从IP网络到内容网络
IP 足够了吗?
从初中的计算机课开始,我们就在学习计算机网络所谓的 “OSI七层模型”,记得当年死记硬背了一大堆概念。那些烂课本毁了多少计算机天才,其实这个模型并不难理解:(学过计算机网络的请自行跳过)
- 物理层:就是信号传输的媒介,光纤、双绞线(我们常用的网线)、空气(wifi)……每种介质都需要自己的编码和调制方式,才能把数据变成电磁波送出去。
- 数据链路层:拿开会打个比方。说话可能不小心说错或者听错,需要有纠错、让对方重说的机制(校验和、重传);几个人都想发言,需要有一种方式进行仲裁,谁先说谁后说(信道分配、载波监听);一个人发言前后需要示意,以便让别人知道他说完了(成帧)。
- 网络层:这是计算机网络初期争议最大的地方。电信行业的传统巨头认为,应该像打电话一样在两端点间的路径上预留出一部分带宽,建立起通信双方的 “虚电路”。而当时正处于冷战时期,美国国防部要求建立起的网络在中间几条线路遭到毁灭性打击时,通信仍然不能中断。于是,最终采用了 “分组交换” 方案,把数据分成若干小块分别封装和投递。就像寄信一样,要投递到远方的机器,就要在信封上写明地址,而且地址要使得邮递员看到它就知道该走哪条路送给下级邮局(比如用身份证号作为地址就是个很糟的主意)。IP 协议是网络层协议的事实标准,大家应该都知道 IP 地址。
- 传输层:计算机网络早期最重要的应用就是在两台计算机间建立“连接”:远程登录、远程打印、远程访问文件……传输层就是在网络层数据包的基础上,抽象出连接的概念。这里的“连接”跟“虚电路”的主要区别是“虚电路”要预留一定的带宽,而“连接”是尽力而为投递的,不对带宽作任何保证。由于互联网上的流量多是突发(burst)的,分组交换比虚电路提高了资源利用率。事实上,历史往往是轮回的,如今在数据中心里,由于流量可预测且可控,又正在回到中心控制的预留带宽方案。
- 应用层:这就不用多说了,Web 基于的 HTTP、FTP、BitTorrent 都是应用层协议。
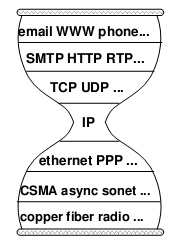
这个模型稳定地运行了几十年,而且由于其层次清晰、可扩展性强,还会继续稳定运行下去。然而,进入21世纪以来,计算机网络的应用场景已经在悄悄改变。**人们使用网络的主要目的是获取和发布信息,而不是在两台机器间建立连接。**如果网络一直局限于共享设备、文件、远程登录之类的,互联网绝不会成为今天这么大的产业,因此难怪 Bill Gates 当年不重视互联网。
问题
端对端、面向连接的互联网架构,在今天的互联网应用场景面前,遇到了三个基础性障碍:
低效的一对多传输
