OpenAI 开发者大会:意料之中的惊艳
(本文首发于知乎)
作为一个 AI Agent 领域的创业者,其实感觉 OpenAI dev day 没有想象的那么惊艳,发布的东西都是在预期范围内的,大概是同行容易相轻吧。
简单总结的话,就是 GPT-4 Turbo 提供了 128K context,知识更新到了 2023 年,API 支持了多模态,支持模型微调,成本降低,速度提升,的确是非常重要的提升,但 GPT-4 相比 GPT-3.5-Turbo 和 LLaMA 的成本仍然高出一个数量级,大规模商用有一定挑战。
Agent 领域其实没有特别多惊艳的,主要就是做了一个 Agent Platform。API 强制用 JSON 格式输出和支持多个 function call 也是非常实用的。但是,Agent 最核心的 memory(记忆)、autonomous(自主意识)、task planning(任务规划)、persona(性格)、emotions(情感)等问题,这次 OpenAI 发布会并没有给出解决方案。如果说今天 OpenAI 发布会之后,一个 Agent 公司的核心竞争力没了,那应该首先反思一下是不是技术护城河太浅了。
GPT-4 Turbo
最惊艳的部分是 GPT-4 Turbo,主要包括几大特性:
 GPT-4 Turbo 的主要特性
GPT-4 Turbo 的主要特性
长上下文
原来是 8K,现在支持 128K 上下文了。如果放到半年前,128K 上下文是很了不起的事情。但长上下文的关键技术已经比较普及,目前很多模型都能支持长上下文了,比如 Claude 能支持 100K context,Moonshot 能支持 250K context,零一万物的 Yi-34B 开源模型支持 200K context。
就算是基于现有的 LLaMA-2 模型,把 4K context 扩展到 100K context 也不是很难的一件事。我的 cofounder @SIY.Z 在 UC Berkeley 做的 LongChat 可以把 context 增加 8 倍,还有 RopeABF 等工作可以进一步把 context length 提升到 100K 的量级。当然,这样提升出来的 context 相比预训练的时候就用更长的 context,可能在复杂语义理解和 instruction following 上有一定的性能差距,但是做个简单的文本总结是足够的。
长上下文不是万金油,有些做 Agent 的人惊呼,有了长上下文,就不再需要 vector database 和 RAG 了,Agent 的记忆问题也被完全解决了,这是完全不考虑成本的说法。上下文输入每个 token 都是要钱的,$0.01 / 1K tokens,那如果把 128K token 的 context 打满,一个请求可就是 $1.28,将近 10 块钱人民币了。大多数人,尤其是 to C 产品,恐怕都付不起这个钱。
