Groq 推理芯片:用空间换时间的把戏
最近 Groq 推理芯片以 500 token/s 的大模型输出速度刷屏了。
一句话来说,这个芯片就是玩了个用空间换时间的把戏,把模型权重和中间数据都放在了 SRAM 里面,而不是 HBM 或者 DRAM。
这是我 8 年前在微软亚洲研究院(MSRA)就做过的事情,适用于当时的神经网络,但真的不适合现在的大模型。因为基于 Transformer 的大模型需要很多内存用来存储 KV Cache。
Groq 芯片虽然输出速度非常快,但由于内存大小有限,batch size 就没法很大,要是算起 $/token 的性价比来,未必有竞争力。
Groq 需要几百卡的集群才能跑 LLaMA-2 70B 模型
 上图:Groq 推理芯片的 spec
上图:Groq 推理芯片的 spec
从 Groq 的 spec 不难看出,一个 Groq 芯片只有 230 MB 的 SRAM,带宽高达 80 TB/s,没有 HBM 或者 DRAM。作为对比,H100 有 96 GB HBM 内存,带宽是 3.35 TB/s。也就是说,Groq 的内存容量只有 H100 的 1/400,但它的内存带宽是 H100 的 25 倍。
Groq 的 int8 算力高达 750 Tops,fp16 算力高达 188 Tflops。作为对比,H100 的 tensor fp16 算力 989 Tflops,也就是 Groq 的算力是 H100 的 1/5。
Groq 用的是相对落后的 14nm 工艺,但也有 215W TDP,不算一个小芯片了,芯片制造成本肯定比 H100 低很多,但不可能比 H100 便宜 10 倍。
一个 LLaMA-2 70B 模型,就算做 int8 量化,也有 70 GB,就算不考虑中间状态的存储,那也需要 305 块 Groq 卡才能放下。
**Groq 还没有公布售价,如果按照跟 H100 的 fp16 算力比例估算售价,一张卡就要 $6,000,那么这个集群需要 $1,800,000。**有人会说这张卡 TSMC 的造价不会超过 $1,000,那我还要说 H100 的造价只有 $2,000 呢,芯片和软件生态的研发成本也是钱啊。
如果做 int8 量化,同样不考虑中间状态存储,一张 H100 就可以放下 LLaMA-2 70B,只需要 $30,000。当然,单块 H100 的吞吐量(token/s)干不过上述 Groq 集群。
