Load/Store 和缓存一致性有没有必要?
(本文首发于 知乎)
CC(cache coherency,缓存一致性)可以分为两个场景:
- 主机内 CPU 和 device 之间的 CC
- 跨主机的 CC
主机内 CPU 和 device 之间的 CC
我认为主机内 CPU 和 device 之间的 CC 是非常必要的。2017 年我在微软实习的时候,用 FPGA 做了一块内存挂到 PCIe 的 bar 空间上,真能在这块 bar 空间上跑起来一个 Linux 系统,但是本来只要 3 秒的启动流程花了 30 分钟,比 host memory 慢了 600 倍。这就是因为 PCIe 不支持 CC,CPU 直接访问 device memory 只能是 uncacheable 的,每次访存都要通过 PCIe 去 FPGA 转一圈,效率低得不行。
因此目前 PCIe bar 空间只能用来让 CPU 给 device 下发 MMIO 命令,数据传输必须通过 device DMA 来进行。因此现在不管是 NVMe 盘还是 RDMA 网卡,都必须走 doorbell-WQE/command-DMA 这一套复杂的流程,如下图所示。
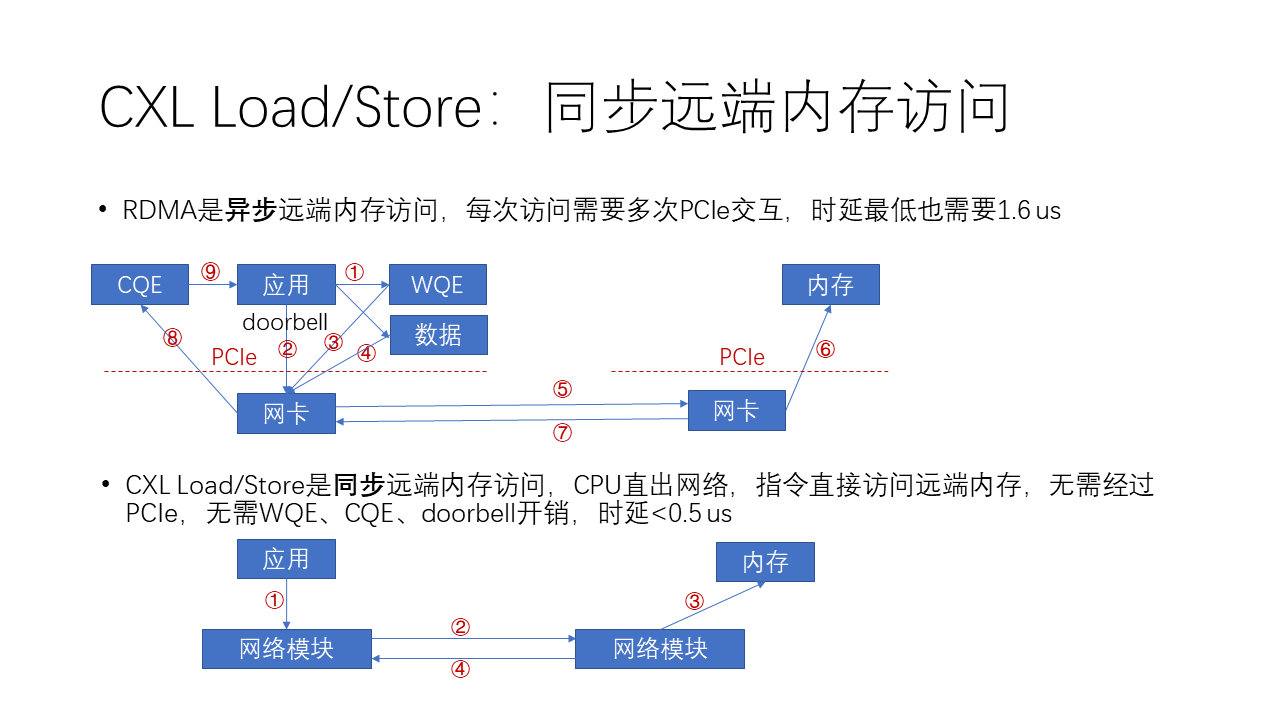 RDMA 和 Load/Store 的流程对比
RDMA 和 Load/Store 的流程对比
如上图所示,在 RDMA 中如果想发送一个数据,那么:
- 软件首先会生成一个 WQE(work queue element),就是工作队列里边的一个工作任务。
- 然后这个任务再下发一个 doorbell,就是按一个门铃到网卡告诉说我有事情要做了。
- 接着,网卡在收到这个门铃之后会从内存里面把这个工作任务取到网卡里面。
- 然后再根据工作任务当中的地址,访问内存中的数据,把它 DMA 到网卡。
- 再接下来,网卡会把这个数据封装成一个网络报文,从本地发送到远端。
- 然后,接收端的网卡在收到了这个数据之后,再把它写到远端的内存。
- 接着,接收端的网卡返回一个完成消息说我干完了。
- 发起端的网卡收到了这个完成消息之后,它就在本地内存中生成一个CQE。
- 最后,应用需要去 poll 这个CQE,也就是说它要获取这个完成队列里的完成事件才能够完成整个过程。
我们可以看到,整个过程非常复杂。相比 RDMA 这种比较复杂的异步的远端内存访问,CXL 和 NVLink 这种 Load/Store 就是一种更简单的同步内存访问方式。为什么它会更简单呢?
