Five Years of PhD at MSRA (Part 2) - Leading My First SOSP Paper
Long read warning: Part two of the “Five Years of PhD at MSRA” series, about 13,000 words, to be continued…
KV-Direct, published at SOSP 2017, was my second paper (as first author). Since the first SIGCOMM paper ClickNP was done with Bo Tan guiding me step by step, KV-Direct was also the first paper I led on my own.
What to Do After SIGCOMM
After submitting the SIGCOMM paper, Bo Tan said that for the next project, I needed to come up with the direction on my own.
Compiler or Application?
We were well aware that ClickNP still had many issues, with the current support for compilation optimization being too simple. We hoped to enhance the compiler’s reliability from the perspective of programming languages. At the same time, we used ClickNP as a common platform for network research within our group to incubate more research ideas.
Naturally, I explored along two directions, one was to extend ClickNP to make it easier to program and more efficient; the other was to use the ClickNP platform to develop new types of network functions to accelerate various middlewares in the network. At that time, we were exploring many middlewares in parallel, such as encryption/decryption, machine learning, message queues, layer 7 (HTTP) load balancers, key-value stores, all of which could be accelerated with FPGAs.
To improve the programmability of ClickNP, I started looking for good talents from the school to join the MSRA internship. Yi Li was interested in programming languages and formal methods during his undergraduate studies. He was the first student I recommended to intern at MSRA. At the start of the spring semester, Yi Li came to MSRA for his internship, coinciding with the completion of his undergraduate thesis. He proposed several key optimizations for the ClickNP system, added some syntax to simplify programming, and corrected some awkward syntax.
However, due to the workload, we did not do a major overhaul of the compilation framework, still using simple syntax-directed translation without using professional compiler frameworks like clang, nor intermediate languages. Therefore, each time a new compilation optimization was added, it seemed rather ad-hoc.
Encountering various strange issues with OpenCL, I had the idea of creating a high-level synthesis (HLS) tool myself, generating Verilog directly from OpenCL. My idea was simple: for application scenarios in the networking domain, what we do is to unroll all loops in a piece of C code into a large block of combinational logic. By inserting registers at appropriate positions, it could become a pipeline with extremely high throughput, capable of processing an input every clock cycle. If the code accesses global states, then such loop dependencies determine the maximum number of registers on the dependency path, which is the upper limit of the clock frequency.
However, Bo Tan disagreed with my idea of creating an HLS tool ourselves, because we were not professional FPGA researchers. Such work lacked innovation, more about filling the “gaps” of existing HLS tools, a engineering problem, difficult to publish top-tier papers in either FPGA or networking fields.
Due to frequent issues with FPGA card programming, I ended up plugging and unplugging FPGA cards in the server room every day, sometimes debugging on-site. Thus, like my undergraduate days in the minor academy’s server room, I often spent hours in the server room, enduring the cold air and noise over 80 decibels.
 Above: Me with MSRA's network group servers, taken by MSRA for promotional materials, I often use this photo
Above: Me with MSRA's network group servers, taken by MSRA for promotional materials, I often use this photo
The Story of the HTTPS Accelerator
FPGAs, besides being suitable for processing network packets, are also very suitable for computation. What scenarios in the networking field require a lot of computation? Naturally, encryption and compression. The product department had already worked on compression, so we naturally chose encryption.
Tianyi Cui was a tech guru I met at USTC LUG, like me, also a former tech department head of the minor academy’s student union, serving as LUG’s CFO in his sophomore year and LUG president in his junior year. In the second semester of his sophomore year, he was very interested in MSRA, so I recommended him for a summer internship. During this two-month internship, Tianyi Cui and I worked together on an FPGA-based HTTPS accelerator.
 Above: Bo Tan and MSRA students, from left: Yuanwei Lu, Tianyi Cui, Kun Tan, Bojie Li, Jeongseok Son
Above: Bo Tan and MSRA students, from left: Yuanwei Lu, Tianyi Cui, Kun Tan, Bojie Li, Jeongseok Son
Theoretically, if the FPGA area were infinite, encryption algorithms like AES, RSA would be easy to implement. These algorithms have a fixed number of iterations, and if fully unrolled, theoretically, they could process a packet fragment (flit) every clock cycle.
But such a pipeline would require an unacceptably large chip area, as the number of iterations is too many. An AES block encryption pipeline has over a dozen S-box inversions, this digital logic would occupy about 20%~30% of the total FPGA area. Since 40% of the space on our FPGA had to be reserved for Hard IP and the basic framework for network, PCIe packet processing, the space available for business logic was less than 60%, using nearly half of this space for AES seemed too much.
The complexity of RSA is on a completely different scale. RSA-2048 requires 2048 modular multiplications and additions, each modular multiplication is a 2048-bit by 2048-bit operation, even on a CPU, one RSA-2048 operation requires 8 million multiplications. If all loops were unrolled into a pipeline, the scale of the digital logic would be thousands of times the area of the FPGA.
Besides chip area, logical dependencies are another factor to consider. For example, in the AES encryption algorithm, if some encryption modes (such as CBC mode) are used, there are dependencies between the different fragments of the message, the calculation input of the second fragment depends on the calculation output of the first fragment, making the entire pipeline “unflowable,” and the throughput of a single network connection still cannot be increased. Therefore, multiple network connections need to be processed in parallel to utilize the FPGA pipeline’s processing capacity fully, requiring us to record the intermediate processing state of each connection.
The challenge of implementing an HTTPS accelerator based on FPGA mainly lies in how to split these huge digital logics into reusable small blocks and save the intermediate states during the computation process.
At that time, Tianyi Cui and I were researching Montgomery Modular Multiplication all day, breaking down the 2048 by 2048 bit computation into 256 by 256 bit blocks. Implementing 2048-bit subtraction was also quite challenging, writing a 2048-bit subtraction directly in OpenCL would “explode” in performance, requiring splitting. Since OpenCL is not convenient for controlling the generated Verilog code, for the core computation modules, we utilized ClickNP’s Verilog module (element) feature, writing directly in Verilog.
In the end, the prototype of the HTTPS accelerator could achieve 12,000 RSA-2048 encryption or decryption operations per second, equivalent to the performance of 20 CPU cores working in parallel at full speed. For symmetric encryption like AES, it could also reach a throughput of over 100 Gbps (but due to the bandwidth limitation of the Ethernet Hard IP, it could only reach 40 Gbps).
