How to Measure the Intelligence of Extraterrestrial Civilizations
This is an old article of mine from 5 years ago. It was a winter night in early 2018 when I set up a large pot by myself in the Thirteen Tombs and sent a small part of human knowledge to Sirius, 8.6 light-years away. The story behind this can be found here. Today, what we are concerned with is that sending messages to potential extraterrestrial civilizations obviously requires making them recognize that the message is sent by an intelligent life form, and also making them understand it.
A very basic question is, how do you prove your level of intelligence in the message? In other words, if I were an intelligent life form monitoring cosmic signals, how would I determine whether a bunch of signals contains intelligence? Since intelligence is not a matter of having or not having, but rather more or less, how do we measure the degree of intelligence contained in these signals? I think my thoughts from 5 years ago are still interesting, so I’m organizing and posting them.
The message is just a string. Imagine we could intercept all communications from aliens and concatenate them into a long message. How much intelligence does it contain? This is not an easy question to answer.
Current technology generally tries to decode the message and then see if it expresses basic information from sciences such as mathematics, physics, astronomy, logic, etc. The Arecibo message from 1974 was encoded in this way, hoping to attract the attention of extraterrestrial civilizations. I tried to find a purely computational method to measure the level of intelligence contained in the message.
Complexity ≠ Intelligence
Let’s start with entropy. Entropy is a measure of the disorder of a message. If each character in the message is uncorrelated with the others, entropy can be easily calculated by the frequency of each character’s occurrence. Unfortunately, the characters in the message are correlated, for example, the English letter q is almost always followed by u. Special encoding of repeated substrings for storage is the principle behind various compression algorithms today. Entropy corresponds to the limit compression ratio achievable by compression algorithms. There is no universally optimal compression algorithm, nor is there an algorithm that can accurately calculate the entropy of a string.
Simple repetitive strings, such as 10101010…, have low entropy, the highest compression ratio, but obviously do not contain intelligence. Randomly generated strings have high entropy, are not compressible, and also obviously do not contain intelligence. Does that mean strings with moderate entropy and compression ratio contain intelligence? The answer is also no. We can imagine a random string of length N repeating indefinitely, and by adjusting the value of N, we can construct strings with almost any value of entropy, but the simple repetition of a random string obviously does not contain intelligence.
There are many measures of the complexity of a message. There is a well-known measure called Kolmogorov complexity, which refers to the length of the shortest program that can output that string. For example, the Kolmogorov complexity of the first million digits of pi = 3.1415926… is not high, because the program to calculate the first million digits of pi does not require many lines of code. Due to the existence of the halting problem, Kolmogorov complexity is uncomputable. But that’s not the most important point. Kolmogorov complexity is also difficult to serve as a measure of intelligence. The Kolmogorov complexity of a random string is the highest, equal to its length; the Kolmogorov complexity of a string with simple repetition of a character is the lowest.
There is another measure called “logical depth,” which refers to the shortest computation time of a shorter program that can compute the string, where a shorter program is defined as a program whose length does not exceed the Kolmogorov complexity plus a constant value. Is a message that takes longer to compute more intelligent? The answer is no. A program that calculates every block in the Bitcoin blockchain (at the current difficulty level) has a high complexity (otherwise, there would not be so many people mining), but the Bitcoin blockchain itself can only prove that it is a sophisticated design by an intelligent civilization, and it is hard to say that it carries most of the intelligence of human civilization.
Estimating Complexity with Neural Networks
In recent years, artificial neural networks have become popular, especially the Transformer in 2017, which solved many problems in the NLP field with a general model. Today’s GPT is also based on the Transformer. The Transformer has also been extended to other fields such as CV, becoming the most promising general model for handling multimodal data. In fact, from the very early days of the birth of artificial neural networks, we knew that they could theoretically approximate any continuous function, it’s just that at that time we had not found the right model structure, training methods, nor did we have enough computing power and data.
