APNet'21: Huawei Unified Bus: Towards Compute Native Networking
This one-hour presentation at APNet 2021 is probably the best publicly available resource on Huawei’s UB (Unified Bus) interconnect to date.
This pictorial record is generated using AI technology based on the APNet 2021 official video, with a small amount of manual corrections.
(Session Chair Prof. Kai Chen) Perhaps I can introduce Kun first. To introduce, Dr. Kun Tan serves as the Vice President of CSI, where he heads the Distribution and Parallel Software Research Lab at Huawei. His research interests lie in networking, network systems, and cloud computing. Today, the topic of discussion is “Towards Compute Native Networking”, which might be a novel concept for some.

(Dr. Kun Tan) Hello everyone, and thank you for the introduction. I have the honor of presenting the first talk today, which centers around “Compute Native Networking”. This might be a new term for most, so I will attempt to explain its meaning and significance. I argue that this novel type of network is something we should pay attention to.
This is part of the work that has been undertaken recently at Huawei in collaboration with HiSilicon. It is a novel networking technology. Let’s discuss the motivation behind it.
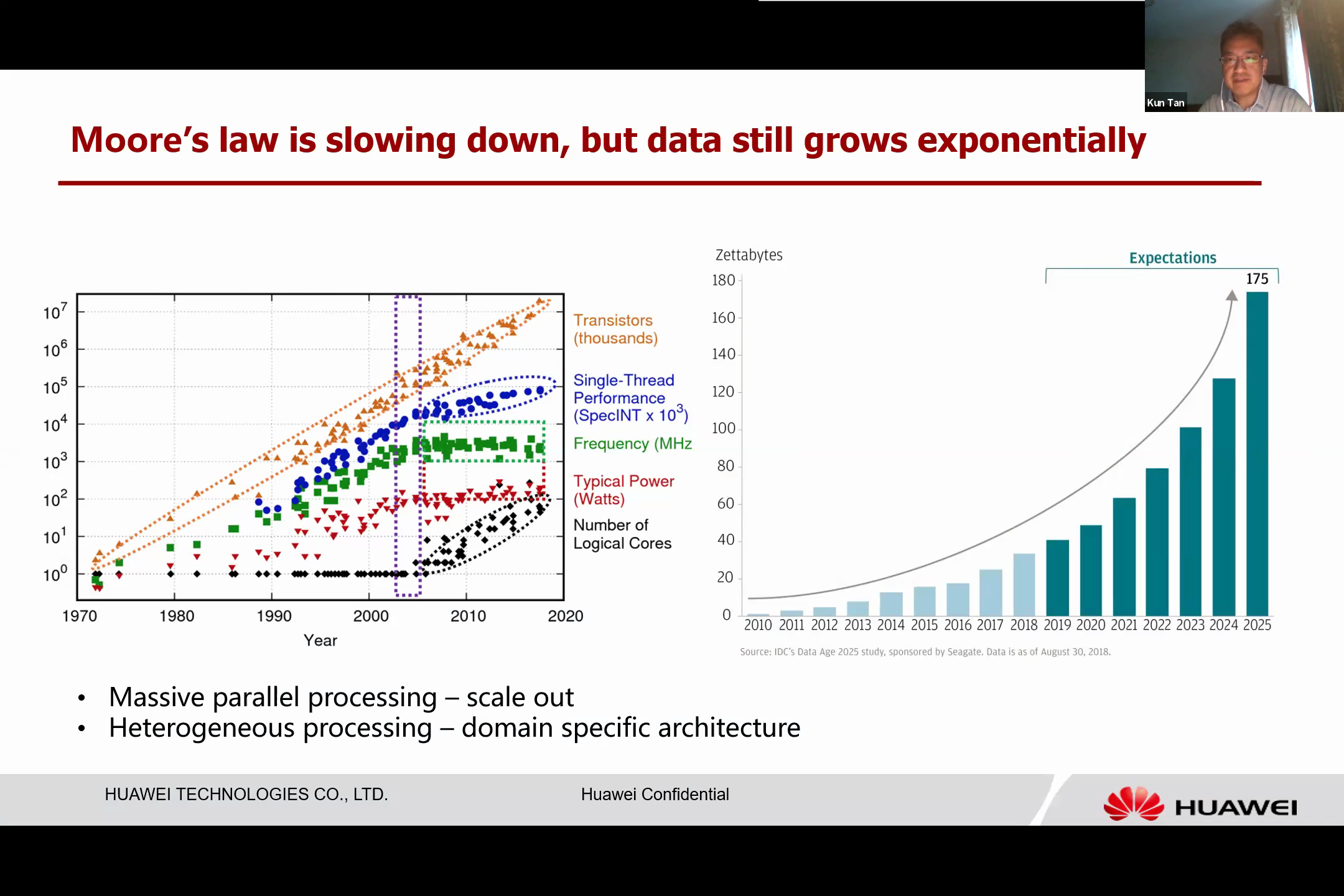
We can look at the development of silicon for inspiration. Moore’s Law is slowing down; we’ve reached 7 nanometers, and now 5 nanometers, but the performance isn’t increasing as rapidly as it once did. However, the amount of data we generate continues to grow exponentially, from social media to the Internet of Things. We still need more computing power to handle and process all this data.
With the slowdown of Moore’s Law, we’ve found that processing this volume of data necessitates massive parallel processing. We cannot rely on a single, fast chip to do this job. We require many types of processors, grouped together, thus we can scale out architectures like data centers.
Another challenge we face is the need for heterogeneous processing. This means that if we cannot increase the speed of individual processors, we may need to use different kinds of processors together to handle the data load.
The pursuit of faster gates has led us to design a variety of domain-specific architectures. Each of these architectures is uniquely suited to handle certain types of workloads, resulting in a plethora of domain-specific architectures, each designed to process its corresponding workload.
However, this leads to some challenges. First, as computing devices multiply and diversify, the process of compiling becomes increasingly complex, sometimes even insurmountably so due to changing workloads over time. Second, we find that designing servers becomes more complicated. Even within a single server, we have multiple types of processors which necessitate a connection that can efficiently facilitate their communication.
Unfortunately, the current I/O architecture falls short in this regard.
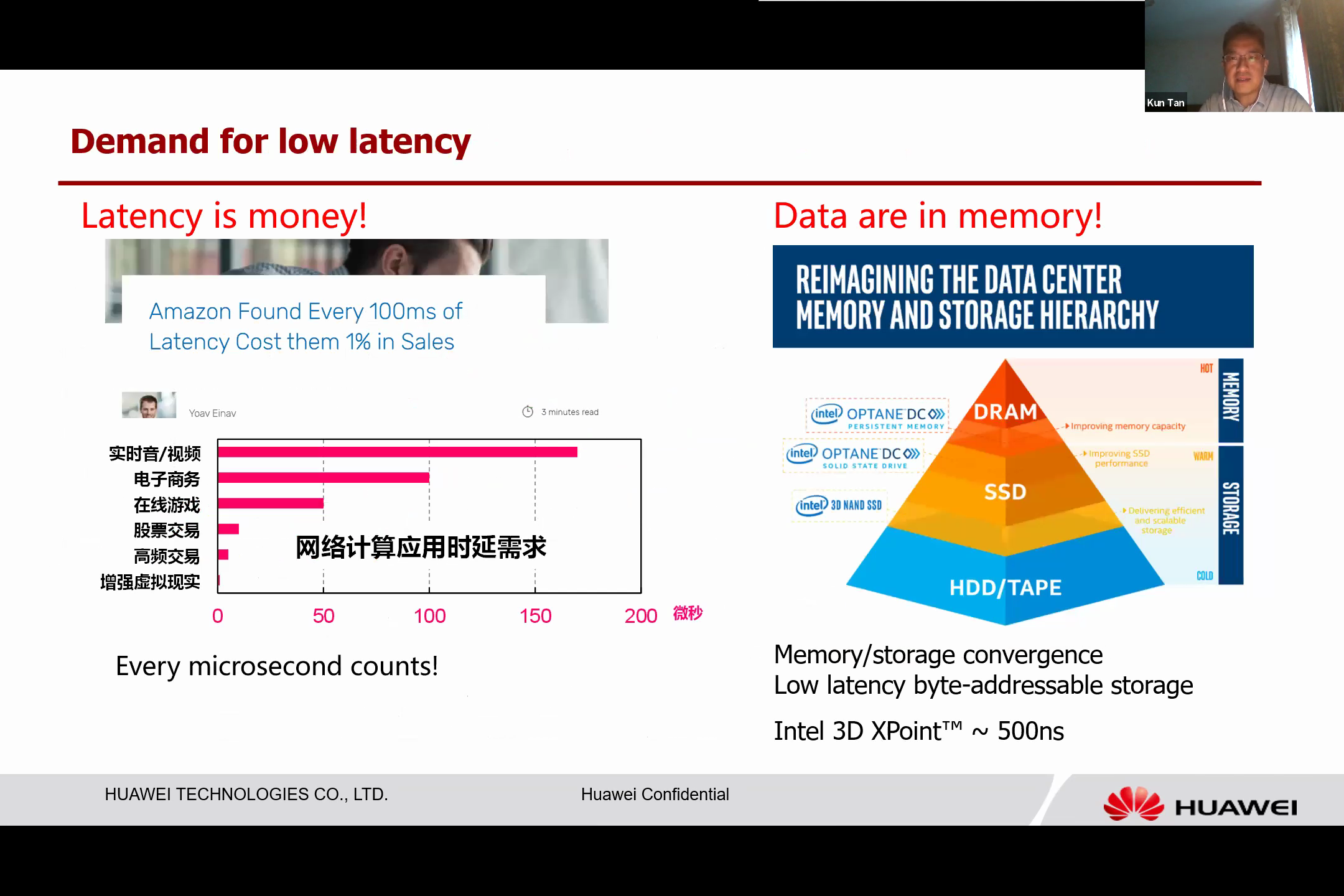
Additionally, the requirements of applications have evolved. Previously, most applications were driven by throughput, but now latency has become a critical factor. Different applications necessitate different latencies, and most require very low latency, on the scale of microseconds. Thus, even microsecond delays can have significant impacts.
Another trend is the emergence of a new type of storage: storage class memory. This byte-addressable type of memory has slower access latency than DDR, but is still faster than conventional storage, like block storage. For example, Intel’s 3D XPoint technology has only a five-microsecond access latency. However, connecting these large memory banks to the CPU becomes a challenge. The existing CPU architecture does not scale well with regards to memory interconnection. Currently, each Intel CPU can only support a few memory channels. Expanding this capacity is a pressing issue.
In summary, we are dealing with a variety of devices, each becoming its own computational entity. The necessity for an interconnection to link them all is evident.
