编写高性能软件的几个技巧
随着计算机处理能力的提高和软件复杂程度的上升,性能往往并不是衡量软件的最重要标准。但有时我们确实需要把计算机的性能榨干。尤其是做研究的时候,为了让性能指标超过对手,不仅要优化算法(渐进复杂度),还要优化实现(复杂度中的常数)。本文试图总结一些规律,望与大家讨论:
不要使用开源软件
开源软件往往考虑的是一个通用问题,因此有很多几乎永远也用不到的配置参数和条件判断;开源软件对代码可读性、可维护性的要求往往高于对性能的要求,因此一般不使用所谓的“奇技淫巧”。
例如,Linux 的 DNS 服务器事实标准 bind9 单核只能达到约 50k 次查询每秒的速度。我没有看过 bind9 的源码,不知道瓶颈在哪里。但我在 NDIS filter driver(网络过滤驱动)里随手写的一个不支持泛域名、只支持 A 记录的权威 DNS 服务器,每个核每秒能支持 500k 次查询。
算法很简单,把 DNS 记录按照域名的 hash 值放进一张预先分配在非分页内存区(non-paged memory)的 hash 表里,采用线性探测法解决冲突,hash 表的占用率是 1/2;从每个 DNS 查询里提取出域名部分,查询 hash 表,直接返回对应的记录。
当 hash 不冲突的时候,每个 DNS 查询事实上只需要访问两次内存,一次找到域名在 hash 表中的索引,一次取出记录的实际内容。剩下的都是一些在 CPU 高速缓存里做字符串处理和内存拷贝的开销了。即使加上其他类型记录的支持,性能应该也不会明显下降。
相信我,大多数需求没有那么复杂,demo 更是如此。实现一个恰好满足需求的最小系统所花的时间,远远小于调优浩如烟海的开源软件代码所花的时间。
使用 C/C++
使用 C/C++,不要用解释型语言,不要用带垃圾回收的语言,JIT(中间码翻译成机器码)的也不行。谁也不希望自己辛辛苦苦设计的算法仅仅是用了 Java 就被人家用 C++ 写的烂算法比下去。
使用了 Google V8 引擎的 Node.js 号称是世界上最快的脚本语言。我曾经用 Node.js 写了一个解析 Whois 数据并把解析后的数据存入 mongodb 的程序,结果这个 whois 解析程序成了瓶颈,mongodb 的 CPU 占用倒只有 20%~30%。后来改用 C 语言和最传统的字符串处理(有点像程序语言的 parser),mongodb 成功成为了瓶颈。当然,也许是我 Node.js 的功力不够,写的正则表达式的效率太低,但至少这一次 C 语言解决了性能问题。
用数组,不要频繁动态分配内存
学 OI 的时候,为了编程迅速和减少出错,老师让我们使用静态数组,“指针”就是数组下标。上大学之后看到专业的程序里都是动态分配内存,就开始嘲笑自己当年用静态数组的“愚蠢”。如今却发现,静态数组还真是高性能的诀窍。它至少有两方面的优势:
- 不需要频繁动态分配内存。因为标准库里分配内存的算法比较复杂,开销比较大。如果不加注意,说不定分配内存所用的 CPU 时间比其他业务逻辑加起来还多呢。
- “指针”就是数组下标,只需要 4 个字节(数组一般不会超过 4G),而真正的指针在 64 位系统上需要 8 个字节。
在实际程序中,输入范围不像 OI 那样有上界,因此静态分配内存是不可能的。但我们可以在程序初始化或数据预处理时,根据输入数据的规模一次分配一大块内存,当成数组来用。所谓的“内存池”,本质上就是一个大数组,可以紧凑地存储大量相同类型的数据结构。
不要频繁动态分配内存的另一个推论是,在性能关键的地方不要使用 C++ 的 new 和 delete,因为它们需要在堆中动态分配和释放内存。可以用 array of struct(结构体数组)代替。
用 mmap I/O 访问文件
读取文件最原始的方式就是一次 fread 一个字节了。不久你就会发现,fread 成了整个程序的瓶颈。有经验的人会告诉你,要用文件缓冲区,一次读进来一块(如 4KB)。不过做字符串处理的时候如果块到了末尾字符串还没结束,就要再读入一块文件内容,还要在逻辑上把两个缓冲区拼接起来。边界条件如果处理不好,bug 就来了。
