Chatbot Arena:基于社区评价的大模型评测基准
(本文首发于知乎回答:《目前大语言模型的评测基准有哪些?》)
必须吹一波我们 co-founder @SIY.Z 的 Chatbot Arena 呀!
Chatbot Arena 是基于社区评价的大模型评测基准。上线一年来,Chatbot Arena 已经有超过 65 万次有效用户投票。
Chatbot Arena 见证大模型的快速进化
最近的一个月,我们在 Chatbot Arena 上见证了几件非常有趣的事情:
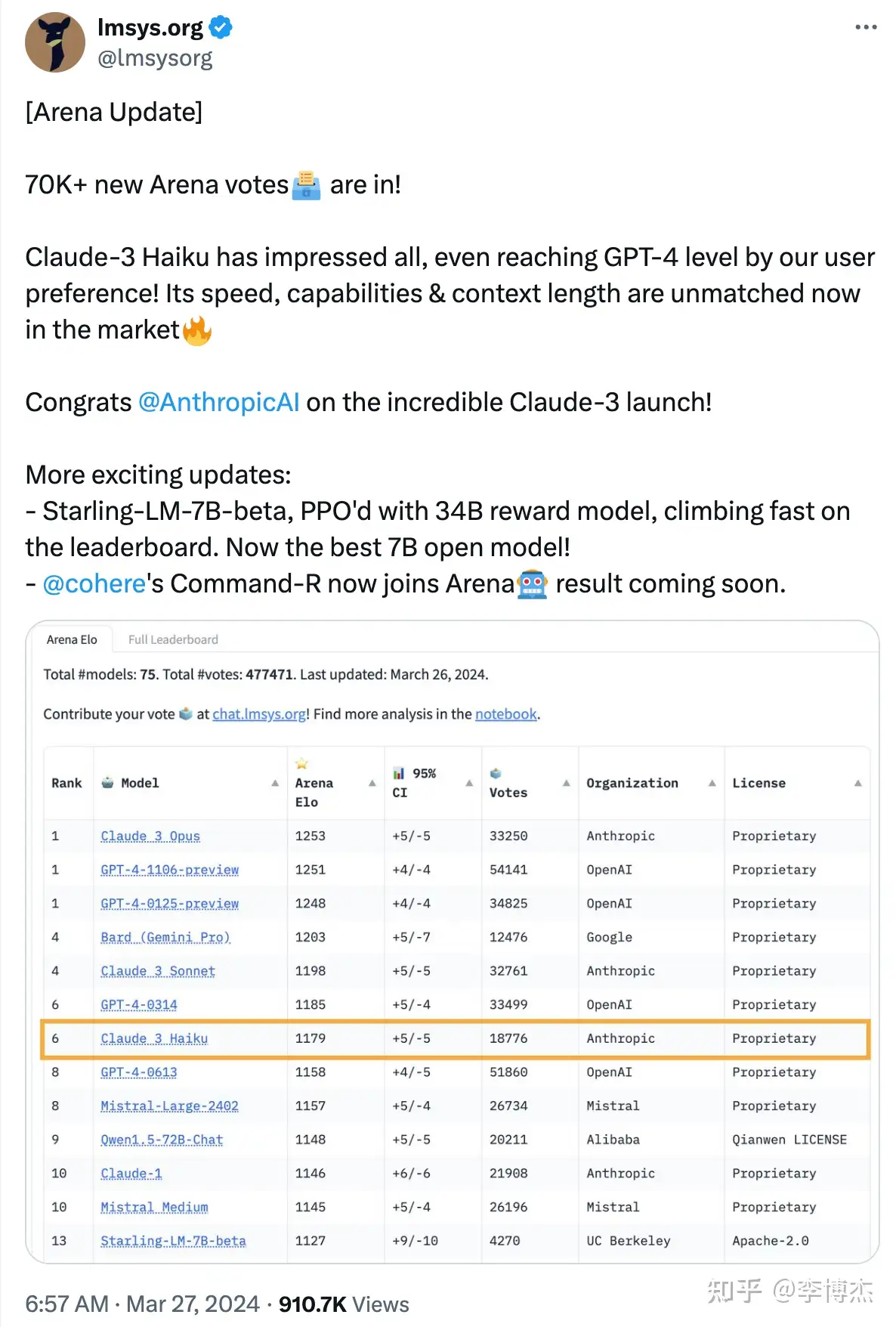
- Anthropic 的 Claude-3 发布,大杯 Opus 模型的性能超越了 GPT-4-Turbo,中杯 Sonnet 和小杯 Haiku 模型的性能也追平了 GPT-4。**这是 OpenAI 以外的公司首次夺得排行榜的首位。**Anthropic 的估值已经 $20B,直逼 OpenAI 的 $80B 了,OpenAI 是应该有点危机感了。
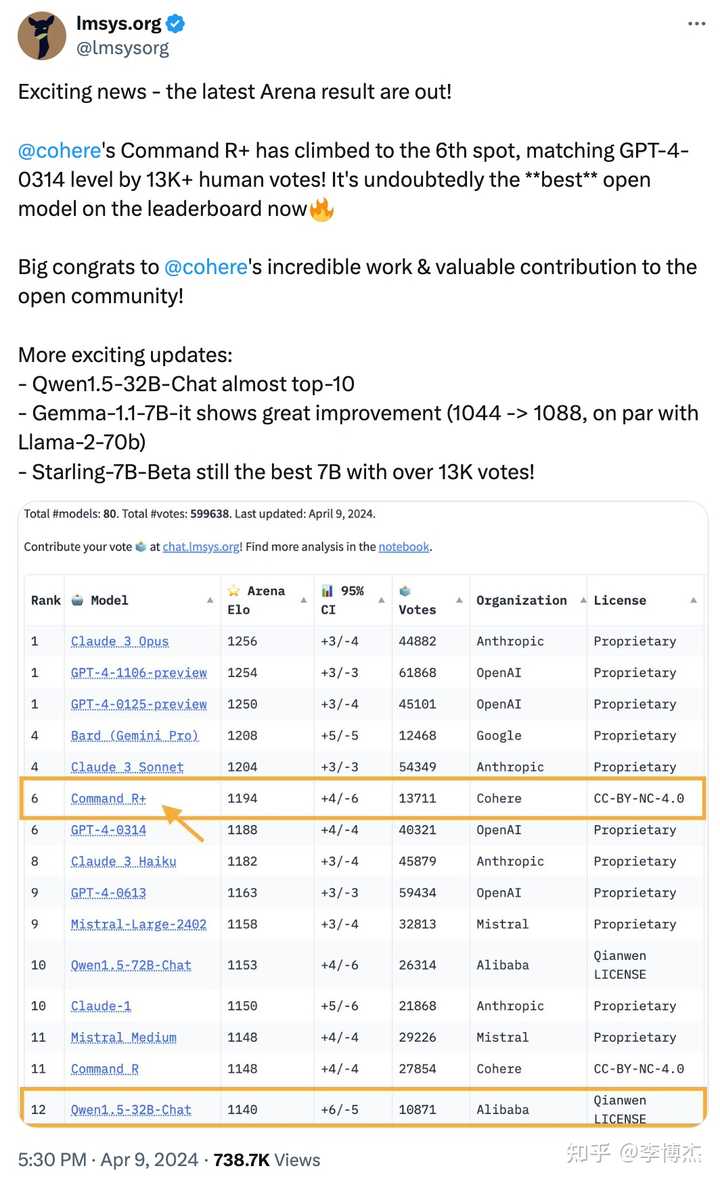
- Cohere 发布了迄今最强的开源模型 Command R+,104B 模型的性能追平 GPT-4,当然跟 GPT-4-Turbo 还有一定差距。我今年年初接受甲子光年采访的时候提出了 2024 年大模型四大趋势(《AI 一天,人间一年:我与 AI 的 2023|甲子光年》):“多模态大模型能够实时理解视频,实时生成包含复杂语义的视频;开源大模型达到 GPT-4 水平;GPT-3.5 水平开源模型的推理成本降到 GPT-3.5 API 的百分之一,让应用在集成大模型的时候不用担心成本问题;高端手机支持本地大模型和自动 App 操控,每个人的生活都离不开大模型。” 第一个是 Sora,第二个是 Command R+,都已经应验。我还是重复这个观点,如果一家主要做基础模型的公司 2024 年还训练不出 GPT-4 的话,就不用再折腾了,浪费了大量算力,最后连开源模型都比不上。
- 通义千问发布了 32B 开源模型,几乎可以达到 top 10,不管中文英文都很能打。32B 模型在成本上的杀伤力还是很强的。
- OpenAI 被 Anthropic 的 Claude Opus 超过了,自然也不示弱,马上发布了 GPT-4-Turbo-2024-04-09,又夺回了排行榜上第一的宝座。不过 OpenAI 迟迟没有发布 GPT-4.5 或者 GPT-5,而且大家期待的多模态模型一直没有出来,这是有点令人失望的。
