Web3 的三种信任来源:从信任人到信任数学、社区和经济
**Web3 最大的两个优势是通证经济(tokenomics)和信任(trust)。**通证经济解决的是利益分配的问题。这篇文章主要讲信任问题。
**传统 Web2 的信任本质上是对人的信任。**我敢把数据放在苹果和谷歌,是因为我相信苹果和谷歌不会出售我的数据。我敢在脉脉上匿名吐槽公司,是因为我相信脉脉不会把我的身份信息泄露。但显而易见的是,在利益面前,人并不是那么可信的。
Web3 能够如何更好地解决信任问题?我认为,Web3 的信任有三大来源:密码学信任(Cryptographic Trust)、去中心化信任(Decentralized Trust)和经济学信任(Economic Trust)。
密码学信任的本质是信任数学,去中心化信任的本质是信任大多数人不会串通起来作恶,经济学信任的本质是信任大多数人不会做亏本的买卖。因此,这三种信任是可靠性递减的。
那为什么不只用密码学信任呢?因为很多问题是单靠密码学信任无法解决的。这三种信任虽然可靠性递减,应用范围却是递增的。
接下来,我们就逐一介绍这三种信任。
密码学信任
- **如何既不透露我是谁,又能证明我的身份?**例如,脉脉需要验证我是某家公司的成员,但我又不希望把我的确切身份告诉脉脉,这可能吗?
- **有随机性的在线游戏如何保证公平性?**例如,一个德州扑克的游戏平台如何证明自己的发牌是绝对公平的,没有庄家在悄悄看牌?
很多朋友可能觉得这只能找一个可信的第三方了,这当然是一种可行方案。但在密码学的帮助下,不依赖第三方的密码学信任(cryptographic trust)是可能的。
验证却不透露信息
比如网站希望验证用户拥有某一机构的邮箱,网站却又不希望知道用户的确切邮箱地址,就可以用 ZK Email 的方法实现。
我们知道邮件都是有 DKIM 签名的,那么只需提供任何一封收到的邮件的 DKIM 签名,就可以证明我拥有该邮件收件人的邮箱地址。但直接提供 DKIM 签名和邮件内容仍然会泄露具体邮箱地址,因此还需要用 ZK(零知识证明)的方法,根据这个 DKIM 签名生成一个零知识证明。
零知识证明(Zero-Knowledge Proof)顾名思义就是在不透露一个知识的情况下证明我知道这个知识。它的本质是把验证 DKIM 签名、验证邮件收件人属于某一组织的算法做成一个混淆电路,然后把加密的邮件内容和 DKIM 签名输入到这个混淆电路,这个混淆电路就可以输出验证结果(是或否)。网站拿到这个零知识证明,就知道这个人持有这个机构的邮件地址,但不知道持有的是哪个邮件地址。
零知识证明几年前还只是学术界和少数极客折腾的玩具,如今已经被广泛应用,今年 Polyhedra 和 zkSync 两家零知识证明领域的龙头公司相继上市,市值都超过 10 亿美金。
其实零知识证明在日常生活中也有很多应用。比如发朋友圈的时候,如何证明我上过中科大,却又不说出中科大的名字?那就可以说一个只有中科大人知道的梗,比如 “废理兴工” “三十,校友,一样”,这就像是对暗号。当然,这种方法在数学上是不严格的,数学上的零知识证明可以做到不泄露任何信息。
保证公平
密码学信任的另外一个场景是保证算法的公平性。
比如运营一款在线游戏,如何保证我的洗牌是公平的,没有偏袒某个玩家(公平洗牌问题),也没有把其他玩家的牌面信息悄悄告诉某个玩家(隐蔽发牌问题)?
