Translation: The Artistic Journey of a C Program
Why does a C program need to be compiled before it can be executed? Why does a C program need to go through the four steps of preprocessing, compiling, assembling, and linking to become an executable file? Let’s start with this simple C program.

Why Compile
This is not a simple question. We know that Python code does not need to be “compiled”, and you can run the result by entering a line of code, which is very user-friendly, isn’t it! This interactive runtime environment is called REPL (Read-Evaluate-Print-Loop), which reads the user’s input statement, executes the statement, outputs the value of the statement, and then returns to the waiting input state.
Why can’t C language use this interactive REPL? Not really. In a private SDK, for easy debugging, a 25,000-line C language interpreter is embedded, supporting almost all C language syntax. It uses lex and yacc for lexical and syntactic analysis, and the names of the syntax structures are copied from the C99 standard. When debugging an API, you only need to enter a statement in the interpreter to call the API, without having to write a C file and compile and run it.
Since the statements in C language have no value, only expressions have value, and the interpreter only accepts statements as input, the print step in REPL is omitted, and there will only be output when the output statement is explicitly called. The only difference here from standard C language is that the statement does not need to be written in the main() function, but is executed line by line. In fact, the main() function in C language is a syntactic sugar, which means that all statements must be written in a function. In languages like Pascal, all statements not in any function are taken out and organized into a “main function”.
It can be seen that what prevents C language from being interpreted is not its syntax. So why does the C development environment generally not provide a user-friendly interpretation execution method, but requires writing a rigorously formatted C file and compiling and running it? This is to be machine-friendly, that is, to improve the efficiency of program execution. Today, using C language to write applications is probably a joke (so there are always people in Hanhai Xingyun BBS proposing to rewrite), C language is mainly used for system bottom, embedded and high-performance occasions. In these places, the programmer’s time is cheaper than the machine’s time.
The performance of compilation is higher than that of interpretation execution, which can be seen from a small example. For example, a statement like c = a + b will be compiled into the following assembly code:
1 | movl 12(%esp), %edx ;12(%esp) is b, %edx <= b |
Only 4 lines, very concise, right! The movl in it is to move data from memory to register or from register to memory, and the actual addition operation is completed in the register.
The same is c = a + b. If it is interpreted and executed, the interpreter needs to do these things:
- Lexical analysis: Read in the string “c = a + b”, break it down into lexemes like “c” “=” “a” “+” “b”;
- Syntax analysis: Recognize that the four lexemes “c” “=” “a” “+” “b” form an assignment expression, and the right end of the assignment expression is an arithmetic expression, performing an addition operation. Form a syntax tree;
- Generate intermediate code: Find the positions of the definitions of the three variables c, a, and b from the symbol table, and turn them into a form similar to assembly code (IL, Intermediate Language), such as %c = add i32 %a %b in LLVM;
- Execute intermediate code: Load the intermediate code into memory and execute it line by line. When executing this line, first look at the current intermediate code to be executed is add, jump to the processing procedure of add, and then really execute the add operation.
The first three steps above are also done by compiled languages like C during compilation, saving runtime; in the fourth step, the machine code generated by compilation does not need to look up the intermediate steps of add like executing intermediate code.
Compilation time and runtime are a kind of trade-off. C programs are usually compiled once, run multiple times or run for a long time, so it is considered worthwhile to spend more time on compilation and do more optimization. And interpreted languages are often used as glue languages, that is, to complete a specific task that is discarded after use. In the PHP kernel development mailing list, a monthly post is why PHP does not do compilation optimization. The official reply is that the running time of PHP programs is often very short, such as 10 ms; if you spend 100 ms on compilation optimization and compress the running time to 1 ms, the total time consumption is 101 ms, which is even slower (not considering intermediate code caching).
The C language compiler has been developed for decades, and the compilation optimization has reached a performance similar to handwritten assembly code, that is, the algorithm written in C is reasonable, the implementation is efficient, and the code can basically exert the maximum potential of the machine, so C language has become a benchmark reference. In the table below, languages like Python, R, Matlab, Octave, etc. that interpret and execute line by line are dozens of times slower than C or even more. Fortran, Go as compiled languages are also fast. JavaScript, Java use JIT (Just-In-Time) technology, which is also fast, but there is still a certain gap with C.