因为它的 Load/Store 是一个同步的内存访问指令,也就是说 CPU(对 CXL 而言)或者 GPU(对 NVLink 而言)有一个硬件模块能够直接访问网络单元。那么这个指令就可以直接去访问远程的内存,而不需要经过 PCIe,这样就不需要 WQE、CQE 还有 doorbell 的这些开销,整个的时延可以降低到 0.5 us 以下。整个过程实际上只需要 4 步:
- 应用发一个 Load/Store 指令;
- CPU 中的网络模块发起一个 Load 或 Store 网络报文,在网络上面获取或者传送数据;
- 对方的网络模块会做一个 DMA,把对应的数据从内存里面拿出来;
- 通过网络回馈给发起的网络模块,然后CPU的这条指令就宣告完成,可以继续进行后续的指令了。
注意这里的 Load/Store 并不一定需要跨主机的 CC,仅仅是要求主机内部的 CPU core 和 device 之间做到 CC。就像 RDMA Read/Write 一样,RDMA Read/Write 是远端内存和本地内存之间的数据搬移,Load/Store 是远端内存和寄存器之间的数据搬移。远端内存或者本地寄存器的数据修改了,并不需要同步到对端。
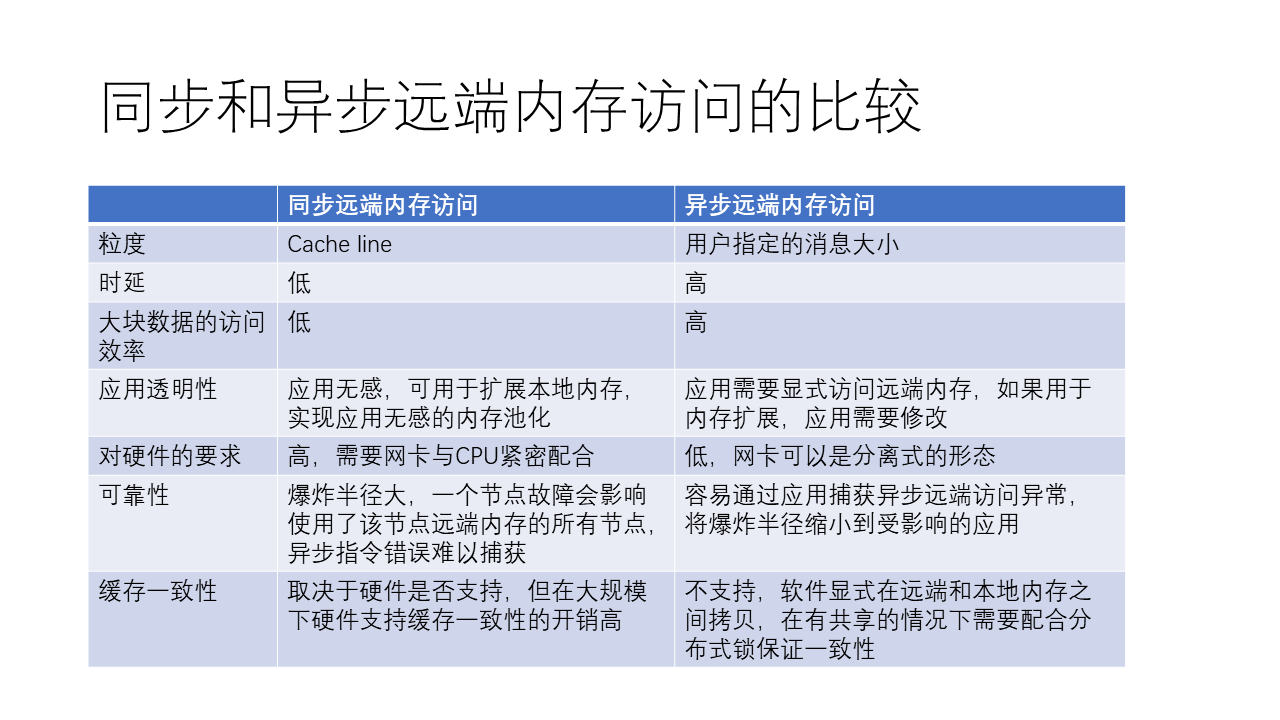 同步和异步远端内存访问的比较
同步和异步远端内存访问的比较
总的来说,同步和异步远程内存访问各有优缺点。同步远程内存访问,如 CXL 和 NVLink,使用简单的 Load 和 Store 操作,可以在不需太多复杂步骤的情况下实现远程内存访问。这种方式相较于异步远程内存访问,如 RDMA,更加简单,但也有一定的局限性。
同步远程内存访问的优势在于:
- 过程简单,交互流程简洁,使得访问延迟较低。
- 对应用程序来说是透明的,可以用来扩展本地内存,而不需要修改应用程序。
- 在访问较小数据量时,效率可能更高。
- 在硬件支持的情况下,可能支持缓存一致性。
同步远程内存访问的劣势包括:
- 对硬件要求较高,需要网卡与 CPU 紧密配合。
- 每次访问的数据量相对较小(通常是一个缓存行,如 64 字节),因此在访问大数据量时,效率可能不如异步远程内存访问。
- 同步远程内存访问的可靠性可能较差,因为一个节点故障可能会影响到使用了该节点所贡献的远端内存的所有节点。有一个所谓 “爆炸半径” 的概念,远端内存如果发生故障了,影响的不只是自己这个节点,这就会导致爆炸半径增大。
- 大规模下的缓存一致性开销很高。
异步远程内存访问的优势在于:
- 用户可以指定访问的数据量大小,从而在访问大数据量时,效率可能更高。
- 对硬件要求相对较低,网卡可以采用分离式形态,如 PCIe 接口的网卡。
- 可以通过应用捕获异常,从而将影响范围缩小到受影响的应用。
异步远程内存访问的劣势包括:
- 过程较复杂,涉及到与网卡的复杂交互,导致访问延迟相对较高。
- 对应用程序来说不是透明的,需要显式访问远程内存,因此如果用于扩展内存,需要修改应用程序。
