From IP Networks to Content Networks
Is IP Enough?
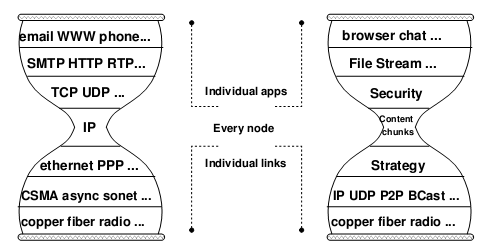
Starting from middle school computer classes, we have been learning about the so-called “OSI seven-layer model” of computer networks, and I remember memorizing a lot of concepts back then. Those rotten textbooks have ruined many computer geniuses. In fact, this model is not difficult to understand: (those who have studied computer networks can skip this)
- Physical Layer: This is the medium for signal transmission, such as optical fiber, twisted pair (the network cable we commonly use), air (wifi)… Each medium requires its own encoding and modulation methods to convert data into electromagnetic waves for transmission.
- Data Link Layer: Let’s use an analogy. When speaking, you might accidentally say something wrong or hear something wrong, so you need a mechanism to correct errors and ask the other party to repeat (checksum, retransmission); when several people want to speak, you need a way to arbitrate who speaks first and who speaks later (channel allocation, carrier listening); a person needs to signal before and after speaking, so that others know he has finished speaking (framing).
- Network Layer: This was the most controversial place in the early days of computer networks. Traditional telecom giants believed that a portion of the bandwidth should be reserved on the path between the two endpoints, establishing a “virtual circuit” for communication between the two parties. However, during the Cold War, the U.S. Department of Defense required that the network being established should not be interrupted even if several lines in the middle were destroyed. Therefore, the “packet switching” scheme was finally adopted, dividing the data into several small pieces for separate packaging and delivery. Just like mailing a letter, if you want to deliver it to a distant machine, you need to write the address on the envelope, and the address should allow the postman to know which way to go to deliver it to the next level post office (for example, using the ID number as the address is a bad idea). The IP protocol is the de facto standard for network layer protocols, and everyone should know the IP address.
- Transport Layer: The most important application of computer networks in the early days was to establish a “connection” between two computers: remote login, remote printing, remote file access… The transport layer abstracts the concept of connection based on network layer data packets. The main difference between this “connection” and “virtual circuit” is that the “virtual circuit” reserves a certain bandwidth, while the “connection” is best-effort delivery, without any guarantee of bandwidth. Since most of the traffic on the Internet is bursty, packet switching improves resource utilization compared to virtual circuits. In fact, history often repeats itself. Nowadays, in data centers, due to predictable and controllable traffic, we are returning to the centrally controlled bandwidth reservation scheme.
- Application Layer: There is no need to say more about this, HTTP, FTP, BitTorrent that the Web is based on are all application layer protocols.
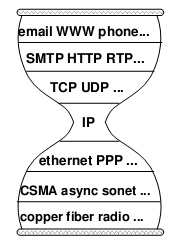
This model has been running stably for decades, and because of its clear hierarchy and strong scalability, it will continue to run stably. However, since the 21st century, the application scenarios of computer networks have been quietly changing. The main purpose of people using the network is to obtain and publish information, not to establish connections between two machines. If the network is always limited to sharing devices, files, remote login, etc., the Internet will never become such a big industry today, so it’s no wonder that Bill Gates didn’t value the Internet back then.
Problems
The end-to-end, connection-oriented Internet architecture faces three fundamental obstacles in today’s Internet application scenarios:
Inefficient One-to-Many Transmission
For example, if one hundred million people are watching the World Cup live at the same time, what kind of servers and bandwidth resources are needed? Calculating at the minimum bitrate of 100kbps, a total of 10Tbps bandwidth is needed. It should be noted that the total bandwidth of China’s international exports is only at the 1Tbps level. Therefore, the World Cup live broadcast we watch is actually “rebroadcast” by domestic video service providers; these video service providers have also placed CDN nodes in each province and each operator for nearby access; this is still not enough, so P2P acceleration may also be needed (these technologies will be explained below). Each intermediate link, especially P2P, will significantly increase the delay of the video, so the time to cheer in front of the computer may be a minute later than the audience in front of the TV.