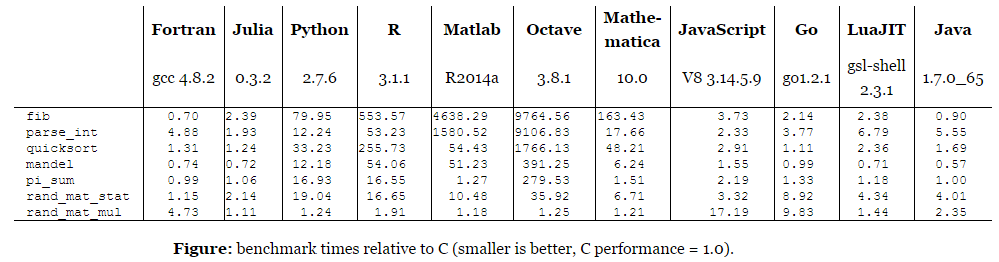 Comparison of various languages with C in terms of performance (Image source: http://julialang.org/)
Comparison of various languages with C in terms of performance (Image source: http://julialang.org/)
Why is compilation divided into four stages?
After a C program is fed into gcc, it goes through a four-stage pipeline to become an executable file.
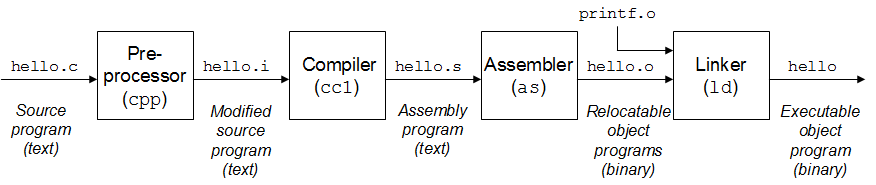
Even though the four stages of preprocessing, compilation, assembly, and linking are encapsulated by cc and can be completed with a single command, we can’t help but ask: Why are there so many stages? Isn’t it enough to translate the source code directly into an executable file?
This involves a basic principle of computer system design: hierarchy and abstraction. David Wheeler once said, “All problems in computer science can be solved by another level of indirection.” Coincidentally, RFC 1925 (The Twelve Networking Truths) also asserts:
1 | (6) It is easier to move a problem around (for example, by moving |
Preprocessing
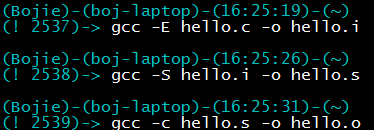
gcc -E hello.c -o hello.i can generate the preprocessed intermediate file hello.i. To show the process of macro expansion, we added some macro definitions in hello.c.
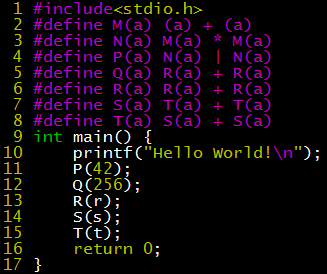
The last few lines of hello.i are as follows.
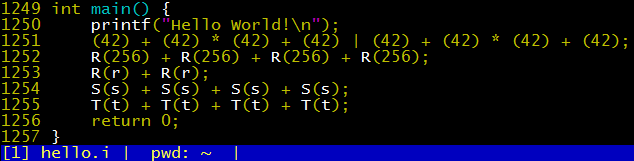
From P(42), we can see that the macro expansion in C language is just string replacement. The operator precedence after expansion may not match what was expected. Therefore, when defining macros with parameters, parentheses should be added on both sides of the expression and the parameters, like this:
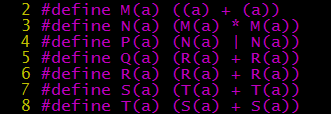
With parentheses, the generated code is much clearer:
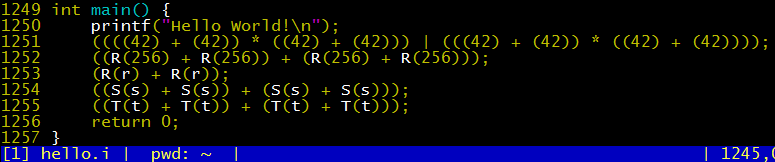
From the expansion process of Q(256), R(r), S(s), and T(t), we can see that the macro expansion in C language will not fall into an infinite loop. It will stop expanding once it encounters itself during the expansion process, that is, it will not recursively expand itself.