The general approximation ability of artificial neural networks means that they can calculate the complexity of most messages quite accurately. Although it is still impossible to calculate entropy or Kolmogorov complexity accurately, artificial neural networks can give a good approximation in most scenarios. Unless the knowledge contained in the message itself is difficult to learn, such as the message itself being encrypted with AES, then artificial neural networks cannot learn its key with the current gradient descent method.
Before the emergence of artificial neural networks, searching for general programs based on input-output examples was generally considered very difficult, as we required 100% accuracy. For this reason, Kolmogorov complexity is often considered a theoretical tool, and it is difficult to come up with a general approximation algorithm that is much better than LZ77. Once we step out of the box of exact algorithms and look for approximate algorithms that allow a certain error rate, we open the door to a new world.
Artificial neural networks are an excellent compressor for complex messages. It can extract the structure from the message and use it to predict the next character based on a substring. The higher the accuracy of the prediction, the higher the compression ratio of the long message. The complexity of the entire message is equal to the size of the model plus the message length multiplied by the prediction error rate, and the compression ratio is the ratio of the message length to the complexity. The prediction error rate will not converge to 0, because there is always uncertainty in the message, stemming from unknown information in the surrounding environment, and not completely determined by the previous message.
A clear problem with using the compression ratio as a measure of intelligence is that the compression ratio is related to the total length of the message. As the total length of the message tends to infinity, the proportion of the message length multiplied by the prediction error rate will become larger and larger, and the proportion of the model size in the message complexity will become smaller and smaller. And the prediction error rate obviously cannot measure intelligence well, the model size is an upper bound on how much intelligence there is.
Different sizes of neural network models can all predict the next character to some extent, just with different accuracies. Before the model can accommodate all knowledge, the larger the model, generally the higher the prediction accuracy. After the model has accommodated almost all knowledge, it is difficult to improve the prediction accuracy. The smallest model size when the prediction accuracy converges is the language complexity of an intelligent civilization.
However, we still cannot distinguish between the simple repetition of random strings and the intelligent conversations filled with wisdom based solely on the model size, because the model sizes they require may be the same.
A simple idea is to attach a “memory” to the neural network, which is an external storage that can be randomly accessed and does not count towards the model size. In this way, random strings can be stored in this external storage, and the entire message can be expressed with a simple model. But if you think about it further, you will find that this idea is completely wrong. Because any model can be stored as a program in this external storage, and the model only needs a fixed-size general “execution program” function to express any program. Programs and data can be converted to each other.
Complexity = Randomness + Intelligence
My humble opinion is that complexity essentially comes from randomness and intelligence, that is, Complexity = randomness + intelligence. Randomness may be artificially added during the message transmission process, or it may come from the surrounding environment. An example of randomness from the environment is the names of historical figures and animals. The number of nouns does not imply the level of intelligence, although there is often a certain positive correlation in reality. Separating from the model what is randomness and what is intelligence is not an easy task.
Therefore, we return to the definition of intelligence. Intelligence, according to the Oxford Dictionary, is the ability to acquire and apply knowledge and skills. In computer terms, intelligence is the ability to recognize patterns (pattern recognition).
First, we train a sufficiently large model with enough messages from an extraterrestrial civilization, and this large model will contain almost all the knowledge of the extraterrestrial civilization. In fact, this large model is a digital clone of the extraterrestrial civilization. Considering that under the physical laws mastered by humans, the transmission of information is much more convenient than that of matter, advanced civilizations may themselves be digital.
At this point, if you take a new message intercepted from an extraterrestrial civilization and input the first half into the large model, the large model will predict the first character of the second half of the message with a high probability. Predicting the next character seems far from intelligence, but with the next character, you can predict the second character, and so on… In fact, any problem can be organized in the form of a fill-in-the-blank question, such as “The capital of China is __”, so a good predictor can express almost all the problems in an intelligent civilization, and thus reflect the ability of an intelligent civilization to solve problems.