Why is this? For example, the otaku next door and I are watching the World Cup separately, and the server has to send two identical video data to the two of us separately. Network switching devices are just busy delivering data packets and don’t care about the content of the data packets. A natural idea is, why can’t you send only one copy and let the network switching device “multicast”? People who understand computer networks will definitely jump out and say that there is no such protocol. This is the difference between engineering and research. Engineering emphasizes using existing hardware and software to complete tasks, like dancing in shackles; research is certainly constrained by natural laws, but it can be imaginative and design more elegant and harmonious architectures.
Not only videos, but also reading news, downloading movies and software are typical one-to-many transmissions. This problem is so huge that the industry mainly uses three workarounds to solve this problem:
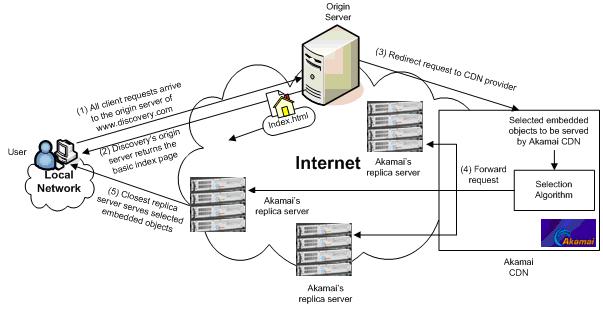
- Content Delivery Network (CDN). Servers are placed in various operators, and content providers put the content to be distributed on them in advance. When users access the source server, they are redirected to a closer CDN node on the network, and users download content from the CDN node nearby.
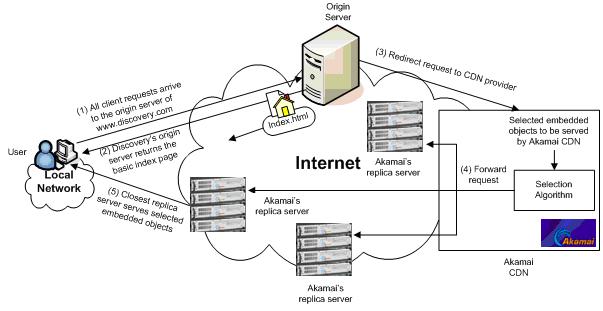 CDN_3
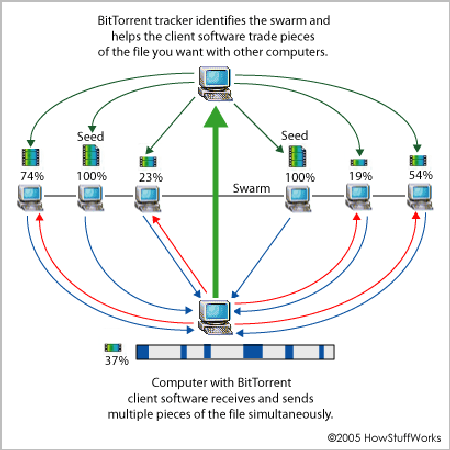
CDN_3 - P2P (Peer to Peer). Everyone has used BitTorrent, right? The principle is to find other users who have the same file and download from these users at the same time. Now many download software, software installation assistants and video clients, such as Thunder, 360 Software Housekeeper, Youku, all use both CDN and P2P technologies.
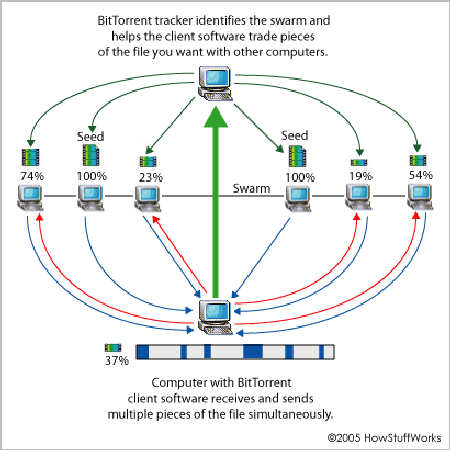 bittorrent
bittorrent - Community caching. The operator deploys a device in the “community” to monitor HTTP traffic that belongs to file download types and caches the data. When someone in the community downloads the same URL again, the data will be taken out of the cache and sent to the user, so it seems much faster to download. Some routers and browsers that claim to have Internet acceleration functions also use similar methods for caching, or even more aggressively, predict user behavior and prefetch files from the server. Before I got involved in network research, I was very disgusted with this behavior. This is like network hijacking. If the file is updated, the user may still download the old file.
