Andromeda: Google's Network Virtualization Technology
I write this article with mixed feelings, because our SIGCOMM paper, which was rushed to the New Year’s Eve, was considered “nothing new” by the reviewers because it was too similar in architecture to this lecture published on March 5 (in fact, our paper contains many technical details not mentioned in this lecture), and had to be withdrawn. How great it would be if Google published their network virtualization technology two months later!
This lecture was given by Amin Vahdat, Google’s Director of Network Technology, at the Open Networking Summit 2014 (video link), introducing the concept of Google’s network virtualization solution, codenamed Andromeda.
The Unknown Demand for Cloud
About the cloud, it is well known for on-demand computing. However, what is less known is that as the scale of the cloud expands, we need new basic models to cope with scale expansion, hardware and software failures, constantly changing network topology, and simplify network management. It is difficult for a service to achieve 99.9% availability, let alone 99.99% availability, and even Google has only a few services that can achieve 99.999% availability. High availability requires expertise in architecture, redundancy, and other areas.
For Google’s large infrastructure, storage, load balancing, DoS attack defense, etc., it is impossible to purchase third-party services, and can only rely on self-development, which of course requires a lot of expertise. From 1G to 10G to 40G to 100G networks, from hard disk to SSD to memory storage, it is not that the use of new hardware can automatically become faster, to make these new hardware play a role, it requires a lot of work by professionals. Google’s key experience is to turn this expertise into internal services and share it within the company.
Andromeda: Network System as a Service
Andromeda network virtualization is a necessary component of the Google Cloud Platform. Software-defined control is required from hardware to software, including quality of service, latency, and fault tolerance. This kind of virtualized SDN is rarely studied before.
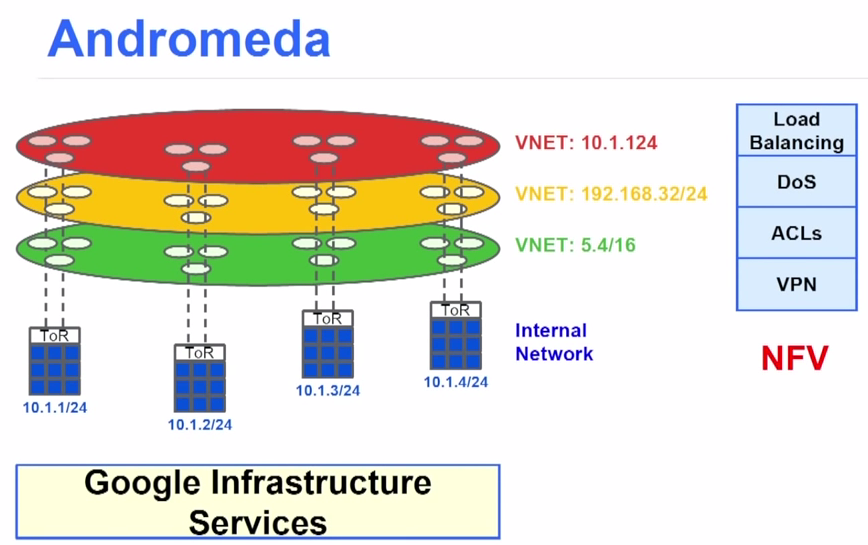
As shown in the figure above, the three colors are three customers, each with a virtual network. The bottom layer is Google’s infrastructure services (such as storage, load balancing, DoS defense) provided to each customer, and network virtualization needs to provide each customer with virtual load balancing, DoS defense, access control list (ACL), virtual private network (VPN) and other services (Network Function Virtualization, NFV).
Google plans to invest $2.9 billion globally to build new data centers. In Google’s large data centers, energy consumption can be two to three times less than in small data centers, but even so, the cost of energy consumption over the 2-5 year life cycle of the hardware is still greater than the cost of the hardware itself.

In order to reduce the few milliseconds of latency between users and Google, Google has built a large-scale CDN network worldwide (as shown below). Google has also built the world’s first large-scale deployment of SDN wide area network (published in SIGCOMM’13).
Google is also a pioneer in software innovation in big data processing (as shown below).
