一个斜杠引发的血案
注:不了解 mirrors 的朋友,请先看《科大开源软件镜像是怎样炼成的》。
祸起 iSCSI
故事要从2013年6月26日讲起。mirrors 有一个网线直连的磁盘阵列,使用 iscsi 协议,上面有一个XFS文件系统。6月26日下午14时许,stephen 在邮件列表里报告 mirrors 挂了。根据 syslog,6月26日13:58,iscsi 连接超时,导致 sdg 访问失败,大量I/O操作被卡住,导致 nginx 被卡住,mirrors HTTP 无法连接。几分钟后,I/O超时,nginx 恢复正常,但磁盘阵列上的源无法使用了。
这是第二次了。就在6月1日,mirrors 就出现了同样的 iscsi 连接超时 (内部页面),导致了同样的后果。因为当时没有经验,服务中断了4小时。当时,我和 tux 都把问题矛头指向磁盘阵列上的 XFS 文件系统,因此试图使用 xfs_repair 修复,没有任何结果,最后 umount,mount 就好了。事实上,问题出在 iscsi 上(具体原因未知),跟 XFS 可能没什么关系。这次故障修复用时2小时。
好景不长。6月27日 10:30,mirrors 再次出现同样的问题,服务又挂了。我故技重施,半小时就解决了问题。这么长时间是因为总是找不到占用着挂载点的进程,原来是 mirror-lab LXC 虚拟机的根分区在磁盘阵列上,lxc-stop 之后就能 umount 了。
“血案”现场
频繁的故障促使我们把 LXC 的根分区移到磁盘阵列外面。斜杠引发的血案由此上演。
4月27日16时许,mirrors 无法 SSH 了,但 HTTP 服务正常,rsync、FTP 服务挂了。原因是 /lib 消失了,/lib/ld-linux.so 也消失了,所有需要动态链接的程序,包括使用 glibc 的程序都无法运行。HTTP 请求不需要开新进程,因此能正常工作;rsync、FTP 每个连接都要开新进程,于是都不能用了。
根据 /var/auth.log 和我的回忆,故障的过程是这样的:
- 由于 mirror-lab 在 sdg 里,sdg 不稳定,所以就想移出来。
- cp -R /path/to/mirror-lab-root/ /path/to/new-mirror-lab-root/
- 启动LXC,发现目录权限和 owner 不对,所以就想用 rsync 修正。
- 在 pwd=/ 里 rsync -aP /path/to/mirror-lab-root/ . 是在 screen 里执行的,然后就logout 了。这个操作导致根目录被覆盖掉。
- 过了一会儿在另一个打开的 session 里发现没有同步过来,screen -r,发现那个 rsync 还没有结束,心想怎么这么慢呢,就 Ctrl+C 掉,cd 到家目录,rsync -aP /path/to/mirror-lab-root/ .
- 马上发现同步目标写错了,在 pwd=/home/boj 里 rm 一长串,其中包括 lib/
- 发现 ls 不了了,就 logout,发现再也不能 login 了。
为什么当时会连犯覆盖根目录和删掉 lib 两个重大错误呢?我觉得是因为当时正忙着写别的程序,心不在焉,敲命令的时候没有过脑子。前两步是在我比较空闲的时候做的,但后面的 rsync 就是在手忙脚乱中做的。
从上面的操作过程里可以吸取几个教训:
- 使用相对路径时,一定要注意 pwd(我几乎不用 pwd=/,知道这很危险,但这确实发生了)
- 第5步,发现没有同步完成时,应该检查一下上次输入的命令,而不是直接重写一遍。
- 不要用 rm xxx/,要用 rm xxx,以免 follow symlink。
- 不能 ls 时不能急于 logout,而要用 bash 内置命令检查一下是什么问题,如果当时没有 logout 说不定还有可能修复。
亡羊补牢
