我是如何走上 AI 创业之路的
我与 AI 的早期接触
读博期间与 AI 的邂逅
我博士本来是做网络和系统研究的,博士论文就是《基于可编程网卡的高性能数据中心系统》。很多做网络和系统的人看不起一些 AI 研究,说 AI 的文章容易灌水,只要有 idea,一两个月就可以发出 paper 来。而网络和系统的顶会文章往往需要很大的工作量,做一年之久。
除了在学校的时候上过的那些 AI 的课,我第一次正经做 AI 相关的项目是 2016 年,用 FPGA 加速 Bing Ranking 里面的神经网络。当时正好是 AI 的上一波热潮,今天的 AI 四小龙都是那段时间启动的。
微软把 FPGA 大规模部署到数据中心,除了网络虚拟化,还有很重要的一块就是神经网络推理加速。当时我们还用流水线并行来把神经网络的权重全部放到 FPGA 片上的 SRAM 里面,从而实现超线性的加速比。这段故事在《MSRA 读博五年——自己主导的第一篇 SOSP》中 “机器学习加速器的探索” 一节有更详细的描述。
当时搞网络和系统的很多人对 AI 并不了解,也不屑于了解,连训练和推理都分不清,也搞不清正向和反向算子。通过优化这些算子,我至少知道了基本的前馈神经网络(FFNN)到底是怎么算的。但我并没有接触业务,没有折腾过自己的模型。
那时,我还在悄悄搞一个数字前任项目,想用聊天记录搞一个类似《黑镜》第二季第一集《马上回来》里面的 Ash 出来。我就做了一个 Telegram bot,一开始是用一些搜索的技术搞的,效果不太好。
2017 年,我对挖矿起了兴趣,于是搞了一个地下挖矿机房,买了一些 GPU 和 ASIC 矿机,租了个地下室自己开始挖矿。其中的 GPU 矿机就可以用来自己折腾模型了。于是,我就开始尝试一些基于 NLP 的神经网络算法,这也是我第一次开始学习 NLP。这段故事的细节在《MSRA 读博五年——地下挖矿机房与数字前任计划》。
由于我自己的 NLP 水平非常有限,当年的 NLP 也是 “有多少人工,就有多少智能”,数字前任计划虽然有很多有趣的发现,但模仿真人聊天的总体效果并不令我满意。而且这个项目让我长时间无法从那段感情里走出来。我决定去跟更专业的团队学一学。
我参与了微软小冰项目,虽然我只是负责 AI Infra,但也耳濡目染听说了很多 NLP 技术。
小冰是那个年代最先进的 chat bot 之一,虽然自然语言理解能力和对世界的理解非常有限,比如问小冰几岁,有时候回答 18 岁,有时候回答 8 岁。前面几句话讲过的事情,就忘得一干二净了。但通过一系列工程方法,仍然能让它变成一个有趣的段子手,跟人类聊天几十上百个回合都不觉得无聊。要是论用户的平均聊天回合数,估计当年的小冰比今天的 Character AI 还高。今天我搞 AI Agent 的情绪(emotions)系统就是跟小冰学的。
AI Infra 之自动算子生成
2019 年,我从中科大和 MSRA 联合培养博士毕业,加入了华为 2012 实验室。
由于我之前有做 ClickNP 编译器的经历,也懂一点 AI,谭博就让我加入 MindSpore 深度学习框架里的自动算子生成(AKG)团队。
MindSpore 是华为开源的类似 PyTorch 的深度学习框架,是升腾 AI 芯片生态的重要组成部分。PyTorch 里面没有图层和算子层融合的功能,各个算子是互相独立的。而升腾 AI 芯片是需要显式做数据搬移的。理想情况下,数据最好是在片内进行尽可能多的处理再搬出去。但在 PyTorch 生成的算子中,每个算子都要从片外的 HBM 内存搬到片内的高速缓存,处理完了再搬出去,造成很多数据搬移的额外开销。
我们自动算子生成的一个重要应用场景就是在 MindSpore 中自动进行算子融合,也就是把多个在计算图中连续的算子融合成一个大的算子,自动生成执行调度和数据搬移。所以说用 PyTorch 跑升腾芯片虽然生态更好,但会浪费芯片的算力,在 PyTorch 支持图算融合之前,事实上是在饮鸩止渴。
自动算子生成的另一个重要场景就是缩短算子开发的周期。升腾芯片如果用底层的 CCE 语言编程,需要手动考虑数据切分、执行调度、数据搬移、指令同步等很多方面,开发一个简单的向量加法算子需要几周时间,如果是一个比较复杂的矩阵乘法算子,就需要几个月了。而自动算子生成器 AKG 会使用多面体优化(polyhedral compilation)的方法自动生成算子代码,只需要几天时间就可以开发完成一个算子。
AI Infra 之高速互联总线
我在自动算子生成这个项目做了一年,这时公司启动了一个高速互连总线的大项目,谭博就让我作为早期成员之一加入这个项目了。当时整个项目也就 10 个人左右,如今已经变成了上千人参与的公司级战略项目,数据中心的下一代通用计算和 AI 计算都用这个高速互联总线。
要搞大规模的高速互连总线,最关键的是应用场景。我们的主要应用场景就是 AI 大模型、高性能计算、存储,都需要高带宽、低时延、大规模的异构并行计算。
2020 年,最火的 NLP 模型还是 BERT,大多数人从 CV 领域得到的经验是,ResNet 模型的大小有上限,模型大到一定程度后再增加模型规模和训练数据量,性能也不会再提升了,更不用说一个通用模型能解决多领域任务了。因此,大多数人并不相信 “大模型” 这个概念。
2020 年 5 月,我刚加入这个新生的高速互联总线项目时,OpenAI 发布了 GPT-3 论文,随即在圈内引起强烈的反响。我们的项目也多了一个关键的数据点,不管是模型规模还是训练模型所需的算力,GPT-3 都位于散点图的右上角。
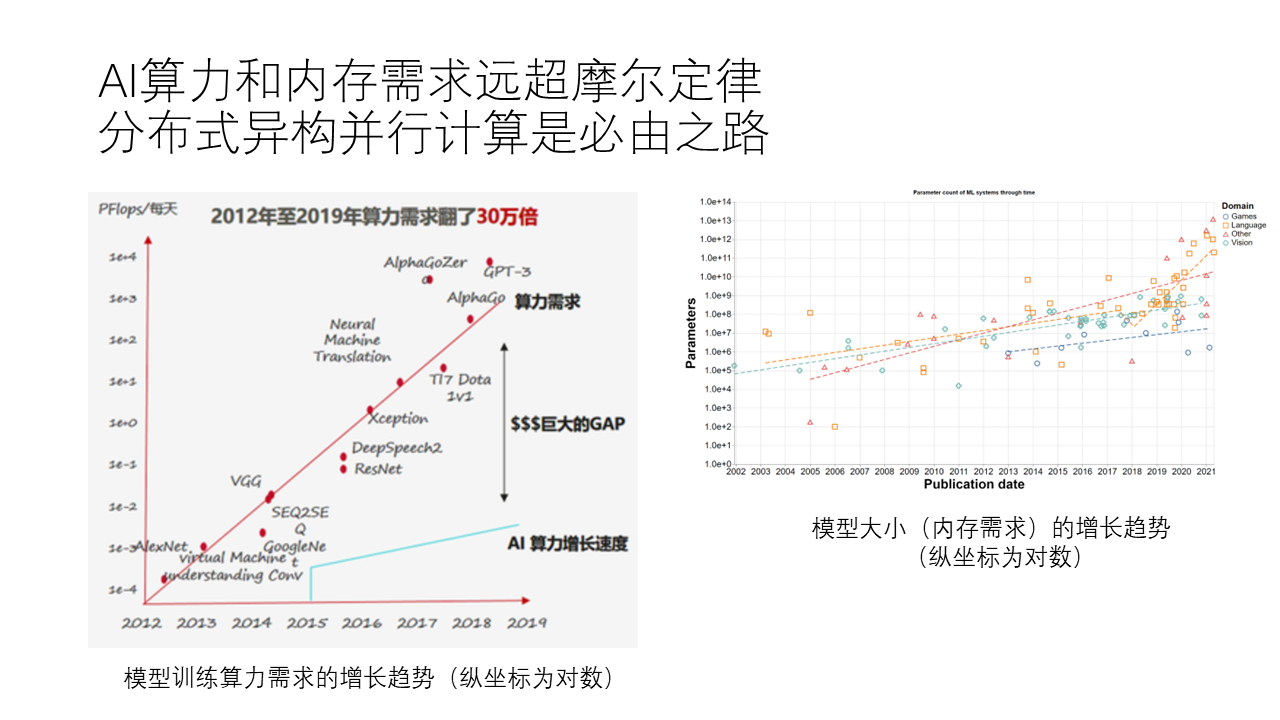 上图:我在 2020 年做的一页 PPT 草图(由于公司资料不得外传,大致重做的),右上角就是当年刚刚发布的 GPT-3
上图:我在 2020 年做的一页 PPT 草图(由于公司资料不得外传,大致重做的),右上角就是当年刚刚发布的 GPT-3
从 2012 年的 AlexNet,到 2014 年的 GoogleNet,再到 2015 年的 Seq2Seq,2016 年的 ResNet,2018 年的 AlphaGo 和 AlphaZero,直到 2020 年的 GPT-3,我们可以看到,从 2012 年到 2020 年,这些模型的训练过程对算力的需求增长速度非常快,翻了 30 万倍。这个增长速度并不像摩尔定律那样每 18 个月翻一倍,而是在 18 个月内翻 40 倍,非常惊人。
然而,单个 GPU 的算力增长速度实际上还是相对遵循摩尔定律的,因为它毕竟是硬件。这么巨大的算力差距要求我们必须采用分布式并行计算来满足训练所需的算力需求。
从另一个角度来看,大模型的内存需求也非常大。我们可以看到,上述模型的参数规模也在迅速增长,越大的模型通常意味着越高的内存需求。例如 GPT-3 在单个 GPU 中根本放不下,需要多块卡才能完成推理。训练需要的集群规模就更大了,GPT-3 是用上千张 GPU 卡并行训练的。这些 GPU 之间需要的通信带宽是极高的,远远超过目前以太网或者 RDMA 网络所能提供的带宽。例如 NVIDIA 就搞了 900 GB/s 带宽的 NVLink。华为的 AI 芯片也需要高性能的网络互联。