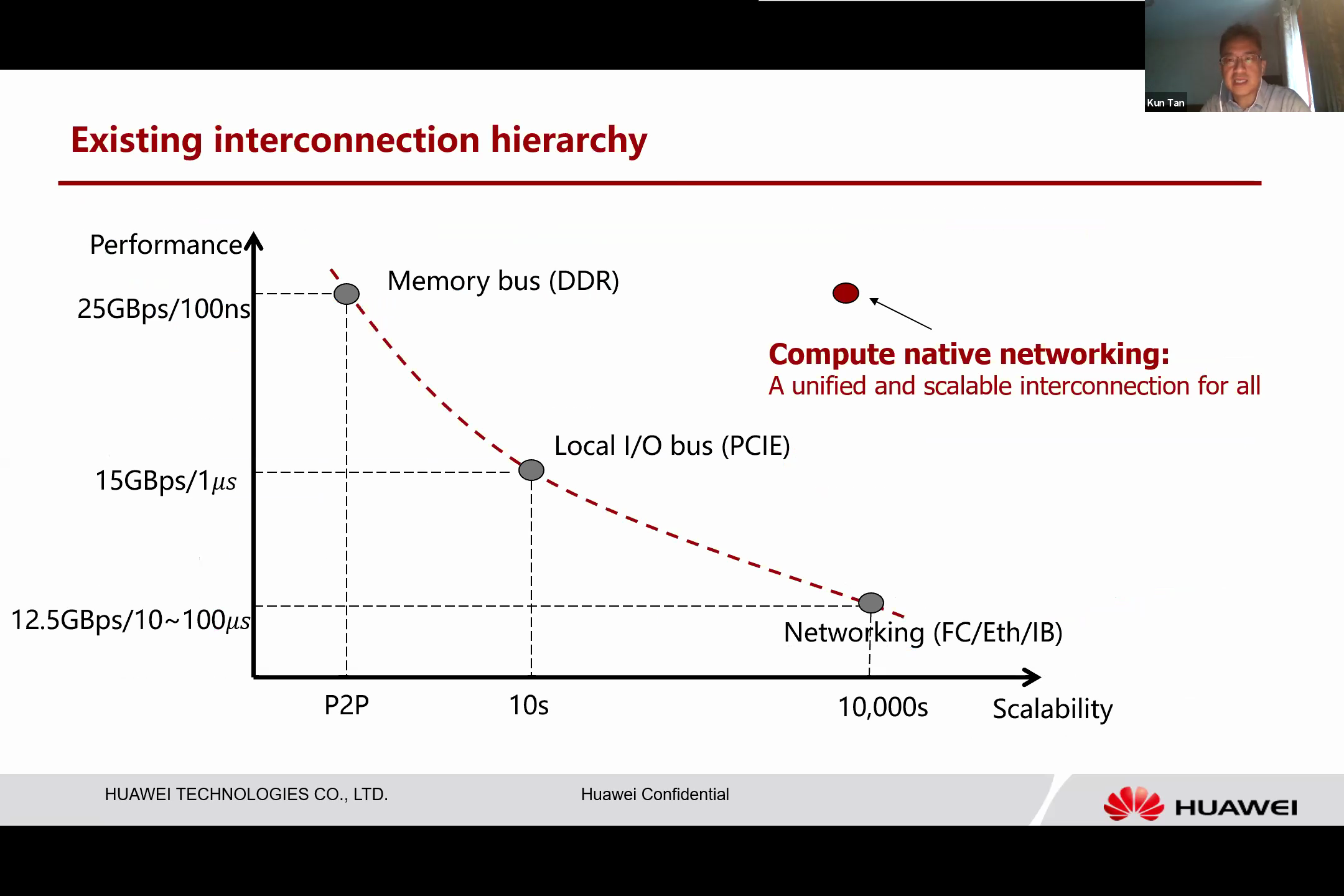
Unfortunately, the current interconnection hierarchy is inadequate, presenting a trade-off between performance and scalability.
As seen on the left, we have memory bus. Memory bus is designed to connect directly to the CPU. While it is incredibly fast, it does not scale well. Typically, one memory channel can only connect to one memory module, resulting in a point-to-point link. On the other end of the spectrum is networking, which scales significantly. We can connect devices on an internet scale, but the performance is subpar. For instance, the current networking interface operates at about 100 gigabytes per second, which is significantly slower than memory. Situated in the middle are local I/O buses like PCIe.
The performance of PCIe lies between that of memory buses and networking, and its scalability is also intermediate. With PCIe, we can connect a handful of devices within a box, but the performance is about 15 gigabytes per second.
Upon examining the current connection hierarchy, it is clear that it does not align with our aim to interconnect a heterogeneous, larger scale of devices. This led to the idea of developing a new type of network, which we call the “compute-native network”. This is a unified and scalable connection designed to connect all types of devices, including memory stacks.
This is the fundamental idea and motivation behind our work. After a year of research, we have developed a prototype called the “Unified Bus”.
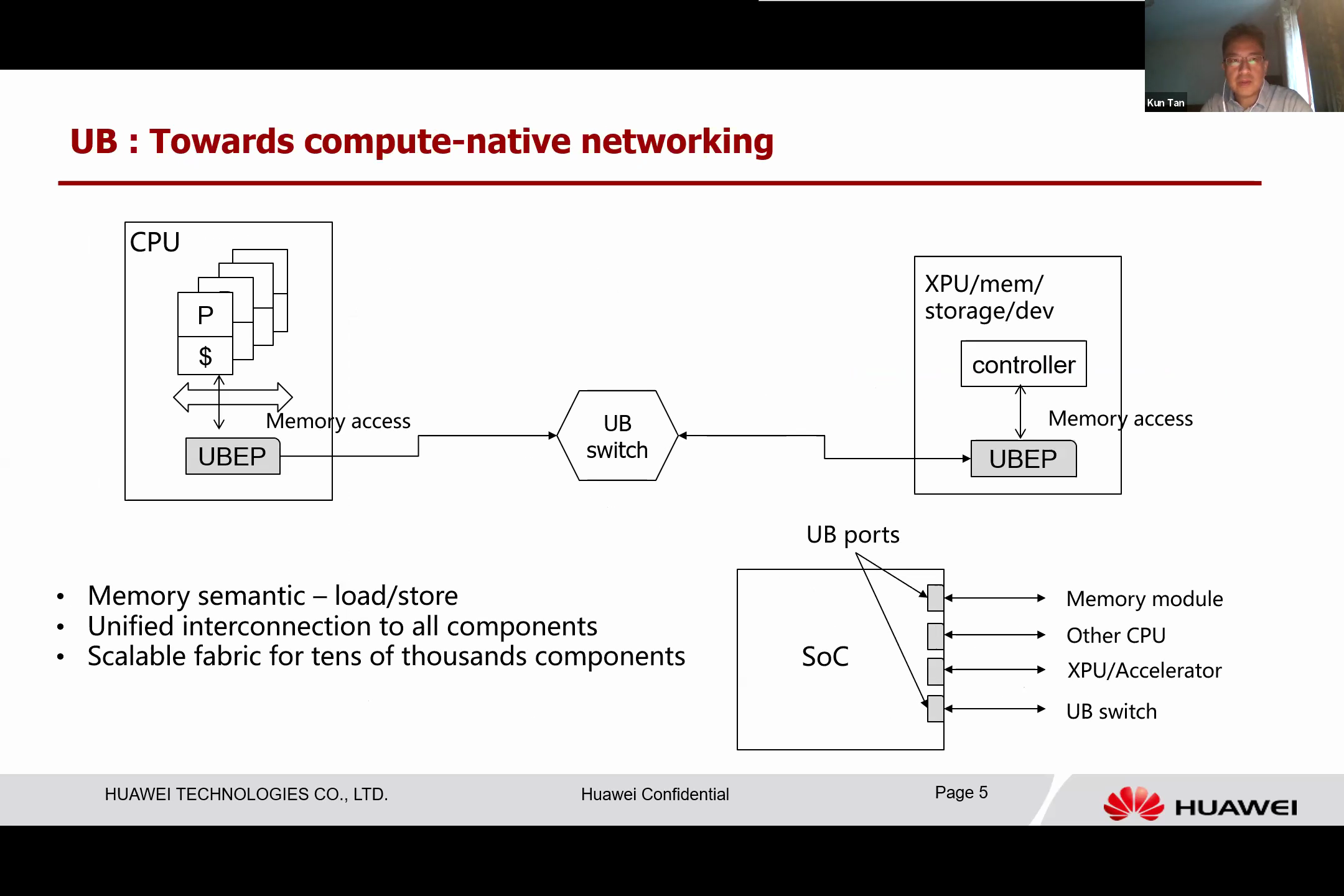
So, why do we refer to it as a “compute-native network”? We believe that there are three properties that define it.
Firstly, a compute-native network is a memory semantic fabric. Unlike traditional networking, which is bitstream-based and not TCP, it should support load and store semantics. This means that every device, whether it’s a processor, a memory module, storage, or another device, is treated as a piece of memory. These devices can load data from one memory location and store data in another. Furthermore, it is unified since its memory semantics are a universal protocol within the computing system. This is what we anticipate.
All devices can utilize this semantic for various types of tasks, making it a highly generic semantic. We can define a single protocol suite that connects to all types of I/O devices, processors, and other components. This also includes a scale fabric, which isn’t designed to connect just a pair or a handful of devices, but to connect tens of thousands of computing components, thus forming a large cluster.
The figure above illustrates the concept of a CPU accessing a remote device using standard load and store instructions. These instructions access what we refer to as the UB memory interface, which forwards these memory access commands to the remote device. These commands are executed in the remote UB, much like accessing local memory.
If we examine the UB, we can predict an interesting future for SoCs or CPUs. Current SoCs have a variety of different types of I/O pins. With the implementation of UB, we predict that there will only be one type of output from SoCs, the UB. The UB offers much-needed flexibility to system designers as they can repurpose these posts for different objectives, unlike current SoCs where resources are divided at the manufacturing stage.