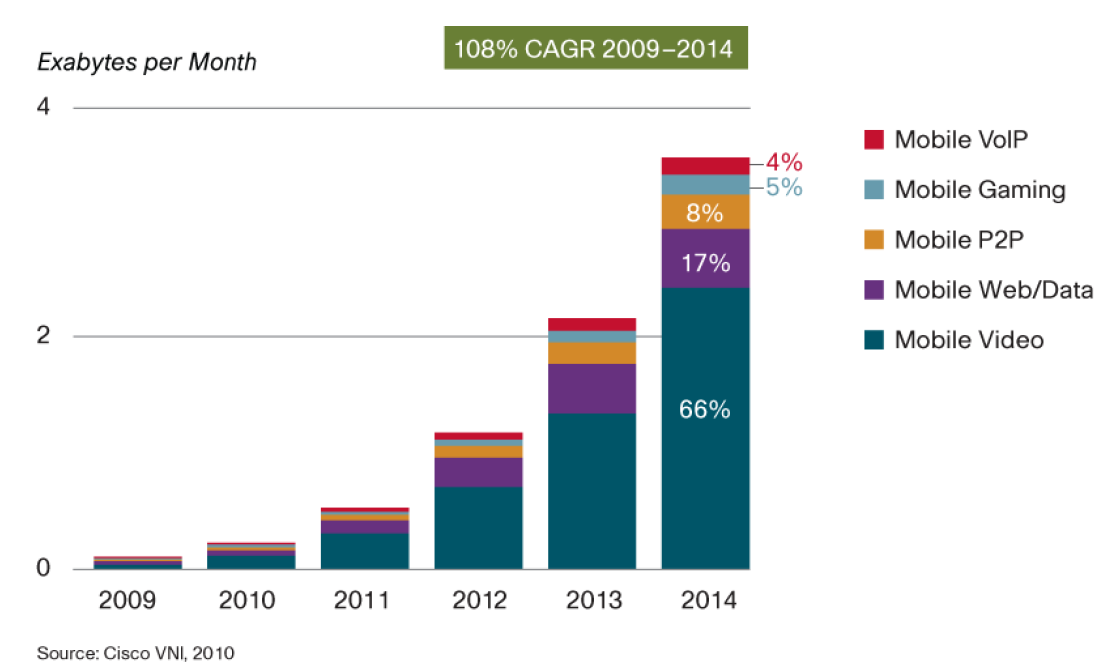
Inefficient one-to-many transmission is the main driving force for the birth of content-centric networks (referred to as content networks in this article, or Named Data Networking). As can be seen from the following figure, video is occupying most of the traffic of the mobile Internet, and most of the video is one-to-many, which is very suitable for multicast.
Local Area Network Transmission
Have you ever noticed that when you transfer files using QQ within a local area network, the speed is very fast, unlike sending it to the QQ server and then downloading it. This is because QQ automatically detects the network topology and establishes a tunnel between the sender and receiver to send data directly. Without this optimization, data transmission that could be done in one room would have to go around a server hundreds of kilometers away!
If you want to play a video on the computer in your bedroom on the TV in your living room, without optimization, the bandwidth to the server may not be sufficient to support high-definition video. However, if the router and application are designed as follows, there is no need for the participation of a central server.
- The TV asks: Who has /home/videos/A?
- The router receives this inquiry, knows from the URL’s home that this is its own content, and broadcasts this request to various devices at home.
- The computer knows it has /home/videos/A, so it replies to the router with the content.
- The router knows the TV needs this content, so it sends the content to the TV.
Of course, to achieve the transmission of streaming media such as video, fragmentation and sequence numbers are needed, but the conceptual design above has explained the problem.