比如有一亿人在同时看世界杯直播,得用什么样的服务器和带宽资源?以最低限度的 100kbps 码率计算,共需要 10Tbps 带宽。要知道中国国际出口的总带宽不过 1Tbps 量级。因此,我们看的世界杯直播其实是国内视频服务提供商“转播”过来的;这些视频服务提供商还在各省各运营商安放了 CDN 节点,以便就近访问;这还不够,因此可能还需要 P2P 加速(下面会解释这些技术)。这每个中间环节,尤其是 P2P,都会显著增加视频的延迟,因此在电脑前欢呼的时间,可能比电视机前的观众晚了一分钟之久。
这是为什么?比如我和隔壁的宅男分别在看世界杯,服务器也要分别发两份一模一样的视频数据给我们俩。**网络交换设备只是在忙碌地投递数据包,并不关心数据包的内容。**一个自然的想法是,为什么不能只发一份,让网络交换设备去 “多播”(multicast)?懂计算机网络的人一定会跳出来,没有这样的协议云云。这就是工程(engineering)和研究(research)的区别,工程强调的是用现有的硬件和软件完成任务,就像戴着镣铐跳舞;研究当然也要受到自然规律的束缚,但可以天马行空,设计更优雅、和谐的架构。
不仅仅是视频,看新闻、下载电影和软件,都是典型的一对多传输。这个问题是如此巨大,以至于工业界主要采用了三种 workaround 来解决这个问题:
- 内容分发网络(Content Delivery Network, CDN)。在各运营商安放服务器,内容提供商事先把需要分发的内容放上去,在用户访问源服务器时跳转到网络上较近的 CDN 节点,用户从 CDN 节点就近下载内容。
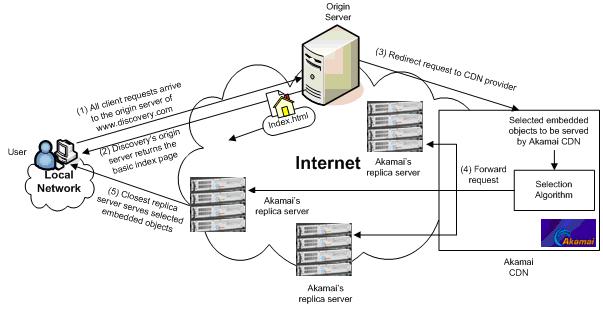 CDN_3
CDN_3 - P2P(Peer to Peer)。BitTorrent 大家都用过吧,其原理是找到其他拥有同一个文件的用户,从这些用户那里同时下载。现在很多下载软件、软件安装助手和视频客户端,如迅雷、360 软件管家、优酷,都综合使用了 CDN 和 P2P 两种技术。
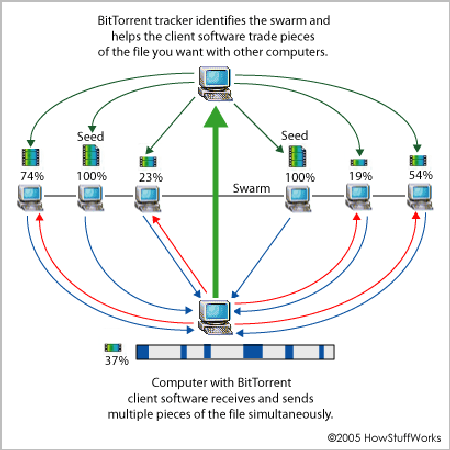 bittorrent
bittorrent - 小区缓存。运营商在“小区”里部署一个设备,监控属于文件下载类型的 HTTP 流量,把数据缓存下来。当小区里再有人下载同样的 URL 时,就会从缓存里取出数据发给用户,这样看起来下载快很多了。一些号称具有上网加速功能的路由器和浏览器,也是采用类似的方法进行缓存,或者干脆更激进一些,预测用户的行为,到服务器上把文件预取下来。在接触网络研究之前,我对这种行为是很反感的,这像是网络劫持,文件更新了,用户下到的可能还是旧文件。
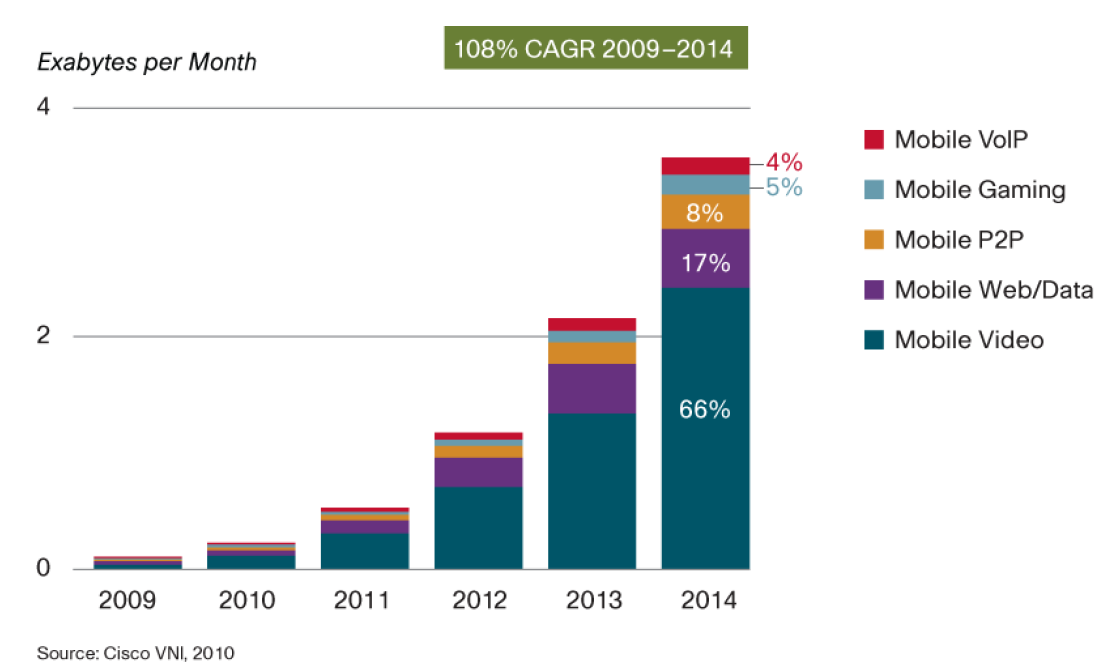
