诺贝尔物理学奖怎么颁给了做 AI 的
(本文首发于知乎回答《2024 诺贝尔物理学奖授予人工神经网络机器学习,为什么会颁给 AI 领域?》)
一些人开玩笑说今年的诺贝尔物理学奖,好多搞物理的都没听说过获奖的这两个人……
人工神经网络与统计物理的关联不是偶然的
7 月初本科毕业 10 年回科大返校的时候,跟几位搞数学和物理的同学聊起了 AI,我吃惊的发现如今 AI 的很多基础概念是源自统计物理,比如 diffusion(扩散模型)和 emergence(涌现)。
@SIY.Z 也给我讲了很多 AI 经典算法背后的统计物理基础,比如此次获奖两人的重要成果 RBM(受限玻尔兹曼机)。
**这种关联并不是偶然的,因为统计物理研究的是大量粒子组成系统的行为,而人工神经网络也是大量神经元组成的系统。**从人工神经网络的早期发展历程,能够清楚地发现这种关联:
Hopfield 网络
1982 年,Hopfield 在研究人类记忆的原理,希望创造一个数学模型,用于解释和模拟神经网络如何存储和重建信息,尤其是在大脑中神经元是如何通过相互连接形成记忆的。
具体来说,这项研究的目的就是要构造一个支持 “语义模糊匹配” 的 CAM(Content-Addressable Memory,内容寻址内存),在存储阶段把需要存储的多条数据放进去,而在重建阶段,放入一个部分丢失或被修改的数据,需要找到与之最匹配的原始数据。
Hopfield 网络利用了物质特性中的原子自旋,这种特性使每个原子可以被看作一个小磁铁。这就是为什么 Hopfield 网络以及后续演进出来的人工神经网络这么像统计物理里面的 Ising 模型。Ising 模型就是用来解释为什么物质具有铁磁性的。
网络的整体结构可以用物理学中自旋系统的能量来描述。如果把能量想象成地面的海拔高度,数据想象成东西南北的坐标,一个 Hopfield 网络就是一片很多个山峰组成的山区景观,从任何地方的天空中扔下去一个小球,都会自动滚动到其中一个山谷的位置。这些山谷所在的位置就是需要存储的原始数据。
在存储信息的过程,也就是训练过程中,通过逐层更新的规则,确定节点之间的连接权值,从而使**存储的图像对应较低的能量状态。今天机器学习训练过程最小化 loss,对应的就是物理学中能量最小化的基本原理。**随着网络状态的不断更新,系统的能量逐渐减少,最终达到一个局部最小值,这对应于网络的稳定状态(吸引子)。这种动态过程类似于物理系统中趋向于最小势能的过程。
在重建信息的过程,也就是推理过程中,当 Hopfield 网络接收到一个失真或不完整的图像时,它通过逐步更新节点的状态来降低系统能量,从而逐步恢复出与输入图像最相似的图像。
Hopfield 发现,不管是大量粒子组成的物理系统,还是大量神经元组成的神经网络,对细节的变化都具有鲁棒性,坏掉一两个神经元很难影响系统整体的特性。这使得增量改变神经网络的权重,逐步学习训练数据中的模式成为可能。
Hopfield 网络证实了大量神经元组成的系统可以产生一定程度的 “计算能力”(计算能力是 “智能” 一词比较学术的表达),也是首次用简单的人工神经元复现了物理学中的**群体涌现(collective emergence)**现象。
Hopfield 网络尽管是人工神经网络的先驱,但它的网络结构不够合理(所有节点都是全连接),同时 Hebbian 学习机制也不够合理,更新规则是确定性的而不是随机化的,导致 Hopfield 网络的学习能力有限,只能存储和重建简单的模式。
这时候就该 Hinton 的玻尔兹曼机出场了。
玻尔兹曼机
1983-1985 年,Hinton 等人提出了玻尔兹曼机。
当时 Hinton 等人的研究目标比 Hopfield 更进一步,不仅是研究大量神经元组成的系统是否能涌现出记忆能力,而是希望**模拟物理世界中大量粒子所组成系统的行为。Sora 的 “生成模型是世界模拟器” 思想可能就是源自这里。**最早我以为 Sora 这个想法来自 Ilya Suskever 的论文,后来毕业 10 周年返校的时候跟搞物理的同学交流,才发现它的根子在上世纪 80 年代的统计物理。
玻尔兹曼机也是一种可以存储和重建信息的结构,但它相比 Hopfield 网络最重要的创新从 ”玻尔兹曼“ 这几个字上就已经体现。
Hopfield 网络假定所有输入数据之间是互相独立的,而玻尔兹曼机假定输入数据服从某种概率分布。因此,玻尔兹曼机是一种概率生成模型(是的,就是今天 GPT 里面的那个 Generative),它不仅仅像 Hopfield 网络那样仅仅试图重现最相似的一条输入数据,而是希望模拟复杂模式的统计分布,生成与输入数据中所包含模式类似的新数据。
具体来说,玻尔兹曼机基于统计学中的最大似然估计。因此,玻尔兹曼机可以在没有标记训练数据的情况下中提取数据中的结构,这就是今天的无监督学习。
在网络结构、更新规则、能量函数上,玻尔兹曼机也体现了随机模型相比确定模型的优势:
网络结构:
- Hopfield 网络:确定性模型,所有节点对称,节点之间是全连接的。