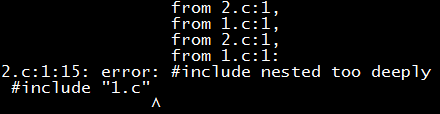
Of course, this does not mean that the preprocessing process will not fall into an infinite loop, because the expansion of #include is recursive. If we #include “2.c” in 1.c and #include “1.c” in 2.c, the preprocessing will output a long string of content and finally report an error: the recursion level is too deep! (Fortunately, gcc does not have a segmentation fault)
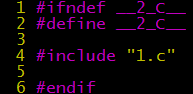
If multiple header files need to reference each other, how can we avoid recursive references? The usual practice is to add the following conditional compilation statements at the beginning and end of the header file: only when the current file has not been included, the content is “displayed”, otherwise, it is “displayed” as an empty file.
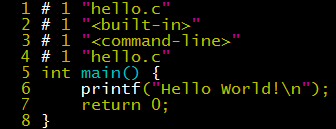
As for the more than a thousand lines of messy stuff at the beginning of hello.i, it’s the content after stdio.h is expanded. If we delete the line #include<stdio.h> and then execute gcc -E hello.c -o hello.i, the intermediate code we get is much cleaner. The file names and line numbers allow us to clearly see where the referenced code comes from. If the reference relationship of header files is very complex (like in the glibc library), looking at the .i file is a good way to debug symbol definition problems.
Compilation
Preprocessing is separated from the compilation process because preprocessing involves accessing external files (include), and the preprocessing process cannot be described by context-free grammar, making it difficult to incorporate into the lexical and syntactic analysis process of compilation. Separating preprocessing allows the compilation stage to be more focused and the solution more elegant.
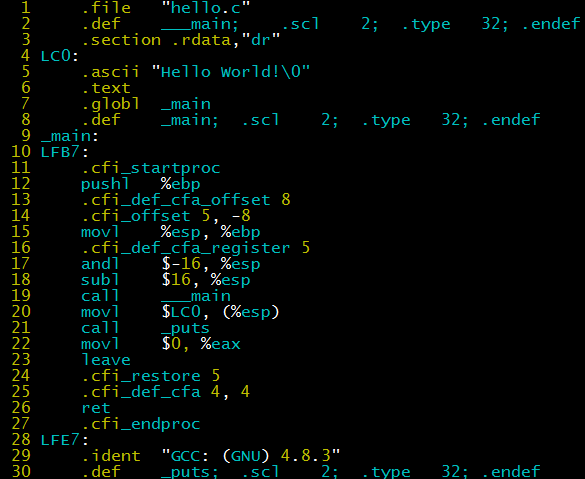
After preprocessing generates hello.i, you can use the -S parameter to compile and generate hello.s.
hello.s is assembly code, where the main tasks are:
- Line 20 moves the pointer of the LC0 string “Hello World!\0” to the memory address pointed to by %esp as the first parameter of the printf function;
- Line 21 calls the _puts function (gcc will replace printf with only one parameter with _puts to improve efficiency, you can add the -fno-builtin parameter to turn off this optimization);
- Line 22 is the return 0 in main.
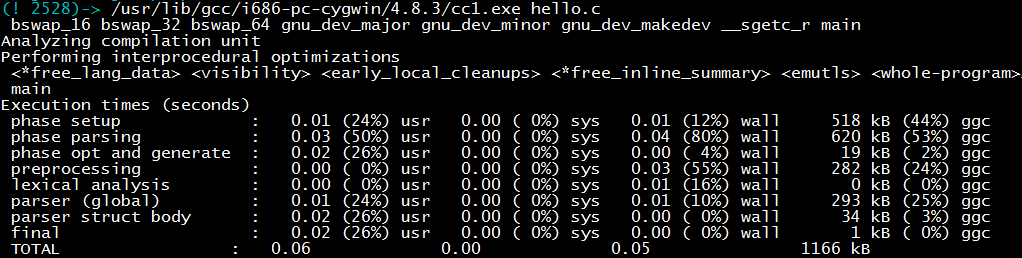
In fact, gcc -S calls the cc1 program for compilation. Directly calling the cc1 program, in addition to generating hello.s, will also print out the time consumed by cc1 compilation at each stage. We can see the preprocessing, lexical analysis, syntax analysis, assembly code generation and other stages.
