SOSP: The Weathervane of Computer Systems Research
(Reprinted from Microsoft Research Asia)
Since its inception in 1967, SOSP (Symposium on Operating Systems Principles) has been held every two years for 50 years. From the UNIX system in 1969 to MapReduce, BigTable, and GFS in the early 21st century, a series of the most influential works in the systems field have been published at SOSP and its biennial sibling conference OSDI. If you compile the most influential papers (Hall of Fame Award) from SOSP and OSDI over the years, it would be more than half of the textbooks on operating systems and distributed systems. As the highest academic conference in the systems field, SOSP and OSDI only accept 30 to 40 high-quality papers each year, so being able to publish a paper at SOSP is an honor for system researchers.
 SOSP’17 Opening Ceremony (Photo Source: Professor Chen Haibo)
SOSP’17 Opening Ceremony (Photo Source: Professor Chen Haibo)
This year, SOSP came to Shanghai, China for the first time, outside of North America and Europe. Dr. Zhou Lidong, Deputy Director of Microsoft Research Asia, and Professor Chen Haibo of Shanghai Jiaotong University served as the chairmen of the conference committee, with Professor Lorenzo Alvisi of Cornell University and Professor Peter Chen of the University of Michigan serving as the chairmen of the program committee. This SOSP conference set several records and firsts: the most registered participants (850); the most sponsors in number and amount; the first time offering live streaming and online Q&A; the first time setting up an AI Systems Workshop to discuss the emerging important application of AI systems; sponsored by Microsoft Research, the first ACM Student Research Competition (SRC) was held, attracting over 40 submissions.
 Ada Workshop Participants Group Photo
Ada Workshop Participants Group Photo
Particularly worth mentioning is that this SOSP conference held the Ada Workshop outside the United States for the first time. Microsoft Research Asia, in conjunction with SOSP’17, invited many female researchers from home and abroad to jointly explore the future of the computer systems field. In 1987, American computer scientist Anita Borg attended the SOSP’87 conference and was surprised to find that she was the only female scientist, which led her to promote the status of women in computer research for the next thirty years. Today, the voices of female researchers in the systems research field are increasingly important. The only author who gave two presentations at this SOSP, Kay Ousterhout, is a female Ph.D. graduate from UC Berkeley, and her advisor Sylvia Ratnasamy is also a renowned female scientist. We hope that the Ada Workshop can help women in the systems research field grow rapidly and inspire more women with dreams to join the systems research field.
 Microsoft's booth at the SOSP’17 conference
Microsoft's booth at the SOSP’17 conference
This SOSP conference attracted 232 submissions from 23 countries and regions across five continents, with 39 papers accepted. The number of submissions increased by 30% compared to the last conference, while the acceptance rate remained unchanged. Microsoft was not only the gold sponsor of SOSP’17 but also published 8 main conference papers (4 of which were first-authored), making it the institution with the most published papers (the second place was MIT, with 6 papers published). The 55 reviewers of SOSP are all leading figures in academia, taking the review work very seriously. Each submission received an average of 4.9 review comments, each comment averaging 6.5 KB in length. After the review, the program committee selected 76 papers, and 23 main reviewers selected the final 39 papers after two days of meetings.
 Xiao Wencong, a Ph.D. student jointly trained by Beihang University and Microsoft Research Asia, presents his research results at the AI Systems Workshop. AI systems are one of the main research directions of the Systems Group at Microsoft Research Asia.
Xiao Wencong, a Ph.D. student jointly trained by Beihang University and Microsoft Research Asia, presents his research results at the AI Systems Workshop. AI systems are one of the main research directions of the Systems Group at Microsoft Research Asia.
 Microsoft Research Asia intern Zuo Gefei presents his research results to SIGOPS Chair Professor Robbert van Renesse at the SOSP Student Research Competition (SRC), which won the silver medal in the undergraduate group.
Microsoft Research Asia intern Zuo Gefei presents his research results to SIGOPS Chair Professor Robbert van Renesse at the SOSP Student Research Competition (SRC), which won the silver medal in the undergraduate group.