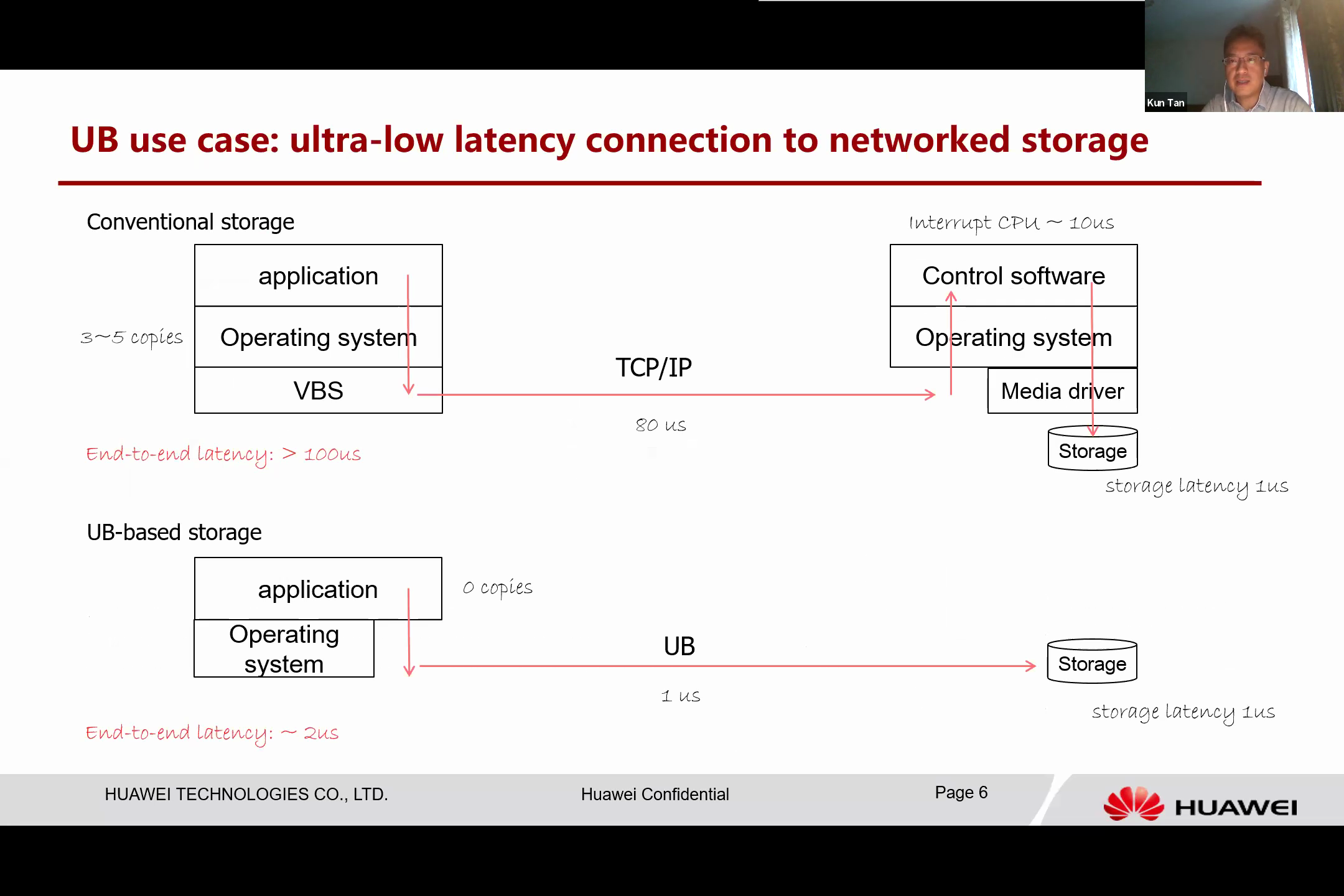
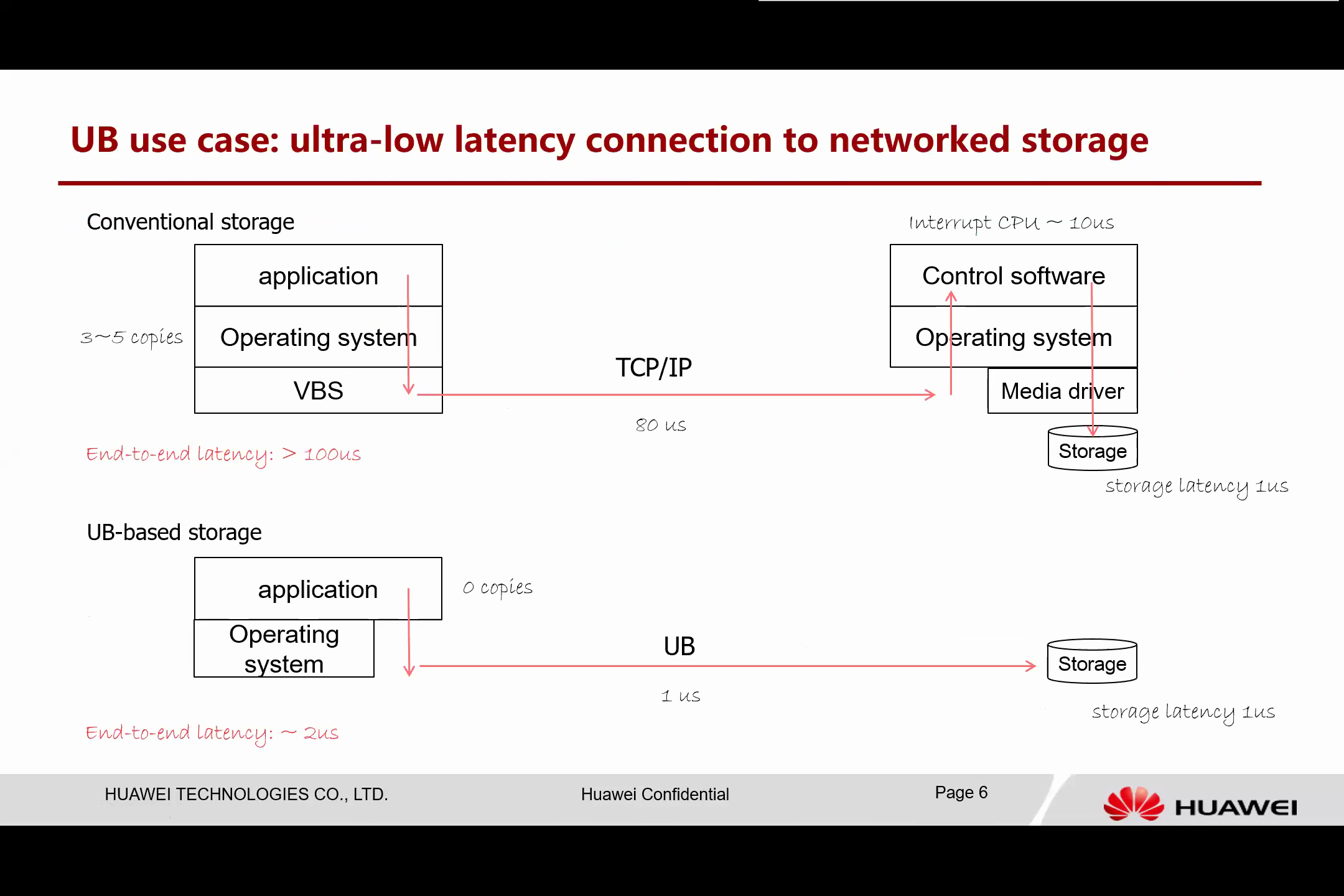
Next, I will present a few interesting examples of UB usage. Let’s begin by discussing how the UB can connect to remote storage. Currently, in conventional storage systems, we have a client (illustrated on the left) and a server (illustrated on the right). The current system is compact, requiring the application to work with the operating system. This adds additional data copies and has virtual block limitations.
The storage driver initiates and forwards this storage access using TCP/IP over thislat. The request is then processed by a control software. Essentially, the control software is situated as a server, translating the command to a local command for the media. Subsequently, the data is written to the storage. As such, multiple software and hardware layers are involved before the task is completed. Currently, even for the highest-tier storage systems, the end-to-end latency is approximately 100 microseconds.
However, when we implement the Unified Bus (UB), the circumstances significantly change. Once the application has completed the configuration authentication, all data path access bypasses the operating system. It is akin to accessing local memory, which enables zero-copy. UB provides ultra-low latency connections, requiring only one microsecond to access remote media and write data directly into it. Consequently, the entire latency is dramatically reduced, marking a considerable improvement.
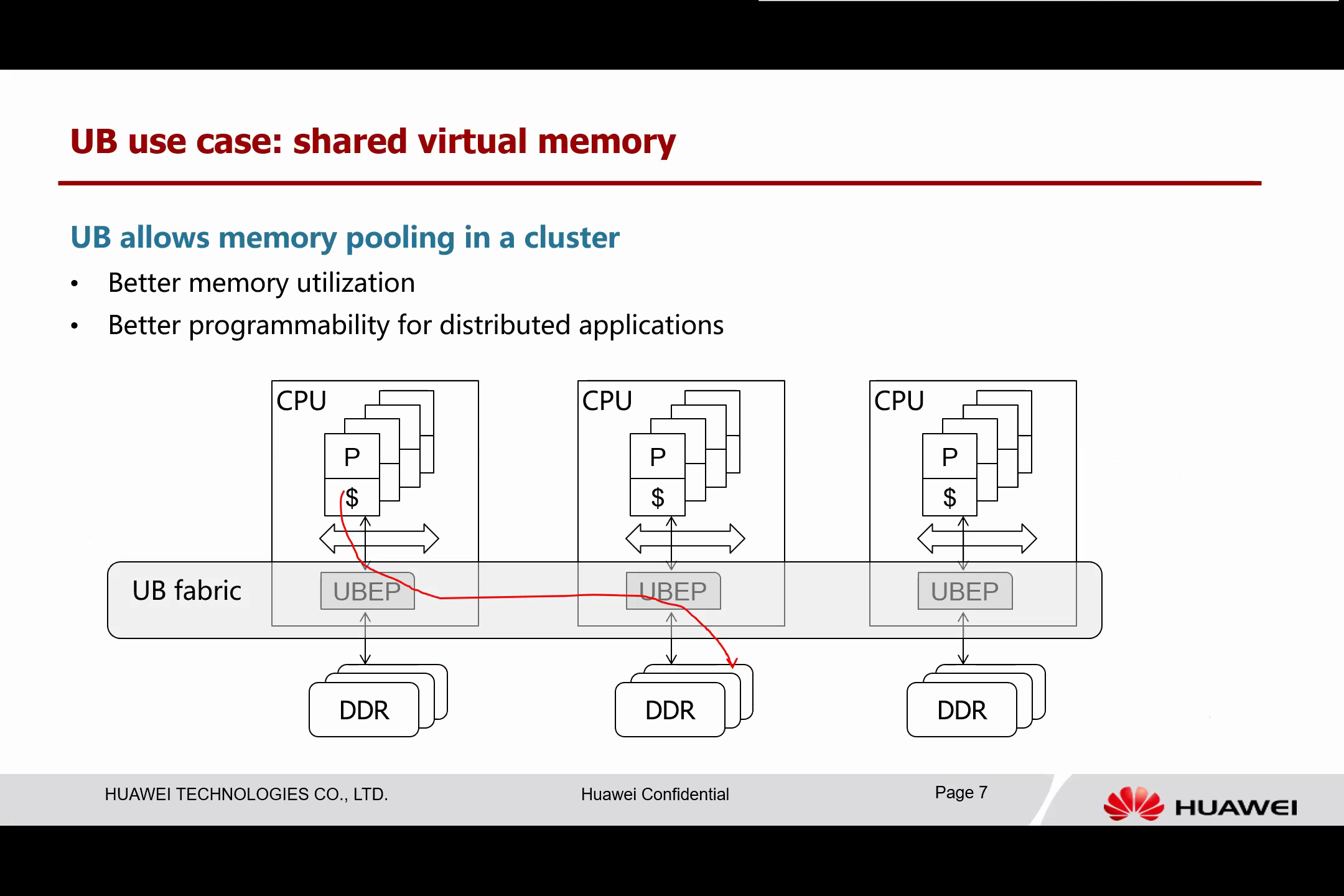
Another compelling use case for the UB is to facilitate the sharing of virtual memory. Essentially, there is no memory partitioning into classes; different servers can contribute their memory to form a shared memory pool. This allows other CPUs to access the memory directly through hardware-assisted channels.
