The Big Talk on Synchronous/Asynchronous, Blocking/Non-blocking
Many people are confused about the difference between these two sets of concepts. Let’s use the example of Xiao Ming downloading a file.
- Synchronous Blocking: Xiao Ming keeps staring at the download progress bar until it reaches 100%.
- Synchronous Non-blocking: After Xiao Ming starts the download, he goes to do other things, occasionally glancing at the progress bar. When it reaches 100%, the download is complete.
- Asynchronous Blocking: Xiao Ming switches to a software that notifies him when the download is complete. However, he still waits for the “ding” sound (which seems silly, doesn’t it?)
- Asynchronous Non-blocking: Still using the software that “dings” when the download is complete, Xiao Ming starts the download and then goes to do other things. When he hears the “ding”, he knows the download is complete.
In other words, synchronous/asynchronous refers to the notification method of the download software, or the API being called. Blocking/non-blocking refers to Xiao Ming’s waiting method, or the API caller’s waiting method.
In different scenarios, all four combinations of synchronous/asynchronous and blocking/non-blocking are used.
Synchronous Blocking
Synchronous blocking is the simplest method, like calling a function in C language and waiting for it to return.
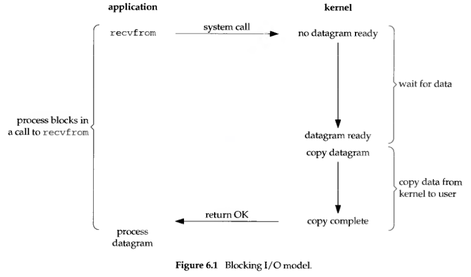
For example, the stat system call to get file metadata only has a synchronous blocking mode. I have encountered a problem on a high-traffic file server (mirrors.ustc.edu.cn) where a large number of nginx processes are in D (uninterruptible) state. This is because the stat system call does not provide a non-blocking I/O (O_NONBLOCK) option (nginx uses non-blocking where it can). During the time the file metadata is read from the disk, the nginx worker process can only wait in kernel mode and cannot do anything else. Not providing the O_NONBLOCK option makes things easier for kernel developers, but users have to pay the price in performance.
Synchronous Non-blocking
Synchronous non-blocking is the polling method of “glancing at the progress bar every once in a while”.
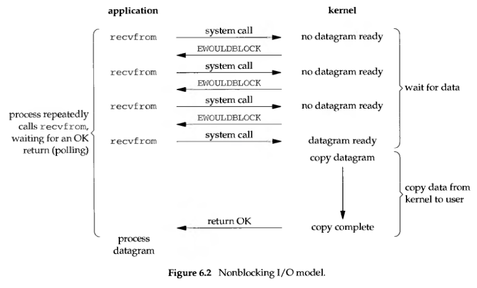
Compared to synchronous blocking, synchronous non-blocking:
- The advantage is that it allows you to do other things while waiting for the task to complete (including submitting other tasks, i.e., multiple tasks can be executed in the “background”).
- The disadvantage is that the response delay of task completion increases, because polling is only done periodically, and the task may be completed at any time between two polls.
Since synchronous non-blocking requires constant polling, and there may be multiple tasks in the “background” at the same time, people have thought of cyclically querying the completion status of multiple tasks. As soon as any task is completed, it is processed. This is the so-called “I/O multiplexing”. The select, poll, and epoll in UNIX/Linux are used for this (epoll is more efficient than poll and select, but they do the same thing). Windows has corresponding WaitForMultipleObjects and IO Completion Ports API (the naming of Windows API is simply streets ahead of POSIX API!)
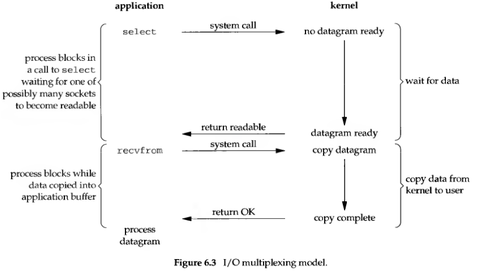 Linux I/O Multiplexing
Linux I/O Multiplexing
Highly concurrent programs generally use synchronous non-blocking rather than multithreading + synchronous blocking. To understand this, we first need to talk about the difference between concurrency and parallelism. For example, if you need to go to several windows in a row to do something in a department, the number of people in the hall is the concurrency, and the number of windows is the parallelism. That is, the number of concurrent tasks (such as simultaneous HTTP requests), and the parallelism is the number of physical resources that can work at the same time (such as the number of CPU cores). By properly scheduling different stages of tasks, the number of concurrent tasks can be much greater than the parallelism. This is the secret of how a few CPUs can support tens of thousands of concurrent user requests. In such a high-concurrency situation, the overhead of creating a process or thread for each task (user request) is very large. The synchronous non-blocking method can throw multiple I/O requests to the background, which can serve a large number of concurrent I/O requests in one process.
Asynchronous Non-blocking
Asynchronous non-blocking is when you throw a task to the “background” to do, and notify when it’s done.
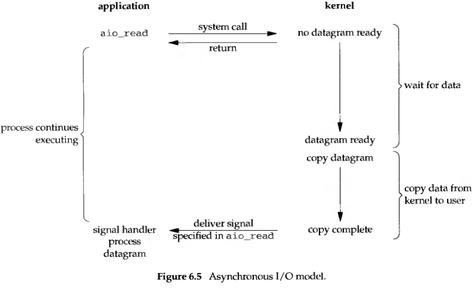
In Linux, the notification method is “signals”.