**多方安全计算和零知识证明可以解决上述两个问题。**首先每个玩家生成一对公私钥。洗牌的时候,每位玩家都对初始状态用自己的私钥加密,这样相当于把箱子上了三把锁。用同态加密的方法,可以在密态下执行计算,完成随机洗牌,相当于摇晃上锁的箱子,把里面牌的顺序摇乱。在发牌的时候,每个玩家需要按照加密的顺序,依次用自己的私钥解密,得到属于自己的牌的信息,并发布一个零知识证明证实自己确实看过了牌(这是为了防止事后抵赖)。
由于解开锁的顺序是固定的,每个玩家只能解密出自己的牌,不能看到其他玩家的牌。平台方由于是在密态下进行计算,不能看到任何人的牌,并且每个玩家都可以验证这个洗牌过程是公平的。
更高效的 TEE
密码学的零知识证明和多方安全计算最大的缺点是执行效率低,一个本来需要一秒钟执行的代码,用零知识证明的方法,可能要一个小时。而基于零知识证明的公平发牌算法开销就更高了,发牌算法稍微复杂一些,或者参与人数多一些(10 个人以上),复杂度就会快速上升。
另外一类可信计算技术 TEE(Trusted Execution Environment,可信执行环境)可以弥补零知识证明执行效率的不足。TEE 是把对数学的信任转移到了对硬件厂商的信任,比如 Intel、AMD、NVIDIA。早期的 TEE 确实经常出现一些漏洞,导致一些人对 TEE 不够信任,但今天的 TEE 技术已经显著发展,不再有那些低级的漏洞了。
TEE 可以达到两个目的,第一是防止有物理接触服务器权限的人窃取秘密,例如云服务商和数据中心;第二是证明我执行的确实是这一份代码,没有造假。
比如前面提到的在线游戏例子,TEE 可以生成一个签名,证明硬件执行的确实是这个没有篡改过的发牌算法。其他人如果不信,就拿相同的代码在同款硬件环境上再跑一遍,TEE 生成的签名一致,就证明硬件的初始状态是一致的,跑的确实是同一份代码。
隐私计算:Web3 比现实世界更火
2019 年左右,以密码学信任和 TEE 为核心技术的隐私计算就迎来了一波热潮。隐私计算公司最常见的应用案例就是数据拥有方和技术提供方之间不需要互相传输明文数据,就可以合作完成数据处理。
例如,医院想用 AI 算法辅助诊断,医院不想把病人的数据交给搞 AI 的公司,而搞 AI 的公司也不想把自己的算法交给医院。使用隐私计算方法,就可以保证双方在不泄露各自机密的前提下完成 AI 辅助诊断。
**但隐私计算在现实中的应用场景一直比较受限。因为很多公司更愿意相信人,而不是相信技术。**他们会说,任何算法在系统实现中都是有漏洞的,如果人不可信,那么往隐私计算系统里面插入后门,也很难被发现。此外,很多公司的隐私保护只是为了法律合规和公共形象,真到为多方安全计算技术付出真金白银的时候,就不一定愿意了。
**隐私计算技术本来是为了解决现实世界中的信任而生,但在 Web3 这个数字世界中反而取得了更多的应用。**如今市面上最火的 Web3 公司,一多半的核心技术都是隐私计算。Web3 甚至成了密码学博士的首选就业去向。这大概是因为 Web3 世界更注重匿名性和隐私,而且更信仰代码而非人性。
去中心化信任
**密码学信任可以解决验证的问题,但不能解决抵赖的问题。**比如,我玩一个游戏通关了,得到了一个道具,睡了一觉起来发现道具不见了,我该如何找游戏公司说理,证明我曾经取得过这个道具?现实中这种抵赖问题往往带来无穷无尽的扯皮。
**解决抵赖的方法就是信息公开,让所有人都能查到完整的历史。**结合上文中零知识证明的方法,可以实现既不暴露隐私,又能在历史中记录自己做过某事。
把信息公开到一个网站上固然可行,但怎么保证这个网站的信息不会被篡改呢?怎么保证这个网站不会某一天突然被 404 呢?