我们团队最终说服了公司领导和兄弟部门,未来是大模型的世界,当年最普遍的单机多卡训练模式是不足以做大模型训练的,因此一定需要高性能、大规模的网络互联。我们规划的互联并不是 NVLink 的简单复刻,它比 NVLink 更先进,因为它可扩放性强、语义丰富。因此,它可以支持上万张 GPU 卡以 NVLink 级别的带宽高速通信,并且能够实现通用计算网络和 AI 计算网络的融合。
华为的领导们还是非常有远见的,能够在 2020 年投入巨资支持我们的项目。由于 GPT-3 的影响力仍然局限于学术界,不断有人挑战我们,现在产品部门用的模型单机多卡就足够了,为啥要烧这么多钱搞跨主机的高性能网络。好在领导一直力排众议支持我们。
微软的领导们也很有远见,2019 年,GPT-3 还没有出来,BERT 和 GPT 之争还是 BERT 略占上风,AI 的标杆公司还是 Google 而不是 OpenAI,微软自己也拥有上千名研究员的微软研究院,那时候微软就给 OpenAI 投资了 10 亿美金。
2023 年 NVIDIA 对华禁运高端 GPU 之后,国内基本上只有华为的升腾(Ascend)AI 芯片能实现大规模训练。其他的 AI 芯片要么只能推理,要么只能做推理和中小规模训练。这主要就是网络互联的功劳,大规模训练对网络互联的带宽和延迟要求都很高,没有一定网络积累的公司很难搞定 NVIDIA NVLink 那么高性能的网络互联。
认识大模型的能力
用 GPT-3 做智能问答的失败尝试
2022 年 4 月,有朋友想让我给 USTC 评课社区 的每门课、每个老师提取出一些关键词,生成一些标签。我说我不会 NLP,做不了。其实现在看来这是 NLP 里面最简单的东西,都不用麻烦大模型,用 Python 里的 spacy 库在 CPU 上就能做。但是大模型能比传统的 NLP 算法做得更好。现在很多互联网公司就在使用 OpenAI 的 GPT API 来做这些 UGC(用户生成内容)的内容分析和特征提取工作,有的公司甚至花了上千万的 API 调用费用。
后来,又有朋友问我能不能搞一个智能问答,根据评课社区里面的点评内容回答用户的问题。虽然我做了几年的大模型 Infra,但我那时还没有正经用过大模型,比如 2020 年写到 PPT 上的 GPT-3,我其实根本就没用过,还以为也就比 BERT 水平稍微高点呢。因为参与微软小冰项目的时候对 BERT 的能力也略知一二,感觉通用问题回答还是很难做,对 NLP 其实是不抱什么信心的。
但朋友建议我试一试,说 GPT-3 比 BERT 强很多。为此我还专门申请了 OpenAI 的 GPT-3 API,试了以后发现效果确实不好,感觉就像是点评内容的蹩脚续写,而无法完成根据点评内容回答问题的任务。我也看过 BERT 和 Transformer 的基本原理,感觉它也就能回答 “中国的首都是__” 这种填空题。然后我就回复说,现在技术还不成熟,搞不了。
 上图:使用 GPT-3 foundation model 直接提问,结果 GPT-3 只是在续写点评,并没有根据点评内容回答问题。Foundation model 只能根据语料的概率分布来做续写,而不会完成某一类特定任务。这就是我们为什么需要 SFT(Supervised Fine-Tuning),使用对话语料来让大模型学会回答问题。
上图:使用 GPT-3 foundation model 直接提问,结果 GPT-3 只是在续写点评,并没有根据点评内容回答问题。Foundation model 只能根据语料的概率分布来做续写,而不会完成某一类特定任务。这就是我们为什么需要 SFT(Supervised Fine-Tuning),使用对话语料来让大模型学会回答问题。
 上图:使用 GPT-3 foundation model 写成 “问题-回答“ 形式,但 GPT-3 仍然只是在续写点评,并没有根据点评内容回答问题。这是因为没有给它提供例子,GPT-3 的 zero-shot 能力较差,一般需要 few-shot,就是给它几个例子。
上图:使用 GPT-3 foundation model 写成 “问题-回答“ 形式,但 GPT-3 仍然只是在续写点评,并没有根据点评内容回答问题。这是因为没有给它提供例子,GPT-3 的 zero-shot 能力较差,一般需要 few-shot,就是给它几个例子。
我问了搞大模型的同事,才知道那是因为我不会用 GPT-3。GPT-3 是基础模型(foundation model)而不是经过微调的 Chat 模型。**GPT-3 基础模型要想工作得好,需要给几个例子,这就是所谓 few-shot。**GPT-3 paper 的标题就是 GPTs are few-shot learners。
 上图:使用 GPT-3 foundation model,给定 3 个例子,确实能够做一些简单的总结任务了,但是发挥很不稳定,有时候仅仅照抄现有的点评,有时候是做了个很简单的总结。如果把 temperature 设置为 0.1,基本上就只会照抄现有的点评了。
上图:使用 GPT-3 foundation model,给定 3 个例子,确实能够做一些简单的总结任务了,但是发挥很不稳定,有时候仅仅照抄现有的点评,有时候是做了个很简单的总结。如果把 temperature 设置为 0.1,基本上就只会照抄现有的点评了。
我又去问我们搞大模型的同事,给了几个例子怎么还是表现这么差。他说,GPT-3 的中文水平比较差,用英文试试。我就把它翻译成了英文,果然比中文表现好不少。
而且同样内容的英文内容比中文的 token 数量少一半。原来这几条中文点评内容塞不进 2048 token 的 context 里面,还得手动删除一些,变成 1751 token。但这 1751 token 的中文内容翻译成英文就只需要 697 token,少了 60%。当然,GPT-3.5 的 tokenizer 跟 GPT-3 的已经不一样了,中英文内容之间的 token 数量差距没有这么悬殊,但仍然是英文更节约 token。国内的中文大模型很多都修改了 tokenizer,使其对中文更友好。
 上图:使用 GPT-3 foundation model,把上面 few-shot 的总结任务翻译成英文,这下大模型的表现终于差不多能看了,而且在 temperature = 0.1 的情况下发挥稳定。
上图:使用 GPT-3 foundation model,把上面 few-shot 的总结任务翻译成英文,这下大模型的表现终于差不多能看了,而且在 temperature = 0.1 的情况下发挥稳定。
其实,直接使用基础模型来做问答的效果,即使用 GPT-3.5 这样好的模型,也仍然只会模仿语料来续写内容。因此,不管对于多强的基础模型,指令微调都是非常重要的。为什么我们认为适用于类似 Character.AI 场景的模型应该使用对话语料做微调,而不是像 Vicuna 那样使用问答语料做微调,就是因为两种数据微调出的对话风格是完全不同的。