所以说在目前的推理 Infra 下,如果 KV Cache 不持久保存,to C 的 Agent 不可能把一年的聊天记录全部塞进 context 里面让它从头算 attention,这样的推理成本太高了。同理,企业信息检索类的 app 也不可能每次都把所有原始文档从头读一遍。Vector database、RAG 和 text summary 仍然是非常有效的降低成本的方法。
知识更新
这个确实很好,知识库从 2021 年 9 月更新到 2023 年 4 月了。其实更新基础模型的知识库是一件挺难的事情。首先,数据清洗的质量非常重要,据说 OpenAI 在做 GPT-3.5 和 GPT-4 的过程中走了一些人,导致长时间没人重新做新数据的清洗工作,因此模型长达一年半没有更新。
其次,更新知识库之后的模型往往需要重新训练,至少需要把新数据(就是 knowledge cutoff 之后新产生的数据)和旧数据按照一定的配比来混合训练。绝不能仅仅使用新数据进行训练,否则会出现灾难性遗忘的问题,学了新的知识就忘了旧的。如何向现有模型中添加大量的新知识,又尽量减少重新训练的开销,是一个非常值得研究的问题。
多模态
OpenAI 近期发布了多个多模态模型,包括图片输入的 GPT-4V 和图片输出的 DaLLE-3,这两个多模态模型分别是图片理解和图片生成的 state-of-the-art。
可惜的是,GPT-4V 和 DaLLE-3 一直只能在 Web 界面中访问,没有提供 API。这次 OpenAI 把 API 给开放出来了。同时,OpenAI 还发布了 TTS(语音合成)API。加上原有的 Whisper,图片、语音的输入输出几个模态都齐活了。
GPT-4V 的价格并不高,输入一个 1024x1024 的图片,只要 765 个 token,也就是 $0.00765。
但是 DaLLE-3 图片生成的价格就比较高了,一张 1024x1024 的图片要 $0.04,跟 Midjourney 的价格差不多。如果自己 host Stable Diffusion SDXL 模型的话,生成一张图的成本可以控制在 $0.01 以下。当然,DaLLE-3 的图片生成质量比 Stable Diffusion SDXL 高很多。例如 SDXL 难以解决的画手指问题、生成带指定字的 logo 问题、复杂的物体位置关系问题,DaLLE-3 就能做得比较好。
Whisper 原来开源的是 V2 版本,这次发布的是 V3 版本,既提供 API,同时也是开源的。之前我就发现,ChatGPT voice call(语音通话)的识别率比我自己部署的 Whisper V2 模型高,果然是 OpenAI 自己隐藏了大招。不过不管是 V2 还是 V3,识别率都已经很高了,除了人名和一些专有名词,日常英语的识别准确率几乎是 100%,即使有少量错误也不妨碍大模型理解意思。