- 玻尔兹曼机:随机模型,把神经网络中的节点划分为可见层和隐含层,使用概率分布来描述状态。可见层负责输入输出,隐含层不与输入输出的信息直接相连。但所有节点仍然是全连接的。
更新规则:
- Hopfield 网络:确定性更新规则,节点状态同步或异步更新,收敛到能量最小的稳定状态。
- 玻尔兹曼机:玻尔兹曼机通过采样(如吉布斯采样或其他马尔可夫链蒙特卡罗方法)来模拟系统的状态转移过程。在采样过程中,系统逐渐向低能量状态收敛。这种逐步“冷却”的过程类似于模拟退火算法,其目标也是通过能量最小化找到全局最优解。
能量函数:
- Hopfield 网络:能量函数是确定性的,随着状态更新,能量减少,系统收敛到局部最小值。
- 玻尔兹曼机:能量函数定义系统的概率分布(即玻尔兹曼分布),低能量状态具有较高概率,系统通过采样找到低能量状态。这与最小作用量原理中的“选择”最优路径类似。
反向传播
1986 年,Hinton 提出了反向传播算法,解决了人工神经网络难以训练的问题,使得深度学习成为可能。所谓的训练,就是做数据拟合,用玻尔兹曼机较少的参数尽量拟合大量数据中的特征,也就是把训练数据中的规律用压缩的方式存储在玻尔兹曼机中。根据奥卡姆剃刀原则,训练数据压缩之后就提取到了特征,学到了知识。
受限玻尔兹曼机
玻尔兹曼机虽然理论上很优雅,但实际用起来效果并不好。因为当年计算机的算力很有限,玻尔兹曼机的全连接网络结构也使其收敛很困难。因此,上世纪 90 年代,人工神经网络进入了寒冬。
21 世纪初,Hinton 提出了受限玻尔兹曼机(RBM)。RBM 相比玻尔兹曼机的最大创新在于,用双层的二分图结构取代了全连接结构,只有可见节点与隐藏节点之间有权重,而同类节点之间没有权重。
玻尔兹曼机由于是完全连接的,训练非常复杂,因为需要处理所有神经元之间的相互依赖关系。尤其是通过马尔可夫链蒙特卡罗(MCMC)采样,收敛速度较慢。而 RBM 由于其受限的双层结构(无层内连接),训练过程可以简化。常用的训练方法是对比散度(Contrastive Divergence, CD),它大大加快了训练速度并使得RBM在实际应用中更加可行。此外,隐含层与可见层之间的依赖是条件独立的,这使得计算隐含单元的激活和权重更新变得更加简单。
后面的故事就是大家都知道的了,新的激活函数、多层神经网络、层间飞线(ResNet),加上逐步发展的算力,深度神经网络成就了 AI 的第一波热潮。至于 Transformer 和 GPT,就是算力增长之后的又一个故事了。
为什么把诺贝尔奖颁给 AI
**统计物理就像量子力学一样,是人类对世界认知的重大飞跃。**量子力学是从决定论到概率论,统计物理是从还原论到系统论。
在统计物理之前,人类是还原论的思想,希望把世界的运行规律归结于简单的物理法则。但统计物理让我们意识到,**复杂系统的特征本身就是复杂的,不能用几条简单的规则概括,因此要想模拟它的行为,就需要用另外一个相对简单的复杂系统,例如人工神经网络,来提取它的特征。**用一个相对简单的复杂系统模拟一个相对复杂的复杂系统,就是特征识别和机器学习。
从 Hopfield 网络到玻尔兹曼机,我们看到概率模型是其中最大的创新。把世界建模成一个概率模型,不仅对量子力学层面的微观粒子成立,在大量粒子组成的宏观系统中也成立。
事实上,Hopfield 和 Hinton 从一开始的研究目标就决定了 Hopfield 网络是确定性的,而 Hinton 会使用概率模型。Hopfield 是要记忆和重建已有的信息,而 Hinton 是要生成与已有数据规律类似的信息。为什么 Hopfield 和 Hinton 是今年获诺奖,而不是 AI 第一波浪潮的 2016 年获奖,就是因为生成模型的价值得到了验证。
再重复一遍,**复杂系统不能用简单的规则解释,需要用另一个相对简单的复杂系统来建模;复杂系统的行为应使用概率模型,而非决定论来建模。**上述两个认知并不显然。今天很多人还在尝试用几条简单的规则解释神经网络的行为;很多人认为深度神经网络是概率模型,因此永远不可能可靠地解答数学问题。这些都是不了解概率论导致的迷思。
**物理学的重要目的之一是发现世界运行的规律。这次授予诺贝尔物理学奖的发现并不是一条具体的物理规律,而是一种能够理解和模拟复杂系统的方法论:人工神经网络。**人工神经网络并不像汽车、计算机那样仅仅是一个应用,它同时也是人类发现世界规律的新方法。因此,虽然我对这次的诺贝尔物理学奖也很吃惊,但回过味来一想,又觉得很有道理。
我的个人暴论
“生成模型是世界模拟器” 这句话随着 Sora 的问世而爆火,其实这句话是 OpenAI 早在 2016 年就提出的,而提出这句话的 OpenAI 首席科学家 Ilya Suskever 又是从他的老师 Hinton 那里学到的这个思想。
仔细想想这句话,其实挺可怕的。物理世界需要一摩尔级别的粒子才能涌现出智能。而人工神经网络使用少几个数量级的神经元,就能模拟一摩尔级别粒子的规律,涌现出智能。这意味着人工神经网络是一种更高效的知识表达形式。在能源有限的情况下,人工神经网络也许是智能更高效的载体。