The 39 main conference papers were fully scheduled in 13 sessions over three days in a single track format, with each paper having 25 minutes for oral presentation and Q&A, covering multiple fields such as bug finding, scalability, network computing, resource management, operating system kernel, verification, system repair, privacy, storage systems, security, fault diagnosis, data analysis, etc.
Next, we will share the latest advancements in system research at SOSP from two aspects: making systems more efficient and more reliable.
More Efficient Data Centers
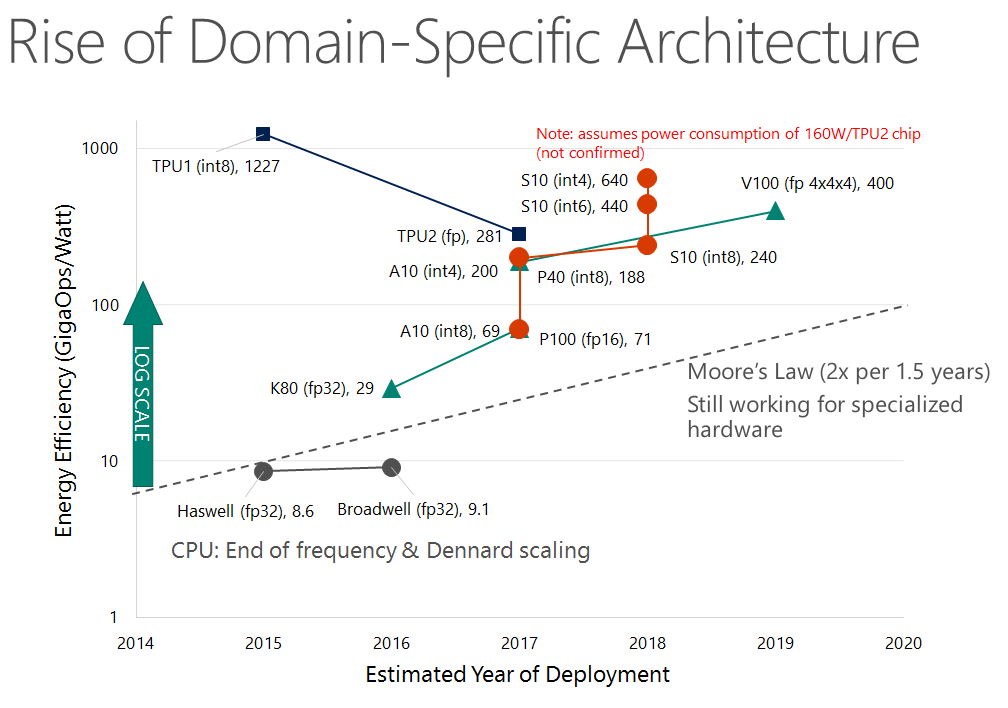 Moore's Law has basically ended for CPUs, but it continues for customized hardware like GPUs, FPGAs, TPUs, etc.
Moore's Law has basically ended for CPUs, but it continues for customized hardware like GPUs, FPGAs, TPUs, etc.
Today’s data centers are increasingly like warehouse-scale supercomputers, rather than loosely distributed systems in the traditional sense. On the one hand, the computing and interconnection capabilities of hardware are getting higher and higher. For example, the speed of the network is not far from the speed of the PCIe bus and DRAM bus, and RDMA can reduce latency from hundreds of microseconds to a few microseconds; the latency of NVMe SSDs is on the order of 100 microseconds, two orders of magnitude lower than mechanical hard drives, and NVM (Non-Volatile Memory) further reduces latency by two orders of magnitude; in many scenarios, the energy efficiency of acceleration devices such as GPUs, FPGAs, and TPUs is two orders of magnitude higher than CPUs. However, traditional operating systems cannot fully utilize the rapidly improving hardware performance due to their mechanisms for accessing peripherals, task switching, and multi-core synchronization.