当时只有 stephen 有 login session,只有一些 bash 内置命令可用。由于 LXC 并没有被破坏,LXC 仍然能正常登录和操作。只不过我们找不到 LXC 的漏洞以跳到主机里。通过 bind mount 的 /srv/array 作为跳板,外界静态链接的程序可以被送进 mirrors 并运行。
tux 做了一个静态链接的 busybox,但 stephen 说不能用。后来 tux 又从其他 Debian squeeze stable x86-64 的机器上复制了 /lib 目录到 mirrors,stephen 把它们 copy 过去了,此时 SSH 连接立即断开了(原因未知)。rsync 和 FTP 服务恢复正常了,可见 copy 过去的 /lib 是有效的。但 SSH 还是进不去(原因未知)。看来是不得不去机房了。
28日 00:49,我们发布了 mirrors 维护通告。由于当时临近期末考试,我和 tux 否决了复杂的、可能需要一天的虚拟化方案,计划速战速决(当时我还不知道做了 rsync 覆盖根目录的傻事,只是以为 /lib 挂了):
- 重启机器,进U盘 live 系统
- 用 dpkg 检查缺失文件的情况,并复制缺失的文件进去
- 重启机器,看是否正常
考虑到系统文件被严重破坏的 mirrors 可能需要重装,stephen 建议我们采用切换 DNS 到备份站点的应急方案。我写了个脚本找出国内几大开源软件镜像的源列表,人工处理名字不同的源之后,随机把现有的源分配给这些镜像站。在备份站点的首页上挂上了维护通告。凌晨3点,backup.mirrors.ustc.edu.cn 在 lug.ustc.edu.cn 服务器上搭建和测试完成。还修改了 mirrors 系列域名 DNS 记录的 TTL 为 120 秒,以便 DNS 修改快速生效。
去机房
6月28日10时,我们来到网络中心机房,开始修复 mirrors。首先,我们修改了 DNS 记录,让 mirrors 系列域名 CNAME 到 backup.mirrors.ustc.edu.cn。一两分钟后,大部分源通过 HTTP 重定向到国内其他开源软件镜像,在 lug.ustc.edu.cn 服务器上看到了飞速刷屏的 access log。
熟悉 mirrors 的硬件环境、确认问题后,tux 用前一晚制作的 Debian 启动U盘启动 mirrors。很快就发现,问题不是那么简单,因为 /home 和 /etc/passwd 都被覆盖了。既然这样,只好重装系统了。
我和 tux 在前一天晚上已经讨论了详细的 LXC 虚拟化方案,但不打算立即实施。但到了机房,tux 希望把虚拟化做出来,我没有提出异议。他又希望在下面搞一层 Xen,以便主机出错时能在不进机房的情况下解决,我也没有提出异议。由此看来,我是负有重大 “领导责任” 的。
12时许,我见没有要结束的意思,就把 pudh 和 bible 叫过来观战。zguangyu 已经回家了,因此没来。我们一起折腾到19点,确保 mirrors-main 不会挂了(这只是一厢情愿),才 “恋恋不舍” 地离开了机房。

“花瓶” 架构
当时设计的虚拟化架构听起来很美妙,但实际做起来困难重重。
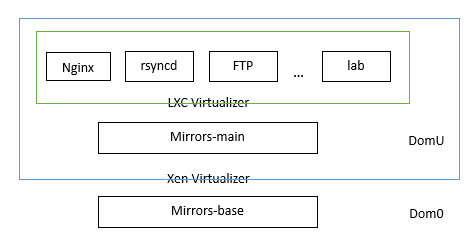
tux 的设 (wa) 计 (keng) 能力果然很强,搞了两层虚拟化,如上图所示。底层虚拟化是 Xen,Dom0 是 mirrors-base,找 jameszhang 要了一个专用IP(202.38.95.106),只能从几个受限 IP ssh,仅用于恢复目的,平时严禁使用。Dom0 挂载了几块本地磁盘,除用于根分区的那一块以外,都映射到 Xen 的 domU 里。domU 只有一个,是 mirrors-main,绑定了 mirrors 三条线路的四个公网IP,通过 eth1 连接 iscsi,挂载磁盘阵列。
第二层虚拟化是在 mirrors-main 上开了几个 LXC container,分别用于 nginx,ftpd,rsyncd,rsync 和 lftp 同步,静态页面生成,mirror-lab,ftp-push(可写ftp)。