低效的一对多传输是催生以内容为中心的网络(本文简称内容网络,Content Centric Networking,或称 Named Data Networking)的主要动力。由下图可见,视频正在占据移动互联网的大部分流量,而大部分视频都是一对多的,非常适合多播。
局域网传输
大家是否感觉到了,用 QQ 在局域网里传文件的时候速度很快,完全不像是发到 QQ 服务器对方再下载下来。这是由于 QQ 自动检测网络拓扑结构,并在收发双方间建立隧道,直接发送数据。如果没有这项优化,本来在一间屋子里就可以搞定的数据传输,就要到数百公里外的服务器绕一圈!
如果想在卧室里的电脑上放视频,在客厅里的电视上播放,如果不做优化,可能到服务器的带宽根本不足以支持高清视频。不过,如果路由器和应用程序设计成下面这样,就完全不需要中心服务器的参与。
- 电视问:谁有 /home/videos/A?
- 路由器收到了这个询问,根据 URL 中的 home 知道这是属于自己的内容,于是向家里的各种设备广播这个请求。
- 电脑知道自己有 /home/videos/A,就把内容回复给路由器。
- 路由器知道电视需要这个内容,就把内容发给电视。
当然,要实现视频等流媒体的传输,还需要分片和序列号,不过上面的概念设计已经说明问题了。
不断移动的网络
越来越多的移动终端正在接入互联网。从一个 wifi 接入点跳到另一个接入点,或者从 wifi 网络跳到蜂窝网络(GPRS 或 3G),已建立的连接都得中断。如果一个人在接入点间频繁走动,那么基本是传输不了什么数据的。为此,电信运营商使用称为 Mobile IP 的技术方案保证用户在蜂窝网络间切换时 IP 不变,应用层软件也需要断点续传。
 meeker-india-mobile-v-desktop-internet
meeker-india-mobile-v-desktop-internet
这看起来不是一个大问题,不过在无线自组织网络中,由于节点的高度移动性,要维持端到端的连接是一件很困难的事。不过,我们为什么需要端到端的连接?如果我需要是对方的一个文件,对方只要声明他有这个文件并且允许我访问,我想让整个网络的节点都来为我尽力转发,不管它走的是哪条路!当然,用 UDP 和 mesh routing 可以做到这一点。不过,传统的路由方式只能选一条路,线路断了,还得重新选路。而且,IP 网络是无论如何不能同时利用 wifi 网络、3G 网络和蓝牙的。
更重要的是,IP 协议栈对某些应用来说本身就是冗余的。比如物联网中的传感器,它只需要把数据发送给接收节点,而不需要关心接收节点的 IP。目前这类低功耗的设备一般采用专有的通信协议,然而 CCN 可以成为一个统一的标准。
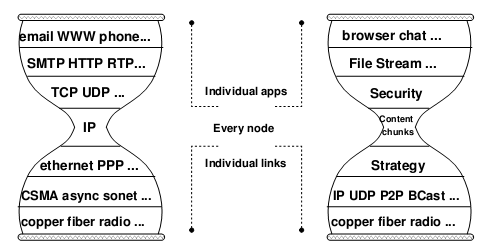