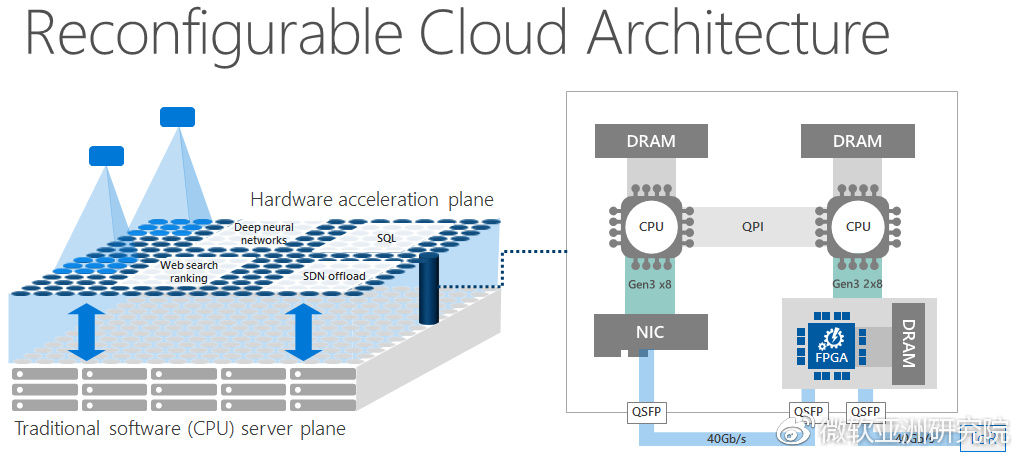 Programmable data center hardware, Microsoft uses programmable network cards equipped with FPGAs as data center acceleration planes
Programmable data center hardware, Microsoft uses programmable network cards equipped with FPGAs as data center acceleration planes
On the other hand, the programmability of data center hardware is getting stronger. For example, programmable switches and network cards allow the network to do caching, aggregation, and scheduling in addition to forwarding packets. Hardware virtualization supported by CPUs, SR-IOV virtualization supported by PCIe devices, SGX secure containers and TSX transaction memory supported by CPUs provide a lot of isolation that is difficult for software to implement efficiently, which is crucial for multi-tenant cloud environments. Technologies such as RDMA/RoCE network cards, GPU-Direct, NVMe Over Fabrics allow devices to interconnect directly bypassing the CPU. How to fully utilize these programmabilities in system design has become a new challenge in the field of system research.
Performance Bottlenecks of Distributed Coordination
About half of the papers at this SOSP are dedicated to improving system performance. One common performance bottleneck is in distributed coordination, and the more nodes, the more severe the bottleneck.
The first problem with distributed coordination is that multiple nodes (servers or CPU cores) are unbalanced, and the worst-case latency (tail latency) of hotspot nodes is high. One solution is to replace distributed coordination with centralized allocation. In key-value store systems, NetCache uses programmable switches as caches to achieve load balancing between different servers in the same cabinet; KV-Direct uses programmable network cards as caches to achieve load balancing between different CPU cores on the same server; another solution is to redistribute tasks. In network processing systems, ZygOS is built on top of IX (letting the network card distribute tasks to different queues corresponding to multiple CPU cores), for load balancing, idle CPU cores “steal” tasks (work stealing) from other cores’ queues, and use inter-core interrupts (IPI) to reduce the processing latency of response packets.