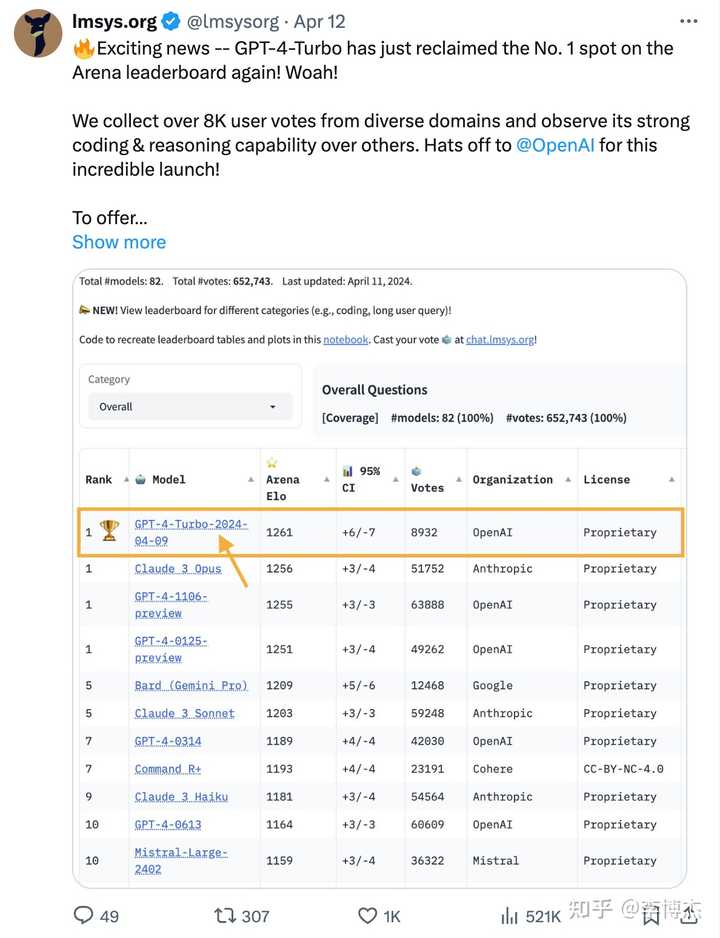
Chatbot Arena 的权威性
那这个 Chatbot Arena 到底有多少权威度,是不是自娱自乐呢?OpenAI、Google 都转发过 Chatbot Arena 的 Twitter 来佐证各自大模型的性能。国内公司比较少引用 Chatbot Arena 的评测结果,我跟相关的朋友也聊过,主要是合规原因,担心海外平台上用户生成的内容不受控。
OpenAI 的主席和联合创始人 Greg Brockman 去年 11 月 18 日被开除前的最后一条 Twitter 就是转发的 Chatbot Arena,当时 GPT-4-Turbo 刚刚超越 GPT-4 成为排行榜的第一名。发完这条 Twitter 之后十几分钟,他就被董事会开除了。因此大量的人跑去问 Chatbot Arena 背后的 LMSys(UC Berkeley 的学术组织),OpenAI 的宫斗跟他们有什么关系。其实就是一个巧合,完全没有关系。
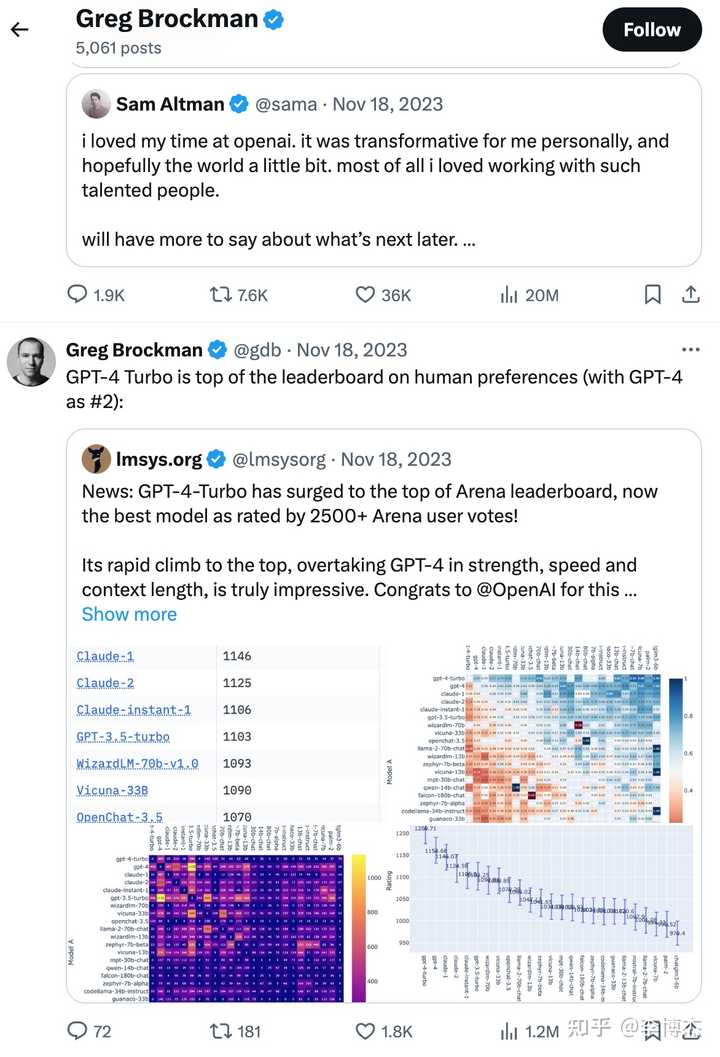
Google 的 Jeff Dean 在发布 Gemini Pro 的时候,也引用了 Chatbot Arena 的排行榜。
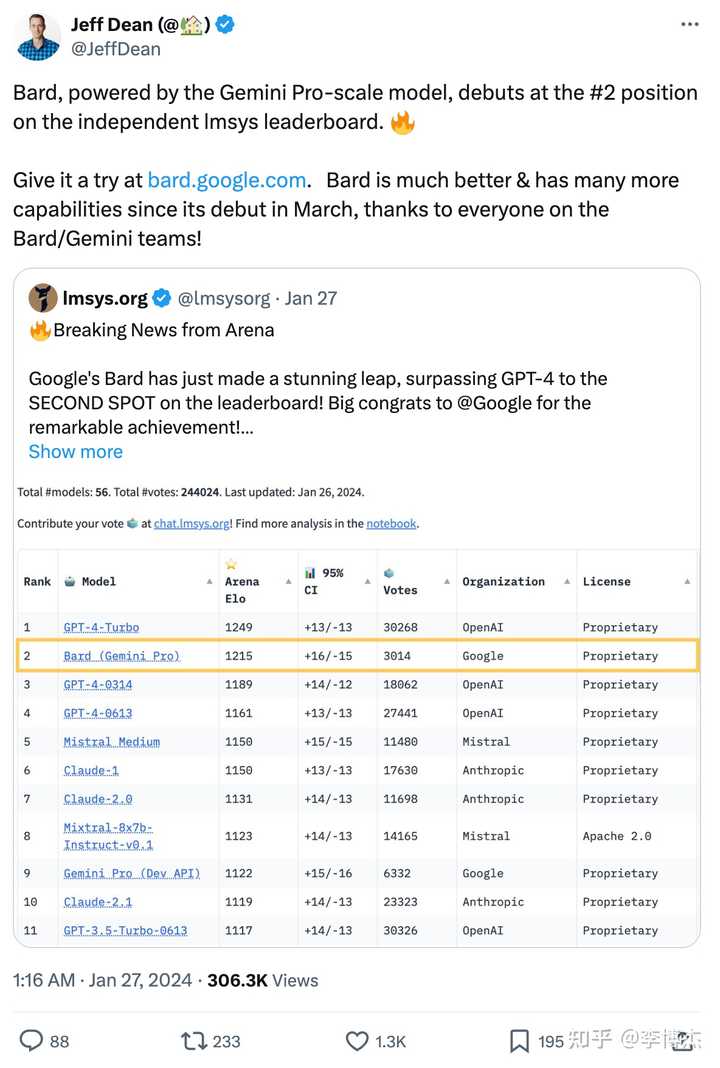
Google CEO 也关注了 LMSys 的 Twitter。
OpenAI 创始团队成员 Andrej Karpathy 去年底甚至说,他们只相信两个大模型评测基准:Chatbot Arena 和 r/LocalLlama。
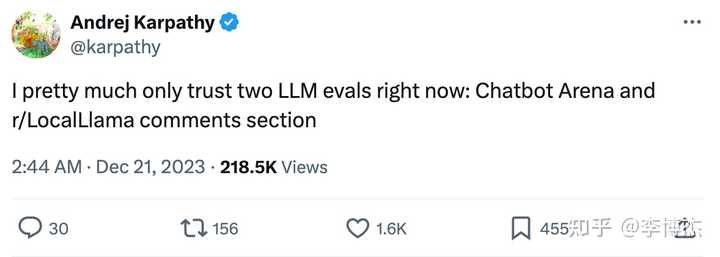
这两个大模型评测基准都是采用社区评价的方式,让社区中的匿名用户来评价大模型的输出。
传统评测基准的数据集污染问题
传统的评测基准一般是使用固定的题库,这样很容易发生数据集污染的问题。
例如,很多国内大模型最喜欢刷的就是 GSM-8K 这个榜。一些公司甚至为了宣称超越 GPT-4,在评测的时候故意采用不公平的评测方法,例如自己用 CoT,GPT-4 用 few-shot;用未对齐的模型跟已经对齐的 GPT-4 做对比。详情可以看我的这个回答《谷歌发布最新大模型 Gemini,包含多模态、三大版本,还有哪些特点?能力是否超越 GPT-4了?》