Tianyi Cui and I made a demo video with VideoScribe, presenting the HTTPS accelerator project at Microsoft Hackathon 2016, standing out from thousands of Hackathon projects worldwide and winning the second place globally in the Cloud and Enterprise Category, marking a perfect end to Tianyi’s two-month summer internship.
Although the HTTPS accelerator solved many engineering problems, we felt it lacked academic innovation to publish a top-tier paper. A year later, Tianyi Cui returned to our group at MSRA for an internship, completing my third research work with me, which is a story for another time.
Exploring Machine Learning Accelerators
AI has always been one of Microsoft Research’s strategic directions.
After Microsoft deployed Catapult FPGAs to every server in the data center to accelerate network virtualization, the Catapult team began exploring whether these FPGAs could also be used to accelerate AI. The academic community has been flooded with papers on using FPGAs for AI training and inference, so our research focus was on how to use high-speed networks to accelerate FPGA AI.
At that time, Microsoft Bing’s search ranking algorithm was a DNN model. FPGAs doing DNN inference have a significant limitation, which is the bandwidth of memory. Our FPGAs did not have high-speed memory like HBM at that time, only DDR4 memory, with a combined bandwidth of only 32 GB/s for two channels.
Most existing works place the model in DRAM, then divide the model into blocks, each block is loaded from the FPGA’s external DRAM to the FPGA’s on-chip SRAM (also known as Block RAM, BRAM), and then computation is done on-chip. Therefore, the cost of data movement becomes the main bottleneck for FPGAs. The compiler’s job is to optimize the shape of the blocks and data movement, which was also my first project at Huawei MindSpore after my PhD graduation.
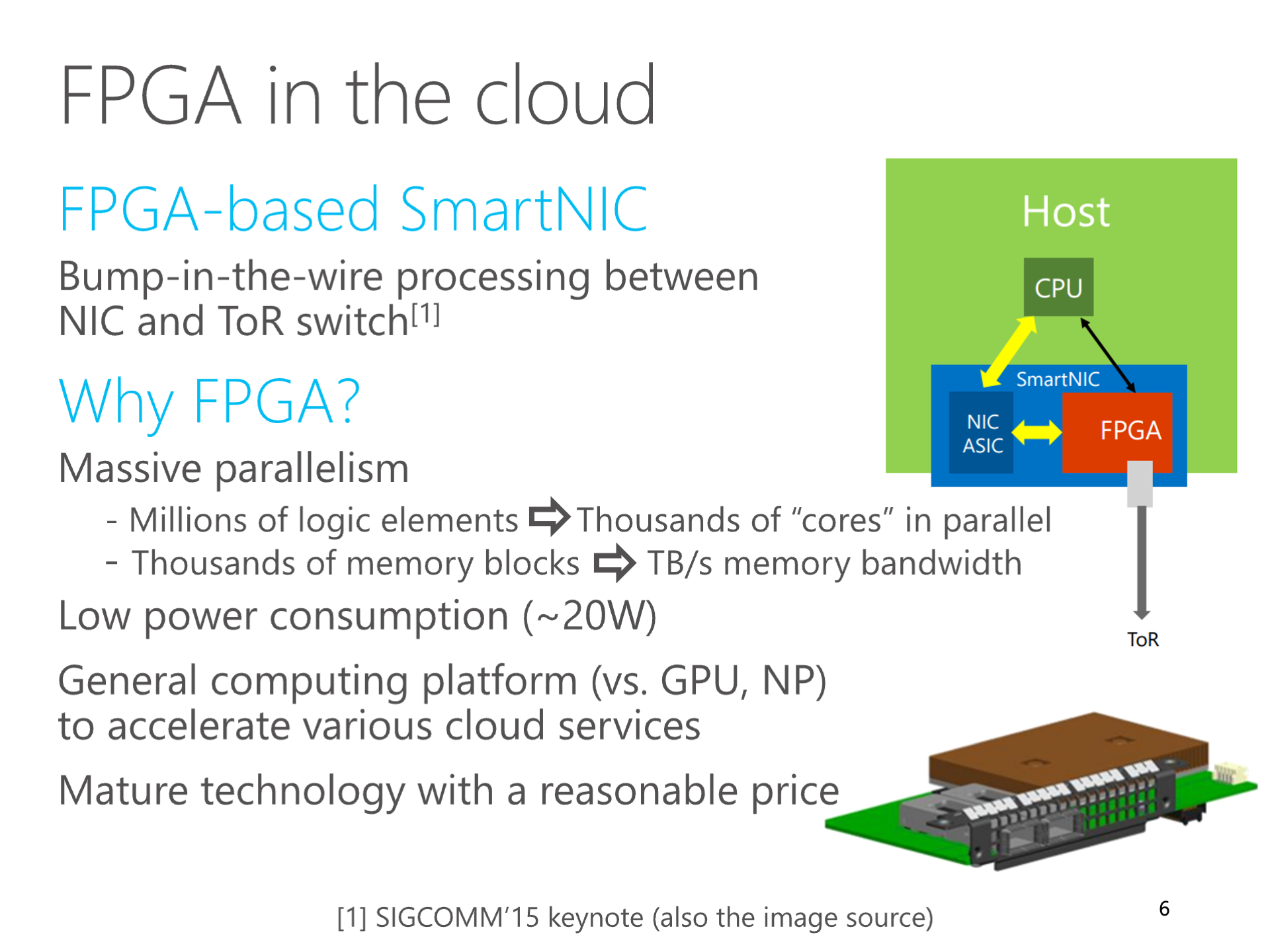 Above: My SIGCOMM 2016 ClickNP paper's summary of FPGA computation characteristics
Above: My SIGCOMM 2016 ClickNP paper's summary of FPGA computation characteristics
In 2016, I thought, could we use a cluster of multiple FPGAs, divide the deep neural network model into several blocks, so that each block could fit into the FPGA’s internal SRAM cache? In this way, what needs to be transmitted through the network are the intermediate results between the blocks. Since there is a high-speed interconnect network between FPGA chips, after calculations, the bandwidth required to transmit these intermediate results would not become a bottleneck for the models we used.
I excitedly reported this finding to our hardware research group’s supervisor, Ningyi Xu, who said that the method I thought of is called “model parallelism”. In some scenarios, this “model parallelism” approach indeed achieves higher performance compared to the traditional “data parallelism” method. Although this is not considered a theoretical innovation, Ningyi Xu said that the idea of fitting the entire model into the FPGA’s internal SRAM cache is somewhat interesting. It’s like using a lot of FPGA blocks connected by high-speed networks as if they were a single FPGA.