- 不支持缓存一致性,需要靠软件在远端和本地内存之间进行拷贝,并在共享内存情况下配合分布式锁来保证一致性。
- 根据实际应用场景和需求,开发者可以选择适合的内存访问方式。对于需要访问较小数据量且对延迟要求较高的场景,同步远程内存访问可能更合适;而对于需要访问大数据量且对延迟要求不高的场景,异步远程内存访问可能更高效。
NVLink 比较有意思的是,大量数据传输也敢走 Load/Store,因为 GPU 的核多,而且 NVLink 的时延低。最近也有一些研究指出 GPU Load/Store 的效率比较低,占用了大量的 GPU 核,而且造成了 GPU 缓存的污染。 例如 MSRA 在 NSDI‘23 上的研究:ARK: GPU-driven Code Execution for Distributed Deep Learning
苹果的 Unified Memory 也是在单机内实现支持 CC 的共享内存的一个不错的设计,CPU 和 GPU 共享内存后,一方面解决了显存不够的问题,另一方面使得 CPU 和 GPU 的协同非常高效。
比如我前几天在 MacBook Pro 上跑了 LLaMA 2 的 4-bit 量化版本,笔记本就能跑 70B 的模型,还是非常 exciting 的。视频在此:Meta 发布开源可商用模型 Llama 2,实际体验效果如何? 这得多亏有 96 GB 的 Unified Memory(其实跑起来只占了 50 GB),如果是 CPU memory 和 GPU memory 隔离开来分别做 96 GB,这成本就高了。
有趣的是如果使用 llama.cpp,在有缓存的情况下,MacBook Pro 上加载 70B 的模型都用不了 1 秒(非首次加载),而 NVIDIA A100 服务器都需要 10 秒左右的时间通过 PCIe 加载模型。这就是因为 CPU 和 GPU 共享内存,减少了数据搬移。
跨主机的 CC
跨主机的 CC 是争议比较大的。一个原因是大规模分布式一致性难以实现,是学术界几十年的 open problem。另一个原因是应用场景很多人没想清楚。
比如内存池化,很多人在讲的故事是借用其他机器的空闲内存,提高集群内存使用率,这就不需要跨主机的 CC,只需要 Load/Store 和主机内的 CC。因为借来的内存也只有一台机器用,出借方不需要访问,其他机器也不需要访问。
终极版的内存池化就是很多台机器共享内存,支持跨主机的 CC。优点很多,简化编程,减少拷贝,提高内存利用率。但是理想很美好,现实中怎么存储数量巨大的 sharer list(共享者列表)?Cache invalidation 的开销太高怎么办? 学术界提出了很多 mitigations,包括:
- 把**缓存粒度(granularity)**从 cache line 扩大到 block,page 甚至 object,以降低存储共享者列表的开销,但是也增加了 false sharing 带来的 invalidation 开销;
- 把 sharer list 的数据结构从 bitmap 改成链表,或者采用分布式存储,把共享同一个 cache line 的机器组成一个 hierarchy;
