Several Techniques for Writing High-Performance Software
With the improvement of computer processing capabilities and the increasing complexity of software, performance is often not the most important criterion for measuring software. But sometimes we do need to squeeze the performance of the computer. Especially when doing research, in order to make the performance indicators surpass the opponent, not only the algorithm (asymptotic complexity) needs to be optimized, but also the implementation (the constant in the complexity) needs to be optimized. This article tries to summarize some rules and hopes to discuss with everyone:
Do not use open source software
Open source software often considers a general problem, so there are many configuration parameters and conditional judgments that are almost never used; open source software often requires code readability and maintainability higher than performance, so it generally does not use so-called “tricks”.
For example, the de facto standard DNS server bind9 of Linux can only reach about 50k queries per second per core. I haven’t seen the source code of bind9, so I don’t know where the bottleneck is. But the authoritative DNS server I wrote casually in the NDIS filter driver (network filter driver), which does not support wildcard domains and only supports A records, can support 500k queries per second per core.
The algorithm is very simple, put the DNS records into a hash table pre-allocated in the non-paged memory area according to the hash value of the domain name, use linear probing to solve conflicts, and the occupancy rate of the hash table is 1/2; extract the domain name part from each DNS query, query the hash table, and directly return the corresponding record.
When the hash does not conflict, each DNS query actually only needs to access the memory twice, once to find the index of the domain name in the hash table, and once to take out the actual content of the record. The rest are some overheads for string processing and memory copying in the CPU cache. Even with the support of other types of records, the performance should not drop significantly.
Believe me, most requirements are not that complicated, especially demos. The time spent implementing a minimum system that just meets the requirements is far less than the time spent optimizing the vast open source software code.
Use C/C++
Use C/C++, do not use interpreted languages, do not use languages with garbage collection, and JIT (translating intermediate code into machine code) is not good either. No one wants their hard-designed algorithm to be beaten by a bad algorithm written in C++ just because Java was used.
Node.js, which uses the Google V8 engine, claims to be the fastest scripting language in the world. I once wrote a program in Node.js to parse Whois data and store the parsed data in mongodb. As a result, this whois parsing program became the bottleneck, and the CPU usage of mongodb was only 20%~30%. Later, I switched to C language and the most traditional string processing (somewhat like the parser of programming language), and mongodb successfully became the bottleneck. Of course, maybe my Node.js skills are not enough, and the efficiency of the regular expressions I wrote is too low, but at least this time C language solved the performance problem.
Use arrays, do not frequently dynamically allocate memory
When studying OI, in order to program quickly and reduce errors, the teacher asked us to use static arrays, and “pointers” are array indexes. After going to university and seeing professional programs all dynamically allocating memory, I began to laugh at my “stupidity” of using static arrays. Now I find that static arrays are really the key to high performance. It has at least two advantages:
- No need to frequently dynamically allocate memory. Because the memory allocation algorithm in the standard library is relatively complex and the overhead is relatively large. If you are not careful, the CPU time used to allocate memory may be more than all other business logic combined.
- “Pointer” is an array index, only needs 4 bytes (the array generally does not exceed 4G), and the real pointer needs 8 bytes on a 64-bit system.
In actual programs, the input range is not as upper-bounded as OI, so static memory allocation is impossible. But we can allocate a large chunk of memory at once based on the scale of the input data during program initialization or data preprocessing, and use it as an array. The so-called “memory pool” is essentially a large array, which can compactly store a large number of identical data structures.
Another corollary of not frequently dynamically allocating memory is not to use C++’s new and delete in performance-critical places, because they need to dynamically allocate and release memory in the heap. You can use array of struct instead.
Use mmap I/O to access files
The most primitive way to read a file is to fread one byte at a time. Soon you will find that fread has become the bottleneck of the entire program. Experienced people will tell you to use file buffers and read in a block (such as 4KB) at a time. However, when doing string processing, if the block reaches the end and the string has not ended, you have to read in another block of file content, and logically concatenate the two buffers. If the boundary conditions are not handled well, bugs will come.