**那么,Groq 集群和 H100 哪个性价比更高呢?**要回答这个问题,首先要搞清楚大模型是怎么拆成小块放进 Groq 卡的。
我在 MSRA 的空间计算探索
2016 年,我在微软亚洲研究院(MSRA)就搞过这种空间换时间的把戏,也就是把模型权重和中间状态全部放进 SRAM。我的博士回忆文章《MSRA 读博五年(二)自己主导的第一篇 SOSP》里面就讲了这段故事,在此摘录如下。
**微软把 Catapult FPGA 部署到数据中心的每台服务器,用于加速网络虚拟化之后,Catapult 团队就开始探索这些 FPGA 是否也能用来加速 AI。**学术界将 FPGA 用于 AI 训练和推理的文章已经连篇累牍,因此我们考虑的重点是如何利用高速网络来加速 FPGA AI。
当时,微软 Bing 搜索的排序算法是一个 DNN 模型。FPGA 做 DNN 推理有一个很大的局限,就是内存的带宽。当时我们的 FPGA 还没有 HBM 这么高速的内存,只有 DDR4 内存,两个通道加起来的带宽只有 32 GB/s。
大多数现有工作的做法是把模型放在 DRAM 里面,然后把模型分块,每一块都从 FPGA 片外的 DRAM 加载到 FPGA 片上的 SRAM(又称 Block RAM,BRAM),然后再在片上做计算。因此,数据搬移的开销就成了 FPGA 的主要瓶颈。编译器的工作就是优化分块形状和数据搬移,这也是我博士毕业后在华为 MindSpore 的第一个项目。
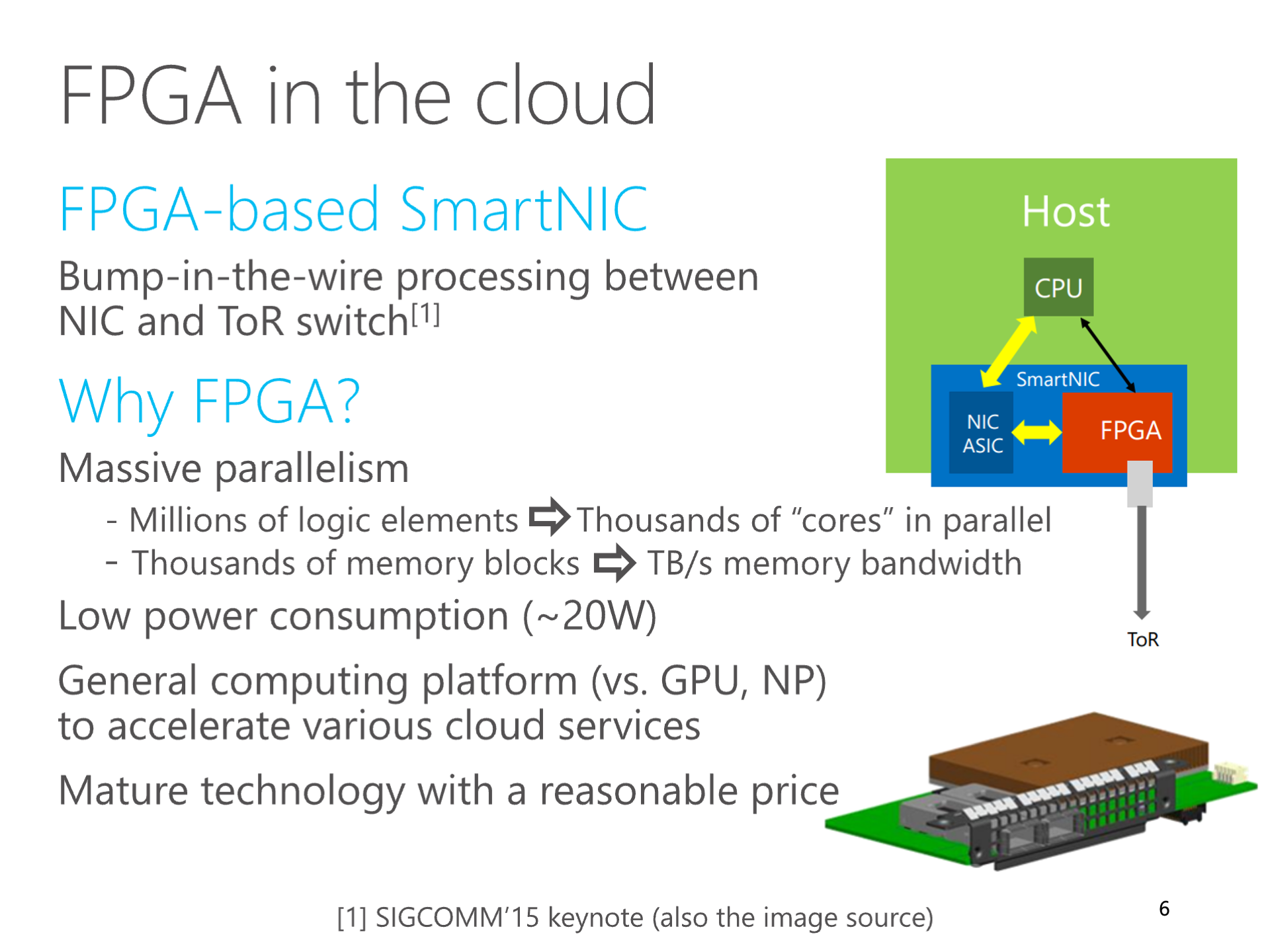 上图:我的 SIGCOMM 2016 ClickNP 论文对 FPGA 计算特征的总结
上图:我的 SIGCOMM 2016 ClickNP 论文对 FPGA 计算特征的总结