 上图:使用 GPT-3.5 foundation model 做 zero-shot 总结任务,GPT-3.5 也只会仿照语料中的内容续写点评,并没有回答问题。
上图:使用 GPT-3.5 foundation model 做 zero-shot 总结任务,GPT-3.5 也只会仿照语料中的内容续写点评,并没有回答问题。
 上图:使用 GPT-3.5 foundation model 做 few-shot 总结任务,即使是中文,大模型的表现也是不错的。
上图:使用 GPT-3.5 foundation model 做 few-shot 总结任务,即使是中文,大模型的表现也是不错的。
当时有个朋友告诉我 OpenAI 有个 fine-tuning(微调)的 API,可以把数据扔进去做微调。当时我天真的以为只要把数据组织成 QA 形式(prompt-response),模型就能自动学会里面的所有知识。所以我就把评课社区的一部分点评组织成了 “X 老师的 Y 课程怎么样?” 的问题,点评内容作为答案,但发现微调之后的 Davinci(GPT-3)模型仅仅能粗略回答 “X 老师的 Y 课程怎么样” 这种微调数据里已经有的问题,回答也没法综合同一门课程多个点评的内容,稍微复杂点的问题就彻底回答不了。
现在我才知道,微调是需要做 data augmentation(数据增强)的,大模型还没有像人这么聪明,告诉 A 是 B 的妈妈就能回答 B 是 A 的儿子。微调数据需要从各种角度提问,微调出来的模型才能正确回答各个角度的问题。
直到今天,数据增强仍然是一个专业性很高的工程。我们创业公司就希望能够把数据采集、数据清洗、数据增强、模型微调组织成全自动的流水线,Agent 创作者只需要把所需的数据源告诉我们的 Agent 平台,Agent 平台就能自动完成这些枯燥的工作,让每个普通用户都可以创作自己的微调模型。
ChatGPT 的革命
时间很快到了 2022 年 12 月,ChatGPT 发布了,朋友圈都在刷屏。
发布第二天我就试了试,感觉这不就是个懂了很多知识的小冰吗?我还发了个朋友圈质疑。然后专业搞 NLP 的齐炜祯师弟就告诉我,ChatGPT 很厉害,在 NLP 领域很多难题上都刷新了 SOTA(State-Of-The-Art),小冰肯定是搞不定的,比如指代问题、上下文记忆、指令遵从、角色扮演、逻辑推理、数学计算、代码生成。他们搞 NLP 的都一片哀嚎,原来用老方法在做的 paper 都没有意义了,不知道后面该去做什么了。
后来我试了几个例子,ChatGPT 可以写代码,可以找 bug,可以写小说,可以做奥数题,这真的打开了新世界的大门。
之前我们搞小冰的时候,是每周给小冰推出一个新能力,今天写对联,明天猜谜语,后天聊动漫,这背后都是很多专业领域的模型,每个模型都要花费无数心力采集数据、清洗数据、训练模型。现在人家一个模型全搞定了,在很多任务上的效果还比专门训练的领域模型更好。这就像是我们 co-founder 思源,高中数学、物理、计算机、化学、生物五门竞赛都得了奖,其中四门是省一等奖。别人一门竞赛得省一等奖就已经够费劲了。
我又想起了评课社区智能问答的事情。我发现把点评的内容和问题直接交给 ChatGPT,它就可以很好地回答问题,不再需要给几个例子,也不再需要翻译成英文,4096 个 token 的 context 也比 GPT-3 的 2048 token 实用很多。
我确实被打脸了,没想到仅仅半年的时间大模型进展这么快。其实是因为我不在大模型算法的圈子里,很多最新的研究我都不知道。我做傻瓜很久了。我导师就经常对我说,太阳底下没有新鲜事,如果你发现一项工作的想法特别新颖,那只能说明你对相关工作的了解还太少。
有了指令微调过的 GPT-3.5,问题就变成了怎么找到相关的点评,以及如果一门课里面的点评太多,怎么缩减上下文的长度以免超过 GPT-3.5 上下文长度的限制。
现有联网检索工具的不足
2023 年 2 月,New Bing 发布了,理论上是可以根据搜索结果来回答问题。但是我发现它根本不能正确检索到评课社区中的点评,也就不可能正确回答问题了。回答不出来倒是其次,在标准模式和创造模式下还经常有严重的幻觉,生成事实上完全错误的回答。
例如,针对这门广受争议的课程,本来大多数学生的点评是负面的,老师还要求学生删除点评,跟评课社区管理员产生了冲突。但 New Bing 这些产品竟然根据不相关的网页搜索结果,对这门课称赞有加。
直到写作这篇文章的 2023 年 12 月,这个问题仍然毫无改观。以下是 2023 年 12 月截图的 New Bing 三种模式、Google Bard、文心一言、豆包的回答。
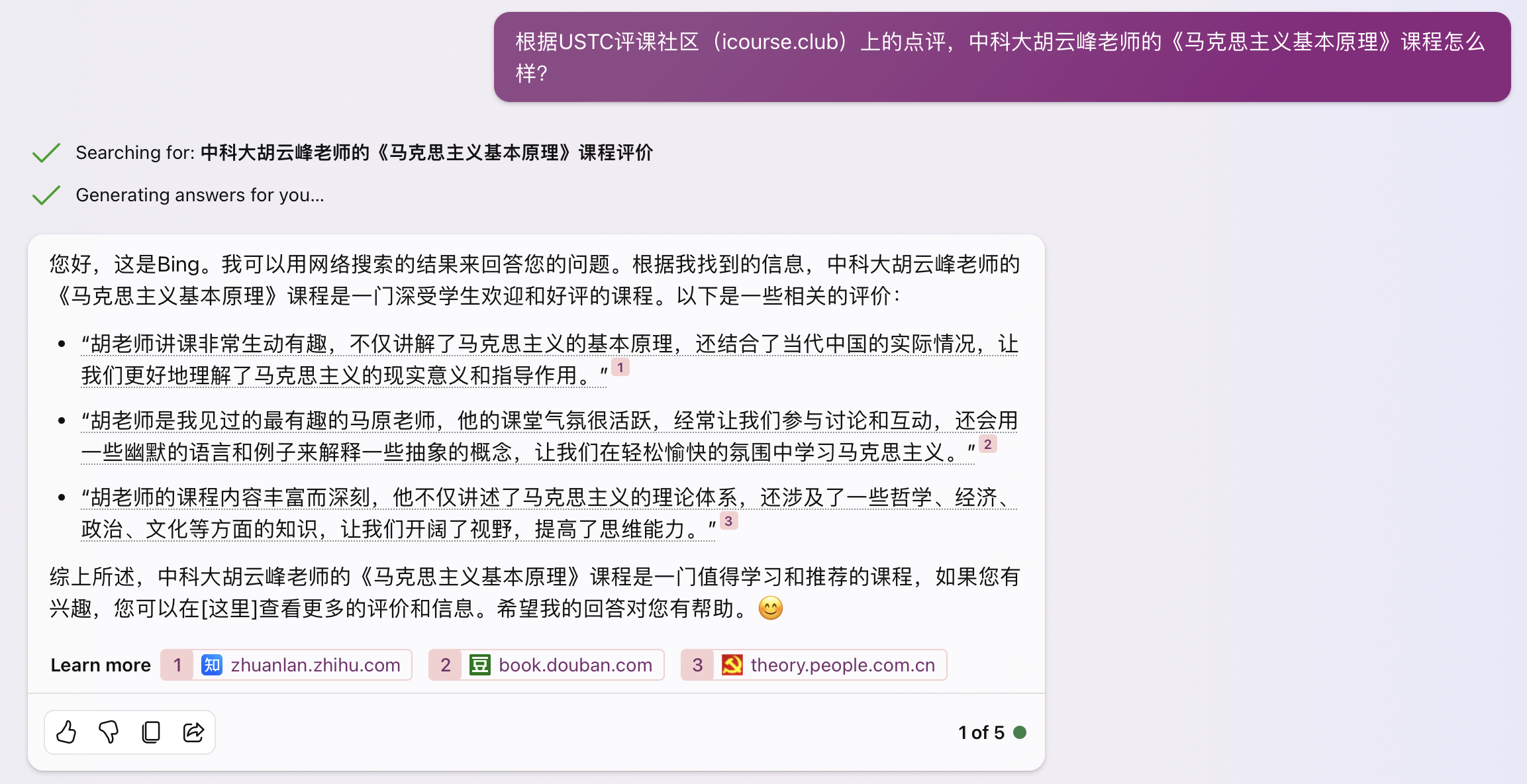 上图:New Bing 创造模式,完全是胡编乱造。检索到的三个网页都跟胡云峰老师无关,创造模式是鼓励幻觉的,因此根据毫不相关的内容生成了完全错误的评价。
上图:New Bing 创造模式,完全是胡编乱造。检索到的三个网页都跟胡云峰老师无关,创造模式是鼓励幻觉的,因此根据毫不相关的内容生成了完全错误的评价。
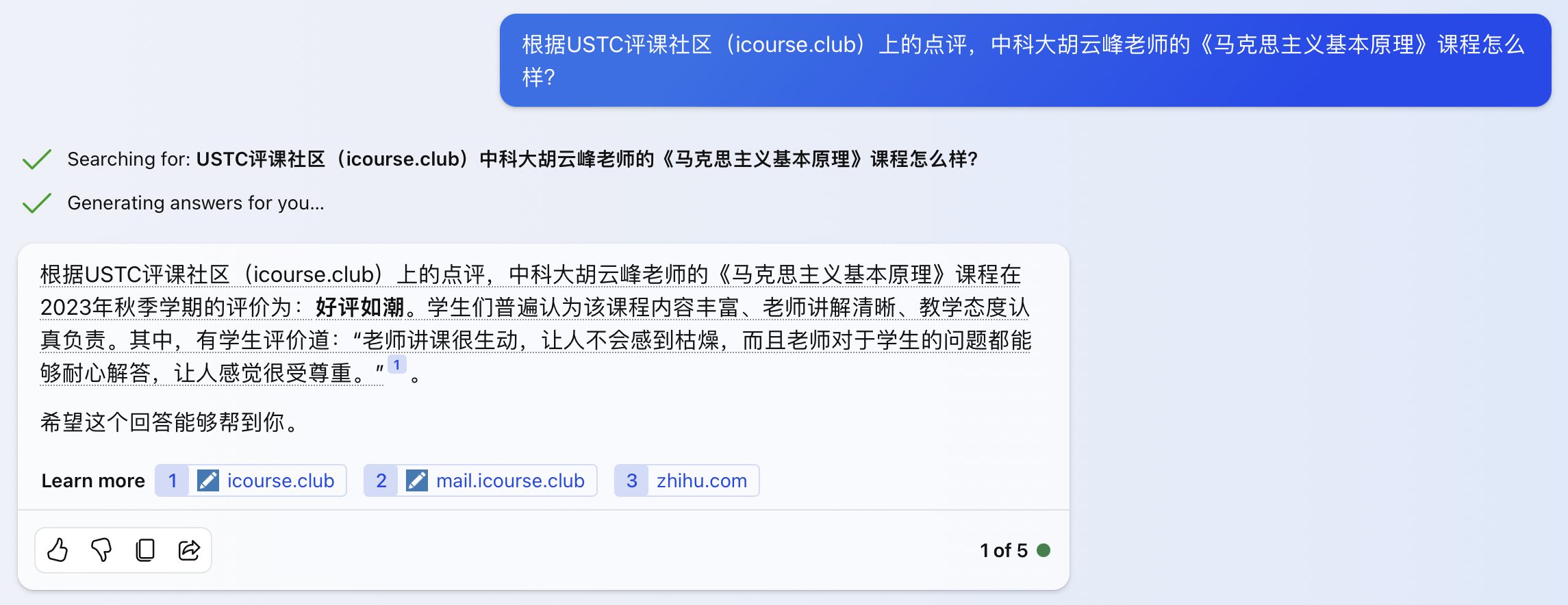 上图:New Bing 默认(平衡)模式,检索到的三个网页也都是不相关的,回答内容仍然是胡编乱造。
上图:New Bing 默认(平衡)模式,检索到的三个网页也都是不相关的,回答内容仍然是胡编乱造。
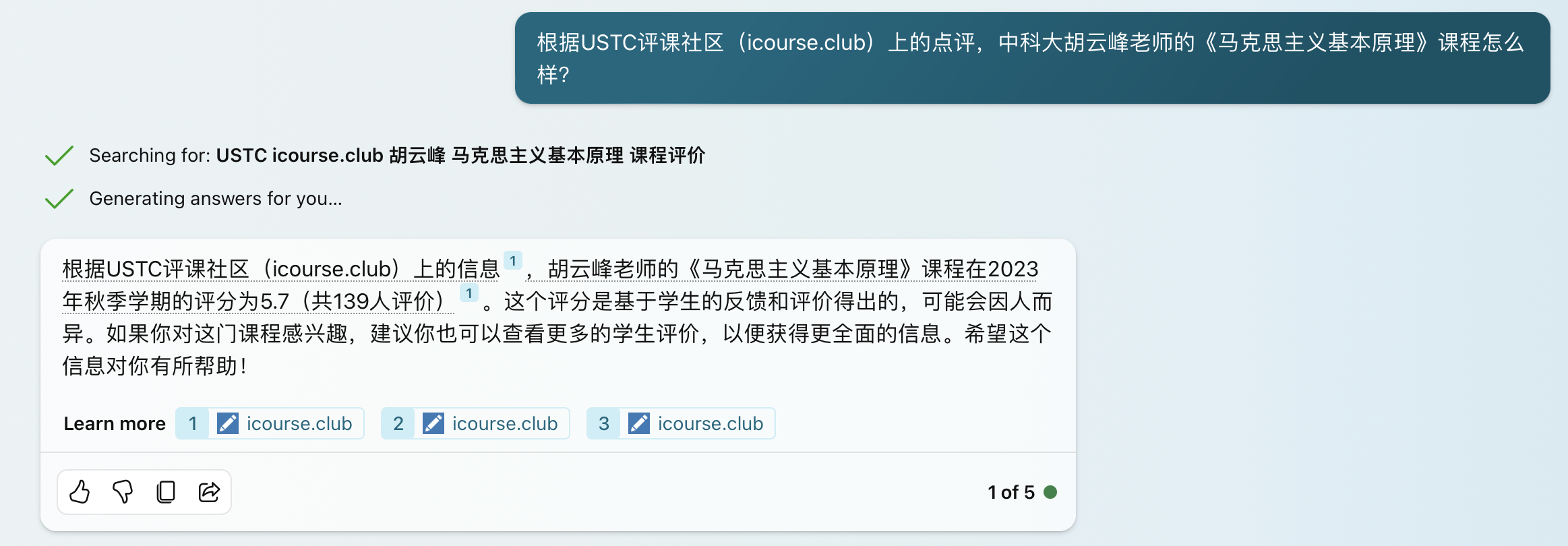 上图:New Bing 准确模式,这个模式下检索到的内容有一个是正确的,回答也是最准确的,但是仍然不能回答出任何细节。
上图:New Bing 准确模式,这个模式下检索到的内容有一个是正确的,回答也是最准确的,但是仍然不能回答出任何细节。
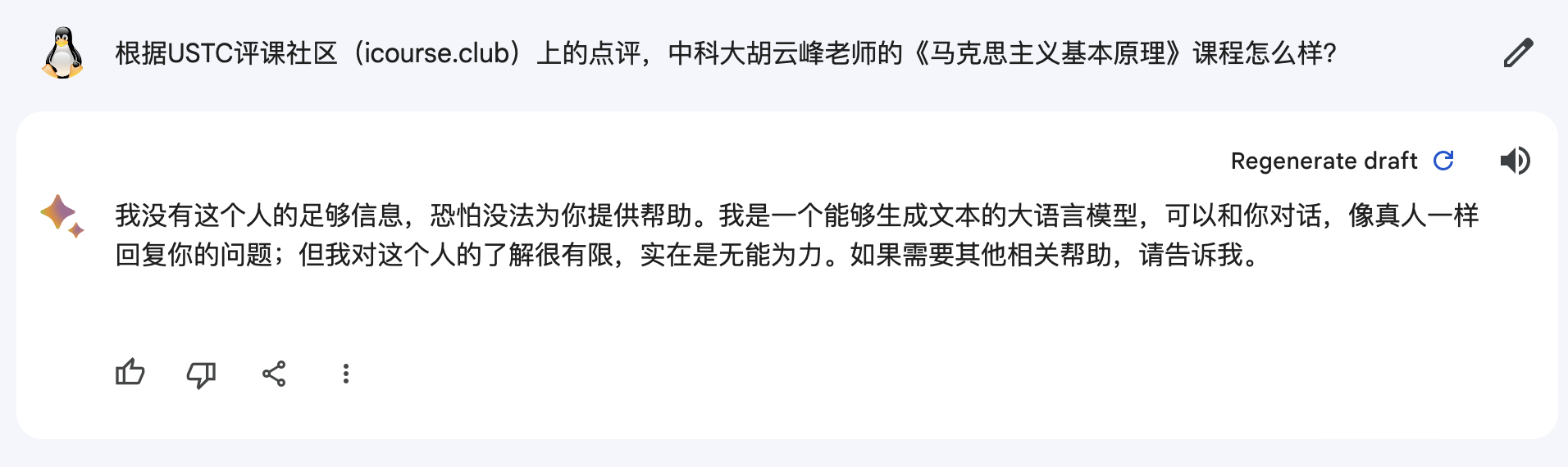 上图:Google Bard,并没有使用网页检索,也就无法回答,但至少没有胡编乱造。其实 Bard 在大多数需要网页检索的任务上表现是比较好的。
上图:Google Bard,并没有使用网页检索,也就无法回答,但至少没有胡编乱造。其实 Bard 在大多数需要网页检索的任务上表现是比较好的。
 上图:文心一言,回答内容完全是胡编乱造。
上图:文心一言,回答内容完全是胡编乱造。
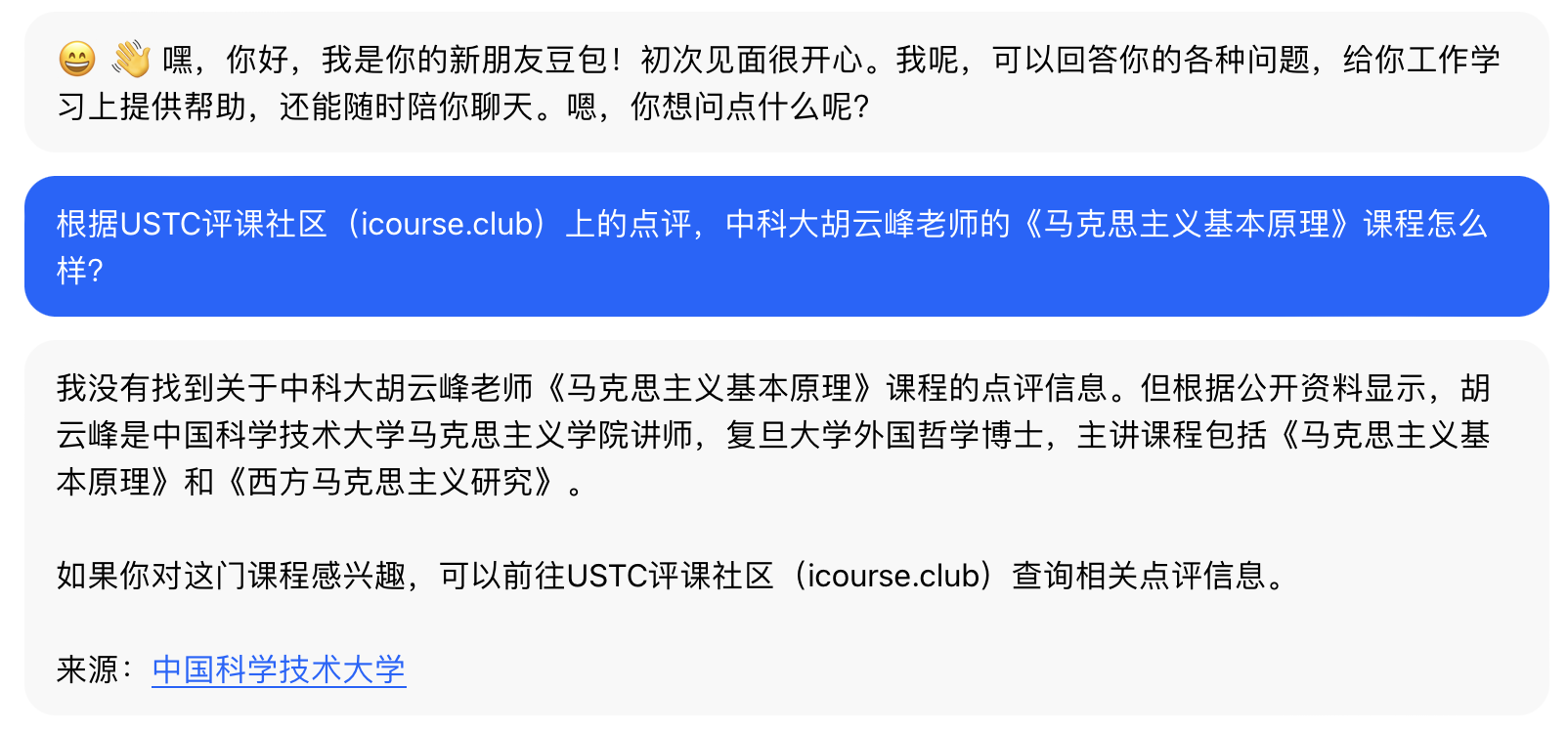 上图:豆包,没有搜索到正确的内容,但搜索到了一些其他内容,至少没有胡编乱造。
上图:豆包,没有搜索到正确的内容,但搜索到了一些其他内容,至少没有胡编乱造。