听起来挺美妙的,但是……装 Xen 的时候,为了让 mirrors-base 能够访问 mirrors-main 的文件系统(以便修复),根分区不是用 Xen 官方工具建立的,而是手工在 LVM 卷上 debootstrap 出来的。DomU 的根文件系统是 NFS 挂载在 Dom0 上的。配置文件里有一些 undocumented 的东西,tux 就开始翻 xen-tools 的 python 源码,终于 NFS 启动成功了……还有几项配置,是参考了之前在少院搞的 Xen 配置文件。
LXC 也不是个好伺候的主,直接建立的 LXC 是启动不起来的。需要修改配置文件 bind mount,建立 tty 设备文件等。我把 mirrors-main 的配置脚本用 git 库管理起来了:http://gitlab.lug.ustc.edu.cn/mirrors/mirrors-main/tree/master (需注册登录)这算是那次不完整的 mirrors 重建留下的一点遗产吧。如果要使用这些脚本,请一定区分清楚是在主机里运行的,还是在 LXC 虚拟机里运行的。
折腾 LXC 网络
折腾完 Xen,LXC 的网络是个更大的麻烦。不想在 mirrors-main 上放任何有用的服务,就需要把 nginx,ftp 和 rsync 分端口映射到 LXC 里。
总共试验了四种方案:
- 让 LXC 和主机共享相同的 IP,用 ip rule 和 fwmark 转发。
- 用 DNAT 端口映射。
- 用 IPVS(Linux Virtual Server)路由。
- 不隔离网络命名空间。
共享 IP?
首先是想让 LXC 和主机共享相同的 IP,就搞了 ip rule 和 fwmark。这并不是那么简单,因为 mirrors-main 的根分区是 NFS 挂载,如果把 NFS 搞断网了,可不是什么好玩的事……因此,我们不得不调整了 local 规则的顺序(以下规则做了简化)。
1 | // rc.local in mirrors-main |
折腾这些规则可不是一帆风顺的。6月29日,mirrors 重建的第二天,我就把 mirrors-main 的 NFS 搞挂了,我就到 mirrors-base 里修。忘了由于什么原因,mirrors-base 的 SSH 断掉了。(不是由于经典的 sudo networking restart,我们全程都是在 byobu 里操作的。)当时是周六,网络中心机房的值班老师不在。我跟 jameszhang 打电话,他主动提出从科大花园跑到网络中心一趟,我们实在是过意不去。
这就 OK 了吗?LXC 能收到入站数据包,但回复的出站数据包就不见了。在 PREROUTING 链还能匹配上,但在 INPUT,POSTROUTING 和 FORWARD 上都找不到回复包,我们猜测是内核的路由逻辑发现 FORWARD 包的源IP和目标网卡的某个IP相同就丢包了。用其他机器做了个实验,发现 Linux 确实不会转发源IP与目标网卡IP相同的包。当时想用 ebtables 搞,但我们研究它的结构后没有想出方案来。
最后,搞定 iptables 转发本地地址被内核“吃掉”的问题,只需要一行:
net.ipv4.conf.<interface>.
我当时是翻了内核源码,定位到“吃掉”非法包的地方。相关 commit:
http://git.kernel.org/cgit/
但是,IPv6 没有对应的选项,我们也没搞出来。
DNAT?
DNAT 端口映射倒是简单,但无法处理 ipv6,内核的 ipv6 NAT 是在 3.7 才有的,我们不想用太新的内核。
IPVS?
接下来试验的是 ipvs (Linux Virtual Server) NAT 模式,宣称支持 ipv6,而且操作起来确实方便。不过 ipv6 确实无法工作,我也不知道是什么原因。
我们又试了把所有虚拟机和主机的网卡桥接起来,使用 ipvs 的直接路由方式,估计是什么地方配置有误,仍然不能按照预想的工作。
不隔离网络命名空间!