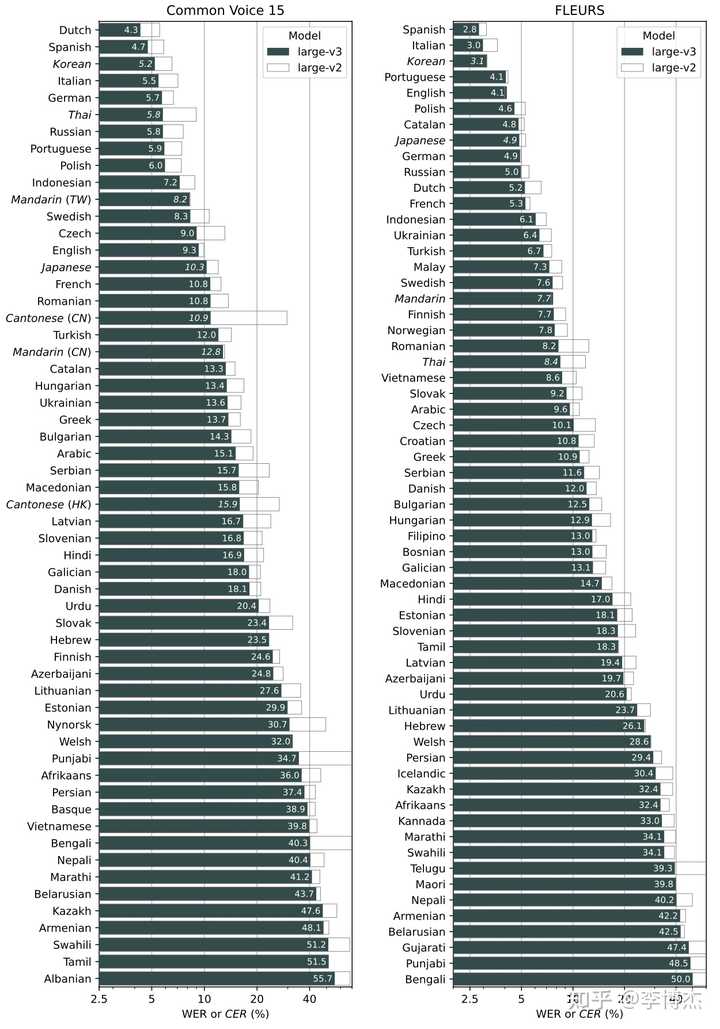 Whisper V2 和 V3 的识别错误率对比
Whisper V2 和 V3 的识别错误率对比
TTS 其实现在开源的 VITS 和其他家的 Google TTS 已经做得不错了。OpenAI 这个模型的语音合成效果自己感觉是更好的。
希望 OpenAI 能够早日推出根据自己提供的语音语料微调 TTS 的能力。很多时候我们需要合成一个特定人或者角色的声音,而不是用千篇一律的声音。当然,微调之后的模型就没办法在推理的时候做 batching 了,会导致推理成本大幅提高。未来更靠谱的方案也许是将特定人或者角色声音的音色提取出来,变成若干个 token,输入到一个统一的模型里,这样就不需要对特定人的语音做微调了,可以用一个模型生成多个人的语音。
支持模型微调
GPT-3.5 16K 版本和 GPT-4-Turbo 都支持模型微调了,这是一件好事。OpenAI 还做起了外包,针对有特别复杂需求的大客户,还可以定制模型。微调之后的模型由于不方便做 batching,至少 LoRA 部分无法 batching 不同的微调模型,推理成本一定是比原来的模型更高的。这也是对推理 Infra 的一个挑战。
成本降低,速度提升
相比 GPT-4,GPT-4-Turbo 输入 token 的成本降低到 1/3,输出 token 的成本降低到 1/2,这是一件大好事。但是 GPT-4-Turbo 相比 GPT-3.5-Turbo 的成本仍然是高一个数量级的,输入 token 高 10 倍($0.01 vs $0.001 per 1K tokens),输出 token 高 15 倍($0.03 vs. $0.002 per 1K tokens)。这样,对成本敏感的应用肯定是需要权衡的。
 新老模型的成本对比
新老模型的成本对比
微软有一篇已经撤稿的 paper 说 GPT-3.5-Turbo 是 20B 的模型,我个人表示怀疑。从 API 成本上推断,以及从 temperature = 0 时输出结果的不确定性推测,GPT-3.5-Turbo 更可能是 100B 以上的 MoE 模型。因为之前已经有泄露的消息说 GPT-4 是 MoE 模型,其实 GPT-3.5-Turbo 是 MoE 模型的可能性也很大。
为了解决 MoE 模型 batching 和 temperature > 0 带来的输出不确定问题,OpenAI dev day 推出了可重复输出功能,通过固定种子,可以保证 prompt 相同时的输出相同,以便调试。