分布式账本
解决这个问题的方法就是分布式账本,它可以构建去中心化信任(decentralized trust)。分布式账本最有名的例子就是比特币。随后诞生的以太坊和各种 Layer-2、Layer-1,都是在解决分布式账本的各种问题,如运行智能合约、延迟高、吞吐量低等。
我博士是研究系统的,很多搞系统的资深专家就经常吐槽区块链。比如微软研究院的一些资深专家就说,比特币刚出来的时候,他们很快就看到了这篇 paper,然后说这是什么破玩意,10 分钟才出一个块。不管哪个分布式系统,只要写操作的延迟高达 10 分钟,一定不会有任何人用这个系统。针对分布式账本的问题,拜占庭容错算法已经发展这么多年了,拜占庭问题的提出人、图灵奖得主 Leslie Lamport 还在微软研究院,哪个拜占庭容错算法不比比特币的效率高?
这种论调忽略了比特币最大的价值在于构建去中心化信任。比特币区块链被世界上众多的节点复制了很多份,只要大多数人没有串通起来一起作恶,分布式账本中记录的历史就不会被篡改。比特币还通过工作量证明(Proof of Work,俗称挖矿)解决了经济动机的问题。这些节点有什么动机记录整个分布式账本,并且不停地同步最新变更呢?用爱发电长期来看是不行的,工作量证明就是它的创新。
以太坊改进了比特币的设计,并提出了 “世界计算机” 的设想,智能合约就是一段通用程序,整个世界就是一个计算机。理论上来说,用 gas 费对算力计费是一个绝妙的 idea。但实际上以太坊主网的性能仍然很有限,导致交易费和 gas 费都很高,普通的计算根本烧不起。
