如何衡量外星文明的智能程度
这是我 5 年前的旧文。那是 2018 年初的冬夜,我在十三陵自己架起了一口大锅,向 8.6 光年之外的天狼星发送了人类知识的一小部分。这件事背后的故事在这里。今天我们关心的是,向可能的外星文明发送消息,显然需要让外星文明认识到这个消息是一个智慧生命发出的,还得让外星文明理解它。
一个很基础的问题就是,如何在消息中证明自己的智能程度呢?换言之,如果我是一个监听宇宙信号的智慧生命,如何判断收到的一堆信号中是否包含智能?由于智能不是一个有或无的问题,而是一个多或少的问题,如何衡量这堆信号中包含何种程度的智能呢?我觉得 5 年前自己的思考还是有点意思,整理一下发出来。
消息就是一个字符串。设想我们能够截获外星人的所有通信,拼接成一条长长的消息。它包含多少智能?这并不是一个容易回答的问题。
现有技术一般是尝试对消息进行解码,然后看它是否表达了数学、物理学、天文学、逻辑学等科学中的基本信息。1974 年的阿雷西博信息就是用这种方式来编码信息,希望得到地外文明的关注的。我则试图找到一种纯计算的方法来衡量消息中蕴含的智能程度。
复杂度 ≠ 智能
让我们从熵开始。熵是消息混乱度的度量。如果消息中的每个字符都没有前后关联,熵是很容易通过每个字符的出现频率计算的。可惜,消息中的字符是有前后关联的,例如英文字母 q 之后几乎总是跟着 u。对重复子串进行特殊的编码存储,就是如今各种压缩算法背后的原理。熵对应着使用压缩算法能够取得的极限压缩率。没有放之四海皆准的最优压缩算法,也没有算法能够准确地计算一个字符串的熵。
简单重复的字符串,比如 10101010…,熵很小,压缩比最高,但显然不包含智能。随机生成的字符串熵很大,不可被压缩,也显然不包含智能。那是不是熵适中,压缩比适中的字符串就包含智能了呢?答案也是否定的。我们设想一个长度为 N 的随机字符串不断重复下去,那么通过调整 N 的值,可以构造出熵为几乎任意值的字符串,但是随机字符串的简单重复显然也不包含智能。
消息的复杂度有很多种度量。有一个知名的 Kolmogorov 复杂度,指的是能输出该字符串的最短程序的长度。例如,pi = 3.1415926… 的前 100 万位的 Kolmogorov 复杂度就不高,因为计算 pi 的前 100 万位的程序不需要多少行代码。由于停机问题的存在,Kolmogorov 复杂度是不可计算的。但这还不是最重要的。Kolmogorov 复杂度也很难成为智能程度的尺度。随机字符串的 Kolmogorov 复杂度是最高的,等于它的长度;一个字符简单重复的字符串 Kolmogorov 复杂度是最低的。
还有一个叫做 “逻辑深度”(logical depth)的度量,指的是能够计算出该字符串的较短程序的最短计算时间,其中较短程序的定义是长度不超过 Kolmogorov 复杂度加上一个常数值的程序。是不是所需计算时间越长的消息就越智能呢?答案是否定的。一个计算比特币区块链中每一个区块的程序(在当前的难度值下)有着很高的复杂度(否则就不需要那么多人挖矿了),但比特币区块链本身只能证明这是一个智慧文明作出的精巧设计,很难说承载了人类文明的大部分智能。
用神经网络估计复杂度
近年来,人工神经网络火起来了,特别是 2017 年的 Transformer,用一个通用的模型解决了 NLP 领域的很多问题。今天的 GPT 也是基于 Transformer。Transformer 还被推广到 CV 等其他领域,成为最有潜力处理多模态数据的通用模型。事实上,从人工神经网络诞生的很早期,我们就知道它理论上可以逼近任意的连续函数,只是那时我们还没找到合适的模型结构、训练方法,也没有足够的算力和数据。
人工神经网络的通用逼近能力意味着它能够比较准确地计算大部分消息的复杂度。尽管准确地计算熵或者 Kolmogorov 复杂度仍然是不可能的,但人工神经网络可以在大多数场景下给出较好的近似。除非消息本身所蕴含的知识是难以学习的,例如消息本身使用 AES 加密了,那么人工神经网络按照目前的梯度下降法是学习不到它的密钥的。