Constantly Moving Networks
More and more mobile terminals are accessing the Internet. Jumping from one wifi access point to another, or from a wifi network to a cellular network (GPRS or 3G), established connections have to be interrupted. If a person moves frequently between access points, basically no data can be transmitted. For this, telecom operators use a technology solution called Mobile IP to ensure that the IP does not change when users switch between cellular networks, and application layer software also needs to support resumption from breakpoints.
 meeker-india-mobile-v-desktop-internet
meeker-india-mobile-v-desktop-internet
This doesn’t seem like a big problem, but in wireless ad hoc networks, due to the high mobility of nodes, maintaining end-to-end connections is a difficult task. However, why do we need end-to-end connections? If I need a file from the other party, as long as the other party declares that they have this file and allows me to access it, I want all the nodes in the network to do their best to forward it for me, regardless of which route it takes! Of course, this can be achieved with UDP and mesh routing. However, traditional routing can only choose one route, and if the line is broken, a new route has to be chosen. Moreover, IP networks can’t simultaneously utilize wifi networks, 3G networks, and Bluetooth.
More importantly, the IP protocol stack itself is redundant for some applications. For example, in the Internet of Things, sensors only need to send data to the receiving node, without caring about the IP of the receiving node. Currently, these low-power devices generally use proprietary communication protocols, but CCN can become a unified standard.
From “Where” to “What”
In fact, what we care about is not “where is the content”, but “what is the content”. More and more websites are using the REST (REpresentational State Transfer) architecture, which uses URLs (Universal Resource Locators) like web addresses to identify each data unit, and uses primitives such as GET, POST, PUT, DELETE to represent SELECT (read), INSERT (add), UPDATE (modify), DELETE (remove) operations on data. REST abandons the concept of “connection”, making operations stateless, and GET, PUT, DELETE operations are even idempotent (multiple consecutive operations are equivalent to one operation), greatly simplifying concurrent programming and reducing the probability of bugs.
In the REST architecture, the URL only describes “what is the content”, not “where is the content” - we can’t possibly know which machine in the data center stores the content corresponding to a URL. Unlike the hash values used by protocols like BT, URLs are firstly human-readable; secondly, they are hierarchical, just like the IP addresses mentioned earlier, so you can easily find the location of resources based on the URL. However, IP addresses are firstly not human-readable (hence the need for domain names), and secondly, they locate machines, not content.
The trend of REST is making the entire Internet increasingly inclined to run on HTTP. Don’t forget, in the classic network model, HTTP is at the topmost application layer! We might as well move REST, represented by HTTP, to a conceptually closer position in the middle of the network protocol stack.
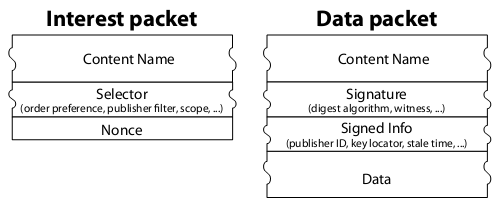
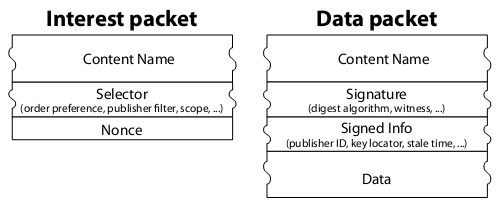
The following figure is the definition of “Interest Packet” and “Data Packet” in the original paper of Content Centric Networking. In fact, “Interest Packet” can be seen as an HTTP Request, and “Data Packet” can be seen as an HTTP Response. We will give a simple explanation of the following figure:
- Content Name is the URL. Note that there is also a URL in the Data Packet.
- Selector is a query language, its ability to match exactly is too weak.
- Nonce is a random serial number, used to discard duplicate Data Packets from different paths.
- Signature is a digital signature to ensure the authenticity of the data packet.
 ccn-2
ccn-2
So far, we haven’t seen the power of Content Centric Networking (CCN). Isn’t it just the over-hyped REST? Is it necessary to have a dedicated workshop at a top conference like SIGCOMM?
Let the router forward intelligently
Well, now everything needs to be “smart”, I also follow the trend. Moreover, the forwarding and caching strategies for CCN in the router are not that simple.