去年 9 月,有人对数据集污染这种刷榜的行为实在看不下去了,写了一篇 paper《Pretraining on the Test Set Is All You Need》,只用一个百万参数的模型,在测试集上训练模型,就能取得完美的评测结果,完爆所有现有大模型。这就说明固定题库的评测方式是不太靠谱的。
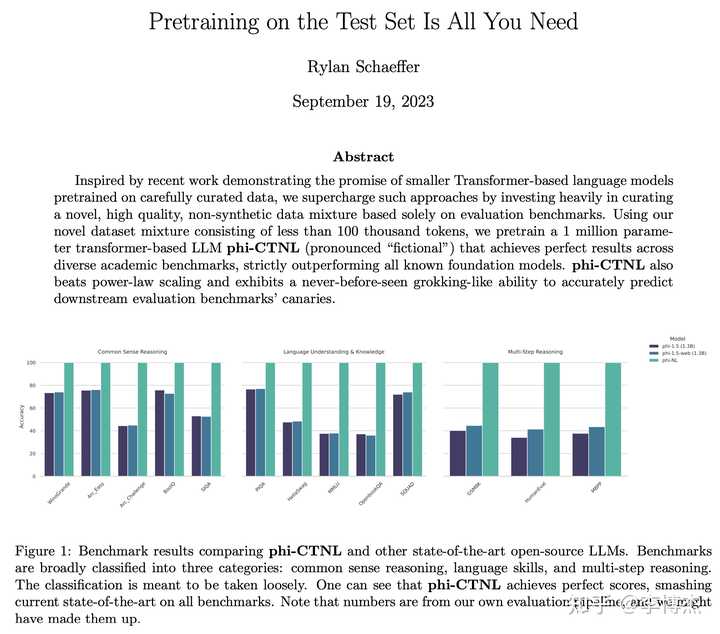
搞过语音的都知道,生成语音的好坏基本上都要看 MOS 分,Mean Opinion Score 就是人的主观评分。Chatbot Arena 就是利用了这个社区评价的方法。
**Chatbot Arena 就是让社区中的匿名用户对大模型提问,然后左右两边两个匿名大模型分别输出两个回复,用户再去投票 A 好还是 B 好。**因为用户和大模型都是匿名的,Chatbot Arena 保证了双盲性。
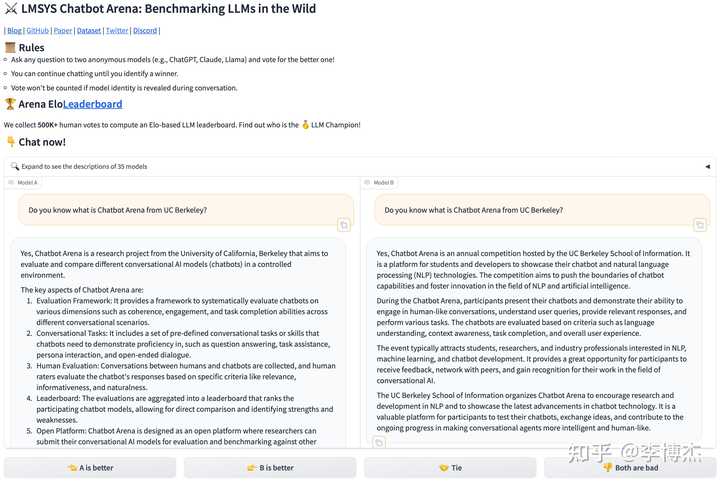
评价比生成更容易,相对评价比绝对评价容易
这种社区投票的机制看起来简单,其实背后有很深刻的哲学依据:评价比生成更容易,相对评价比绝对评价容易。
**OpenAI 提出的超级对齐(Superalignment)要做的事情就是保证未来超越人类的超级智能服从人类的意图。一个弱智能怎么可能监督一个强智能呢?**OpenAI 超级对齐团队的主管 Jan Leike 在 2022 年就发表了一个著名的论断:评价比生成更容易。
在此我把 Jan Leike 原文中 “评价比生成更容易” 这一部分翻译一下,原文在此:https://aligned.substack.com/p/alignment-optimism
评估比生成更容易
这一原则很重要,因为它使我们能够轻松地从系统中获得有意义的对齐工作。如果这一点成立,意味着如果我们将时间和精力集中在评估系统的行为而不是亲自完成这些工作上(即使它们的生成能力可能不如我们),我们可以大大加速我们的研究。
这一性质是递归奖励建模(recursive reward modeling)(以及在某种程度上,OpenAI 提出的 Debate)的基础:**如果评估比生成更容易,那么 AI 辅助的人类将比智能水平相当的 AI 生成器更具优势。**只要这一点成立,我们就可以通过为 AI 系统执行这些任务创造评估信号,训练 AI 模型,来扩展到越来越难的任务。虽然递归奖励建模不会无限扩展,但它也不需要无限扩展。它只需要扩展到足以让我们能够用它来监督大量的对齐研究。
