A Slash Triggers a Bloodbath
Note: For those who are not familiar with mirrors, please read “How USTC Open Source Software Mirror is Made“ first.
Trouble Starts with iSCSI
The story begins on June 26, 2013. Mirrors has a disk array directly connected by a network cable, using the iSCSI protocol, with an XFS file system on it. Around 14:00 on June 26, stephen reported in the mailing list that mirrors was down. According to syslog, at 13:58 on June 26, the iSCSI connection timed out, causing sdg access failure, a large number of I/O operations were stuck, causing nginx to be stuck, mirrors HTTP could not connect. A few minutes later, I/O timed out, nginx returned to normal, but the sources on the disk array could not be used.
This was the second time. On June 1, mirrors had the same iSCSI connection timeout (internal page), leading to the same consequences. Because we had no experience at that time, the service was interrupted for 4 hours. At that time, both tux and I pointed the problem to the XFS file system on the disk array, so we tried to use xfs_repair to fix it, but there was no result, and finally umount, mount was fine. In fact, the problem was with iSCSI (specific reason unknown), and it may have nothing to do with XFS. This failure took 2 hours to repair.
The good times didn’t last long. At 10:30 on June 27, mirrors had the same problem again, and the service was down again. I used the same old trick, and the problem was solved in half an hour. The reason it took so long was always because I couldn’t find the process occupying the mount point. It turned out that the root partition of the mirror-lab LXC virtual machine was on the disk array, and it could be umounted after lxc-stop.
“Bloodbath” Scene
Frequent failures prompted us to move the root partition of LXC out of the disk array. The slash triggered a bloodbath.
Around 16:00 on April 27, mirrors could not SSH, but HTTP service was normal, rsync, FTP service was down. The reason was that /lib disappeared, /lib/ld-linux.so also disappeared, all programs that need dynamic linking, including programs using glibc, could not run. HTTP requests do not need to open a new process, so they can work normally; rsync, FTP each connection needs to open a new process, so they can’t be used.
According to /var/auth.log and my memory, the process of the failure was like this:
- Because mirror-lab is in sdg, and sdg is unstable, I wanted to move it out.
- cp -R /path/to/mirror-lab-root/ /path/to/new-mirror-lab-root/
- Start LXC, find that the directory permissions and owner are not correct, so I want to use rsync to correct it.
- In pwd=/, rsync -aP /path/to/mirror-lab-root/ . was executed in screen, then logout. This operation caused the root directory to be overwritten.
- After a while, I found that it hadn’t been synchronized in another open session, screen -r, found that rsync hadn’t ended, I thought why it was so slow, then Ctrl+C, cd to the home directory, rsync -aP /path/to/mirror-lab-root/ .
- Immediately found that the synchronization target was written incorrectly, rm a long string in pwd=/home/boj, including lib/
- Found that ls couldn’t be done, then logout, found that I couldn’t login again.
Why did I make two major mistakes of overwriting the root directory and deleting lib at that time? I think it’s because I was busy writing other programs at that time, I was absent-minded, and I didn’t think about it when I typed the command. The first two steps were done when I was relatively free, but the later rsync was done in a hurry.
We can learn several lessons from the above operation process:
- When using relative paths, be sure to pay attention to pwd (I hardly use pwd=/, I know it’s dangerous, but it did happen)
- In step 5, when you find that the synchronization is not complete, you should check the command you entered last time, instead of rewriting it directly.
- Don’t use rm xxx/, use rm xxx, to avoid following symlinks.
- When you can’t use ls, don’t rush to logout, but use the built-in bash command to check what the problem is. If you didn’t logout at that time, you might still have a chance to fix it.
Better Late Than Never
At that time, only Stephen had a login session, and only some bash built-in commands were available. Since LXC was not damaged, LXC could still log in and operate normally. However, we couldn’t find any vulnerabilities in LXC to jump into the host. Through the bind mount’s /srv/array as a springboard, statically linked programs from the outside world can be sent into mirrors and run.