2016 年,我想到,**能否利用多块 FPGA 组成的集群,把深度神经网络模型拆分成若干块,使得每一块都能放进 FPGA 内部的 SRAM 高速缓存?**这样,需要通过网络传递的就是各块之间的中间结果。由于 FPGA 芯片之间有高速的互联网络,经过计算,对于我们使用的模型,传输这些中间结果所需的带宽并不会成为瓶颈。
我兴奋地把这个发现报告给我们硬件研究组的主管徐宁仪老师,他说,我想到的方法叫做 “模型并行”。在一些场景下,这种 “模型并行” 的方法确实相比传统的 “数据并行” 方法能取得更高的性能。尽管这并不算是一个理论创新,但徐宁仪老师说,把整个模型都放进 FPGA 内部的 SRAM 高速缓存这个想法是有点意思的。这就像是把很多块 FPGA 利用高速网络互联,当成了一块 FPGA 来用。
为了跟数据仍然放在 DRAM 里的传统模型并行方法相区分,我们把这种所有数据都放在片上 SRAM 内的模型并行方法叫做 “空间计算”(spatial computing)。
**空间计算这个名词听起来很高大上,但其实是最原始的。**我们搭建一个逻辑门组成的数字电路来完成特定的任务,这就是空间计算。基于图灵机理论的微处理器诞生之后,时间计算就成为主流,微处理器在不同的时刻执行不同的指令,这样只需要一套硬件电路,就可以完成各种各样的任务。但从体系结构的角度看,微处理器是用效率换取了通用性。
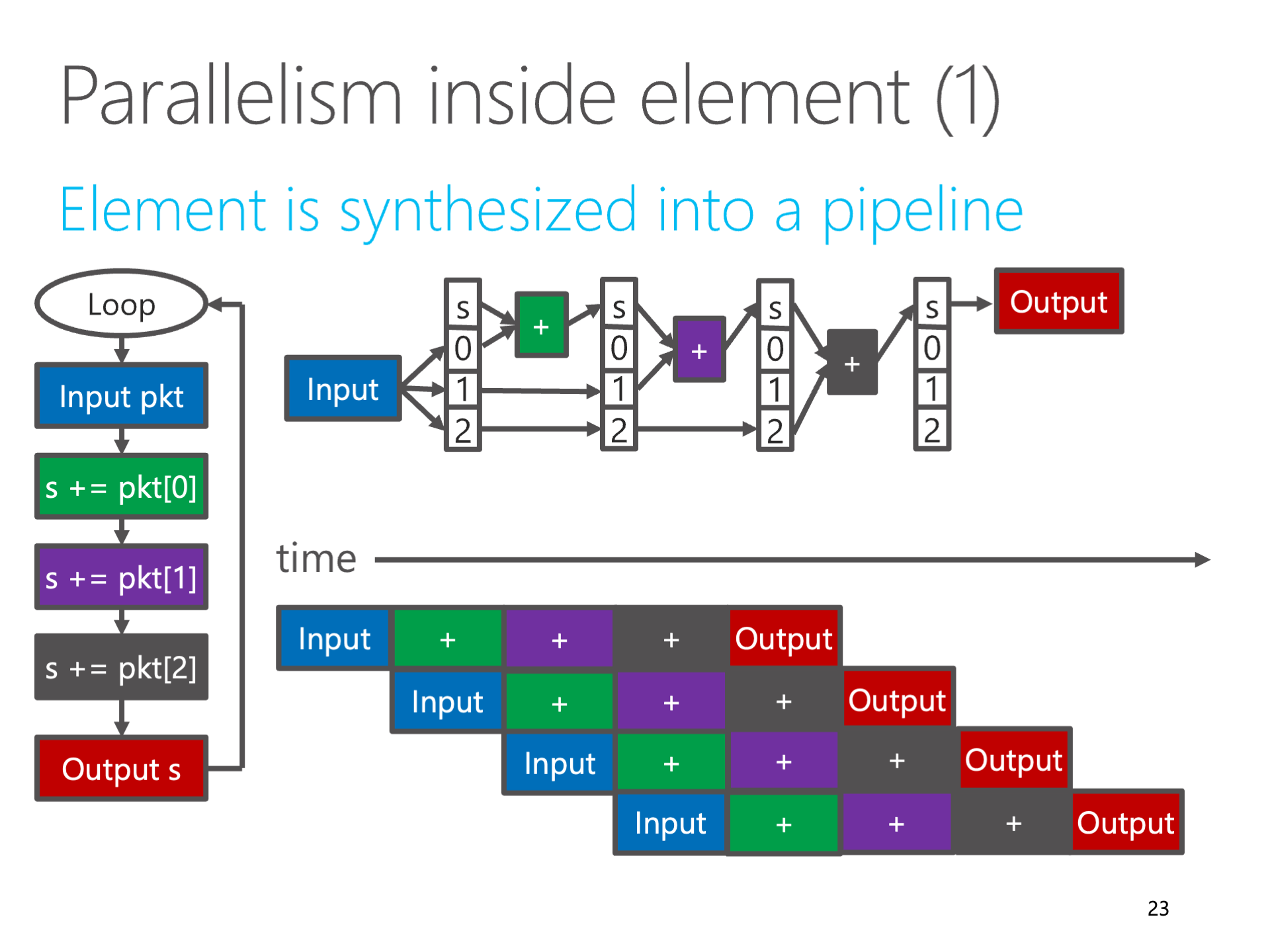 上图:用流水线把计算逻辑完全流水线化,就是空间计算
上图:用流水线把计算逻辑完全流水线化,就是空间计算
**在 FPGA 和 ASIC 的世界里,为了效率,空间计算仍然是主流。**在 FPGA 高层次综合(HLS)中,循环次数固定、不包含任意跳转的代码(编译领域的学名叫做 SCoP,Static Control Part,静态控制区域),可以进行完全的循环展开和函数内联,进而转换成一块组合逻辑,在合适的地方插入寄存器后,就变成一条完全流水线化的数字逻辑了。这样的数字逻辑每个时钟周期都可以接受一个输入的数据块。
搞分布式系统的都知道,多台机器组成的集群难以实现线性加速比,也就是说机器多了,通信和协同的代价高了,平均每台机器的产出就少了。但这种 “空间计算” 的方法在 FPGA 数量足够多到能够在片上 SRAM 容纳下整个模型时,可以实现 “超线性” 加速比,也就是模型并行中每个 FPGA 的平均产出相比单个使用数据并行方法的 FPGA 更高。