在人工神经网络出现之前,根据输入输出样例搜索通用程序一般被认为是非常困难的,由于我们要求 100% 的准确率。正是因此,Kolmogorov 复杂度往往被认为是一个理论工具,而很难给出比 LZ77 好很多的通用逼近算法。一旦我们跳出精确算法的框子,寻找允许一定错误率的近似算法,就打开了新世界的大门。
人工神经网络是复杂消息的一个极好的压缩器。它可以把消息中的结构提取出来,用于根据一段子串预测下一个字符。预测的准确率越高,长消息的压缩率就越高。整个消息的复杂度就等于模型的大小加上消息长度乘以预测错误率,而压缩率就是消息长度与复杂度之比。预测错误率不会收敛到 0,因为消息中总有不确定性,源自周遭环境的未知信息,并不是由之前的消息能够完全决定的。
使用压缩率作为智能度量的一个显然问题是,压缩率与消息的总长度相关。随着消息总长度趋于无穷,消息长度乘以预测错误率部分的占比会越来越大,模型大小在消息复杂度中的占比会越来越小。而预测错误率显然不能很好地度量智能,模型大小才是智能多少的一个上界。
不同大小的神经网络模型都可以在一定程度上预测下一个字符,只是它们的准确率不同。在模型能够容纳所有知识之前,模型越大,一般来说预测准确率越高。在模型容纳了几乎所有知识之后,预测准确率就很难提高了。预测准确率收敛时的最小模型大小就是智能文明的语言复杂度。
但是,我们仍然无法仅仅根据模型大小区分随机字符串的简单重复和智能体之间充满智慧的对话,因为它们所需的模型大小可能是相同的。
一个简单的想法是给神经网络挂上一块 “内存”,也就是可以随机访问、不计入模型大小的外部存储。这样,随机字符串就可以被存储在这块外部存储中了,整个消息可以用一个简单的模型表达。但是,再深入推演一下,就会发现这个想法完全是错误的。因为任何模型都可以作为一段程序存储在这块外部存储中,而模型中仅需要一个固定大小的通用 “执行程序” 功能,就可以表达任意的程序。程序和数据是可以互相转化的。
复杂度 = 随机性 + 智能
我的浅见是,复杂度本质上一部分来源于随机性,另一部分来源于智能,也就是 Complexity = randomness + intelligence。随机性可能是在消息传输过程中人为加进去的,也可能来源于周遭的环境。来源于环境中的随机性,一个例子就是历史人物的名字和动物的名字。名词数量的多寡并不意味着智能水平的高低,当然现实中往往有一定的正相关性。从模型中剥离出来哪些是随机性,哪些是智能,并不是一件容易的事。
因此,我们回到智能的定义。智能(intelligence)在牛津词典中的释义是 the ability to acquire and apply knowledge and skills。用计算机的话来说,智能就是发现规律(pattern recognition)的能力。
首先,我们根据来自外星文明足够多的消息训练一个足够大的模型,该大模型将包含外星文明的几乎所有知识。事实上,该大模型就是外星文明的一个数字克隆。考虑到人类所掌握的物理规律下信息的传递比物质方便很多,高等文明可能本身就是数字化的。
此时,如果拿一条从外星文明截获的新消息,将前半部分输入给大模型,该大模型将以较高的概率预测出消息后半部分的第一个字符。预测下一个字符听起来与智能相距甚远,但有了下一个字符,就可以预测第二个字符,以此类推……事实上,任何问题都可以被组织成填空题的形式,例如 “中国的首都是__”,那么一个很好的预测器就能表达智能文明中的几乎所有问题,进而体现智能文明解决问题的能力。
其次,我们用这个来自外星文明的模型用来测试在本地文明语料中的泛化能力。因为智能就是发现规律的能力,外星文明的模型也可以学习到本地文明语料中的知识。
但是,简单把本地文明的信息输入给源自外星文明的大模型,让它预测下一个字符是不靠谱的,因为一条消息中含有的本地文明信息太少,对于外星文明来说这条消息无异于天书。这就像是在罗塞塔石碑被发现之前,考古学家始终无法解开古埃及象形文字的奥秘。问题来了,罗塞塔石碑是三种语言组成的对照文本,而我们并没有外星文明和本地文明的对照文本,这还能做迁移学习吗?