我们现在还不知道人工神经网络的能力边界在哪里。它真的足够通用到建模物理世界中的所有现象吗?**事实是,从 Hopfield 网络、玻尔兹曼机、RBM、深度神经网络到 Transformer,模型能力正在不断突破限制。**如今,一些被认为 Transformer 不可解决的问题都快被突破了。
例如,数学计算往往被认为是 Transformer 不可解决的问题,但如今 CoT(思维链)和基于强化学习的 OpenAI o1 基本解决了大模型做简单数值计算和符号计算的问题。
**OpenAI o1 甚至可以利用世界知识和逻辑推理能力,从数据中发现一些高层次的规律。**例如给出 Pi 的前 100 位,说这个数字是有规律的,让它预测第 101 位,它能够发现这是 Pi,并且按照 Pi 的计算方法,把第 101 位准确地计算出来。之前很多人认为这种知识发现能力和多步骤的复杂数值计算是 Transformer 永远都搞不定的,知乎上还有一个问题《如果把π的前10000亿位喂给大模型,让它预测后面的数字,它会得出相对准确的结果吗?》,下面的回答基本都是讽刺。但事实证明,利用 test-time scaling(增加推理时间做慢思考),这其实是可能的。
现在 OpenAI o1 mini 本科理科大多数专业课的题都会做,比如四大力学、数学分析、线性代数、随机过程、微分方程,o1 mini 对复杂的计算题大概能做对 70%-80%,简单概念题和计算题正确率 90% 以上,计算机系本科那些计算机编码题就更不是问题了,我觉得 o1 mini 在数学系、物理系和计算机系都能本科毕业了。o1 正式版出来之后估计会更强。我一边测就一边调侃说,我自己智商有限,当年高等数学就没有学明白,就只能用一些比我更聪明的工具来弥补我自己智力的不足了。
**人类在发现规律方面的能力被 AI 赶上并超越,也许就是 10 年内的事情。也许几十年后,获得诺贝尔物理学奖的将是 AI。**那时,我们人类应该做什么呢?我的思考是,人类应该决定 AI 的方向。这就是被赶走的 Ilya Suskever 和 Jan Leike 在 OpenAI 做的超级对齐(Superalignment):如何保证比人还聪明的 AI 能够遵循人类的意图。
诺贝尔奖官网其实解释了为什么物理学奖颁给了 Hopfield 和 Hinton 两个做 AI 的。有两个版本,一个科普一些的,一个深入一些的。两篇文章都写得不错,推荐一读。
科普一些的诺奖官网介绍
https://www.nobelprize.org/prizes/physics/2024/popular-information/
今年的获奖者使用物理学工具构建了帮助奠定当今强大机器学习基础的方法。约翰·霍普菲尔德(John Hopfield)创建了一种可以存储和重建信息的结构。杰弗里·辛顿(Geoffrey Hinton)发明了一种可以自主发现数据属性的方法,这在当今使用的大型人工神经网络中变得非常重要。
他们使用物理学在信息中寻找模式
许多人都体验过计算机如何在不同语言之间进行翻译、解释图像,甚至进行合理的对话。或许不太为人所知的是,这种技术长期以来对包括海量数据的分类和分析等研究具有重要作用。过去十五到二十年间,机器学习的发展突飞猛进,并利用了一种称为人工神经网络的结构。如今,当我们谈论人工智能时,通常指的就是这种技术。
尽管计算机无法思考,但机器现在可以模仿记忆和学习等功能。今年的物理学奖得主帮助使这一切成为可能。他们利用物理学的基本概念和方法,开发了使用网络结构来处理信息的技术。
机器学习不同于传统的软件,传统软件更像是一种配方。软件接收数据,根据清晰的描述进行处理,并生成结果,就像有人收集食材并按照配方加工,最终做出蛋糕。而在机器学习中,计算机通过示例进行学习,使其能够解决那些过于模糊和复杂而无法通过逐步指令处理的问题。一个例子是解释图像以识别其中的物体。
模仿大脑
人工神经网络通过整个网络结构来处理信息。最初的灵感来自于理解大脑如何工作。早在20世纪40年代,研究人员就开始推导出支撑大脑神经元和突触网络的数学原理。另一个关键的拼图来自心理学,得益于神经科学家唐纳德·赫布(Donald Hebb)的假设,即学习发生是因为神经元之间的连接在一起工作时得到增强。
后来,这些想法被用于尝试通过构建人工神经网络的计算机模拟来重现大脑的网络功能。在这些模拟中,大脑的神经元被节点所模仿,这些节点被赋予不同的值,而突触则由可以变强或变弱的节点之间的连接来表示。赫布的假设仍然是通过称为训练的过程来更新人工网络的基本规则之一。
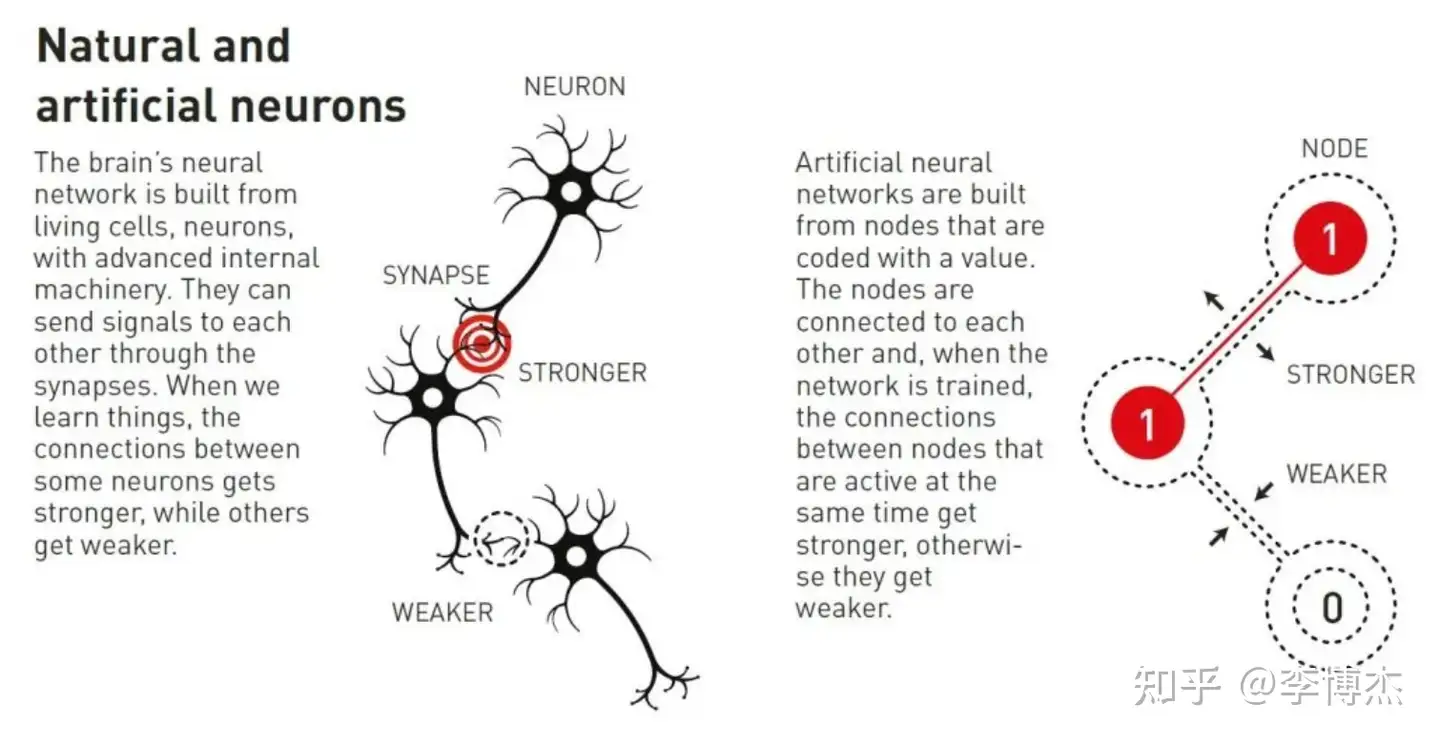 自然和人工神经元的插图
自然和人工神经元的插图
到20世纪60年代末,一些令人沮丧的理论结果使许多研究人员怀疑这些神经网络是否会有任何实际用途。然而,在20世纪80年代,几位重要的理念产生了影响,包括今年的获奖者的工作,重新唤起了人们对人工神经网络的兴趣。
关联记忆
想象一下你正试图记住一个你很少用到的相对不常见的词,比如通常在电影院或讲堂中见到的斜坡地板的词汇。你在记忆中搜寻。它有点像“坡道”(ramp)……也许是“径向”(rad…ial)?不,不是这个。是“rake”,就是它!