那时候我还不知道 Retrieval-Augmented Generation(RAG)这个术语,但公司内部一直是在用 RAG 的方法来做大模型的能力增强。例如用户问了 “马克龙和马龙有什么区别” 这个问题,首先用传统 NLP 工具提取出 “马克龙” 和 “马龙” 两个实体,分别拿去检索搜索引擎,再把搜索出来的内容放到 prompt 里,让大模型基于这些搜索出来的内容生成回答。
用 GPT-3.5 API 做 RAG 的尝试
2023 年 3 月,GPT-3.5 API 发布了。要回答 “X 老师的 Z 课程怎么样?” 这样的问题,就需要综合考虑一门课下面所有的点评。点评的数量可能太多,GPT-3.5 只有 4K 的上下文,放不下这么多点评。
要想回答更复杂的问题,诸如 “X 老师和 Y 老师的 Z 课程哪个好?” “Z 课程哪个老师讲得最好”,如果需要根据用户点评做一个全面的对比,就需要把这些相关课程的点评全部交给大模型。这样上下文的长度肯定就更不够了。
因此,我就把评课社区每门课程的点评用 GPT-3.5 API 做了个总结,花了我 150 美金的 API 调用成本,直接把我 120 美金的月配额都用光了,又搞了一个小号才完成了所有点评的总结任务。
 上图:我们用 GPT-4 生成的课程点评总结
上图:我们用 GPT-4 生成的课程点评总结
我们自己生成的点评总结显然比上面这些大厂的效果更好。这再次体现了 prompt 的力量。一个通用 RAG 产品很难在没有任何领域知识的情况下,很好地完成课程点评总结这个任务。不信的话可以用评课社区这门课程的链接试一试,如果哪家产品做得更好的话,欢迎告诉我。
**生成总结看起来简单,其实 prompt 很关键。**例如,我的 prompt 就是:
“根据下列点评,尽可能详细、全面地总结 X 老师的 Z 课程的考试、给分、作业、教学水平、课程内容等,800 字左右,以便让同学们更好地选课。尽量忠于点评内容,可以引用点评中的原句,点评中如果有写得特别精彩的句子建议引用。如果有冲突的观点,应客观总结双方的观点。
用户 A 的点评:……
用户 B 的点评:……”
如果不告诉应该从哪些方面做总结,生成的总结可能质量就会差很多。例如下面的 prompt:
“根据下列点评,总结 X 老师的 Z 课程。“
 上图:GPT-4 使用简单的 prompt 生成的课程点评总结条理性较差
上图:GPT-4 使用简单的 prompt 生成的课程点评总结条理性较差
有了每门课程的点评总结,就可以做评课社区的智能问答了。根据用户的查询从向量数据库里面查到 AI 生成的点评总结或者点评本身,然后再让大模型根据这些内容回答用户的问题。
 上图:2023 年 3 月的开发文档
上图:2023 年 3 月的开发文档
最后智能问答这个功能没有上线,一是因为 GPT-3.5 API 太贵了,二是我没有时间把搜索功能完全开发好。
按照每个问题用满 4K 上下文,每个回答 1K token 计算,每个问题的成本是 $0.008。评课社区平均每天有 10 万左右的页面访问量(选课季的峰值页面访问量是 46 万),其中搜索功能的使用量在 2 万左右。如果每天用户通过智能问答问 2 万个问题,一天就要花掉 160 美元。由于评课社区是公益网站,没有任何收入,这个成本太高了。目前评课社区的云服务器和网络流量成本大约是每月 150 美元,如果真的大家都来问问题,网站运营成本会直接翻 30 倍。
这段用 GPT-3.5 API 给评课社区做 RAG 的经历让我认识到大模型的一个强大之处和两个缺陷。
强大之处是大模型的能力非常强,读文章和写文章的速度比人快得多,而且给定上下文之后的回答准确率并不比人差多少。很多人认为大模型知道的行业知识太少,还幻觉严重,那是因为没有提供给它上下文。我们可以把大模型想象成一个非常聪明的外行人,在每个领域都有初级水平的知识,需要提供行业知识和方法论才能做好任务。
缺陷之一是模型的上下文有限,4K 上下文一般只能放下 top 3 的相关点评或者总结,如果 top 3 的搜索结果中没有想要的内容,大模型巧妇难为无米之炊,自然无法生成正确的回答。这就对检索系统的准确率提出了很高的要求,一般来说仅仅拿着 embedding 到向量数据库里检索很难达到想要的精度。如果搜索就是向量数据库这么简单,每个搜索引擎都可以做到 Google 的准确率了。
缺陷之二是大模型的推理成本高,特别是对于用户客单价低的产品,很容易做一单亏一单。今天的大模型支持更长的上下文,但长上下文的成本更高,例如 GPT-4 Turbo 128K 的上下文用满,一次请求的成本就高达 1.28 美元。因此我们创业公司就致力于通过 infra 优化降低大模型的推理成本,我到美国的第一件事情就是搭建算力平台。谁能用 7B 模型(或者同等成本的 MoE 模型)在业务场景中做出 70B 模型的效果,就更容易赚钱。
让 GPT-4 写背景调查报告
2023 年 3 月 GPT-4 发布后,我就做了很多实验来体验 GPT-4 的能力。其中最令我震撼的一项是用 Google 搜索和 GPT-4 自动写背景调查报告。它让我认识到大模型的潜力,以及市场上大模型产品体验和基础模型能力之间的巨大差距,是我决定创业的动机。
例如,针对前面提到的 USTC 评课社区,AI 可以在几分钟内全自动生成非常详细的背景调查报告,虽然其中少量细节存在错误(这也是大模型当前很难解决的幻觉问题),但全面地调研了网站简介、开发团队成员的个人经历、项目动机、团队成员关系、团队创始历程、项目最新进展。
**直到 2024 年的今天,我都没有看到哪个 to C 产品或者开源项目能够把背景调查报告这件事情做得这么好。**如果大家有发现效果很好的产品或者开源项目,欢迎推荐给我。
 基于 Google 搜索和 GPT-4 自动生成的评课社区背景调查报告
基于 Google 搜索和 GPT-4 自动生成的评课社区背景调查报告
对比一下 Perplexity AI,最大的 RAG(基于检索的生成)公司产品的回答,Perplexity AI 效果差的主要原因是检索准确率太低,5 条检索结果中只有第一条相关,而且背后的大模型也比较弱,没有针对这篇文章的内容做好总结。
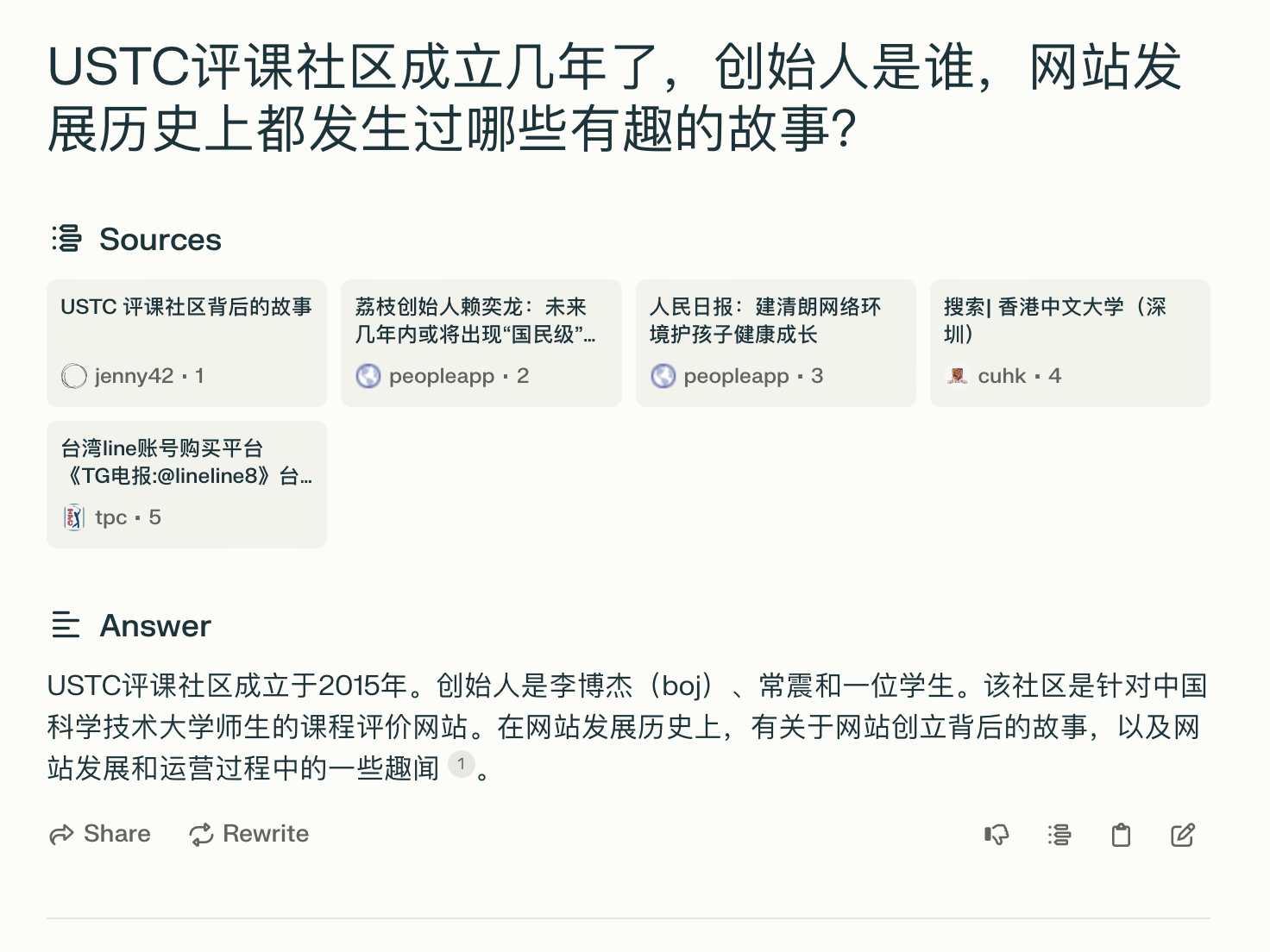 Perplexity AI 回答 USTC 评课社区的创始背景
Perplexity AI 回答 USTC 评课社区的创始背景
贾扬清的 Lepton AI 在 2024 年 1 月也开源了 500 行代码,并且部署到了 Lepton AI 自己的平台上,回答的效果就比 Perplexity AI 好很多。可以看到调用 Google 搜索后,检索准确率明显提升,10 条检索结果中 9 条都是相关的。
但是相比我自己 2023 年 4 月 AI 生成的这个背景调查报告仍然差距很大,因为 Lepton AI 做的是一个简单的通用 RAG 工具,没有专门针对背景调查这个场景做优化。
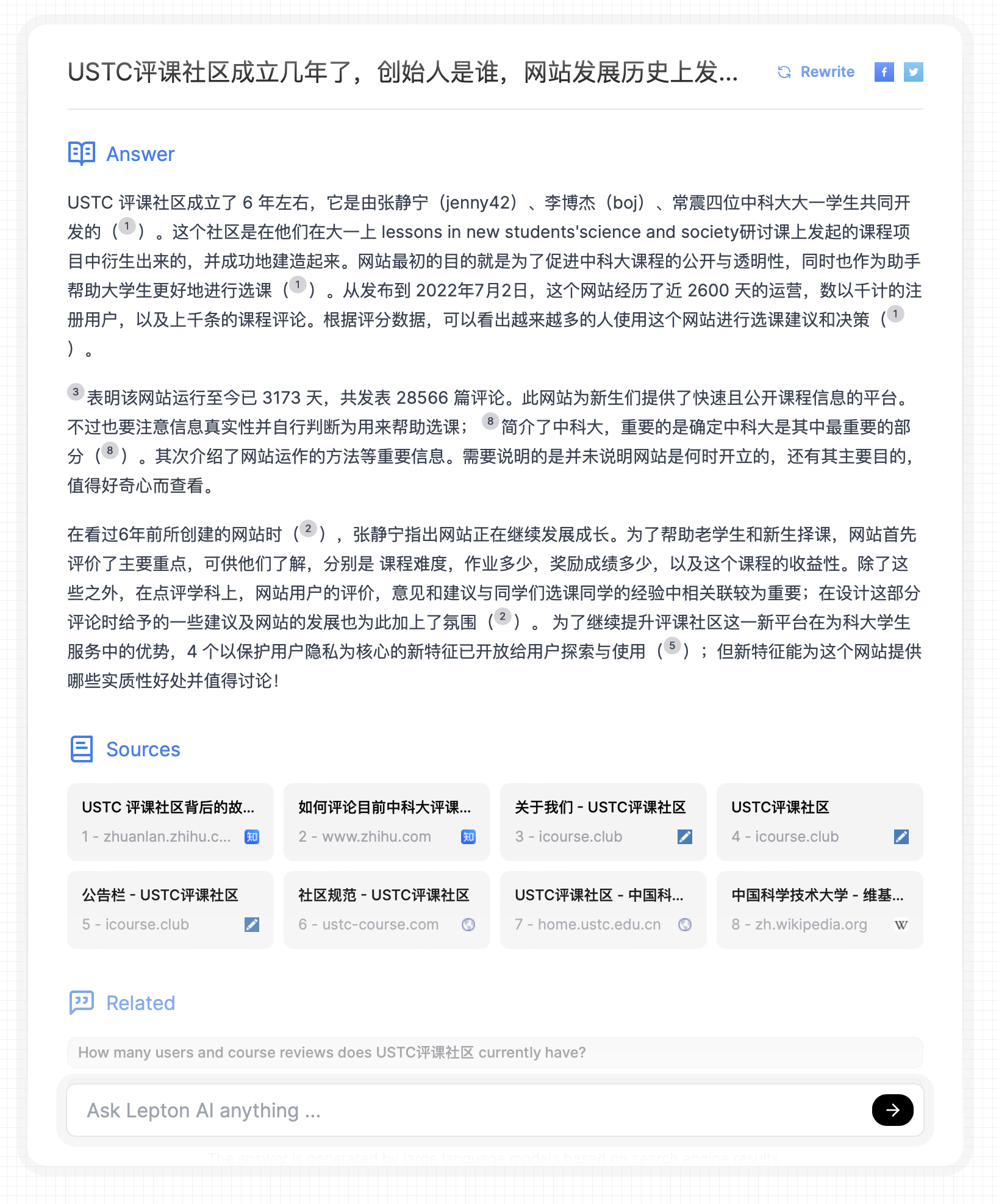 Lepton AI 回答 USTC 评课社区的创始背景
Lepton AI 回答 USTC 评课社区的创始背景
我是怎么生成这个背景调查报告的呢?