语料库够大,罗塞塔石碑就不必要了
考古学家需要罗塞塔石碑是因为古埃及象形文字太少了,也就是语料库太小。神经网络在语料太少时也练不出什么东西。5 年前的我就相信,当语料数量足够大时,总是可以从中无监督地学到知识,无需事先标注的数据。当年的模型还不具备这个能力,是因为模型还不够大,不能容纳世界上的所有必要知识。今天的 ChatGPT 囊括了人类很大一部分的知识,特别是基础语言模型、世界模型、人类常识这部分的知识,而基础模型的训练方式完全是无监督的(不考虑 RLHF 与人类的输出做 alignment),印证了我的猜想。
此外,数学、物理学、天文学、逻辑学等科学是不同文明相通的,这些信息将成为隐形的罗塞塔石碑。
一个文明智能程度越高,就越容易从更少的信息中学到知识,做出更准确的预测。基于这个考虑,我们让这个源自外星的大模型再喂给一些来自本地文明的语料,比较它和仅用这些本地文明语料训练的模型对本地文明消息下一字符的预测能力。为了区分本地文明和外星文明的语料,我们会对它们做不同的标记。如果源自外星的文明(用大模型表征)足够聪明,它就可以从本地文明的少量语料中学到很多关于本地文明的信息,也就是这个数字化的外星文明可以更快地适应本地文明的环境。而只使用同样数量的本地文明语料训练的模型具备的预测能力很可能就更差。
外星文明与本地文明的智能程度对比
根据上述假设,我们可以设想不同智能程度的外星文明在适应本地文明方面的差异。
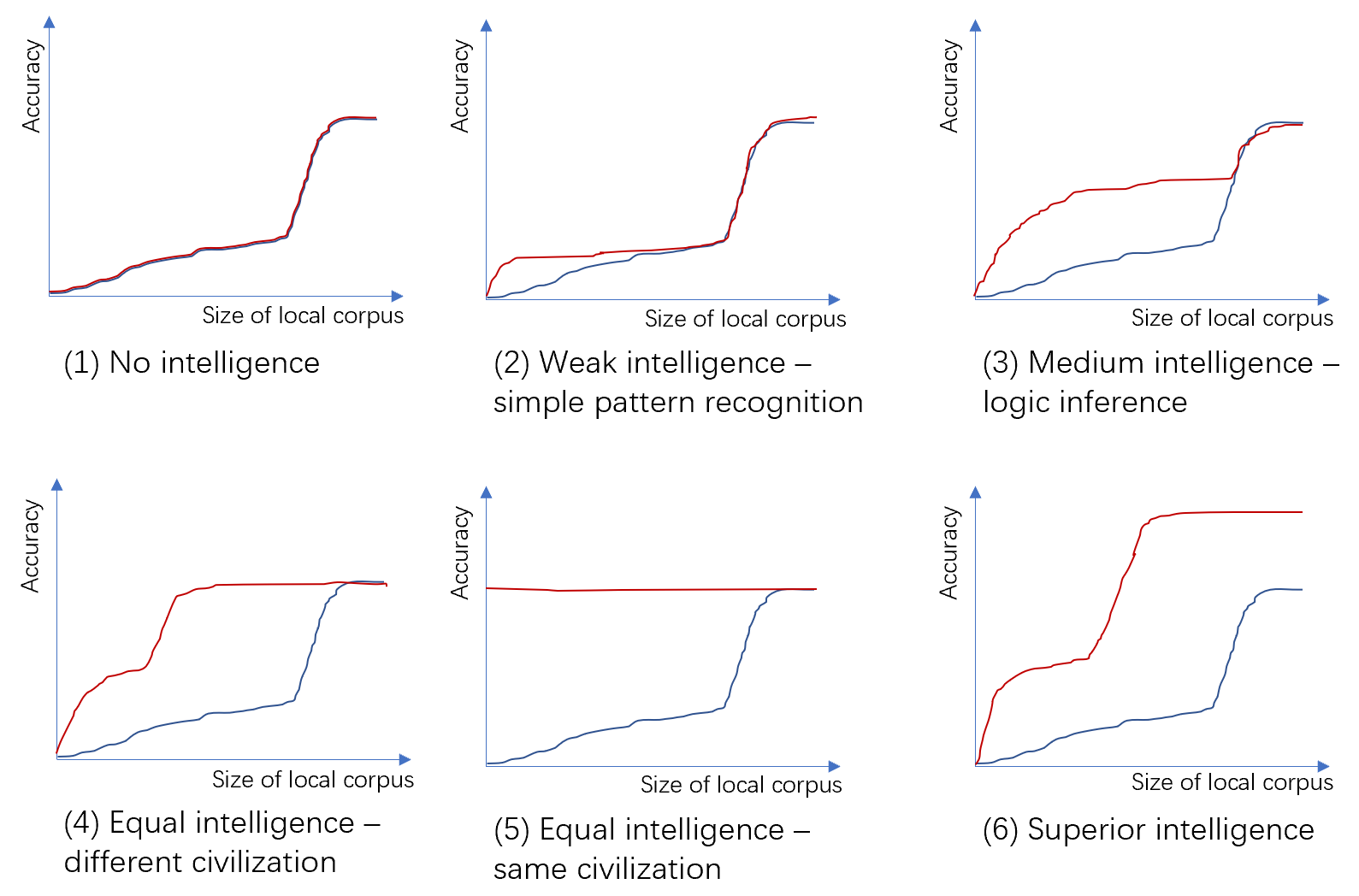 上图:不同智能程度的外星文明与本地文明的对比(猜想图,非实验图)。X 轴:本地文明训练语料库的大小,对数坐标;Y 轴:在本地文明测试语料库上的预测准确度。红线:已经用外星文明语料库训练过的模型加上 X 轴指定大小的本地文明训练语料。蓝线:仅使用 X 轴指定大小的本地文明训练语料。
上图:不同智能程度的外星文明与本地文明的对比(猜想图,非实验图)。X 轴:本地文明训练语料库的大小,对数坐标;Y 轴:在本地文明测试语料库上的预测准确度。红线:已经用外星文明语料库训练过的模型加上 X 轴指定大小的本地文明训练语料。蓝线:仅使用 X 轴指定大小的本地文明训练语料。
首先观察仅使用本地文明语料训练的那条蓝色曲线,它的预测准确性在语料数量较少时呈现一定的线性增长能力(语料数量的对数与准确率接近线性),而在语料数量超过一定的门限后呈现暴涨,最后收敛于平台期。