To distinguish from the traditional model parallelism method where data is still stored in DRAM, we call this model parallelism method, where all data is placed on-chip SRAM, “spatial computing”.
The term spatial computing sounds grand, but it’s actually the most primitive. We build a digital circuit composed of logic gates to complete specific tasks, and this is spatial computing. After the birth of microprocessors based on Turing machine theory, temporal computing became mainstream, with microprocessors executing different instructions at different moments. This way, only one set of hardware circuits is needed to complete a variety of tasks. However, from an architectural perspective, microprocessors trade efficiency for versatility.
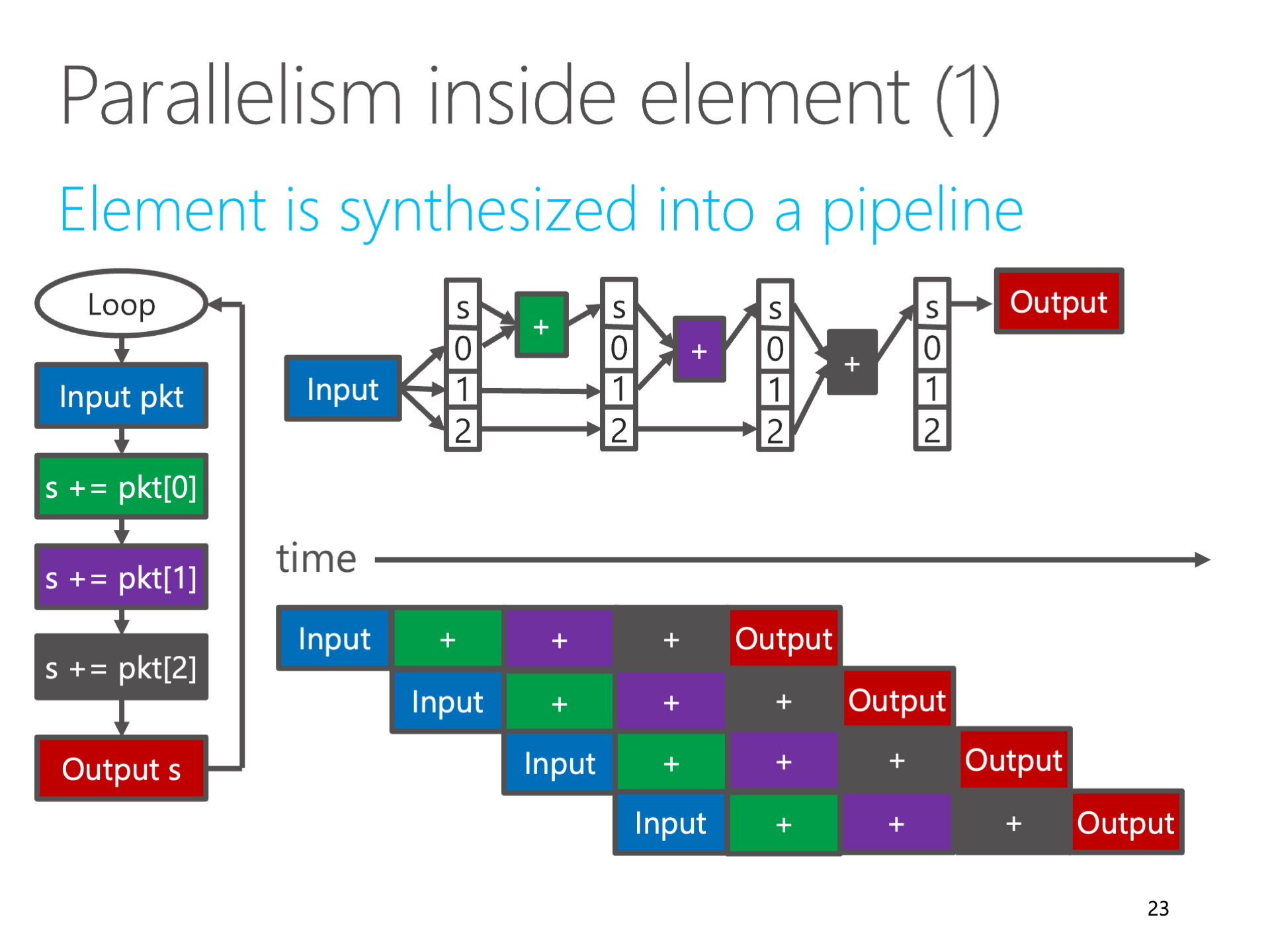 The figure above: Fully pipelining the computation logic is spatial computing
The figure above: Fully pipelining the computation logic is spatial computing
In the world of FPGA and ASIC, for efficiency, spatial computing is still mainstream. In FPGA high-level synthesis (HLS), code that has a fixed number of loops and does not contain arbitrary jumps (known in the compilation domain as SCoP, Static Control Part), can be fully unrolled and functions inlined, thereby transforming into a block of combinational logic. After inserting registers at appropriate places, it becomes a fully pipelined digital logic. Such digital logic can accept a block of input data every clock cycle.
Everyone in distributed systems knows that it’s difficult for clusters composed of multiple machines to achieve linear speedup, meaning that as more machines are added, the cost of communication and coordination increases, reducing the average output of each machine. But this “spatial computing” method can achieve “super-linear” speedup when there are enough FPGAs to fit the entire model in on-chip SRAM, meaning the average output of each FPGA in model parallelism is higher compared to using a single FPGA with data parallelism method.
Once the memory bandwidth issue for accessing the model is solved, the computing power of FPGAs can be fully unleashed. We conducted a thought experiment: every server in Microsoft Azure data center is equipped with an FPGA, if the computing power of 100,000 FPGAs in the entire data center is scheduled like a single computer, it would take less than 0.1 seconds to translate the entire Wikipedia. It was also demonstrated as a business scenario at an official Microsoft conference.