这种通过类似词汇寻找正确词汇的过程类似于物理学家约翰·霍普菲尔德在1982年发现的关联记忆。霍普菲尔德网络可以存储模式,并具有重现这些模式的方法。当网络收到一个不完整或稍微扭曲的模式时,这种方法可以找到最相似的存储模式。
霍普菲尔德之前曾利用他的物理学背景来探索分子生物学中的理论问题。当他被邀请参加有关神经科学的会议时,他遇到了关于大脑结构的研究。他被所学内容所吸引,并开始思考简单神经网络的动态。当神经元一起作用时,它们可以产生新的强大特性,这些特性对于只关注网络的单个组成部分的人来说是显而易见的。
1980年,霍普菲尔德离开了普林斯顿大学的职位,他的研究兴趣使他远离了物理学领域的同事们,并移居大陆。他接受了加州理工学院(Caltech)化学和生物学教授的职位,在位于南加州帕萨迪纳的加州理工学院,他可以自由使用计算机资源进行实验,发展他关于神经网络的想法。
然而,他并没有抛弃他在物理学中的基础,在那里他找到了解如何理解由许多小组件共同作用的系统产生新现象的灵感。他特别受益于对具有特殊特性的磁性材料的学习,这些材料的原子自旋使每个原子成为一个微小的磁铁。相邻原子的自旋相互影响,这可以形成自旋相同方向的区域。他能够利用描述材料如何在自旋相互作用时发展的物理学来构建一个具有节点和连接的模型网络。
网络在景观(landscape)中保存图像
霍普菲尔德构建的网络具有通过不同强度的连接相互连接的节点。每个节点可以存储一个单独的值——在霍普菲尔德的第一个工作中,这个值可以是0或1,就像黑白图片中的像素。
霍普菲尔德用一个属性来描述网络的总体状态,这相当于物理学中自旋系统中的能量;能量通过一个公式计算,该公式使用了所有节点的值以及它们之间所有连接的强度。霍普菲尔德网络通过将图像输入节点来编程,节点被赋予黑色(0)或白色(1)的值。然后使用能量公式调整网络的连接,使保存的图像具有较低的能量。当另一个模式被输入到网络时,有一条规则用于逐个检查节点,并查看如果该节点的值发生变化,网络是否具有较低的能量。如果发现将黑色像素改为白色可以降低能量,则改变其颜色。这一过程继续进行,直到无法找到进一步的改进。当到达这一点时,网络通常会重现训练时的原始图像。
如果你只保存一个模式,这可能看起来不太显著。或许你会想,为什么不直接保存图像本身并将其与正在测试的另一幅图像进行比较,但霍普菲尔德的方法特别之处在于,多个图像可以同时保存,网络通常可以区分它们。
霍普菲尔德将搜索网络保存状态的过程比作将一个球滚过由山峰和山谷组成的景观(landscape),其摩擦力减缓了其运动。如果球在某个位置掉落,它将滚入最近的山谷并停在那里。如果给网络提供一个接近保存模式的模式,它将以同样的方式继续前进,直到它到达能量景观的谷底,从而在其记忆中找到最接近的模式。
霍普菲尔德网络可用于重建包含噪声或部分被擦除的数据。
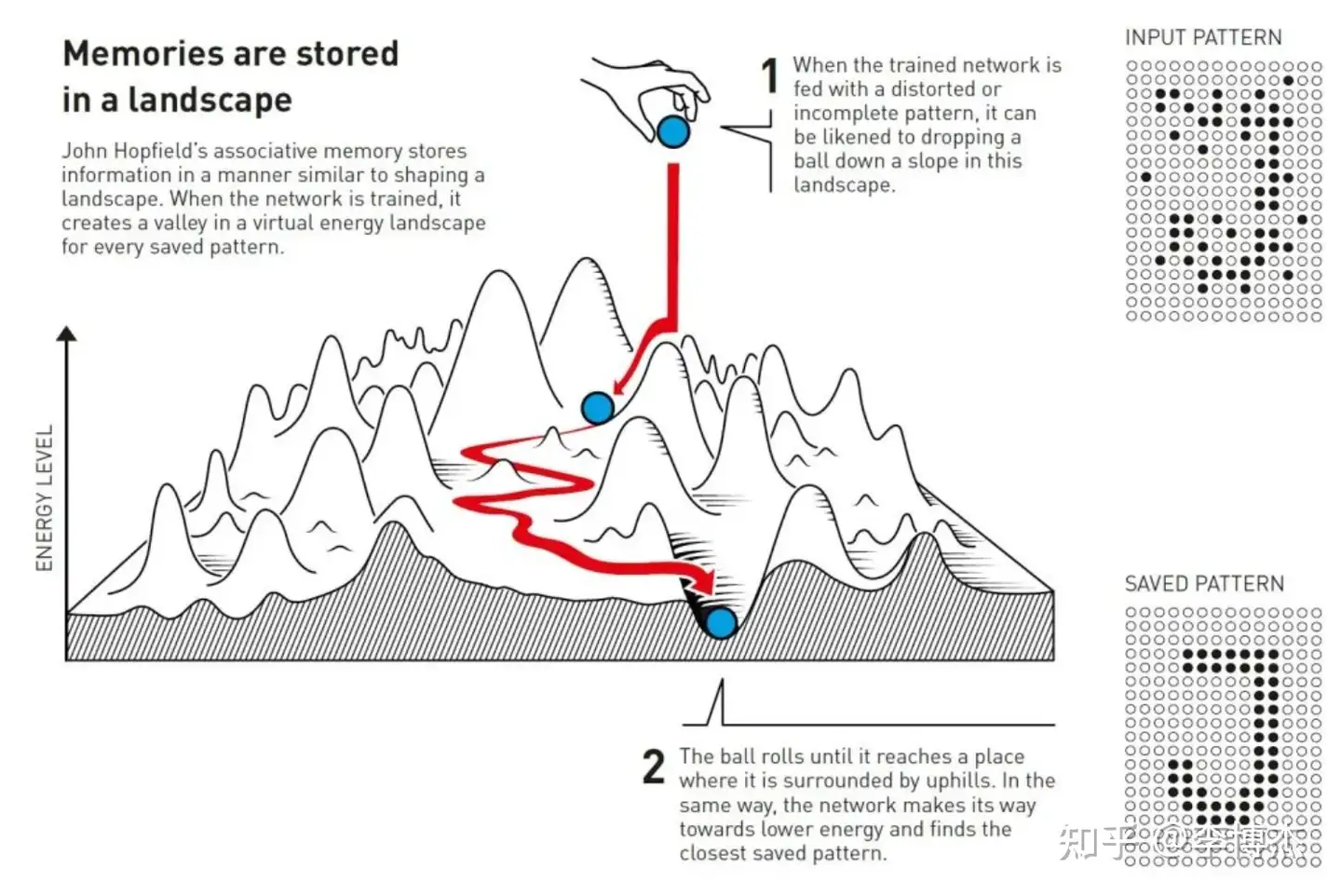 网络在景观中保存图像
网络在景观中保存图像
霍普菲尔德及其他人继续发展霍普菲尔德网络的细节,包括可以存储任意值的节点,而不仅仅是零或一。如果将节点视为图像中的像素,它们可以有不同的颜色,而不仅仅是黑白。改进的方法使得能够保存更多图像,即使它们非常相似,也可以将它们区分开来。同样可以识别或重建任何信息,只要它是由许多数据点组成的。
利用十九世纪物理学进行分类
记住一幅图像是一回事,但解释它描绘的内容则需要更多。
即使是非常年幼的孩子也可以指出不同的动物,并自信地说出它是狗、猫还是松鼠。虽然他们偶尔会出错,但很快他们几乎总是正确的。即使没有看到任何关于物种或哺乳动物的图表或概念解释,孩子们也可以学会这一点。在遇到每种动物的几个例子后,不同类别就在孩子的头脑中形成了。人们通过体验周围的环境学会识别猫,理解一个词,或进入一个房间并注意到有什么改变了。
当霍普菲尔德发表他的关联记忆文章时,杰弗里·辛顿正在美国匹兹堡的卡内基梅隆大学工作。他之前在英格兰和苏格兰学习过实验心理学和人工智能,正思考机器是否可以像人类一样学习处理模式,找到自己的分类方法来整理和解释信息。与他的同事特伦斯·塞诺夫斯基(Terrence Sejnowski)一起,辛顿从霍普菲尔德网络出发,利用统计物理学的思想进行了新的构建。
统计物理学描述了由许多相似元素组成的系统,例如气体中的分子。
虽然很难追踪气体中的所有分子,但可以通过整体来确定气体的总体性质,例如压力或温度。气体分子在其体积内以个别速度扩散的方式有很多种,但仍可以得出相同的集体属性。