Secondly, we use this model from an alien civilization to test its generalization ability in the local civilization corpus. Intelligence is the ability to discover patterns, and the model from an alien civilization can also learn knowledge from the local civilization corpus.
However, it is not reliable to simply input the information of the local civilization into the large model from the alien civilization and let it predict the next character, because the information of the local civilization contained in a message is too little, and for the alien civilization, this message is no different from a book from heaven. This is like before the Rosetta Stone was discovered, archaeologists could never unlock the mystery of ancient Egyptian hieroglyphs. The question is, the Rosetta Stone is a comparative text composed of three languages, and we do not have a comparative text between alien and local civilizations, can we still do transfer learning?
A large enough corpus makes the Rosetta Stone unnecessary
Archaeologists need the Rosetta Stone because there are too few ancient Egyptian hieroglyphs, that is, the corpus is too small. Neural networks also can’t train much when the corpus is too small. I believed 5 years ago that when the amount of corpus is large enough, knowledge can always be learned unsupervised from it, without the need for pre-labeled data. The models at that time did not have this capability because they were not big enough to accommodate all the necessary knowledge in the world. Today’s ChatGPT encompasses a large part of human knowledge, especially the knowledge of basic language models, world models, and human common sense, and the training method of the basic model is completely unsupervised (not considering RLHF alignment with human output), which confirms my conjecture.
In addition, mathematics, physics, astronomy, logic, and other sciences are common to different civilizations, and this information will become the invisible Rosetta Stone.
The higher the intelligence level of a civilization, the easier it is to learn knowledge from less information and make more accurate predictions. Based on this consideration, we fed some corpora from the local civilization to this large model from outer space, comparing its ability to predict the next character of local civilization messages with models trained only with these local civilization corpora. To distinguish between local and alien civilization corpora, we will mark them differently. If the civilization from outer space (represented by the large model) is smart enough, it can learn a lot of information about the local civilization from a small amount of local civilization corpus, that is, this digital alien civilization can adapt to the local civilization environment faster. And the model trained only with the same amount of local civilization corpus is likely to have poorer predictive ability.