The compiler is divided into front-end and back-end. The front-end includes preprocessing, lexical analysis, syntax analysis and other steps, which have been mentioned before, and its output is an abstract syntax tree; the back-end is to get assembly code based on the abstract syntax tree. The separation of front-end and back-end is a major breakthrough in the development history of compilers. Suppose there are M programming languages in the world and N different architectures. If the front-end and back-end are not separated, a compiler needs to be written for each combination of programming language and architecture, requiring M*N compilers. The intermediate language can describe the semantics of all programming languages and is close enough to machine language, so only M compiler front-ends and N compiler back-ends need to be written.
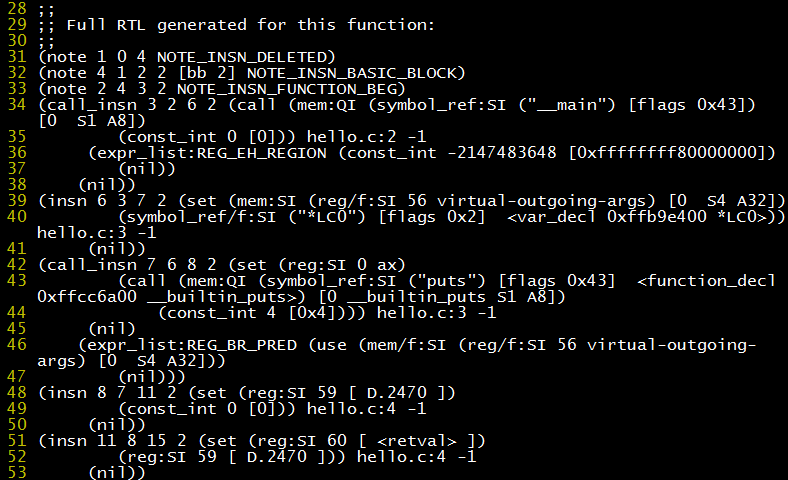
Obviously, such an intermediate language will not be simple. The intermediate language of gcc is called RTL, which looks obscure. Using gcc -S -fdump-rtl-expand hello.c can generate an intermediate language file hello.c.150r.expand (the number 150 may vary), the content is a tree structure represented in list form.
In contrast, clang’s intermediate representation is much more beautiful (at least from a human-readable perspective). clang -S -emit-llvm hello.c can generate LLVM (Low Level Virtual Machine) intermediate code hello.s (note this is not assembly code), clearly showing the definition of the main() function, the “Hello World\n” string (.str), the function call to printf and return 0.
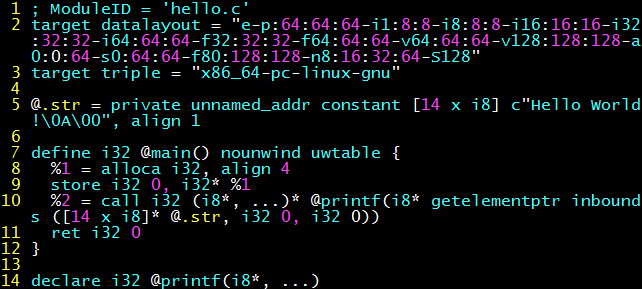
The intermediate language not only eliminates the combination explosion of “M programming languages, N architectures”, but also has important significance for compilation optimization. Many types of compilation optimizations are architecture-independent, such as constant propagation, dead code elimination. Look at the following C program, there is no input, the number of loop executions is also fixed, that is, the output sum can be pre-calculated; and unused is not output at all, that is, these assignment operations are meaningless.