在折腾两天后,tux 做出了一个艰难的决定:不隔离网络命名空间。
不过,这种配置也带来了更大的风险:LXC 内执行 init 0 就会运行关机脚本,停止网络设备,然后 mirrors-main 的网络就会停止运行!也就是说,只能运行 lxc-stop 来关闭虚拟机,在虚拟机内 shutdown 是很危险的。
性能问题
磁盘
6月30日8时许,HTTP 访问初步恢复(没有 IPv6),于是把 DNS 切回来了。
DNS 刚刚切回来20分钟,就发现响应很慢,CPU 几乎是 100% wait,于是9时许又切回 backup.mirrors 了。回去睡觉。
当天搞明白了原因,是 Xen 的磁盘虚拟化层导致的。当初是在 Xen Dom0 上挂载 LVM,再把 LVM 分区映射到 DomU(mirrors-main)的。tux 改成了把物理硬盘(/dev/sdx)直接映射进 DomU,再在 DomU 上挂载 LVM,问题解决。
网络
7月2日6时,mirrors HTTP 服务恢复,首页挂上公告,把 DNS 切换回来,向 科大 LUG 和清华 TUNA 邮件列表发布了恢复公告。
观察半小时没有问题后,我就回去睡觉了。事实上,因为当时还是清晨,访问量很小,I/O 性能问题还没露出其狰狞的面目。一整天,我们都没有去看 mirrors,也没有恢复 collectd 监控服务,因此我们对服务器的运行状态一无所知。
19时许,anthon 社区报告了 mirrors 访问缓慢的问题。我们这才发现首页几乎都打不开,这一整天 mirrors 几乎是不可用的状态。
20时许,查明了 mirrors 访问缓慢的原因。iscsi 是在 Xen 的 domU,不知道 Xen 的网络虚拟化层捣了什么鬼,总之 iscsi 挂载 XFS 的磁盘阵列只有几百K,而 I/O util 已经是 100% 了。Nginx 在 I/O 很慢时会被卡住,因此本地磁盘上的 HTTP 请求速度也受到牵连。我把磁盘阵列 umount 了,本地磁盘的访问马上正常了。
晚上24时许,tux 解决了这个性能问题。把 iscsi 在 Xen 的 dom0 挂载,再直接映射到 domU 里,就好了。由此推断是 Xen 的网络虚拟化层导致的。
故障影响
6月28日10时到7月2日6时的92小时里,来自 12.8 万个IP的 1060 万次 HTTP 请求被重定向到其他源,来自 1.1 万个IP的 161 万次 HTTP 请求因为没有设置重定向而无法正常完成,也就是说 94.5% 的 HTTP 请求被重定向到其他源。而用户是否能正常使用,还取决于被重定向到的源的可用性。例如,6月28日中午有两个小时左右,由于 bjtu 源恰好也挂掉了,导致 40% 的用户无法使用 debian 源(当时做的是 2:4:4 在 tuna、bjtu、sjtu 间负载均衡)。
7月2日上午9时至晚20时,由于前面提到的性能问题,mirrors 基本处于完全瘫痪的状态,打开首页都要很久,校内下载速度只有十几K。相比前几天重定向到其他源,这才是本次故障事件最严重的影响。
我们对这次影响数以十万计服务器和 PC 用户的大规模故障深表歉意。
总结
这次 mirrors 大规模故障,有两个原因:一是我 “一个斜杠” 的误操作,二是修复过程中的折腾。
误删 /lib
直接把 Zhang Cheng 的评论 摘过来了:
紧急的事情总是有,比如我在公司就碰到过一些紧急情况,由于受到攻击或者程序bug或者其他原因,导致一些关键服务器宕机。这时候,经验少的人很容易慌张,不知道该怎么办(因为只知道挂了,但不知道问题出在哪里,定位问题很困难),而我碰到这样的情况,会刻意的告诉自己,冷静,仔细的思考,不要轻易的下结论。慌张对解决问题起不到任何作用,冷静的思考才是正道。比如有一次夜里我们的一台db服务器宕机了,由于NFS的原因,连带另外几台机器的nginx都响应很慢。但是大家都没有先验经验,不知道nfs会导致nginx hang住,所以也根本想不到nfs有故障这回事。大家只是知道nginx响应很慢,但是看系统的各项指标(cpu、内存、带宽、io等)都很正常,所以有人提出重启机器。我当时拒绝了重启,因为没有找到问题的根源,甚至连线索都没有,盲目的重启,可能无法解决问题,甚至会破坏现场,使得这个问题再也无法找到。后来无意中通过/proc/$nginx-pid/stack中看到了nfs的影子,以此为线索最终定位到了nfs的问题。