- If the process is busy doing other things in user mode (for example, calculating the product of two matrices), it is forcibly interrupted and calls a previously registered signal handling function. This function can decide when and how to handle this asynchronous task. Since the signal handling function is suddenly intruding, like an interrupt handling program, there are many things it can’t do. Therefore, to be safe, it usually “registers” the event and puts it in a queue, then returns to what the process was originally doing.
- If the process is busy doing other things in kernel mode, such as reading and writing to the disk in a synchronous blocking manner, then the notification has to be hung up. When the kernel mode task is finished and is about to return to user mode, the signal notification is triggered.
- If the process is currently suspended, for example, it has nothing to do and is sleeping, then the process is awakened. The next time there is a CPU idle, this process will be scheduled, and the signal notification will be triggered.
Asynchronous APIs sound easy, but they are difficult to implement, mainly for the implementers of the API. Linux’s asynchronous I/O (AIO) support was introduced in 2.6.22, and many system calls do not support asynchronous I/O. Linux’s asynchronous I/O was originally designed for databases, so read and write operations through asynchronous I/O are not cached or buffered, which means they cannot take advantage of the operating system’s caching and buffering mechanisms.
The asynchronous I/O API in the Windows API (known as Overlapped I/O) is much more elegant. It allows you to specify a callback function on I/O APIs such as ReadFileEx, WriteFileEx, etc., which will be called when the I/O operation is completed. This is essentially a layer of encapsulation on top of the “signal”. In addition to specifying a callback function, these asynchronous I/O requests can also use the “traditional” synchronous blocking method (WaitForSingleObject), multiplexed synchronous non-blocking method (WaitForMultipleObjects) to wait. Multiple asynchronous I/O requests can also be bound to an I/O Completion Port to wait together.
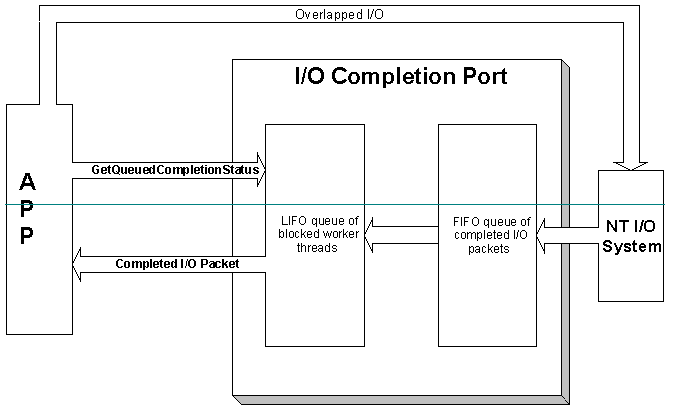 Principle of Windows Asynchronous I/O
Principle of Windows Asynchronous I/O
Many people regard Linux’s O_NONBLOCK as asynchronous, but in fact, it is the synchronous non-blocking method mentioned earlier. Because Linux’s asynchronous I/O is difficult to use, nginx used O_NONBLOCK and epoll in its early versions. It started to support asynchronous I/O from 0.8.11, but the default is still the synchronous non-blocking method. It should be pointed out that although the I/O API on Linux is a bit rough, each programming framework has a well-packaged asynchronous I/O implementation. The operating system does less, leaving more freedom to the user, which is the design philosophy of UNIX and one of the reasons for the variety of programming frameworks on Linux.
Asynchronous Blocking
Why am I still staring at the progress bar stupidly when there is a download completion notification? This seemingly stupid method is also useful. Sometimes our API only provides asynchronous notification methods, such as in node.js, but the business logic requires doing one thing after another, such as accepting user HTTP requests only after the database connection is initialized. Such business logic requires the caller to work in a blocking manner.
In order to simulate the effect of “sequential execution” in an asynchronous environment, it is necessary to convert synchronous code into asynchronous form, which is called CPS (Continuation Passing Style) transformation. The continuation.js library by BYVoid is a tool for CPS transformation. Users only need to write code in a synchronous manner that is more in line with human common sense, and the CPS transformer will convert it into a nested asynchronous callback form.
 Example of asynchronous code after CPS transformation (source: continuation.js)
Example of asynchronous code after CPS transformation (source: continuation.js)
 Example of synchronous code written by the user (source: continuation.js)
Example of synchronous code written by the user (source: continuation.js)
Another reason for using the blocking method is to reduce response latency. If the non-blocking method is used, a task A is submitted to the background and starts doing another thing B, but before B is finished, A is completed. If you want the completion event of A to be processed as soon as possible (for example, A is an urgent transaction), either discard the half-done B, or save the intermediate state of B and switch back to A. Task switching takes time (whether it is loading from disk to memory or from memory to cache), which will inevitably slow down the response speed of A. Therefore, for real-time systems or latency-sensitive transactions, sometimes the blocking method is better than the non-blocking method.
Finally, it should be added that the concept of synchronous/asynchronous is different in different contexts. This article is talking about API or I/O. In other contexts, it may mean something else, for example, in distributed systems, synchronization means that each node synchronizes according to the clock beat, and asynchronous means that it is executed immediately after receiving a message.