事实上,CPU 的分页内存机制和操作系统早已为我们准备好了解决方案—— mmap I/O。它可以把一个文件映射到一块逻辑上连续的内存区域,读写这块内存区域中偏移为 offset 的位置,就相当于访问这个文件的第 offset 字节。就好像整个文件已经被载入到一段连续内存一样。当读到尚未载入内存的内存位置时,会触发缺页中断,操作系统将磁盘上的内容读进内存,再让程序恢复执行,这一切对程序都是透明的。mmap I/O 还能减少数据在用户态和内核态之间的拷贝(fread 需要把读出的数据从内核态拷贝到用户态)。
设置 CPU affinity
用 pthread_create 创建线程后,可以用 pthread_setaffinity_np 设置 CPU 亲和性,即这个线程跑在哪个 CPU 上。如果我们有 8 个核,开启了 8 个计算线程,我们显然不希望 8 个线程挤在其中的一个核上。
更微妙的问题发生在开启了 Hyper Threading(超线程)的 CPU 上,这种 Intel 技术使得一个物理核可以当成两个逻辑核使用,它们共享同一套计算部件,两个核上的指令序列插空交替执行(指令序列 A 在等待内存时,指令序列 B 就可以执行)。如果我们有 8 个物理核,16 个逻辑核,开启 8 个计算线程分别安排在 CPU 0~7,有可能它们运行在 4 个物理核上,而另外 4 个物理核还是空闲的。可以查看 /proc/cpuinfo 来获取逻辑核与物理核的对应关系,进而把计算线程尽量分布在不同的物理核上。
使用原子指令而不是锁
遇到多线程的竞争,我们首先想到的就是锁。但锁的开销往往比较大,如果使用互斥锁(mutex)且需要等待,就需要挂起线程,进行上下文切换。事实上很多计数器一类的应用都可以用 CPU 的原子增减(increment、decrement)、交换(exchange)、位运算指令来实现。在 gcc 中这些指令以 __sync 开头(传送门),在 Win32 API 中这些指令以 Interlocked 开头(传送门)。
避免 false sharing
我们都知道 CPU 非对齐访问要访问两次总线,效率很低,因此编译器都知道把整数按照4字节对齐。但在多核多线程处理中,还有一种以 64 字节为单位的对齐。在我用的 Intel 处理器中 CPU 高速缓存是以 64 字节的行(cache line)为单位的,只要其中的一个字节缓存不命中,就要从内存中读取整行;只要其中的一个字节被写入,就要通知其他处理器把相同地址的这一行清出高速缓存(缓存失效)。
如果我们有一个 16 线程的计算密集程序,每个线程 i = 0..15 用到一个 4 字节全局变量 ThreadGlobal[i],则每个线程写入全局变量时,其他处理器的全局变量缓存都要失效。本来各线程的全局变量互相不影响,可以分别缓存,但 CPU 缓存行的设计破坏了缓存,这就是 false sharing。
避免 false sharing 的方法很简单:让每个线程私有的全局变量按 64 字节(或处理器架构上的缓存行宽度)对齐。遗憾的是,编译器并不能自动做到这一点,需要把线程全局变量封装在结构体中,自己添加 padding。例如
1 | struct ThreadGlobal { |
网卡中断不是免费午餐
在 1Gbps 网卡上,即使是 64 字节的小包,收满线速(line-rate)也毫无压力。但在更高速(如 10Gbps)的网络上,小包线速接收则是基本不可能的。当遇到瓶颈时,要观察系统的 kernel time,如果内核时间占了大部分,则不是用户态进程(如 socket 程序)的问题,而是中断处理不过来了。
网卡和网卡小端口驱动按照数据包头的 hash 值将中断分配到几个 CPU 之一。如果这些 CPU 处理不过来中断(有可能不是在中断的顶半部处理不过来,而是在底半部或称 DPC 队列里处理不过来),则可能导致系统崩溃。
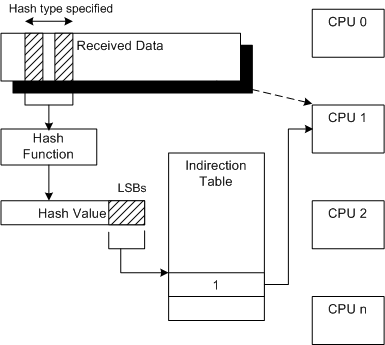
一些经验:
- 使用 Receive Side Scaling (RSS) 让中断分布在更多的 CPU 上。
- 发包测试时要让源IP、目的IP、源端口、目的端口中的至少一个参数随机(random)或轮转(round robin),否则发来的包总是 hash 到一个 CPU 上处理。
- 关闭防火墙,如果规则数目众多,数据包通过防火墙需要不少计算开销。
- 设置计算线程的亲和性时,避开忙着处理网卡中断的 CPU。