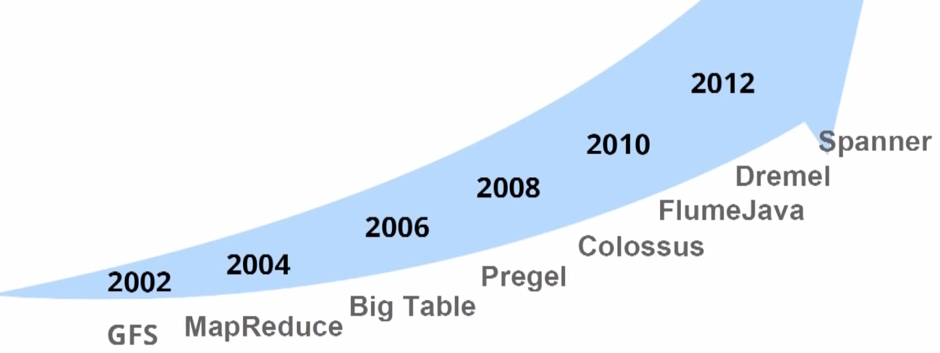
Google needs to turn these large-scale systems in networking and software into internal services and provide them to other services within the company. Large-scale distributed systems including GFS, MapReduce, BigTable, Spanner, B4 SDN all follow two points of experience (of course, Andromeda is no exception):
- A logically centralized or hierarchical control layer and a P2P data layer are better than a fully distributed system.
- Horizontal scalability (adding machines) is better than vertical scalability (using better hardware).
Balancing Computing, I/O, and Network
Now the computing power of virtual machines is getting stronger and stronger, and the bandwidth and latency of storage are getting lower and lower (as shown below). Amdahl proposed a not well-known law in the late 1960s: in parallel computing, every 1MHz of computing requires 1Mbps of I/O. Due to the slowness of random access of mechanical hard drives, this law is difficult to implement and has gradually been forgotten. Modern Flash storage makes it possible, but in the cloud, virtual machines and storage are not deployed on the same physical machine, at this time the bandwidth and latency of the network will become a bottleneck. The goal of Andromeda is to build a system that balances computing, I/O, and network, rather than always waiting for another resource.
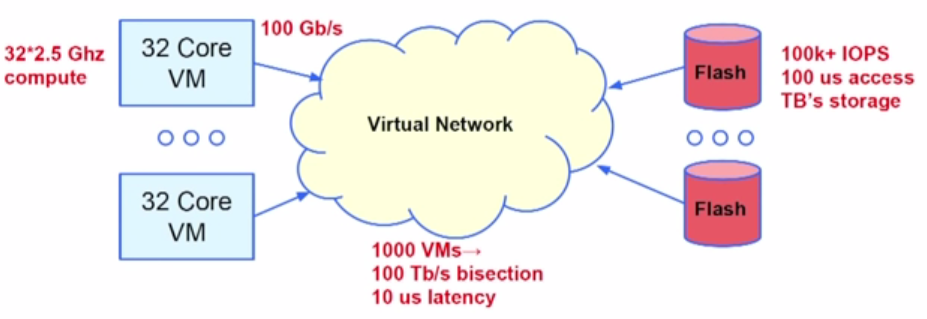
If we imagine the above 1000 virtual machines connected to a virtual switch (a common Clos model in data centers), it is equivalent to building a virtual network with 1000 ports. How to build this high-bandwidth, low-latency virtual network, while ensuring isolation between virtual networks, providing load balancing, external access, virtual machine migration, high availability of storage, and other functions?
The simplest definition of Software Defined Networking (SDN) is to distinguish between the control layer and the data layer, allowing the control layer and the data layer to evolve separately. The control layer needs to run on ordinary servers without the need for special hardware. Andromeda needs to use network cards, software switches, storage, packet processors, hardware switches, and other network components to achieve isolated, high-performance virtual networks, to achieve end-to-end service quality and availability.
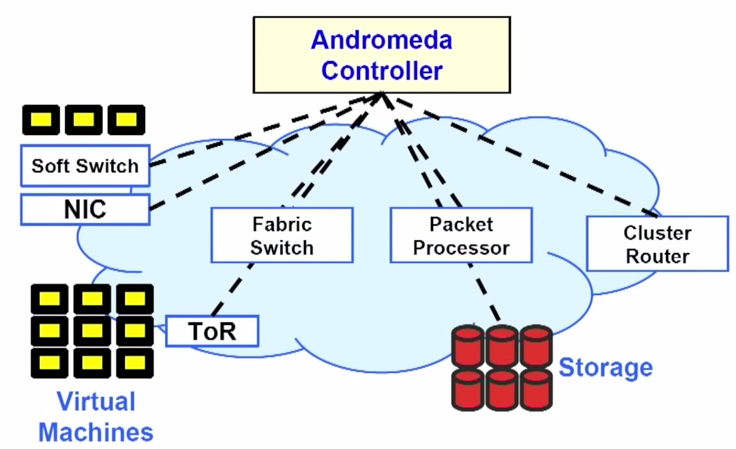
The opportunities and challenges brought by software-defined virtual networks are logically centralized network management, there can be no machine-to-machine communication protocols that are not centrally controlled, and no exceptions can be made for network components with “special effects”. Network middleware includes load balancing, access control, firewalls, NAT, DoS defense, etc., some are stateful, some are stateless; some are software implemented, some are specialized hardware, these specialized hardware are sometimes difficult to integrate into a unified global model. Andromeda needs to divide the virtual functions of the network between software switches and hardware packet processors.