From “Where” to “What”
事实上,我们关心的不是 “内容在哪里”,而是 “内容是什么”。目前越来越多的网站使用 REST (REpresentational State Transfer) 架构,就是用像网页地址一样的 URL (Universal Resource Locator) 来标识每个数据单元,并使用 GET、POST、PUT、DELETE 等原语 (primitive) 来表示对数据的读取 (SELECT)、增加 (INSERT)、修改 (UPDATE)、删除 (DELETE) 操作。REST 摒弃了“连接”的概念,把操作变成无状态的,GET、PUT、DELETE 操作甚至是幂等的(连续多次操作等价于一次操作),大大简化了并发编程,降低了出现 bug 的概率。
在 REST 架构中,URL 只描述了“内容是什么”,而没有说 “内容在哪里”——我们不可能知道一个 URL 对应的内容存储在数据中心的哪台机器上。与 BT 之类协议采用的 hash 值不同,URL 首先是人类可读的;其次是分层次的,就像前面说的 IP 地址一样,可以根据 URL 比较容易地找到资源所在的位置。不过,IP 地址首先人类不可读(所以需要域名),其次它定位的是机器而不是内容。
REST 潮流使得整个互联网将越来越倾向于运行在 HTTP 上。不要忘了,在网络经典模型中,HTTP 可是在最上层的应用层!我们不妨把 HTTP 为代表的 REST 移到概念上更靠近网络协议栈中间的位置。
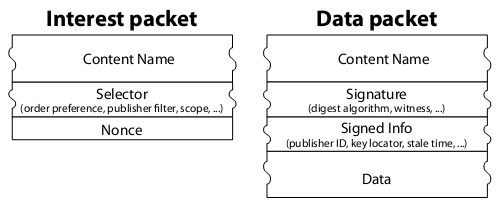
下图是 Content Centric Networking 的原始论文中对 “Interest Packet” 和 “Data Packet” 的定义。事实上,“Interest Packet” 可以被看成 HTTP Request,“Data Packet” 可以被看成 HTTP Response。我们对下图做一个浅显的解释:
- Content Name 就是 URL。注意,Data Packet 中也有 URL。
- Selector 是查询语言(query language),精确匹配的表达能力太单薄了。
- Nonce 是一个随机的序列号,以便丢弃从不同路径来的重复 Data Packet。
- Signature 是数字签名,以保证数据包的真实性。
 ccn-2
ccn-2
至此,我们还没看出 Content Centric Networking (CCN) 的强大之处。不就是已经被炒烂的 REST 嘛,至于在 SIGCOMM 这种顶级会议上专门开一个 workshop 吗?