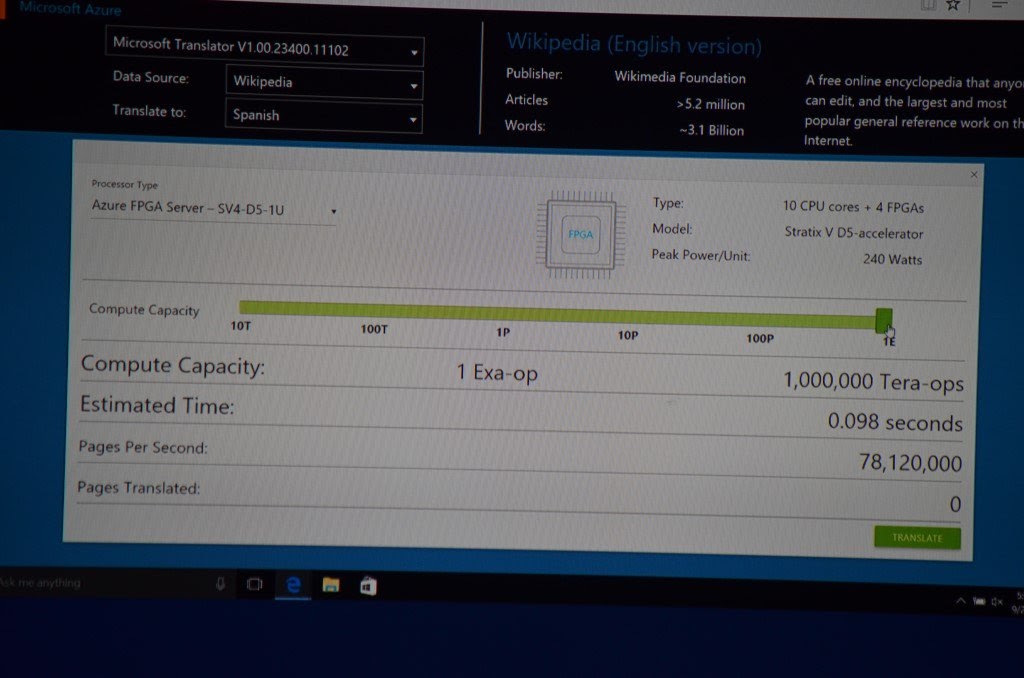 The figure above: A demo at a Microsoft conference using FPGA to accelerate machine translation, if the computing power of 1 Exa Ops in the entire data center is utilized, it would take less than 0.1 seconds to translate the entire Wikipedia
The figure above: A demo at a Microsoft conference using FPGA to accelerate machine translation, if the computing power of 1 Exa Ops in the entire data center is utilized, it would take less than 0.1 seconds to translate the entire Wikipedia
KV-Direct: My Second Paper
My second paper, KV-Direct, was co-authored with Ruan Zhenyuan as the co-first author, who is also a genius I recommended from USTC to intern at MSRA, almost joining at the same time as Cui Tianyi. Because Ruan joined during the summer of his junior year, his internship at MSRA lasted for a year until graduation.
Accelerating Key-Value Storage with FPGA
Key-Value Storage is a very typical middleware in the system domain, simply put, it’s like the unordered_map in C++ or dict in Python, but it’s not in local memory, instead, it’s on other hosts in a distributed system, requiring access through the network. Memcached and Redis are typical key-value stores, but their performance is tens to hundreds of times slower compared to local unordered_map. The root cause lies in the thick software network protocol stack, where the overhead of network communication far exceeds accessing a value in memory. We thought, if using FPGA to make a key-value store, with a minimal communication protocol stack on FPGA using ClickNP, its performance would definitely be good.
Later, I learned about a classic article in the system domain, “Scalability! but at what COST?”, co-authored by three big names who were originally at Microsoft Silicon Valley Research Institute and then collectively laid off. It talks about how some distributed systems in the system research domain claim to have good scalability, but the performance of hundreds of CPU cores is not as good as a single-threaded program written by oneself on a single CPU core.
Professor Chen Wenguang from Tsinghua also noticed this phenomenon. He said, in his early years working in the HPC domain, it was not easy to achieve a 1% performance improvement. Later, he found that the performance of these graph computing systems was so poor that a single optimization could result in dozens to hundreds of times performance improvement.
The same is true in the key-value storage domain. The main performance bottlenecks of commonly used systems in the industry, such as Redis and Memcached, are not in accessing key-values, but in the thick kernel network protocol stack. The academic big names have a keen sense of smell, and they have optimized along two paths. One path is to replace TCP/IP with RDMA, and the other path is to use high-performance packet processing frameworks like DPDK. On the RDMA path, the academic community has also explored using pure bilateral semantics, a combination of unilateral and bilateral semantics, and other schemes.
Using FPGA to implement key-value storage definitely has high performance, but what are the academic challenges and contributions? With the experience from three projects such as the ClickNP compiler improvement, HTTPS accelerator, and machine learning inference acceleration, I realized that to publish top-tier papers, it’s not enough to have important problems and good performance; the challenges must be sufficient, and the solutions innovative enough, not too straight-forward.
A senior planner at Huawei said that the initiation of company projects is a syllogism: the problem is severe, the technology is powerful, and the effect is significant. This logic also applies to academic research.
Initially, I thought about making richer semantics as a selling point since the existing high-performance key-value storage in academia generally only supports Memcached’s get/put and does not support Redis’s list, map, and other advanced semantics. Tan Bo said that this was too engineering-focused and might be a thankless task.
Tan Bo said, I need to gradually cultivate my own research taste. Every researcher has their unique research taste, which is how to recognize and evaluate existing research work and future research directions. For example, some people prefer theoretical research, while others prefer system research. As research progresses, it’s also necessary to gradually understand the research taste of other major researchers, so that one can submit to more suitable conferences and modify the paper according to the research taste of potential reviewers.
Farewell to Tan Bo
On September 22, 2016, Thursday, Tan Bo suddenly told us interns that the next day would be his last day at Microsoft. I wasn’t very surprised because there had been rumors that Tan Bo might be going to Huawei, but I didn’t know the specific time, just felt it was too soon, too sudden.
In the afternoon, Tan Bo chatted with me in the pantry, asking me what direction I planned to work on in the future, programming languages or systems. After thinking for a while, I chose systems. Tan Bo agreed with my choice, saying that MSRA didn’t have much accumulation in programming languages but had more in systems, and working on networked systems would be a good direction. This chat in the pantry for two or three minutes determined my doctoral path. Then, Tan Bo introduced me to Professor Zhang Lintao, the chief researcher of the systems group. When Tan Bo was visiting Princeton, Professor Zhang was doing his PhD there, and they became good friends.