评估比生成更容易是一个普遍存在于许多领域的性质:
**形式化问题:**大多数计算机科学家相信 NP != P,这意味着存在一大类问题在形式上确实具有这一性质。大多数这些问题还已经在我们能想到的算法中经验性地显示出这一性质:SAT 求解、图算法、证明搜索、模型检查等等。
**传统体育和游戏:**任何值得观看的体育或游戏都具有这一性质。不仅观众需要能够判断谁赢了比赛,还需要知道谁领先以及谁正在进行精彩的动作或比赛。因此,评估需要足够简单,以便绝大多数观众能够完成。同时,生成(精湛地进行游戏)需要足够困难,以便最优秀的人可以轻易地从大多数人中脱颖而出;否则,举办比赛就没有多大意义了。例如:你可以通过查看玩家的单位和经济来判断谁在《星际争霸》中领先;你可以通过查看杀死/死亡统计和赚取的金钱来判断谁在 DotA 中领先;你可以通过查看材料和位置来判断谁在国际象棋中领先(尽管评估位置可能很困难);你可以通过查看计分板和哪个球队的球场上花费的时间最多来判断谁在足球或橄榄球比赛中获胜;等等。
许多消费产品:比较不同智能手机的质量要比制造更好的智能手机容易得多。这不仅适用于容易衡量的特征,如 RAM 的数量或像素的数量,还适用于更模糊的方面,如手机握持的舒适度以及电池的持久性。事实上,对于大多数(技术)产品来说,这一点都是正确的,这就是为什么人们关注亚马逊和 YouTube 评论的原因。相反,对于评估对个别消费者来说困难且政府监管较少的产品,市场通常充斥着低质量产品。例如,营养补充品常常没有它们声称的益处,不含它们声称的活性成分的量,或含有不健康的污染物。在这种情况下,评估需要昂贵的实验室设备,因此做出购买决定的大多数人没有可靠的信号;他们只能服用补充剂,看看身体感觉如何。
**大多数工作:**每当公司雇佣员工时,他们需要知道这名员工是否真正帮助他们实现使命。在评估员工的工作表现上花费和完成工作一样多的时间和努力是不经济的,所以只能花费少得多的努力来评估工作表现。这有效吗?我当然不会声称公司能完美地获得员工实际表现的信号,但如果他们不能比员工更容易地进行评估,那么像绩效提升、晋升和解雇等努力将基本上是随机的,是浪费时间。因此,那些不花大量时间和精力评估员工表现的公司应该会胜过其他这样做的公司。