统计物理学可以分析组成部分共同存在的状态,并计算它们发生的概率。有些状态比其他状态更可能发生;这取决于系统的能量,能量由十九世纪物理学家路德维希·玻尔兹曼(Ludwig Boltzmann)的方程式描述。辛顿的网络利用了该方程,该方法于1985年以“玻尔兹曼机”这个引人注目的名称发表。
识别同类的新实例
玻尔兹曼机通常使用两种不同类型的节点。信息被输入到称为可见节点的一组中。另一组节点形成隐藏层。隐藏节点的值和连接也影响整个网络的能量。
玻尔兹曼机通过逐个更新节点值的规则来运行。最终,机器会进入一个状态,节点的模式可以发生变化,但网络整体的属性保持不变。每种可能的模式都有一个特定的概率,这取决于根据玻尔兹曼方程计算出的网络能量。当机器停止时,它会生成一个新模式,这使得玻尔兹曼机成为一种早期的生成模型。
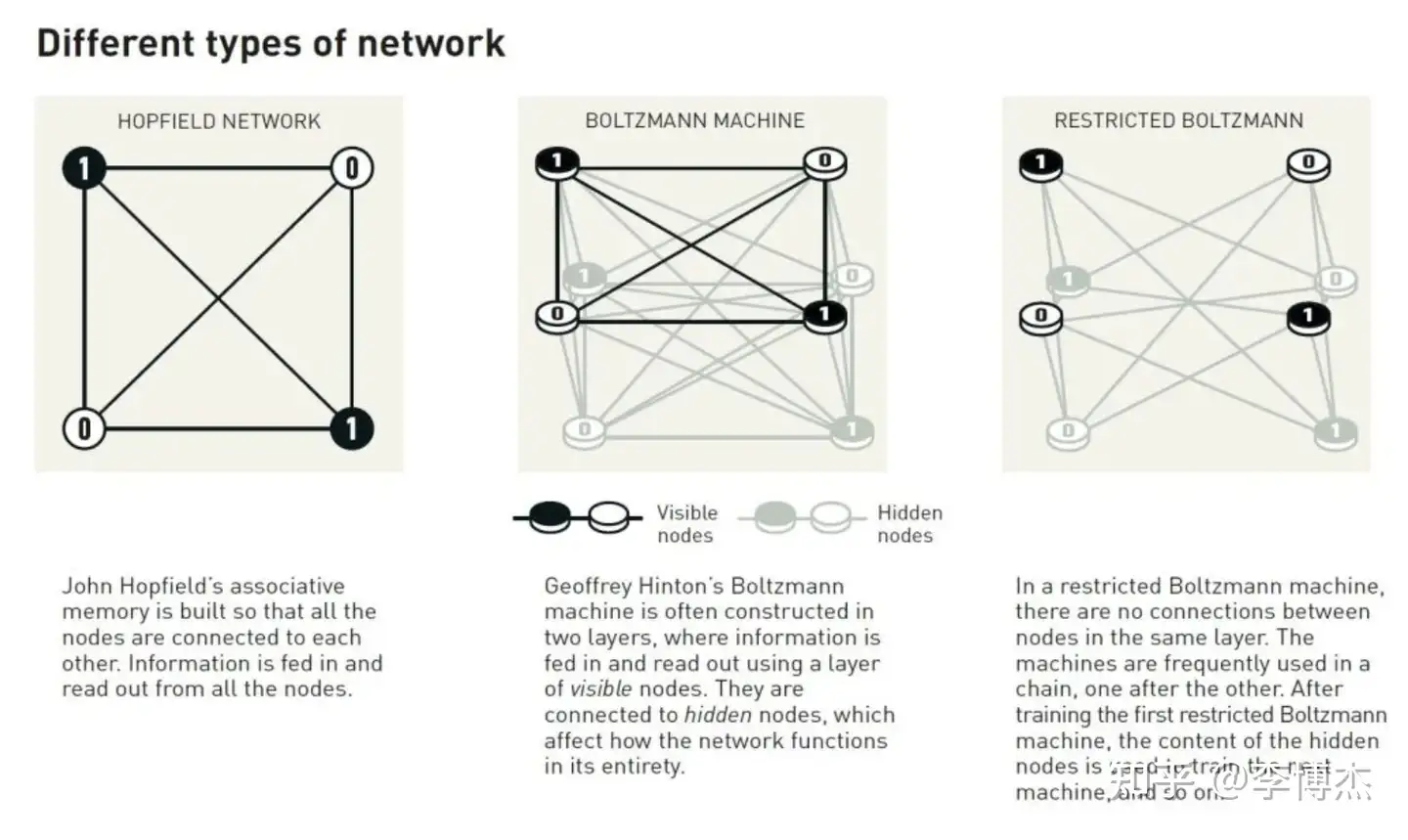 不同类型的神经网络
不同类型的神经网络
玻尔兹曼机通过示例进行学习——不是通过指令,而是通过提供给它的示例。它的训练过程是通过更新网络连接中的值,使得训练时输入给可见节点的示例模式的出现概率最大化。如果在训练过程中多次重复同一模式,则该模式的概率将更高。训练还会影响生成类似于训练示例的新模式的概率。
训练好的玻尔兹曼机可以在它从未见过的信息中识别出熟悉的特征。想象一下,你遇到了朋友的兄弟姐妹,你立刻能看出他们一定是亲戚。以类似的方式,玻尔兹曼机可以识别属于训练材料中类别的全新实例,并将其与不同类别的材料区分开来。
在其原始形式中,玻尔兹曼机效率较低,寻找解决方案需要很长时间。当它以不同方式得到发展时,事情变得更加有趣,辛顿一直在继续探索这一点。后来的版本进行了简化,删除了一些单元之间的连接。事实证明,这可能使机器更为高效。
在20世纪90年代,许多研究人员对人工神经网络失去了兴趣,但辛顿是少数继续在这一领域工作的学者之一。他还帮助开启了新一轮的激动人心的成果爆发;2006年,他和同事西蒙·奥辛德罗(Simon Osindero)、叶怀德(Yee Whye Teh)以及鲁斯兰·萨拉库丁诺夫(Ruslan Salakhutdinov)开发了一种预训练网络的方法,即在多个玻尔兹曼机层级中逐层预训练。这种预训练为网络中的连接提供了更好的起点,优化了其训练,以识别图像中的元素。
玻尔兹曼机通常用作更大网络的一部分。例如,它可以根据观众的偏好推荐电影或电视剧。
机器学习——今天与明天
我们要感谢从 20 世纪 80 年代开始的工作,约翰·霍普菲尔德和杰弗里·辛顿帮助奠定了机器学习革命的基础,这场革命自 2010 年左右开始。
我们现在目睹的这一发展得益于大量可用于训练网络的数据的获得,以及计算能力的极大提升。今天的人工神经网络通常规模庞大,由多个层构成。这些被称为深度神经网络,它们的训练方式称为深度学习。
快速浏览一下霍普菲尔德在 1982 年关于关联记忆的文章,可以让我们对这种发展有一个了解。文中,他使用了一个具有 30 个节点的网络。如果所有节点彼此连接,则会有 435 个连接。节点有它们自己的值,连接具有不同的强度,总共有不到 500 个参数需要跟踪。他还尝试了一个具有 100 个节点的网络,但由于当时使用的计算机过于复杂而无法处理。我们可以将其与今天的大型语言模型进行比较,后者由上亿个参数构建的网络组成。
现在,许多研究人员正在开发机器学习的应用领域。哪些应用会变得最有前景还有待观察,同时围绕这项技术的开发和使用也展开了广泛的伦理讨论。
由于物理学为机器学习的发展提供了工具,因此值得注意的是,作为研究领域的物理学也从人工神经网络中受益良多。机器学习长期以来一直被用于我们从以前的诺贝尔物理学奖中熟悉的领域。这些领域包括通过处理海量数据来发现希格斯粒子的使用;另一个应用包括减少测量来自碰撞黑洞的引力波中的噪声,或者寻找系外行星。
近年来,这项技术也开始被用于计算和预测分子和材料的性质——例如计算决定其功能的蛋白质分子的结构,或研究哪些新材料的版本可能具有最适合用于更高效太阳能电池的特性。
深入一些的诺奖官网介绍
https://www.nobelprize.org/uploads/2024/09/advanced-physicsprize2024.pdf
“为人工神经网络启发的机器学习奠定基础性发现与发明”
2024 年诺贝尔物理学奖由瑞典皇家科学院授予约翰·霍普菲尔德和杰弗里·辛顿,以表彰他们在人工神经网络(ANN)及其推动机器学习领域的基础性贡献。
引言
自 1940 年代起,以人工神经网络(ANNs)为基础的机器学习在过去三十年中发展成为一种多功能且强大的工具,既可以应用于日常生活,也可以应用于前沿科学领域。通过人工神经网络,物理学的边界被扩展到了生命现象和计算领域。