Tux made a statically linked busybox, but Stephen said it couldn’t be used. Later, Tux copied the /lib directory from another Debian squeeze stable x86-64 machine to mirrors, and Stephen copied them over. At this point, the SSH connection was immediately disconnected (reason unknown). Rsync and FTP services were restored to normal, indicating that the copied /lib was effective. But SSH still couldn’t get in (reason unknown). It seems that we have to go to the machine room.
At 00:49 on the 28th, we issued a mirrors maintenance announcement. Since it was close to the final exam at that time, Tux and I vetoed the complicated virtualization plan that might take a day, and planned to fight quickly (at that time I didn’t know that I had done the silly thing of rsync covering the root directory, I just thought /lib was hung):
- Restart the machine, enter the USB live system
- Use dpkg to check the situation of missing files, and copy the missing files in
- Restart the machine to see if it is normal
Considering that the mirrors with severely damaged system files may need to be reinstalled, Stephen suggested that we adopt the emergency plan of switching DNS to the backup site. I wrote a script to find out the source list of several major domestic open source software mirrors, and after manually processing the sources with different names, randomly assigned the existing sources to these mirror sites. The maintenance announcement was posted on the homepage of the backup site. At 3 o’clock in the morning, backup.mirrors.ustc.edu.cn was set up and tested on the lug.ustc.edu.cn server. The TTL of the DNS record for the mirrors series domain name was also changed to 120 seconds for quick DNS changes to take effect.
Going to the Machine Room
At 10 o’clock on June 28th, we came to the network center machine room to start repairing mirrors. First, we modified the DNS record, making the mirrors series domain name CNAME to backup.mirrors.ustc.edu.cn. A minute or two later, most of the sources were redirected to other domestic open source software mirrors via HTTP, and a rapidly scrolling access log was seen on the lug.ustc.edu.cn server.
After familiarizing ourselves with the hardware environment of mirrors and confirming the problem, Tux used the Debian boot USB made the night before to boot mirrors. It was quickly discovered that the problem was not that simple, because both /home and /etc/passwd were overwritten. In that case, the system had to be reinstalled.
Tux and I had already discussed the detailed LXC virtualization plan the night before, but we didn’t plan to implement it immediately. But when we got to the machine room, Tux wanted to get the virtualization done, and I didn’t object. He also wanted to add a layer of Xen underneath, so that if the host had a problem, it could be solved without going to the machine room, and I didn’t object to this either. It seems that I bear a major “leadership responsibility”.
Around 12 o’clock, I saw no intention to end, so I called pudh and bible to watch the battle. Zguangyu had already gone home, so he didn’t come. We struggled together until 19 o’clock, ensuring that mirrors-main would not hang (this is just wishful thinking), before we “reluctantly” left the machine room.

“Vase” Architecture
The virtualization architecture designed at that time sounds wonderful, but it is difficult to implement in practice.
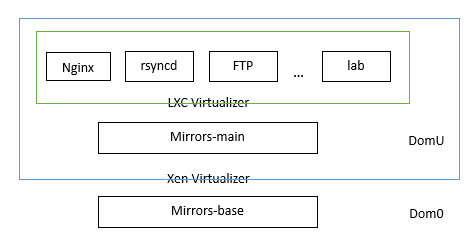
Tux’s design (wa) ability (keng) is indeed strong, creating two layers of virtualization, as shown in the figure above. The underlying virtualization is Xen, Dom0 is mirrors-base, and a dedicated IP (202.38.95.106) was requested from jameszhang. It can only be accessed via SSH from a few restricted IPs and is strictly prohibited from being used except for recovery purposes. Dom0 has several local disks mounted, all of which are mapped to Xen’s domU except for the one used for the root partition. There is only one domU, which is mirrors-main. It binds the four public IPs of the three mirrors lines and connects to iscsi through eth1 to mount the disk array.
The second layer of virtualization is a few LXC containers opened on mirrors-main, used for nginx, ftpd, rsyncd, rsync and lftp synchronization, static page generation, mirror-lab, and ftp-push (writable ftp).