解决了访问模型的内存带宽问题,FPGA 的算力就可以充分释放出来。我们做了一个思想实验:微软 Azure 数据中心每台服务器都部署了一块 FPGA,**如果把整个数据中心的 10 万块 FPGA 的算力都像一台计算机一样集中调度起来,只需要不到 0.1 秒,就可以翻译完成整个维基百科。**它也在微软的一场官方发布会上作为一个业务场景做了演示。
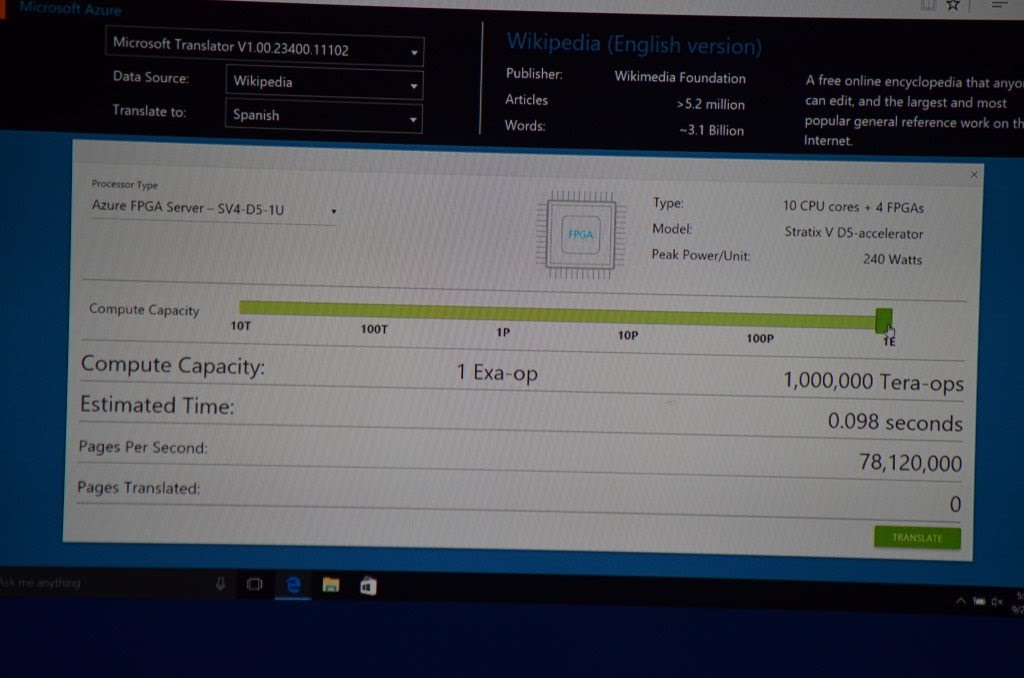 上图:微软发布会上用 FPGA 加速机器翻译的 demo,如果把整个数据中心 1 Exa Ops 的算力都用起来,只需要不到 0.1 秒就可以翻译完整个维基百科
上图:微软发布会上用 FPGA 加速机器翻译的 demo,如果把整个数据中心 1 Exa Ops 的算力都用起来,只需要不到 0.1 秒就可以翻译完整个维基百科
大模型做空间计算的 KV Cache 困境
空间计算的故事是不是听起来很美好?但问题在于今天基于 Transformer 的大模型并不是当年我们做的 DNN 模型。
DNN 模型的推理过程中需要存储的中间状态很少,比权重小很多。但 Transformer 的 decode 过程中需要保存 KV Cache,而且这个 KV Cache 的大小与上下文(context)长度成正比。
假设我们不做任何 batching,那么对于 LLaMA-2 70B 模型(int8 量化),假设输入和输出的上下文 token 数量达到了最大的 4096,80 层的 KV Cache 一共需要 2 (K, V) * 80 (layers) * 8192 (embedding size) * 4096 (context length) * 1B / 8 (GQA 优化) = 0.625 GB。(感谢好几位朋友指出我第一版文章中的错误,忘记考虑 GQA 优化了,导致认为 KV Cache 的存储开销过大)