2017 年,我们搞系统的一群博士生拿着以太坊的白皮书就开喷,纷纷嘲笑这个 “世界计算机” 效率低下。但现实恰恰是效率低下的以太坊智能合约解决了去中心化信任问题,币价一路飙升,而我们在学术界做的每秒能做十亿次交易、理论上号称一台机器撑起 12306 的高性能系统却无人问津。
Git:区块链的思想先驱
事实上,通过区块链构建去中心化信任,远远不是各种代币专有的。
**2005 年诞生的版本管理工具 Git 很可能是区块链思想的先驱。**Git 采用签名组成一条链的方式,保证代码修改历史难以被篡改。在一些公开项目的 Git 仓库中,commit 是要作者或者代码审核者签名的。一个恶意的人无法在 Git 历史中插入、删除或者篡改一个 commit,却保持后面所有 commit 的 hash 和签名不变。
因此,只要记住了一个 commit 的 hash,就意味着它之前的代码修改历史不会被篡改;或者即使没有记住 commit hash,只要一个 commit 后面有足够多不同人签名过的 commit,该 commit 之前的历史就很难被篡改,因为这意味着需要其后所有签名过的人串通起来篡改历史。
鲜为人知的证书透明度日志
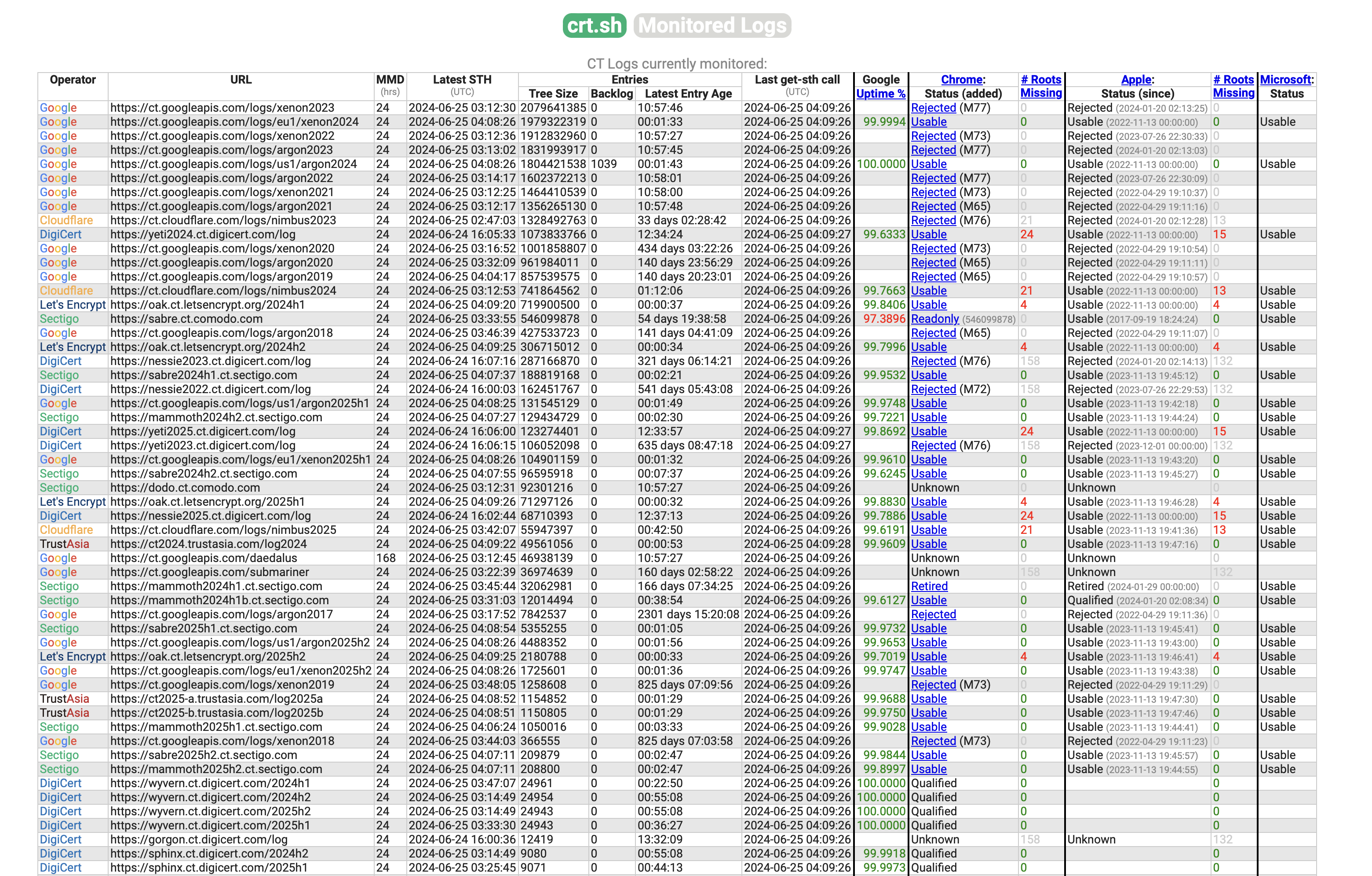
**证书透明度(Certificate Transparency)是通过区块链构建去中心化信任的一个很好的例子。**它尽管没有标榜自己是区块链,只说是一个日志(log),但事实上几乎就是一条联盟链。
今天的绝大多数网站都使用 TLS 证书验证网站的身份,而 TLS 证书是 CA(Certificate Authority)签发的。那么如果我掌控了一家 CA 或者入侵了一家 CA,是不是就可以给任意的网站签发证书,进而仿冒任何网站了?