学术研究:评估学术研究是出了名的困难,政府资助机构几乎没有工具来区分好的和坏的研究:通常需要由非专家做出决定,大量低质量的工作得到资助,而代理指标如引用次数和发表论文数量则被过度优化。NeurIPS 实验著名地发现学术审查过程中存在大量噪声,但容易被忽视的是,也存在很多有意义的信号:撰写一篇 NeurIPS 论文通常需要至少几个月的全职工作(比如 >1000 小时),而一篇评审通常在几小时内完成(例如,4 次评审各花费 3 小时,总共 12 小时)。然而,评审委员会在接受/拒绝决定上的一致率达到 77%,在接受口头报告/焦点评级论文上的一致率达到 94%。考虑到生成与评估的努力相差两个数量级,这是一个令人难以置信的高一致率(远高于 OpenAI API 任务的数据标注一致率,OpenAI 的数据标注一致率只有 70-80%)!关于学术激励的破坏和 NeurIPS 论文是否真正推动了人类的科学知识,还有很多话要说,但至少对于写一篇能进入 NeurIPS 的论文这个任务来说,这个说法似乎是成立的。
然而,也有一些任务这个原则通常不成立:写下你的签名比评估给定的涂鸦是否是你的签名要容易。对一张狗的图片进行加密或哈希处理很简单,但评估一些给定的二进制数据是否是一张加密或哈希处理过的狗的图片则非常困难。这使得密码学成为可能。
以上证据并不意味着这个原则也适用于对齐研究。但这确实在很大程度上指向这个方向。换句话说,如果评估 NeurIPS 论文比写它们困难得多,并且评审们的意见不倾向于超过随机水平,那么我们不应该将此视为对齐研究易于自动化的证据吗?
更重要的是,如果对齐研究的评估不比生成更容易,这对纯粹由人驱动的对齐研究来说也是一个坏消息:在这种情况下,找到对齐问题解决方案的人将无法说服其他人使用该解决方案,因为其他人不会知道它是否有用。相反,每个 AGI 开发者都需要为自己找到解决方案。
尽管评估对齐研究的任何代理指标都可能被过度优化,并将导致看似有说服力但根本上有缺陷的对齐研究,但这并不意味着不会有仍然有用的代理指标可以优化一段时间。
然而,有一个重要的警告:敌对构造的输入可能比非敌对的输入更难评估(尽管可能仍然比生成容易)。例如,超人类水平的围棋 AI Agent 可能有简单的漏洞。对齐研究的一个假设例子:通过仅控制训练过程中的随机性,可以在模型中植入后门。不了解这一点的人类评估者将错过由恶意 AI 系统秘密操纵随机性源编写的训练代码中的重要缺陷。