相比 70 GB 的权重,0.625 GB 看起来不多吧?但如果真的不做 batching,价值 $1,800,000 的 300 多张 Groq 卡就只能达到 500 token/s 的吞吐量,这么大的集群只能服务一个并发用户,按照每 token 的价格计算,就是 $3,600 / (token/s)。
那么 H100 的每 token 价格怎么样呢?
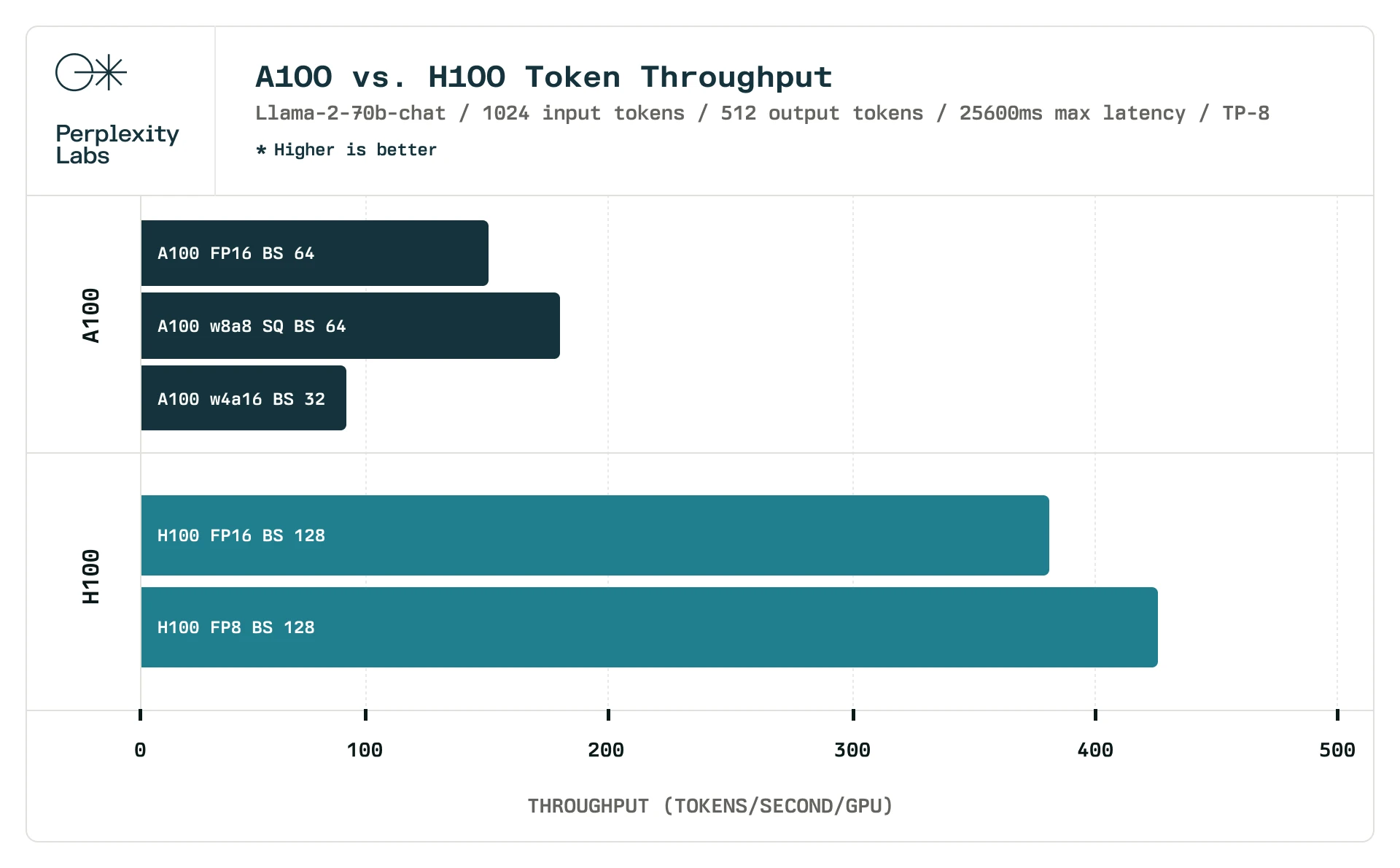 H100 每张卡的吞吐量(token/s),来源:Perplexity AI
H100 每张卡的吞吐量(token/s),来源:Perplexity AI
根据 Perplexity AI 的数据,对 LLaMA-2 70B,在 batch size = 128 的时候,8 卡 H100 机器平均每张卡的 int8 推理性能大约是 425 token/s。按照每张 H100 卡 $30,000 计算,那就是 $70 / (token/s)。价格相差 50 倍!
为了让我们昂贵的 Groq 集群也能多服务几个并发请求,我们就需要增加 batch size,比如增加到跟 8 卡 H100 机器的典型设置 batch size = 128 相同。KV Cache 的大小是跟 batch size 成正比的,一个样本是 0.625 GB,128 个样本就是 80 GB。
注意,模型本身只有 70 GB,KV Cache 这些中间状态有 80 GB,这 150 GB 内存至少需要 652 张 Groq 卡来放下。这个集群的成本高达 $3,912,000,只是前面 batch size = 1 的 2 倍。128 个并发请求是 128 * 500 = 64,000 token/s,那么就是 $61 / (token/s),价格比 H100 还稍低一些。
我们知道 H100 本身已经有很高的溢价了,很多人都在想着用 4090 集群来做推理,比 H100 至少便宜一半。(如何用 4090 集群跑 70B 模型是另外一个问题,这里就不讨论了。)现在来了个跟 H100 性价比差不多的芯片,还只能做 Transformer,能不能跑 diffusion model 还不一定呢,你说买不买?