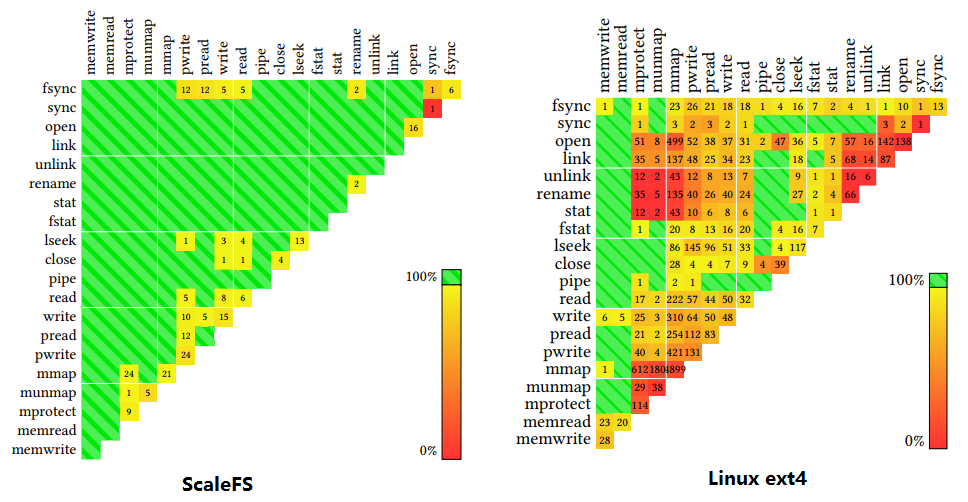 There are many shared memory conflicts between the system call interfaces of the Linux file system, and ScaleFS eliminates most of the conflict situations (Image source: Scaling a file system to many cores using an operation log, SOSP’17)
There are many shared memory conflicts between the system call interfaces of the Linux file system, and ScaleFS eliminates most of the conflict situations (Image source: Scaling a file system to many cores using an operation log, SOSP’17)
The second problem with distributed coordination is that the bandwidth and latency occupied by communication are high. One way is to reduce conflicts semantically so that each node does not interfere with each other. In file systems, ScaleFS improves the Linux API, which has many semantic conflicts, based on the swappable file system API (sv6), builds a conflict-free file system abstraction in memory, records the file system operations of each core in the log, and merges the logs of different cores when it needs to write to disk; in digital currency systems, to efficiently implement Byzantine consensus among a large number of untrusted nodes, existing systems often need to compete for “mining” to select representatives, while Algorand uses a verifiable random function (VRF), which can select universally recognized representatives without communication and a lot of computation; in anonymous communication systems, the Atom system achieves anonymous broadcasting and discovers dishonest nodes with a high probability by randomly grouping users, without the need for all nodes in the network to communicate with each other. Another way to reduce the communication overhead in distributed coordination is to introduce central nodes. Eris uses the natural centers in the network (programmable switches) to act as “sequencers”, achieving strictly ordered broadcast messages with very low overhead, thereby greatly simplifying concurrency control in distributed transactions. To achieve concurrency control of shared memory on multi-core, ffwd delegates the “lock grabbing” operation usually implemented with atomic operations to a CPU core for coordination, achieving higher throughput.
System Interface Abstraction
There is a famous saying in the system field, “Any problem in computer science can be solved by adding a middle layer”. Interfaces that are too low-level lead to complex application programming and consistency issues when accessed concurrently. For example, both LITE and KV-Direct papers point out that the abstraction of RDMA is not entirely suitable for data center applications. First, RDMA exposes low-level information such as buffer management to users, making RDMA programming much more complex than TCP socket, and in the case of many connections, the memory address virtual-real mapping table can easily cause network card cache overflow. To this end, LITE proposes a more flexible and easy-to-use API, and transfers the work of virtual-real mapping from the network card to the CPU. Secondly, for data structures that require multiple memory accesses to complete an operation, to ensure the atomicity of data structure operations, concurrent write operations by multiple clients have a high synchronization overhead. For this, KV-Direct extends the RDMA memory access semantics to the higher-level semantics of key-value operations, and implements out-of-order execution of concurrent atomic operations in the programmable network card on the server side.