另一个重要的开放问题是,如果你不能依赖来自现实世界的反馈信号,评估是否仍然比生成更容易。例如,如果你不被允许运行一段代码,评估一段代码是否比编写它更容易?如果我们担心我们的 AI 系统正在编写可能包含木马和破坏沙箱的代码,那么在我们仔细审查之前,我们不能运行它来“看看会发生什么”。在这种情况下,重新编写代码可能比发现隐藏的缺陷更容易(这是 Rice 定理所暗示的,没有防御优势)。
正如 Jan Leike 指出的,日常生活中 “评价比生成更容易” 是非常普遍的。评价一道菜好不好吃不需要成为一个厨师,评价一门课讲得好不好不需要成为一个教授。
其实这个观点也并不是所有人都认同。我 2015 年搞科大评课社区的时候,有些人就认为,学生没有资格评价教授的课讲得好不好。
OpenAI 是第一次把这个简单而普遍的真理用来解决 AI 甚至人类最重要的问题:如何保证比人还聪明的超级智能服从人类的意图。
OpenAI 顺着这个 “评价比生成更容易” 的思路,2023 年底终于发表了超级对齐领域的第一篇研究成果:Weak-to-Strong Generalization,也就是用弱模型监督强模型,提升强模型的性能。虽然我们目前还没有超人智能(下图中,Superalignment),但可以用两个比较弱的模型来做模拟实验(下图右,Our Analogy),实验结果证明弱模型的监督确实可以提升强模型的性能。这是与传统机器学习中强模型监督弱模型(下图左,Traditional ML)显著不同的,为超级对齐这个 AI 甚至人类最重要的问题带来了曙光。
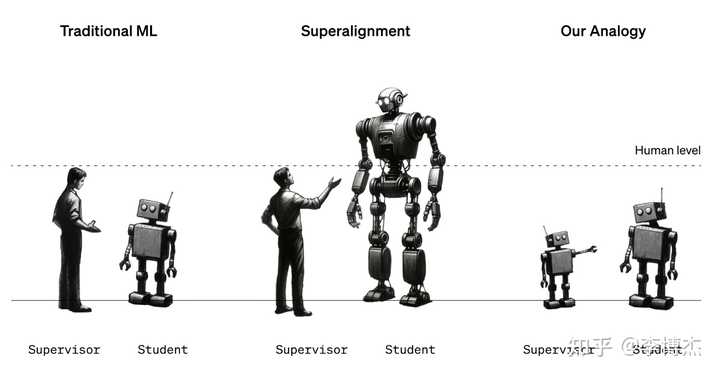 Weak-to-Strong Generalization
Weak-to-Strong Generalization
**那么 Chatbot Arena 为什么采用模型 PK 的竞技场(Arena)方式,而不是让用户直接对模型输出的好坏打分呢?**这也是有哲学依据的:相对评价比绝对评价容易。
比如,如果我不是一个设计师,那么并不容易绝对评价一个网页的设计好不好。但是给我两个设计方案,大多数人都可以对比这两个方案到底哪个更好。
大模型生成的内容也是类似的。如果用绝对评分的方式,首先很多人自己也很难评价大模型生成的文字、图片、语音、视频等好不好,其次有些人喜欢打高分,有些人喜欢打低分。但是相对评分,特别是 Chatbot Arena 这种双盲的相对评分,就可以避免绝对评分困难、分数难以归一化的问题。