人工神经网络受到大脑中生物神经元的启发,包含大量“神经元”或节点,通过“突触”或加权连接来相互作用。它们被训练执行特定任务,而不是执行预定的指令集。其基本结构与统计物理学中应用于磁性或合金理论的自旋模型有着密切的相似性。今年的诺贝尔物理学奖表彰了利用这一联系在人工神经网络领域取得突破性方法进展的研究。
历史背景
20 世纪 40 年代,首批基于电子的计算机出现,最初是为军事和科学目的发明的,旨在完成对人类而言繁琐且耗时的计算。到 20 世纪 50 年代,出现了相反的需求,即让计算机执行人类及其他哺乳动物擅长的模式识别任务。
这种以人工智能为目标的尝试最初由数学家和计算机科学家发起,他们开发了基于逻辑规则的程序。直到 20 世纪 80 年代,这种方法仍在继续,但对于图像等的精确分类所需的计算资源变得过于昂贵。
与此同时,研究人员开始探索生物系统如何解决模式识别问题。早在 1943 年,神经科学家 Warren McCulloch 和逻辑学家 Walter Pitts 提出了一个大脑中神经元如何协作的模型。在他们的模型中,神经元形成了来自其他神经元的二进制输入信号的加权和,这决定了一个二进制输出信号。他们的工作成为后来研究生物和人工神经网络的出发点。
1949 年,心理学家 Donald Hebb 提出了学习和记忆的机制,即两个神经元的同时且重复的激活会导致它们之间突触的增强。
在人工神经网络领域,探索了两种节点互联系统的架构:“递归网络”和“前馈网络”。前者允许反馈交互,后者则包含输入层和输出层,可能还包括夹在中间的隐藏层。
1957 年,Frank Rosenblatt 提出了用于图像解释的前馈网络,并在计算机硬件中实现了这一网络。该网络包含三层节点,只有中间层与输出层之间的权重是可调的,并且这些权重以系统化的方式确定。
Rosenblatt 的系统引起了相当大的关注,但在处理非线性问题时存在局限性。一个简单的例子是“仅一种或另一种,但不能同时存在”的异或 (XOR) 问题。Marvin Minsky 和 Seymour Papert 在 1969 年出版的书中指出了这些局限性,这导致人工神经网络研究在资金方面陷入了停滞。
在这一时期,受磁性系统启发的并行发展,旨在为递归神经网络创建模型并研究其集体属性。
1980 年代的进展
20 世纪 80 年代,在递归神经网络和前馈神经网络领域都取得了重大突破,导致了人工神经网络领域的迅速扩展。
John Hopfield 是生物物理学领域的一位杰出人物。他在 20 世纪 70 年代的开创性工作,研究了生物分子之间的电子转移及生化反应中的错误纠正(称为动力学校对)。
1982 年,Hopfield 发表了一个基于简单递归神经网络的联想记忆模型。集体现象在物理系统中频繁出现,例如磁性系统中的畴结构和流体中的涡流。Hopfield 提出,是否在大量神经元的集体现象中会出现“计算”能力。
他注意到,许多物理系统的集体属性对模型细节的变化具有鲁棒性,他通过使用具有 N 个二进制节点 sis_is_i (0 或 1) 的神经网络来探讨这个问题。网络的动态是异步的,个别节点以随机时间进行阈值更新。节点 sis_is_i 的新值通过所有其他节点的加权和决定:
h\_i = \\sum\_{j \\neq i} w\_{ij} s\_j
如果 h\_i > 0,则设置 s\_i = 1,否则 s\_i = 0(阈值设为零)。连接权重 w\_{ij} 被认为是对存储记忆中节点对之间相关性的反映,称为 Hebb 规则。权重的对称性保证了动态的稳定性。静态状态被识别为存储在 N 个节点上的非局部记忆。此外,网络被赋予了一个能量函数 E:
E = - \\sum\_{i < j} w\_{ij} s\_i s\_j
在网络的动态过程中,能量单调递减。值得注意的是,早在 20 世纪 80 年代,物理学和人工神经网络之间的联系就通过这两个方程式显现出来。第一个方程可以用来表示 Weiss 分子场(由法国物理学家 Pierre Weiss 提出),描述了固体中原子磁矩的排列,第二个方程通常用于评估磁性配置的能量,例如铁磁体。Hopfield 很清楚这些方程在描述磁性材料中的应用。
比喻来说,这个系统的动态将 N 个节点驱动到一个 N 维能量景观的谷底,这些谷底对应于系统的静态状态。静态状态表示通过 Hebb 规则学习的记忆。最初,Hopfield 的动态模型中可以存储的记忆数量有限。在后来的工作中开发了缓解这一问题的方法。