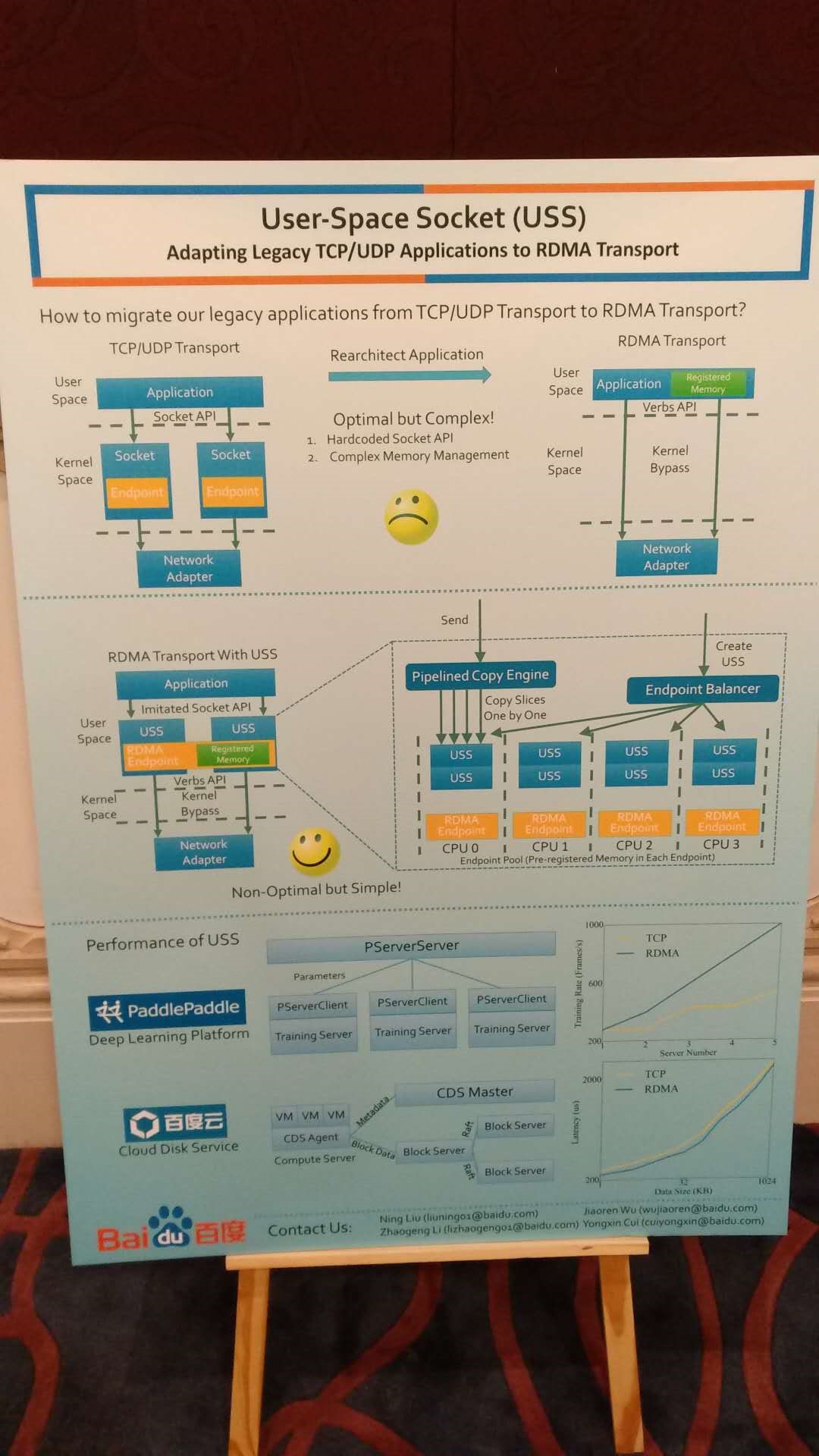 Baidu's proposed USS, translating socket semantics to RDMA. There are also multiple similar works in academia.
Baidu's proposed USS, translating socket semantics to RDMA. There are also multiple similar works in academia.
However, the level of abstraction is not the more the better. When there are too many layers of abstraction, two middle layers may do the same thing, and they cannot fully utilize the performance of the underlying hardware. For example, in a virtualized environment, each virtual machine often only does one small thing, and at this time the scheduling, resource management, and other abstractions of the virtual machine operating system seem redundant. The design of Unikernel came into being, compiling the application program, runtime library, and drivers in the kernel together, becoming a lightweight virtual machine without distinguishing between user mode and kernel mode; for applications that are more complex in system calls or require multiple processes, you can also use Tinyx to customize a streamlined Linux “distribution” for the application, still using the Linux kernel, but with much faster startup speed. For example, key-value storage on SSDs may be organized in the form of log-structured trees, and the underlying FTL of SSDs is a similar structure. NVMKV merges the two, reducing the overhead of write operations.