In fact, the CPU’s paged memory mechanism and the operating system have long prepared a solution for us—mmap I/O. It can map a file to a logically continuous memory area. Accessing the offset position in this memory area is equivalent to accessing the offset byte of this file. It’s as if the entire file has been loaded into a continuous memory. When reading a memory location that has not yet been loaded into memory, it will trigger a page fault, the operating system will read the content on the disk into memory, and then let the program resume execution, all of which are transparent to the program. mmap I/O can also reduce the copying of data between user mode and kernel mode (fread needs to copy the read data from kernel mode to user mode).
Setting CPU Affinity
After creating a thread with pthread_create, you can use pthread_setaffinity_np to set CPU affinity, i.e., which CPU this thread runs on. If we have 8 cores and start 8 computing threads, we obviously don’t want the 8 threads to squeeze onto one of the cores.
A more subtle problem occurs on CPUs with Hyper Threading enabled. This Intel technology allows a physical core to be used as two logical cores. They share the same set of computing components, and the instruction sequences on the two cores are executed alternately (when instruction sequence A is waiting for memory, instruction sequence B can execute). If we have 8 physical cores, 16 logical cores, and start 8 computing threads arranged on CPUs 0~7, they may run on 4 physical cores, while the other 4 physical cores are still idle. You can check /proc/cpuinfo to get the correspondence between logical cores and physical cores, and then distribute the computing threads on different physical cores as much as possible.
Use Atomic Instructions Instead of Locks
When encountering multi-thread competition, the first thing we think of is locks. But the overhead of locks is often quite large. If you use a mutex and need to wait, you need to suspend the thread and switch contexts. In fact, many counter-like applications can be implemented with CPU atomic increment/decrement, exchange, and bitwise operation instructions. In gcc, these instructions start with __sync (link), and in the Win32 API, these instructions start with Interlocked (link).
Avoid False Sharing
We all know that CPU non-aligned access requires two bus accesses, which is very inefficient, so compilers know to align integers by 4 bytes. But in multi-core multi-thread processing, there is another alignment in units of 64 bytes. In the Intel processor I use, the CPU cache is in units of 64-byte lines (cache line). If any byte in it misses the cache, the whole line needs to be read from memory; if any byte is written into, it needs to notify other processors to clear this line of the same address from the cache (cache invalidation).
If we have a 16-thread compute-intensive program, each thread i = 0..15 uses a 4-byte global variable ThreadGlobal[i], then when each thread writes into the global variable, the global variable cache of other processors needs to be invalidated. Originally, the global variables of each thread did not affect each other and could be cached separately, but the design of the CPU cache line destroyed the cache, which is false sharing.
The method to avoid false sharing is simple: align each thread’s private global variable by 64 bytes (or the cache line width on the processor architecture). Unfortunately, the compiler cannot do this automatically, and needs to encapsulate the thread global variables in a structure and add padding yourself. For example
1 | struct ThreadGlobal { |
Network Card Interrupts Are Not Free Lunch
On a 1Gbps network card, even 64-byte small packets can be received at line-rate without any pressure. But on higher-speed (such as 10Gbps) networks, line-rate reception of small packets is basically impossible. When encountering a bottleneck, you need to observe the system’s kernel time. If the kernel time takes up most of the time, it is not a problem with the user-mode process (such as a socket program), but the interrupt handling is not keeping up.
The network card and the network card small port driver distribute the interrupts to one of several CPUs according to the hash value of the packet header. If these CPUs can’t handle the interrupts (it may not be that they can’t handle the top half of the interrupt, but they can’t handle the bottom half or the DPC queue), it may cause the system to crash.
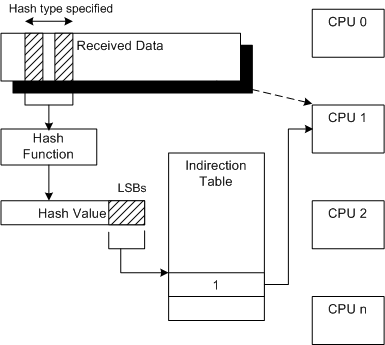
Some experiences:
- Use Receive Side Scaling (RSS) to distribute interrupts to more CPUs.
- When testing packet sending, at least one parameter in the source IP, destination IP, source port, and destination port should be random or round robin, otherwise the packets sent will always be hashed to one CPU for processing.
- Turn off the firewall. If there are many rules, it takes a lot of computing overhead for packets to pass through the firewall.
- When setting the affinity of computing threads, avoid CPUs that are busy handling network card interrupts.