未来的应用很可能需要 model router 的能力,根据不同类型的问题选择不同成本的模型,这样就可以在降低成本的同时,保证性能不明显下降。因为大多数应用中,用户的大多数问题都是简单问题,并不需要麻烦 GPT-4。
提升 Rate Limit
原来 GPT-4 的 rate limit 非常低,经常用着用着就触发 rate limit 了,根本不敢上线用来服务高并发的用户请求。现在 GPT-4 的 rate limit 提升了,每分钟可以用 300K token,小规模服务应该是够用了。如果用满 300K token,每分钟就会烧掉 3 美金,先看看账上的钱够不够烧吧。
用户每个月可以用的 credit(配额)也增加了,这是一件好事。原来要超过 120 美金每月的配额,还要专门申请。
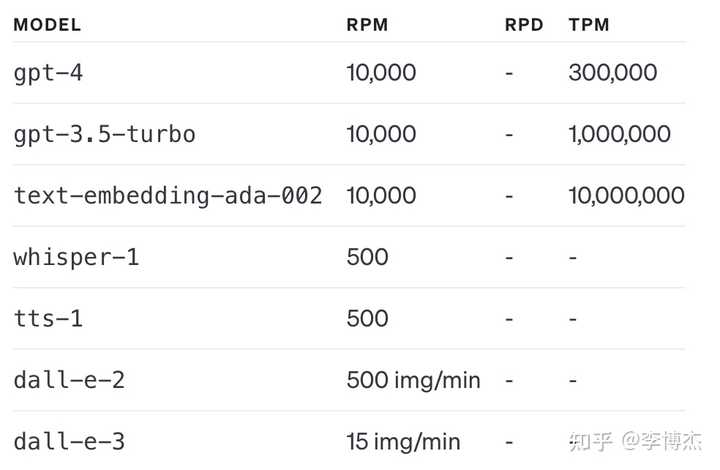 目前的 GPT 配额
目前的 GPT 配额
但是 GPT-4-Turbo 目前的配额很少,每天只有 100 个请求,跟 Web 界面上的 GPT-4 一样抠门。希望能够早日增加 GPT-4-Turbo 的 rate limit,让它能够在生产环境中使用。
Agent
早就有传闻说 OpenAI 一直在 Agent 领域憋大招,果然这次 OpenAI dev day 的后半部分就 focus 在 Agent 上了。
OpenAI 的 App Store
OpenAI 早就搞了 plugin(插件)系统,设想搞成大模型应用的 App Store,但是一直不太好用。这次发布的 GPTs 离这个梦想更近了一步。
GPTs 最大的创新在于提供了 Agent Platform,可以理解成 Agent 的 App Store。
GPTs 让用户可以定制属于自己的 Agent,使其更适应在日常生活、特定任务、工作或家庭中的使用,并分享给其他人。例如,GPTs 可以帮助你学习任何棋盘游戏的规则,帮助你的孩子学习数学,或者设计贴纸。任何人都可以简单地创建自己的 GPT,不需要编程。创建一个 GPT 就像开始一次对话,提供指示和额外的知识,并选择它可以做什么,比如搜索网页、制作图片或分析数据。
OpenAI 还将在本月晚些时候启动 GPT 商店,用户可以在 GPT 商店里购买 GPT(购买 GPT 听起来怎么怪怪的,还不如叫 Agent)。在商店里,可以搜索 GPTs,还有排行榜。GPT 的作者可以获得收益。
我一开始感觉 GPT 这个名字不好听,还不如用 Agent 呢。最后 Sam Altman 解释了,“Over time, GPTs and Assistants are precursors to agents, are going to be do much much more. They will gradually be able to plan, and to perform more complex actions on your behalf.“(随着时间推移,GPTs 和助手将成为 Agent 的前身,将能做越来越多的事情。它们将逐渐能够规划,代表你完成更加复杂的行动。)也就是说,Sam Altman 对 Agent 的期待很高,他认为现在的这些应用还不足以被称为 Agent,任务规划这些核心问题还没解决,这也许是 OpenAI 没有用 Agent 这个名词的原因吧。