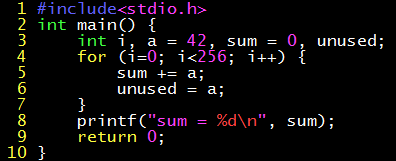
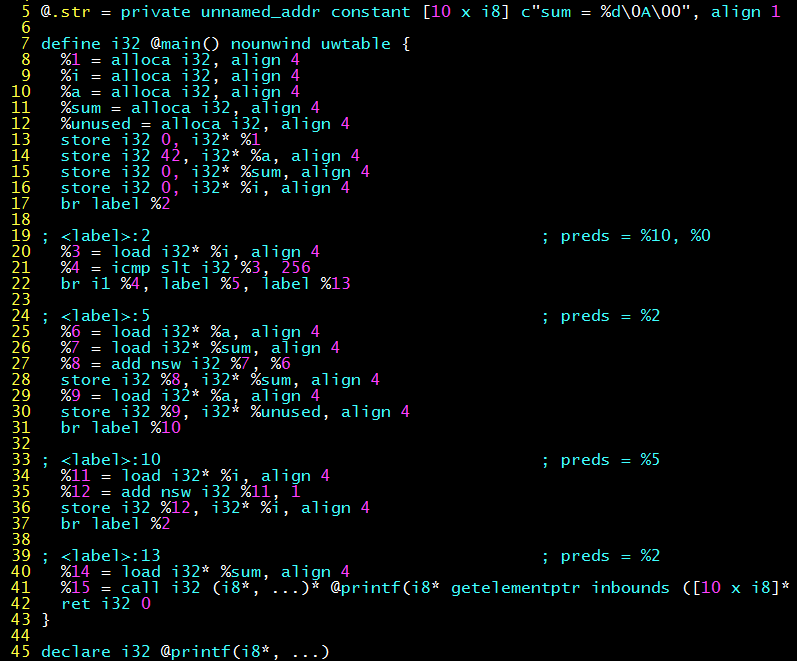
Without enabling compilation optimization, the generated LLVM intermediate code is as follows, you can see that the code faithfully performs loop, accumulation and assignment operations. (clang -O0 -S -emit-llvm hello.c)
After enabling compilation optimization (clang -O1 -S -emit-llvm hello.c), you can see that the original lengthy intermediate code is left with a printf statement, its two parameters are the string “sum = %d\n” and the parameter 10752 (=42*256).
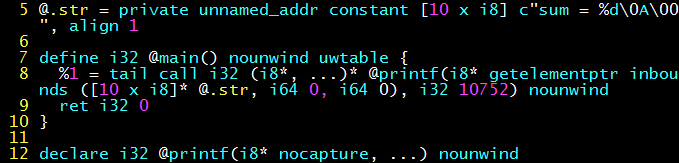
The above architecture-independent compilation optimization is completed on the intermediate code. No matter how many programming languages there are, you only need to implement the compilation optimization algorithm for one kind of intermediate code, which is the significance of the “intermediate layer” of intermediate code for compilation optimization.
Assembly
Assembly is to convert assembly code into instructions that the machine can execute. Compared to compilation, assembly is a relatively easy and happy process, because it is just a one-to-one translation according to the correspondence table of assembly instructions and machine instructions.
In the assembly process, only a small amount of information is lost, so we can have a dis-assembler. The reason why there is no decompiler is that the syntax structure information of the high-level language is lost during the compilation process, and the names of local variables are also replaced with offsets, so once the program is compiled into binary code, it cannot be restored to the source code.
 Structure of the target file generated by assembly
Structure of the target file generated by assembly
From assembly code to machine code is so simple, why should it be made a separate compilation step? This is due to historical reasons. In the era without high-level languages, programmers used assembly language, so assembly language and assembler appeared much earlier than compilers. When developing a compiler, there is naturally no need to reimplement the assembler, so the output of the compilation stage is assembly code, and the assembler completes the rest of the work.
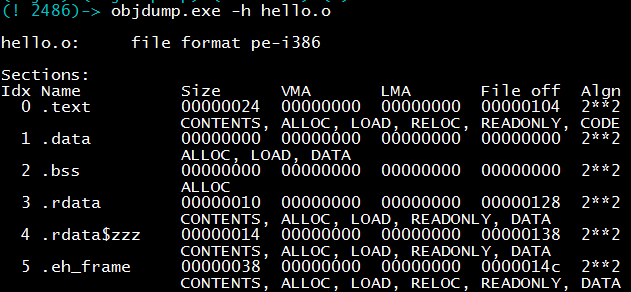
This process can be done with gcc -c hello.s -o hello.o, or you can directly call the assembler as: as hello.s -o hello.o. In fact, gcc is just a wrapper for cc1 (compiler), as (assembler), ld (linker), and the actual work is done by these tools. The following figure shows the three processes of hello.c preprocessing, compilation, and assembly.
