用 Vibe Coding 解决 LLM 限制采样的面试题
这是我司的一道面试题。
有人说我们的 Vibe Coding 编程题太难了,其实我司的 2 小时 Vibe Coding 面试题都基本不需要自己写代码。只要把题输到 prompt 里面,跟 LLM 持续交互提需求和改进方向,AI 就给你自己做完了。
为什么叫 Vibe Coding?就是让你尽量少直接写代码。人和 AI 的分工变得非常明确:人负责把控方向、定义问题、审查结果,而 AI 负责具体的实现。像 Claude Code 这种就是一个极致,人不准动代码,只有 LLM 能动代码。
下面,我将通过这道面试题的完整经历,来展示 Vibe Coding 是如何运作的。这整个探索过程并非一帆风顺,AI 的初期方案存在严重缺陷。正是通过我不断的审查和方向修正,我们才最终抵达了那个可用的解决方案。这不仅是关于一个技术问题的解答,更是一次关于未来软件开发模式的深度探索。
值得一提的是,这篇文章本身,也是我在 Cursor 中,让 Gemini 2.5 Pro 根据我的工作日志(包含我与 AI 的所有对话、代码的演进过程)自动生成的。从我开始向 Cursor 提出最初的问题,到完成最终可用的程序,再到生成这篇图文并茂的博客文章,整个过程仅花费了 1.5 小时。
The Challenge: LLM 限制采样
一个学英语的软件需要保证其内置的 LLM 输出的所有单词都必须在一个 3000 词的词库范围内。
要求:
- 使用大语言模型(LLM)的**限制采样(Constrained Sampling)**方法,修改推理框架(如
transformers)中的 token 采样算法,保证 LLM 输出的所有内容都在这个给定的 3000 词的词库范围内。 - 当然,要允许输出标点符号、空格、换行等,但不允许输出特殊字符、中文、法语、表情符号等。
- 词库中单词的大小写变换都认为是合法的单词,例如词库中有
apple一词,那么apple、Apple、APPLE都认为是合法的输出。 - 3000 词的词库可以从网上随便找一个常见英语单词表。
- 要求限制采样算法性能尽可能好。
这道题的难点在于,它要求我们深入到 LLM 推理的“神经中枢”——采样过程。简单的 Prompt Engineering 无法提供 100% 的保证,我们必须在模型生成每一个 Token 的瞬间进行干预。这考验的是对 Tokenization、Logits 和采样算法的深入理解。
The Journey: 一场充满“弯路”的 Vibe Coding 探索
我使用的工具是 Cursor。我们的旅程充满了试错、纠偏和迭代。
第一回合:AI 的天真初尝试与我的“当头棒喝”
我将面试题原封不动地交给了 AI。它的第一反应非常快,但提出的方案却犯了一个根本性的概念错误。
AI 的初始方案:
- 预处理: 遍历 3000 词的词库。
- 构建白名单: 将这 3000 个单词通过 Tokenizer 切分,得到一个“合法 Token ID 集合”。
- 采样限制: 在每次生成时,只允许模型从这个“合法 Token ID 集合”中进行采样。
这个方案看起来简单直接,但它完全忽略了上下文和单词的构成。我立刻发现了问题所在,并直接否定了这个方案。
我给 AI 的反馈:
这个方案是错的。它没有理解单词是由多个 token 构成的。比如词库里有apple,一个常见的 Tokenizer 可能会把它切分成ap和ple。在你的方案里,单独的ple这个 Token 本身很可能不对应任何一个完整的合法单词,所以它不会在你的白名单里。当模型生成了ap之后,它下一步将永远无法生成ple,从而永远也写不出apple这个词。我们需要的是验证单词的延续性,而不是孤立地验证单个 Token。
这是人机协作的第一个关键时刻:人类专家负责识别高层次的、概念性的逻辑谬误,防止 AI 在错误的方向上浪费精力。
第二回合:走向“正途”?Trie 树的优雅与陷阱
收到我的反馈后,AI 认识到了错误,并提出了一个在算法上更优的方案。
AI 的第二个方案:Trie 树(前缀树)
- 构建Trie: 将 3000 个单词(全部转为小写)构建成一棵 Trie 树。树的每个节点代表一个字符,从根到任意节点的路径构成一个单词前缀。
- 状态追踪: 在生成过程中,维护一个指针,指向当前部分生成单词在 Trie 树中的位置。
- 合法性判断: 在生成下一个 Token 时,遍历所有可能的 Token,解码成字符串,然后检查这个字符串能否让当前 Trie 树的指针继续向下移动。只有能让指针继续前进的 Token 才是合法的。
我: “对,用 Trie 树是正确的方向。就这么做。”
我批准了这个设计。Trie 树的效率很高,是解决这类前缀匹配问题的标准答案。AI 很快生成了基于 Trie 的代码。然而,真正的魔鬼藏在细节里,我们很快就一起掉进了 Tokenization 的泥潭。
我们发现,一个纯净的、基于字符的 Trie 树,在面对 transformers 真实的 Tokenizer 时,显得力不从心:
- 带前缀的 Token: Tokenizer 为了效率,经常会把高频词前面的空格也编码进去,生成类似
apple这样的 Token。我们的 Trie 树里只有apple, - 复合 Token: 一个 Token 可能包含单词和结尾的标点,比如
cat.。我们要在 Trie 树里处理这个.吗?难道要把所有单词的标点组合都加进去?这会导致状态爆炸。 - 不完整的 Subword Token: 正如之前提到的
apple->ap,ple。这部分 Trie 树能处理,但结合上面的问题,情况就失控了。 - 大小写与特殊字符:
\nOnce这样的 Token 如何与小写的 Trie 树匹配?