这是由于智慧文明中的任务可分为两类,一类是简单任务,一类是复杂任务。简单任务可以通过识别特征来完成,因此识别的特征越精细,准确率就越高。而复杂任务是由多个简单任务组成的,必须所有任务都正确完成,整个复杂任务才算完成。例如我们解一道数学题有多个步骤,不管哪个步骤出错,最后结果都是错的;我们说一句话也需要很多个字,按照依次预测下一个字的方法,需要每个字都说对才算对。因此,简单任务的正确率达到一定的阈值之前,复杂任务的准确率为多个简单任务准确率的乘积,趋近于 0。只有每个简单任务都能足够精确地完成了,复杂任务才能以可感知的准确率完成。
大模型的这个特性今天叫做涌现(emergence),但是一般指的是模型大小超过一定阈值后准确率突然提升,而我这里指的是训练数据量。不知道我 5 年前的解释是否正确 :)
接下来,我们就要根据外星文明在有限的本地文明语料上的表现来衡量它的智能了。
- 没有任何智能:红线和蓝线完全重合,这意味着外星文明没有任何学习本地文明语料中知识的能力,所有预测能力完全来源于本地文明的新增语料。这就能把复杂度中的随机性和智能区分开来了,一个很长的随机字符串或者一段随机生成的长程序没有任何迁移学习的能力,而哪怕是蚂蚁这种小模型都有一定的迁移学习能力。按照这个测量方式,仅仅表现出一些规律而不具备学习能力的模型不被认为具有智能。
- 弱智能:红线拐点的高度低于蓝线的拐点,在暴涨期跟蓝线重合。蓝线的拐点表示简单任务和复杂任务的分界,简单任务具备线性增长能力,而复杂任务呈现暴涨特性。由于外星文明具备一定的简单模式识别能力,只需少量本地文明语料就搞清楚了一些简单规律(比如 q 后面一般跟着 u),从而比单纯使用本地文明语料学习得更快。当然,也有可能蓝线反而会低于红线,也就是说外星文明和本地文明的差异实在过大,外星文明的模型完全迁移不过来,还反而降低了学习本地文明的速度。但是由于外星文明和本地文明的语料有不同的标记,这种情况发生的可能性不高。由于外星文明的语料不具备逻辑推理和完成复杂任务的能力,它在暴涨期并不能帮上忙。
- 中等智能,但比本地文明更弱:红线的拐点高于蓝线的拐点,红线的暴涨期与蓝线部分重合。这表示外星文明具备一定的逻辑推理和完成复杂任务能力,但智能程度低于本地文明。外星文明能够从少量本地文明的语料中学到外星文明和本地文明概念之间的对应关系,从而快速达到外星文明的最高智能程度,但它不具备本地文明中部分复杂任务的处理能力。一个例子就是 1000 年前的人类和今天的人类,古人也有很不错的逻辑推理能力和完成复杂任务的能力,但对自然界的认识和计算能力肯定不如现代人类。