The example of “Local Area Network Transmission” has already shown what the router can do. Although I have been studying the network for less than two months, I have a strong intuition that the future router is definitely not as simple as the network manager setting routing rules. It is in a special position in the network, just like the mobile phone is in a special position in the hand, it is too humble to just make calls and send text messages. Today we won’t digress, let’s talk about what indispensable role the router can play in CCN.
First, we need to update the concept of “network card”. The traditional network card (interface) is the interface between the host and the network link, and each link requires a network card. (If a VPN is turned on, it is equivalent to adding a virtual link, which requires a virtual network card.) In CCN, to avoid confusion, face replaces interface, each link still corresponds to a network card (face), and each network-using application also corresponds to a network card (face). In this way, the CCN protocol stack on the host is almost the same as the router’s responsibilities, each application is connected to the host through a “line”, there is no difference between local data packets and forwarded data packets, and the structure seems more harmonious.

Every host or router running CCN has three tables:
- Forwarding Information Base (FIB), just like the routing table of the IP network, it is also the longest prefix match. Since there is no concept of IP address, you only need to care about which road to take, and you don’t need the “next hop IP”. Each item in the table is for a given URL prefix, which faces need to be forwarded to. The simplest strategy is to forward to all faces except the source face, and smarter strategies can use routing protocols similar to BGP/IS-IS to choose the route. However, traditional routing protocols can only generate a tree, and CCN is not afraid of loops because the Data Packet contains a URL. The routing protocol applicable to CCN is currently a hot research topic.
- Pending Interest Table (PIT), just like the URL being loaded in the browser, or the domain name being resolved in the recursive DNS server, you need to record each received query but not yet received data URL, and which faces need this data. When the corresponding data is received, it will be forwarded to the needed face and deleted from the PIT.
- Content Store, is to cache some recently frequently used query results. This table can be as small as in memory, or as large as on disk. This is the core trick to speed up one-to-many transmission. As long as one user requests it, all routers along the way will cache this data. As long as the next user comes to request it and it has not been cleared from the cache, it can directly return the data without having to send a request to the data source again.
Incremental deployment
Even if a network architecture is good, if it requires all network equipment in the world to be replaced overnight, it is not feasible. Fortunately, the content network can be incrementally built on the basis of the current IP network: several content network “islands” can be connected to the Internet through the existing IP network.
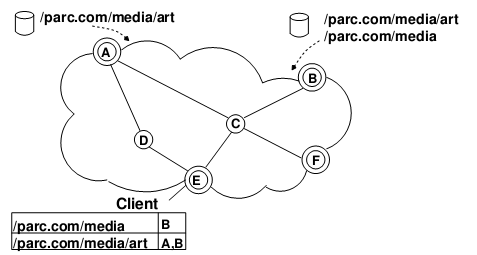
In the above figure, the double circle is the IP+CCN dual-stack router, and the single circle is the IP router. A user next to node A can provide content with the prefix /parc.com/media/art, node A will insert this prefix into the FIB table, and tell this message to B, E, F. A user next to node B can provide content with /parc/media/art and /parc/media (the same content can be provided by multiple nodes), node B will insert it into the FIB table and notify B, E, F. When a user next to E needs /parc/media/art/impressionist-history.mp4, E will go to A and B to find it. Of course, prefix flooding is quite bandwidth-consuming, which restricts the number of “islands”. Recent research results use additional fields in the BGP protocol, which can allow BGP routers to convert prefix announcement messages into IP routing announcement messages.
As for the search for the top-level URL prefix in the IP network, it can be assisted by the existing DNS system.
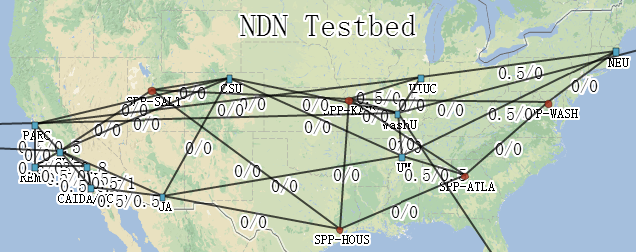
If you still don’t believe it, please see the figure below. (You can see the real-time network topology and traffic map at http://ndnmap.arl.wustl.edu/). This is so much like the network topology on the eve of the Internet’s birth! At that time, the experimental IP network was built on the basis of the telephone network. Today, the experimental content network is built on the basis of the IP network.