Assistants API
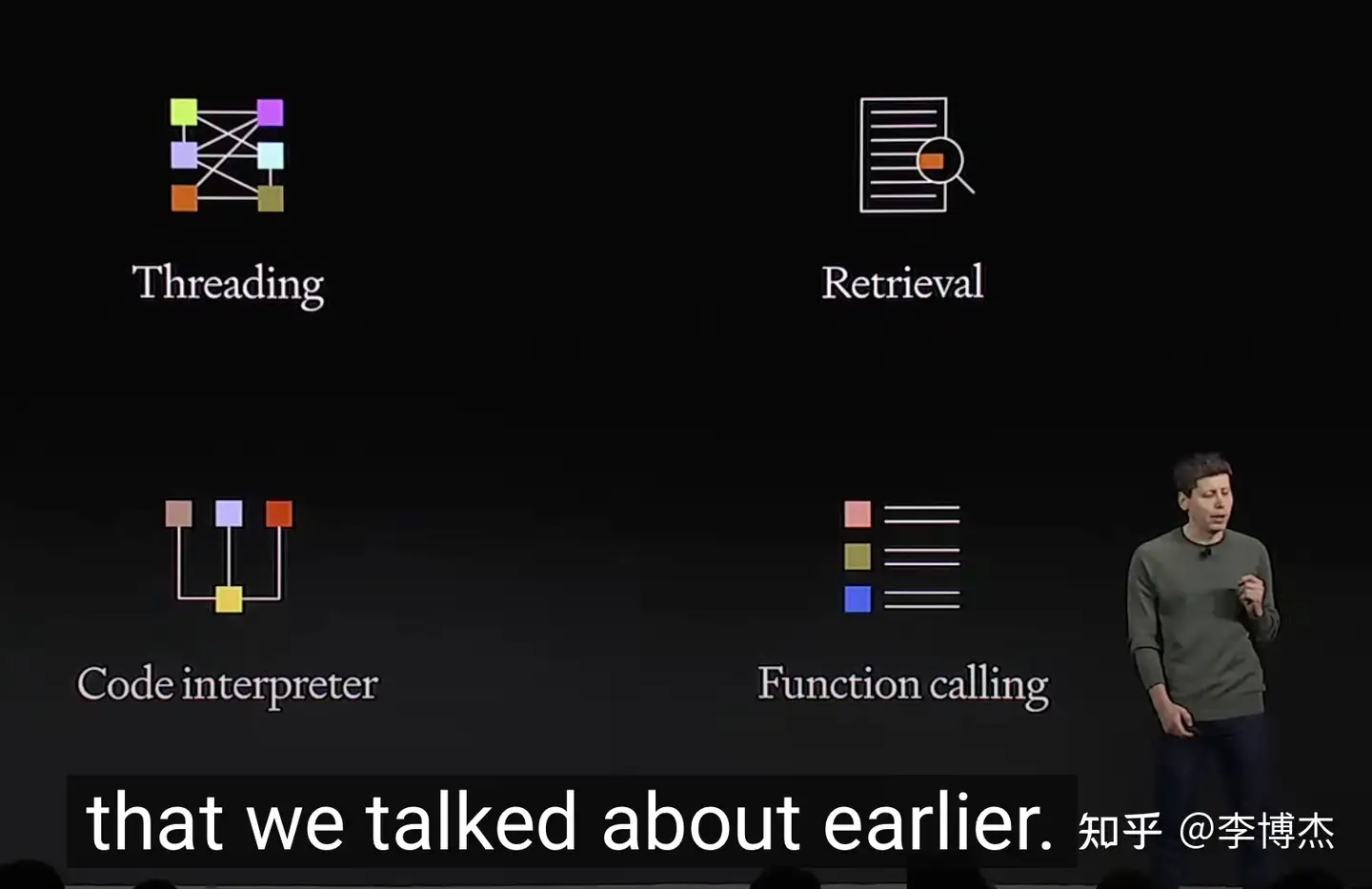 Assistants API 的四项核心能力
Assistants API 的四项核心能力
为了方便用户创作 GPT(就是 Agent 应用),OpenAI 推出了 Assistants API(助手 API),提供了持久的、无限长的 thread,代码解释器,搜索,函数调用等核心能力。原来需要用 LangChain 干的事情,现在用 Assistants API 大部分也可以做了。
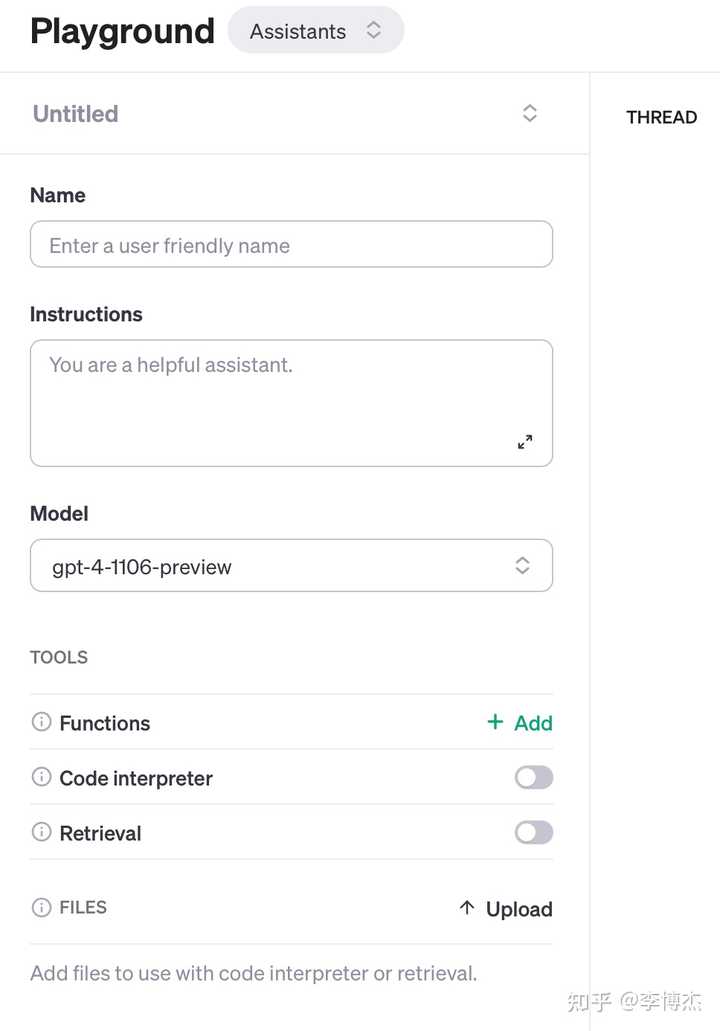 Assistants 的创作界面
Assistants 的创作界面
Assistants API 引入的关键变化是持久的、无限长的 thread。开发者不再需要关心 thread 的状态管理问题,也不需要关心上下文窗口约束的问题。
这个持久的、无限长的 thread 表面上看起来只是增加了一个存储功能,把对话从无状态变成有状态了,但事实上是实现记忆、提高用户粘性的关键一步。
如果一个平台只是提供无状态的 API,那么随时都可以被取代,现在很多家大模型的 API 都是跟 OpenAI 兼容的,import openai 之后设置一下接口地址就能替换掉了,因此 OpenAI 唯一的优势就是模型性能和成本,一旦出现更有竞争力的模型,很容易就会被替代掉。
但有状态的 thread 就不一样了,它保存了用户跟 Assistant 沟通的记忆,随着时间推移,Assistant 会越来越懂你,就像一个认识多年的朋友,是没有办法轻易取代的。我一直认为 Agent 的记忆是非常关键的,它不仅可以改进用户体验,降低 Agent 与用户的沟通成本,同时也可以提高用户粘性,让用户产生依赖感。
此外,Assistants 还可以在需要的时候调用新的工具,包括:
代码解释器:在一个沙箱执行环境中编写并运行 Python 代码,并能生成图表,处理各种数据和格式的文件。Assistants 可以运行代码来解决复杂的代码和数学问题。
检索(RAG,Retrieval Augmented Generation):利用大模型之外的知识来增强助手的能力,例如来自专有领域的数据、产品信息或用户提供的文档。OpenAI 会自动计算和存储 embedding,实现文档分块和搜索算法,不再需要自己折腾了。相当于是一个 SaaS 版的 LangChain。