Hopfield 使用他的模型作为联想记忆,也用作错误纠正或模式补全的工具。一个带有错误模式(例如拼写错误的单词)的系统会被吸引到最近的局部能量最低点,从而进行纠正。当发现可以通过使用自旋玻璃理论的方法来分析模型的基本属性(如存储容量)时,模型获得了更多的关注。
当时一个合理的问题是,这个模型的属性是否是其粗略二进制结构的产物。Hopfield 通过创建模型的模拟版本回答了这一问题,该版本具有由电子电路运动方程给出的连续时间动态。他对模拟模型的分析表明,二进制节点可以替换为模拟节点,而不会丢失原模型的集体属性。模拟模型的静态状态对应于在有效可调温度下的二进制系统的平均场解,并且在低温下接近二进制模型的静态状态。
Hopfield 和 David Tank 利用模拟模型的连续时间动态,开发出了一种求解复杂离散优化问题的方法。他们选择使用模拟模型的动态,以获得更“柔和”的能量景观,从而促进搜索。通过渐进减少模拟系统的有效温度,仿照全局优化中的模拟退火过程,进行优化。这种方法通过电子电路的运动方程积分求解优化问题,这期间节点不需要中央单元的指令。该方法是利用动力系统求解复杂离散优化问题的开创性例子之一,更近期的例子是量子退火。
通过创建和探索这些基于物理学的动力学模型,Hopfield 对我们理解神经网络的计算能力做出了基础性贡献。
玻尔兹曼机
1983-1985 年,Geoffrey Hinton 与 Terrence Sejnowski 及其他同事一起开发了 Hopfield 1982 年模型的随机扩展,称为玻尔兹曼机。玻尔兹曼机中的每个状态 s = (s\_1, ..., s\_N) 被赋予一个遵循玻尔兹曼分布的概率:
P(s) \\propto e^{-E/T}, E = - \\sum\_{i < j} w\_{ij} s\_i s\_j - \\sum\_{i} \\theta\_i s\_i
其中 T 是一个假想温度,\\theta\_i 是偏置,或局部场。
玻尔兹曼机是一种生成模型,与 Hopfield 模型不同,它专注于模式的统计分布,而非单一模式。它包含对应于要学习模式的可见节点,以及为了能够建模更一般的概率分布而引入的隐藏节点。
玻尔兹曼机的权重和偏置参数定义了能量 E,这些参数是通过训练确定的,使得模型生成的可见模式的统计分布与给定的训练模式的统计分布之间的偏差最小。Hinton 和他的同事们开发了一个形式优雅的基于梯度的学习算法来确定这些参数。然而,每一步算法都涉及为两个不同的集合进行耗时的平衡模拟。
尽管理论上很有趣,但在实践中,玻尔兹曼机的应用初期相对有限。然而,它的一个精简版本,称为限制玻尔兹曼机(RBM),发展成为一个多功能的工具(见下一节)。
Hopfield 模型和玻尔兹曼机都是递归神经网络。80 年代还见证了前馈网络(feedforward network)的重要进展。1986 年,David Rumelhart、Hinton 和 Ronald Williams 展示了如何使用一种称为反向传播的算法训练包含一个或多个隐藏层的架构来进行分类。这里的目标是通过梯度下降最小化网络输出与训练数据之间的均方偏差 D。这要求计算 D 相对于网络中所有权重的偏导数。Rumelhart、Hinton 和 Williams 重新发明了一个方案,该方案曾由其他研究人员应用于相关问题。此外,更重要的是,他们证明了具有隐藏层的网络可以通过这种方法进行训练,执行那些已知无法通过无隐藏层网络解决的任务。他们还阐明了隐藏节点的功能。
向深度学习迈进
80 年代的方法论突破很快带来了成功的应用,包括图像、语言和临床数据的模式识别。一个重要的方法是多层卷积神经网络(CNN),由 Yann LeCun 和 Yoshua Bengio 使用反向传播进行训练。CNN 架构起源于 Kunihiko Fukushima 创建的新认知网络方法,而这一方法受到 1981 年获得诺贝尔生理学或医学奖的 David Hubel 和 Torsten Wiesel 工作的启发。LeCun 和他的同事开发的 CNN 方法从 90 年代中期开始被美国银行用来分类支票上的手写数字。另一个成功的例子是 Sepp Hochreiter 和 Jürgen Schmidhuber 在 90 年代发明的长短期记忆法(LSTM),这是一种用于处理序列数据的递归网络,例如语音和语言,它可以通过时间展开映射为多层网络。
尽管 90 年代的一些多层架构取得了成功的应用,但训练具有许多层次之间密集连接的深层网络仍然是一项挑战。对许多该领域的研究人员来说,训练密集的多层网络似乎遥不可及。这一局面在 2000 年代发生了变化。Hinton 是这一突破的领导者,RBM 是其中的重要工具。