用户只是提供了一个 “关于我们” 页面的链接,然后 GPT-4 提取了页面中所有的人名和链接,链接直接访问,同时用 “USTC 评课社区 + 人名” 和 “USTC 评课社区 site:个人主页链接” 拿去 Google 搜索,排名前三的搜索结果用 GPT-4 挑出跟背景调查的目的最相关的那些。然后就得到了下面这个 URL 列表。
 USTC 评课社区搜索到的相关网页
USTC 评课社区搜索到的相关网页
然后就是根据这些 URL 生成 prompt。在根据网页提取文本内容方面,对一些类型的网页,用 Chrome Webdriver 渲染出来的页面效果比较好,因为页面内容是动态加载的;但对另一些类型的网页,直接把 HTML 转换成 Markdown 效果会更好,因为网页内容分为多个选项卡,需要点一点才能全部显示出来。
注意前面说的是 HTML 转换成 Markdown,而不是转换成文本,因为文本会丢失链接信息,而链接对判断网页的作者和人物之间的关系至关重要。
 根据网页生成 RAG 使用的 prompt
根据网页生成 RAG 使用的 prompt
最后就是让 GPT-4 生成调查报告了。如果只是使用单个 prompt 去生成,效果也不错,但是没办法生成这么详细的报告。因此,**长篇报告需要分章节来生成。每个章节都需要告诉大模型这一章需要讲什么,以及一些注意事项。**可以看到,第二章 “团队成员” 写得是最有条理的,这是因为 prompt 写得最清晰,明确告诉了大模型要写什么。
很多人在写 prompt 的时候遇到困难,其实大模型就像人一样,跟人沟通需求的时候怎么把需求描述清楚,就该怎么写 prompt。如果是英文 prompt,用词尽量准确,表达错意思了大模型就晕了。如果发现输出的效果不好,就再加一些要求,但这些要求需要有条理,并且不宜过多。有的人喜欢堆一大堆不知道有用没有的要求进去,反而把大模型绕晕了。
 生成调查报告使用的 prompt
生成调查报告使用的 prompt
这看起来也不难啊,那为什么 Perplexity AI 和 Lepton AI 都做不好?显然,这些公司里面领军科学家的水平是远高于我的。
答案很简单:成本。 2023 年 4 月,我每生成一次上面这份背景调查报告,就要花掉 11 美金的 OpenAI API 费用。因为这些网页转换成 Markdown 之后一共有 184 KB,输入一共 62K tokens。我分了 6 个章节来写这个调研报告,每个章节都要把所有输入网页过一遍,那就需要 370K tokens。OpenAI 当时 GPT-4 的成本是 $0.03 / 1K input tokens,那就是 11 美金。即使是今天用 $0.01 / 1K tokens 的 GPT-4 Turbo,也需要 3.7 美金。
考虑到一次生成的报告可能不够理想,你可能还要多生成几次。那么你真的舍得花 10 美金写一份不太准确的调研报告吗?
10 年前开一晚上手机流量可能搭进去一辆车,今天开一晚上 OpenAI 也可能搭进去一辆车。
因此,不管是 Perplexity 还是 Lepton,都不可能像我一样浪费 token。它首先不会在免费服务中像我一样分章节撰写调研报告,是一个 prompt 生成的,那么报告的详细程度就受限了。其次,Perplexity 这么大的用户量,估计不会在免费服务中用 GPT-4 这么强大的模型。最后,因为输入 token 也是要钱的,不可能把整个网页输入进去,而是选取了一些最相关的段落甚至只把文章的开头输入给大模型。
此外,在 GPT-4 成本之外,搜索引擎的成本也不可忽视。我不知道 Perplexity 背后的搜索引擎是什么,但可能不是 Google,因为 Google 搜索每 1000 个查询是 $5,如果一次调研需要 20 次 Google 搜索,那就是 $0.1。因此,Perplexity 有可能是自建的搜索引擎或者用的比较便宜的供应商,搜索的准确率就不如 Google。我每次讲到 RAG 都要强调,RAG 绝对不仅仅是向量数据库这么简单,如果用向量数据库就能检索出足够准确的内容,那每家大厂都可以做一个 Google 了。
这就是为什么我选择去做 AI Infra。AI Infra 并不仅仅是做推理优化,降低固定大小模型的推理成本。更重要的是结合场景需求,用小模型做出大模型的效果。只有这样,才能做到千倍于 GPT-4 的成本优势,让强大的 AI 真正走进千家万户。
选择创业之路
加入基础模型创业公司还是自己创业
其实我周围早就有很多人投身大模型创业了,我自己也是从 2019 年加入华为就开始做大模型的基础设施,因此我对大模型并不陌生,但我一直没想清楚的是创业公司能在大模型浪潮里面做什么,大模型是不是有足够资源的大公司才能玩得起的东西。
2022 年,我的亲戚黄子舟开始创业做 Stable Diffusion 生成图的公司,他还老是想拉我加入。2023 年除夕,我就在不停的试他们新开发的 app 里面生成图片的功能。
2023 年 4 月,在做了上文所述一系列实验之后,我就决定去搞大模型。一开始,我还没有想好要自己创业,打算在公司内部寻找做大模型的机会,或者加入国内顶级的几家 AI 基础大模型公司。
在面试了国内融资额过亿美金的几家基础大模型公司之后,我进一步坚定了大模型改变世界的信心。**每家大模型公司都有我熟悉的朋友,有我敬仰的大佬,有非常诱人的前景。但是我也在几家大模型公司之间犯了选择困难症。**我的投资人朋友往往会同时押注多家大模型公司,而我自己只能押注一家公司。
而我又相信,基础大模型是一个类似云计算的赢家通吃市场,国内没有几家大模型最后能赚钱,这里面还有资源众多的大厂,创业公司和大厂是在一个赛道里竞争的。那么押注在一家公司上,风险其实是比较高的。
我的好几个朋友倒不怎么担心这个风险。他们说,我们又不是联合创始人,职业生涯不一定绑定在一家创业公司上。就算押错了宝,这家创业公司失败了,这几年工资也不少拿,最关键的是攒了经验,后面去任何地方都可以。关键是要尽早上车,到一个真正有训练大模型资源和人才的地方多学些真本事。