This memory pool provides several benefits from a holistic system perspective. Firstly, it enhances memory utilization. Some applications might be computation-centric, while others are memory-centric. When memory resources are confined to a single server, computation-centric applications might have spare memory that is left unused. However, with memory pooling, memory-centric applications can utilize this spare capacity more efficiently.
Secondly, shared virtual memory presents a single address space to applications. Even though the memory is distributed, it is conducive to optimizing distributed applications and simplifying the programming of these applications.
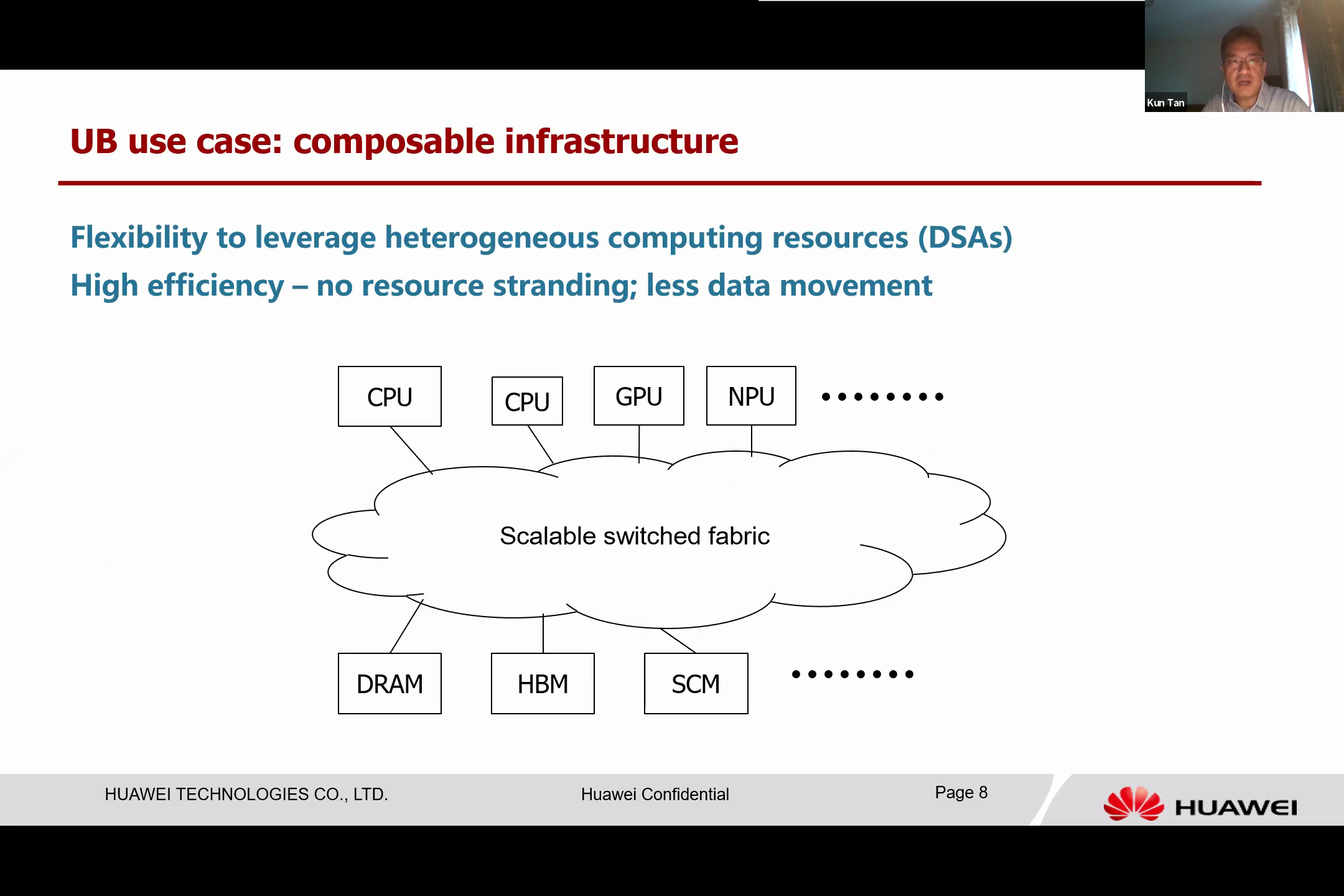
In the following use case, we are dealing with a composable infrastructure, specifically examining the current heterogeneous cluster. We have a variety of different devices operating under this domain-specific architecture. Consequently, allocating these resources to the server presents a significant challenge, as I mentioned earlier. This becomes particularly problematic as the workload changes.
If these devices are statically attached to a server, then balancing the general computing resource and the domain-specific architecture (DSA) resource becomes highly challenging. However, if we have a flexible pool of computing resources, these resources can be recomposed to better suit different workloads. As such, when a workload arrives, we can allocate different resources to be utilized, thus making more efficient use of the computing resources available and reducing the amount of data movement.
For example, memory and storage can be shared among all devices, allowing direct access to data from storage media, rather than needing to copy data from a remote location to a local one before computation can occur. This efficiency and reduction in data movement can be enabled by providing a unified high-performance memory semantic interconnection.
Let’s delve into a few details of how we can achieve this. We’ll first look at the programming model of the Unified Bus (UB).
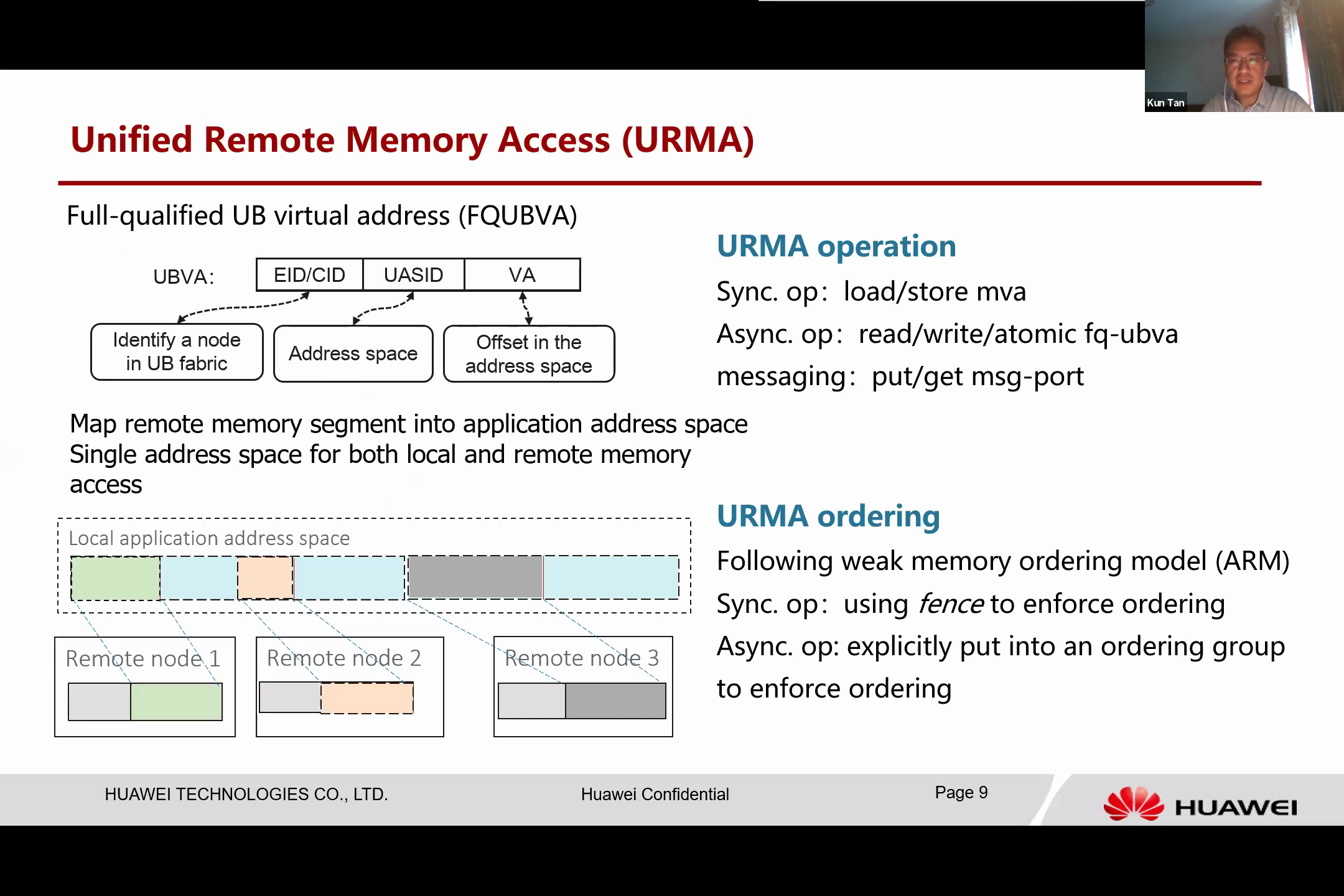
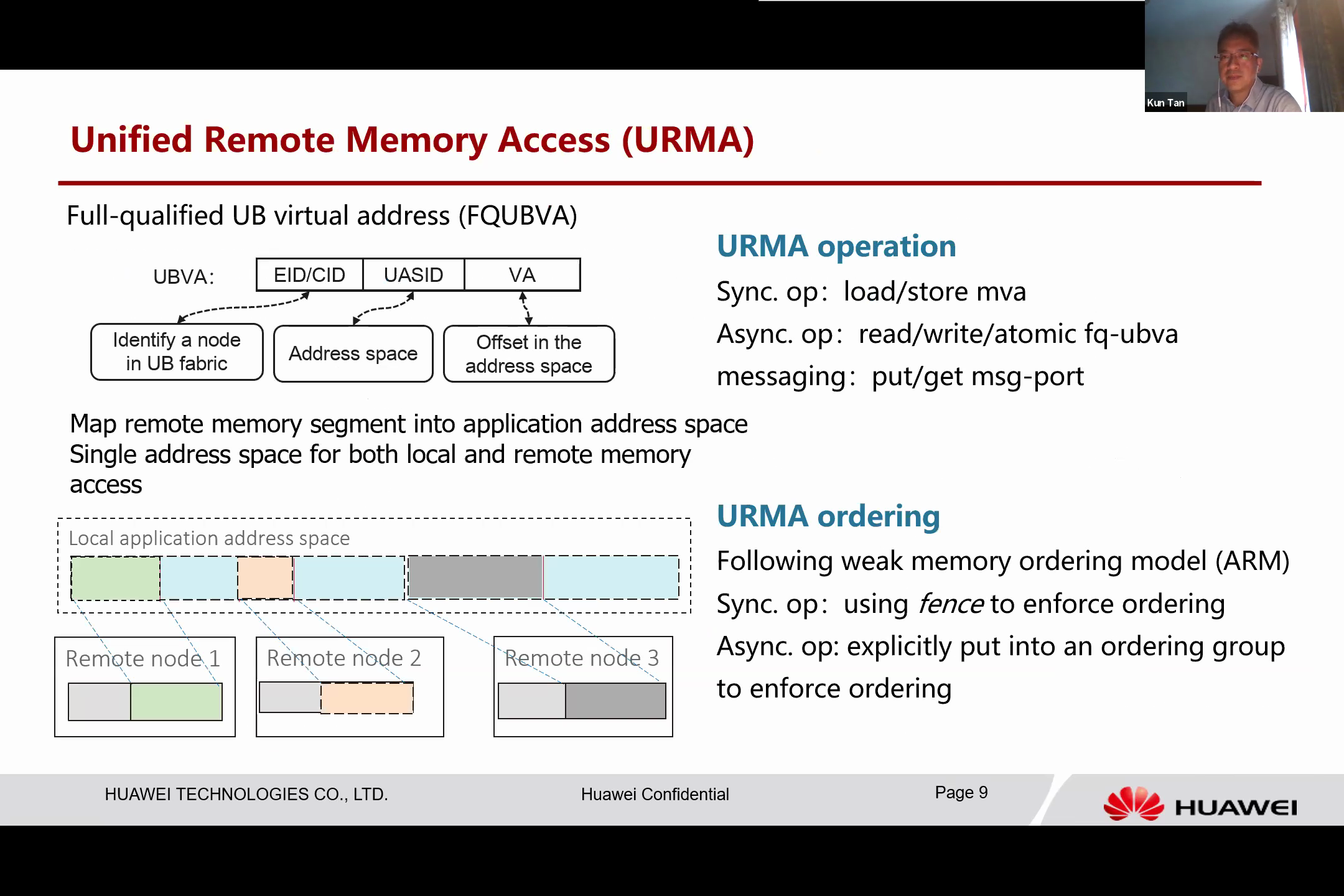
The general programming model of UB, which we refer to as Unified Remote Memory or URMA, allows every resource to be addressed by a memory address. Essentially, a memory address in UB has an Entity ID, which identifies a computing node, and a UASID, which is the ID for the address base of the computing node. The VA is the offset in that address space. As this is a fully qualified UB virtual address, the remote memory can be mapped into the application’s address space.