It sounds wonderful, but… when installing Xen, in order for mirrors-base to access the file system of mirrors-main (for repair), the root partition was not created with the official Xen tool, but was manually debootstraped on the LVM volume. The root file system of DomU is NFS mounted on Dom0. There are some undocumented things in the configuration file, so tux started to flip through the python source code of xen-tools, and finally NFS started successfully… There are several configurations that refer to the Xen configuration file that was previously set up in Shao Yuan.
LXC is not an easy master to serve, the directly established LXC cannot be started. It is necessary to modify the configuration file bind mount, create tty device files, etc. I managed the configuration scripts of mirrors-main with a git library: http://gitlab.lug.ustc.edu.cn/mirrors/mirrors-main/tree/master (registration required) This can be considered a legacy left by the incomplete mirrors rebuild. If you want to use these scripts, please be sure to distinguish whether they are running in the host or in the LXC virtual machine.
Tinkering with LXC Network
After tinkering with Xen, the network of LXC is a bigger problem. If you don’t want to put any useful services on mirrors-main, you need to map nginx, ftp, and rsync to different ports in LXC.
A total of four schemes were tested:
- Let LXC and the host share the same IP, and use ip rule and fwmark for forwarding.
- Use DNAT for port mapping.
- Use IPVS (Linux Virtual Server) for routing.
- Do not isolate the network namespace.
Shared IP?
The first idea was to let LXC and the host share the same IP, so ip rule and fwmark were used. This is not so simple, because the root partition of mirrors-main is NFS mounted, and if NFS is disconnected, it’s not a fun thing… Therefore, we had to adjust the order of the local rules (the following rules have been simplified).
1 | // rc.local in mirrors-main |
Tinkering with these rules was not smooth sailing. On June 29, the day after the mirrors were rebuilt, I hung up the NFS of mirrors-main and went to mirrors-base for repairs. I forgot why, but the SSH of mirrors-base was disconnected. (It was not due to the classic sudo networking restart, we were operating in byobu all the time.) It was Saturday at the time, and the duty teacher in the network center computer room was not there. I called jameszhang, and he volunteered to run from the University of Science and Technology Garden to the network center. We really felt sorry.
Is this OK? LXC can receive inbound packets, but outbound reply packets are missing. It can be matched in the PREROUTING chain, but it cannot be found in INPUT, POSTROUTING, and FORWARD. We guessed that the kernel’s routing logic found that the source IP of the FORWARD packet was the same as an IP of the target network card and dropped the packet. We did an experiment with another machine and found that Linux indeed will not forward packets with the same source IP and target network card IP. We wanted to use ebtables at the time, but we didn’t come up with a solution after studying its structure.
In the end, to solve the problem of iptables forwarding local addresses being “eaten” by the kernel, only one line is needed:
net.ipv4.conf.<interface>.
At that time, I flipped through the kernel source code and located the place where the “illegal” packets were “eaten”. Related commit:
http://git.kernel.org/cgit/
However, there is no corresponding option for IPv6, and we couldn’t figure it out.
DNAT?
DNAT port mapping is simple, but it can’t handle ipv6. The kernel’s ipv6 NAT was not available until 3.7, and we don’t want to use a too new kernel.
IPVS?
The next experiment was ipvs (Linux Virtual Server) NAT mode, which claimed to support ipv6, and indeed it was convenient to operate. However, ipv6 really couldn’t work, and I didn’t know why.
We also tried to bridge all the network cards of the virtual machines and the host, using the direct routing mode of ipvs. We guess there was some misconfiguration somewhere, and it still couldn’t work as expected.
Don’t isolate network namespaces!
After two days of tinkering, tux made a tough decision: not to isolate network namespaces.
However, this configuration also brings greater risks: executing init 0 in LXC will run the shutdown script, stop the network device, and then the network of mirrors-main will stop running! That is to say, only lxc-stop can be used to shut down the virtual machine, and shutdown in the virtual machine is very dangerous.
Performance issues
Disk
At about 8 o’clock on June 30, HTTP access was initially restored (without IPv6), so we switched the DNS back.