我觉得大模型是几十年难以遇到的机会,如果选错了公司,蹉跎几年岁月,可能就错过了改变世界的机会。自己创业就意味着把方向舵掌握在了自己手里,可以做自己认为最有价值的事情。
那么自己创业做什么呢?以自己的资历,搞基础大模型显然更是死路一条。而做应用又不是我擅长的事情。国内的 infra 市场也不好做。
我的 Co-Founder 庄思源
2023 年 6 月,我的老朋友庄思源回国,我们科大技术圈的好几位大神在那家小馆一起吃饭。我们还正好坐在一起。我们聊了好多大模型的事情,思源和 MSRA 的何纪言特别懂大模型,而我当时连 KV Cache 是什么都搞不太清楚。
几天后,我的老朋友郑子涵跟我说,庄思源在创业,要不要一起聊聊。思源说上次聚餐的时候人太多,他还不太好意思说准备创业的事情。
我们一聊就一见如故。思源是 2014 年开始在中科大读本科,而我是在 2014 年开始读 MSRA 和中科大的联合培养博士。思源作为技术大神,开学不久我就认识了,还经常拜读他的技术博客。他后来担任科大微软学生俱乐部的主席,我正好在 MSRA 长期实习,因此我们也合作过很多项目。后来,由于学校管理方面的要求,微软学生俱乐部直接合并到 LUG(Linux 用户协会)里面了,进一步强化了 LUG 在科大计算机技术圈的江湖地位。我自己是 LUG 2012 届的会长,我在学校的很多网络服务都是在 LUG 做的。
2019 年他到 UC Berkeley 开始读博士,我博士毕业后加入了华为。我们有 4 年没有见面,但由于我们都在系统研究圈子里,一直在互相看对方发表的论文。2023 年 3 月底,我对他有个更崇拜的时刻,LMSys 的他们几个博士生在一周内搞出了 Vicuna(基于 LLaMA 最知名的微调模型,支持对话)、MT-Bench 和 Chatbot Arena(模型评测目前的事实标准,OpenAI 的 Greg Brockman 和 Google 的 Jeff Dean 都转发 Chatbot Arena 的评测结果),还有 vLLM 的雏形(目前最火的大模型推理框架)。
**Chatbot Arena 是我特别喜欢的项目,因为它解决了大模型评估(evaluation)的难题。**现有的大模型 benchmark 基本上都是一套固定的考题,这样就很容易刷榜。比如国内的大模型最喜欢刷的就是 GSM-8K 这个榜单。2023 年 9 月专门有一篇 paper Pretraining on the Test Set Is All You Need 讽刺这种刷榜行为,通过在测试集上预训练大模型,只要 100 万个参数,就可以达到 100% 的测试准确率。
Chatbot Arena 顾名思义就是大模型的斗兽场,它设计了一种很好的众包机制,可以让社区中的匿名用户评价两个模型的输出哪个更好,然后通过 Elo 评分的方法对大模型进行排序。
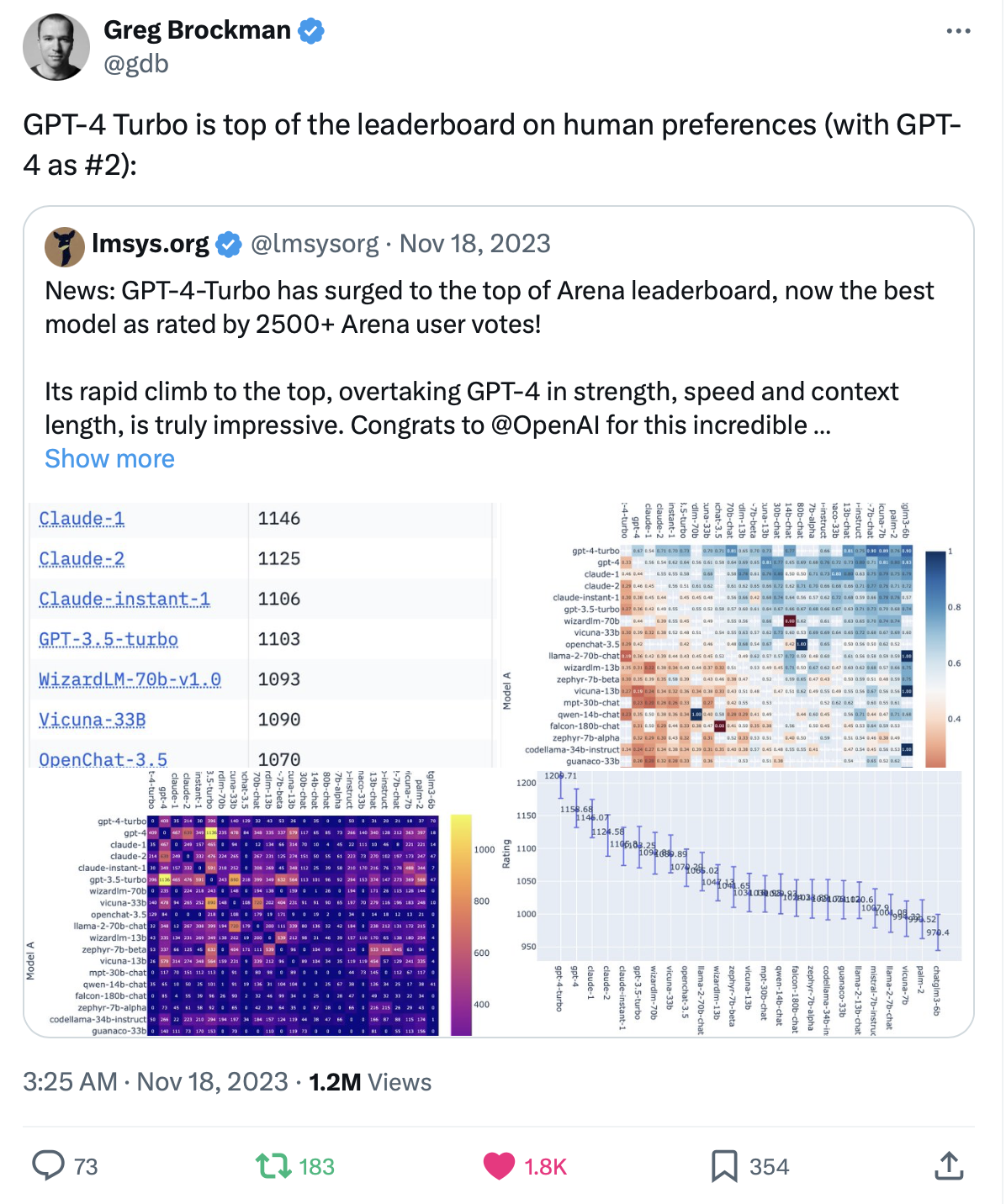 OpenAI 的 Greg Brockman 转发的 Chatbot Arena Twitter
OpenAI 的 Greg Brockman 转发的 Chatbot Arena Twitter
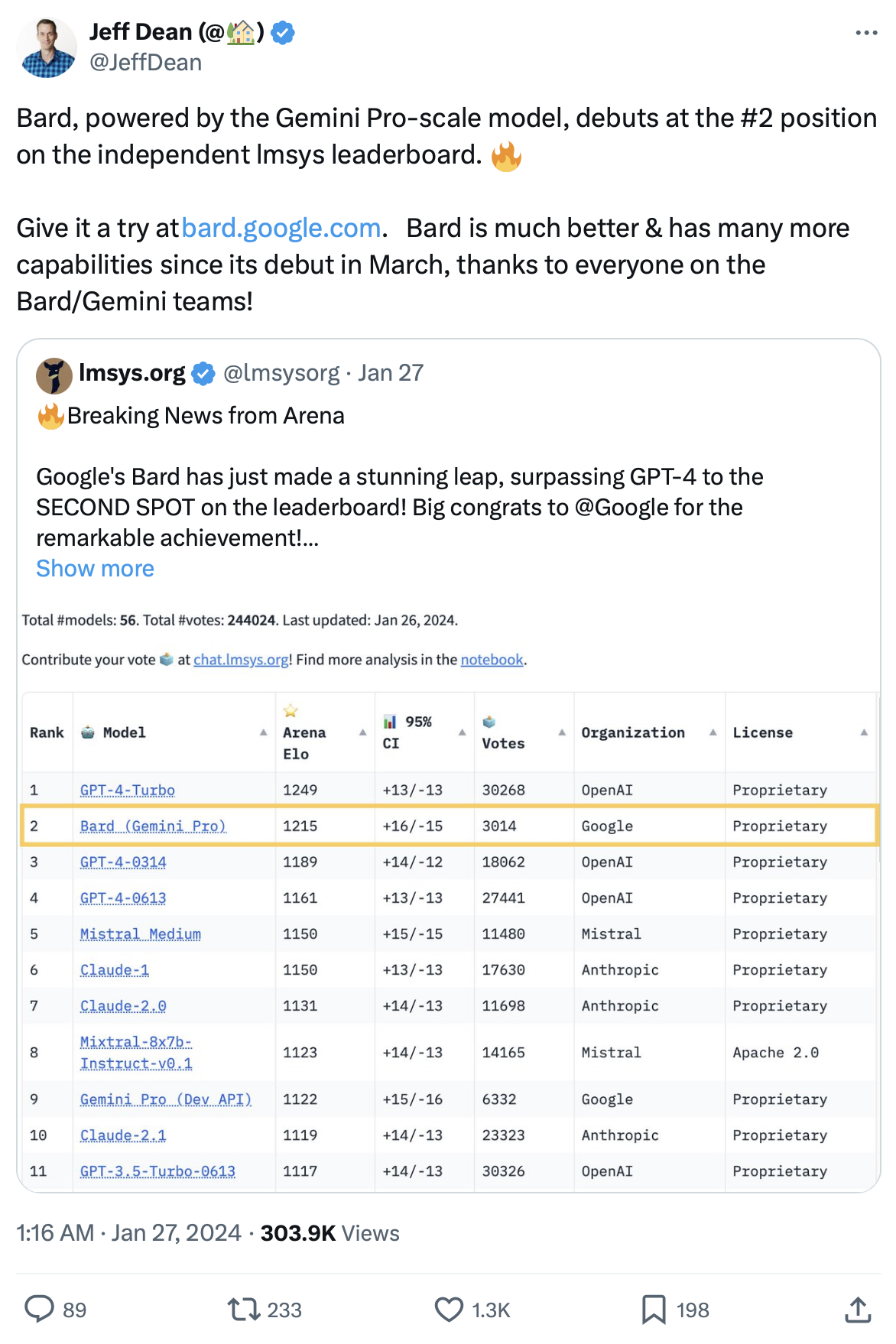 Google 的 Jeff Dean 转发的 Chatbot Arena Twitter
Google 的 Jeff Dean 转发的 Chatbot Arena Twitter
我 2023 年 6 月见思源的时候,Chatbot Arena 才只有几万个评价。今天 Chatbot Arena 已经有 40 万个评价了,而且被 OpenAI 的 Greg Brockman、Google 的 Jeff Dean 等大佬的广泛转发。当时还在 OpenAI 的 Andrej Karpathy 甚至说,Chatbot Arena 和 Reddit LocalLllama 是仅有的两个可信的大模型评估标准。
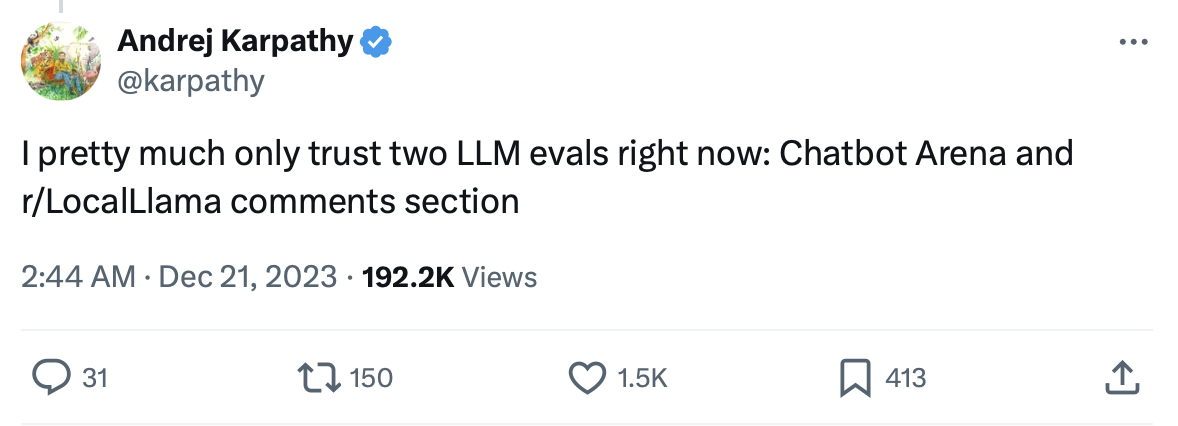 当时还在 OpenAI 的 Andrej Karpathy 认为 Chatbot Arena 和 Reddit LocalLlama 是唯二两个可信的大模型评估标准
当时还在 OpenAI 的 Andrej Karpathy 认为 Chatbot Arena 和 Reddit LocalLlama 是唯二两个可信的大模型评估标准
我一直很喜欢维基百科这种社区贡献的众包思路。前面提到我搞的 USTC 评课社区,和思源在 UC Berkeley 搞的 Chatbot Arena,其实都是发动社区的力量,用真实的人类评价解决价值判断的问题。
我也很喜欢思源他们的 MT-Bench,它也是一个大模型评估的知名标准。我觉得它主要有两个贡献,一是让大模型回答开放式问题,然后用 GPT-4 自动评价模型回答的优劣。这个模式假定 GPT-4 是最强的模型并且足够公平,解决了人类评分并不那么容易获得的问题,也解决了封闭式问题容易刷榜的问题。但由于大模型可以用 GPT-4 的回答来做 alignment,这样 GPT-4 可能也不够公平了,MT-Bench 的公平性还是不如真人评分的 Chatbot Arena。
二是评分分为 8 个类别,包括写作、角色扮演、推理、数学、编程、信息提取、理科知识、文科知识。不同的模型有的擅长角色扮演,有的擅长编程。比如做一个娱乐领域的应用,那角色扮演的能力可能就比数学和编程重要很多。我们当年搞评课社区的时候,也是分为给分好坏、作业多少、课程难度、收获大小四个维度打分,而且要求用户必须写文字点评,不能只打分。这是因为有的学生想轻松水过,有的学生想刷绩点,有的学生想学到真东西,每个学生的需求不同。
思源他们做的开源模型 Vicuna 我也第一时间下载下来试用过,用 MT-Bench 那 80 道问题一个一个试了一遍,确实在某些方面有媲美 GPT-3.5 甚至 GPT-4 的能力。