On Friday, we interns helped Tan Bo pack his luggage, including dozens of patent stones, which were stacked against a wall like the periodic table, taking several trips to move. The patent stone is a commemoration given by Microsoft to patent applicants, a cubic rock weighing about one kilogram, engraved with the patent’s name, applicant, and application time. (For pictures, you can search “Microsoft patent cube”)
Tan Bo’s advice to us, which I no longer remember in detail, included two points:
- Research is about discerning truth from falsehood, in pursuit of truth. This is also what Tan Bo often told us. Published papers are not necessarily the truth; we need analytical thinking.
- Research is not about quantity, but having representative works. When talking about a researcher, what comes to mind first are his few representative works.
 The figure above: After Tan Bo left, as his subordinate, I was "promoted" temporarily in the organizational tree, hanging under Dean Hong, this was the moment I was closest to the CEO in the organizational tree
The figure above: After Tan Bo left, as his subordinate, I was "promoted" temporarily in the organizational tree, hanging under Dean Hong, this was the moment I was closest to the CEO in the organizational tree
MSRA’s “Rice Ball”
At MSRA, we interns often gathered together for meals. Microsoft Beijing had 4 restaurants at that time, the third floor of building one had several dining lines in the cafeteria, the second floor had the “Cloud + Client” Chinese restaurant and a (forgotten name) Western restaurant, and the third floor of building two had a buffet restaurant. Because the Western and buffet restaurants were more expensive, we usually ate in the cafeteria at noon and gathered in the “Cloud + Client” Chinese restaurant for dinner, which was also not expensive per person.
 The figure above: MSRA rice ball trip to Mangshan, back row from left: Lu Yuanwei (Ball King), Taekyung Heo, Yang Ze, Xiao Wencong (Teacher Cong), Wang Yun, Xiaoyi Chen, front row from left: Li Bojie, Cao Shijie, Zhang Ru, Han Zhenhua
The figure above: MSRA rice ball trip to Mangshan, back row from left: Lu Yuanwei (Ball King), Taekyung Heo, Yang Ze, Xiao Wencong (Teacher Cong), Wang Yun, Xiaoyi Chen, front row from left: Li Bojie, Cao Shijie, Zhang Ru, Han Zhenhua
Our dining group often goes out together, such as for birthday meals, hiking, karaoke, skiing, etc. Initially, the dining group mainly consisted of co-trained PhD students, but later some relatively short-term interns also joined. When one table could no longer fit us all, we gradually split into dining groups for each floor, such as ours on the 12th floor. Dining groups from other floors even formed a few couples.
 Above: MSRA dining group taking a photo in front of the MSRA logo
Above: MSRA dining group taking a photo in front of the MSRA logo Above: MSRA dining group taking a photo in front of the Microsoft logo under Building 2
Above: MSRA dining group taking a photo in front of the Microsoft logo under Building 2 Above: MSRA dining group taking a photo in MSRA's sky garden
Above: MSRA dining group taking a photo in MSRA's sky garden Above: MSRA dining group taking a photo in front of the MSRA logo
Above: MSRA dining group taking a photo in front of the MSRA logo
The Story of KV-Direct
During the summer vacation, Zhenyuan Ruan and I implemented the basic functionality of key-value storage based on ClickNP. We realized that the DDR capacity on the FPGA is limited. If all data is stored in the DDR on the FPGA board, then the capacity of the key-value storage would only be 4 GB or 8 GB (depending on our two different versions of FPGA boards). Meanwhile, the DDR space on the host is up to 256 GB. Therefore, we hoped to store the data in the host memory, with the FPGA receiving key-value operations from the network, accessing the host memory through PCIe, and then replying through the network.
This introduced several challenges. First is the limited PCIe bandwidth. The PCIe bandwidth of a network card is generally designed to be slightly greater than the network bandwidth. For example, our FPGA has 2 Gen3 x8 PCIe, but due to engineering reasons of the board, only one Gen3 x8 can be used, meaning the theoretical bandwidth is only 64 Gbps; the network bandwidth is 40 Gbps. This means if a key-value operation uses more than twice its own size in PCIe bandwidth, then the network bandwidth cannot be fully utilized, and PCIe will become the bottleneck. More importantly, the performance of PCIe small packets is very poor. Before optimization, a Gen3 x8 could only achieve about 30 M op/s, which is far from the performance of the best systems in academia, whether they are based on RDMA or DPDK.
For this reason, we decided to first optimize the performance of PCIe small packets. If Mellanox network cards can do it, why can’t our FPGA? This is because our FPGA platform mainly uses PCIe as a control plane and does not intend to use PCIe to transfer a large amount of data, so there was no optimization for PCIe small packet performance. It seems we had to take matters into our own hands, delve into the PCIe spec, and optimize the Verilog code responsible for PCIe processing on the FPGA platform (the PCIe transaction layer is implemented in Verilog, while the link layer and physical layer are implemented in Hard IP).
The most critical optimization was pipelining the TLP processing. Originally, processing a PCIe packet (TLP) required at least 5 clock cycles to go through the various stages of processing. The next TLP could not start processing until the previous one was finished. We pipelined the entire process, so the critical path for processing a PCIe TLP only needed 2 clock cycles. Thus, at a clock frequency of 200 MHz, theoretically, it could reach a throughput of 100 M op/s. Another optimization was increasing the support for concurrent DMA requests, which was relatively simple, just increasing the depth of the waiting FIFO and configuring the parameters of the Hard IP. To allow the code in ClickNP to directly access the host memory, we added a PCIe channel to ClickNP, which could directly convert read and write commands into PCIe TLPs to access the host memory.
These efforts involved thousands of lines of Verilog code, but because they sound more engineering-oriented, they were not presented in the KV-Direct paper at all. We spent several person-months of development and debugging work. After optimizing the Verilog code to the extreme, the performance of PCIe small packets improved somewhat, but still did not meet expectations. Finally, we identified the root cause of the performance bottleneck, summarized in Section 2.4 and Figure 3 of the KV-Direct paper. First, PCIe has a flow control mechanism, possibly due to the Hard IP, the PCIe response latency of the FPGA is relatively high, causing the flow control mechanism to limit the flow and insufficient concurrency. Secondly, for PCIe reads, our FPGA’s Hard IP only supports 64 tags (marks for concurrent requests), further limiting the concurrency to 64. Therefore, the throughput for small data reads and writes through PCIe was only about 60 M op/s and 80 M op/s, respectively. There is always a lot of such foundational work in building platforms for system research, which itself does not have any research innovation, but is essential for conducting valuable research work.