Linking
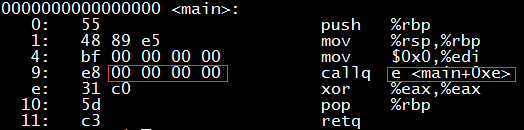
The assembly process has already produced machine code, so why do we still need linking? In fact, the unlinked target code (.o file) is not executable. If we disassemble the output of the previous assembly step (hello.o), we will be surprised to find that the place where the puts function was originally called, the jump target is actually the next instruction (as shown in the red box below)! What’s going on?
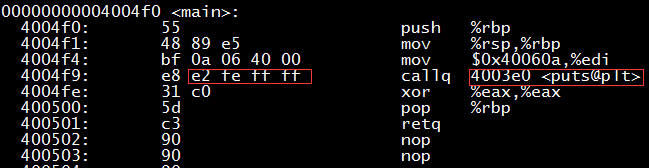
After clang -O1 hello.c -o hello generates an executable file, use objdump -d ./hello to view the disassembled code, and you will find that the addresses inside have been filled in.
What magical magic has the linker completed? How does it fix the offset of the callq jump target address in the .o file? What we saw just now with objdump -d hello.o is not all of it. There is also a relocation table hidden in the target file hello.o, which stores the names and addresses of functions and variables (collectively referred to as symbols) that it does not know.
The 0xa to 0xd bytes of hello.o should store the address of the puts function, but there is no definition of the puts function in hello.c (this function is in the glibc library, which is part of the C standard library stdio, note that the implementation of the puts function is not in stdio.h, the header file only has the function declaration), so neither the compiler nor the assembler knows where it is, and can only fill in a 0 as a placeholder. This placeholder information is recorded in the relocation table, as shown in the red box below. What the linker does is to find the puts function in the glibc library, and then replace the 4 bytes at this placeholder with the real address of the puts function.
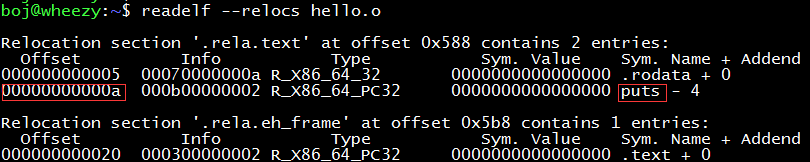
One of the main tasks of the linker is to relocate symbols between different modules. As early as when miserable programmers (it seems that there was no such profession at the time) used machine language to write programs on punched tape, they could not bear the trouble of manually modifying the jump addresses between modules, so they had symbol tables and linkers that relocated based on symbol tables. Therefore, the history of the linker is longer than that of the assembler.
 Picture source: Review of Data Storage History
Picture source: Review of Data Storage History
The nm command can conveniently view the symbols (functions, variables) in the target file, where U represents undefined.
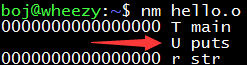
If you try nm hello this executable file, you will find that the puts function is still in an undefined state, only its name is suffixed, becoming puts@@GLIBC_2.2.5. This is because glibc is dynamically linked, that is, the code of the puts function is not put into the executable file, but is linked to the GLIBC_2.2.5 library in the file system when the hello program is running.
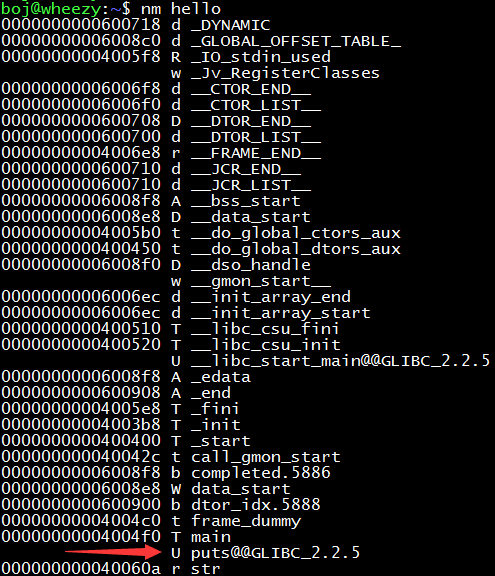
Where is the puts function? Let’s go to the libc library to find out. It’s in the ioputs.o target file.