函数调用:函数调用是 OpenAI 为构建 Agent 推出的杀手级功能。其中有两个亮点。
 GPT 一次生成多次函数调用
GPT 一次生成多次函数调用
第一,支持使用严格的 JSON 格式输出。以往的模型经常会在输出的 JSON 前后增加一些不必要的前缀和后缀,这样还需要做后处理才能喂给 API。现在可以指定强制使用 JSON 格式输出了。
第二,支持一次生成多次函数调用。以往一般一次大模型只能输出一次函数调用,这样如果整个过程中需要多个外部 API 配合,就需要多次大模型介入,不仅增加了处理延迟,也增加了 token 成本的消耗。OpenAI 通过强大的代码生成能力,使得一次大模型调用就可以生成多次串联在一起的函数调用,从而显著降低复杂工作流场景下的延迟和成本。
应用示例
OpenAI 展示的几个应用的例子不错,不过都是其他人做过的。OpenAI 想展示的是在这个平台上可以很容易地创建自己的 Agent。
比如旅行助理 Agent 的例子,恰好就是昨天我自己干的事情。我昨天早上去 USC 玩,在校园里遇到几个游客,问我能不能带他们逛一逛,我说我也是第一次来,要不让 AI Agent 陪我们一起逛吧。然后就让我自己做的 AI Agent 带着我们去了几个标志性的建筑。
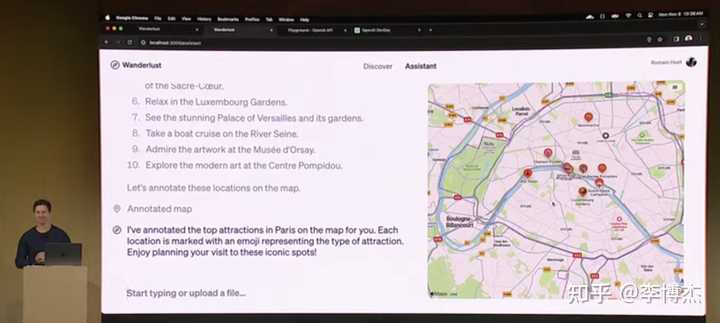 OpenAI 展示的旅行助理 Agent
OpenAI 展示的旅行助理 Agent
使用 Whisper、TTS、GPT-4V、DaLLE-3,可以轻松做出多模态 Agent。DevDay 上展示的可以语音聊天抽奖的 App 就是用 Whisper 和 TTS 做出来的。
 OpenAI Dev Day 最后展示的可以语音聊天抽奖的 Agent
OpenAI Dev Day 最后展示的可以语音聊天抽奖的 Agent
最后这个 AI 抽奖环节和给每个人 $500 API credit 的 Agent,真是把节目的效果拉满了,不愧是 AI 界的春晚呀。
ChatGPT 改进
首先,ChatGPT 把之前 GPT-4 里面的 Bing Search、DaLLE-3 等功能合一了,用户无需在不同模型间切换,ChatGPT 会自己选择调用哪种插件。
其次,ChatGPT 新增了 ChatPDF 的功能,使得 ChatGPT 可以直接处理 PDF 和其他类型的文件。这一下子把 ChatPDF 给干没了。
创业公司的护城河在哪里
很多人看了 OpenAI dev day 之后,惊呼大模型生态里面原来那么多公司,现在要只剩下 OpenAI 一家了。
 一位网友的评论,大模型生态要只剩下 OpenAI 一家了
一位网友的评论,大模型生态要只剩下 OpenAI 一家了
之前也有很多创业者不断在讨论,要是我做的东西 OpenAI 也做了,怎么办?