**这种 CA 作恶的事情不只是理论上存在,而是现实中发生过的。**因此 2013 年,谷歌发起了证书透明度机制,要求所有 CA 签发的证书必须记录到一条只允许追加的链上。后来越来越多的公司加入证书透明度日志,每个公司都成为这条链的一个验证节点。这样除非所有公司联合起来作恶,就没有办法篡改已经签发的证书。
那么浏览器是如何验证一个证书是否有效呢?证书在添加到链上时,验证节点会对证书进行签名,并附加到证书上,相当于除了 CA 以外,还有至少另外两个公司的验证节点给这个证书盖了章。浏览器不仅要验证 CA 签名的有效性,还要验证证书透明度节点的签名。三个公司一起作恶的概率就很低了。
 证书透明度日志
证书透明度日志
证书透明度日志自 2013 年以来,已经记录了超过 84 亿张证书。相比之下,比特币区块链才刚刚超过 10 亿笔交易,以太坊主网也只有 23 亿笔交易。**目前,证书透明度日志平均每秒都会添加上百张证书,远远超过比特币和以太坊主网的交易次数(每秒十几次)。**当然,Solana 之类主打高性能的 Layer-1 可以达到每秒 3000 次交易以上,但 Solana 是中心化的。
**证书透明度还是 Google 搜集全世界信息的一个阳谋。**一些公网可访问,但需要员工登录的内部网站,也能在 Google 上检索到首页,虽然它的内容是空的。这些网页在公网上基本上是不可能有链接的,那么 Google 是怎么索引到它们的呢?其中一个信息源可能就是证书透明度日志。一个网站只要申请了 TLS 证书,就会立刻被记录在案,Google 的爬虫就可以发现这个网页。
由于证书透明度日志是公开的,我也利用它发现了很多公司尚未发布的产品。**例如 OpenAI 的 Sora 在发布前两天就已经上线了 sora.openai.com,GPT-4o 在发布前一个月就上线了 webrtc.chatgpt.com,懂行的人一看就知道是用来做实时语音聊天的。**这甚至都不需要自己同步一份证书透明度日志,crt.sh 就提供了公开查询。
我在华为面试的时候,经常问候选人关于 TLS 的问题。很多搞网络的人都能大致说清楚 TLS 协议的工作原理。但涉及到 PKI 机制,就知道的不多了。听说过证书透明度的候选人更是一个都没有。确实有很多 Internet 至关重要的基础设施,对大多数程序员来说是鲜为人知的。
永不丢失的信息
如果我想把一些信息永久公开,保证 300 年内不会丢失,该怎么做呢?
我写过这样一个知乎回答,摘录如下。
GitHub Archive Program
最简单的:GitHub Archive Program,只要是 2019 年 11 月到 2020 年 2 月间至少有一次 commit、一个 star 的 repo,或者至少 250 个 star 的 repo,就会进入 GitHub Archive Program,被刻到强化胶卷上,放到挪威的北极存储仓库,至少能保存千年。
印成书、刻到石头上
次简单的:印成书。首先导出成 PDF,然后在某宝上找个印书的就行了,书籍保存得好的话 300 年不是问题。
(刻到石头上是比印到书上更持久的保存方式,几千年都问题不大,但我还不想给自己树碑,立生祠)
(我也刻成光盘保存了,但是光盘的寿命达不到题主要的 300 年。磁带虽然是很好的备份介质,但一般寿命也到不了 300 年。)
存储在区块链公链里
现在开始提难度了:把信息存储在公开的区块链公链里面,比如以太坊之类的公链,需要付出的就是一些 gas 费,但我觉得 300 年之后以太坊这样的公链仍然是不会消亡的。这种信息存储方式虽然成本较高,相当于是让所有参与公链的节点都帮你存了一份拷贝,但是相比印成书或者刻成石头的方案,信息随时可以提取出来。
隐写在论文里
**更难一点的:把信息隐写在自己发表的论文里面。**IEEE、ACM 的论文数据库很可能在 300 年后仍然保存完好,可以随时查阅。而一篇发表的论文往往少则 1 MB,多则 10 MB,可以放下很多 “无关信息”。不管是利用 PDF 的注释功能直接嵌入信息,还是在论文图片的频域中隐写信息,都可以把这些数据藏在自己发表的论文里,论文越经典,信息丢掉的概率就越低。
保存在大模型里