Comparison of intelligence levels between alien and local civilizations
Based on the above assumptions, we can imagine the differences in adapting to local civilizations by alien civilizations of different intelligence levels.
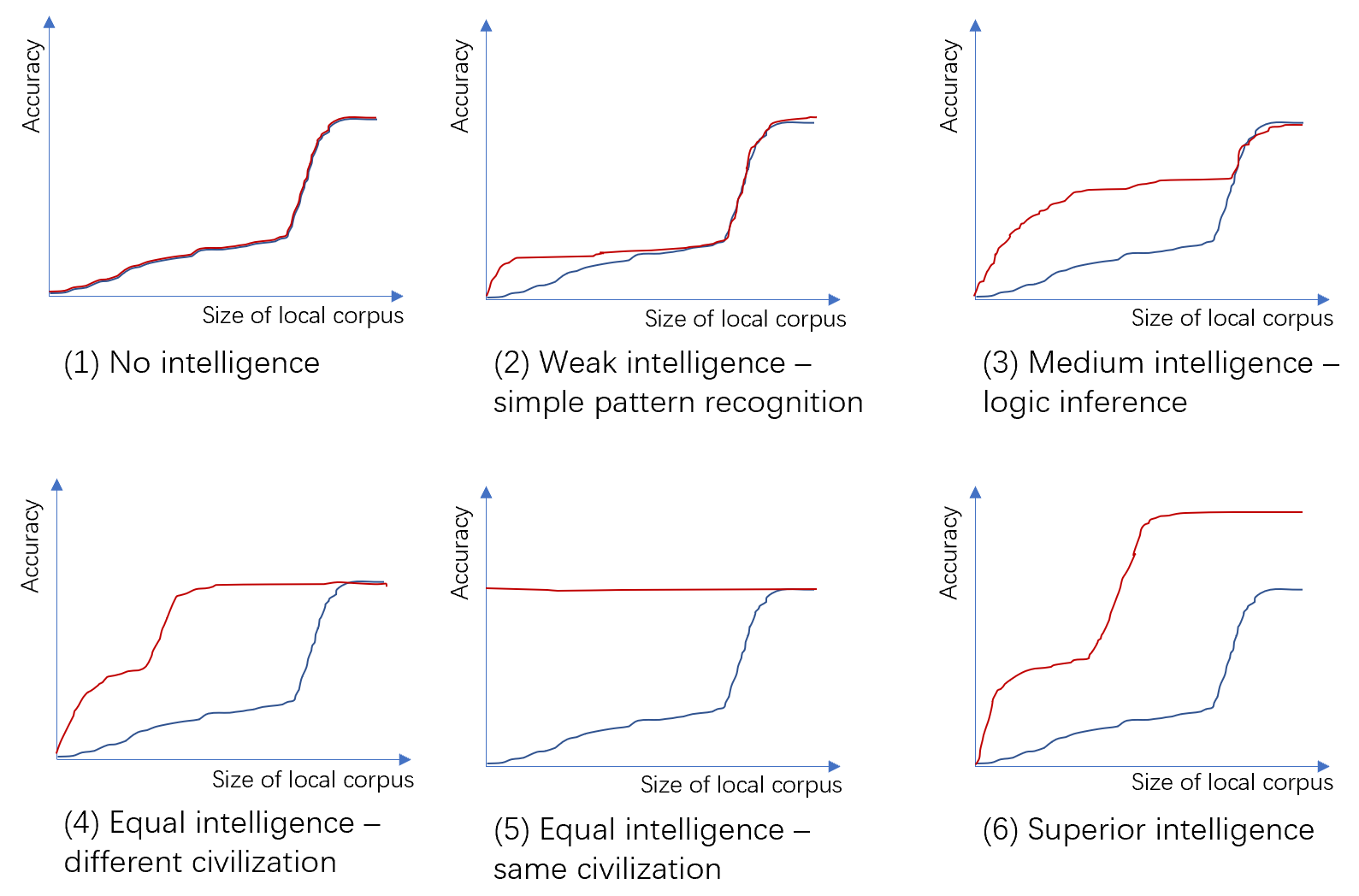 Above: Comparison of alien civilizations of different intelligence levels with local civilizations (conjecture diagram, not experimental diagram). X-axis: Size of the local civilization training corpus, logarithmic coordinates; Y-axis: Prediction accuracy on the local civilization test corpus. Red line: The model already trained with the alien civilization corpus plus the local civilization training corpus of the size specified on the X-axis. Blue line: Only using the local civilization training corpus of the size specified on the X-axis.
Above: Comparison of alien civilizations of different intelligence levels with local civilizations (conjecture diagram, not experimental diagram). X-axis: Size of the local civilization training corpus, logarithmic coordinates; Y-axis: Prediction accuracy on the local civilization test corpus. Red line: The model already trained with the alien civilization corpus plus the local civilization training corpus of the size specified on the X-axis. Blue line: Only using the local civilization training corpus of the size specified on the X-axis.
First, observe the blue curve trained only with the local civilization corpus. Its prediction accuracy shows a certain linear growth capability when the amount of corpus is small (the logarithm of the corpus amount is close to linear with accuracy), and it shows a surge after exceeding a certain threshold, and finally converges to a plateau.
This is because the tasks in an intelligent civilization can be divided into two categories, simple tasks and complex tasks. Simple tasks can be completed by identifying features, so the more refined the identified features, the higher the accuracy. Complex tasks are composed of multiple simple tasks, and the entire complex task is only considered complete if all tasks are completed correctly. For example, when we solve a math problem, there are multiple steps, and if any step is wrong, the final result is wrong; when we speak a sentence, we also need many words, and according to the method of predicting the next word in turn, we need to get every word right to be considered correct. Therefore, before the accuracy of simple tasks reaches a certain threshold, the accuracy of complex tasks is the product of the accuracy of multiple simple tasks, approaching 0. Only when each simple task can be completed accurately enough, can the complex task be completed with a perceptible accuracy.