Just 20 minutes after the DNS was switched back, we found the response was very slow, the CPU was almost 100% wait, so we switched back to backup.mirrors at about 9 o’clock. Went back to sleep.
The reason was figured out that day, it was caused by Xen’s disk virtualization layer. Originally, LVM was mounted on Xen Dom0, and then the LVM partition was mapped to DomU (mirrors-main). tux changed it to directly map the physical hard disk (/dev/sdx) into DomU, and then mount LVM on DomU, and the problem was solved.
Network
At 6 o’clock on July 2, the mirrors HTTP service was restored, an announcement was posted on the homepage, the DNS was switched back, and a recovery announcement was released to the USTC LUG and Tsinghua TUNA mailing lists.
After observing for half an hour without any problems, I went back to sleep. In fact, because it was still early in the morning, the traffic was very small, and the I/O performance problem had not yet shown its hideous face. All day, we didn’t look at mirrors, nor did we restore the collectd monitoring service, so we knew nothing about the server’s operating status.
At about 19 o’clock, the anthon community reported the slow access problem of mirrors. We only then discovered that the homepage could hardly be opened, and mirrors was almost unusable all day.
At about 20 o’clock, the reason for the slow access to mirrors was found out. iscsi is in Xen’s domU, I don’t know what the network virtualization layer of Xen has done, anyway, the disk array of iscsi mounted XFS only has a few hundred K, and the I/O util is already 100%. Nginx will be stuck when I/O is slow, so the HTTP request speed on the local disk is also affected. I umounted the disk array, and the local disk access was immediately normal.
At about 24 o’clock in the evening, tux solved this performance problem. Mount iscsi in Xen’s dom0, and then directly map it into domU, it’s okay. It is inferred that it is caused by Xen’s network virtualization layer.
Impact of the failure
During the 92 hours from 10 o’clock on June 28 to 6 o’clock on July 2, 10.6 million HTTP requests from 128,000 IPs were redirected to other sources, and 1.61 million HTTP requests from 11,000 IPs could not be completed normally because there was no redirection set, that is to say, 94.5% of HTTP requests were redirected to other sources. Whether users can use it normally depends on the availability of the source they are redirected to. For example, for about two hours at noon on June 28, because the bjtu source also happened to be down, 40% of users could not use the debian source (at that time, a 2:4:4 load balance was done between tuna, bjtu, and sjtu).
From 9 o’clock in the morning to 20 o’clock in the evening on July 2, due to the performance problems mentioned above, mirrors was basically completely paralyzed, it took a long time to open the homepage, and the download speed within the school was only a dozen K. Compared with the redirection to other sources in the previous few days, this is the most serious impact of this failure event.
We deeply apologize for this large-scale failure that affected hundreds of thousands of server and PC users.
Conclusion
This large-scale failure of mirrors has two reasons: one is my “one slash” misoperation, and the other is the tinkering during the repair process.
Accidentally deleted /lib
Directly quote Zhang Cheng’s comment:
Emergencies always happen. For example, I have encountered some emergencies in the company, due to attacks, program bugs or other reasons, causing some key servers to crash. At this time, people with less experience are easily panicked and don’t know what to do (because they only know that it’s down, but they don’t know where the problem is, and it’s difficult to locate the problem). When I encounter such a situation, I will deliberately tell myself to calm down, think carefully, and not to draw conclusions easily. Panic does not help to solve the problem, calm thinking is the right way. For example, one night our db server crashed, due to NFS, several other machines’ nginx responded very slowly. But everyone has no prior experience and doesn’t know that nfs can cause nginx to hang, so they can’t think of the problem of nfs failure at all. Everyone just knows that nginx responds very slowly, but looking at the various indicators of the system (cpu, memory, bandwidth, io, etc.) are very normal, so someone proposed to restart the machine. I refused to restart at the time, because I did not find the root cause of the problem, and even had no clues. Blind restart may not solve the problem, and may even destroy the scene, making this problem never found. Later, I accidentally saw the shadow of nfs in /proc/$nginx-pid/stack, and finally located the problem of nfs based on this clue.