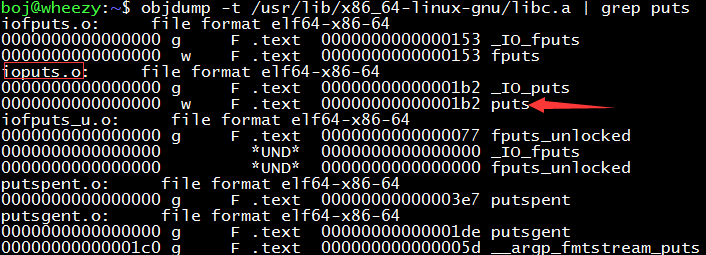
First, unzip the libc.a library (it is a compressed package composed of multiple .o files): ar -x /usr/lib/x86_64-linux-gnu/libc.a. We try to use the ld command to manually link hello.o into an executable file, but the result below pours cold water on us: there are still undefined symbols!
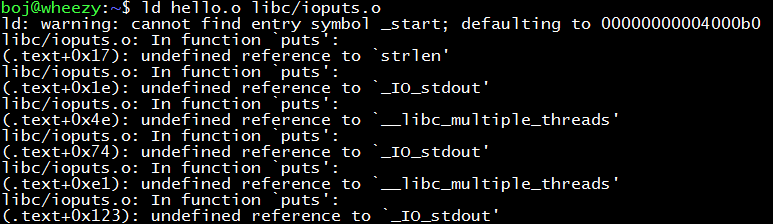
The reason here is that the ioputs.o in the libc library is not “self-sufficient”, but has many undefined symbols. One undefined symbol (puts) is eliminated, and thousands of undefined symbols emerge. Therefore, we have to go to find these undefined symbols, link the corresponding libraries, and recurse this process until all symbols are found.
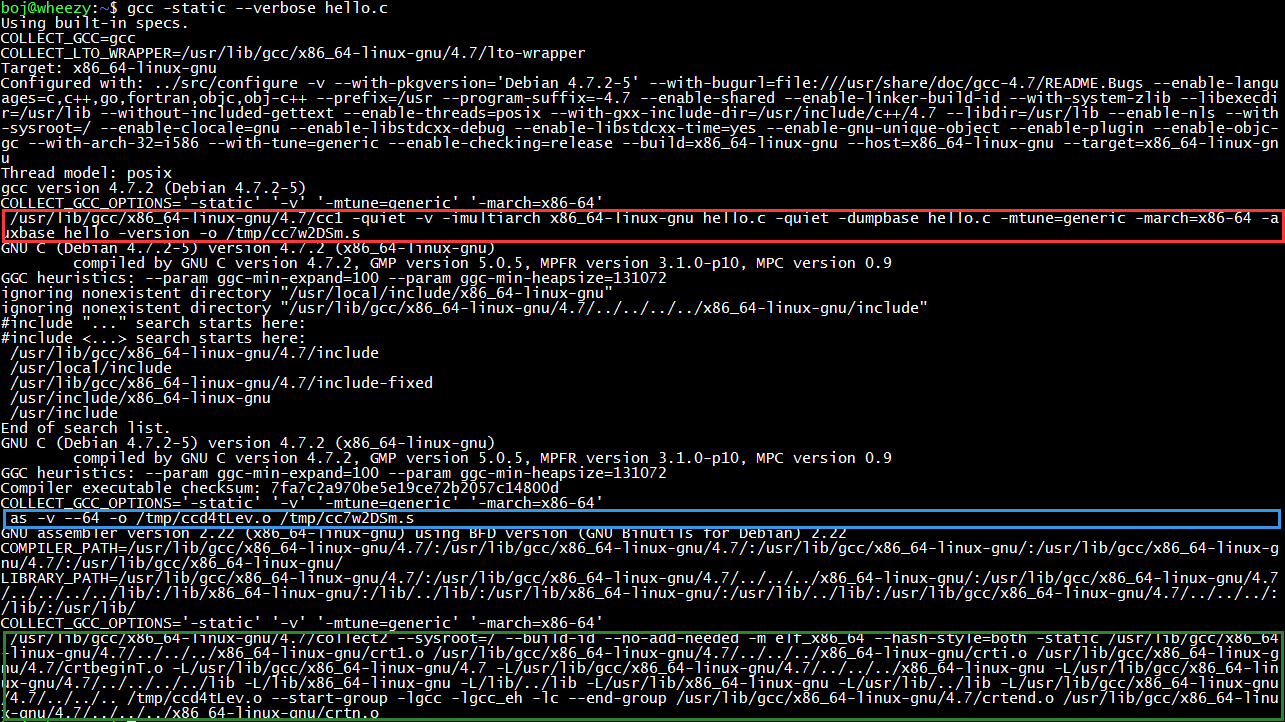
gcc can help us complete the process of finding libraries. gcc -static –verbose hello.c can output the detailed process of gcc compiling hello.c into an executable file, where the red box (cc1) is the preprocessing and compilation process, the blue box (as) is the assembly process, and the green box (collect2) is the linking process.