让路由器智能转发
嗯,现在什么都要加上 “智能” 二字,我也赶一回时髦。而且路由器里针对 CCN 的转发和缓存策略,还真不是那么简单。
前面 “局域网传输” 的例子已经体现了路由器能做的事。我虽然开始研究网络不到两个月,但有一种强烈的直觉,未来的路由器一定不是网管配配路由规则那么简单。它在网络中就处在那个特殊的位置,就像手机就在人手上这样一个特殊的位置,只用来打电话、发短信太屈就了。今天我们不扯远的,就说说路由器在 CCN 中能起到什么责无旁贷的作用。
首先,我们需要更新一下 “网卡” 的概念。传统意义上的网卡(interface)是主机和网络链路之间的接口,每条链路都需要一个网卡。(如果开了 VPN,相当于增加了一条虚拟链路,就需要一个虚拟网卡。)在 CCN 中,为避免混淆,用 face 代替了 interface,每条链路仍然对应一块网卡(face),而每个使用网络的应用也对应一块网卡(face)。这样,主机上的 CCN 协议栈就跟路由器的职责差不多了,每个应用通过一条“线”连到主机,不再有本地数据包和转发数据包的区别,结构显得和谐多了。

每个运行 CCN 的主机或路由器,都有三张表:
- 转发规则表(Forwarding Information Base,FIB),就像 IP 网络的路由表,也是最长前缀匹配。由于没有 IP 地址的概念,只需要关心从哪条路走,而不需要“下一跳 IP”。表里的每一项,就是对于一个给定的 URL 前缀,需要转发到哪些 face。最简单的策略是转发到除源 face 外的所有 face,更智能的策略可以使用类似 BGP/IS-IS 的路由协议选路。不过传统路由协议只能生成一棵树,而 CCN 由于 Data Packet 里包含 URL,是不怕环路的。适用于 CCN 的路由协议是目前的研究热点。
- 查询等待表(Pending Interest Table,PIT),就像浏览器里正在载入的 URL,或者递归 DNS 服务器里正在解析的域名,要记录每个已收到查询但尚未收到数据的 URL,以及哪些 face 需要这个数据。当收到对应的数据时,就会把它转发给需要的 face,并从 PIT 中把这项删除。
- 内容缓存(Content Store),就是缓存一些最近经常被用到的查询结果。这张表可以小到在内存里,也可以大到在磁盘里。这是加速一对多传输的核心法宝。只要有一个用户请求了,沿途的所有路由器都会缓存这个数据,只要下一个用户来请求的时候还没被从缓存里清掉,就能直接返回数据而无须向数据源再发出请求。
增量部署
一个网络架构就算再好,如果需要一夜间更换全世界所有的网络设备,那也是不可行的。可喜的是,内容网络可以在目前的 IP 网络基础上增量搭建起来:若干个内容网络“孤岛”可以通过现有的 IP 网络连入互联网。
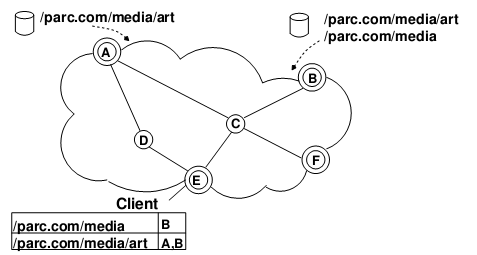
以上图为例,双圆圈是 IP+CCN 双栈路由器,单圆圈是 IP 路由器。A节点旁的一个用户可以提供 /parc.com/media/art 前缀的内容,A节点会插入此前缀到 FIB 表,并把此消息告诉 B、E、F。B节点旁的一个用户可以提供 /parc/media/art 和 /parc/media 的内容(同一个内容可以由多个节点提供),B节点会插入 FIB 表并通告 B、E、F。当一个在 E 旁边的用户需要 /parc/media/art/impressionist-history.mp4 时,E 就会到 A、B 去找。当然,前缀通告洪泛是比较耗带宽的,这制约了 “孤岛” 的数量。最近的研究成果利用 BGP 协议中的附加字段,可以让 BGP 路由器把前缀通告消息转化成 IP 路由通告消息。
至于顶级 URL 前缀在 IP 网络中的查找,可以借助现有的 DNS 系统。
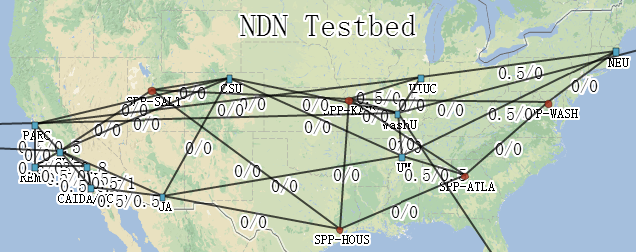
如果你还不相信的话,请看下图。(在 http://ndnmap.arl.wustl.edu/ 可以看到实时的网络拓扑和流量图)这多像 Internet 诞生前夜的网络拓扑啊!那时,实验性的 IP 网络建立在电话网络基础上。今天,实验性的内容网络建立在 IP 网络基础上。
安全性
安全性主要分为两个层面,一是信任数据来源,二是防止攻击。
信任数据来源
CCN 是 peer-to-peer 的传输,如果谁都能宣称自己是任何实体,肯定就乱了。首先,CCN 的 Data Packet 都是带有数字签名的,这保证数据不会在传输过程中被篡改。不过,我给自己签个名,宣称我是 Google,谁知道呢?