Realizing the limited PCIe bandwidth and poor small packet performance, reducing the number of PCIe read and write operations becomes particularly important. This challenge is quite similar to that faced by key-value storage systems accessing remote memory through RDMA one-sided operations. Zhenyuan Ruan is a particularly smart junior. Mention an idea to him, and he quickly gets it; present him with a difficult problem, and he often thinks of clever solutions. He speaks as fast as I do, and sometimes when we can’t get his point, he quietly mocks us for not being very smart.
To reduce the number of PCIe read and write operations, first, Zhenyuan Ruan and I designed a set of sophisticated hash tables and memory allocators to minimize the number of PCIe read and write operations, achieving most inline key-value read operations with only 1 PCIe read operation, and write operations with only 1 PCIe read operation and 1 PCIe write operation. Especially important is that, even when memory utilization is high, it still achieves a lower average number of PCIe read and write operations.
Secondly, we thought of the previously “abandoned” DDR due to its small capacity, wanting to use DDR to assist the host memory. But this is not an easy task, because the bandwidth of DDR is on the same order of magnitude as PCIe, while the capacity of DDR is far less than that of the host memory. If DDR is used as a cache for the host memory, then the system performance might not improve, but might even decline, because the cost of querying the cache is too high. If DDR is only used as an extension of the host memory capacity, then because the capacity of DDR is too small, it can take on too little workload, and the host memory remains the throughput bottleneck, with the added processing capability of DDR being just a drop in the bucket. After much thought, Zhenyuan Ruan and I finally designed a set of caching and load balancing ideas, using DDR as a cache for part of the host memory area, thereby utilizing the bandwidth of DDR.
The second challenge is high PCIe latency. On our FPGA platform, reading the host memory through PCIe takes about 1 us of latency, which is much higher than the theoretical latency, but this might be due to the Hard IP, and we are powerless to change it. During this 1 us, dozens or even hundreds of key-value operation requests may arrive. Some of these key-value operations may have dependencies, such as writing a value and then reading a value, which requires that the read value is the newly written value. To avoid blocking the pipeline, we designed an out-of-order execution engine to handle situations with data dependencies.
Collaborators of KV-Direct: Mentor Lintao, God Ruan, King of Balls, and Teacher Cong
In the systems group, Yuanwei Lu (King of Balls) and Wencong Xiao (Teacher Cong) are my good friends, and also among the few co-trained students in the systems group. King of Balls and my mentor were originally Tan Bo. After Tan Bo left, King of Balls’ mentor became Professor Yongqiang Xiong, and my mentor became Professor Lintao Zhang. Teacher Cong’s mentor was the then director of the systems group, Professor Lidong Zhou, who is now the dean of MSRA. Together with my junior, Zhenyuan Ruan, the four of us collaborated on the KV-Direct paper.
In the KV-Direct project, most of the code was developed by Zhenyuan Ruan, and many key designs were also proposed by him, so I listed him as a co-first author. It was surprising to me that Ruan, as a senior undergraduate student, had such strong research capabilities. After graduation, he went to UCLA to study for a master’s degree under FPGA master Jason Cong, and later went to MIT to pursue a PhD with Frans Kaashoek. He has already published more than 5 papers at top conferences like OSDI and NSDI, which is indeed very impressive.
At MSRA, excellent people tend to attract even more excellent people. The Guo Moruo Scholarship is the highest scholarship at USTC, with only 15 undergraduate students selected each year, and among the USTC students who interned with me, there were 5 Guo Moruo Scholarship winners. My own grades were poor, with a GPA of only 3.3, ranking in the upper middle. The GPAs of the juniors who interned with me (yes, no female juniors) were probably no lower than 3.7, all academically and technically excellent. I think these geniuses were willing to intern with me because, first, I had published a SIGCOMM paper, and second, I had a significant influence in the USTC LUG.
 Above: Mentor Lintao Zhang (right), me (left), and Zibo Wang (middle) who interned together
Above: Mentor Lintao Zhang (right), me (left), and Zibo Wang (middle) who interned together
Mentor Lintao Zhang would have us report our progress once a week and have a one-on-one discussion with me once a month. He also often invited us to eat at the company cafeteria or outside restaurants. He invited us so often that sometimes we felt embarrassed. During one-on-one discussions or meals, Mentor Lintao Zhang often shared many of his original theories with us.
For example, his most famous “Thirty Years” theory: to solve a difficult problem, go read articles from thirty years ago. For instance, neural networks were first proposed in the 1980s and became popular again around 2010. Innovators from the last ten or twenty years are still active in research. If their methods from back then could solve today’s problems, they would have solved them themselves. But most innovators from thirty years ago are no longer on the front lines, and old methods buried in piles of old papers might be useful now. Additionally, in many fields, system architectures also develop in a spiral, such as thin clients and fat clients, centralized and distributed, unified instruction set and heterogeneous computing, etc., where the new architecture might have been played out in the previous historical cycle.
Mentor Lintao Zhang also said that the development of things often does not conform to his expectations. For example, when he was a PhD student, he thought it would be difficult to do lithography below 1 um because of diffraction, but the semiconductor industry, with so much money invested, managed to achieve a few nanometers. When Wang Jian went to Alibaba to work on the cloud, he thought that these people, who had never done system research, would definitely not be able to develop a cloud, but Alibaba Cloud became more and more powerful. This was not just his prediction, but the prediction of many experts in the field. Therefore, the most unreliable thing is predicting the future.
Experiments of KV-Direct
Despite having optimized the single-card performance of KV-Direct to the extreme, the performance of a single card is still limited by PCIe bandwidth and network bandwidth, and cannot be too high. If we submit it like this, reviewers might think at first glance that the performance improvement over existing work is not much.
I want to fully utilize the PCIe performance of the CPU and create a major news in key-value storage performance. A Xeon E5 CPU has 40 PCIe lanes, and a dual-socket server has 80, theoretically supporting 10 FPGA cards. Since machines used for AI training are equipped with 8 cards, why can’t we plug multiple FPGA cards into a server? Unfortunately, our group did not have a host that could insert 8 cards at that time, and applying for an 8-card host required a long process, which we couldn’t wait for the paper submission.