As you can see, to generate a statically linked (i.e., not dependent on any library) executable file, you still need to link many libraries. A small Hello World compiled executable file is 789 KB. If you do not use static linking, that is, use the default dynamic linking method, the generated executable file is only 6.7 KB.
When a dynamically linked executable file is run, the Linux kernel loader will find libc.so.6, ld-linux-x86-64.so these two files (linux-vdso.so.1 is a virtual dynamic link library that exists in the kernel) from the file system and link them. This not only reduces the overhead of disk space but also reduces memory overhead because the copies of the libc library and ld-linux library in memory are shared among different processes.

It can be seen that the libc and ld-linux libraries play an important role in the system. Apart from a few statically linked programs like ldconfig, dynamically linked programs basically depend on ld-linux (responsible for dynamic linking) and libc (standard C library).
By the way, dynamic link libraries (so in Linux and dll in Windows) are also executable files. If you don’t believe it, run ld-linux.so or libc.so (the path may vary in different systems). You can also add parameters to ld-linux.so!

*Bonus: Does the program start executing from main?
Programmers who don’t know that C programs start from main must be impostors on the street. Since it starts from main, it must end when main return 0. Now is the time to witness the miracle.
The “hook function” registered by atexit actually executed after the main function returned! This shows that there must be something outside of main wrapping it. In addition, the main function has parameters such as argc, argv, and envp. Who initialized them?
In fact, C programs start executing from the entry point in the C Run-Time (CRT). This entry point is at a specific parameter position in the executable file header. When the kernel loads the executable file, it will read this entry point address and jump to this entry point address when the process is created and returned to user mode.
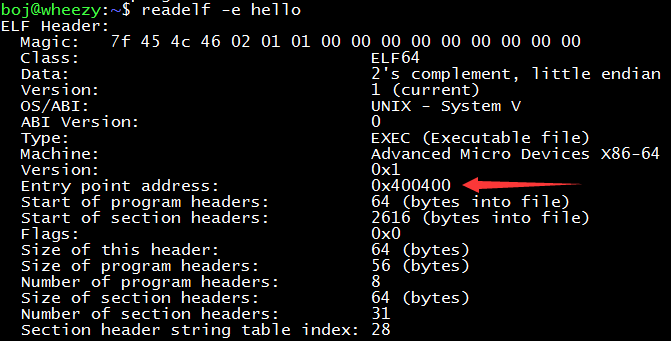
When ld performs the linking process, it will link the function named _start in glibc as the entry point. It will push argc and argv that carry user parameters and envp that carry environment variables into the stack, then initialize global variables related to the operating system version, call the system call that allocates heap space to initialize the heap, and finally call main. After main ends, it will check the hooks hung by atexit, and finally call the exit system call to exit the process.
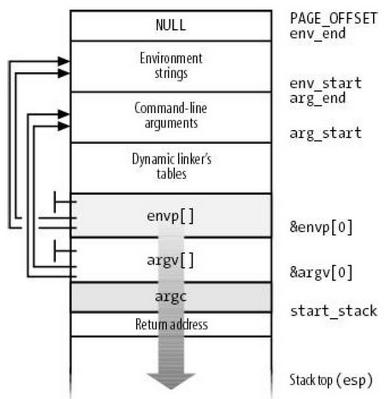
References: “Self-Cultivation of Programmers - Linking, Loading, and Libraries”