This is how we can achieve a single address space for application. If we look at the figure on the left bottom, we can see the application’s linear address base and segments of remote memories dynamically mapped from this remote memory. This means that you can use the same method to access these resources.
The local memory and the remote memory are integrated in the application address, thus supporting three types of operations. The first operation is synchronous, essentially the store instructions and atomic instructions to this mapped virtual address are akin to those from application software. This operation is essentially like accessing a normal address, using standard computer instructions.
The second type of operations, known as asynchronous operations, is akin to a memory copy command directed to the Unified Bus (UB), which will execute it. Upon completion of this transaction, the UB notifies the CPU that the memory operation is completed. Moreover, the UB supports messaging, which can be viewed as a two-sided operation. It involves sending a message port to the data and obtaining the data from the port, a process that is straightforward.
Another integral design feature of UB is that it follows memory order since it is fundamentally a memory fabric. Thus, these Uniform Memory Access (URMA) operations are executed in an out-of-order manner to maximize access parallelism. However, in certain scenarios, we still need to follow a specific order of operations. This requires the application or the programmer to explicitly use these fence instructions or put them into an explicitly ordered queue or group to ensure that order.
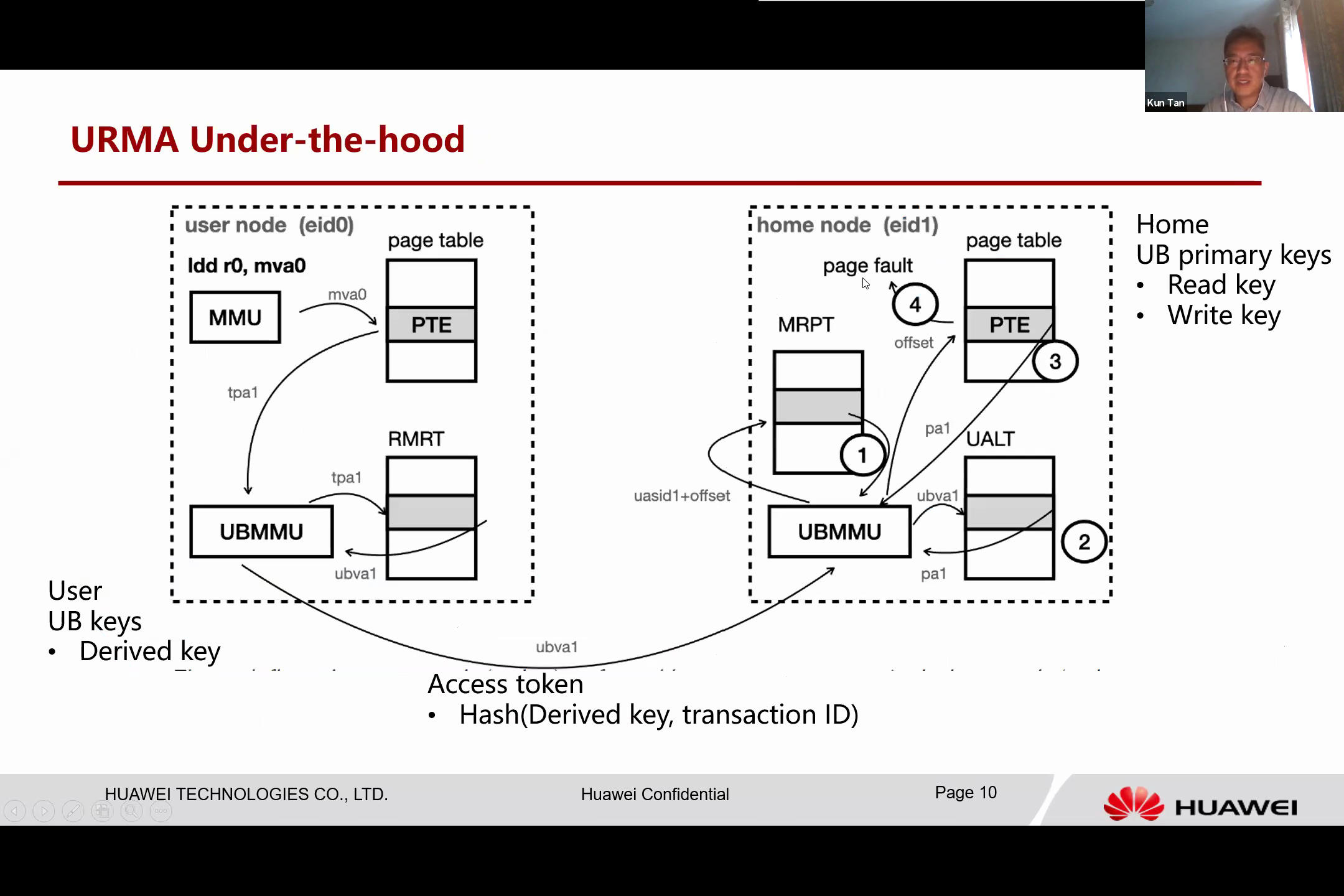
Let’s now examine how these URMA operations work in practice with the UB. The UB is entirely integrated into the CPU, including a crucial memory management unit, dubbed the UBMMU. For instance, let’s consider the process of loading data from a remote address. Presumably, the remote memory has been mapped into a local address base, and this local virtual address is MVA 0.
When the software or the CPU executes this load instruction, the local memory management of the CPU translates this memory - MVA 0 - by examining the page table and translating it into a tagged physical address, TPA 1. This TPA 1 is then mapped to the UB space.
The Unified Bus Memory Management Unit (UBMMU) module captures the data and we examine another table, the Remote Memory Region Table. This table translates the address into a fully qualified UB memory address. Following this, the access is translated to a UB memory operation and sent over Unified Bus Protocol to the remote node.
Upon receiving the operation, the remote side utilizes the UBMMMU module to process the address. It then checks the Memory Region Protection Table to verify if the access is valid. If validated, it refers to another table, the UB Address Lookup Table.
This table is essentially a scalable cache for the page table, analogous to a Translation Lookaside Buffer (TLB), but with a significantly larger size. It operates memory-based and retains a large volume of data. If the UB Address Lookup Table holds the entry for this UB memory address, it can return the physical address directly. It then executes the physical address, loads the data, and returns the value to the source.
In the event of a miss, the UBMMU module performs a page walk to locate the page table of the home node application and finds the actual physical address. In some instances, if the address is not in memory - for example, if it has been swapped out by the home operating system - it will trigger a page fault to the application. The operating system then performs the swapping and, once the operation resumes, the data is noted and returned to the user node.
This integration with the UBMMU allows it to directly read the application CPU’s memory and page table, which is a unique feature. It can manage the page fault and does not need to pin the physical memory at the home node. The home node can freely manage the physical address based on its policy without disrupting the entire access process.
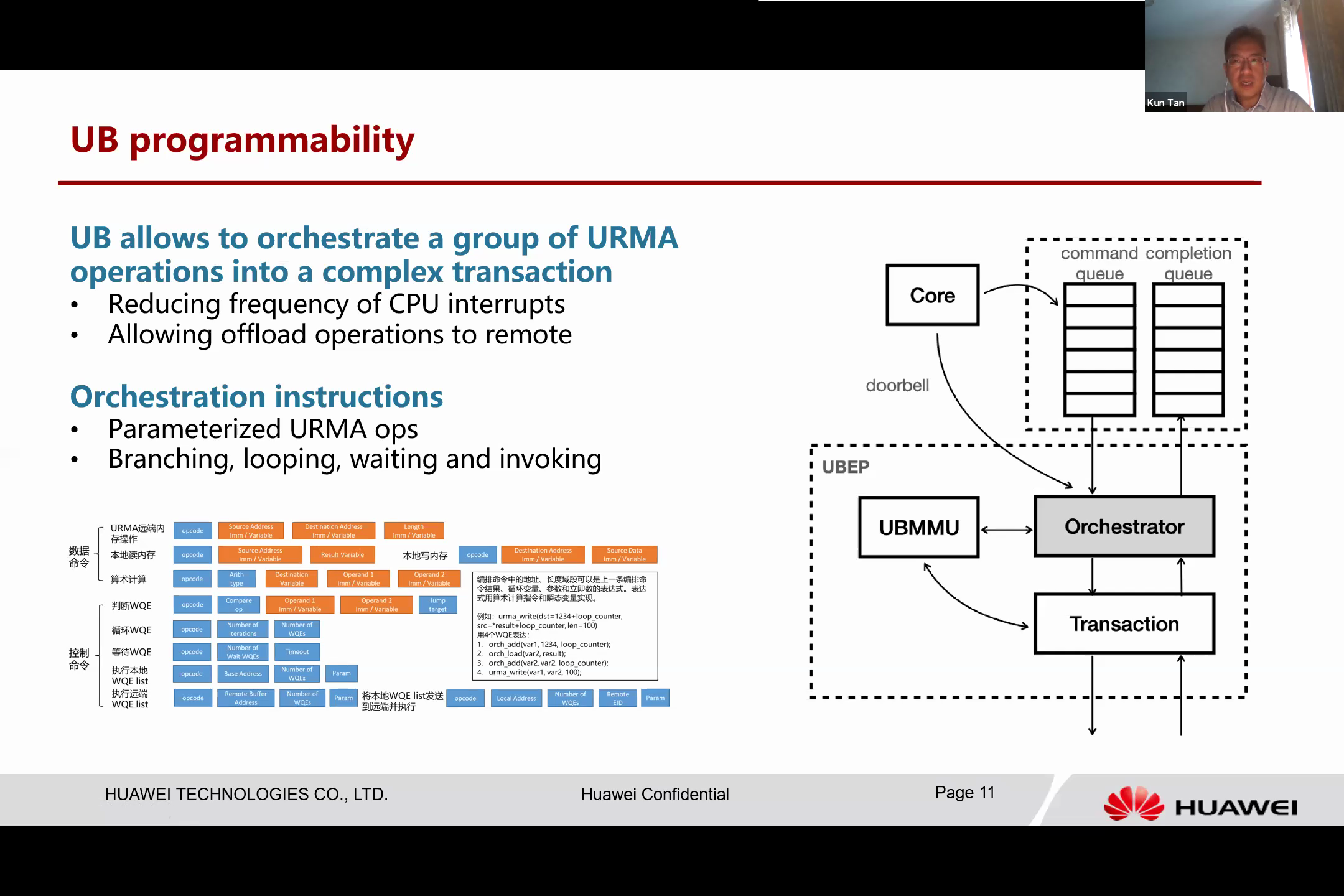
Besides the basic URMA operations, the Unified Bus is also programmable and has a programming engine that we refer to as the Orchestrator.