在目前的 PKI (Public Key Infrastructure) 下,是若干个受信任的机构(被称为 CA)给受信任的机构和个人颁发数字证书,证书的持有者再拿 CA 签名的证书去给传输的内容(如 HTTPS)签名。操作系统中会内置这些 CA 的数字签名,这样就保证所传输内容的不可伪造性。不过,如果 CA 被攻破了,或者不再遵守 Don’t be evil 的行为准则,整个信任机制就岌岌可危了。这种信任危机在历史上是出现过的,直接导致那家倒霉的 CA 破产。
CCN 中的信任并不是非黑即白的 “一揽子方案”,而是基于上下文(contextual)的。
首先,需要建立起一个人所信任的 key 列表。这有多种方式:
- 树形结构:假如我是微软公司员工,就会信任 microsoft.com 的 key,这个 key 所签名的其他微软员工的 key 我也会信任,这样公司内部就能够安全通信了。
- 传统的基于签名的公钥体系(前面说的 PKI)
- PGP Web Of Trust。每个人都可以给网络中其他若干人签名,形成一张信任关系的大网,即使有一两个人背叛也无所谓。Debian Developers 就是使用 PGP Web Of Trust 维持这个大型松散团队的信任关系的。
其次,内容的安全由“安全链接”来声明。例如,受信任的A发布的内容P里包含一个到内容Q的安全链接,则内容Q就比较靠谱。如果很多受信任的内容都有指向内容Q的安全链接,则Q的靠谱程度就会非常高。(像不像 PageRank?)应用到目前的网络上,就会形成一个 “安全链接” 构成的大网。即使一个发布者背叛了,试图伪造数字签名,也会有更多的证据证明原有的签名的可信度高于伪造的数字签名。
防止攻击
CCN 非 “端到端” 的设计天然消除了网络攻击中的一大类:直接向目标主机发送恶意数据包。因此 CCN 的攻击可能集中在 DoS (Denial of Service) 上。
- 反射攻击:由于压根没有源 IP 的概念,伪造源 IP 就是无稽之谈了。
- 隐藏合法数据:除非控制住了必经之路,是做不到的。由于 CCN 不需要生成树,如果这条路收不到数据,Interest Packet 可以走另一条路发出去,并沿着那条路接收 Data Packet。
- 发送大量随机编造的请求(Interest):这看起来很有效,因为请求是匿名的。可以在路由器上限制有多少已发出的 Interest 没有收到回应,就像 IP 网络中限制半开连接数以防止 SYN flood。
- 发送大量未经请求的回复(Data):没有任何作用,因为会被丢弃。
结语
论文作者没有提到的一个问题是,内容网络不是端到端的,所有请求都是匿名的,内容提供商就无从得知谁访问了这些内容,也无法针对地区做访问控制。当然,目前运营商的小区缓存已经使访问次数的统计不再准确。
另一个问题是,URL 前缀不容易匹配,需要路由器里更大的 TCAM 空间。这方面已经有不少研究,不过字符串比整数天然更难处理,这将是制约内容网络大规模部署的一个瓶颈。
Anyway,内容网络是一个切中当今互联网痛点的新兴网络模型,也得到了学术界的认可。不论这个网络模型今后是否会大规模推广,甚至取代目前的 IP 网络,内容网络的基本思想及其在名字分配、多径路由、信任机制等方面的研究成果,都可以为现有的基于 REST 架构的网络应用提供借鉴。
References
- V. Jacobson, D. K. Smetters, J. D. Thornton, M. F. Plass, N. H. Briggs, R. L. Braynard (PARC) Networking Named Content, CoNEXT 2009, Rome, December, 2009.
- http://www.ccnx.org
- http://ndnmap.arl.wustl.edu/