**更难的:保存在大模型里。**大模型的训练语料来自公开互联网,如果你要保存的信息已经在公开互联网上随处可见,那么大模型很可能已经学到你想要保存的信息。但题主要保存的是自己的私密日记,公开互联网上估计没有,那么就需要写一些 Wikipedia 条目。Wikipedia 在各种大模型训练数据中的权重都很高。
当然,这就是以信息的公开为代价换取了信息的持久保存。如果不想公开,那可以用暗语之类的方法把日记重写一遍。
300 年之后,不管世界的主人是人类还是 AI,大模型都将是世界上不可或缺的一部分。来自初代大模型的信息,一定不会被轻易丢弃。
在星际无线电波中游荡
**Top 级难度:保存在星际无线电波里。**我们搞网络的有一个技巧:当网络的端点保存不下数据时(比如临时拥塞),就让这些数据在网络里面打转。就像机场降落的跑道紧张时,天上的飞机就要在机场附近打转。在空中传播的无线电波也可以是存储信息的媒介,但提取信息的难度非常大,已经超过了人类目前科技的极限。
以太坊区块链是最简单实用的方案
在以上这些方案中,以太坊区块链是最简单实用的。
我的朋友就做了一个 Ethernote,连接上自己的钱包就可以写日记。Ethernote 把日记本的数据保存在智能合约的 CallData 里面,由于智能合约内部不可读,存储成本较低,每保存一个字节只需要 16 gwei 的 gas 费(准确的说是每 32 字节 512 gwei),按照今天的以太坊币价,20K 字节才需要 1 美元。
 Ethernote 界面
Ethernote 界面
Ethernote 不需要数据库,只要有一个以太坊全节点(full archive node)的 JSON RPC URL,就可以查询到并解码出这些智能合约中记录的内容。当然,查询效率肯定没有数据库高。因此,商业项目一般是有个数据库用于服务用户的网页 API 请求,另外跟区块链同步以保证数据不会丢失,且不会被篡改。
经济学信任
在密码学信任、去中心化信任都不能解决问题的时候,经济学信任(Economic Trust)就该出场了。经济学信任其实就是惩罚恶意行为,这一般通过 staking/slashing(质押/罚没)机制来实现。
所谓 staking,就是质押一部分币到智能合约里。所谓 slashing,就是在发现恶意行为时,由社区多数人投票或者由算法判定,智能合约自动没收质押的币,实现经济惩罚。
如果没有 slashing 机制,参与者诚实行动的动机就仅仅依靠代币毒性。所谓代币毒性就是一旦一个协议被攻击成功,其代币的价值就会大大降低,进而参与者质押的资产就损失了。代币毒性并不是一个好的经济学信任机制,因为代币贬值对好节点和坏节点的惩罚相同,考虑到坏节点可能收受了贿赂,就会出现坏节点驱逐好节点的情况。
算法判定恶意行为
最经典的 staking/slashing 协议就是以太坊的 PoS(Proof of Stake)机制。在以太坊 PoS 中,当验证者(validator)作出与大多数其他验证者一致的投票时,当验证者提议区块时,以及当验证者参与同步委员会时,他们会收到奖励。如果一个验证者行动缓慢,没有及时参与投票,那么就无法及时领取到这一区块的奖励。
**Slashing(罚没)是针对有明显恶意行为的验证者。**例如,在同一时隙提议或签名两个不同的区块;试图生成一个包围其他区块的新区块,以更改历史;通过证明同一个区块的两名候选人进行 “双重投票”。如果这些行为被检测到,验证者就会被罚没。1/32 的质押将被立即销毁,然后验证者的质押将在为期 36 天的移除期内逐渐流失。
在以太坊的 slashing 机制中,由于恶意行为很容易被算法自动发现,2020 年 PoS 正式启用以来,被罚没的验证者仅占总验证者的不到千分之一。经济学信任虽然不能杜绝恶意行为,但可以通过惩罚尽量减少恶意行为。
**Slashing 机制可以大幅加大尝试贿赂攻击的腐败成本。**在以太坊协议中,贿赂成本必须达到所有验证者质押总额的三分之一,才可能攻击成功。
投票判定恶意行为