The UB can transform a set of Unified Memory Access (URMA) operations into a complex transaction, a feature that allows for the grouping and submission of multiple operations at once to the UB, which can then execute these without further CPU interruption. This enables complex transactions to proceed without increasing CPU overhead, a stark contrast to current IO procedures.
In traditional IO procedures, every operation must be controlled by the CPU, leading to increased workload on the CPU for every IO command. This process is both time-consuming and complicated. However, UB has the ability to offload these operations remotely. For instance, some operations, such as remote operations, can be condensed into a small program and sent to a remote UB to be completed, eliminating the need for constant back-and-forth communication between the home node and the destination node.
The UB also includes orchestration instructions, encompassing parameters for operations that can be filled with detailed data values at runtime, as well as branching, looping, waiting, and invoking instructions. This allows for the execution of conditional and loop operations, and the coordination of other orchestration operations.

A practical application of UB’s orchestration capability can be seen in replication transactions.
For instance, a client can orchestrate memory write transactions and send them to a primary node. This primary node executes the instructions, writes to different backups, and collects all the results. If all the results are successful, the primary node can return the result to the client in a single round.
This ensures that the entire transaction does not involve the CPU, resulting in faster operations and lower latency.
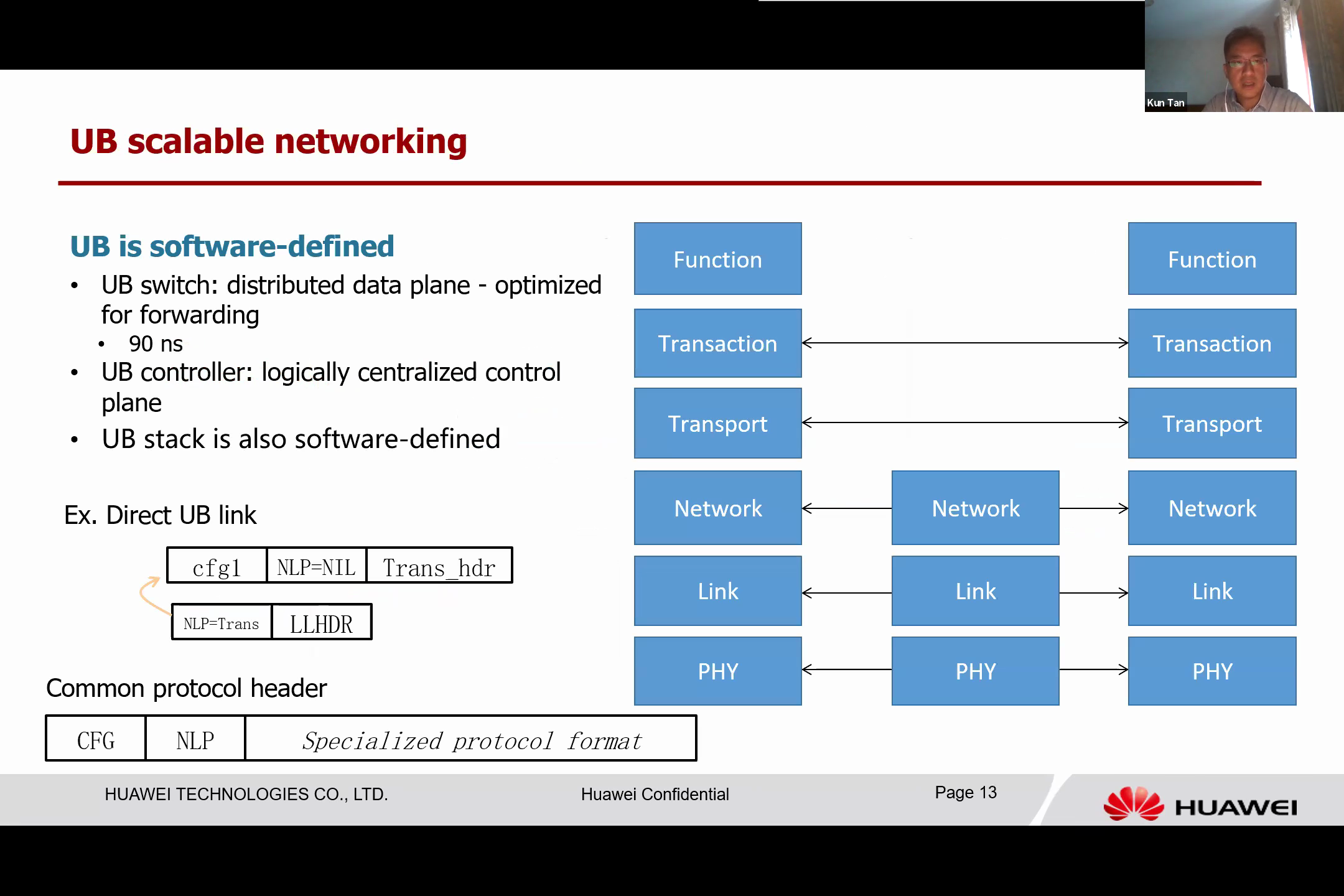
The UB follows the software-defined design principle. It features a UB switch, which is essentially a distributed data plane optimized for forwarding. This extremely low-latency forwarding engine takes about 90 nanoseconds to forward a packet after a simple lookup.
The UB performs quick forwarding operations through one or two memory lookups. The UB controller, a logically centralized control plane, is instrumental in this process. Running on servers, it configures and controls all UB switches to perform forwarding jobs.
The UB stack is software-defined. Conventionally, seven layers of protocols are used. However, in some UB use cases, not all these protocols are required. The speaker highlights that in certain scenarios, such as when the UB directly connects with a computing device or a memory module, networking headers and transport are not needed. The transaction layer can be directly linked to the link layer.
This is made possible by using common protocol headers on every layer, each containing two fields. The first field indicates the configuration and type of layer, while the second field points to the protocol encapsulated in the current protocol payload. For instance, in direct UB links, the link layer protocol points to the transaction, bypassing the network and transport layer. This reconfigurability of the protocol stack enhances the adaptability of the UB, allowing it to perform comparably across various scenarios.
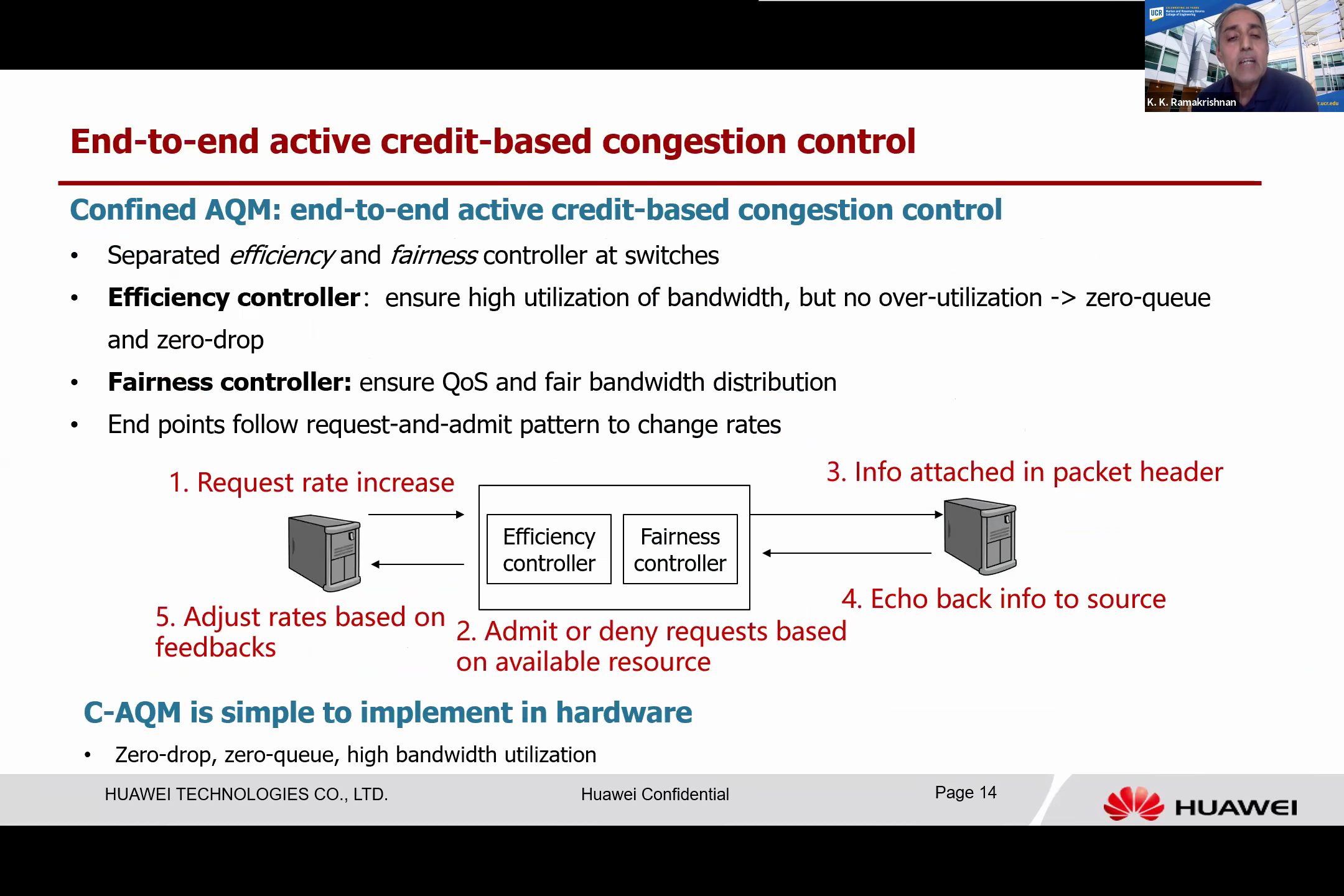
The UB also includes end-to-end active congestion control. To expand a single chip to a larger scale, effective congestion control is critical. In a large network, congestion is inevitable, leading to a significant degradation in performance due to queuing delay. The aim is to avoid underutilizing the network bandwidth or experiencing excessive delays.