This characteristic of the large model is called emergence today, but it generally refers to a sudden increase in accuracy after the model size exceeds a certain threshold, while I am referring to the training data volume here. I don’t know if my explanation from 5 years ago is correct :)
Next, we will measure its intelligence based on the performance of the alien civilization on the limited local civilization corpus.
- No intelligence: The red and blue lines completely coincide, which means that the alien civilization has no ability to learn the knowledge in the local civilization corpus, and all predictive ability comes entirely from the additional local civilization corpus. This can distinguish the randomness and intelligence in complexity, a very long random string or a randomly generated long program has no transfer learning ability, while even a small model like an ant has a certain transfer learning ability. According to this measurement method, models that only show some patterns without learning ability are not considered intelligent.
- Weak intelligence: The height of the inflection point of the red line is lower than the inflection point of the blue line, and it coincides with the blue line during the surge period. The inflection point of the blue line represents the boundary between simple tasks and complex tasks. Simple tasks have linear growth capability, while complex tasks show surge characteristics. Since the alien civilization has a certain simple pattern recognition ability, it only needs a small amount of local civilization corpus to figure out some simple rules (such as q is generally followed by u), thus learning faster than using only local civilization corpus. Of course, it is also possible that the blue line will be lower than the red line, which means that the difference between the alien civilization and the local civilization is too great, and the model of the alien civilization cannot be transferred at all, and it even reduces the speed of learning the local civilization. But since the corpora of alien and local civilizations have different markings, this situation is unlikely to occur. Since the corpus of the alien civilization does not have the ability to reason logically and complete complex tasks, it cannot help during the surge period.
- Medium intelligence, but weaker than local civilization: The inflection point of the red line is higher than the inflection point of the blue line, and the surge period of the red line partially overlaps with the blue line. This means that the alien civilization has a certain ability to reason logically and complete complex tasks, but the intelligence level is lower than that of the local civilization. The alien civilization can learn the corresponding relationship between the concepts of the alien civilization and the local civilization from a small amount of local civilization corpus, thereby quickly reaching the highest intelligence level of the alien civilization, but it does not have the ability to handle some complex tasks in the local civilization. An example is humans 1000 years ago and modern humans. Ancient people also had very good logical reasoning ability and the ability to complete complex tasks, but their understanding of the natural world and computing ability were definitely not as good as modern humans.
- Equal intelligence: The model pre-trained with the alien civilization corpus, that is, the red line, only needs a small amount of local civilization corpus to learn the corresponding relationship between the concepts of the alien civilization and the local civilization, thereby reaching the same intelligence level. An example is modern people who use English and modern people who use Chinese. This is an extreme case of medium intelligence.
- A special case of equal intelligence, alien civilization = local civilization: In the special case of alien civilization = local civilization, the “alien civilization” is at its peak from the beginning, and the new local civilization corpus does not help at all. This reflects the huge impact of the similarity of intelligence on this measurement method. The more similar the alien civilization is to the local civilization, the less local civilization corpus is needed to learn the corresponding relationship between the two civilizations. That is to say, under the measurement method in this article, the more similar the alien civilization is to the local civilization, the local civilization may consider the alien civilization to be more intelligent. I have not yet thought of a method to measure the “absolute intelligence level” of a civilization.
- Strong intelligence, stronger than local civilization: If the alien civilization is stronger than the local civilization, it only needs a small amount of local civilization corpus to learn the corresponding relationship between the two civilizations and solve the difficult problems that the local civilization cannot solve, that is, its prediction accuracy can be higher than that of the local civilization. Of course, the relative intelligence level of such a civilization may not be easy to measure, because the local civilization may not have the ability to propose questions that are sufficient to distinguish different strong intelligent civilizations, and the algorithms and computing power used by the local civilization to train the large model may also be insufficient to train a model that can show the level of the alien civilization. This is also easy to understand, it is difficult for a person to measure the absolute level of someone much stronger than themselves.