大家维护mirrors都难免会碰到各种紧急的事情。这几年维护服务器的经验,使得我的性格越来越“慢”,越来越“果断”,在各种紧急情况(不一定是操作服务器)下能够不慌张,能够沉着,能够果断的做出决定。这也是我最大收获之一。
维护服务器的经验,同样使得我养成了许多条件反射。例如我在执行任何可能有伤害的命令前,都会在敲回车前停顿1秒。还有许多命令在执行前我都会给自己留个backup的退路。比如我见过一个人敲crontab命令时敲错了,敲成了crontab -<某单词>,某单词中含有字母’r’,导致crontab被清空,所以后来我每次执行crontab命令前,都会下意识的先执行一次crontab -l,这样即使后面自己出错了,还有机会找出前面的内容以恢复;同时我在线上部署crontab任务时,也尽量避免直接用crontab命令,而是写文件放到/etc/cron.d/中,以杜绝这种错误。
===== 引文结束 =====
修复过程中的折腾
这暴露了几个严重问题:
没有把用户体验放在第一位,在生产服务器上折腾不熟悉的技术。以后遇到服务器故障,在不破坏现场以便事后分析的前提下,要把尽快恢复服务放在首位。
没有培养新人,人员上容易发生“单点故障”。故障期间恰好是期末考试周,我和 tux 都很忙。LUG 其他人早先没碰过 mirrors,也没办法插手。
系统配置文件没有完整备份,只是把与服务有关的配置文件用 git 管理起来了,导致 SSH key 丢失。
恢复服务之后没有对运行状态进行持续监控。应当尽快恢复 collectd、ganglia 之类的监控服务。
高负载服务只有最基本的报警,运维人员无法及早得知硬盘满、内存短缺、I/O util 过高等 “安全隐患”。可以尝试用 monit 或 nagios 做更细粒度的报警。
此外,关于 mirrors 的日常运维,也已经暴露了一些问题。虽然与此次故障无关,但与之前的其他故障有关,也是值得重视的。源的同步状态只有粗糙的监控。应该加上长期统计以供调整同步策略参考。
syslog 一定要检查,比如 nf_conntrack table full,如果不是 iscsi 故障,运维人员都不知道有这回事。
虚拟化的迷思
虚拟化可以让运维变得更简单,也可以让运维变得更复杂。
如果 HTTP、rsync、FTP 等基础服务在主机上,同步脚本之类的在 LXC 虚拟机上,就能起到隔离的效果,提高稳定性,也便于分不同人维护。
然而,像这次 mirrors 重建这样,搞两层虚拟化,而且试图把 HTTP、rsync、FTP 这些 “大象” 塞进 LXC 的 “冰箱” 里,不仅需要用大量的胶水在不同的层次间黏合,还容易带来性能问题。更严重的是,当出现问题的时候,我们要花更长的时间排查问题出在哪个层次;出问题的层次越低,修复的复杂度越高。
兴也勃焉,亡也忽焉
我想,这个成语最能够形容我上学期对 mirrors 做的事了。
- 2012年11月24日,在 Linux User Party 上,信誓旦旦地宣布要搞 mirrors lab,让更多人参与 mirrors 维护。不过,在来自 tux 的阻力下,这个计划一直搁置。
- 2013年3月15日,tux 在内部邮件中提出使用 os-level 虚拟化技术的想法。
- 3月29日,沙盒第一版做好了,没有使用 LXC,而是 tux 自编的命名空间隔离脚本。lab.mirrors.ustc.edu.cn 在 nginx 里指向 /srv/array/exports,也就是提供了 HTTP 访问。
- 4月5日,利用一个经典 chroot 漏洞,我获得了 mirrors 主站的 root 权限。也许这是 LUG 成员第一次通过非正常途径获取权限,也希望这是最后一次。
- 4月10日,我再次催促 tux 在 mirrors 上部署安全的 container。
- 4月12日,container 里同步完成 kernel.org, chakra, apache, php.net 几个镜像,设置 crontab 6小时同步一次。正在同步的镜像还有 pypi, rubygems, openwrt, trisquel, dev.mysql.com。
- 4月12日,tux 把同步完成的4个镜像放入主站首页。
- 4月18日,tux 使用 LXC 建立好了 mirror-lab,算是第二版沙盒吧。
- 4月27日,LUG 换届大会召开,tux 宣布了 mirror-lab 成立,但并没有开账号。
- 4月28日,mirrors-lab 的一大波新同步的镜像上线。