- 控制共享者数量,比如 NVIDIA 之前就是用 page fault 来搞 CC,只允许单个共享者 exclusive access(但是 NVIDIA 毕竟还是对 CPU 和 OS 缺少控制,要是我做 page-fault-based CC,肯定把解决 page fault 的流程搞成全硬化的,通常情况下不让 CPU 和 OS 参与);学术界也有控制最多 3 个(for example)共享者的,多了就把原来的共享者踢出去;
另一条路是使用 lease 的概念取代共享者列表,到了过期时间缓存自动失效,写操作的同步延迟最大可能跟租期一样长。Lease 的方法有个 trade-off,如果租期太短,那么读操作需要反复获取更新的值,读效率变低;如果租期太长,写操作的同步延迟又太高。
其实我感觉更靠谱的一种方法是把 CC 跟业务相结合,因为业务最清楚什么时候数据该同步,业务一般也比较清楚数据有哪些共享者。比如在分布式系统里面,一般都是需要先获取对象的读写锁,然后访问数据,最后再释放锁。访问数据的过程中可能有读有写,但这个中间过程可能不一定需要实时同步到其他节点,事实上有很多场景是根本不想让中间结果为别人所知(分布式事务的原子性)。获取锁的时候把数据从源端同步到本地,释放锁的时候再把修改过的数据从本地同步到源端。既然业务里面都实现读写锁了,那肯定得在内存里面存储共享者列表吧?共享者列表没地方放的问题自然也解决了。这样,如果我做一个硬件加速的读写锁 + 对象同步语义,作为 RDMA 语义的扩展,是不是更实用?一个 RTT 不仅搞定了读写锁,又搞定了对象数据的同步,还不浪费数据所在主机的 CPU,岂不美哉?
如果感觉大多数业务里没有用锁,上面的读写锁不够实用,那也可以做一个乞丐版的跨主机 CC,只支持用户按需同步,不支持实时同步,这样在很多场景下也够用了,只是需要软件上搞定触发同步的时机,也就是靠软件解决 cache invalidation 问题,编程比较麻烦。
**简化编程有时候比追求那点性能更重要。编程简单了,很可能意味着架构更通用。**比如 NVIDIA 的 GPU 和以 TPU 为代表的一大堆 DSA 就是典型的例子,这些 DSA 在 ResNet 的时代一个比一个牛,同等工艺算力提升几倍,但是遇到 Transformer 有效算力基本上都不行了。更不用说 DSA 的生态问题了,算子开发是要成本和时间的,DSA 算子的开发成本一般比 CUDA 更高。如果 DSA 在 Transformer 时代靠谱的话,A100/H100 就不会像现在这样卖断货了。
跨主机的 CC 我觉得主要还是用在 Web service、大数据、存储之类的场景。目前我还没想到在 AI 和 HPC 领域能有什么应用,AI 和 HPC 一般都是 collective operations(集合通信),embedding 也是有逻辑上中心化的 parameter server 来存储,对多机共享内存数据的需求似乎不大。如果我说错了,欢迎指正。