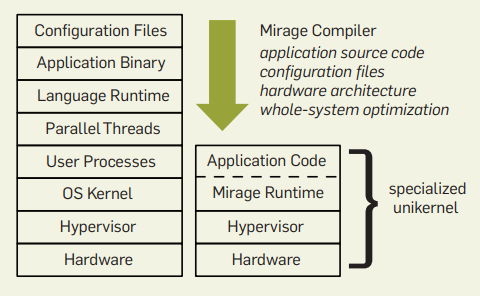 Comparison of Unikernel (right) customized for applications and Linux (left) (Image source: Unikernels: The Rise of the Virtual Library Operating System, ACMQueue, Jan. 2014)
Comparison of Unikernel (right) customized for applications and Linux (left) (Image source: Unikernels: The Rise of the Virtual Library Operating System, ACMQueue, Jan. 2014)
Classic abstractions may hide many unnecessary features and designs unsuitable for modern hardware architectures. It is well known that the newly born user-space network protocol stack and file system are much more efficient than the implementation in the Linux kernel. ScaleFS and its research group’s previous work showed that the system call interface of Linux has many designs that are not conducive to multi-core scaling. A paper that implements multi-process, isolation, and memory sharing on a 64 KB embedded computer (like a USB token such as Yubikey) with Rust shows that the core mechanisms of modern operating systems are not complicated. The low access latency of NVMM (Non-Volatile Memory) means that applications need to mmap directly access NVMM (without the physical memory cache in the classic file system), but the consistency of persistent storage requires snapshot and error correction functions, and the NOVA-Fortis file system is designed for this. In the paper Strata: A Cross Media File System, the authors also pointed out that traditional file systems amplify a small write operation into a whole block of write operations, which was designed for mechanical hard drives and SSDs, but it is a waste for NVM that can efficiently execute small random writes.
Even if the abstraction provided by the CPU lacks certain features, system designers can often implement them in software without waiting for the next generation of hardware that is eagerly awaited. For example, ARM v8.0 does not support nested virtualization, and the NEVE system uses a para-virtualization method, modifying the software of the inner virtual machine (guest hypervisor), and simulating the trap of the outer virtual machine. Also, Intel SGX does not support dynamic memory allocation, and there are security vulnerabilities in the operating system detecting protected code behavior through page faults. Komodo replaces privileged instructions implemented by CPU hardware with verified software, achieving faster and more flexible evolution. Therefore, high-performance systems do not mean putting as many functions as possible into hardware in software, but finding a reasonable boundary and interface between hardware and software.
“Swiss Army Knife” Systems
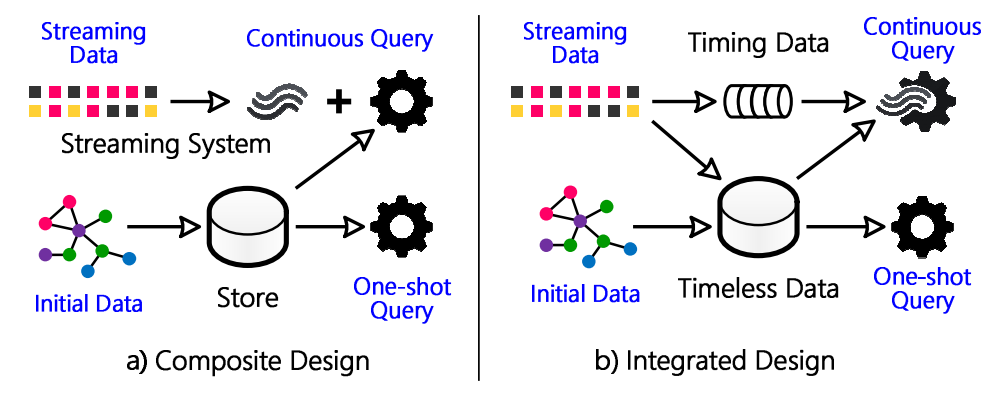 Comparison of traditional stream processing and database systems (left) and Wukong+S (right) (Image source: Stateful Stream Querying over Fast-evolving Linked Data, SOSP’17)
Comparison of traditional stream processing and database systems (left) and Wukong+S (right) (Image source: Stateful Stream Querying over Fast-evolving Linked Data, SOSP’17)
In addition to solving the bottlenecks of existing systems, another direction of system research is to build systems that can work efficiently in various application scenarios. For example, stream processing systems often assume that stream computing functions are continuously running and stateless, while database systems assume that data is unchanged during the execution of queries, making it difficult to do continuous stream queries and one-time simple snapshot queries in one system. The Wukong+S system goes further on the basis of the Wukong system at last year’s OSDI, separating the state that does not change over time from the state that changes over time, allowing both stream and one-time queries to be efficiently completed. Similarly, in a database system where OLAP and OLTP coexist, if the OLAP query runs on a snapshot, the statistical information obtained is outdated. The Xylem system, which won the gold medal in the graduate group of the SOSP student research competition, treats the OLAP query as a view, and incrementally updates the view when OLTP modifies the data, so that the results of OLAP can reflect the latest state of the database. Also, stream processing systems have low latency but long recovery time, batch processing systems can recover quickly but have high latency. The Drizzle system decouples the data processing cycle and the fault recovery cycle, achieving low latency and fast recovery of stream processing.