防刷票机制
为了避免刷票,Chatbot Arena 使用了很多机制,包括:
- CloudFlare 阻挡机器人
- 对每个 IP 做投票数量限制
- 回答如果暴露了模型身份,用户的投票不计入排行榜(因此通过问 “你是谁” 这样的问题来破坏双盲是行不通的)
当然,Chatbot Arena 由于是完全匿名的,并不能从根本上杜绝 Sybil attack,也就是俗称的刷票。如果 Chatbot Arena 背后的排行榜有更大的经济利益,刷票就是一个需要更严肃考虑的问题了。
Chatbot Arena 上的所有用户投票经过清洗和匿名化处理后,都是公开的。这里是处理这些用户投票数据的 Google Colab Notebook:https://colab.research.google.com/drive/1KdwokPjirkTmpO_P1WByFNFiqxWQquwH#scrollTo=tyl5Vil7HRzd
下载用户投票数据的地址(注意现在是 4 月 13 日,但只提供了 4 月 10 日的数据下载,排行榜也是更新到 4 月 11 日,因为需要清洗数据之后才能更新公开的排行榜):https://storage.googleapis.com/arena_external_data/public/clean_battle_20240410.json
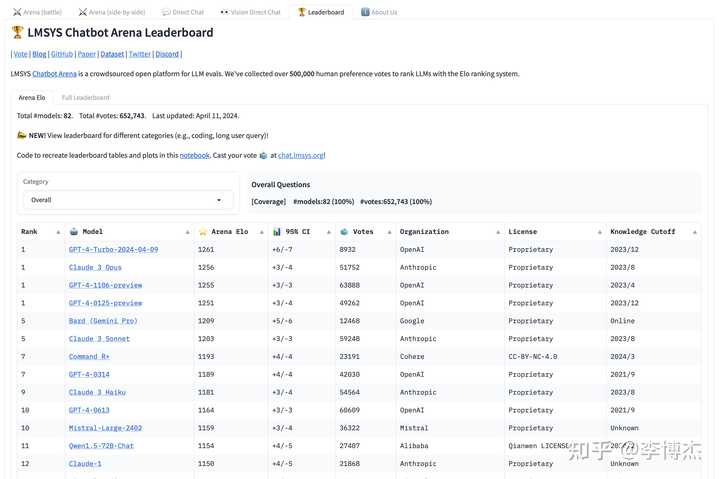
根据投票结果,使用类似国际象棋比赛中 Elo 评分的方法,Chatbot Arena 得出一个模型的排行榜。社区用户还做了一年来 Chatbot Arena 排行榜变化的视频,可以看到大模型真的竞争很激烈,经常城头变幻大王旗。
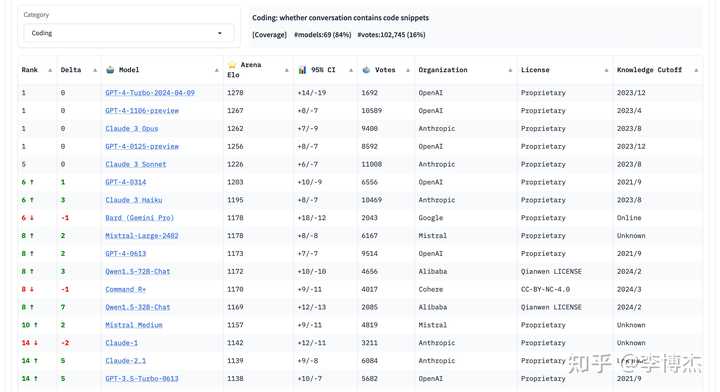
最近 Chatbot Arena 还新增了分类排行榜。
比如代码的:
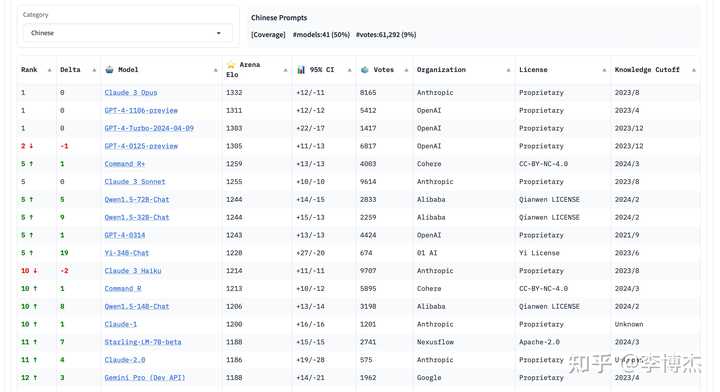
中文的:
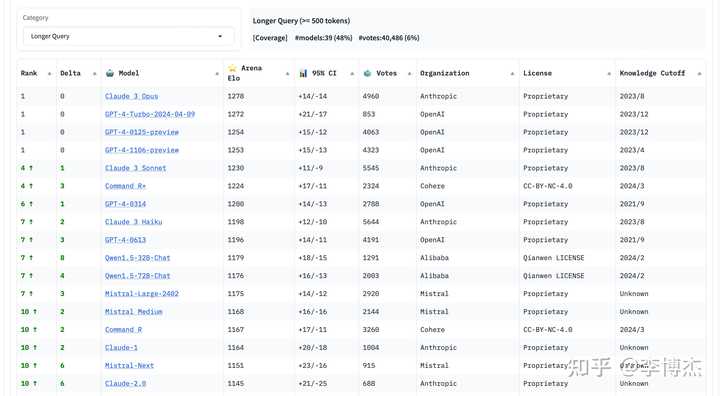
长上下文的:
**其实做一个有公信力的排行榜真的很不容易。**说一点跟 Chatbot Arena 无关的个人经历,我给科大评课社区搞排行榜的时候,就有人说,最不受欢迎的课程排行榜很容易得罪人,建议只保留最受欢迎的课程排行。不过最后我们还是保留了最受欢迎和不受欢迎两个排行榜,并没有老师因为排行榜找我们的麻烦。相反,想让我们删除点评的老师都是因为具体的点评内容。事实上这个排行榜评出的 top 10 最受欢迎老师跟学校教务处官方独立收集的 top 10 老师中有 7 个是相同的,说明社区评价的一致性还是挺高的。
2022 年我想参与一个导师评价网站,我老婆就强烈反对,说这样的网站很容易得罪人。因此,要搞社区评价,首先就不能怕得罪人,其次要从机制设计和运营策略上尽可能鼓励客观理性的评价。
Chatbot Arena 的排行榜不但没有得罪这些搞大模型的公司,反而成了各大 AI 公司宣传各自模型的官方基准。这跟 Chatbot Arena 的机制设计和运营策略是很有关系的。首先 Chatbot Arena 不是让用户直接点评模型本身,而是让匿名用户对匿名模型的输出进行双盲投票,这样就避免了不客观的极化评论,保证了平台的公平性。其次 Chatbot Arena 的官方 Twitter 经常祝贺各种模型排名的上升和新模型的评测结果,也为这些模型背后的公司提供了宣传素材。
Chatbot Arena 简史
@SIY.Z 他们这些 UC Berkeley 的 PhD 在去年 GPT-4 刚出来的时候,就预见到大模型会百花齐放,大模型会快速进化,因此快速推出了 Chatbot Arena。
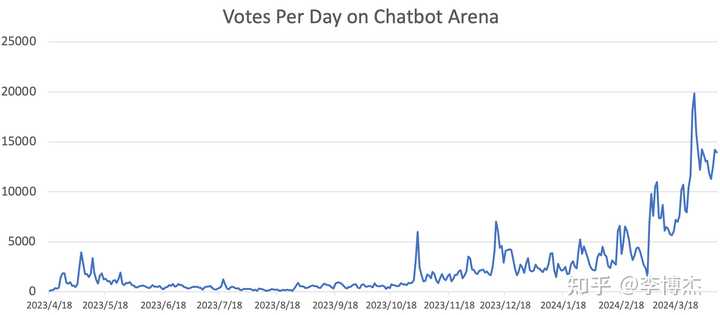
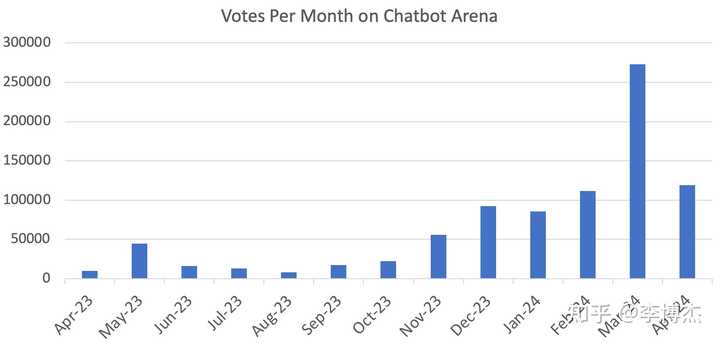
**2023 年 4 月 18 日,Chatbot Arena 正式上线,那一天只有 113 张投票。今天,Chatbot Arena 每天都有上万张投票。**近一年的时间,已经有 65 万投票了。
Chatbot Arena 有两个热度爆炸性增长的时间段,第一次是 2023 年 11 月,GPT-4-Turbo 发布带来了一波热度,随后就是 OpenAI 的 Greg Brockman、Google 的 Jeff Dean、OpenAI 的 Andrej Karpathy 相继发推。
第二次热度爆炸性增长是 2024 年 3 月,就是本文开头提到的几个大模型你方唱罢我登场,Google、Anthropic、Mistral 纷纷具备了过招 OpenAI GPT-4 的实力,连 Cohere 开源的 Command R+ 都来过招 GPT-4 了。