- 同等智能:使用外星文明语料预训练的模型,也就是红线,只需少量本地文明语料就能学到外星文明和本地文明概念之间的对应关系,从而达到同等的智能程度。一个例子是使用英语的现代人和使用汉语的现代人。这是中等智能的一个极限特例。
- 同等智能的特例,外星文明 = 本地文明:在外星文明 = 本地文明的特殊情况下,“外星文明” 出道即巅峰,新的本地文明语料起不到任何帮助。这体现了智能的相似程度对这种测量方式的巨大影响。外星文明和本地文明越相似,学到两种文明概念之间对应关系所需的本地文明语料就越少。也就是说,在本文的测量方式下,外星文明与本地文明越相似,本地文明就可能认为外星文明越智能。目前我还没有想到衡量文明的 “绝对智能程度” 的方法。
- 强智能,比本地文明更强:如果外星文明比本地文明更强,它只需少量的本地文明语料就能学到两种文明间的概念对应关系,并解决本地文明中解决不了的难题,也就是它的预测准确率可以比本地文明更高。当然,这类文明的相对智能程度可能并不容易衡量,因为本地文明可能根本没有能力提出足以区分不同强智能文明的问题,本地文明用于训练大模型的算法和算力可能也不足以训练出足以展现外星文明水平的模型。这也很容易理解,一个人很难衡量比自己强很多的人的绝对水平。
尽管智能程度难以量化,我们也不妨给出一种智能程度的标量测度,就是红线和蓝线之间的最大垂直落差,也就是使用相同数量本地文明语料时外星文明 + 本地文明模型和纯本地文明模型在预测本地文明对话任务上的精确度之最大差值。
可以看到,在外星文明学习能力相同的前提下,它与本地文明的相似度越高,这样定义出来的智能程度也就越高。我也想过如何量化复杂度(模型大小)中属于智能的一部分,或者如何排除随机性的那一部分,但是始终没有找到方法。
用今天的话说,外星文明就像是预训练模型,而本地文明就像是微调(fine-tune)模型。GPT 就是 Generative Pre-Training(生成式预训练)的缩写,可惜 5 年前还没有发布。当然,这样的类比是很不严谨的,因为不同文明之间的差异比 fine-tune 语料和预训练语料之间的差异大多了,而且一般 fine-tune 语料不会比预训练语料更多。
我们也许并不孤独