Everyone who maintains mirrors will inevitably encounter various emergencies. The experience of maintaining servers over the years has made my character more and more “slow”, more and more “decisive”, and able to stay calm and make decisive decisions under various emergencies (not necessarily operating servers). This is also one of my biggest gains.
The experience of maintaining servers has also made me develop many conditioned reflexes. For example, before I execute any potentially harmful command, I will pause for 1 second before hitting enter. I also leave a backup way out for myself before executing many commands. For example, I saw a person make a mistake when typing the crontab command, and typed crontab -<some word>, the word contains the letter ‘r’, causing the crontab to be cleared, so later I will subconsciously execute crontab -l first every time I execute the crontab command, so even if I make a mistake later, I still have a chance to find out the previous content to recover; at the same time, when I deploy crontab tasks online, I also try to avoid using the crontab command directly, but write files to /etc/cron.d/ to prevent this kind of error.
===== End of quote =====
Tossing during the repair process
This exposed several serious problems:
Did not put user experience first, tossing unfamiliar technology on the production server. In the future, when encountering server failures, under the premise of not destroying the scene for subsequent analysis, we should put the restoration of service as soon as possible first.
Did not train new people, it is easy to have a “single point of failure” in personnel. During the fault period, it happened to be the final exam week, and both I and tux were very busy. Other people in LUG had not touched mirrors before and could not intervene.
The system configuration file does not have a complete backup, only the configuration files related to the service are managed with git, causing the SSH key to be lost.
Did not continuously monitor the running status after restoring the service. We should restore monitoring services such as collectd and ganglia as soon as possible.
High-load services only have the most basic alarms, and operation and maintenance personnel cannot know in advance about hard disk full, memory shortage, high I/O util, etc. “Safety hazards”. You can try to use monit or nagios for more granular alarms.
In addition, about the daily operation and maintenance of mirrors, some problems have also been exposed. Although it has nothing to do with this fault, it is related to previous other faults and is worth paying attention to.The synchronization status of the source only has rough monitoring. Long-term statistics should be added for reference in adjusting synchronization strategies.
syslog must be checked, such as nf_conntrack table full, if it is not an iscsi fault, the operation and maintenance personnel do not know about it.
The mystery of virtualization
Virtualization can make operation and maintenance simpler, or it can make operation and maintenance more complicated.
If HTTP, rsync, FTP and other basic services are on the host, and synchronization scripts are on the LXC virtual machine, it can have an isolation effect, improve stability, and facilitate maintenance by different people.
However, like this mirrors rebuild, doing two layers of virtualization, and trying to stuff HTTP, rsync, FTP and other “elephants” into the LXC “refrigerator”, not only requires a lot of glue to bond at different levels, but also easily brings performance problems. What’s more serious is that when a problem occurs, we have to spend more time troubleshooting the problem at which level; the lower the problem level, the higher the complexity of repair.
Rise and fall
I think, this idiom can best describe what I did for mirrors last semester.
- November 24, 2012, at the Linux User Party, I solemnly announced that I would set up a mirrors lab to allow more people to participate in mirrors maintenance. However, under the resistance of tux, this plan has been shelved.
- March 15, 2013, tux proposed the idea of using os-level virtualization technology in internal emails.
- March 29, the first version of the sandbox was completed, without using LXC, but tux’s self-compiled namespace isolation script. lab.mirrors.ustc.edu.cn points to /srv/array/exports in nginx, which provides HTTP access.
- April 5, using a classic chroot vulnerability, I got the root permission of the mirrors main site. Perhaps this is the first time that LUG members have obtained permissions through abnormal channels, and I hope it is the last time.
- April 10, I urged tux to deploy a secure container on mirrors again.
- April 12, the container completed the synchronization of several mirrors such as kernel.org, chakra, apache, php.net, and set crontab to synchronize once every 6 hours. The mirrors being synchronized also include pypi, rubygems, openwrt, trisquel, dev.mysql.com.
- April 12, tux put the 4 mirrors that have been synchronized into the main site homepage.
- April 18, tux set up mirror-lab with LXC, which is probably the second version of the sandbox.