- 5月1日,php.net 镜像转移到 lug 服务器上,申请官方源被拒。
- 5月9日,一批比较稳定的源被放上 mirrors 主页。我不太确定,但这可能是我第一次动用 mirrors 主站上的账号。
- 5月10日,stephen 拿出了 mirrors 曾经的一版 index,放在 testindex.mirrors.ustc.edu.cn。
- 5月10日,把 mirror-lab 上的同步脚本用 git 管理。
- 5月13日,hackage 源上线。
- 5月15日,zguangyu 提出在 mirrors 上同步 PPA,tux 给他开了账号。这是 mirror-lab 上除了 tux 和我以外的第三个人。
- 5月19日,向 sourceforge 提出 mirror 申请,不过在一次回复之后就再也没有回信了。
- 5月20~24日,向多个发行版官方提出官方源申请。
- 5月25日,根据 stephen 的建议,mirror-lab 上我的同步脚本升级。
- 5月31日,tux 修复了早先一直 502 的 FreeBSD 源。
- 5月31日,mirrors 某块本地硬盘满了。
- 6月1日,mirrors 第一次磁盘阵列 iscsi 故障。
- 6月3日,PyPI 同步改用 bandersnatch,变得稳定了。
- 6月4日,PyPI 源(pypi.mirrors.ustc.edu.cn)开始试用。
- 6月4日,nginx 日志文件格式升级,增加两个字段。
- 6月9日,mirror-lab 修改默认出口为移动出口。
- 6月10~15日(具体时间记不清了),mirror-lab 开始悄然从 mirrorservice.org 同步 sourceforge 源。
- 6月12日,给 pudh 开 mirror-lab 账号。
- 6月14日,发布了 meego 源。
- 6月15日,去掉了 meego 源,添加 tizen 源。(多亏了移动出口,一天 500G 的源就同步完了)
- 6月16日,把 mirrors 主站的同步脚本用 git 管理,这是我第一次看到 mirrors 原来的同步脚本。
- 6月17日,给 anthon 开源社区提供可写 FTP。
- 6月20日,对 mirrors 主站各镜像的同步状态逐一排查,尽量做到全绿。
- 6月20日,把 mirrors 的 nginx、rsyncd、vsftpd、logrotate、rc.local 等系统配置文件用 git 管理。
- 6月20日,mirrors 主站的同步脚本改为默认移动出口。
- 6月20日,stephen 发布了 mirrors 的磁盘负载分析。
- 6月21日,stephen 在内部邮件中提出了系统维护的一些规范。这些规范在重建 mirrors 时被采用。
- 6月24日,我开始写 mirrors 新版首页。
- 6月26日,mirrors 第二次磁盘阵列 iscsi 故障。
- 6月27日,mirrors 第三次磁盘阵列 iscsi 故障。
- 6月27日,我不慎把 mirrors 搞挂了。
- 6月28日至7月2日,mirrors 关站维护,HTTP 被重定向到其他源。
- 7月2日,在未解决负载问题的情况下满负荷运行,导致一天几乎无法访问,事实上这才是最长的故障时段。
- 7月4日,搞清楚了故障原因,总结教训。
- 7月5日,tux 把 LXC 的一些文档整理到了 LUG wiki 内部页面。
- 7月5日、6日,我和 tux 相继离开学校,mirrors 重建工作陷入停滞。
前几天,mirrors 又发生了一次硬盘故障。在 mirrors 之前的维护人员都不在场的情况下,新一届 LUG 技术团队在短短两天内重建了 mirrors 的各项基本服务,并部署了合理的 LXC 虚拟化架构。尽管故障不是什么好事,但最近这次重建是值得庆贺的。重建效果总体上令人满意,比我们两个月前那次务实多了。
在今后的一段日子里,希望 mirrors 维护团队:
- 吸取故障教训,完善备份和监控;
- 尽快把 SourceForge 源联系好;
- 恢复 mirrors 原有的 SSH 账号和家目录;
- 逐步为已有源的同步状态和访问热度添加监控。
祝愿 mirrors 早日走出故障的阴影,重振昔日雄风,继续领跑大陆高校开源软件镜像。作为 LUG 访问量最大的网络服务,相信 mirrors 能让她的每位维护者领略到别样的风采。