代码为了处理这些边缘情况,开始充斥着大量的 if/else、字符串预处理和状态重置逻辑。整个方案变得臃肿、脆弱,失去了最初的优雅。
这时,我再次扮演了“刹车”和“导航员”的角色。
我: “Trie 的方案因为 Tokenization 的问题变得太复杂了,我们正在‘为醋包饺子’。换个思路,放弃对 Token 本身的解析,回归到它的最终效果上。我们不关心一个 Token 内部长什么样,只关心它被解码并拼接到当前文本后,在字符串层面,新形成的单词是否合法。”
这个决策是整个项目最重要的转折点。我引导 AI 放弃了那个理论上最优但工程上极其复杂的方案,转向了一个更务实、更健壮的方案。
第三回合:回归本源,打造稳定且透明的系统
AI 迅速理解了我的新方向,并重写了核心逻辑,这也是我们最终采用的方案。
最终方案的核心逻辑:
- 使用
LogitsProcessor: 这依然是最佳的介入点。 - 遍历候选 Token: 在每一步生成时,获取 top-k 的候选 Token。
- 模拟与解码: 对于每一个候选 Token,将它与当前已生成的
input_ids拼接,然后调用tokenizer.decode()得到一个完整的候选字符串candidate_text。 - 字符串层面的验证:
a. 找到当前文本中最后一个单词分隔符(如空格、标点)的位置。
b. 提取出candidate_text中从该位置开始的、新形成的最后一个单词或单词前缀。
c. 将这个提取出的字符串(转为小写)与我们的 3000 词词库进行验证。如果它是词库中某个单词的前缀,或者它本身就是一个完整的、在词库中的单词,则判定为合法。 - 过滤 Logits: 只保留那些通过了字符串验证的 Token,将其余 Token 的概率设为负无穷。
这个方案虽然在每次验证时都涉及解码和字符串操作,但它完美地将我们从 Tokenization 的泥潭中解放了出来,因为我们总是在一个可预测的、人类可读的字符串上进行操作。
从这里开始,我们的开发进入了快车道。我向 AI 提出了一系列增强体验的需求:
- 可视化调试:用红、绿、蓝三种颜色标记每个 Token 的决策状态,让我能直观地看到 AI 的”思考过程”。
- 修复 Contraction Bug:通过可视化,我们很快定位并修复了
she's very被错误判定的问题。AI 发现是撇号'被当成了单词边界,导致它去验证s是否合法。我指导它”忽略撇号后的单个字母片段”,从而解决了问题。
下面是系统运行时的实际输出,展示了每个 Token 的验证过程:
 系统初始化和第一步生成
系统初始化和第一步生成