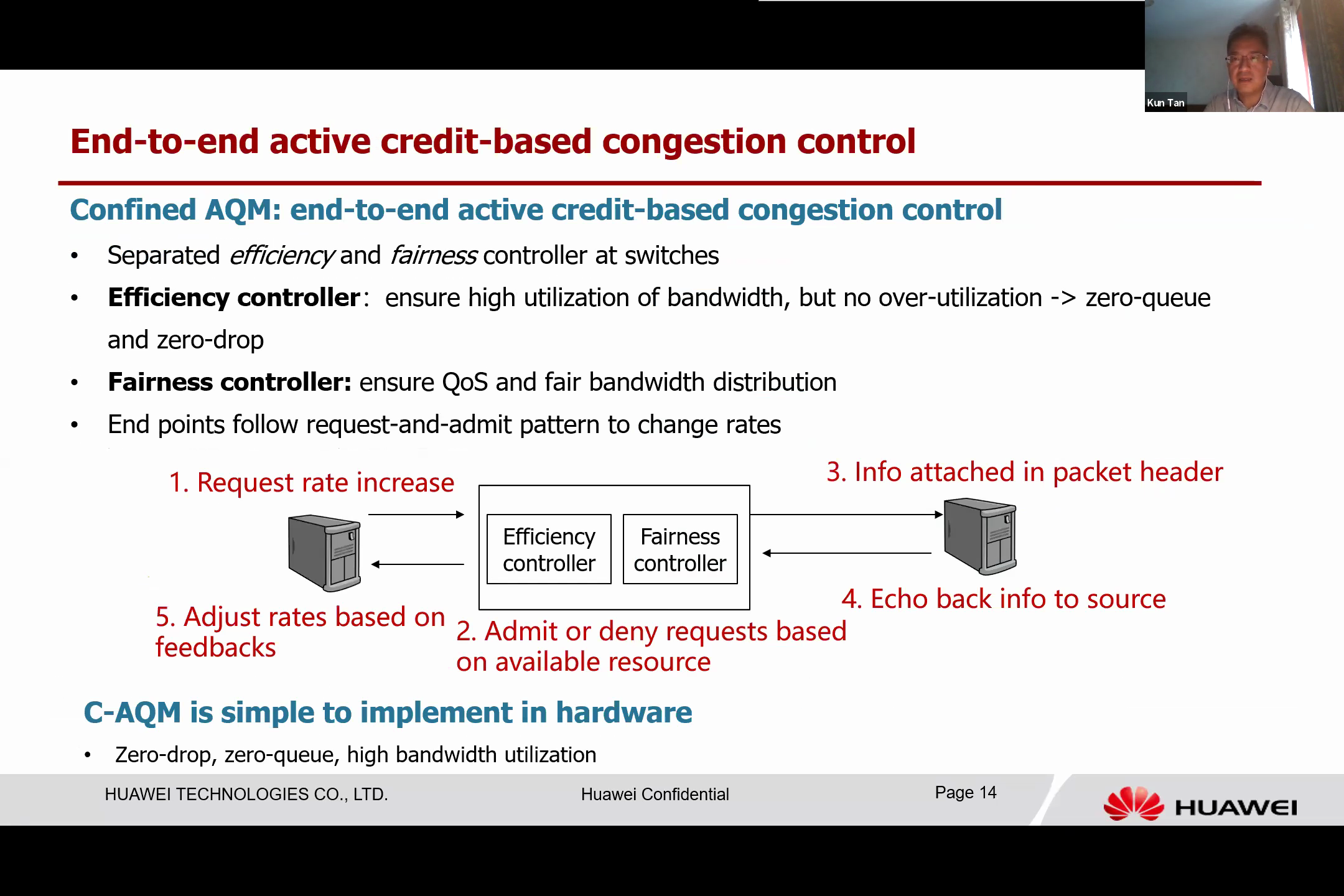
Now we talk about the design of a new type of congestion control protocol we refer to as “Confined AQM”, or C-AQM. This protocol operates on an end-to-end, active credit-based congestion control principle. The fundamental concept is that the endpoint and intermediate switch work in harmony, adhering to a request and admit pattern.
When the end system wishes to alter the rate, the switch separates the efficiency controller from the fairness controller. The efficiency controller’s primary purpose is to ensure that the link bandwidth is highly utilized but not overly so, aiming to achieve almost zero queue and zero drop. Simultaneously, the fairness controller works to maintain the quality of service and achieve fairness among the competing flows.
The workflow of the Confined AQM protocol is as follows: when a system attempts to increase the rate, it sends a request and embeds this into the packet header. As the packet header passes through each switch, the efficiency controller determines whether it is going to be allocated or not, based on the available bandwidth on the switch port. The fairness controller then operates independently, taking the bandwidth from high-rate flows and directing it toward lower-rate flows.
The switch decides whether to authorize the request, sending that information back in the packet header when it arrives at the destination. This information is then echoed back in the acknowledgment headers, and upon arriving at the source, the rate is adjusted based on the feedback.
One significant challenge in designing this scheme is ensuring that the protocol is simple and can be easily implemented in hardware to achieve zero drop, zero queue, and high bandwidth retention.
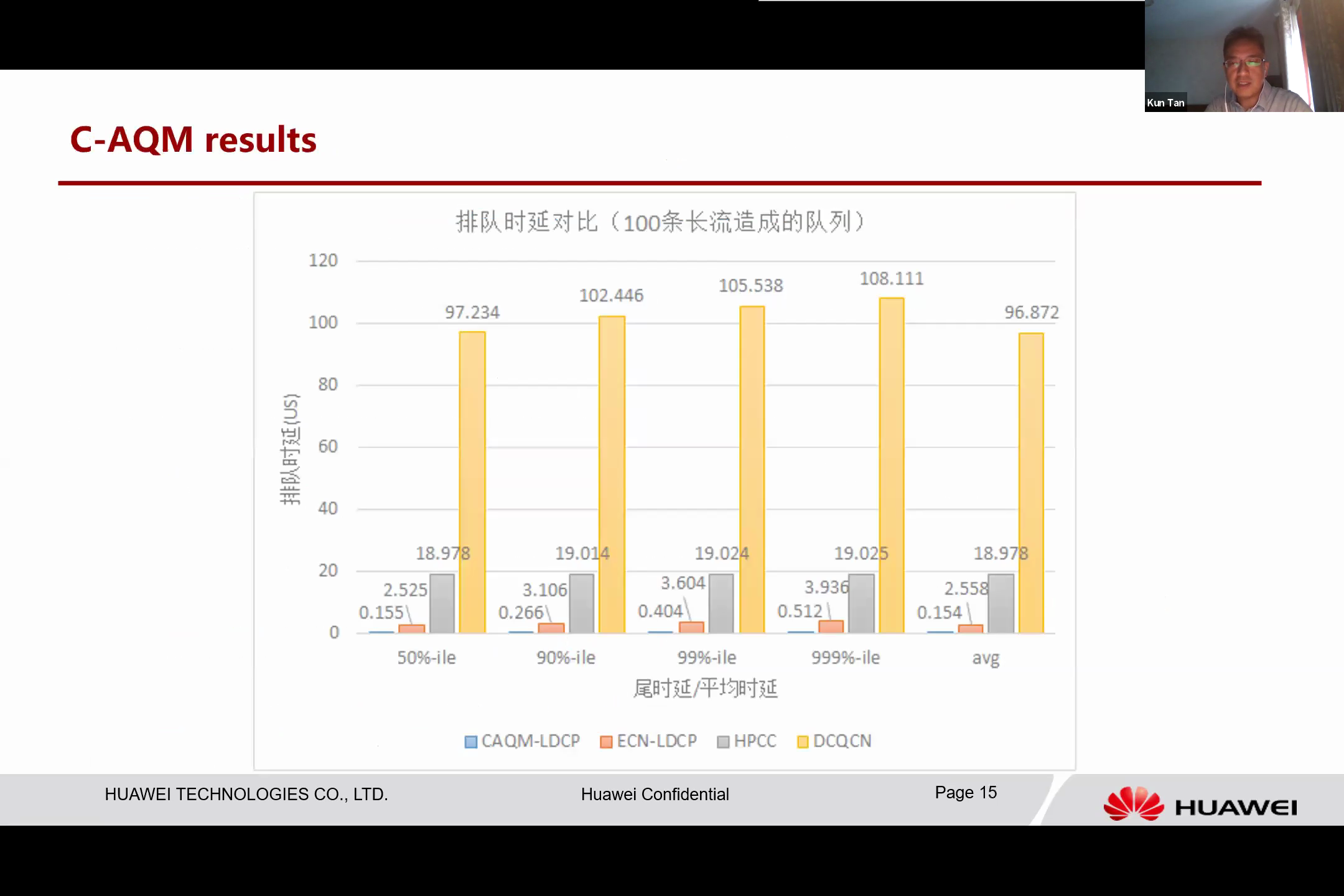
Simulations have shown that compared to conventional congestion control, which often results in higher queue delay, our method offers improved performance by proactively adapting to conditions.
The existing system can experience a significant delay when contracted. However, the delay is nearly eliminated thanks to an efficient controller that works effectively to circumvent this condition.
