examples. These DSAs were all great in the ResNet era, with the same process technology, the computing power increased several times, but when they encountered Transformer, the effective computing power was basically not enough. Not to mention the ecological problems of DSA, operator development requires cost and time, and the development cost of DSA operators is generally higher than CUDA. If DSA was reliable in the Transformer era, A100/H100 would not be sold out as they are now.
I think cross-host CC is mainly used in scenarios like Web service, big data, storage, etc. At present, I haven’t thought of any applications in AI and HPC fields. AI and HPC are generally collective operations (collective communication), and embedding also has a logically centralized parameter server for storage, so there seems to be little demand for shared memory data across multiple machines. If I’m wrong, I welcome corrections.