RBM 网络只有可见节点与隐藏节点之间的权重,而同类节点之间没有权重。对于 RBM,Hinton 创造了一种高效的近似学习算法,称为对比散度,该算法比全玻尔兹曼机的算法快得多。随后,他与 Simon Osindero 和 Yee-Whye Teh 一起开发了一种逐层预训练多层网络的方法,每层网络使用 RBM 进行训练。该方法的一个早期应用是自动编码器网络,用于降维。经过预训练后,可以使用反向传播算法进行全局参数微调。通过 RBM 预训练可以在没有标记训练数据的情况下提取数据中的结构,如图像中的角。这些结构被识别后,通过反向传播进行标记变得相对简单。
通过这种方式连接预训练的层,Hinton 成功实现了深层和密集网络的示例,这是迈向如今深度学习的一个里程碑。后来,其他方法可以替代 RBM 预训练,达到相同的深层和密集人工神经网络的性能。
人工神经网络作为物理学和其他科学领域的强大工具
前文主要讨论了物理学是如何推动人工神经网络的发明和发展的。反过来,人工神经网络正日益成为物理学中建模和分析的强大工具。
在一些应用中,人工神经网络被用作函数逼近器,即人工神经网络被用来为所研究的物理模型提供一个“复制品”。这可以显著减少所需的计算资源,从而允许以更高的分辨率研究更大的系统。通过这种方式取得了显著进展,例如量子力学多体问题。深度学习架构被训练来重现材料的相的能量以及原子间力的形状和强度,达到与从头量子力学模型相当的精度。通过这些经过人工神经网络训练的原子模型,可以更快地确定新材料的相稳定性和动态特性。成功应用这些方法的例子包括预测新的光伏材料。
通过这些模型,还可以研究相变以及水的热力学性质。同样,人工神经网络表示的发展使得在显式物理气候模型中达到更高的分辨率成为可能,而不需要额外的计算能力。
人工神经网络在粒子物理学和天文学中的应用
在 90 年代,人工神经网络(ANNs)成为了复杂度日益增加的粒子物理实验中的标准数据分析工具。例如,像希格斯玻色子这样极为稀有的基本粒子只在高能碰撞中短暂存在(例如希格斯玻色子的寿命约为 10−2210^{-22}10^{-22} 秒)。这些粒子的存在需要通过探测器中的轨迹信息和能量沉积来推断出来。通常,预期的探测器信号非常罕见,并且可能被更常见的背景过程所模仿。为了识别粒子的衰变并提高分析效率,人工神经网络被训练来从大量快速生成的探测器数据中挑选出特定的模式。
人工神经网络提高了 90 年代在欧洲核子研究中心(CERN)的大型电子-正电子对撞机(LEP)上寻找希格斯玻色子的灵敏度,并在 2012 年 CERN 的大型强子对撞机(LHC)上发现希格斯玻色子的分析中发挥了作用。人工神经网络也用于费米实验室的顶夸克研究中。
在天体物理学和天文学中,人工神经网络也成为了标准的数据分析工具。一个最近的例子是利用南极 IceCube 中微子探测器的数据进行神经网络驱动分析,从而生成了银河系的中微子图像。开普勒任务利用人工神经网络识别了系外行星的凌日现象。银河系中心黑洞的事件视界望远镜图像也使用了人工神经网络进行数据处理。
到目前为止,使用深度学习人工神经网络方法取得的最为显著的科学突破是 AlphaFold 工具的开发,它可以根据氨基酸序列预测蛋白质的三维结构。在工业物理和化学建模中,人工神经网络也日益发挥重要作用。
人工神经网络在日常生活中的应用
基于人工神经网络的日常应用清单非常长。这些网络支持了几乎所有我们在计算机上所做的事情,例如图像识别、语言生成等等。
在医疗保健中的决策支持也是人工神经网络的一个成熟应用。例如,最近的一项前瞻性随机研究表明,使用机器学习分析乳腺X线照片显著改善了乳腺癌的检测率。另一个最新的例子是用于磁共振成像(MRI)扫描的运动校正技术。
结语
Hopfield 和 Hinton 所开发的开创性方法和概念在塑造人工神经网络领域方面发挥了关键作用。此外,Hinton 还在推动深度和密集人工神经网络方法的发展中起到了主导作用。
他们的突破,建立在物理科学的基础上,为我们展示了一种全新的方式,利用计算机来帮助我们解决社会面临的诸多挑战。简单来说,得益于他们的工作,人类现在拥有了一种全新的工具,能够用于良好的目的。基于人工神经网络的机器学习正在彻底改变科学、工程和日常生活。该领域已经在为构建可持续社会的突破铺平道路,例如帮助识别新的功能材料。深度学习和人工神经网络的未来使用,取决于我们人类如何选择使用这些已经在我们生活中扮演重要角色的强大工具。