- April 27, the LUG handover meeting was held, tux announced the establishment of mirror-lab, but did not open an account.
- April 28, a large wave of new synchronized mirrors on mirrors-lab went online.
- May 1, the php.net mirror was transferred to the lug server, and the application for the official source was rejected.
- May 9, a batch of relatively stable sources were put on the mirrors homepage. I’m not sure, but this might be the first time I used the account on the mirrors main site.
- May 10, stephen took out a previous version of the mirrors index and put it on testindex.mirrors.ustc.edu.cn.
- May 10, manage the synchronization script on mirror-lab with git.
- May 13, the hackage source went online.
- May 15, zguangyu proposed to synchronize PPA on mirrors, and tux gave him an account. This is the third person on mirror-lab besides tux and me.
- May 19, submitted a mirror application to sourceforge, but after one reply, there was no reply.
- May 20~24, submitted official source applications to multiple distributions.
- May 25, according to stephen’s suggestion, my synchronization script on mirror-lab was upgraded.
- May 31, tux fixed the FreeBSD source that had been 502 for a long time.
- May 31, a block of local hard disk on mirrors was full.
- June 1, the first iscsi failure of the mirrors disk array.
- June 3, PyPI synchronization changed to use bandersnatch, becoming stable.
- June 4, PyPI source (pypi.mirrors.ustc.edu.cn) began trial use.
- June 4, nginx log file format upgrade, adding two fields.
- June 9, mirror-lab changed the default exit to mobile exit.
- June 10~15 (I don’t remember the exact time), mirror-lab began to quietly synchronize the sourceforge source from mirrorservice.org.
- June 12, gave pudh a mirror-lab account.
- June 14, released the meego source.
- June 15, removed the meego source and added the tizen source. (Thanks to the mobile exit, a 500G source was synchronized in one day)
- June 16, managed the synchronization script of the mirrors main site with git, this is the first time I saw the original synchronization script of mirrors.
- June 17, provided writable FTP for anthon’s open source community.
- June 20, checked the synchronization status of each mirror on the mirrors main site one by one, trying to achieve all green.
- June 20, managed the system configuration files such as nginx, rsyncd, vsftpd, logrotate, rc.local, etc. of mirrors with git.
- June 20, the synchronization script of the mirrors main site was changed to the default mobile exit.
- June 20, stephen released the disk load analysis of mirrors.
- June 21, stephen proposed some norms for system maintenance in internal emails. These norms were adopted when rebuilding mirrors.
- June 24, I started writing the new homepage of mirrors.
- June 26, the second iscsi failure of the mirrors disk array.
- June 27, the third iscsi failure of the mirrors disk array.
- June 27, I accidentally crashed mirrors.
- June 28 to July 2, mirrors closed for maintenance, HTTP was redirected to other sources.
- July 2, running at full load without resolving the load problem, leading to almost inaccessible in one day, in fact, this is the longest fault period.
- July 4, figured out the cause of the fault, summarized the lessons.
- July 5, tux sorted out some LXC documents to the LUG wiki internal page.
- July 5 and 6, tux and I left school one after another, and the mirrors rebuilding work fell into a standstill.
A few days ago, mirrors had another hard disk failure. In the absence of previous maintenance personnel of mirrors, the new LUG technical team rebuilt the basic services of mirrors in just two days and deployed a reasonable LXC virtualization architecture. Although the fault is not a good thing, the recent rebuild is worth celebrating. The overall effect of the rebuild is satisfactory, much more pragmatic than what we did two months ago.
In the coming days, I hope the mirrors maintenance team will:
- Learn from the failure, improve backup and monitoring;
- Contact the SourceForge source as soon as possible;
- Restore the original SSH accounts and home directories of mirrors;
- Gradually add monitoring for the synchronization status and access heat of existing sources.
I wish mirrors can walk out of the shadow of the failure soon, rejuvenate its former glory, and continue to lead the open source software mirror in mainland colleges and universities. As the network service with the largest traffic in LUG, I believe mirrors can show its maintainers a different style.