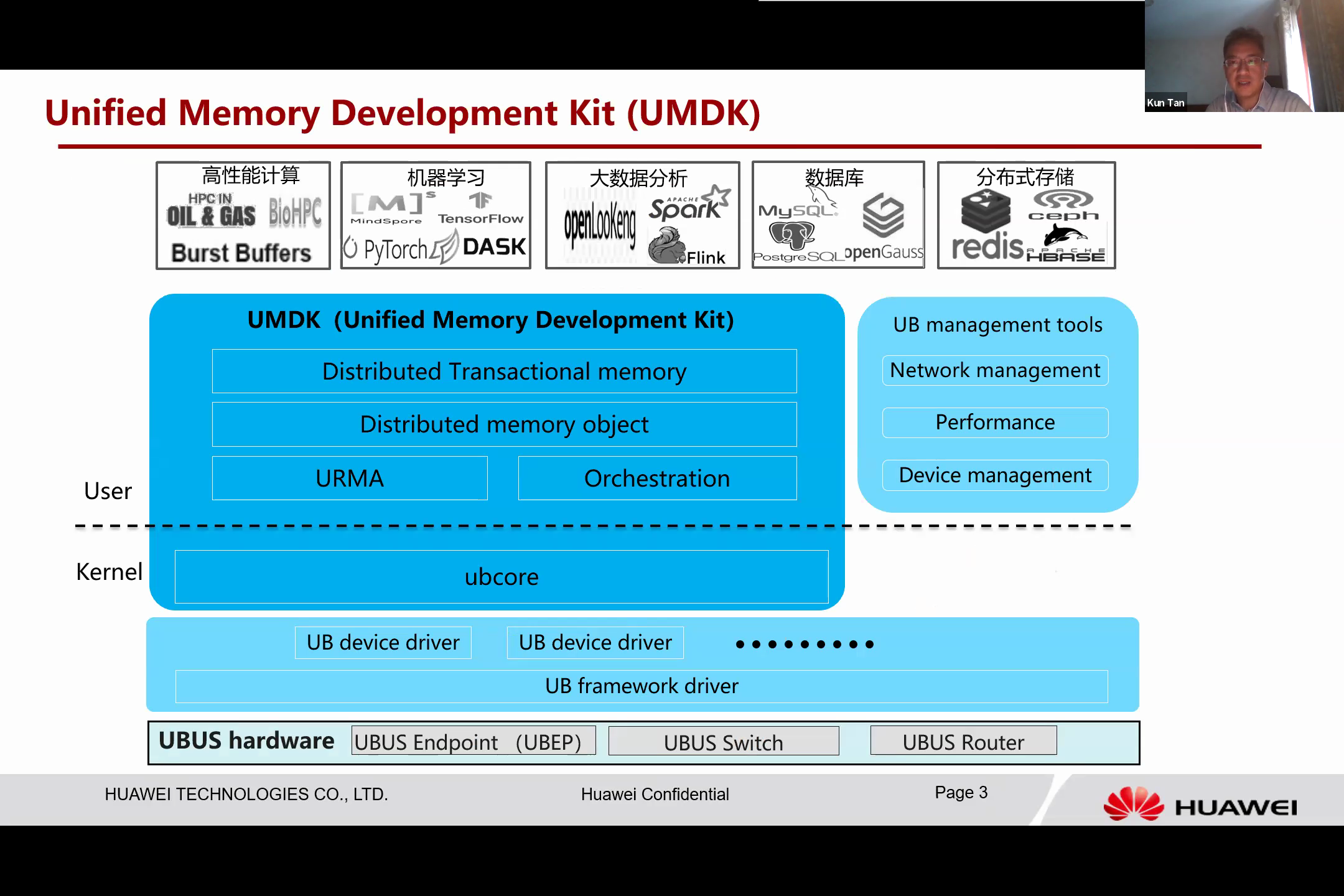
It should be noted that URMA is still a very low-level semantic. To facilitate programming, we have designed a unified memory development kit around URMA operations. It provides a range of programming APIs to programmers, not only these very low-level URMA APIs, but also a framework that one can orchestrate memory transactions with. In addition, it contains high-level abstractions, allowing for easy use of this shared memory.
With the distributed memory operations API, one can essentially manage memory over this shared memory and also distribute transactional memory. This provides inherent UB features to build transactional memory, enabling the creation of distributed data structures that can be updated atomically. This shared memory can, therefore, be easily utilized.
The UMDK aims to provide the same API, even without UB hardware. In fact, this UMDK can operate with existing hardware, but with software simulation for all these features. This has convinced us that it is building a bridge for the application to shift from the current programming model hardware to the UB-labeled system.

In conclusion, we propose a new type of network: a compute-native network. We believe this will be a paradigm shift for future distributed systems. It’s a memory-centric, scalable, high-performance unified interconnection designed to connect all heterogeneous devices. It has many applications in AI computing, responsible computing, big data, and HPC.
However, we are still facing many challenges before we can fully realize this vision. One such challenge is translating protocol design into high-performance chip design, which requires a greatly simplified protocol due to the limited hardware area resources.
We also aim to support cache concurrency in the Unified Bus (UB), but we still need to determine the type of cache concurrency necessary to support a system of such large scale.
When dealing with a large-scale system, failures are unavoidable. Currently, memory faults are not handled efficiently in the existing operating systems. We require a more graceful and elegant approach to handle memory faults.
We also need to expend considerable effort in shifting existing applications and utilizing UMDK to optimize their performance.

I believe I have covered all topics for today. Thank you, and I welcome any feedback.
(Session Chair Prof. Kai Chen) Thank you for the talk. We can now field some questions. You may ask the first question.
Question 1: Thank you for the impressive talk. I concur with your philosophy and design concept, but I have a question to better understand your work.
On your sixth slide, you compared the existing traditional processing methods where an operating system in the middle handles other devices and requires drivers. In the diagram below, in my understanding, these functions like memory MMU or disc management have not magically disappeared. Instead, they have been relocated somewhere else in a different form. For instance, you might have moved a subset of operating system functions into Network Interface Card (NIC) or into System on a Chip (SOC), or you might have a dedicated chip to handle that.
You also need some sort of hardware adaptation layer to serve the functions previously provided by the drivers. In your subsequent slides, you mentioned some global automation to handle, for example, address conflicts. There might be some challenges when you plug in more memory or disc, or add new devices. Some devices may even leave the network.
I am not sure whether my understanding is correct or if you have a different approach to solving these problems.
Answer 1: This figure is intended to illustrate the benefits from the data path. Of course, you still need a management plane to manage, for example, metadata lookups and resource allocation for blocks on the storage. We still need this sort of work somewhere, perhaps in the operating system.
This is just to illustrate the overhead of data path access. This means that once you have this block and you want to write data on it. So why we still need a system like VBS? This is due to the lack of a virtual address in the current system, regardless of whether it is a network, RoCE, or IO. In these systems, you need the operating system in between to ensure security and separation.
However, the Unified Bus (UB) is different. It innately supports virtual addresses and different virtual address spaces. The hardware utilizes UB memory management unit (UBMMU) to do the isolation. This allows the resource to be exposed directly to the application. Therefore, the application writes just as if it was writing to memory.
This is essentially how the benefits from the data path are derived.
Question 1: Thank you. So, when adding such layers in different places, one might wonder how they compare to previous designs or what the rationale is behind their potential superiority. The benefits stem from the fact that we now have a virtual layer to resolve the virtual system.
Answer 1: This is not in the software; the virtual address is primarily handled by the hardware. The address is translated in the hardware.
Question 1: So we need some global knowledge to resolve address conflicts?
Answer 1: Address conflict resolution is easy with the UB End Point (UBEP). The UB address has three tuples. Each node ID essentially identifies the resource located on the computing devices or computing node. It has an address space which can be treated as an application ID, or it can be understood as a resource divided naturally by the different virtual spaces.
By using this, you gain sufficient knowledge for the data path. Of course, we still have the control plane and management plane to allocate this address space and identify where the resource is located, i.e., at which computing node. We still have this logic in software, but we believe that the management plan is visited less frequently than the data plane.
Question 2: I indeed have two questions: one that is somewhat technical, and another that is a bit more abstract. I’m curious as to whether this should be referred to as “Network Native Computing.” However, setting that aside, I’m particularly interested in your congestion control mechanism.
In the past, I explored credit-based congestion control when I commenced work on ATM. Subsequently, we were faced with two options regarding this credit-based control. One was adopting the ECN idea, which resonates with your approach of piggybacking information from the remote end and maintaining credits to ensure zero loss and minimal queuing.
Nevertheless, people eventually opted for hop-by-hop solutions instead of end-to-end, primarily due to the formidable challenge of handling buffering variability. If you choose end-to-end, you risk overextending the buffering. Have you given this any thought?
My preference is for this system to function than to resort to the hop-by-hop credit-based control that we eventually settled on. This approach integrates my ECN idea with credits, but it does present a challenge. I’m curious to know if you’ve considered this.
Answer 2: I’m trying to comprehend your concerns about buffer management within the switch system. Your primary concern, as I understand it, is how we manage, for instance, the startup process. When a flow begins, we transmit a burst of packets without any knowledge of the system’s state.
Question 2: Even in the presence of minimal variability, some buffering is necessary, correct?
Answer 2: The proposal differs slightly from the ECN idea. It proposes that you be notified not only when congestion occurs and a backup is needed but also when I wish to take the additional buffer implemented by incorporating red and lead to confirm alignment with the switch.
The concept is akin to using software to place requests in the header. If these requests are recognized within the network switch, they need to be addressed in the subsequent round. Otherwise, these requests are lost and need to be reissued. By adhering to this protocol, at least we ensure the buffer already exists within the intermediate switch before data transmission occurs.
Question 2: I agree that if there is a method to truncate this loop, handling could potentially occur with a smaller amount of buffering.
Answer 2: Indeed, it is a sound proposal to expedite the process when a decision change occurs. One could send feedback directly from the switch to the source, instead of routing it to the end and back. We have considered this design, however, its complexity has been a deterrent. We might explore this option later, but for now, we leverage the end transaction method.
The transaction procedure currently involves sending a request, receiving a response, and executing the response. This three-way authentication is what we currently utilize.
Question 3: Given the complexity and cost, I have a broader question. In the early ‘80s, there was a struggle to create a framework similar to this one. The goal was to have a single universal connector or cluster for storage and networking. We had difficulty meeting everyone’s needs at a cost point that made sense.
Revisiting this issue, I wonder if you have considered these issues and might have insights on why this might have fundamentally changed. Why does it make sense now to do this?
Answer 3: This is indeed a good question. When we started, we faced many challenges. However, there are two things I believe are worth considering.
First, I think the computing device types we handle are becoming less varied. When we examine our cluster, we find that previously we had various types of devices including storage, memory, computing XPUs, and numerous types of I/O devices, all operating at a slow speed. Now, when we observe this center, all the devices are evolving, and what remains are memory and computing devices. Even storage has transformed into memory. Consequently, computers have become more diverse. We have general computing CPUs, GPUs, NPUs, DPUs, and various types of DSAs. However, all of these computing devices are akin to processors and have memory.
This change implies that the different semantics we have created have converted to memory semantics. This leads us to the idea that we need to change the main semantics with the network, transforming it into memory semantics instead of a byte stream abstraction. This forms a significant part of our motivation. We need to interconnect all types of devices as computing devices, these XPUs, using memory protocols. So, memory protocols might become the majority rather than the stream.
Question 4: I understand you’re curious about the underlying communication protocol we use in this Unified Bus (UB) design. Are we still using the Ethernet, IP, or have we developed a new one?
Answer 4: Indeed, we have developed a new protocol. As I mentioned earlier, we are aiming for very high speeds, trying to boost it to around 800 gigabit per second per lane.
This new protocol functions at the network layer, similar to an IP network, but we are using different types of headers. These headers can embed congestion information and multi-path information, thus supporting multi-path routing.
We have taken some design cues from the existing IP network, but not all features align. The most significant difference is that we have adopted the whole SDN approach instead of routing because we are focusing primarily on the cluster data center type of network.
Question 4: So, this means that you have developed a new communication protocol to replace Ethernet and replace PCIe, right?
Answer 4: Yes.
Indeed, we can still operate IP. Essentially, one can continue utilizing IP over Unified Bus (UB).
(Session Chair Prof. Kai Chen) Are there any questions from anyone? If not, let’s express our gratitude for this insightful session. Thank you.
(The End)