More Reliable Systems
 At the SOSP opening ceremony, the conference chair's suggestions for keywords for OSDI 2018
At the SOSP opening ceremony, the conference chair's suggestions for keywords for OSDI 2018
In a production environment, reliability is often a more important consideration than performance. At this year’s SOSP opening ceremony, the conference chair listed several words he hoped to see at next year’s OSDI, including enclave, specification, crash, bug, verification, and testing. There are several ways to improve software reliability: finding bugs, formal verification, fault diagnosis and recovery, virtualization and isolation.
 Test cases automatically generated by the best paper DeepXplore, the first row is the original image, the second row changes the lighting conditions; the third row is another set of original images, the fourth row adds interference blocks (Image source: DeepXplore: Automated Whitebox Testing of Deep Learning Systems, SOSP’17)
Test cases automatically generated by the best paper DeepXplore, the first row is the original image, the second row changes the lighting conditions; the third row is another set of original images, the fourth row adds interference blocks (Image source: DeepXplore: Automated Whitebox Testing of Deep Learning Systems, SOSP’17)
The two best papers at this year’s SOSP are in the field of reliability, one proposing the problem of automatic white-box testing of deep neural networks, and the other proposing the problem of efficient web server auditing. Both papers propose novel and important problems and provide beautiful solutions. DeepXplore points out that the test cases generated by previous deep adversarial networks are neither realistic nor comprehensive. By analogy with software testing code coverage, the concept of neural network testing coverage is proposed. If an input to a neural network causes a neuron to be in an active state, it is considered to cover this neuron. DeepXplore also proposes an optimization method to generate test cases to maximize neuron coverage, and found many boundary cases that were misidentified in neural networks such as autonomous driving and malware recognition.
Another best paper aims to discover abnormal Web server behavior (such as tampering with programs or untrustworthy service providers) by recording the execution process of the Web server. The access to shared objects and network interactions of the Web server are recorded, so the processing of a request is purely functional. The processing of multiple requests is combined and deduced using a method similar to symbolic execution, which greatly reduces the time overhead of the verifier compared to repeatedly executing each request. Another paper from Microsoft, CrystalNet, is also dedicated to efficient simulation problems. Traditional network simulators are slow in simulating large-scale networks and it is difficult to simulate the software of the control plane, however, most network failures are due to the control plane rather than the data plane. For this reason, Microsoft uses virtual machines or containers to simulate switch firmware and network controllers, simulate the behavior of the control plane, and simulate the behavior of other operators on the WAN, making data center-scale network simulation possible.