Example 1: Chain of Network Middleware
Imagine we need the network functions shown in the figure below, a packet coming out of a virtual machine first goes through a firewall, then rate limiting, then accounting, then routing, and finally leaves from the physical network card.

If we start several processes in the host, each responsible for these functions, it may not be a problem for a few hundred Mbps of traffic. But if near line speed or even line speed performance is required, considering latency, the above data path needs to be organized in a pipeline manner, if one pipeline is not enough, it needs to be split into several parallel pipelines, each pipeline bearing a certain load.
We also need to consider locality and traffic characteristics, fully utilize the characteristics of network components with the same function, for example, hardware firewalls have high performance but small rule capacity, software firewalls are slower but the rule capacity is almost infinite, we can “cache” hotspot rules in hardware firewalls, and most of the relatively “cold” rules are placed in software firewalls.
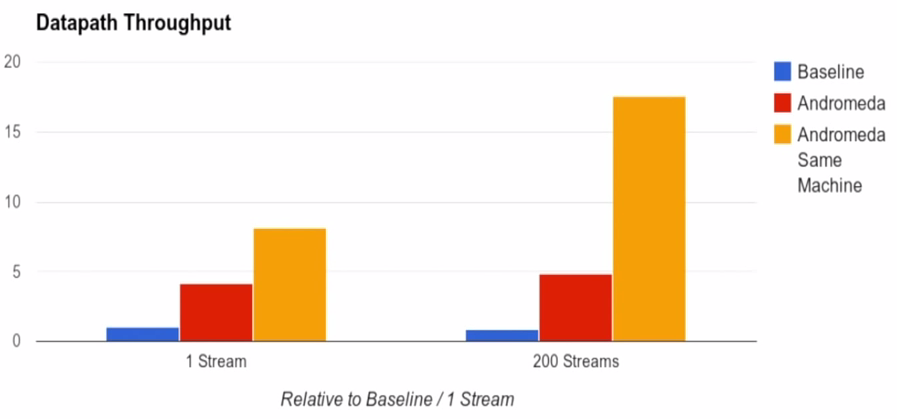
According to Google’s tests, Andromeda’s performance is quite good. The benchmark test is on the same physical machine using a traditional all-software, unoptimized network virtualization solution; Andromeda refers to a simulated actual deployment environment, where network middleware and virtual machines are not necessarily on the same physical machine; Andromeda Same Machine is compared with the benchmark test, assuming that all network middleware is deployed on the physical machine where virtualization is located.
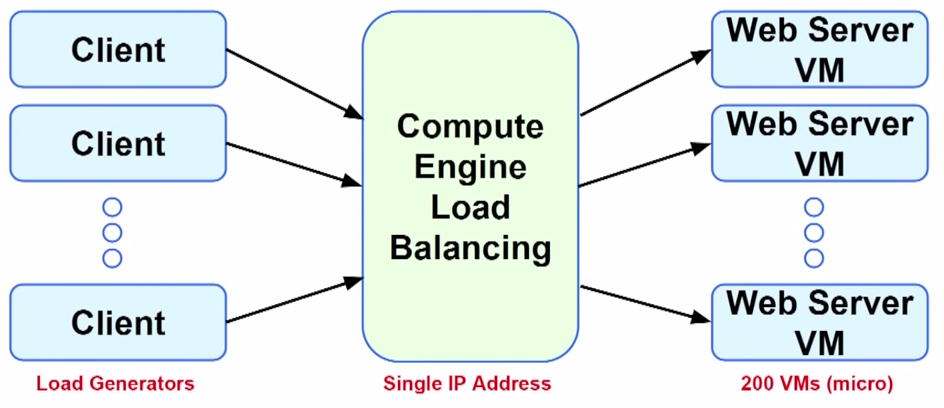
Example 2: Load Balancing
Google has built a cheap and efficient load balancing system. The testbed shown in the figure below generated 1M QPS (query per second) requests, Google’s load balancing system prepared the required network resources (such as setting up virtual machines for middleware) in just 5 minutes, switched these traffic over in 4 seconds, and stabilized the load of each network component after 120 seconds. The entire process cost only 10 dollars.
Summary
Andromeda leverages Google’s more than 10 years of experience in achieving high performance on shared computing platforms, using logically centralized Software Defined Networking (SDN) to control various network components, achieving end-to-end functionality, Quality of Service (QoS), and high availability on virtual networks, with almost no performance loss while providing isolation.
Regrettably, this presentation was mainly conceptual and did not reveal many technical details, we look forward to Google revealing more details about Andromeda.