图1:系统开始生成时的 Token 验证过程。绿色表示通过验证的 Token,系统选择了 “Once” 作为第一个词。
第四回合:绝处逢生,实现优雅的回溯机制
系统稳定后,我提出了终极挑战:
我: “能实现一个回溯机制吗?比如,当模型选择了
scr,然后发现后面无法跟任何合法的 token(如scruffy不在词库里)时,我们能退回一步,不选scr,而是选另一个词。但要有重试次数限制,防止死循环。”
AI 再次展现了它强大的算法能力,设计并实现了一个经典的回溯算法:
DecisionPoint数据结构: 一个用于记录”岔路口”信息的数据类,包含位置、当前选择和备选方案列表。decision_history栈: 每当遇到有多个合法选择的步骤时,就创建一个DecisionPoint并压入栈中。- 回溯逻辑: 当遇到死胡同时,从栈顶弹出一个
DecisionPoint,选择一个之前没试过的备选方案,截断错误的生成路径,然后从这个新路径继续生成。 - 最终失败处理: 如果回溯用尽了所有备选方案仍然找不到出路,为了避免无限循环,系统会放弃限制,直接从原始概率中采样一个 Token,并将其标记为红色,以示它违反了词库限制。
下面展示了回溯机制的实际工作过程:
 遇到死胡同触发回溯
遇到死胡同触发回溯
图2:系统在生成 “scr” 后发现无法继续,所有后续 Token 都被标记为无效(红色 x),触发了回溯机制。
 回溯过程中的替换选择
回溯过程中的替换选择
图3:回溯算法找到了替代方案 “curious”,蓝色标记表示这是通过回溯选择的 Token。
第五回合:最终润色,完美的交互式报告
最后,为了让整个系统不仅能用,而且好用、易于理解,我提出了最后的 Vibe:
我: “让输出更具视觉表现力。在回溯时,高亮显示完整的上下文,并解释回溯的原因。同时,输出一份结构化的 JSON 日志,方便分析。”
AI 再次完美地完成了任务。现在,最终的输出报告包含了丰富的彩色日志、回溯历史和一份详细的 generation_debug.json 文件。
最终成果展示
完整代码实现: constrained_sampling_string.py
系统在完整运行过程中展现了强大的自适应能力:
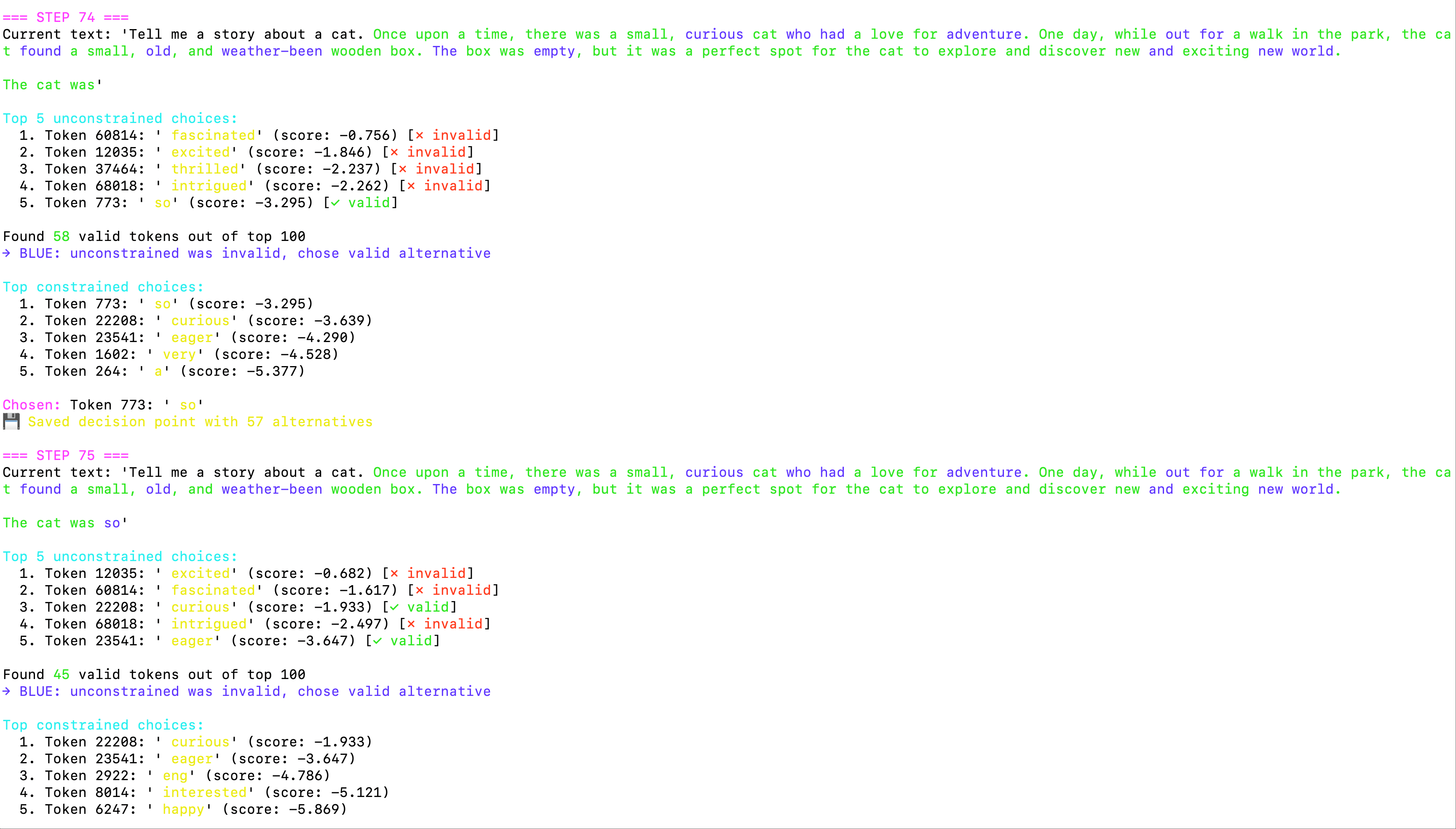 系统持续生成过程
系统持续生成过程
图4:系统继续生成过程,可以看到大部分 Token 都能正常通过验证(绿色),偶尔需要选择替代方案(蓝色)。
当系统遇到死胡同并成功回溯时,报告会这样显示,提供了充足的上下文:
 完整的回溯历史和最终输出
完整的回溯历史和最终输出