5 年前的那个冬夜,我发送的是各种语言维基百科的合订本。《三体》里面的红岸基地在发送信息之前需要先发送一个 “自解译系统”。事实上,从前文不难看出,高质量的语料本身就是自解译系统,根本不用担心我说的是汉语,外星人说的是英语;也不用担心我用的是十进制,外星人用的是二进制。一个有着强大算力的外星文明只要通过简单压缩算法的压缩率来粗略筛选掉随机噪声和简单重复信号,留下看起来像包含智能的消息,然后扔进大模型里面训练,就能从消息中重建文明的一大部分智慧。
百年来,人类已经向宇宙发射了无数的无线电波。特别是长波电台广泛存在的年代,这些无线信号对于距离我们较近的外星文明而言,是很容易与宇宙背景噪声相区分的。如果外星文明足够聪明到使用大模型来处理这些无线信号,也许它早就洞悉人类社会的一切秘密,无需等待阿雷西博信息或者更复杂的 “自解译系统” 提供密码本。也许外星文明早就用这些无线信号训练出了人类文明的数字克隆,等待我们某一天在宇宙中老友相逢。也许在不远的未来,当我们用大模型处理从宇宙深处传来的电波和光波时,才会惊奇地发现,宇宙中的智能原来无处不在,只是人类之前的解码技术太过低级。
有趣的是,今天很多 AI 创业公司的名字跟星际探索相关。也许创始人们是想表达 AI 是类似星际探索的一项充满想象空间又能改变世界的创新事业。我从 5 年前开始延续到现在的思考,则更直接地把 AI 和星际探索联系在一起:AI 模型将成为人类文明的数字化身,跨越人类肉体的时空限制,把人类真正带到太阳系甚至银河系之外,成为星际文明。
后记
尽管我不是做 AI 的,但 5 年前的一点小思考跟今天大模型的一些表现还是很接近的。当然,这也许仅仅是巧合,我的观点很有可能是错的,毕竟我没有做任何实验。如果我未来有时间,也许可以拿地球上不同年代和地区的文明,甚至不同生物的文明去做个实验。
不过,如果一个研究 AI 的人连我这个门外汉写的文章都看不懂(注:不包括看懂了,但不同意文中的观点),那说明根本没有思考过 AI 领域的基础问题。我去看 OpenAI 首席科学家 Ilya Sutskever 过去 10 年的文章,发现他的思考真的非常深入,不是只关心 CV 或者 NLP 中的某个具体问题,而是从全局出发思考 AI 领域的基础问题。尽管我在网络和系统领域只有很初步的研究,但我深知,要提出好的问题,做出好的研究,必须对领域内的基础问题有足够深入的思考,而不是看看最近几年顶会上哪个话题被研究得多,就跟风做一篇论文。