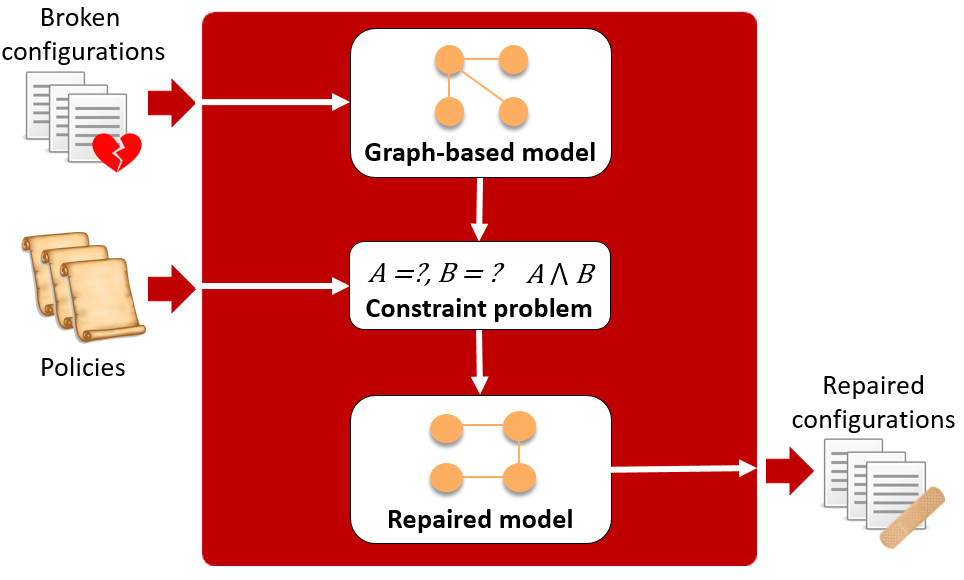 CPR system automatically repairs erroneous network configurations (Image source: Automatically Repairing Network Control Planes Using an Abstract Representation, SOSP’17)
CPR system automatically repairs erroneous network configurations (Image source: Automatically Repairing Network Control Planes Using an Abstract Representation, SOSP’17)
When a system fails, two things need to be done. On the one hand, it should be able to automatically repair to a usable state to ensure the availability of the service. The CPR system, in which Microsoft Research is involved, can automatically adjust routing to meet some pre-specified network reachability constraints when a network control plane failure occurs. MittOS proactively rejects requests when the queue is too long and there is a risk of exceeding the maximum allowable delay, directing the application to other replicas for processing. On the other hand, sufficient logs should be left for operations personnel to investigate and thoroughly resolve. Due to the complexity of system states and uncertainty during operation, even with logs, reproducing bugs is a well-known challenge. The Pensieve system mimics the human method of analyzing bugs, using static analysis to start from the most likely error locations, backtracking based on control flow and data flow, skipping most of the code that is likely irrelevant to the error, until external input (API calls), thereby generating test cases.
Automatically generating test cases to find bugs is good, but only systems that have undergone formal verification can guarantee the absence of certain types of bugs. However, formal verification often requires an order of magnitude more manpower to write proofs than code development, greatly limiting its application in industry. HyperKernel achieves automated proof by restricting kernel programming, the most important of which is that there can be no infinite loops and recursion, which is also the requirement of P4 and ClickNP, two high-level languages for programming switches and network cards. Some system call interfaces need to be modified to transfer indefinite loops to user mode. At this time, the control and data flow graph of the kernel is a directed acyclic graph, which can traverse all execution paths to automatically verify the specifications specified by the programmer for HyperKernel, and can also be mapped to switch lookup tables or FPGA logic circuits for hardware acceleration.
Summary
 Group photo of teachers and students from the University of Science and Technology of China at SOSP, including the co-first author of KV-Direct published by the Systems Group of Microsoft Research Asia, Bojie Li (third from right in the back row), Zhenyuan Ruan (first from right in the back row), and the Systems Group interns from Microsoft Research Asia who participated in the SOSP Student Research Competition, Yuanwei Lu (second from right in the front row), Tianyi Cui (second from left in the front row), and Ge Fei Zuo (seventh from left in the back row).
Group photo of teachers and students from the University of Science and Technology of China at SOSP, including the co-first author of KV-Direct published by the Systems Group of Microsoft Research Asia, Bojie Li (third from right in the back row), Zhenyuan Ruan (first from right in the back row), and the Systems Group interns from Microsoft Research Asia who participated in the SOSP Student Research Competition, Yuanwei Lu (second from right in the front row), Tianyi Cui (second from left in the front row), and Ge Fei Zuo (seventh from left in the back row).
The 26th SOSP conference, held in China for the first time, attracted many academic leaders who are rarely seen on weekdays, and also gave many Chinese teachers and students a chance to experience a top academic conference. Important issues, innovative designs, and solid implementations are the three elements that can be published at top system conferences. Of course, publishing a paper is just a small step. For a system to have an impact, it still needs to find real application scenarios, which is also the direction of my future efforts.