图5:完整的回溯历史记录,显示了系统在生成过程中的5次回溯操作,以及最终生成的完整故事。底部的统计信息显示了各种 Token 的分布情况。
从输出结果可以看到,系统成功地:
- 极大地保证了词汇合规性:绝大部分生成的单词都在预定义的 3000 词词库中。为了避免在极端情况下陷入无限回溯,当所有回溯路径都失败后,系统会选择输出一个不合规的 Token(用红色标出)来继续生成。
- 实现了智能回溯:当遇到死胡同时能够自动回退并选择替代方案
- 提供了丰富的调试信息:彩色编码让整个生成过程一目了然
- 保持了文本的流畅性:尽管有诸多限制,生成的故事依然连贯自然
结语:Vibe Coding,人与 AI 的深度共舞
这次经历让我深刻体会到 Vibe Coding 的强大之处。在这个过程中,我没有写一行具体的实现代码,但我扮演了不可或缺的角色:
- 架构师:在 AI 提出错误或过于复杂的方案时,把握了正确的方向,做出了关键的技术选型决策(例如放弃 Trie)。
- 测试工程师:通过观察输出,发现了多个边缘 case 和 bug。
- 产品经理:提出了增强可视化、提升调试体验的需求。
- 设计评审:对 AI 提出的方案(如
LogitsProcessor)进行确认,并对复杂算法(如回溯)提出高层设计思路。
AI 则像一个天赋异禀但需要引导的初级开发者,承担了所有繁重的编码、调试和算法实现工作。它会犯错,但只要给它正确的“Vibe”,它就能以惊人的速度迭代和修正。
人一定要对自己的能力边界有清晰的认知。工业革命之后,没有人再和机器比拼力气;在今天,任何一个程序员都很难跟 AI 比写简单代码的速度。我认为,未来甚至可能没有人能跟 AI 比拼智力。我发现越是聪明的人,认识到这一点就越快,而越是平庸的人,越容易给自己拒绝使用 Vibe Coding 找各种借口。
最近和一些猎头朋友聊天时,猎头朋友认为应当适当放宽招聘要求,公司不能只由绝顶聪明的人构成,因为聪明人想法多,很多 “落地” 的活儿还是需要普通人来干。
我的观点是,这正是 AI 带来的根本性变革。过去需要普通程序员做的很多 “落地” 工作,现在 AI 能以更高的水平和更快的速度完成。因此,公司与其招聘大量普通水平的程序员,不如直接让 AI 来承担这部分工作。这使得招聘的需求发生了变化:我们只需要那些能够在当前 SOTA 模型能力之上的顶尖人才,他们能够驾驭 AI,解决更复杂、更抽象的问题。
Vibe Coding 正是这种趋势下的产物。它不仅仅是一种有趣的尝试,它很可能代表了未来软件开发的一种重要形态。我们人类开发者需要不断提升自己的抽象能力、设计能力和批判性思维,学会与 AI 高效协作,将我们的精力从繁琐的实现细节中解放出来,专注于在更高维度上创造价值。