那么其他 batch size 是否存在甜点呢?batch size 每增加 1,就要存储 0.625 GB 的 KV Cache,这就需要 3 张 Groq 卡。其他 AI 芯片一般都是算力或者内存带宽瓶颈,Groq 的瓶颈却是内存容量。也就是说每个并发请求,或者说每 500 token/s,都需要增加价值 $18,000 的 3 张卡,每 token 价格不可能低于 $36 / (token/s) ,虽然比 H100 便宜,但是仍然达不到 4090 的水平。(Groq 每张卡的 TDP 是 215W,跟 4090 一样 token/W 比较低,电力成本比较高)
Groq 不需要给 NVIDIA 贡献利润
有人会问,为啥 Groq 宣称他们的推理服务价格比使用 NVIDIA 芯片的 Anyscale、Together AI 等公司还低呢?这是因为 Groq 自己就是做芯片的,没有 NVIDIA 这个中间商赚差价。
对于 Groq 来说,估计售价 $6,000 的芯片自己的成本可能还不到 $1,000。如果按照每张 Groq 卡 $1,000 来核算成本,那 batch size = 128 的集群成本就只要 $652,000,每 token 价格就是 $10.2,比 H100 便宜 7 倍。 当然,这里都没有考虑电力成本、主机成本和网络设备成本,在芯片都用成本价来算的时候,电力成本可能反而成了大头了,就像挖矿一样。
但是如果 NVIDIA 自己也用 H100 的成本价 $2,000 来提供推理服务,那每 token 价格就直接降低到 1/15,每 token 只要 $4.7,比 Groq 按成本价核算还便宜一半。由此可以看到 NVIDIA 的利润空间有多大了。
NVIDIA 高达一半以上的净利润率,营收还快赶上阿里了,这样赚钱的垄断生意要有航母才守得住。难怪 Sam Altman 看不下去了,OpenAI 辛辛苦苦做模型赚的钱都喂给 NVIDIA 了,因此要组个 7 万亿美金的局,从沙子开始,重塑整个芯片行业。
模型越大,空间计算的网络挑战越大
如果我们要推理的不是 70B 的 LLaMA-2,而是号称 1,800B 的 GPT-4,又会怎么样?