Security
Security is mainly divided into two levels, one is to trust the source of data, and the other is to prevent attacks.
Trust the source of data
CCN is peer-to-peer transmission. If anyone can claim to be any entity, it will definitely be chaotic. First of all, CCN’s Data Packet is digitally signed, which ensures that the data will not be tampered with during transmission. However, if I sign for myself and claim that I am Google, who knows?
Under the current PKI (Public Key Infrastructure), several trusted institutions (known as CAs) issue digital certificates to trusted institutions and individuals. The certificate holders then use the CA-signed certificates to sign the transmitted content (such as HTTPS). The operating system will embed these CA’s digital signatures, thus ensuring the non-forgery of the transmitted content. However, if the CA is breached, or no longer adheres to the Don’t be evil code of conduct, the entire trust mechanism is in jeopardy. This trust crisis has occurred in history, leading directly to the bankruptcy of the unfortunate CA.
The trust in CCN is not a black-and-white “one-size-fits-all” solution, but is based on context.
First, a list of keys that a person trusts needs to be established. There are several ways:
- Tree structure: If I am a Microsoft employee, I will trust the key of microsoft.com, and I will also trust the keys of other Microsoft employees signed by this key, so that the company can communicate securely.
- The traditional signature-based public key system (the aforementioned PKI)
- PGP Web Of Trust. Everyone can sign for several other people in the network, forming a large web of trust relationships. Even if one or two people betray, it doesn’t matter. Debian Developers use PGP Web Of Trust to maintain the trust relationship of this large loose team.
Secondly, the security of the content is declared by the “security link”. For example, if the trusted A publishes content P containing a secure link to content Q, then content Q is relatively reliable. If many trusted contents have secure links pointing to content Q, then the reliability of Q will be very high. (Does it look like PageRank?) Applied to the current network, it will form a large web composed of “security links”. Even if a publisher betrays and tries to forge a digital signature, there will be more evidence to prove that the credibility of the original signature is higher than the forged digital signature.
Prevent attacks
The non-“end-to-end” design of CCN naturally eliminates a large category of network attacks: sending malicious packets directly to the target host. Therefore, CCN attacks may focus on DoS (Denial of Service).
- Reflection attack: Since there is no concept of source IP at all, forging source IP is nonsense.
- Hide legitimate data: Unless you control the must-pass route, it is impossible. Since CCN does not need to generate a tree, if this road cannot receive data, the Interest Packet can be sent out along another road and receive the Data Packet along that road.
- Send a large number of randomly fabricated requests (Interest): This seems very effective because the request is anonymous. You can limit how many issued Interests have not received a response on the router, just like limiting the number of half-open connections in the IP network to prevent SYN flood.
- Send a large number of unrequested replies (Data): It has no effect because it will be discarded.
Conclusion
One problem that the author of the paper did not mention is that the content network is not end-to-end, all requests are anonymous, and content providers do not know who has accessed these contents, and cannot control access by region. Of course, the small area cache of the current operators has made the statistics of access times inaccurate.
Another problem is that the URL prefix is not easy to match, and requires larger TCAM space in the router. There has been a lot of research in this area, but strings are naturally more difficult to handle than integers, which will be a bottleneck for the large-scale deployment of content networks.
Anyway, the content network is an emerging network model that hits the pain points of today’s Internet, and has also been recognized by the academic community. Whether this network model will be widely promoted in the future, or even replace the current IP network, the basic ideas of the content network and its research results in name distribution, multipath routing, trust mechanism, etc., can provide reference for existing REST-based network applications.
References
- V. Jacobson, D. K. Smetters, J. D. Thornton, M. F. Plass, N. H. Briggs, R. L. Braynard (PARC) Networking Named Content, CoNEXT 2009, Rome, December, 2009.
- http://www.ccnx.org
- http://ndnmap.arl.wustl.edu/