其实这个问题跟之前国内互联网创业圈的经典问题一样,要是我做的东西腾讯也做了,怎么办?
我的回答很简单,要么做 OpenAI 不做的东西,要么做 OpenAI 暂时还做不出来的东西。
比如我们公司做的 companion bot(陪伴类 Agent),是 OpenAI 明确表示不做的,Sam Altman 多次表示类人的 Agent 没有价值,真正有价值的是辅助人完成工作的。OpenAI 和微软的价值观比较匹配,都是做企业级的、通用的东西,看不上泛娱乐的东西。虽然陪伴类 Agent 这个赛道也非常卷,基本上每家大模型公司都在推出陪伴类 Agent,但是目前还没有做得特别好的,至少没有一个能做到《Her》里面 Samantha 的水平。这个领域还有很多基础问题需要解决,例如 task planning、memory、persona、emotions、autonomous thinking,上限非常高。
另外一个例子是开源模型,低成本模型,这也是 OpenAI 很可能不会做的。OpenAI 是往 AGI 方向走的,一定是要让模型的能力越来越强,7B 的小模型根本入不了 OpenAI 的法眼。但是 GPT-4 的价格我们也看到了,就算 GPT-4-Turbo 也仍然很高。事实上对于 to C 的很多场景,连 GPT-3.5-Turbo 的价格都是无法承受的高。因此,在很多场景下,我们需要自己 host 7B、13B 的模型,解决用户大部分的简单需求。据说,Character.AI 是自研的 7B 左右大小的对话模型,每个请求的成本是 GPT-3.5-Turbo API 的 1/10 以下。虽然 Character 有时候看起来比较笨,memory 和 emotions 都做得不好,但人家成本低呀!低成本会成为公司的核心竞争力。
第三个例子是游戏,大模型肯定会深刻改变游戏行业,但 OpenAI 不太可能自己涉足游戏,就算做游戏也是跟游戏公司合作。比如最近大火的《完蛋!我被美女包围了!》,以及很多宅男宅女喜欢的 galgame,目前都是用户做选择题的方式来决定剧情的走向。如果用户可以跟游戏人物用自然语言交互,剧情也是根据用户的喜好定制出来的,将是一种全新的游戏体验。
那么什么是 OpenAI 暂时做不出来的东西?比如视频输入和视频生成,很可能 OpenAI 不会在短期内推出,或者即使推出也会成本较高。OpenAI 是在推动大模型的前沿,一定会用足够大的模型生成最高质量的视频,而不会想着生成廉价而劣质的视频。现在 RunwayML Gen2 的成本就比较高,7.5 分钟就要 90 美金。AnimateDiff 的成本比较低,但是效果还有待提升,最近社区做了很多改进。Live2D、3D 模型又需要比较高的建模成本,而且只能生成人物相关的模型,没法生成复杂的交互视频。这就是后来者可以努力的。
另外一种 OpenAI 暂时做不出来的东西是依托硬件的。比如 Rewind 的录音吊坠,Humane 类似电影《Her》里面放在上衣口袋里的 AI Pin,都是一些很有趣的硬件发明。此外,依托智能手机的 Siri 等也是 OpenAI 难以取代的入口。
最后,有数据壁垒的场景也是 OpenAI 很难直接取代的。例如,互联网公司在现有 App 中增加大模型推荐能力,就是有数据壁垒的,其他公司很难做。
Infra 很重要
Sam Altman 把微软 CEO Satya Nadella 请上来讲了一通,其中最重要的信息我认为就是 Infra 的重要性。Azure 是 OpenAI 训练和推理的基础设施,像 GPT-4 万卡训练集群就是 Azure 提供的。大多数公司目前尚不具备万卡集群高效训练的基础设施,单是万卡网络高速通信的能力和故障自动恢复的能力都不具备。
考虑到训练和推理的成本,Infra 将是大模型公司未来 2-3 年胜负手的关键因素之一。