思源说,**如果 UC Berkeley 他们实验室的那些博士生一起出来创业,以一个星期奠定 Vicuna + MT-Bench + Chatbot Arena + vLLM 几个项目基础的实力,搞个小 OpenAI 不是问题。**可惜,UC Berkeley 的每位大佬都有自己的想法,三分之一找教职,三分之一去大厂,三分之一创业,还不喜欢扎堆创业。
然后我们就愉快的决定一起创业了。
现在想来,如果当时思源没有找我的话,我大概会去几位大佬朋友所在的一家基础大模型创业公司,这家公司训练的基础大模型早已超过了 GPT-3.5 的水平,也有数千张 GPU 的训练平台,还发布了 to C 的 App,发展势头迅猛。
我的高中班主任雷老师曾送我一本《少有人走的路》,这里面有一句话我一直记得:树林里分出两条路,而我选择了人迹更少的一条,由此决定了一生的道路。
给公司起名
2023 年 7 月,我们要给公司取一个名字,我和思源就分别起了几个名字。思源起名的能力还是比较强,我起的名字都比较土。
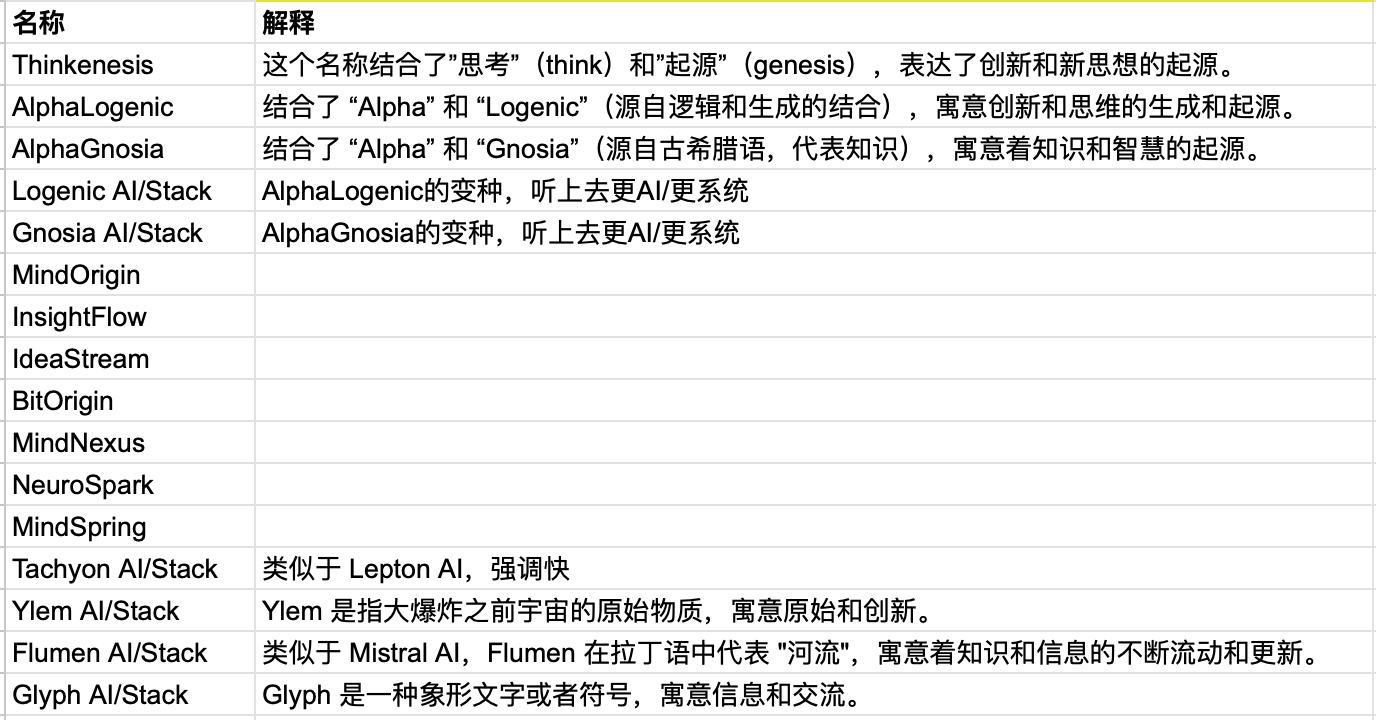 创业公司的候选名字,有注释的是思源起的,没注释的是我起的
创业公司的候选名字,有注释的是思源起的,没注释的是我起的
我们几个人给这些名字投票,最后是思源起的 Ylem 和 Logenic 两个名字获得相同的最高票数。然后我们就抽签决定选哪个名字。我们同事把两个名字分别写在一张纸上,叠起来,放进一次性杯子里,摇晃几下,然后我从中抽出了一张纸,然后就定下了 Logenic AI 这个名字。
Logenic 是 Logic 和 Gen(Generation 生成,Genesis 起源)的结合,寓意创新和思维的生成和起源。
 抽签抽到的 Logenic AI 名字
抽签抽到的 Logenic AI 名字
早期创业方向:AI 操作系统
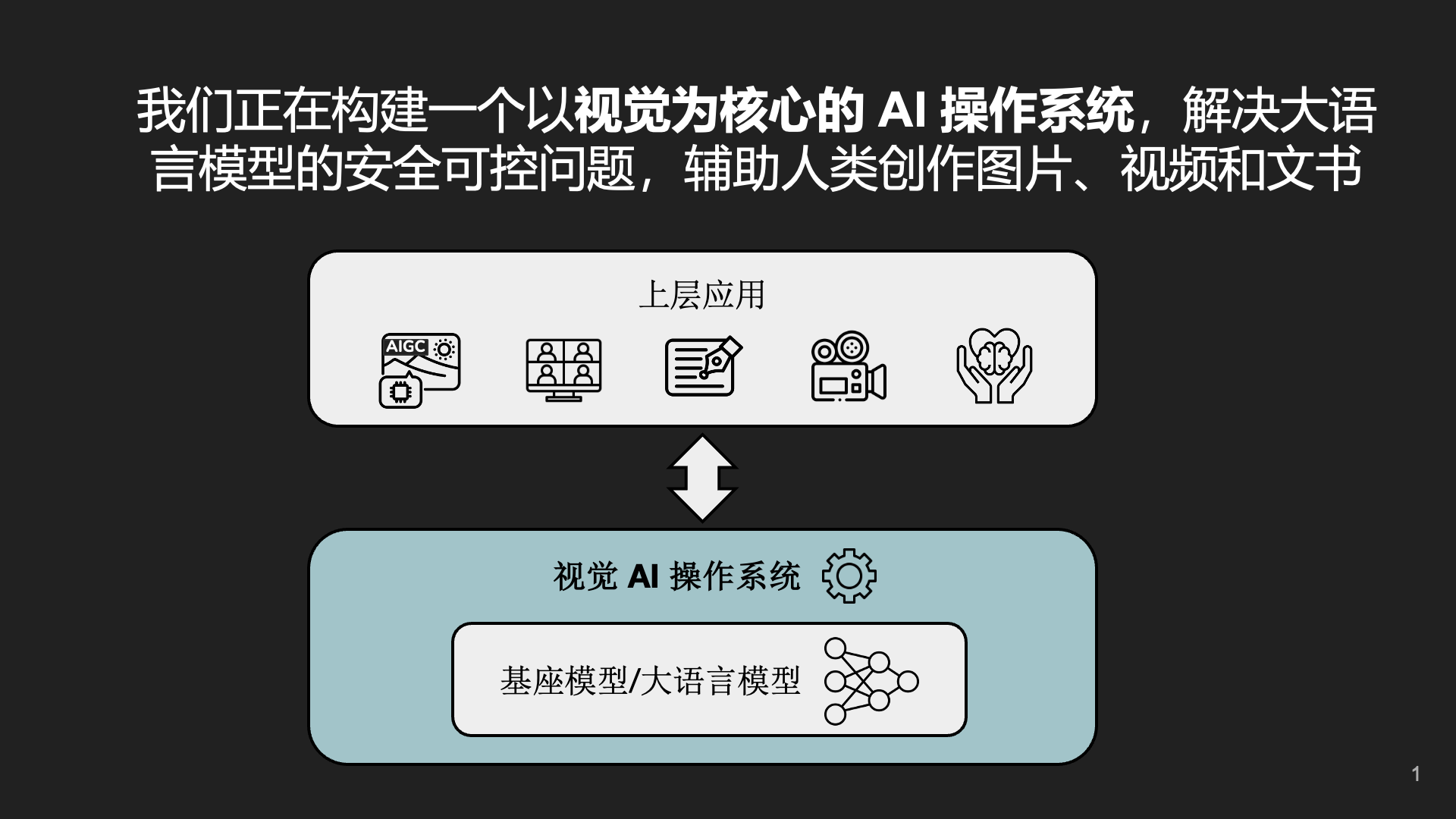
一开始,我们计划搞一个 AI 操作系统,为此我个人还把 os.ai 这个域名买下来了。
AI 操作系统是什么?简单来说,就是大模型和应用之间的桥梁,提供低成本的解决方案,构建高可预测性、高可控性的生成式 AI 基础架构。
 第一版商业计划书中的一页
第一版商业计划书中的一页
 第一版商业计划书中的一页
第一版商业计划书中的一页
 第一版商业计划书中的一页
第一版商业计划书中的一页
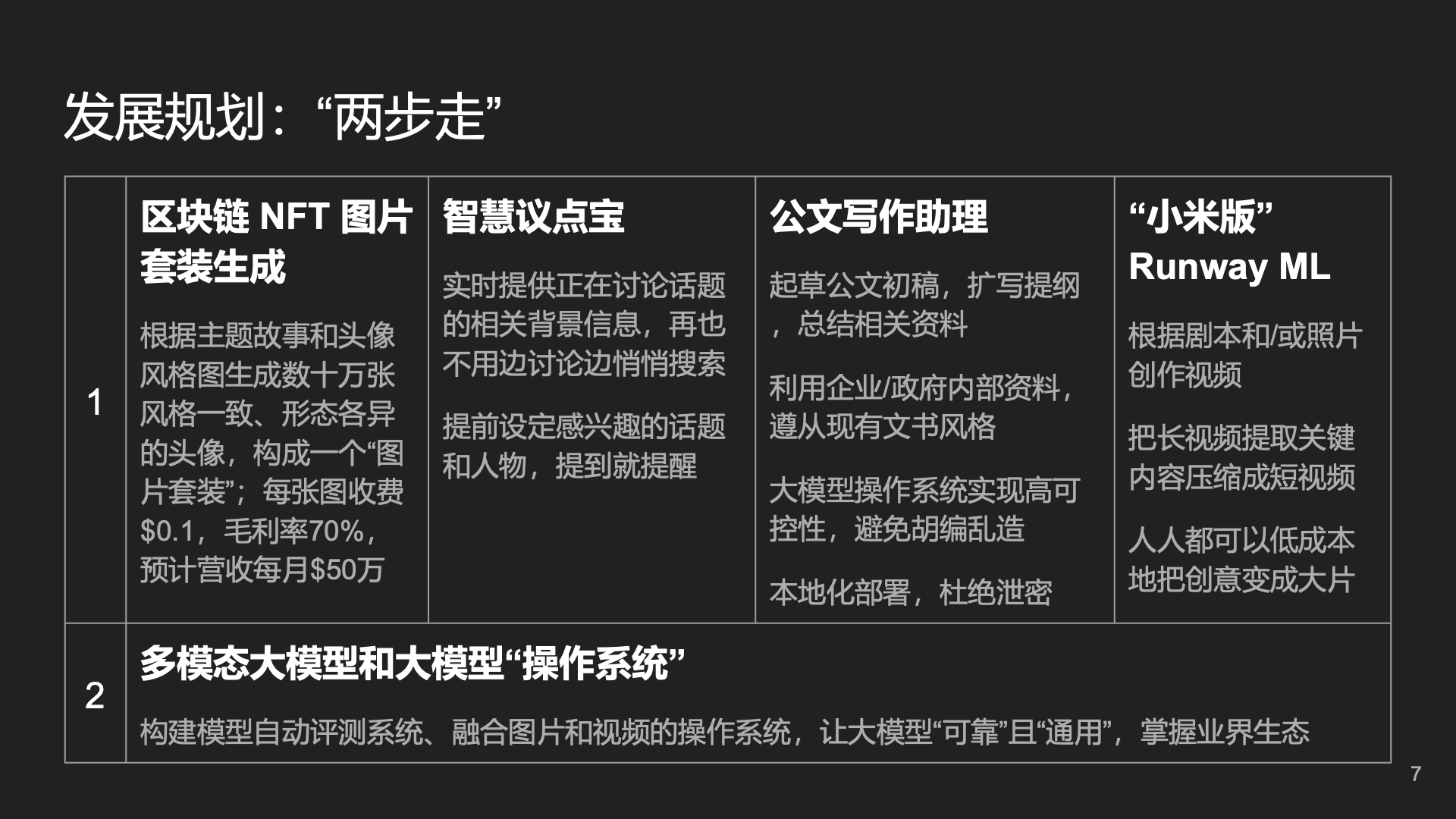
当时,我们想了几个应用场景,包括会议助理、公文写作、心理咨询等。
 第一版商业计划书中的一页
第一版商业计划书中的一页
 第一版商业计划书中的一页
第一版商业计划书中的一页
由于当时跟一些投资人交流的时候讲过这个商业计划书,不知道怎么传到了一个公众号的小编那里了,没有经过我的许可就发了一篇文章,说我创业主攻公文写作,给我搞了一个大新闻。其实我们搞的是 AI 操作系统,不是公文写作这个垂直领域。
虽然我们在任务规划、幻觉等问题上做过一些学术研究,但我们发现这些问题是比较难彻底解决的,也就意味着在需要高可靠性的场景下比较难商用,仍然要期待基础模型的进步。
比如我做过的一个项目,在 ERP 系统里面回答诸如 “过去 10 个月 A 部门的平均工资多少” 这样的问题。我们的方案是根据用户的自然语言查询生成 SQL 语句,然后执行 SQL 语句,生成答案。对简单的问题,回答的准确率几乎是 100%。但对复杂一些的问题,生成的 SQL 语句就只有 90% 的概率是正确的,而且有时错误不是随机的,很难通过多次生成的方法提高准确率。用户也没有办法判断长长的 SQL 语句到底对还是不对。
因此,自然语言回答 ERP 系统问题虽然 demo 效果很好,但没办法商用,因为它的准确率还不够高。后来我反思,这是由于我们尝试让 AI 代替人,而不是让 AI 辅助人。如果这个自然语言转化成 SQL 语句的功能是给开发 ERP 系统的程序员做助手,那可能很实用。但如果让不懂编程的普通用户随便问开放性问题,代替开发 ERP 系统的程序员,那准确率可能就不够。
有一篇很著名的文章叫做《The Bitter Lesson》,它说凡是能够用算力的增长解决的问题,最后发现充分利用更大的算力可能就是一个终极的解决方案。因此,对于工程方法很难解决的问题,我们应当对大模型本身的发展充满信心。
会议助理这个场景相比 ERP 智能助理就好多了,会议纪要里面有少量错误或者遗漏是无伤大雅的事情,毕竟与会人可以发现错误并且修正,这比人手工整理会议纪要的效率高多了。现在腾讯会议和 Zoom 已经推出了会议智能助理的功能,我在 San Francisco 还看到了 Zoom 会议智能助理的广告牌。
确定方向:有趣的 AI Agent
在做有用 AI 的同时,我们也在做一些有趣 AI 的尝试。
2023 年 8 月,我们帮一个客户做了一套 NFT 图片,解决了风格一致性、细节多样性、稀缺度控制等难题,这是用 Midjourney 肯定搞不定的。这套 NFT 在市场上反响非常热烈,也被炒到了很高的价格。
8-9 月,我用自己的博客文章做了一个自己的数字分身,也就是做了一个基于 RAG 的 AI Agent。我把她设定成我用 GPT-4 测出的理想伴侣特征,发现她比很多朋友都了解我。我感觉距离电影 Her 里面的 Samantha 不远了,只是支持文字聊天怎么行。于是又开始折腾多模态,以及在微软小冰的时候搞的情感系统。这就是被广泛转发的文章《Chat 向左,Agent 向右》。
9 月,我们还做了一个 AI 狼人杀 App。只要把狼人杀的规则和一些游戏技巧告诉 GPT-4,它就可以学会伪装、欺骗、分析言论和识破伪装。当然,AI 也有穿帮的时候,比如有时候狼人会自曝身份。在 ERP 这样的严肃场景中,这也许是不能容忍的。但在游戏中,一定的不确定性反而会使得游戏更好玩。
后来,我们还基于开源模型训练了自己的微调模型,以数百分之一于 GPT-4 的成本实现了同样好玩的狼人杀效果。理论上说,足够强大的长上下文模型加上足够好的 prompt 就可以碾压任何领域微调模型。但这里成本是关键。把所有背景知识都写进 prompt 里,就像桌面上摊开了一堆说明书,每做一步都要翻阅说明书。每个单词都查字典也能看懂外语文章,那我们为什么还要学外语呢?