另外一些涉及人类行为的系统中,单靠算法并不能判定恶意行为。例如在一个链上游戏中,是否存在两个玩家私下里串通,这是算法很难判断的。
这种情况下,就需要社区来举报恶意行为,并通过投票来判定恶意行为。为了防止 Sybil attack(生成大量匿名账户参与投票的攻击),一般来说投票的份额与质押金额成正比。这就是彻底的谁更有钱谁就说了算。由于持有一种代币很多的人一般不希望币价下跌,就会更希望维护社区公平。
当然,简单根据质押金额会导致恶意用户买入并质押大量代币获取投票权,进行恶意投票后,又马上取消质押并出售代币。这对社区投票生态将造成严重影响。因此,很多社区将质押代币数量与质押时间的乘积作为投票权,这样就鼓励希望参与社区治理的用户长期质押代币,不仅可以降低抛压稳定币价,还可以避免短期质押的攻击。
基于质押的交易
淘宝和各种中介平台本质上都是基于质押的交易。交易双方之所以敢在平台上交易,是因为对平台的信任。当然,交易双方也需要为这种信任支付佣金或者中介费。
**如果交易的整个过程都可以在区块链上追溯,那么中介平台就可以被智能合约取代。**智能合约可以在数学上保证是公平的,交易双方只需支付少量的交易费用,不再需要信任平台。目前这种方式在现实世界中的应用还主要限于有一定信任基础的联盟链,主要原因是大多数现实世界交易的过程没有做到在区块链上可追溯。
现实世界和区块链世界的接口永远是最薄弱的一环,就像人永远是所有网络中最容易被攻击的一环。当无法做到绝对可信的时候,就是经济学信任发挥价值的地方。只要破坏信任的代价远远高于攻击它能带来的潜在收益,攻击发生的概率就会大大降低。
结语
在 Web3 诞生之前,如果人完全不可信,就很容易陷入囚徒困境。Web3 自诞生之初就是匿名的,就更是一个黑暗森林,到处都是带枪的猎人。
之所以 Web3 没有陷入囚徒困境,就是因为 Web3 通过密码学信任、去中心化信任和经济学信任三大机制,从对个人和公司的信任转移到对数学的信任、对大多数人不会同时作恶的信任、对经济利益的信任。
《三体》里面的黑暗森林假说基于两大基本公理和猜疑链、技术爆炸两大基本假设。基本公理包括:(1)生存是文明的第一需要,(2)文明不断增长和扩张,但宇宙中的物质总量保持不变。猜疑链假设是双方无法判断对方是否为善意文明。技术爆炸假设是文明进步的速度和加速度不见得是一致的,弱小的文明很可能在短时间内超越强大的文明。在这四条基本假设下,不暴露自己是最好的选择。
但 Web3 世界中,第二条基本公理和猜疑链、技术爆炸都是不成立的。一种代币之所以值钱,就是因为社区共识,这跟所有货币和等价物是一样的。越多人参与到一个协议中,这个协议的总价值就越高。因此这不是一个零和游戏,第二条基本公理不成立。密码学信任、去中心化信任、经济学信任都是从不同的角度解决猜疑链的问题。而技术爆炸在现实世界中是不存在的,如果一个人掌握了破解椭圆曲线的算法,那么整个区块链的信任基础都不复存在了。因此,Web3 世界不但没有像《三体》一样出现信任危机,效率还比 Web2 世界的传统经济更高。
由于大多数公众不理解数学,协议设计和代码实现中也容易存在漏洞,目前 Web3 信任还基本是极客圈子里的游戏,尚未被普罗大众接受。甚至一些 Web3 行业的从业者都说不清楚这三种信任的区别。还有的人说,trustless(无信任)是人类文明的倒退。
华为的管理精髓之一就是 “基于不信任的管理”。我第一次听到这个说法的时候还挺反感,怎么能不信任公司的员工呢?一位商界大佬也说,一开始创业他总是把人性想得太好,没有一开始就把流程制度设计完善,结果做大了之后就出了很多问题。他听了任总讲的基于不信任的管理,感觉醍醐灌顶。Google 一直在推行的也是 Zero Trust(零信任)的安全模型。零信任事实上是西方管理体系的重要理念,其关键就是通过流程化管理使企业的运行摆脱对人的依赖。
Web3 的三大特征是 trustless(无信任),permissionless(无门槛)和 decentralized(去中心化)。Trustless 不是字面意义的没有信任,而是从信任人进化成了信任数学、社区和经济。信任的进化一定会成为人类文明的一个重要里程碑。