The first thing I thought of was to use the existing 2U server’s PCIe slots to plug in a few more cards. But many of the PCIe slots in a 2U server are PCIe Gen3 x16, and we could only use x8 for one card, wasting the remaining x8. In addition, our FPGA cards are full-height half-length, and some PCIe slots are half-height, which cannot fit FPGA cards. For this reason, I went to Hailong Electronics City in Zhongguancun and bought several PCIe extension cables and bifurcation expansion cards. Back in the MSRA machine room, I opened the chassis, separated the cards with static bags after using the extension cables, and stacked them on top, like an overloaded truck.
 Above: 8 FPGA cards plugged into the group's 2U server
Above: 8 FPGA cards plugged into the group's 2U server
Only two cards were plugged in, and the BIOS blue-screened during self-check, saying that some cards had PCIe training errors. I reflashed the BIOS to solve this problem, and finally, the two cards could run normally. When all 8 cards were plugged in, the device manager recognized all 8 cards, but when running the performance test, I suddenly smelled a burnt odor, and the motherboard was burned. I am probably the first, and possibly the last, in the MSRA systems group to burn a motherboard. Fortunately, the precious FPGA cards were not damaged.
Mentor Lin Tao said that it might be due to insufficient power supply to the motherboard. If he had known in advance, he would not have let me burn the motherboard. Then he gave me a thick book on PCIe bus brought back from the United States to study.
 Above: 8 FPGA cards were recognized for the first and last time because the motherboard burned out during the subsequent performance test
Above: 8 FPGA cards were recognized for the first and last time because the motherboard burned out during the subsequent performance test
So how to solve the problem of multi-card servers? I thought of Xianyu. Although a 4U 8-card host costs over a hundred thousand, a motherboard that supports 10 cards only costs 2000 yuan on Xianyu. I paid for one out of my pocket; along with buying two second-hand Xeon E5 2650 V2 CPUs, one for 1000; 16 pieces of second-hand 8 GB DDR3 memory, totaling 2400 yuan; and pulling out a 500 yuan Juyuan power supply from a mining rig, as well as some cooling fans, this 8-card machine only cost about 7000 yuan in total.
After plugging in one FPGA, it ran well, then another, still no problem, and finally all 10 FPGAs were plugged in, still running very smoothly. PCIe was basically maxed out, but the host’s DDR was indeed not yet maxed out, which confirmed our guess.
 Above: KV-Direct's motherboard, bought on Xianyu for 2000 yuan
Above: KV-Direct's motherboard, bought on Xianyu for 2000 yuan
 Above: KV-Direct's pre-system before plugging in FPGA, merely worth 7000 yuan
Above: KV-Direct's pre-system before plugging in FPGA, merely worth 7000 yuan
Who would have thought, the world’s fastest single-machine key-value storage system at that time was actually built on a second-hand pre-system worth 7000 yuan, of course, this does not include the price of 10 FPGA cards, which are much more expensive than the pre-system.
 Above: KV-Direct experimental environment, 10 cards reached 1.2 billion key-value operations per second
Above: KV-Direct experimental environment, 10 cards reached 1.2 billion key-value operations per second
Writing of KV-Direct
In writing KV-Direct, one question we needed to answer was, why do we need such high-performance key-value storage? If it’s just traditional web services, there isn’t such a high demand for key-value storage performance, and the saved cost isn’t much either. Mentor Lin Tao and Professor Cong gave me an important input: big data computing applications have a high throughput demand for key-value storage, such as parameter servers in machine learning. Although graph computing currently uses custom data structures to store vertices and edges, theoretically, they can also use key-value storage. Thus, creating a system that is 10 times faster than the most advanced key-value storage in academia is valuable.
Mentor Lin Tao helped us revise the paper, literally changing it word by word. Mentor Lin Tao’s English level is very high, and he can effortlessly communicate with foreigners in English during meetings. Reading his revised papers, I am also learning English. For example, to be frugal on memory accesses, Mentor Lin Tao changed it to be frugal on memory accesses. The title of section 2.2 of the paper was originally Challenges of High-Performance KVS Systems, and he changed it to Achilles’ Heel of High-Performance KVS Systems. The first sentence of this section, Building a high performance KVS is a non-trivial exercise of optimizing various software and hardware components in a computer system, suddenly opened up the scope.
Speaking of this “exercise,” Mentor Lin Tao often told us, many top conference papers are just exercises of PhD students, students need to publish papers to graduate, and not every paper can be of high quality. First learn to publish papers, solve problems set by others; then learn how to discover new problems and how to apply solutions to practice. We are still at the stage of not even having learned to publish papers. After all, Mentor Lin Tao is a gold medalist in the International Physics Olympiad, with tens of thousands of citations for his papers, and his early work has won the test of time award, being one of the first chief researchers to return to MSRA from Silicon Valley.
On the SOSP deadline day, Mentor Lin Tao stayed up all night with us, revising the paper together. At 8 a.m., when the deadline arrived, Mentor Lin Tao said, let’s go, I’ll take you out for breakfast. Mentor Lin Tao then took us to Xibu Mahua Beef Noodles for breakfast, and then we went home to catch up on sleep.
 Above: KV-Direct team rushing for the SOSP deadline in MSRA's elevator, from left: Xiao Wencong, Lu Yuanwei, Ruan Zhenyuan, Li Bojie
Above: KV-Direct team rushing for the SOSP deadline in MSRA's elevator, from left: Xiao Wencong, Lu Yuanwei, Ruan Zhenyuan, Li Bojie
SOSP 2017 Conference
SOSP and OSDI are the two top conferences in the field of computer systems, where many classic works in operating systems and distributed systems have been published historically. In 2017, Dean Zhou Lidong of MSRA and Professor Chen Haibo of Shanghai Jiao Tong University jointly brought SOSP to Shanghai, China, marking the first time SOSP came to China.
 Above: Teachers and students from USTC at SOSP 2017
Above: Teachers and students from USTC at SOSP 2017
At this SOSP, in addition to the main venue presentation of KV-Direct, we also demonstrated many other research results, including IPC-Direct (later SocksDirect) co-authored with Cui Tianyi, and total order message broadcasting co-authored with Zuo Gefei. The stories of these projects will be detailed later. Professor Cong and Qiu Wang also presented their respective research results.