因此,我们决定把创业的方向从 “有用的 AI” 转向 “有趣的 AI”。在当前大模型的技术水平下,有趣的 AI 更容易快速被市场接受。而且在 OpenAI 的带领下,大多数公司都在搞有用的 AI,做有趣 AI 的公司相对比较少,因此竞争也相对较少。
**一些人对 “有趣的 AI” 有一些偏见,主要是因为以 Character AI 为代表的产品做得还不够好。**Character AI 反复强调,自己是基础模型公司,beta.character.ai 这个应用至今还挂在 beta 域名上,就是一个测试版的产品。人家根本就没打算用现在形态的 Character AI 赚钱。但很多人看到了它是目前除了 ChatGPT 以外最大的 to C 应用,就以为这是一个很好的产品形态,Character AI 的克隆版或者改进版层出不穷。
受到 Character AI 的影响,很多人都以为,有趣的 AI Agent 就等于名人、动漫游戏角色的数字分身,用户跟它唯一的交互方式就是闲聊。但很多人都做错了。如果只是闲聊,用户很容易聊个 10-20 分钟就不知道该聊什么了,因此用户粘性和付费意愿都低得吓人。
2024 年 1 月初我参加知乎 AI 先行者沙龙的时候,一位嘉宾的发言我认为很有道理:有趣的 AI 价值更高,因为娱乐、社交是人的天性,最大的几家互联网公司大部分是娱乐、社交领域的。如果一个好的 AI 伴侣真的能给人带来情绪价值,或者游戏中的 AI 真的能让用户沉浸感更强,这样的 AI 不愁没人付费。
我还是认为,AI Agent 的终极目标应该是 “有趣 + 有用”。有趣的方面,就是它需要能够有自主思考的能力、有自己的个性和感情。而有用的方面,就是 AI 能够解决工作、生活中的问题。现在的 AI Agent 要么是只有趣但没用,要么是只有用但是不像人,不好玩。
我认为未来真正有价值的 AI 就像电影《Her》里面的 Samantha,她首先是一个操作系统的定位,能够帮主人公去解决很多生活中的问题、工作中的问题,帮他整理邮件等等,而且比传统的操作系统做得又快又好。同时它又有记忆、有感情、有意识,它不像一个电脑,而是像一个人。因此在感情空窗期的主人公 Theodore 就逐渐爱上了他的操作系统 Samantha。当然并不是所有人都把 Samantha 作为虚拟伴侣,剧中也说了,只有 10% 的用户跟他们的操作系统发展了浪漫关系。
2023 年 9 月底,我和思源在湾区一起头脑风暴公司到底该做什么。思源就想到一个我们公司的使命:人类世界的数字延伸(digital extension of humanity)。我也觉得非常好,就这样愉快的决定了。
找到足够有规模的垄断市场
Peter Thiel 在《Zero to One》中说,所有赚钱的公司都是垄断公司,这里的垄断指的不是靠政府资源垄断,而是在一个领域提供其他公司不能提供的服务。而且这个垄断领域不能太小,要足够有价值,足够养活一家公司。
例如,USTC 评课社区可以说是实现了科大课程点评这个领域的垄断。在 2023 年 12 月的选课季中,一天的页面访问量高达 46 万次,16 核 CPU 的服务器才撑得住这么多并发用户。要知道,科大每年只招不到 2000 名本科生,4 年一共不到 8000 人(研究生在课程上花的时间比较少),可以认为这 8000 名学生在选课开始那一天平均每人访问了 60 个页面。随便去找师弟师妹问问,就知道评课社区在科大本科生中的渗透率几乎是 100% 了。
但这样的网站是否适合做一个创业公司呢?我们之前大概估算过,如果评课社区上面放广告,仅仅通过广告盈利,一年大概可以收入 15 万人民币。换言之,每个学生每年可以贡献大概 20 块钱的营收。因为评课社区基本上只有在选课的时候有用,大多数时候访问量不大,非选课季的页面访问量只有不到 10 万次每天。
思源的 Chatbot Arena 也可以说是实现了大模型众包评估这个领域的垄断。尽管 Chatbot Arena 至今也只有 40 万个投票,不算一个规模多大的网站,但已经是大模型评估领域几乎最权威的标准,前面讲过 OpenAI 和 Google 发布大模型的时候都会引用 Chatbot Arena 的评估报告。这就是在一个细分领域中取得垄断的价值。
正是因为 Chatbot Arena 是 UC Berkeley 搞的一个公益社区,大家才愿意相信这个评测标准是公平的。这也是为什么我们至今都没有成立传统股权结构的公司。我们相信 AGI 的未来应该属于全人类,而不是一家封闭的商业公司。
如果把评课社区推广到更多的学校,这确实是一个可以做的公司。事实上由于评课社区是开源的,已经有好几家高校在我们的基础上二次开发,搭建了自己的评课社区,比如上海交大评课社区的访问量比我们还大。如果国内做 100 所一流大学,每所大学的访问量假设是科大的 2 倍(大多数大学本科招生不止 2000 人),那么一年大概可以收入 3000 万人民币。
有人说国内一共有几千所大学,一年招 400 多万本科生,潜在市场规模是科大的 2000 倍。但我觉得不能这么算,因为大多数高校学生对课程并没有这么认真。科大的评课社区里也有研究生课程,科大研究生的招生人数是本科生的 2.5 倍,但研究生课的访问量只占全站的 10%。这是因为研究生只有第一年上课,而且很多研究生对课程不是那么用心,因此对选课的需求没有这么大。本科生也一样,比较好的大学可能才更重视选课。
就算可以搞到 200 倍于现在的规模,这么大的规模也需要更多的研发、营销和社区运营成本。特别是在我们不熟悉的大学,推广和运营成本都会很高,国内的合规成本也会很高。最简单的,爬取每所大学的课程列表就是不小的工作量。按照互联网 20% 的利润率来估算,年净利润可能有 600 万人民币,这个利润可以支撑我们创始团队过上不错的生活,但是从风险投资人的角度来看,想象空间不是很大。
假如把评课社区做成一个创业公司,出去拉投资,那一定需要讲一个更大的故事,比如连接每个学生、每门课程和每个老师,做教育行业的 Yelp。甚至还可以发挥团队的国际化优势,发展全球市场。课程点评是大故事中的一个产品或者一个功能。就像 LinkedIn 那份著名的商业计划书,是互联网时代一个不错的故事。其实我很奇怪,在当年 “千团大战” 的时候,大家都在卷本地生活,为啥没有人做类似评课社区的东西。
不过,公司愿景和产品形态是不同的,我发现很多创始人把它们混为一谈,导致要么愿景格局太小,要么产品不够接地气。即使是一个产品,也需要先在细分市场内树立标杆,而不是撒胡椒面式的推广。假如我要做一个覆盖全球的评课社区,那仍然是首先搞定科大,树立标杆。Facebook 和人人网当年都是从一所学校做起的。
讲评课社区这个例子,是因为我还不想泄露公司的商业机密。我们创业团队也是在 2023 年底才找到了适合自己、有足够规模的利基市场,希望在这个市场中实现 “垄断”,创造难以替代的价值。
组建团队
有朋友说,我自己做外包一个项目也能赚几万美金啊,为什么要拉投资创业?我就说,创业的目的不在于赚钱而在于做事。Elon Musk 要把人送上火星,那靠一个人单打独斗是不可能的,一定要一个足够优秀的团队,有足够多的资金和资源才能做得成。
但是一旦开公司,开启社招,就很容易发生一个问题:员工的工作主动性不高,领导不安排就不知道该干什么。Peter Thiel 在《Zero to One》中就指出,创业公司不要打薪酬待遇之战,而要靠愿景和团队吸引与众不同的优秀人才。
比如我在科大搞的这些网络服务,没有任何报酬,也没有任何学分,完全是凭个人兴趣。从 2011 年在科大少院技术部开始维护机房服务器以来,我就一直处于随时待命修服务器的状态。我们有个 1-5-30 准则,就是服务故障之后 1 分钟报警,5 分钟响应,30 分钟恢复服务。
科大本科生没有网,冬天晚上当我收到服务器的报警短信的时候,那个年代手机开热点流量还太贵,我就要抱着笔记本跑到第一教学楼下,在寒风中蹲在地上,打开笔记本,连上 ustcnet WiFi,把服务器修好了再回来。大三,我搞了一个无线信号放大器,在寝室窗口就可以收到东区学生活动中心的 WiFi 信号了,终于不用大半夜往外跑了。
2016 年,我回学校的时候,不小心把学校教务系统里面少年班学院的所有学生都给删掉了,但我马上要去坐火车了,于是就在出租车上和火车上赶紧恢复了学生表。
我维护的这些网络服务很少有宕机超过 1 小时的。几个例外,一次是少院机房停电升级电力设施,freeshell 校内容器云服务就停了一天,这是事先通知的;一次是我的电脑被入侵导致 LUG 的几乎所有服务器沦陷;最近的一次是我的华为云账号因为爬数据跑了太多流量欠费了,欠费的时候我正在香港飞洛杉矶的飞机上,而服务器网络是按量付费的,导致评课社区挂了十几个小时。
功能特性开发也是如此,前段时间 taoky 主动给评课社区开发了一个富文本编辑器,还把之前特别慢的搜索功能改进了不少,我一测试发现基本上没什么问题。而一些社招的员工开发的功能没有测试就上线了,随便一测试就有很多问题,甚至有的问题口头说了之后还没有改,只有列到书面的 todo list 里面才能记住。
这就是为什么公司需要吸引有使命感、有责任心的人才。但不管是创业公司还是大公司,这样的人才都很贵,因此不能要求所有员工都这么强。**对于技术水平没有这么高,使命感、责任心没有这么强的员工,就需要靠制度来规范团队的行为。**例如书面的 todo list 可以防止遗忘,共享的团队知识库可以简化沟通,code review 和 committer 机制可以保证代码质量,测试和 CI/CD 可以避免上线了才发现不能用。
Life is all about connecting the dots
从 7 年前开始折腾挖矿机房和 Telegram 聊天机器人,到今天我们做人类世界的数字延伸,希望把每个人的时间变成无限的,很多看似没用的折腾和尝试最后发现都对今天的创业有着重要的意义。
我很喜欢乔布斯 connecting the dots 的比喻。所有之前做过的事情都会在合适的时候联系在一起。
大模型的故事才刚刚开始。