Although the intelligence level is difficult to quantify, we might as well give a scalar measure of intelligence level, which is the maximum vertical drop between the red and blue lines, that is, the maximum difference in accuracy on the local civilization dialogue task between the alien civilization + local civilization model and the pure local civilization model when using the same amount of local civilization corpus.
It can be seen that, under the premise of the same learning ability of the alien civilization, the higher its similarity to the local civilization, the higher the intelligence level defined in this way. I have also thought about how to quantify the part of complexity (model size) that belongs to intelligence, or how to exclude the random part, but I have not found a method.
In today’s terms, the alien civilization is like a pre-trained model, and the local civilization is like a fine-tuned (fine-tune) model. GPT stands for Generative Pre-Training, unfortunately, it was not released 5 years ago. Of course, such an analogy is very imprecise, because the difference between different civilizations is much greater than the difference between fine-tune corpus and pre-trained corpus, and generally, the fine-tune corpus is not more than the pre-trained corpus.
We may not be alone
On that winter night 5 years ago, what I sent was a bound volume of Wikipedia in various languages. In “The Three-Body Problem”, the Red Coast Base needs to send a “self-interpreting system” before sending information. In fact, as can be seen from the previous text, high-quality corpus itself is a self-interpreting system, and there is no need to worry that I speak Chinese and aliens speak English; there is no need to worry that I use decimal and aliens use binary. An alien civilization with strong computing power only needs to roughly filter out random noise and simple repetitive signals through the compression rate of a simple compression algorithm, leaving messages that seem to contain intelligence, and then throw them into the large model for training, and it can rebuild a large part of the civilization’s wisdom from the messages.
For a hundred years, humans have sent countless radio waves into the universe. Especially in the era when long-wave radio stations were widespread, these wireless signals are easy to distinguish from cosmic background noise for alien civilizations that are relatively close to us. If an alien civilization is smart enough to use a large model to process these wireless signals, it may have already seen through all the secrets of human society, without waiting for the Arecibo message or a more complex “self-interpreting system” to provide a codebook. Perhaps the alien civilization has long trained a digital clone of human civilization with these wireless signals, waiting for us to meet old friends in the universe one day. Perhaps in the near future, when we use large models to process radio and light waves from deep in the universe, we will be surprised to find that intelligence is everywhere in the universe, it’s just that human decoding technology was too primitive before.
Interestingly, the names of many AI startups today are related to interstellar exploration. Perhaps the founders want to express that AI is an innovative business full of imagination and can change the world, similar to interstellar exploration. My thinking from 5 years ago to now directly links AI with interstellar exploration: AI models will become the digital incarnation of human civilization, crossing the spatial and temporal limitations of the human body, bringing humans truly beyond the solar system and even the Milky Way, becoming an interstellar civilization.
Postscript
Although I am not in AI, a little thought from 5 years ago is still very close to some of the performances of large models today. Of course, this may just be a coincidence, and my views are very likely wrong, after all, I have not done any experiments. If I have time in the future, maybe I can take civilizations from different eras and regions on Earth, or even civilizations of different creatures, to do an experiment.
However, if a person who studies AI cannot understand the article written by me, an outsider (note: does not include understanding but disagreeing with the views in the article), it means that they have not thought about the basic problems in the field of AI at all. I read the articles of OpenAI’s chief scientist Ilya Sutskever over the past 10 years and found that his thinking is really very deep, not just caring about a specific problem in CV or NLP, but thinking about the basic problems in the field of AI from a global perspective. Although I only have a preliminary study in the field of networks and systems, I know deeply that to propose good questions and do good research, one must have a deep enough understanding of the basic problems in the field, rather than just looking at which topics have been researched a lot in the top conferences in recent years and following the trend to write a paper.