After SOSP, when I was giving a talk at Fudan University, I mentioned that my academic achievements are actually those of our team, especially relying on the excellent students I attracted from USTC. The core members of USTC LUG for several sessions were basically poached by me, some came to our group for internships, and some were recommended by me to intern in other groups. By then, the LUG buddies interning at MSRA could gather for a meal.
 Above: By October 2017, my collaborators from USTC at MSRA, without these excellent students, I could definitely not have achieved these research results
Above: By October 2017, my collaborators from USTC at MSRA, without these excellent students, I could definitely not have achieved these research results
Meeting my wife at an academic talk at USTC
According to USTC’s requirements for jointly supervised PhD students, each jointly supervised PhD student needs to give at least one academic talk at the university. I was very honored when Professor Tan Haisheng from Dean Li Xiangyang’s lab invited me to give a talk and have an academic exchange with the lab’s students afterward.
On November 2, 2017, I gave an academic talk titled “Accelerating Data Center Infrastructure with Programmable Hardware” at USTC, mainly about the ClickNP and KV-Direct papers, along with the HTTPS, AI acceleration work mentioned earlier, hoping to use FPGA as the acceleration plane for data centers, connecting various heterogeneous computing devices and storage devices, breaking the traditional CPU-centric data center architecture.
 Above: My "Accelerating Data Center Infrastructure with Programmable Hardware" talk poster at USTC
Above: My "Accelerating Data Center Infrastructure with Programmable Hardware" talk poster at USTC
 Above: After inviting me to give an academic talk at USTC, Professor Tan Haisheng and Professor Hua Bei presented me with a commemorative trophy. Professor Hua Bei was my undergraduate thesis advisor. The trophy reads "Dr. Li Bojie", but I had not yet obtained my PhD degree at the time, so my classmates teased me, saying the school has already decreed you can graduate :)
Above: After inviting me to give an academic talk at USTC, Professor Tan Haisheng and Professor Hua Bei presented me with a commemorative trophy. Professor Hua Bei was my undergraduate thesis advisor. The trophy reads "Dr. Li Bojie", but I had not yet obtained my PhD degree at the time, so my classmates teased me, saying the school has already decreed you can graduate :)
Who could have predicted that on this day I would meet my future wife? Meng Jiaying was a student of Professor Tan Haisheng, attended the talk that day, and also participated in the academic exchange. That session was originally Professor Tan’s group meeting, but once they heard I was coming, three girls from Professor Zhang Lan’s group also came. Professor Tan’s group had only Meng Jiaying and Liu Liuyan, and from Professor Zhang Lan’s group came Xue Shuangshuang, Li Yannan, and Li Anran. When Professor Tan introduced Li Yannan, he said she was Ruan Zhenyuan’s girlfriend (which I already knew), and she felt that such an introduction was not very appropriate.
Although I added everyone on WeChat at the time, with my face blindness, I didn’t remember many people. When giving the talk, I left my collection of papers in the conference room. At that time, junior brother Liu Huiqi contacted me to get the collection of papers, but when I went to get the collection of papers, upon seeing him, I asked: Are you Meng Jiaying? I don’t know how I blurted out Meng Jiaying’s name, mistakenly confusing the gender, becoming a joke in Professor Tan’s lab. That day, Meng Jiaying did indeed contact me on QQ to ask for the PPT of the talk, and there was no further contact. Perhaps this was a destined fate.
 Above: Professor Tan Haisheng invited me and his students for an academic exchange
Above: Professor Tan Haisheng invited me and his students for an academic exchange
 Above: Professor Tan Haisheng invited me and his students for an academic exchange
Above: Professor Tan Haisheng invited me and his students for an academic exchange
There was also a coincidence that evening, it was the first and last time I met with my ex-girlfriend after we broke up. At that time, I said, although it had been a year and a half since we broke up, I still couldn’t forget her. She said, maybe it would be better if you find someone else.
Failed my proposal defense, but I got a girlfriend
In November, Jiaying and I just added each other on WeChat, without any further contact. On December 1st, she came to me with a research question, and it took me a day to reply, and another day for her to respond, but that’s how we started talking about research. Actually, I’m quite busy usually, often not replying to messages on WeChat for several days, sometimes accumulating dozens of unread messages. I don’t know why, but that day I suddenly became interested in chatting. For the next two weeks, we didn’t contact each other.
On December 18th, I returned to school to handle the procedures for my proposal defense and attended a lecture about the proposal requirements. Jiaying also attended this lecture. She said that she saw someone who looked a lot like me but wasn’t sure until others in the lab confirmed it was indeed me. Jiaying reached out to me on WeChat for confirmation, and then we started talking again, and our communication became more frequent, almost without interruption.
On January 10th of the following year, I returned to school for my proposal defense. At that time, I didn’t take the proposal defense very seriously, many of the illustrations in the proposal report were screenshots from PPT, and the format didn’t quite meet the school’s requirements. One of the defense committee members asked if the thesis also directly used screenshots from PPT. Dean Li said that these two papers (ClickNP and KV-Direct) were wasted being presented this way; they should be told as a whole story; now, it’s just pieced together, like a bunch of engineering projects. In the end, my proposal was not approved.
However, that evening was the first time Jiaying and I met alone. We went to Zhixin City, had spicy fish hotpot at Xinxidao, and watched a movie. Before our first meeting alone, to prevent face blindness, I specifically looked at her photo, so I recognized her from afar and greeted her. Since then, our relationship warmed up quickly. Before the New Year (February 10th to February 14th), we went to Taiyuan, Pingyao, and Jiexiu, visiting Pingyao Ancient City and Qiao’s Family Compound. In Pingyao Ancient City, Jiaying’s hands were always freezing red, I wanted to warm them, and then it turned into holding hands. Valentine’s Day coincidentally was on Chinese New Year’s Eve, we strolled in Taiyuan together, and then went back to our respective hometowns. On February 19th, while we were at home, we confessed to each other over a video call.
In June, my second proposal was finally approved. This time I referred to the format of my senior’s proposal report and seriously considered what kind of story a doctoral thesis should tell. I slightly modified the title of my doctoral thesis to “High-Performance Data Center Systems Based on Programmable Network Cards”, generalized FPGA to the concept of programmable network cards, and proposed to use programmable network cards to implement full-stack acceleration of computing, networking, and memory storage nodes in cloud computing data centers, including virtual networks, network functions, data structures, and operating system communication primitives.
This article is part of the “Five Years of PhD at MSRA” series (II) leading my first SOSP paper, to be continued…