单是放下所有这些参数,哪怕用 int8 量化,都需要 7,826 张卡。这还不算 KV Cache。
在这么大的规模下,空间计算的网络互联会有很大的挑战。
7,826 张卡就算是把流水线并行做到极致,Transformer 每层一个流水级,假设 GPT-4 也是 80 层,每个流水级都需要 100 张卡做张量并行(tensor parallelism),这 100 张卡需要很高性能的 all-to-all 通信。为了维持 2 ms/token 的高吞吐量,网络通信延迟也必须在微秒级别。在万卡的规模下,这对网络互联的挑战是非常大的。
因此我猜测 Groq 做的可能不是一个基于交换机的互联网络,而是一个点对点的互联拓扑,每张卡互联周围的若干张卡,就像超算里面常见的 2D/3D Torus 一样。微软的 Catapult FPGA 一开始也是想搞这种类似超算的点对点拓扑,虽然数学上很漂亮,但最后发现通用性不强,还是改成了依靠基于标准交换机的 fat-tree 网络。当然 Catapult FPGA 的互联带宽不可与 NVLink 和 Groq 同日而语。
如果 Groq 能把 GPT-4 也做到 500 token/s 的输出速度,我真的会很佩服他们。
此外,上 TB/s 的网络互联既然都做出来了,为什么不用它互联 HBM 内存?
虽然用 SRAM 做 HBM 内存缓存的想法不太靠谱(Transformer 每个参数都要访问,没有局部性),但有了 HBM 至少可以做持久化 KV Cache 这些优化,比如把上百 K token 的 prompt prefill 进去,把 KV Cache 放到 HBM 里面,需要的时候再加载进来,这样就省去了很多重新计算 KV Cache 的 prefill 成本。
用过 OpenAI API 的都知道,大多数场景下 API 最烧钱的是输入而非输出。输入包括 prefill prompt(背景知识和指令)和 conversation(历史对话),输入长度经常动辄数十 K token(本文计算 KV Cache 内存容量时假设最长 4K token),但输出长度却很少超过 1K token。虽然每输入 token 比每输出 token 便宜,但输入的成本仍然一般高于输出。如果能够降低 KV Cache 重新计算的开销,功莫大焉。
结论
Groq 的优点是:通过把所有数据放进 SRAM,达到很高的内存带宽,进而实现很高的单请求 token/s,不管用多少块 H100 都很难达到 500 token/s 的输出速度。对输出速度要求很高的应用场景,以 Groq 为代表的空间计算是很有前景的。
Groq 的缺点是:每块卡的 SRAM 容量有限,KV Cache 占用的内存很大,需要很大的集群规模。因此:
- 如果 Groq 跟 NVIDIA GPU 类似,按照算力来对芯片定价,那么推理成本跟 H100 相当。
- Groq 集群的门槛高,最低配置都要 300 张卡,$1.8M 的投资,它的性能太差;如果要性价比高,就要 1000 张卡,$6M 的投资。相比之下,8 卡 H100 的 $0.3M 太便宜了。
其实我有个大胆的猜测,Groq 的架构可能是为上一代 DNN 而非 Transformer 设计的,当时还没有想到 KV Cache 会占这么多内存,空间计算是个很漂亮的 idea,就像我们当年在微软也是这么做的。这两年 Transformer 火了,但芯片设计不那么容易改动,就用 “地表最快 token 输出速度” 这个技术指标,一下子搞了个大新闻。
Transformer 是个很干净、通用的架构,对芯片来说,就是拼算力、内存容量、内存带宽、网络带宽这些硬指标,没有什么可玩花招的。